Hi, we're Apify, a full-stack web scraping and browser automation platform. If you're interested in using Python for web scraping, this tutorial shows how to use timeouts effectively in the Python Requests library for any HTTP request.
You need to use timeouts when making requests in Python. They prevent your program from freezing indefinitely while waiting for a response from external servers or APIs.
In this article, you’ll learn how to use timeouts effectively in the Python Requests library for any HTTP request. You'll learn:
- how to set connect and read timeouts
- handle timeout exceptions
- use timeouts with sessions
- use timeouts in a multithreaded environment
We'll also provide some practical code examples and explore alternatives to the Python Requests library.
Python Requests
The Python requests library makes sending HTTP requests incredibly easy. As one of the most popular Python packages with over 30 million weekly downloads, Requests is relied upon by over 2.5 million repositories on GitHub. It supports various HTTP methods (GET, POST, PUT, DELETE) to interact with APIs, enabling CRUD operations on API resources. Requests is also a popular tool for web scraping tasks, simplifying the process of fetching website content and allowing you to extract valuable data.
You can install Requests using the following command:
pip install requests
Why implement timeouts in Python Requests?
When making requests to external servers, you have to set timeouts. If a server doesn't respond promptly, it can cause your application to freeze or run indefinitely, which is not only frustrating for users but also wastes resources like CPU cycles, memory, and threads in small amounts.
The requests library doesn't come with default timeouts. So you must explicitly configure them using the timeout parameter to avoid unnecessary delays and resource wastage.
Templates for Requests, Beautiful Soup, Scrapy, Playwright, Selenium
Setting timeouts in Python Requests
To set a timeout for a request, use the timeout parameter. This parameter accepts either an integer or floating-point number, specifying the maximum number of seconds to wait for a response from the server.
Setting timeout for entire Python Requests
Let's make a simple GET request with the timeout parameter set to 3 seconds. This specifies a maximum wait time of 3 seconds for a server response. The timeout applies to the overall request, including connection establishment and receiving the response. If the request doesn't receive a response within 3 seconds, a Timeout exception will be raised
import requests
resp = requests.get("https://httpbin.org", timeout=3)
print(resp)
Setting connect and read timeouts separately
Connect timeout refers to the maximum duration allowed to connect with the server. On the other hand, read timeout specifies the maximum waiting time for a response after the connection has been established.
If you provide a single value to the timeout parameter, it will act as a combined timeout for both connection and receiving the response. However, to set separate timeouts, you can pass a tuple comprising of the connect timeout and read timeout values (connect_timeout, read_timeout) to the timeout parameter.
import requests
resp = requests.get("https://httpbin.org", timeout=(3, 5))
print(resp)
This request will time out if either the connection establishment takes more than 2 seconds or if the server response is slow, taking more than 5 seconds to transmit data.
Handling timeout exceptions
If a request times out (no response within the limit), a Timeout exception is raised. To prevent your program from crashing, handle this exception using a try-except block.
import requests
resp = requests.get("https://httpbin.org", timeout=(0.001, 0.002))
print(resp)
The result is this:
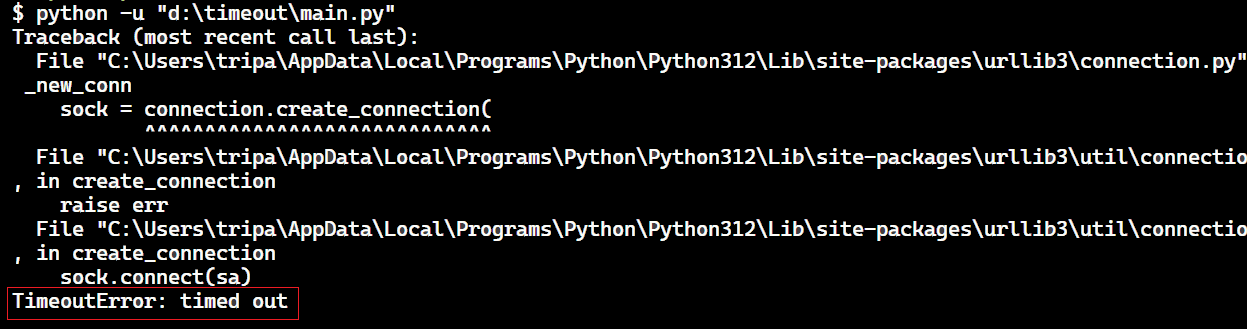
The code is causing a timeout error due to the low connection and read timeouts we’ve set. HTTP requests typically take longer than milliseconds to complete, so reasonable timeouts are essential. Establishing connections and receiving responses takes time, so using low values, like in this example, is not recommended. We only used these low values to demonstrate how timeout exceptions appear.
This error can be easily handled using try-except blocks. The following code will catch the timeout error and print a message instead of letting the program crash.
import requests
try:
resp = requests.get("https://httpbin.org", timeout=(0.001, 0.002))
except requests.exceptions.Timeout:
print("The request timed out!")
Implementing timeouts with sessions
To set a global default timeout for all requests made using the session, you can create a custom class inheriting from requests.Session and override the request method.
import requests
class TimeoutSession(requests.Session):
def request(self, method, url, **kwargs):
kwargs.setdefault("timeout", 4)
return super().request(method, url, **kwargs)
session = TimeoutSession()
try:
response = session.get("https://httpbin.org")
if response.status_code == 200:
print("Request successful!")
else:
print("Request failed with status code:", response.status_code)
except requests.exceptions.Timeout:
print("Request timed out!")
except requests.exceptions.RequestException as e:
print("Request failed:", e)
Here's what the code does:
- The
TimeoutSessionclass inherits fromrequests.Session, creating a custom session object for making HTTP requests. - It overrides the
requestmethod to intercept all HTTP requests made through the session. - Within the overridden method,
kwargs.setdefault('timeout', 4)sets a default timeout of 4 seconds for any request using this session object.
Timeouts in multi-threaded / asynchronous setups
In multi-threaded programming, handling timeouts properly is crucial to avoid blocking and ensure efficient resource utilization. Imagine you have a program with multiple threads making requests to different websites. If one of these websites is slow or unresponsive and there's no timeout set, the thread making the request will wait indefinitely for a response, effectively blocking that thread from doing anything else.
Here's an example illustrating how to handle timeouts in a multi-threaded setup:
import requests
import concurrent.futures
def make_request(url):
try:
response = requests.get(url, timeout=3)
return response.status_code, response.content
except requests.exceptions.Timeout:
return "Timeout occurred for URL:", url
except requests.exceptions.RequestException as e:
return "Request failed for URL:", url, e
urls = [
"https://httpbin.org/",
"https://scrapeme.live/shop/",
"https://quotes.toscrape.com/",
]
with concurrent.futures.ThreadPoolExecutor() as executor:
futures = [executor.submit(make_request, url) for url in urls]
for future in concurrent.futures.as_completed(futures):
result = future.result()
print(result)
The above code uses ThreadPoolExecutor from the concurrent.futures module to execute requests asynchronously across multiple threads. Each request is submitted asynchronously using the executor.submit() method. Once the requests are complete, we iterate over the futures returned by as_completed() to obtain the results and print them.
Timeout best practices
To prevent applications from hanging indefinitely, set timeouts for external server requests. Here are some best practices:
- Always set timeouts to avoid indefinite hanging, which is unacceptable.
- If you're making requests to a service that you know is quick, a shorter timeout could be appropriate. On the other hand, if the requests involve large data or complex operations, longer timeouts (up to 30 seconds) might be necessary.
- It's a good practice to set connect timeouts to slightly larger than a multiple of 3, which is the default TCP packet retransmission window.
- Implement proper error handling for
Timeoutexceptions. This allows your code to react appropriately to timeouts. - Consider retrying requests upon timeout errors or temporary network issues.
Deploy any scraper to Apify
Examples of using timeouts in Python Requests
Let's explore some practical scenarios where timeout can be effective.
Example 1: Scraping data
Let's scrape some data from the YC news website, such as URLs, titles, or rankings. We'll use a 3-second timeout and handle any exceptions that arise due to timeouts.
import requests
from bs4 import BeautifulSoup
try:
response = requests.get("https://news.ycombinator.com/", timeout=3)
html = response.text
soup = BeautifulSoup(html, "html.parser")
articles = soup.find_all(class_="athing")
output = []
for article in articles:
data = {
"URL": article.find(class_="titleline").find("a").get("href"),
"title": article.find(class_="titleline").getText(),
"rank": article.find(class_="rank").getText().replace(".", ""),
}
output.append(data)
print(output)
except requests.exceptions.Timeout:
print("The request timed out. Please try again later.")
except requests.exceptions.RequestException as e:
print("Request failed:", e)
The result is:

Example 2: Creating a GitHub repository
This example demonstrates creating a GitHub repository using a POST request. We'll specify a timeout and handle any exceptions that might occur during repository creation.
To interact with the GitHub API, you'll need to create a personal access token. For more information about interacting with the GitHub API using HTTP methods like GET, POST, PATCH, and DELETE, you can refer to How to use the GitHub API in Python.
import requests
base_url = "https://api.github.com"
def create_repo(access_token, repo_name, repo_descr=None):
url = f"{base_url}/user/repos"
headers = {
"Authorization": f"token {access_token}",
}
data = {
"name": repo_name,
"description": repo_descr,
}
try:
response = requests.post(url, headers=headers, json=data, timeout=2)
response.raise_for_status()
if response.status_code == 201:
repo_data = response.json()
return repo_data
else:
return None
except requests.exceptions.Timeout:
print("Request timed out. Please try again later.")
return None
except requests.exceptions.RequestException as e:
print("Request failed:", e)
return None
access_token = "YOUR_ACCESS_TOKEN"
repo_name = "timeout"
repo_descr = "New repo created using timeout!"
new_repo = create_repo(access_token, repo_name, repo_descr)
if new_repo:
print(f"New public repo created successfully!")
else:
print("Failed to create a new repo.")
The result is:

Example 3: Simple local application
Let's create a simple Flask app. We‘ll intentionally slow down the server by adding a sleep function. Afterward, we’ll initiate a request from the client side and observe if any timeouts occur.
from flask import Flask
import time
app = Flask(__name__)
@app.route("/order")
def order():
time.sleep(30)
return "What do you want to order today?"
if __name__ == "__main__":
app.run(debug=False, port=8080)
import requests
server_url = "http://127.0.0.1:8080/order"
try:
response = requests.get(server_url, timeout=4)
response.raise_for_status()
print(response.text)
except requests.exceptions.Timeout:
print("Request timed out. Please try again later.")
except requests.exceptions.RequestException as e:
print("Request failed:", e)
Here's the result:
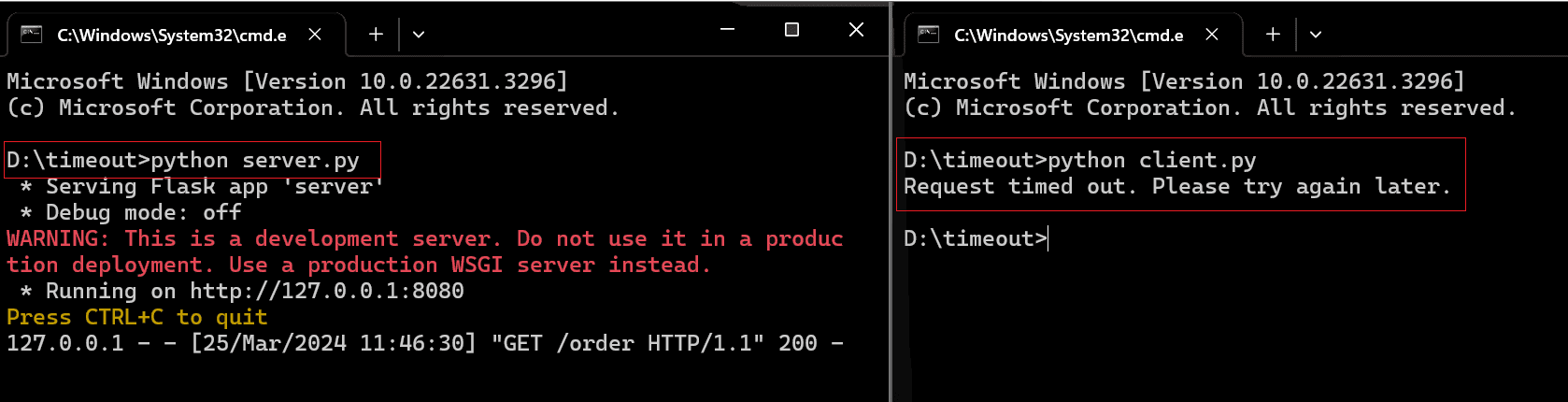
The timeout errors occur, but we’ve handled them gracefully.
Third-party alternatives to Requests
There are several alternatives to the Python Requests library, such as aiohttp, httpx, urllib3, and uplink. But here, we’ll just focus on the httpx and aiohttp libraries.
aiohttp
aiohttp is a widely used Python library that offers both server and client frameworks for asynchronous HTTP communication. It has many capabilities like custom headers, authentication, cookies, and handling redirects. It is built on the asyncio library which enables support for async/await syntax.
You can install it using this command:
pip install aiohttp
The following code handles timeouts by setting them during the HTTP request using aiohttp.ClientTimeout and catching asyncio.TimeoutError exceptions.
import aiohttp
import asyncio
async def fetch_data(url):
try:
async with aiohttp.ClientSession() as session:
async with session.get(
url, timeout=aiohttp.ClientTimeout(connect=3, sock_read=4)
) as response:
if response.status == 200:
return await response.text()
else:
print("Failed to fetch URL. Status code:", response.status)
return None
except asyncio.TimeoutError:
print("Timeout occurred while fetching the URL.")
return None
except aiohttp.ClientError as e:
print("An error occurred:", e)
return None
async def main():
url = "http://httpbin.org"
content = await fetch_data(url)
if content:
print(content)
asyncio.run(main())
httpx
httpx is a Python HTTP client library that supports synchronous and asynchronous operations.
Install it using the following command:
pip install httpx
This code uses httpx.AsyncClient for asynchronous requests and sets a timeout using httpx.Timeout.
import httpx
import asyncio
async def fetch_data(url):
try:
async with httpx.AsyncClient() as client:
timeout = httpx.Timeout(timeout=3)
response = await client.get(url, timeout=timeout)
if response.status_code == 200:
return response.text
else:
print("Failed to fetch URL. Status code:", response.status_code)
return None
except httpx.TimeoutException:
print("Timeout occurred while fetching the URL.")
return None
except httpx.HTTPError as e:
print("An HTTP error occurred:", e)
return None
async def main():
url = "http://httpbin.org"
content = await fetch_data(url)
if content:
print(content)
asyncio.run(main())
Conclusion
We've seen that timeouts are critical configurations when making requests to unreliable servers and APIs. We've also learned how the requests library provides flexible options for setting timeouts. Now you know how to use Python Requests to handle timeout exceptions, use timeouts with sessions, and use them in a multithreaded environment.