


A few weeks ago, I spent hours searching for airline tickets online. I wanted to find the cheapest flights on a particular airline for specific dates. Clicking through websites, comparing prices, and adjusting dates was quite tedious.
Fortunately, there's a solution - Selenium can automate this task. With Selenium, you can write scripts that automatically navigate websites, fill out forms, click buttons, and extract data. This means you can automate repetitive web tasks, like searching for the best flight prices across multiple dates and airlines. Selenium is versatile—it's used for website testing, scraping, and automating any web-based task you'd normally do manually.
In many cases, companies looking to scale automation projects choose to partner with teams specializing in nearshore software development. This approach allows businesses to access skilled Python and QA engineers in nearby regions, working in similar time zones to accelerate project delivery. Nearshore teams often handle large-scale Selenium-based automation, continuous integration pipelines, and testing frameworks, giving organizations flexibility and cost efficiency without the challenges of offshore coordination. Businesses can also hire software development contractors to extend their in-house teams, without long-term hiring commitments.
Prerequisites for Python browser automation
Browser automation using Python is straightforward. We only need Python installed with the respective web browser (Firefox, Safari, Chrome, etc.).
Installing Selenium
Selenium can be installed directly using pip as:
pip install selenium
Downloading WebDriver
Selenium requires a driver to interface with the browser, known as a WebDriver. WebDrivers are provided by all the major browsers, such as Chrome, Firefox, etc. The next step is to install the WebDriver. For example, we will install the Geckodriver for Firefox from the respective link.
This may sometimes cause some issues, so it must be installed carefully. Please place it in PATH (/usr/bin) or (/usr/local/bin) to avoid errors.
Once the installation has been completed, we can confirm the installation by opening a Python file or a JuPyter notebook and importing it as:
from selenium import webdriver
driver = webdriver.Firefox()
It will open the browser to confirm that Selenium and the respective WebDriver are installed successfully.
If you have been having trouble installing a particular browser’s driver for some time, I recommend switching to another driver to save time.
Basic Python browser automation operations
We have installed the prerequisites, so let's go ahead and perform some basic browser automation operations. Using Selenium, we can open a website and interact with it by entering the data and clicking the buttons. Since finding a website with all the desired functionalities is hard, I’ll go through this tutorial and try several websites. To begin with, we’ll use the Practice Test Automation website, which is quite simple. Let’s start by opening the URL.
Opening a browser window
Using the same driver object we defined earlier, we will call the get() method to open the respective URL in the (already opened) browser window.
driver.get("https://practicetestautomation.com/practice-test-login/")
Interacting with web elements
To interact with an element, we need to either know its name or find it (we will see it shortly). To find the name of an element, we can go to one and “inspect” it. For example, if we check the textbox under “Username” on the login page, the inspection feature highlights its ID (which is username).
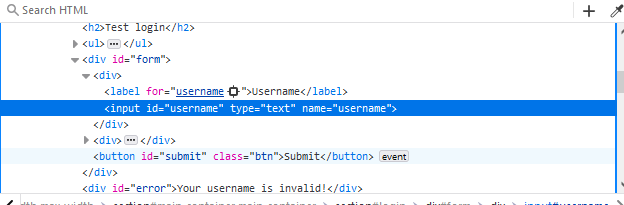
Using this ID, we can access this element as:
from selenium.webdriver.common.by import By
textboxUserName = driver.find_element(By.ID, 'username')
So, we have found the target element. Now, you can explore further by adding some data (in this case, a sample username and password are given on the page). We can use the send_keys() method for this purpose.
from selenium.webdriver.common.keys import Keys
textboxUserName.send_keys('student')
Similarly, for the password field.
textboxPassword = driver.find_element(By.ID, 'password')
textboxPassword.send_keys('Password123')
XPath
XPath stands for XML Path Language. Using it, we can provide the relative path of an element. In Selenium, we can use By.XPATH to refer to elements using XPath. While we have already identified the password field and inserted the password there, it would be nice to have an XPath example, too.
textboxPassword=driver.find_element(By.XPATH,"//input[@id='password']")
textboxPassword.clear();
textboxPassword.send_keys('Password123')
We're using textboxPassword.clear() to clear the password field before reentering it.
Button click
Having filled out the form, we can now submit it. To click a button, we can call the click() method.
buttonLogin = driver.find_element(By.ID, "submit")
buttonLogin.click()
As you can see in the screenshot below, the submission is successful.
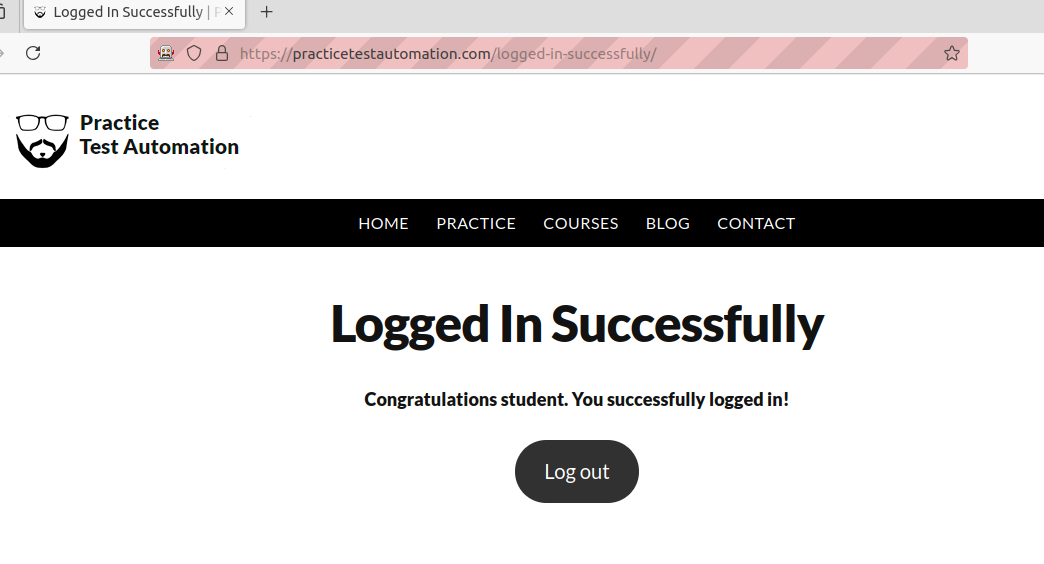
Now that we are done with the browser, we can close it with driver.quit().
Basics - complete example
import time
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.common.by import By
driver = webdriver.Firefox()
driver.get("https://practicetestautomation.com/practice-test-login/")
textboxUserName = driver.find_element(By.ID, 'username')
textboxUserName.send_keys('student')
textboxPassword=driver.find_element(By.XPATH,"//input[@id='password']")
textboxPassword.send_keys('Password123')
buttonLogin = driver.find_element(By.ID, "submit")
buttonLogin.click()
time.sleep(3); #Using this delay here so you can see the successful login
driver.quit()
Advanced browser automation operations
So far, we’ve just opened the website and signed in. It’s exciting, but Selenium’s role doesn’t (and shouldn’t) stop here. There’s plenty more to do, which can be performed using advanced operations.
Handling different browser windows and tabs
Often, while browsing through catalogs, it shows a number of pages (due to a huge number of quotes). In such cases, one would be curious to open the subsequent pages in other tabs (and switching across). For example, Quotes on Goodreads is a large database that shows multiple pages for a given author:
from selenium import webdriver
driver = webdriver.Firefox()
driver.get("https://www.goodreads.com/author/quotes/947.William_Shakespeare")
To open some of these links in the new tabs, we will use the JavaScript’s window.open() .
driver.execute_script("window.open('https://www.goodreads.com/author/quotes/947.William_Shakespeare?page=2');")
driver.execute_script("window.open('https://www.goodreads.com/author/quotes/947.William_Shakespeare?page=3');")
It will open two new tabs (pages 2 and 3).
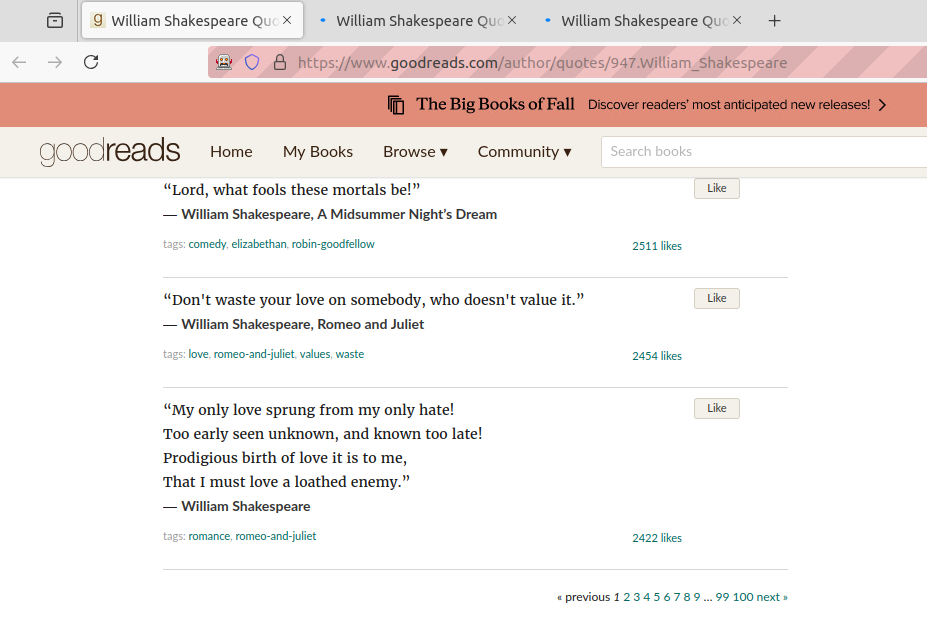
For switching to another tab, we can refer it using the driver.window_handles.
handles_list = driver.window_handles
handles_list
#Output
# ['11B97B2A09C579CF774A078690818A04',
# '349704D834980602DCEA4C067734E07B',
# '04BD8C4B136794C7355613E57185AB60',
# '82B0FF0BBD20A26513053065188E5B8F']
Since it is a list, we can access any tabs using the respective index. For example, handles_list[1] will refer to the second tab and so on.
💡 If you look carefully, you can see tabs are opened asynchronously, and we have the second page in the fourth tab, and so on. A better approach is to use waits—a topic we will cover shortly—after opening every tab, as it will ensure the order is maintained.
To switch to the respective tab, we will use switch_to.window().
driver.switch_to.window(handles_list[2])
driver.quit()
Complete example
import time
from selenium import webdriver
driver = webdriver.Firefox()
driver.get("https://www.goodreads.com/author/quotes/947.William_Shakespeare")
driver.execute_script("window.open('https://www.goodreads.com/author/quotes/947.William_Shakespeare?page=2');")
driver.execute_script("window.open('https://www.goodreads.com/author/quotes/947.William_Shakespeare?page=3');")
driver.execute_script("window.open('https://www.goodreads.com/author/quotes/947.William_Shakespeare?page=4');")
handles_list = driver.window_handles
driver.switch_to.window(handles_list[2])
driver.switch_to.window(handles_list[3])
driver.switch_to.window(handles_list[4])
time.sleep(3)
driver.quit()
Working with frames
Working with frames (also known as iframes) in Selenium requires you to switch the context of the WebDriver to the frame before interacting with elements inside it. To switch to a frame, you can use the switch_to.frame() method of the WebDriver.
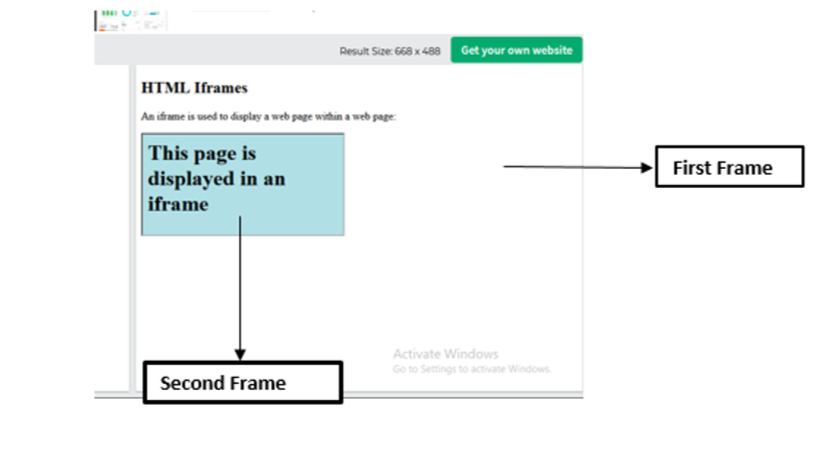
from selenium import webdriver
from selenium.webdriver.common.by import By
driver = webdriver.Firefox()
driver.get("https://www.w3schools.com/html/tryit.asp?filename=tryhtml_iframe")
driver.switch_to.frame('iframeResult')
input_text_frame=driver.find_element(By.XPATH,"//iframe")
driver.switch_to.frame(input_text_frame)
As you can see, we use switch_to.frame() as we used for the windows.
Handling pop-ups and alerts
Often, when logging into a website, we get a pop-up asking whether we accept or reject cookies. We can also handle these popups and alerts using Selenium.
For example, we open StackOverflow and get the cookies accept/decline popup.
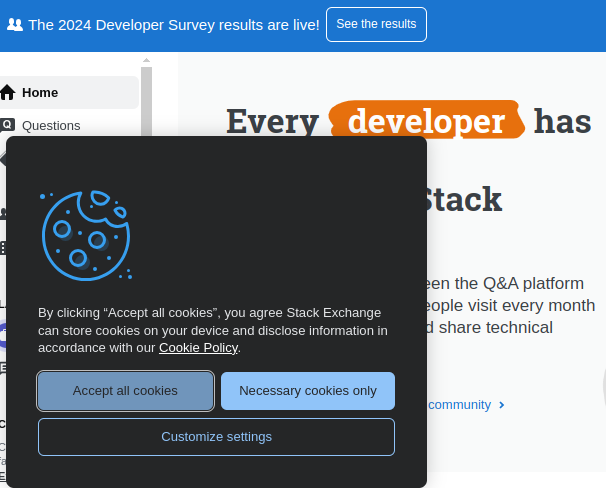
If we inspect it as usual, we can find the IDs for the respective buttons and use them to handle them. The highlighted button refers to “Accept all cookies.”

Depending upon our preference, we pick the respective button and click it.
cookie_reject_button = driver.find_element(By.ID, 'onetrust-reject-all-handler')
cookie_reject_button.click()
Similarly, we can handle the alert boxes too.
Alertboxes
For alertboxes, we can use switch_to.alert. It will get us the alert box object, that we can accept or decline. Here is a little CodePen to use with alertboxes.
from selenium import webdriver
driver = webdriver.Firefox()
driver.get("https://codepen.io/pervillalva/full/zYyYOPY")
alert = driver.switch_to.alert
alert.dismiss() #you can call accept() if you want to accept it.
Once we reject it, the alertbox is closed, and we come across something even more serious.
Kudos to my parents for not being named "Connor," so we are safe here.
Automating form submission
We have already seen (right at the start) how to use Selenium to automate form submission. Let's complement this with another little example, where you can also see how to select dropdowns.
Handling dropdown menus in Selenium can be done using the Select class from the selenium.webdriver.support.ui module. After finding the dropdown element, we will initialize the respective Select object.
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import Select
driver = webdriver.Firefox()
driver.get("https://layers.pk/")
drop_down_element=driver.find_element(By.XPATH,"//select[@id='wcmlim-change-lc-select']")
select_object = Select(drop_down_element)
We can select it using the text (select_by_visible_text) or by index.
select_object.select_by_visible_text('Lahore - Gulberg 4')
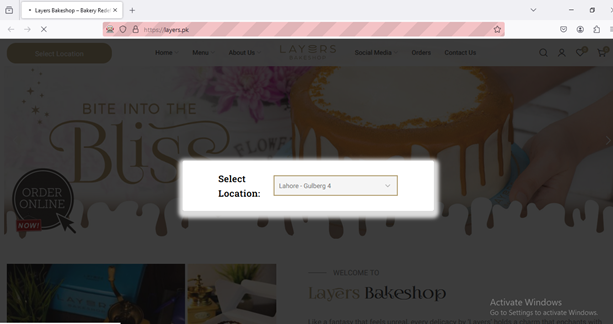
We can select them by index or by value, too.
select_object.select_by_value('4')
driver.quit()
Taking screenshots
Taking screenshots is another exciting feature of Selenium. And it's much simpler than it seems. All you have to do is to specify the desired path and call save_screenshot().
screenshot_path = '\\home\\ss001.png'
driver.save_screenshot(screenshot_path)
It will save the screenshot in the given folder (home, in this case) with the respective name.
Web scraping with Selenium
We've covered the basics of automating web browsing. Let's look at something more powerful: getting data from websites. This is called web scraping.
While automating web tasks is useful, collecting data from websites is often even more valuable. Selenium can do both.
Extracting data from web pages
Let's try a new example to show how web scraping works. We'll use Selenium to find job listings in Brisbane on LinkedIn.
from selenium import webdriver
from selenium.webdriver.common.by import By
driver = webdriver.Firefox()
url = "https://au.linkedin.com/jobs/jobs-in-brisbane-qld?position=1&pageNum=0"
driver.get(url)
To find the jobs or job elements on the page, we can inspect it, revealing that all the jobs are placed within a specific CSS selector (jobs-search__results-list under ul).
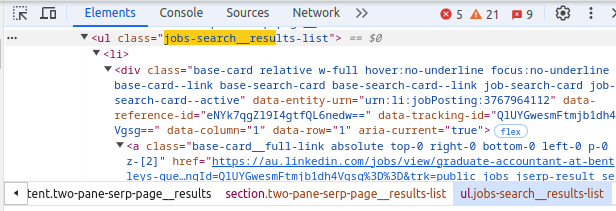
Using this information, we can find these elements:
job_elements = driver.find_elements(By.CSS_SELECTOR, 'ul.jobs-search__results-list li span.sr-only')
And we can loop over these job_elements to fetch the required details. For example, here I am fetching the job titles.
import pandas as pd
job_titles = [job.text for job in job_elements]
df = pd.DataFrame(job_titles)
print(df)
driver.quit()
💡 Here, I am using Pandas as a personal preference. Please feel free to use any alternative method if you would like to.
Saving extracted data
Now that we've seen how to extract data, let's save it. Pandas, a Python library, lets us save data in various formats like CSV, JSON, or XML. Here's how to save our job listings as a JSON file in the current folder:
df.to_json('BrisbaneJobs-Page1.json')
Now, it is saved and can be used later for further processing in different tasks, such as analyzing, training ML models, etc.
For more information on libraries for Python, check out our YouTube video:
Common issues in Python browser automation
Browser automation with Python (or any language) is a sea of knowledge. As a result, some issues are commonly faced, and I'd like to cover them.
Dealing with dynamic content
Many websites use JavaScript, and as a result, their elements may take some time to load. A common mistake is to ignore this and assume all the elements have already been loaded.
We can handle this by either implicit or explicit waits. In an implicit wait, we specify the number of seconds before proceeding further.
driver.implicitly_wait(5)
Often, we can't be sure about the loading time. Will it be 2 seconds or 10 seconds (or more)? Specifying smaller wait times may lead to missing elements, and more significant times can result in unnecessary wait times. Selenium provides us better control by explicit waits, where a loop keeps checking if the condition is met and exits once it is. Here, we can specify the time limit for the loop. For explicit wait, we will instantiate a WebDriverWait instance.
wait = WebDriverWait(driver, 5)
Having instantiated the instance, we will specify the “break” condition—i.e., the element we are searching for. For that, we need to import the expected_conditions first.
from selenium.webdriver.support import expected_conditions as EC
required_element = wait.until(EC.presence_of_element_located((By.ID, "expected_element")))
Best practices in Python browser automation
While performing browser automation, it would be good to keep a few things things in mind:
- Headless browsers - for faster automation, we can use headless mode. We can simply add
"--headless"in thewebdriver's options. - Session management - often some websites require logging in repeatedly. To avoid this inconvenience, we can even handle cookies for persistent sessions.
- Respecting website restrictions - some websites impose restrictions on the amount of requests they receive. They are often placed in
robots.txt. You can check out this post for detailed insights on web scraping's legality. - Parallel execution - Web automation is fast, but for large amounts of data, we need something faster. When I had to scrape many websites and online PDFs, it took hours. Multithreading can speed this up by running tasks in parallel. If you know how to use it, consider it for your project. But be careful - multithreading can cause issues like race conditions if you're not familiar with it.
Why is Python good for web automation?
Python is well-suited for web automation due to its simplicity and large user base. While Selenium supports multiple programming languages, Python's extensive community provides readily available support and resources for developers. This combination of ease of use and community backing makes Python a practical choice for web automation tasks.
Using Playwright instead of Selenium
Switching from Selenium to Playwright can make web automation faster and easier. Playwright is a newer tool that works with different browsers like Chrome, Firefox, and Safari. It’s also better at handling things that happen at the same time on a web page, so you don’t have to use tricky fixes like with Selenium. Check out our post on Playwright vs. Selenium to see which you prefer.




