



Part 1
The first part is a beginner-friendly introduction to datacenter proxies, You'll learn about:
- Datacenter proxies and why you should use them
- The difference between datacenter and residential proxies
- How to try datacenter proxies
- Various types of datacenter proxies
In Part 2 we will dive deeper into the topic and show practical tips and code examples for scraping with datacenter proxies, how to avoid blocking, and how to keep your proxies healthy.
What are datacenter proxies?
Datacenter proxies, which you can acquire through cloud service providers and hosting companies Bright Data, Oxylabs, and Apify, to name just three, are a fast and cheap way to mask your real IP address, so you can access a website anonymously and bypass web scraping protections. Your request to a website will go through a server in a big data centers, and the target website will see the datacenter’s IP address instead of yours.
Why use datacenter proxies?
Proxies, in general, not only obfuscate your online identity but also allow you to rotate your IP address to reduce the likelihood of your web scraping activities getting detected and enable you to send more requests to extract the data you need.
Proxies also let you bypass geolocation protections by using proxies in a specific country since companies enforce geolocation restrictions to block countries or regions to avoid traffic overload on their website.
But why use datacenter proxies specifically?
Datacenter proxies vs. residential proxies
Datacenter proxies run on servers operated in big data centers. This makes them easier to identify than residential proxies, which are installed on end-user devices like mobile phones, laptops, or televisions. Which type should you pick? It's quite easy, actually:
Datacenter proxies are faster, more stable and way cheaper than residential and other proxy types, so you should always use them first, and only ever use residential proxies when there's no other way - when datacenter proxies are heavily blocked by the website you want to scrape.
The best way to find out whether datacenter proxies are going to work for you is trial and error. Try scraping the website with datacenter proxies. If it works, you’ve just saved yourself a shedload of money.
Pro tip: You need to try datacenter proxies with more than 1 request to know if they’ll work for you. We recommend trying them with at least 50 requests per IP. We’ll show you how to keep your proxies healthy (meaning not blocked) in part 2.
Testing datacenter proxies
You can test scraping the target website using a datacenter proxy provider, such as Oxylabs and Bright Data, or using Apify Proxy. To do that, you will first need to create an account with one of the providers and then find a connection URL in their documentation.
For example, for Apify, the connection URL looks like below, and you can find your password here.
http://auto:p455w0rd@proxy.apify.com:8000
A proxy with a URL like this is usually called a super proxy. It's called a super proxy because it can automatically rotate IP addresses (notice auto in the URL), change location, and more. All of the above providers use super proxies. Some other providers might give you access in a different way, using proxy server IP addresses. They would look, for example, like this:
http://username:p455w0rd@59.82.191.190:8000
What's the difference? The latter usually gives you access to a single specific IP address. In our example: 59.82.191.190. No automatic rotation, no location changes. To make use of proxies like this, you need to get many of them and rotate them in your applications.
Below we show examples of using a proxy with common HTTP clients. We use an Apify Proxy URL as an example, but it will look pretty much the same for any other provider.
Shell:
curl "https://example.com" \
--proxy "http://auto:p455w0rd@proxy.apify.com:8000"
JavaScript:
import { gotScraping } from 'got-scraping';
const response = await gotScraping({
url: 'https://example.com',
proxyUrl: 'http://auto:p455w0rd@proxy.apify.com:8000',
});
Python:
import requests
proxy_servers = {
'http': 'http://proxy.apify.com:8000',
'https': 'http://proxy.apify.com:8000',
}
auth = ('auto', 'p455w0rd')
response = requests.get('https://example.com', proxies="proxy_servers, auth=auth)
With the examples and providers above, you can test whether you can scrape your target website using a datacenter proxy. If it doesn't work or works only for a few requests, don't worry. It's still possible to make it work. We explore the options in Part 2.
What are the types of datacenter proxies?
There are various ways you can split datacenter proxies into groups, but we find the following the most interesting:
By ownership - shared and dedicated proxies
Shared datacenter proxies are shared by all users of the proxy service. Shared proxies might already be blocked by the website you're looking to scrape, because another user may have already burned them on that website. Burning out proxies means they've overused them to the extent that they've been temporarily locked or even blacklisted for an extended period of time.
Their advantage? They’re significantly cheaper than dedicated proxies. They are a great choice for scraping local, or not very popular websites, because the chances of someone else burning them for you is lower there.
Dedicated datacenter proxies are available only to you, the developer, and you’re the one who manages them. This makes them more expensive, but no one else can burn them.
As for the longevity of dedicated datacenter proxies, this depends on doing your homework as a developer. If you use a few tricks for bypassing web scraping protections (request headers, correct cookies, browser fingerprints), your proxies will have a better reputation and will be able to handle more requests and last longer. We’ll show you useful techniques in Part 2.
By payment scheme - per GB, per IP, or a combination
Various paid proxy services are available depending on your needs. Per IP is a good option if you need a lot of bandwidth (when downloading videos, for example) but don’t care that much about the number of IPs, or if you want to build your own private pool of proxies that you can rotate and rely on.
Per GB is useful when your activity needs to appear as though it’s being carried out by lots of users without downloading too much data, such as e-commerce scraping. To further optimize costs, some providers, such as Bright Data, offer a combination of IP/GB payments.
By protocol - HTTP and SOCKS
Both HTTP and SOCKS protocols are efficient and equally anonymous. Your choice depends on personal preference or your own infrastructure.
HTTP and HTTPS are the most popular protocols. You can use a trick called HTTP CONNECT tunneling to send almost anything over HTTP, so they are the go-to solution for most people.
SOCKS and SOCKS5 are a special type of protocol used for proxies, but software libraries and tools might not support them, so do your research before buying proxies that support only SOCKS protocols. They are most often used in enterprise settings.
Part 2
In this section, you’ll learn how to:
- Fix common problems with datacenter proxies that cause blocking
- Change proxy country to overcome geolocation bans
- Use proxy sessions to keep your proxies healthy
- Use cookies and headers to improve your proxy success rates
- Create human-like proxy sessions that are hard to block
How to use datacenter proxies and avoid blocking
There are numerous ways how a website can block your proxy IPs. In this section we will explore all the common ones.
Blocking based on proxy location
The first thing you should do before buying hundreds of datacenter proxies is to test which country you need them to be in. Websites often block IPs by country, even if they don’t serve geolocation specific content, or they apply higher rate limits to foreign IPs. How can we overcome this problem?
Let’s take, as an example, a website that can only be accessed in the U.S.: https://www.napaonline.com. We're from Europe. What happens if we try to connect to it by curling it?
curl "https://www.napaonline.com"
We get this:
error code: 1009
Upon closer inspection we see that it's an error from Cloudflare, a well known bot protection provider. It says that we can't access the website from our country.
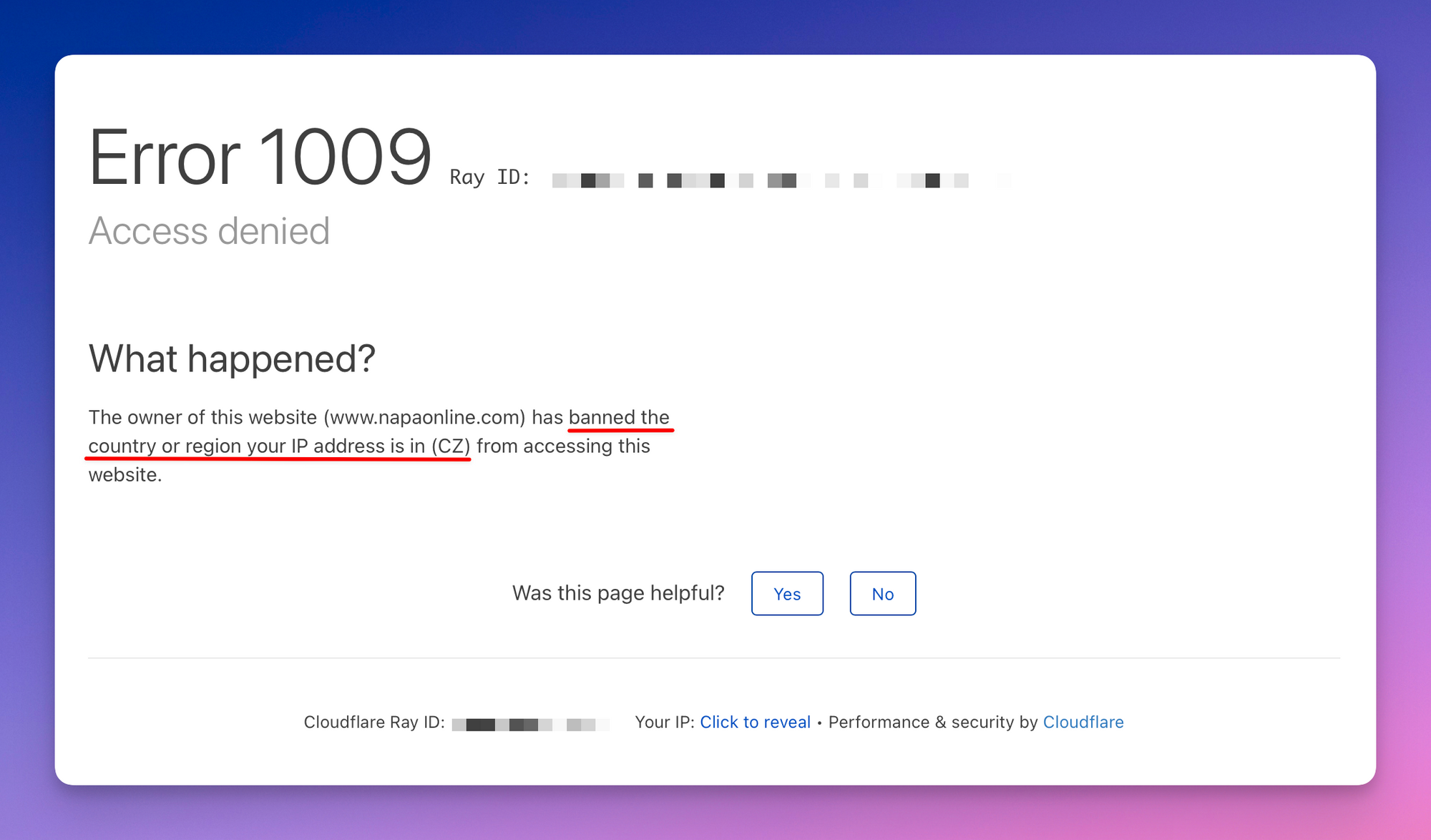
Since we can’t access the website from our location, we need to use a proxy server, so it looks like we’re accessing it from another location or IP address. It's a US website, so a safe bet is trying it with a US proxy.
The example shows how to do it with Apify Proxy, but the structure is almost exactly the same for all providers. To set the country to the United States, we need to use a proxy URL like this:
http://country-US:p455w0rd@proxy.apify.com:8000
Note the country-US in the URL. It tells the proxy to use only US IP addresses. Most proxy providers use very similar parameters in their proxy URLs. Now when we curl the website, we will successfully bypass the country check.
curl "https://www.napaonline.com" \
--proxy "http://country-US:p455w0rd@proxy.apify.com:8000"
If you try it yourself you'll see that you'll manage to bypass the country check, only to get flagged for yet another check - a fingerprint check. We will talk about fingerprints later in this guide.
Blocking based on proxy ASNs
Some companies block entire IP ranges of datacenter proxies by blocking ASNs (autonomous system numbers). Every device that connects to the internet is connected to a so-called autonomous system, and every autonomous system controls a set of IP addresses. ASNs are 16- or 32-bit numbers prefixed by AS, and you can check an ASN for IP prefixes, look up an IP address, and search all ASNs belonging to a network here.
Did you know? More and more people are sharing their public IP addresses since more users are connecting to the same exit nodes on the internet provider level. It’s common for a whole block of buildings to have the same IP address.
You might have issues with ASNs and IP ranges before you even start scraping because they’re known to the blocking mechanism even before you begin. For example, AWS IP ranges can be found here.
How does this look in the real-world? Let's take the website https://www.crunchyroll.com as an example. They use Cloudflare to prevent access to the website from known proxy ASNs. We tried curling it using a proxy from a known proxy pool and this is what we received:
error code: 1005
When we used the same proxy in a browser, Cloudflare greeted us with a new type of ban screen.
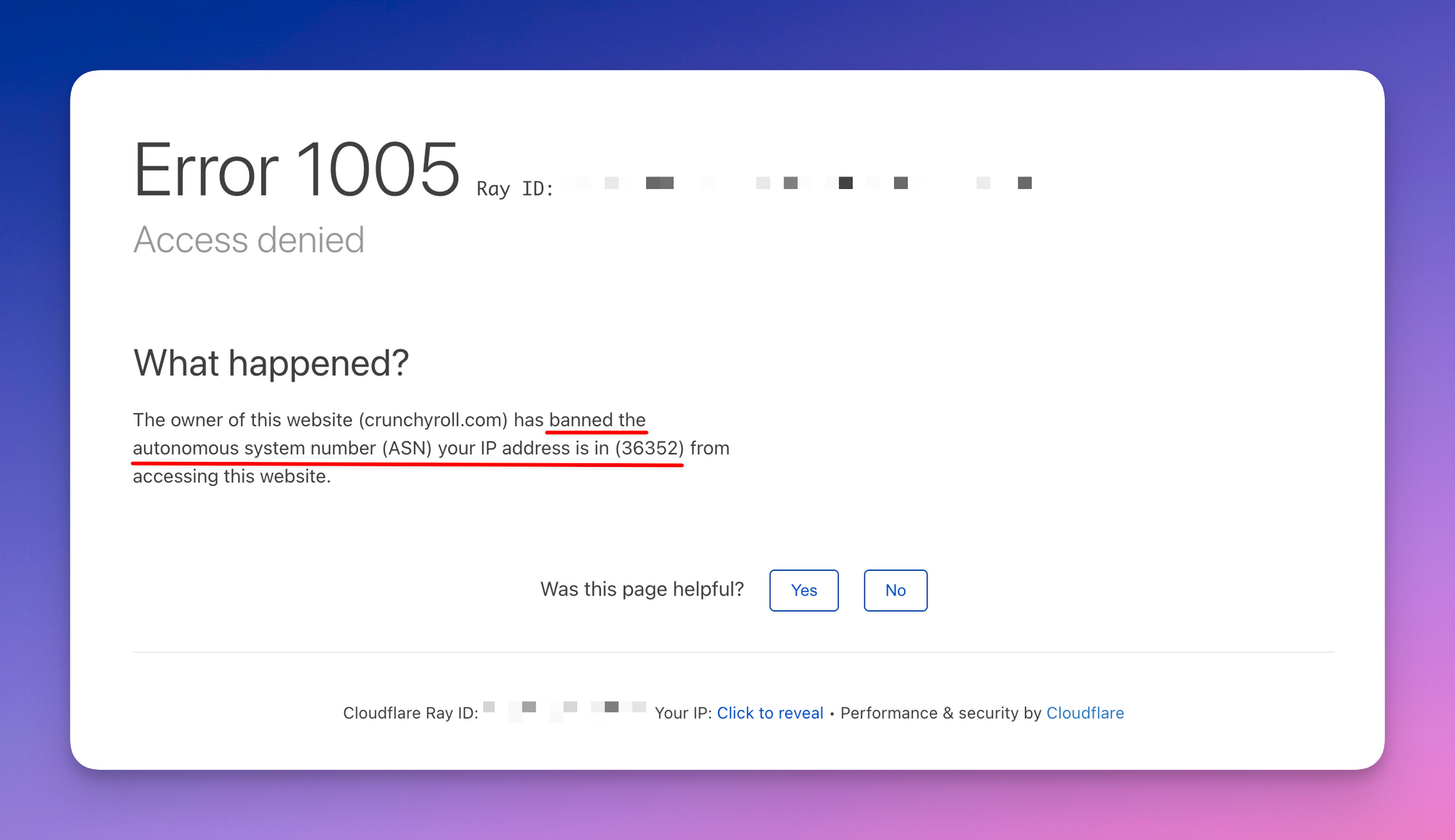
What can you do when you encounter a ban like this? The best option is to use other datacenter proxies which are not in the same ASN range. This might require trying proxies from a different provider or requesting a new set of dedicated IPs.
If you're using shared proxies, you can try to rotate through many of them and see if some are working. Shared proxy pools are usually large, so it's definitely worth trying out more than one IP. For this reason, Apify Proxy combines proxies from multiple providers, so that we have access to many different IP ranges.
Blocking based on HTTP request signature
Denying access based on your IP address is probably the most common way of blocking, but it's not the only tool in the anti-scraping arsenal of websites. A very common way of blocking uses the HTTP headers of your request to determine if you're a bot. Not even the best proxy in the world can help you if your requests fail this check.
Consider curling https://amazon.com (we use-L to follow redirects):
curl "https://amazon.com" -L
No matter what IP address we use, we'll get a response that includes this text:
Sorry! Something went wrong on our end. Please go back and try again or go to Amazon's home page.
Amazon recognized us as a bot, because we have not sent human-like headers with our request.
It's fairly simple to convince Amazon that we're human. We only needed to add a proper user agent:
curl "https://amazon.com" -L \
--user-agent "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/109.0.0.0 Safari/537.36"
But on many websites, it's not that easy, and you need to add far more headers, use HTTP2 (or even HTTP3) and a proper TLS fingerprint with your HTTP client before the website allows access.
If you're working with Node.js, consider using Got Scraping. It's an open-source HTTP client that automatically adds human-like headers to your requests, supports HTTP2 and uses browser-like TLS.
Blocking based on blacklists
Even if you get your country correct, the website does not block your proxy ASN, and you use a human-like request signature, your proxy may still fail you. Either because its IP address was burned by another user (if you're using shared proxies), or because it's known to services like Cloudflare as a proxy IP address. In cases like this, you usually receive a 403 error or 500 HTTP status code, or no status code at all, because the proxy fails to establish a connection.
If this happens, the only solution is to wait some time (usually hours or days) or get a new proxy. The goal is to not let this happen to your proxies. We'll explore options how to keep proxies healthy later.
Blocking based on rate limits
The final common type of IP blocks is a rate limit. The website simply limits the number of requests it will serve from a single IP address. This could be 50 a minute or 200 an hour. Usually there's no way to predict a rate limit without actually hitting it. You can typically tell that you've hit a rate limit on a website because you've received a 429 HTTP status code. The good thing about rate limits is that they usually don't lead to long-lasting bans. They're also quite easily bypassed simply by using more IP addresses.
If a website's rate limit is 200 requests an hour, you can rotate 100 IPs to scrape 20,000 pages an hour. This is where a shared pool of proxies really shines, because you can get access to hundreds of IPs without having to pre-purchase them.
How to optimize performance of datacenter proxies
We've worked through the most common methods websites use to ban our proxies. But that does not mean that our work is over. The fact that we can scrape one or ten pages using a proxy does not mean that we will be able to scrape thousands. To keep our proxy pool healthy, we need to take care of it properly.
Let's recap what we learned earlier:
- First, you need to make sure that your proxies are from the right geolocation.
- Second, you need to check the whole range isn't banned. If it is, you have to find a different provider.
- Third, you need to provide correct HTTP headers to not look like a bot.
Once your proxies pass those tests, you're good to go. But you still don't want to get them blacklisted or hit rate limits. This is how you do it.
Crafting human-like proxy traffic
Imagine how a typical user browses the web. They use a web browser and a single IP address from which they connect. This IP address could be their own, or it could be shared by the whole building or a block of buildings. Finally, the web browser sends a specific set of HTTP headers and uses a known TLS signature.
For optimal performance of your proxies, you need to make their traffic look like human traffic. You don't need to get it perfectly right all the time, but the closer you get, the longer your proxies will last and the more money you'll save.
Human users use browsers and cookies
The vast majority of modern websites send cookies in their HTTP responses. Cookie is a special type of HTTP header that allows a website to save some data to your computer, so that when you next arrive, you can have a personalized experience. Cookies keep items in your shopping basket or keep you logged in.
Why is this important for web scraping? Because the websites usually send you some token, ID or identifier and then create a temporary profile of your connection on their server. Its naive version could look something like this:
{
"userId": "user12345",
"ipAddress": "134.135.50.40",
"userAgent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/109.0.0.0 Safari/537.36"
}
Your browser will automatically save the ID it received in the cookie and make all subsequent requests to the same website using that ID: user12345. This allows the website to track you.
Now, imagine we rotate a proxy and the website then receives the same user ID, but from a different IP address. Once or twice the website might let it slide, because people's IP addresses sometimes change. But they hardly change multiple times in a row. This either means the user has been teleporting around the world real fast, or, you guessed it, they're a bot.
Because most people connect to the internet through shared public IP addresses, you can send several cookies (IDs) from a single IP address. You should never send a single cookie (ID) from multiple IP addresses, though, because that does not happen in reality.
For optimal proxy performance, we need to create proxy IP + cookie + header combinations and use them together consistently. To be able to do that, we need to leverage proxy sessions.
Use proxy sessions and smart IP rotation
Most proxy providers have a feature called proxy sessions. Sessions allow you to lock a certain IP, so it doesn't rotate. That gives you granular control over your session and IP rotation. You can use sessions to:
- precisely control IP rotation; you should spread the load evenly over them
- remove IPs that hit a rate limit from rotation, letting them cool down
- stop using IPs that were accidentally blacklisted (403, 500, network errors) to prevent damaging their reputation further
- combine IPs, headers and cookies into human-like sessions that are much less likely to get blocked
A proxy URL with a session usually looks like this:
http://session-my_session_id_123:p455w0rd@proxy.apify.com:8000
If you're not using a super proxy, but a list of individual IP addresses, then you should treat each IP address as a separate session.
Whenever you make a request to the proxy with the same session ID (my_session_123) it will go through the same IP address. This way, you can pair an IP address with human-like cookies and other headers and create a list of users that you can rotate through. Remember, we will be rotating users, not IPs.
Consider this naive example in JavaScript. First, we need to create many users with browser-like headers. For simplicity, we're showing just the user-agent header.
const user1 = {
sessionId: 'user1',
headers: {
"user-agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/107.0.0.0 Safari/537.36",
},
cookieJar: new CookieJar(),
}
const user2 = {
sessionId: 'user2',
headers: {
"user-agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10.15; rv:107.0) Gecko/20100101 Firefox/107.0",
},
cookieJar: new CookieJar(),
}
// const user3 = ...
Then, we scrape the target website using those users, assigning them IP addresses using proxy sessions and storing their cookies in separate cookie jars. Here we're showing how it could look using the popular Got HTTP client.
const response = await got('https://example.com', {
headers: user.headers,
cookieJar: user.cookieJar,
agent: {
http: new HttpProxyAgent({
proxy: `http://session-${user.sessionId}:p455w0rd@proxy.apify.com:8000`
})
}
})
This approach will ensure that our proxy session + cookie + header combos will be consistent and our traffic blends in with normal human traffic.
See how emulation of human users impacts performance on websites like Alibaba, Google or Amazon in this article on shared IP address emulation. Spoiler, a lot.
How to manage proxy sessions easily in Node.js
Using the above approach will produce far better results, proxy longevity and health than using plain random or round-robin rotation, but the implementation itself is not easy. Luckily, there are a few open-source libraries that can remove a lot of the heavy lifting.
Got-Scraping
The first is Got-Scraping, an extension of the above-mentioned Got that's purposefully built for web-scraping. It automatically generates headers based on real browsers and lets you pair them with proxy sessions easily. Got-Scraping has all the features of Got, so it is a good choice if you're looking for a Node.js HTTP client for your scraping application.
const session = { /* ... */ };
const response = await gotScraping({
url: 'https://example.com',
headerGeneratorOptions:{
devices: ['desktop'],
locales: ['en-US'],
operatingSystems: ['windows'],
},
proxyUrl: `http://session-${session.id}:p455w0rd@proxy.apify.com:8000`,
sessionToken: session,
});
Crawlee
A more complete and full-featured open-source library that handles proxy session management is Crawlee. It can scrape using both HTTP requests and headless browsers and automatically handles proxy sessions, headers and cookies using its SessionPool class.
The best thing about Crawlee in this sense is that it has reasonable defaults, limits the maximum number of uses of each session, and automatically discards sessions based on common blocking errors like 403 or 429. In most cases, it "just works".
import { CheerioCrawler, Dataset, ProxyConfiguration } from 'crawlee';
const proxyConfiguration = new ProxyConfiguration({
proxyUrls: ['...'],
});
const crawler = new CheerioCrawler({
proxyConfiguration,
sessionPoolOptions: {
// Indicates that we want to rotate
// through 100 human-like sessions.
maxPoolSize: 100,
},
async requestHandler({ request, $, enqueueLinks, log }) {
const title = $('title').text();
log.info(`Title of ${request.loadedUrl} is '${title}'`);
await Dataset.pushData({ title, url: request.loadedUrl });
await enqueueLinks();
},
});
// Add first URL to the queue and start the crawl.
await crawler.run(['https://crawlee.dev']);
Crawlee also works with Puppeteer and Playwright and automatically manages not only request headers, but full browser fingerprints. This helps avoid blocking on a completely different level. You can find more information about proxy management in Crawlee in the proxy management guide.
Which datacenter proxy should you choose?
Before throwing a lot of money down the drain for residential proxies, try the above tips to get the most out of your datacenter proxy pool. You might find that datacenter proxies are all you need.
You can pick any proxy provider that you like, but don't forget to test the proxies before fully committing. One feature you should absolutely require are proxy sessions. Without them, you cannot manage the pool optimally, and you'll end up paying more for proxies and other infrastructure than needed.
Apify Proxy is a super proxy and a great alternative to other datacenter proxies. It automatically rotates IP addresses, but it also lets you lock an IP in a session or change proxy countries easily when web scraping. All those features reduce your chances of getting blocked.
But frankly, all the good proxy providers can do that. The biggest benefit of Apify Proxy is its integration with the Apify platform, a cloud platform for building, running and monitoring web scrapers and browser automation tools.
Apify provides all the scraping infrastructure under one roof including proxies, serverless containers, storage, distributed queues, scraper monitoring, integrations, and it seamlessly works with Scrapy, Crawlee, Puppeteer, Playwright and any other open-source library.
You can learn more about web scraping and browser automation in the Apify documentation and Apify Academy. Happy scraping!



