You don't need to be a web scraping master if you know how to get ChatGPT to help you out. This guide will teach you how to use it as a web scraping assistant and save a ton of time coding.
Can ChatGPT scrape websites?
No, ChatGPT can't do web scraping directly. But it can provide guidance, code examples, and explanations on how to use frameworks and libraries for scraping tasks. For actual web scraping, you would need to use a programming environment that can execute code and interact with websites.
That's precisely what this tutorial will demonstrate, only we'll be using ChatGPT to help us.
We'll scrape X (formerly known as Twitter), which is a JavaScript-rendered website. That means content is not present in the HTML source code but is loaded or generated after the initial page load. So, not the easiest of sites to scrape. We'll demonstrate how ChatGPT makes it a lot easier.

To follow this, you don't even need to know a programming language. But you will need:
- Any code editor (I'll be using a Jupyter Notebook inside VSCode).
- Python downloaded and installed on your system.
- A ChatGPT account (free or paid).
ChatGPT web scraping tutorial
We're going to scrape X posts (you probably still call them tweets) from the Apify X account: https://x.com/apify. As X is a dynamic website, we'll need a tool that can execute JavaScript and interact with web pages.
1. Take care of prerequisites
One of the best frameworks for scraping dynamic websites like X is Playwright for Python, so that's the tool we'll use here. Install it using pip:
pip install Playwright2. Inspect the website and identify the right tags
Web scraping involves identifying the appropriate tags when you inspect the web page. So, right-click and choose 'Inspect' and let's do some tag-hunting for Apify tweets:
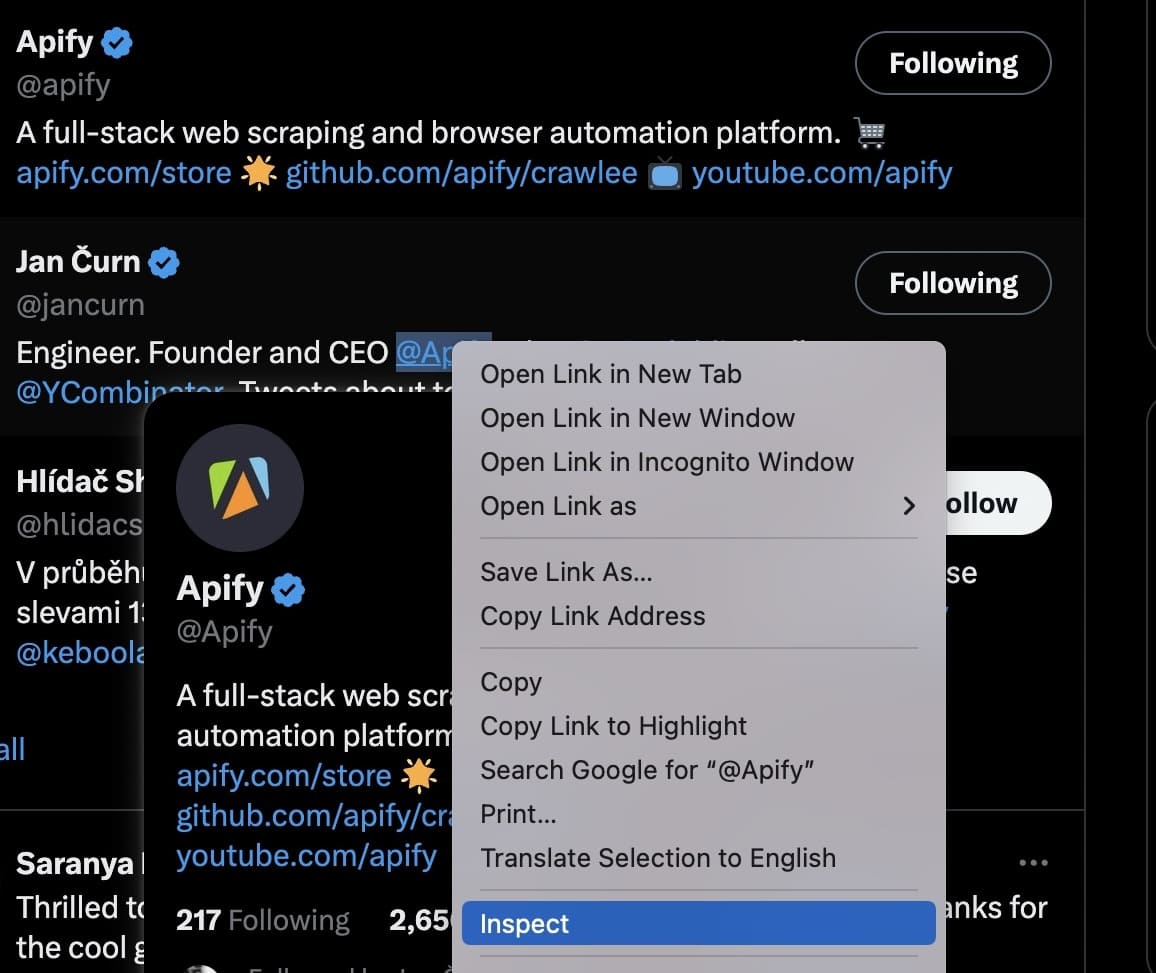
Right-click on a post to inspect the elements you need to scrape:
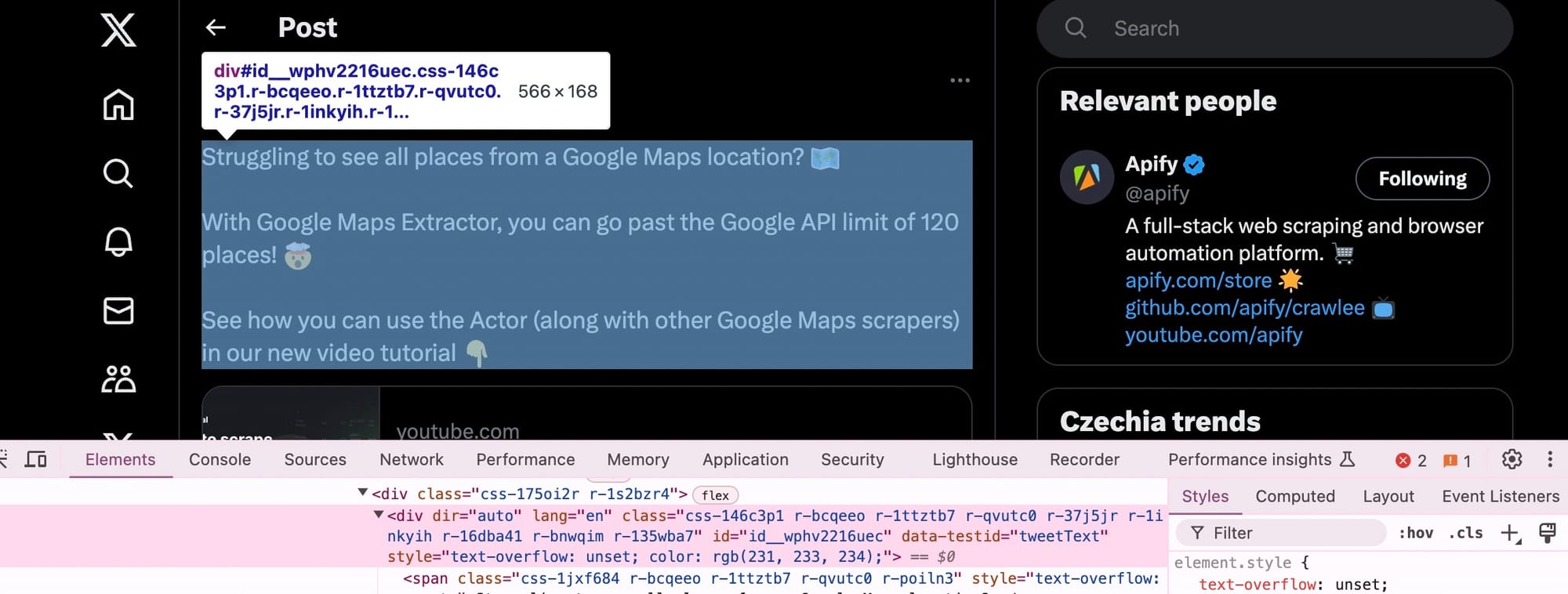
The div element contains the lang attribute, which is often used on tweet text to denote the language of the tweet.
We'll choose this so the web scraping script focuses on tweets rather than other types of content on the page.
3. Craft a prompt for ChatGPT
Now you know the URL, tool, and tags you want, it's time to prompt your AI web scraping assistant.
For this particular case, here's the prompt we'll give ChatGPT:
#Maximize the window, wait 10 seconds, and locate all the elements with the following XPath: "div" tag, attribute name "lang".
#Print the text inside these elements.
#Scroll down until it has scraped and printed at least 20 different tweets.
Prompt explanation:
- Maximizing the window: This helps to load more content initially and reduces the need for excessive scrolling. It also helps ensure that responsive websites display their content in the desktop view, which often includes more information than mobile views.
- Waiting 10 seconds: Waiting allows the webpage to load fully to make sure all elements, including dynamically loaded content like tweets, are completely rendered before the script tries to interact with them. This helps avoid issues where the script might try to access elements that aren't yet available.
- XPath: The XPath expression
//div[@lang]targets alldivelements that have alangattribute so we can extract relevant content (tweets) only.
After telling us to set up Playwright and follow the same steps we gave it, ChatGPT provided us with this code:
import asyncio
from playwright.async_api import async_playwright
async def scrape_x_com_apify():
async with async_playwright() as p:
browser = await p.chromium.launch(headless=False)
context = await browser.new_context()
page = await context.new_page()
# Maximize the window
await page.set_viewport_size({"width": 1920, "height": 1080})
# Navigate to the URL
await page.goto('https://x.com/apify')
# Wait for the page to load
await page.wait_for_timeout(10000)
tweet_texts = set()
while len(tweet_texts) < 20:
# Locate all elements with the given XPath
tweet_elements = await page.query_selector_all('//div[@lang]')
# Extract and print text from each element
for element in tweet_elements:
text = await element.inner_text()
tweet_texts.add(text)
print(text)
if len(tweet_texts) >= 20:
break
if len(tweet_texts) < 20:
# Scroll down to load more tweets
await page.evaluate('window.scrollBy(0, window.innerHeight)')
await page.wait_for_timeout(2000)
await browser.close()
# Run the function
asyncio.run(scrape_x_com_apify())
4. Review the code
Once ChatGPT responds with code, it’s always a good idea to review it first. Just check that it does what it's supposed to do. Make sure it uses the libraries or packages you want to include. If you find any glitches, provide feedback to ChatGPT and ask it to generate the code again.
5. Run and debug the code
Copy-paste the GPT-generated script in your code editor of choice. Here it is in Jupyter Notebook on VSCode:
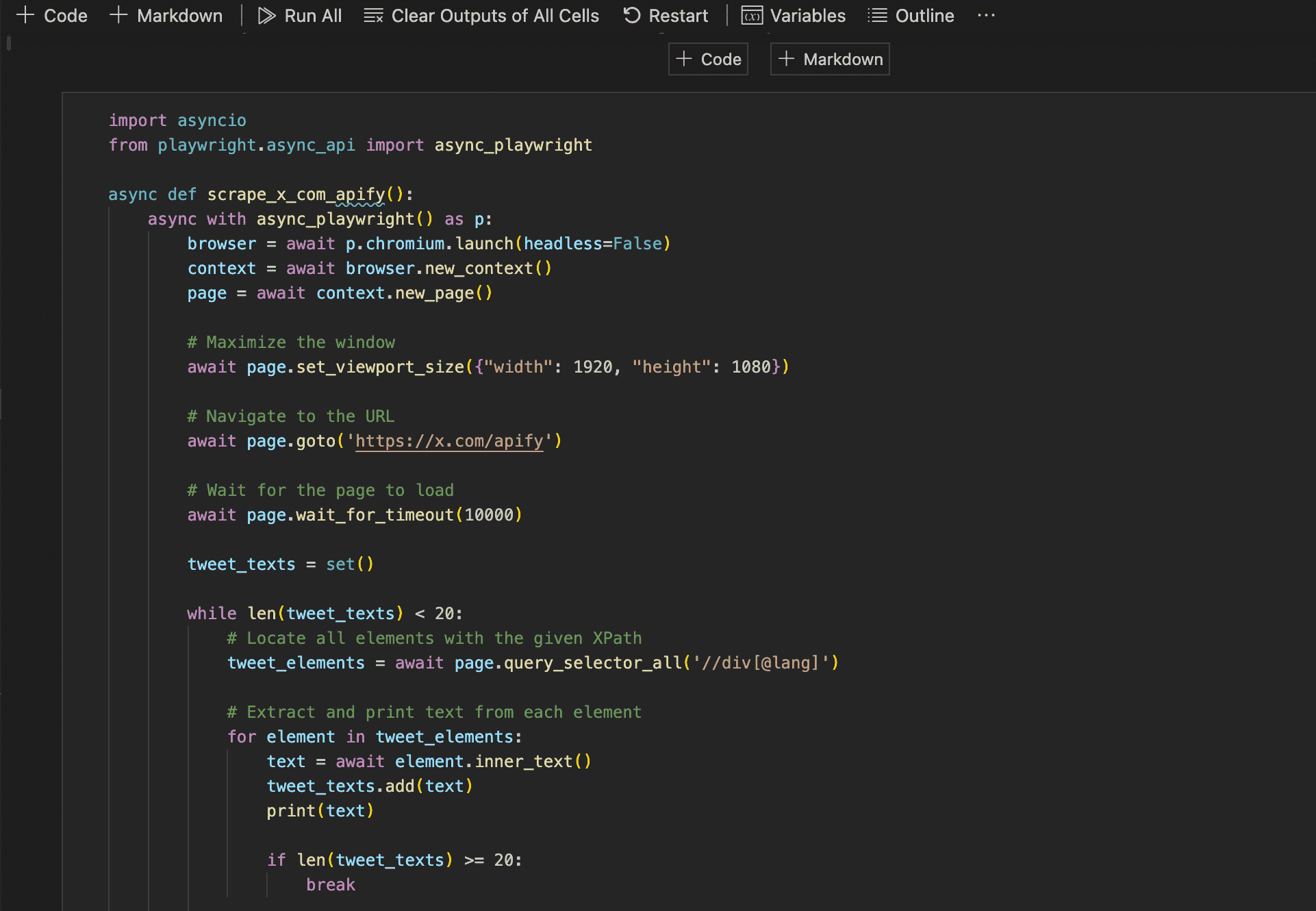
It started well: it opened a Chrome browser and navigated to the Apify Twitter page:
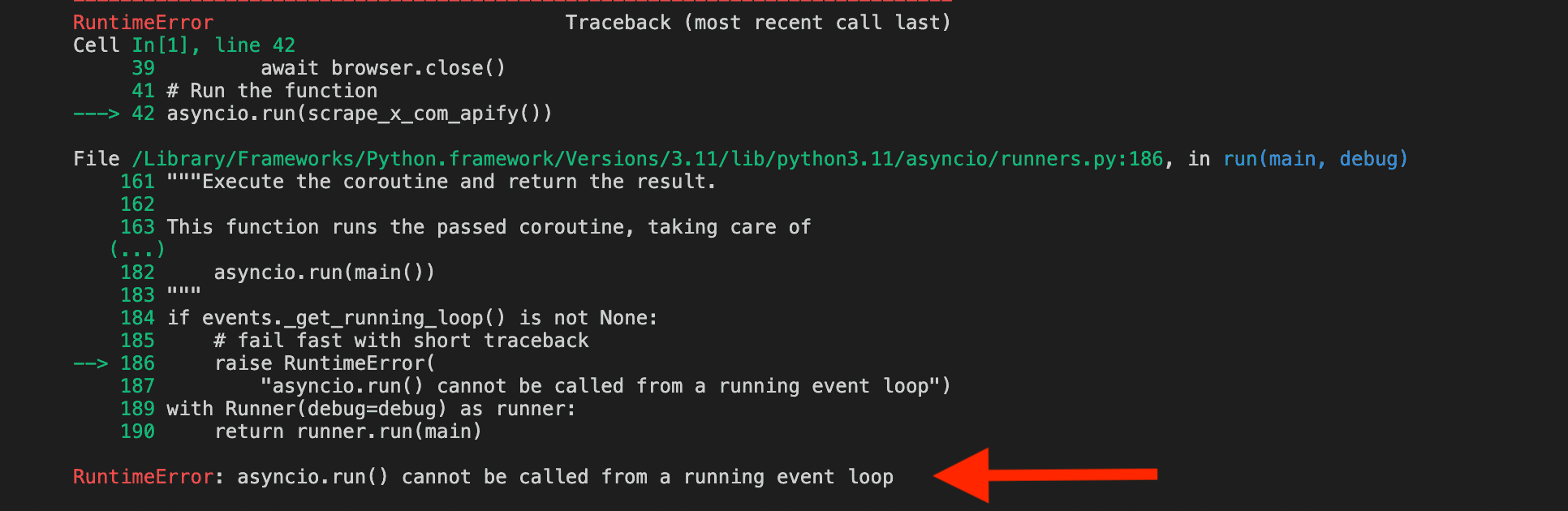
However, it failed to print the data. Instead, we got this runtime error:
This brings us to debugging.
ChatGPT is pretty good at rectifying code errors. The best thing is you don't even need to spend time typing. Just taking a screenshot and uploading it usually does the trick.
So, we took a screenshot of the error and uploaded it into ChatGPT.
It recognized the problem and responded with a solution:
The error message indicates that asyncio.run() cannot be called from a running event loop. This typically occurs when running asynchronous code in environments like Jupyter notebooks or certain IDEs. To resolve this, you can use a different approach to run your asyncio code within these environments. Instead of using asyncio.run(), use the event loop directly.
It gave us some adapted code to run. So, let's try again:
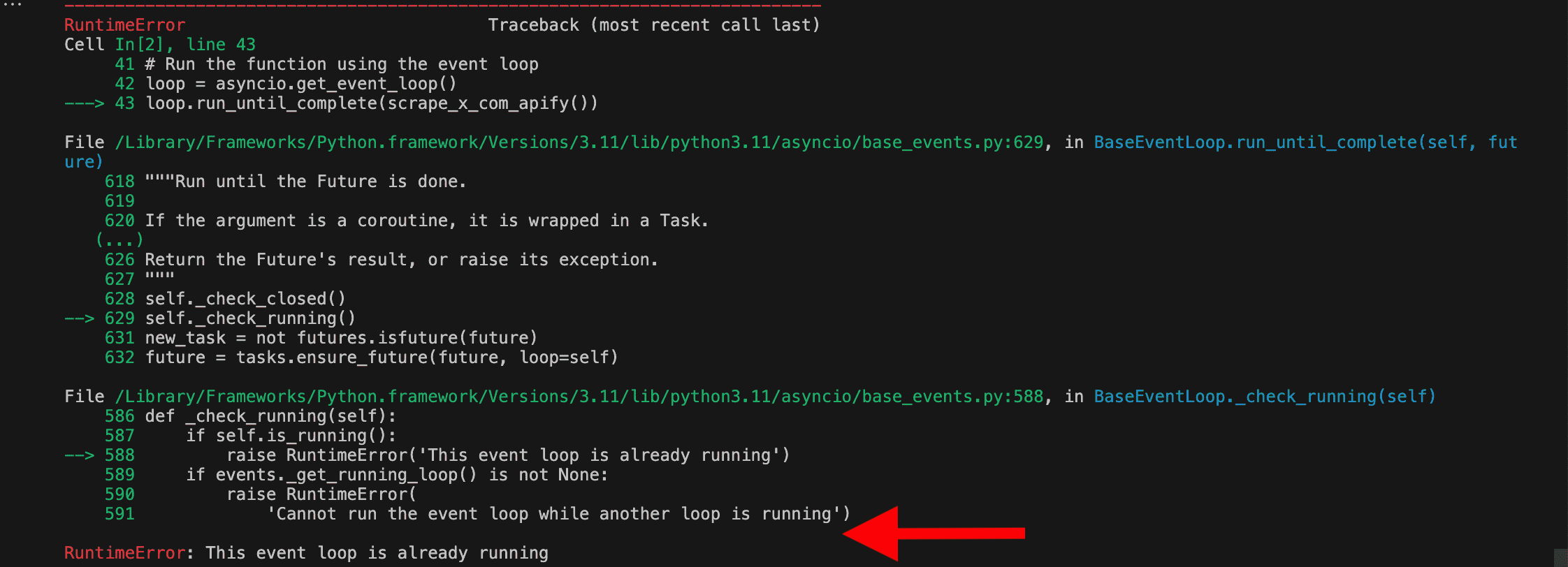
Another error. We showed ChatGPT the screenshot and got this response:
To avoid the error that occurs because the event loop is already running, we can use an alternative approach by creating a new event loop or using nest_asyncio to allow nested use of asyncio.run. The nest_asyncio library can patch the running event loop to allow it to be re-entered. First, install nest_asyncio using pip if you haven't already:
pip install nest_asyncioThen modify the script as follows:
import asyncio
import nest_asyncio
from playwright.async_api import async_playwright
nest_asyncio.apply()
async def scrape_x_com_apify():
async with async_playwright() as p:
browser = await p.chromium.launch(headless=False)
context = await browser.new_context()
page = await context.new_page()
# Maximize the window
await page.set_viewport_size({"width": 1920, "height": 1080})
# Navigate to the URL
await page.goto('https://x.com/apify')
# Wait for the page to load
await page.wait_for_timeout(10000)
tweet_texts = set()
while len(tweet_texts) < 20:
# Locate all elements with the given XPath
tweet_elements = await page.query_selector_all('//div[@lang]')
# Extract and print text from each element
for element in tweet_elements:
text = await element.inner_text()
tweet_texts.add(text)
print(text)
if len(tweet_texts) >= 20:
break
if len(tweet_texts) < 20:
# Scroll down to load more tweets
await page.evaluate('window.scrollBy(0, window.innerHeight)')
await page.wait_for_timeout(2000)
await browser.close()
# Run the function using the event loop
asyncio.run(scrape_x_com_apify())
When we ran the modified script, it proceeded to open the Chrome browser and navigate to the web page...

Playwright opening the Chrome browser and navigating to the X website
And success! It printed the data in the terminal:

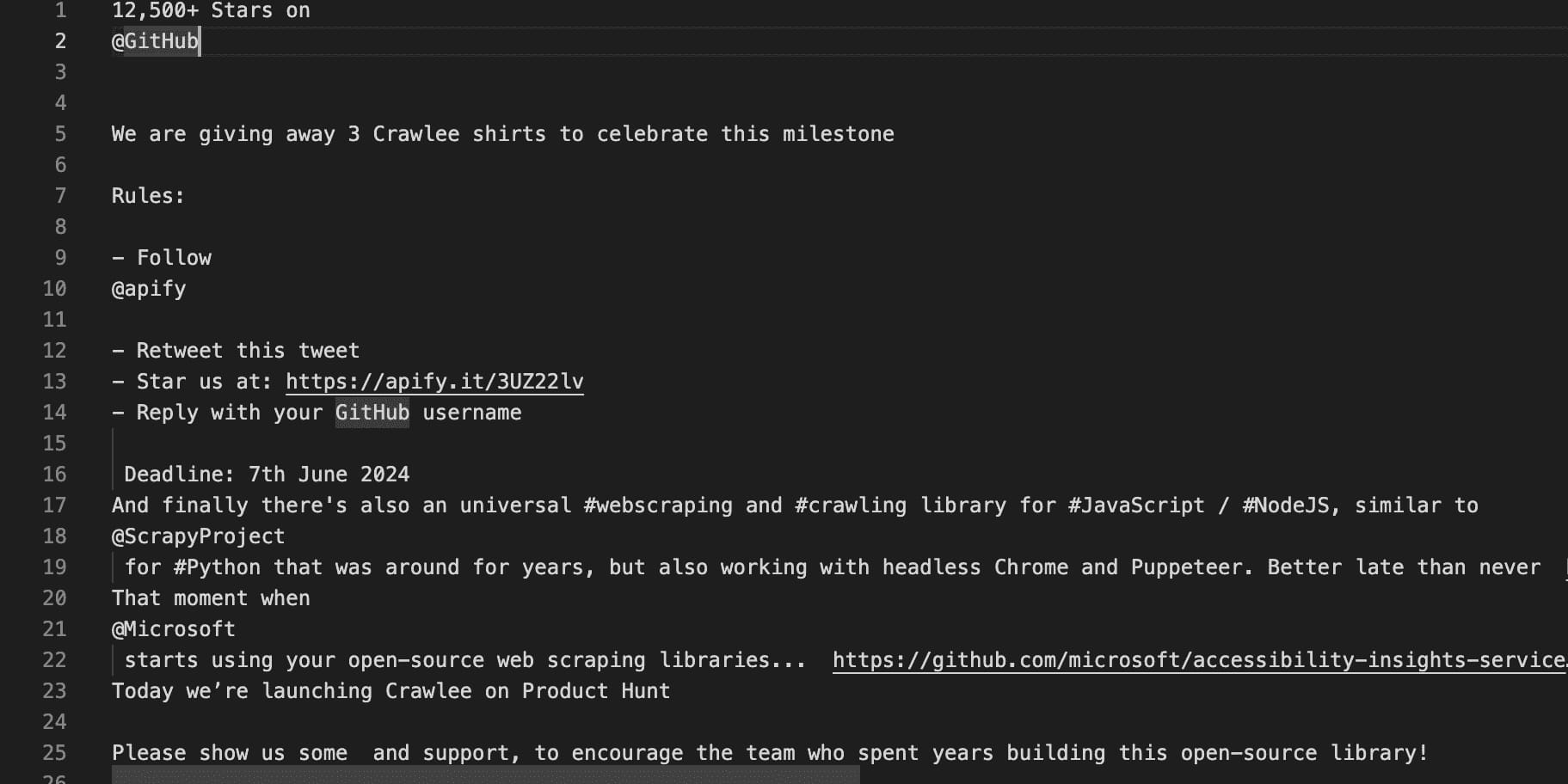
Data printed to the console
How to not get blocked when scraping with ChatGPT
We've shown you how to perform a simple web scraping task with ChatGPT, but code isn't enough for any serious, large-scale scraping project.
Extracting data from modern websites poses challenges beyond dynamic content: CAPTCHAs, IP blocks and bans, browser fingerprints, and more.
To prevent your scraper from getting blocked, you need infrastructure that provides you with things like smart proxy management and browser fingerprint generation.
The best solution? Deploy your code to a cloud platform like Apify.
The Apify platform was built to serve large-scale and high-performance web scraping and automation needs. It provides easy access to compute instances, storage, proxies, scheduling, webhooks, integrations, and more.
Tips for scraping with ChatGPT
- Use DevTools to inspect the target website.
- Pick a programming language and determine the right tools for the scraping task.
- Be as specific as possible and always describe the schema (div tags, attribute names, etc.).
- Always run the code yourself.
- Upload screenshots to ChatGPT to help you fix errors.
Conclusion
Although ChatGPT can't do web scraping directly, we've demonstrated how you can use it to help you scrape web content, even from dynamically loaded pages. By using Playwright in Python with ChatGPT, we successfully extracted tweets from X.com. This goes to show that you don't need to be a web scraping master or AI engineer to do ChatGPT web scraping.
Frequently asked questions
Can ChatGPT read websites?
ChatGPT can access and read some websites through its browsing mode. However, when browsing, it's not clear whether it's running searches on the Bing index or actually visiting pages. Regardless, there are some websites ChatGPT can't read, such as paywalled content, dynamic content, and private sites.
Can ChatGPT do web scraping?
No. ChatGPT can't do web scraping directly. But it can provide guidance, code examples, and explanations on how to use frameworks and libraries for scraping tasks. For actual web scraping, you would need to use a programming environment that can execute code and interact with websites.
How do I get ChatGPT to scrape websites?
ChatGPT is a language model designed to process and generate text based on the input it receives. It doesn't have the capability to interact with external websites or execute code. However, GPT Scraper and Extended GPT Scraper are two Apify tools you can use to extract content from a website and then pass that content to the OpenAI API.
![Top 100+ AI influencers to follow on Instagram [2026]](https://storage.ghost.io/c/f2/6e/f26ec999-9a90-4aee-a0d4-9b3ca2bb668f/content/images/size/w1200/2026/04/5-ways-web-scraping-can-improve-your-business-2.png)