Why I built this
I was already tracking remote jobs from We Work Remotely for a personal project, but WWR covers only a slice of the remote job market. Working Nomads lists a different set of roles, often with more detailed company information including employee benefits, social links, and hiring regions. I wanted all of that in one clean dataset.
Building the crawlpilot/working-nomads-scraper turned out to be a very different challenge compared to the WWR Actor. Working Nomads loads its job listings through an internal Elasticsearch API, not plain HTML. This meant I could not just parse the page with Cheerio. I had to intercept the network request, read the payload, and replay it for pagination.
This article explains exactly how I did that, what broke along the way, and how the company enrichment layer works on top of the job data.
Prerequisites
To follow along, you will need:
- An Apify account (free tier is enough for testing)
- Node.js v18 or higher
- Playwright installed via npm install playwright
- Crawlee and the Apify SDK
- Basic understanding of browser DevTools and network tab
- Familiarity with how Elasticsearch responses are structured
Understanding how Working Nomads loads job data
Before writing any code, I opened Working Nomads in Chrome DevTools and went to the Network tab. When the job listing page loaded, I noticed a POST request firing to /jobsapi/_search. That was the key insight.
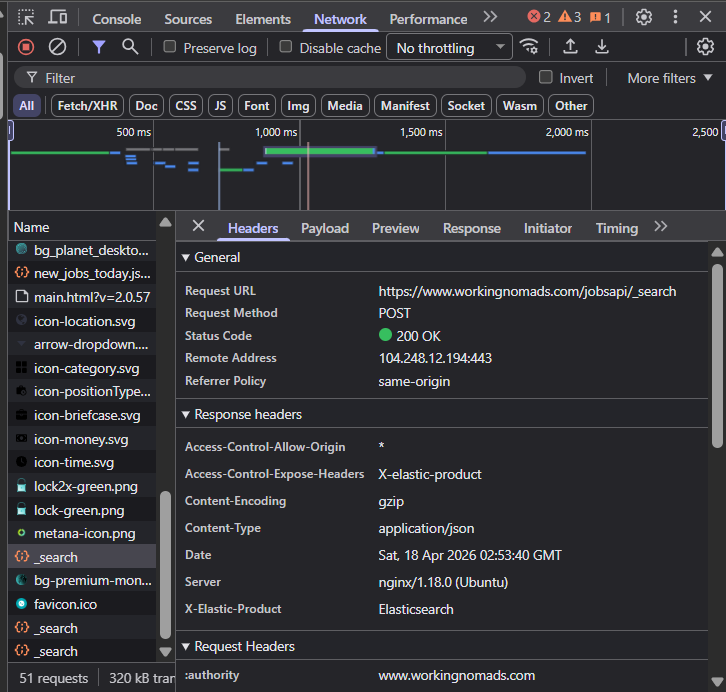
Working Nomads uses an AngularJS frontend that fetches jobs from an internal Elasticsearch endpoint. The response comes back as structured JSON with full job data already included: title, company, description, salary, tags, locations, apply URL, and more. There was no need to visit individual job detail pages.
The Elasticsearch payload includes from and size parameters for pagination, similar to SQL OFFSET and LIMIT. Once I captured the initial request payload, I could replay it with incrementing from values to paginate through all results.
Company profiles, however, are rendered server-side on separate pages at /remote-company/{slug}. So the architecture ended up being two distinct layers: API interception for job data, and Playwright-based HTML parsing for company profiles.
Actor architecture
I chose Playwright over CheerioCrawler for this Actor, which is the opposite of what I used for WWR. The reason is that Working Nomads renders the initial job list through JavaScript. Without a real browser, the Elasticsearch call never fires and there is nothing to intercept.
The Actor runs in three stages:
- Navigate to the listing URL with Playwright and listen for the Elasticsearch API response
- Extract job data from the API response and paginate by replaying the request payload with fetch()
- For each job, visit the company profile page with the same Playwright browser instance and extract company details
A company cache (Map) prevents hitting the same company profile more than once across multiple job listings.
Intercepting the Elasticsearch request
This is the core technique of the whole Actor. I set up a response listener before navigating to the page, so Playwright captures the API call as it happens:
const apiResponses = [];
page.on('response', async (response) => {
if (response.url().includes('/jobsapi/_search') && response.status() === 200) {
try {
const json = await response.json();
if (json.hits?.hits?.length > 0 && json.hits.hits[0]._source.description?.trim()) {
apiResponses.push({ request: response.request(), json });
}
} catch (e) {}
}
});A few things worth noting here. I filter responses by URL to only capture the jobs endpoint, not every API call the page makes. I also validate that the response has actual job data with descriptions before storing it. Early in testing, I was capturing empty or malformed responses that caused issues downstream.
After the page loads, I pull the original request payload from the captured response object:
const apiCall = apiResponses[0];
const searchPayload = JSON.parse(apiCall.request.postData());
const totalHits = apiCall.json.hits.total.value;This gives me the exact search parameters the site itself used, including any filters the user set in the URL, like category or location. I replay them faithfully rather than constructing my own payload, which means the Actor respects whatever filters the user passes as input.
Handling pagination with the Elasticsearch payload
Once I have the initial payload and total job count, pagination is straightforward. I increment the from field and POST the modified payload directly using fetch(), skipping Playwright for subsequent pages:
let from = searchPayload.from + searchPayload.size;
while (from < totalHits && (!effectiveMaxJobs || totalPushed < effectiveMaxJobs)) {
searchPayload.from = from;
const res = await fetch(API_URL, {
method: 'POST',
headers: { 'Content-Type': 'application/json' },
body: JSON.stringify(searchPayload)
});
if (!res.ok) break;
const data = await res.json();
await processJobs(data.hits.hits, page);
from += searchPayload.size;
}Using fetch() for pagination instead of Playwright is a deliberate performance decision. Opening a new browser page for every paginated request would be slow and memory-heavy. Since the Elasticsearch endpoint accepts plain JSON with no cookie or session requirement, a simple fetch() call works fine after the initial browser session is established.
Extracting and normalizing job data
Each job comes from the _source field of an Elasticsearch hit. The data is mostly clean but needs some normalization. The position type for example comes as a two-letter code:
positionType: (() => {
const pt = src.position_type?.toLowerCase();
if (pt === 'pt') return 'Part-time';
if (pt === 'ft') return 'Full-time';
if (pt === 'fr') return 'Contract';
return src.position_type || 'N/A';
})(),The description comes as raw HTML. I store it as-is but also create a plain text version by stripping all HTML tags:
descriptionText: src.description ? src.description.replace(/<[^>]*>/g, '').trim() : '',Salary handling needed two fields because Working Nomads stores both a short display range and a full annual USD figure in separate fields. I capture both so users can work with whichever format suits their pipeline.
Company profile enrichment
This is what separates this Actor from a basic job listing scraper. For each unique company, I visit the Working Nomads company profile page and extract:
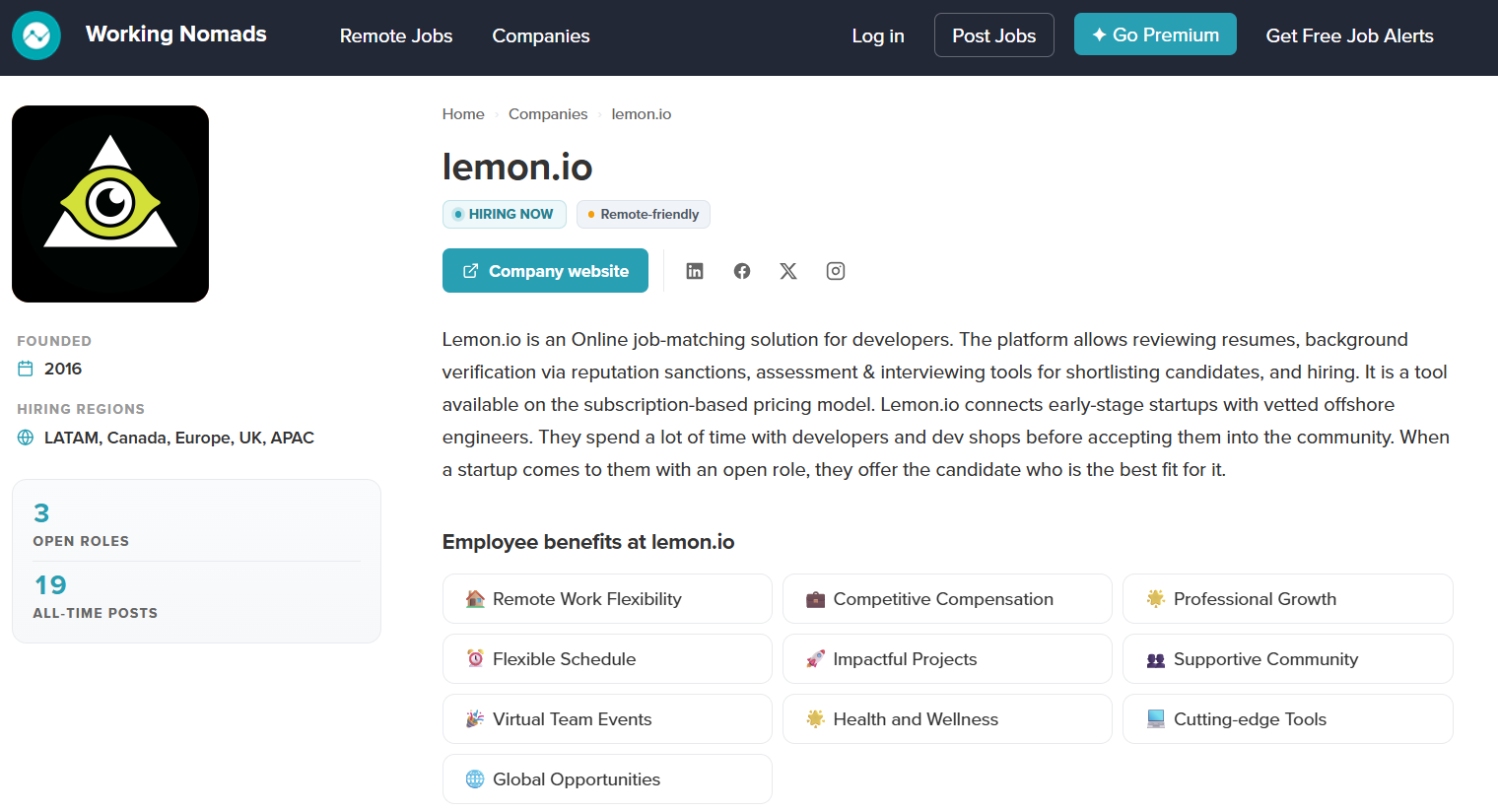
- Company website
- LinkedIn, Twitter, Facebook, GitHub, YouTube, and Instagram links
- Company logo URL
- Founded year
- Hiring regions
- Company about section
- Employee benefits list
Social links are extracted by checking both the image alt text and the href of each anchor in the .company-links container:
const imgAlt = $(el).find('img').attr('alt') || '';
if (imgAlt.includes('LinkedIn') || href.includes('linkedin.com')) data.companyLinkedIn = href;
if (imgAlt.includes('Twitter') || href.includes('twitter.com') || href.includes('x.com')) data.companyTwitter = href;I check both the alt text and the URL because some companies use custom icon images where the alt attribute is more reliable than the domain.
Extracting employee benefits
Benefits were tricky to extract cleanly. They sit below an h2 containing the word 'benefits', but the same section also contains navigation links and promotional text. I added a filter to exclude those:
$('h2:contains("Employee benefits"), h2:contains("benefits")').nextAll('p').each((i, el) => {
const txt = $(el).text().trim();
if (txt && !txt.includes('Explore') && !txt.includes('Remote Jobs')) {
benefits.push(txt);
}
});This is the kind of selector logic that only comes from actually looking at the rendered HTML. The benefits section bleeds into promo content without a clear structural boundary, so the text filter is necessary.
Caching company profiles
Multiple jobs often share the same company. Without caching, the Actor would visit the same company profile page dozens of times in a large run. I used a simple Map to store results by company slug:
const companyCache = new Map();
async function getCompanyData(page, slug) {
if (companyCache.has(slug)) {
return companyCache.get(slug);
}
// ... fetch and parse company page ...
companyCache.set(slug, data);
return data;
}In a run with 100 jobs from 30 unique companies, this saves 70 redundant page visits. The performance difference is significant, especially when each company page has a 60-second timeout and a networkidle wait condition.
Free vs. paid user limits
Like the WWR Actor, I implemented a free user cap using Apify's environment variable. This one checks two variables to handle both the older and newer Apify SDK conventions:
const isPaid = process.env.APIFY_IS_PURCHASED === 'true' || process.env.APIFY_USER_IS_PAYING === '1';
const FREE_LIMIT = 5;
const effectiveMaxJobs = !isPaid ? Math.min(FREE_LIMIT, maxJobs || FREE_LIMIT) : maxJobs;Free users get 5 jobs. Paid users get whatever limit they set, or unlimited if they leave it blank. The limit is checked at every job before pushing to the dataset, so it is always respected even across paginated runs.
What broke first and how I fixed it
Problem 1: Capturing empty API responses
Working Nomads fires multiple requests to /jobsapi/_search when the page loads, not just one. Some of those are preflight or metadata requests that return empty hits arrays. My first version stored all of them and then crashed trying to process empty job arrays.
The fix was to validate the response before storing it, specifically checking that hits exist and that the first result has a non-empty description. That filters out all the noise and keeps only the real job data response.
Problem 2: Playwright timing issues on company pages
Company profile pages use a btn-primary button that links to the company website. But the href attribute takes a moment to populate after page load. On my first runs, I was scraping the button before the href was set and getting empty or relative URLs.
I added a waitForFunction call that waits until the button href starts with http before proceeding. This sounds simple, but it took a while to identify because the failure was silent and just produced N/A for the website field:
await page.waitForFunction(() => {
const btn = document.querySelector('.btn-primary');
return btn?.href?.startsWith('http');
}, { timeout: 20000 }).catch(() => {});The .catch() at the end means if this times out, the Actor continues rather than crashing. Some company pages genuinely have no website button, so a hard failure here would have broken entire runs.
Problem 3: Benefits text mixing with promo content
The employee benefits section on company pages does not have a clean container. The benefits are just p tags that follow the h2 heading, and so is the promotional footer text that says things like 'Explore Remote Jobs on Working Nomads'. My first version was picking all of that up as benefits.
I added text-based exclusion filters for known promo strings. It is not a perfect solution, but it handles the real-world cases I encountered across dozens of company pages during testing.
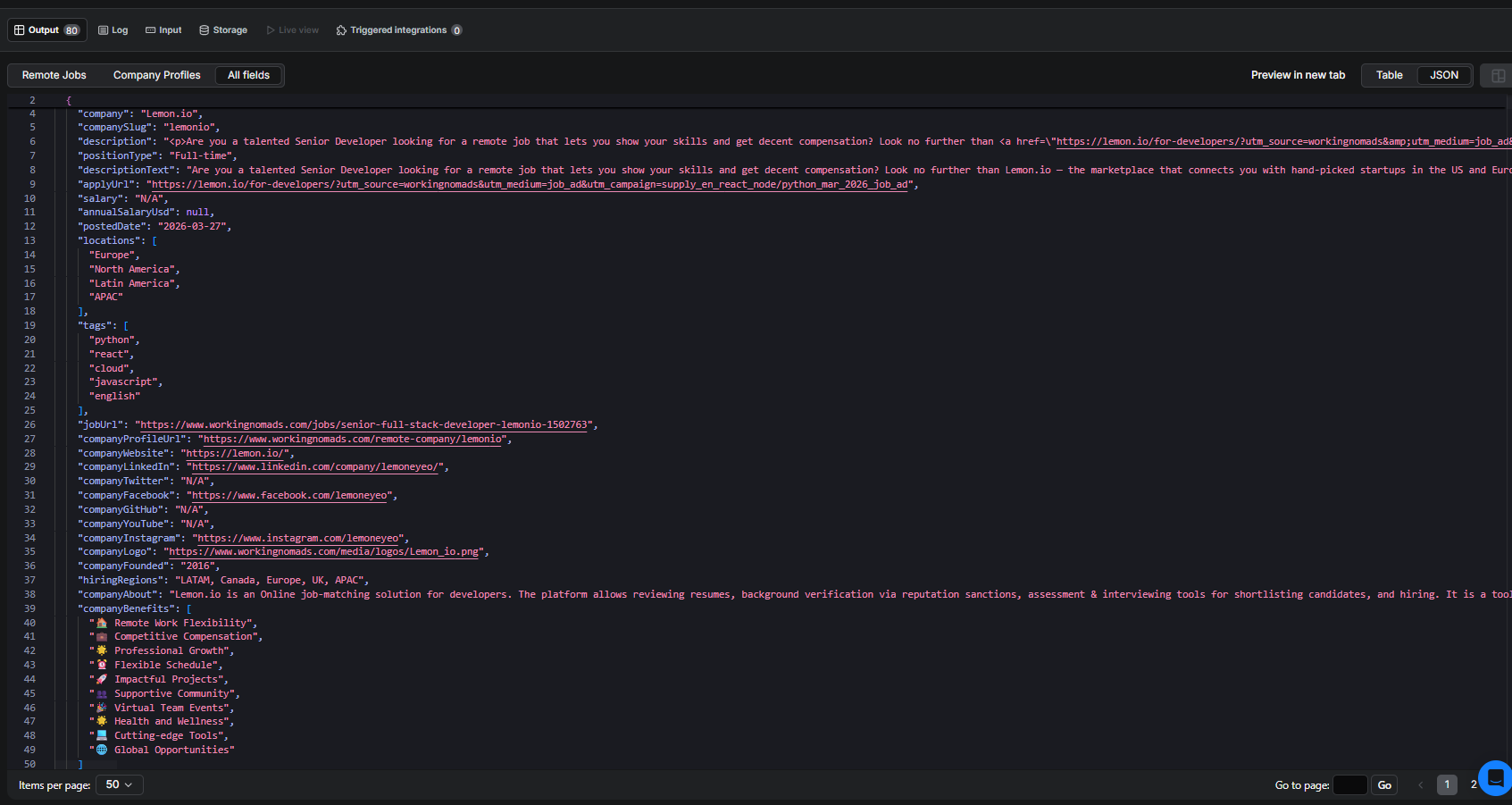
Sample output
Here is what a real record from the dataset looks like:
{
"title": "Senior Vue Developer",
"company": "Lemon.io",
"companySlug": "lemonio",
"description": "<p>Are you a talented Senior Developer looking for a remote job that lets you show your skills and get decent compensation? Look no further than <a href=\"https://lemon.io/for-developers/?utm_source=workingnomads&utm_medium=job_ad&utm_campaign=supply_en_vue_apr_2026_job_ad\" rel=\"nofollow\" target=\"_blank\">Lemon.io</a> — the marketplace that connects you with hand-picked startups in the US and Europe.</p>\n<p><strong>What we offer:</strong></p>\n<ul>\n<li>The rate depends on your seniority level, skills and experience. We've already paid out over $11M to our engineers.</li>\n<li>No more hunting for clients or negotiating rates — let us handle the business side of things so you can focus on what you do best.</li>\n<li>We'll manually find the best project for you according to your skills and preferences.</li>\n<li>Choose a schedule that works best for you. It’s possible to communicate async or minimally overlap within team working hours.</li>\n<li>We respect your seniority so you can expect no micromanagement or screen trackers.</li>\n<li>Communicate directly with the clients. Most of them have technical backgrounds. Sounds good, yeah?</li>\n<li>We will support you from the time you submit the application throughout all cooperation stages.</li>\n<li>Most of our projects involve working in a fast-paced startup environment. We hope you like it as much as we do.</li>\n<li>Through our community, we will connect you with the best developers from more than 71 countries.</li>\n</ul>\n<p>We have different positions for Senior Vue Developers, including front-end and full-stack roles. Please check the requirements for each option in the topic below.</p>\n<p>We also have many other positions available—please check the job listings below.</p>\n<h3><strong>Requirements for Senior Vue.js Positions:</strong></h3>\n<ul>\n<li>4+ years of software development experience</li>\n</ul>\n<p><strong>Commercial experience with:</strong></p>\n<ul>\n<li>Vue.js 4+ years & Nuxt.js 2+ years<br/><strong>OR</strong></li>\n<li>Vue.js 2+ years & Symfony 3+ years<br/><strong>OR</strong></li>\n<li>Vue.js 3+ years & PHP 3+ years<br/><strong>OR</strong></li>\n<li>Vue.js 3+ years & Node.js 3+ years<br/><strong>OR</strong></li>\n<li>Vue.js 3+ years & Python 3+ years<br/><strong>OR</strong></li>\n<li>Vue.js 3+ years & .NET 5+ years & TypeScript 1+ year<br/><strong>OR</strong></li>\n<li>Vue.js 5+ years & .NET 3+ years & TypeScript 1+ year</li>\n</ul>\n<p><strong>Other requirements:</strong></p>\n<ul>\n<li>Strong technical skills: as a Senior Developer, you are expected to be able to create projects from scratch and have a deep understanding of application architecture.</li>\n<li>Clear and effective communication in English — advanced ability to discuss business tasks, justify decisions, and communicate issues. Good self-presentation is also essential for upcoming client calls.</li>\n<li>Strong self-organizational skills — ability to work full-time remotely with no supervision.</li>\n<li>Reliability — we want to trust you and expect that you won’t let us and the client down.</li>\n<li>Adaptability and Flexibility — the ability to onboard the project promptly after accepting it and start delivering results quickly.</li>\n</ul>\n<p>Sounds good for you? Apply now and join the <a href=\"https://lemon.io/for-developers/?utm_source=workingnomads&utm_medium=job_ad&utm_campaign=supply_en_vue_apr_2026_job_ad\" rel=\"nofollow\" target=\"_blank\">Lemon.io</a> community!</p>\n<p><strong>NOT YOUR TECH STACK?</strong></p>\n<p>We have multiple projects available for Senior Developers. If you have 4+ years of commercial software development experience and are proficient in any of the following areas and roles: AI Agent Architect, AI Automation Architect, React & Node, React & Python, React & Golang, Python & Flask, Golang, React & Ruby, PHP & Angular, React & .NET, Android & iOS, Angular & .NET, Angular & Node.js, MLOps, React & Java, Data Science, Blockchain (Web3/Solidity/Solana), Symfony & React, Symfony & Angular, Symfony & JavaScript & Next.js & TypeScript, Data Analysis, React & PHP, Data Engineering, AI Engineering, Data Annotation, DevOps, Svelte & Python, Svelte & Node, Svelte & TypeScript, Rust, Shopify & JavaScript, Python & Node, Angular & TypeScript, Ruby & Ruby on Rails, React Native & Ruby, React Native & Python, PHP & Laravel, .NET & C#, Java & Spring, Unreal Engine & C++, Python & LLM, Unity, Machine Learning Engineering — we’d be happy to connect and match you with a suitable project.</p>\n<p><strong>If your experience matches our requirements, be ready for the next steps:</strong></p>\n<ul>\n<li>VideoAsk — watch a short video about our startup, up to 10 minutes</li>\n<li>Complete your profile on our website</li>\n<li>Screening call</li>\n<li>Technical interview</li>\n<li>Feedback</li>\n<li>Magic Box (we are looking for the best project for you).</li>\n</ul>\n<p>We do not provide visa assistance, and our cooperation model does not include the benefits typically offered with direct hire.</p>\n<p>P.S. <strong>We work with developers from 71+ countries in different regions:</strong> Europe, LATAM, the U.S (if you are an owner of W-9 ben form), Canada, Asia (Japan, Singapore, South Korea, Philippines, Indonesia), Oceania (Australia, New Zealand, Papua New Guinea), and the the UK. However, we have some exceptions.</p>\n<p><strong>At the moment, we don’t have a legal basis to accept applicants from the following countries:</strong></p>\n<ul>\n<li>European: Hungary, Iceland, Liechtenstein, Kosovo, Belarus, Russia, and Serbia.</li>\n<li>Latin America: Cuba and Nicaragua</li>\n<li>Most Asian countries and Africa.</li>\n</ul>\n<p>We expand and shorten the list of exemptions regularly.</p>\n<p> </p>",
"positionType": "Full-time",
"descriptionText": "Are you a talented Senior Developer looking for a remote job that lets you show your skills and get decent compensation? Look no further than Lemon.io — the marketplace that connects you with hand-picked startups in the US and Europe.\nWhat we offer:\n\nThe rate depends on your seniority level, skills and experience. We've already paid out over $11M to our engineers.\nNo more hunting for clients or negotiating rates — let us handle the business side of things so you can focus on what you do best.\nWe'll manually find the best project for you according to your skills and preferences.\nChoose a schedule that works best for you. It’s possible to communicate async or minimally overlap within team working hours.\nWe respect your seniority so you can expect no micromanagement or screen trackers.\nCommunicate directly with the clients. Most of them have technical backgrounds. Sounds good, yeah?\nWe will support you from the time you submit the application throughout all cooperation stages.\nMost of our projects involve working in a fast-paced startup environment. We hope you like it as much as we do.\nThrough our community, we will connect you with the best developers from more than 71 countries.\n\nWe have different positions for Senior Vue Developers, including front-end and full-stack roles. Please check the requirements for each option in the topic below.\nWe also have many other positions available—please check the job listings below.\nRequirements for Senior Vue.js Positions:\n\n4+ years of software development experience\n\nCommercial experience with:\n\nVue.js 4+ years & Nuxt.js 2+ yearsOR\nVue.js 2+ years & Symfony 3+ yearsOR\nVue.js 3+ years & PHP 3+ yearsOR\nVue.js 3+ years & Node.js 3+ yearsOR\nVue.js 3+ years & Python 3+ yearsOR\nVue.js 3+ years & .NET 5+ years & TypeScript 1+ yearOR\nVue.js 5+ years & .NET 3+ years & TypeScript 1+ year\n\nOther requirements:\n\nStrong technical skills: as a Senior Developer, you are expected to be able to create projects from scratch and have a deep understanding of application architecture.\nClear and effective communication in English — advanced ability to discuss business tasks, justify decisions, and communicate issues. Good self-presentation is also essential for upcoming client calls.\nStrong self-organizational skills — ability to work full-time remotely with no supervision.\nReliability — we want to trust you and expect that you won’t let us and the client down.\nAdaptability and Flexibility — the ability to onboard the project promptly after accepting it and start delivering results quickly.\n\nSounds good for you? Apply now and join the Lemon.io community!\nNOT YOUR TECH STACK?\nWe have multiple projects available for Senior Developers. If you have 4+ years of commercial software development experience and are proficient in any of the following areas and roles: AI Agent Architect, AI Automation Architect, React & Node, React & Python, React & Golang, Python & Flask, Golang, React & Ruby, PHP & Angular, React & .NET, Android & iOS, Angular & .NET, Angular & Node.js, MLOps, React & Java, Data Science, Blockchain (Web3/Solidity/Solana), Symfony & React, Symfony & Angular, Symfony & JavaScript & Next.js & TypeScript, Data Analysis, React & PHP, Data Engineering, AI Engineering, Data Annotation, DevOps, Svelte & Python, Svelte & Node, Svelte & TypeScript, Rust, Shopify & JavaScript, Python & Node, Angular & TypeScript, Ruby & Ruby on Rails, React Native & Ruby, React Native & Python, PHP & Laravel, .NET & C#, Java & Spring, Unreal Engine & C++, Python & LLM, Unity, Machine Learning Engineering — we’d be happy to connect and match you with a suitable project.\nIf your experience matches our requirements, be ready for the next steps:\n\nVideoAsk — watch a short video about our startup, up to 10 minutes\nComplete your profile on our website\nScreening call\nTechnical interview\nFeedback\nMagic Box (we are looking for the best project for you).\n\nWe do not provide visa assistance, and our cooperation model does not include the benefits typically offered with direct hire.\nP.S. We work with developers from 71+ countries in different regions: Europe, LATAM, the U.S (if you are an owner of W-9 ben form), Canada, Asia (Japan, Singapore, South Korea, Philippines, Indonesia), Oceania (Australia, New Zealand, Papua New Guinea), and the the UK. However, we have some exceptions.\nAt the moment, we don’t have a legal basis to accept applicants from the following countries:\n\nEuropean: Hungary, Iceland, Liechtenstein, Kosovo, Belarus, Russia, and Serbia.\nLatin America: Cuba and Nicaragua\nMost Asian countries and Africa.\n\nWe expand and shorten the list of exemptions regularly.",
"applyUrl": "https://lemon.io/for-developers/?utm_source=workingnomads&utm_medium=job_ad&utm_campaign=supply_en_vue_apr_2026_job_ad",
"salary": "N/A",
"annualSalaryUsd": null,
"postedDate": "2026-04-28",
"locations": [
"Europe",
"North America",
"Latin America",
"APAC"
],
"tags": [
"vuejs",
"php",
"python",
"javascript",
"english"
],
"jobUrl": "https://www.workingnomads.com/jobs/senior-vue-developer-lemonio",
"companyProfileUrl": "https://www.workingnomads.com/remote-company/lemonio",
"companyWebsite": "N/A",
"companyLinkedIn": "N/A",
"companyTwitter": "N/A",
"companyFacebook": "N/A",
"companyGitHub": "N/A",
"companyYouTube": "N/A",
"companyInstagram": "N/A",
"companyLogo": "N/A",
"companyFounded": "N/A",
"hiringRegions": "N/A",
"companyAbout": "N/A",
"companyBenefits": []
}
The company benefits array and social links are what make this dataset stand out. For job market analysis or recruitment tooling, having that context in the same record saves a lot of downstream enrichment work.
Deploying to Apify Store
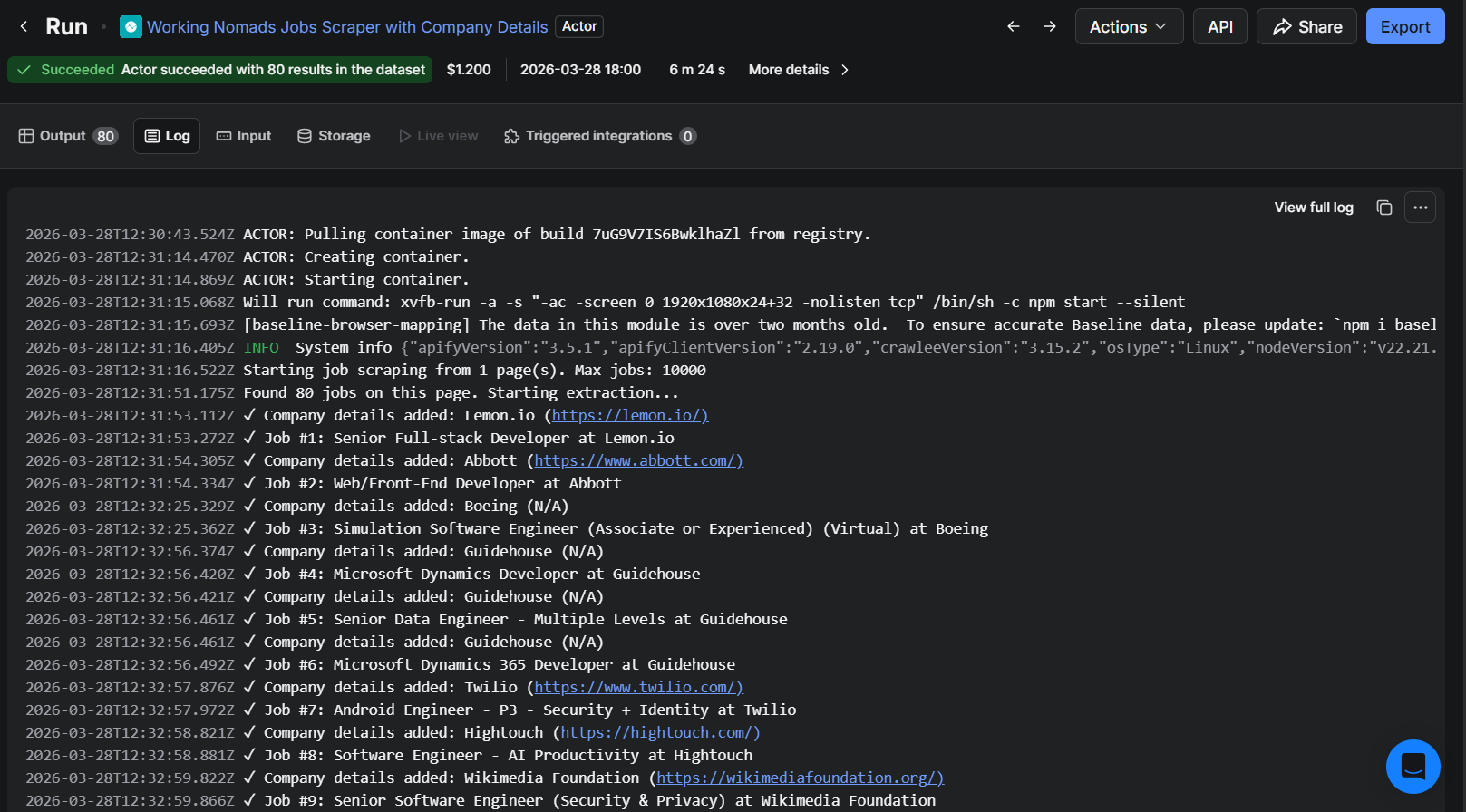
The deployment process is the same as any other Apify Actor. After testing locally with apify run --purge, push with: apify push.
The input schema exposes three parameters: urls (array of Working Nomads listing URLs to scrape), includeCompanyDetails (boolean to toggle company enrichment), and maxJobs (job count limit).
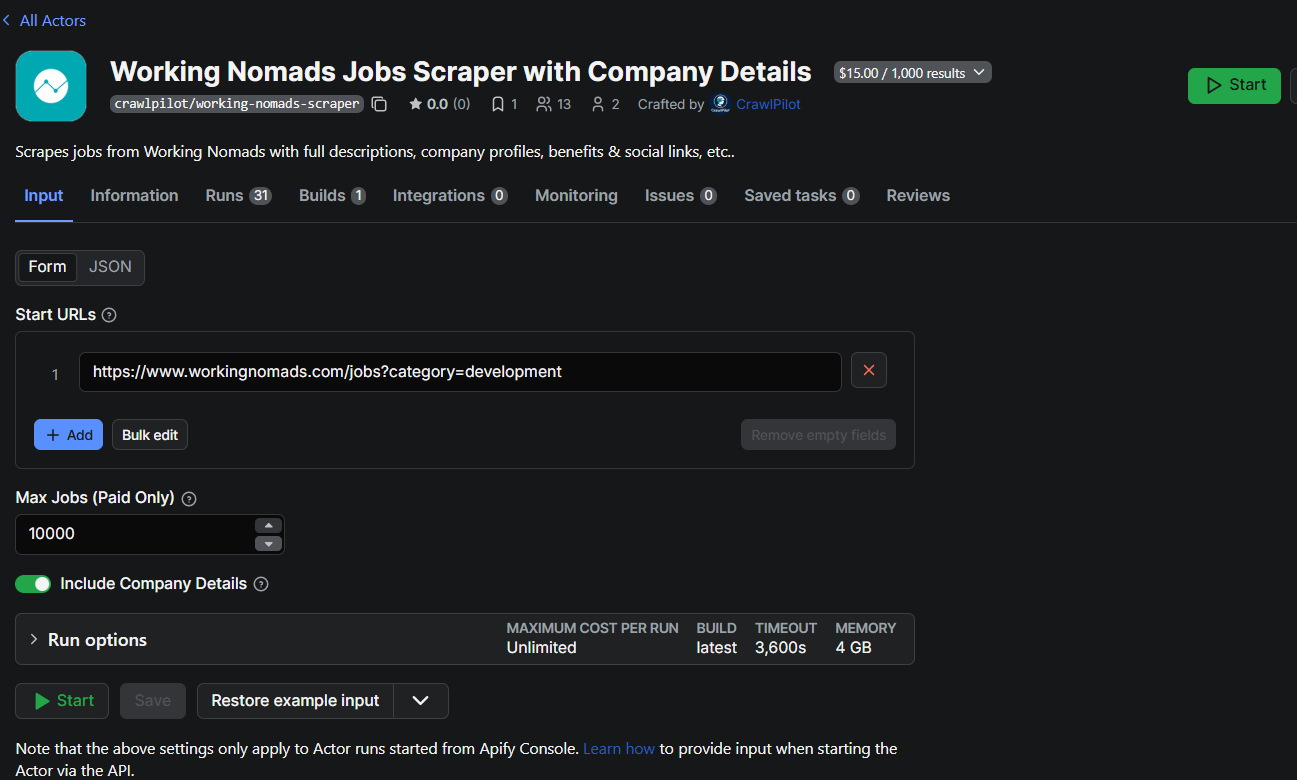
You can find the Actor on Apify Store. Keeping companyDetails as a toggle is important because visiting company pages adds significant time to each run. Users who just need job listings can turn it off and get results much faster.
Lessons learned
- Network interception is often cleaner than HTML parsing when a site uses an internal API. The Elasticsearch response gives you structured data directly, with no selector maintenance needed.
- Mix Playwright and fetch() strategically. Use the browser only where you need JavaScript execution, and fall back to fetch() for anything that works as a plain HTTP call. This keeps memory usage down on paginated runs.
- Always validate intercepted responses before storing them. Sites fire multiple API calls on load and not all of them contain what you need.
- Silent failures in scraping are worse than loud ones. Wrapping company page visits in try/catch with fallback values means a broken company page never kills a full run.
- A simple Map cache for repeated entities like company profiles has an outsized impact on performance. It is worth adding even for moderately sized runs.
Conclusion
Working Nomads was a more interesting technical challenge than I expected going in. The Elasticsearch interception approach turned out to be cleaner than traditional HTML scraping because the API response gives you structured data with no selector fragility. The harder part was the company enrichment layer, where timing issues and messy HTML required more defensive coding.
If you need remote job data from Working Nomads with full company context, the Actor is live on Apify Store: crawlpilot/working-nomads-scraper.
Questions or feedback? Join the conversation on Apify Discord.

FAQ
Does this work with any Working Nomads category or location filter?
Yes. Pass any Working Nomads listing URL as input and the Actor will respect the filters in that URL. The Elasticsearch payload is captured directly from that page, so whatever filters you set in the URL get replayed for pagination automatically.
Why use Playwright instead of Cheerio or Puppeteer?
Working Nomads loads job data through JavaScript. Without a real browser, the Elasticsearch request never fires. Playwright was chosen over Puppeteer for its cleaner async API and better network interception support.
How long does a full run take?
It depends on how many jobs and unique companies are in the results. Job data extraction via API is fast. Company profile visits are the slow part, about 5 to 10 seconds per unique company. For 100 jobs from 40 companies, expect roughly 5 to 8 minutes with company enrichment enabled.
Can I disable company enrichment to speed things up?
Yes. Set includeCompanyDetails to false in the Actor input, and it will skip all company page visits. Job data alone runs significantly faster.