


If you’re looking for a data collection tool to build or improve AI applications - be they language models, agents, or chatbots - you're likely trying to:
- Automate large-scale data gathering across the web or internal systems
- Structure and clean that data fast - without wrangling it manually
- Feed that data into AI models for training, fine-tuning, or enrichment.
The following tools are built for exactly that. They actively collect real-world data — from websites, APIs, or human input — to help you train, fine-tune, or evaluate AI models. For example, a team building an AI budgeting tool might use these to gather and organize financial data from multiple sources — much like in Workday Implementation.
Each one is actively used in 2025 by teams building AI agents, NLP systems, large language models, and other generative AI applications.
8 best AI data collection tools in 2025
1. Apify
Apify is a web scraping browser automation platform that lets you automate data extraction from any public website using its extensive library of “Actors.” It’s used by teams building recommendation systems, monitoring e-commerce data, or training NLP models on live content.
👍 Best for: Developers and data teams needing structured datasets from public websites.
⚙️ Features:
- Thousands of prebuilt scrapers to collect data from specific websites.
- Supports data collection from complex sites with JavaScript and CAPTCHAs.
- Integration with popular libraries, frameworks, and vector databases.
- Cloud storage with flexible data export formats (CSV, JSON, HTML +).
- Session and proxy management to avoid IP blocks.
💪 Benefits:
- Quick start-up due to scraping templates.
- Easy deployment and management of scrapers.
- Real-time monitoring and alerts for scraper performance.
💰 Pricing:
- From $39/month.
✅ Pros:
- Wide range of ready-made web scrapers.
- Smooth integration with coding libraries and AI frameworks.
- Cloud infrastructure and proxy management.
❌ Cons:
- Learning curve for customization.
- Complex billing.
A specialized scraping tool built for AI training and fine-tuning is Apify's Website Content Crawler. It extracts clean text from web pages and exports it to Markdown so you can feed relevant data to AI models. It supports JavaScript and CAPTCHA-solving to collect data from complex sites and integrates with AI frameworks and vector databases like LangChain, Hugging Face, Pinecone, and more.
2. Firecrawl
Firecrawl is built from the ground up for AI agents and LLM workflows. It crawls and extracts structured data from websites using natural language input, making it ideal for real-time model training and retrieval-augmented generation (RAG) pipelines.
👍 Best for: Teams building LLM workflows or retrieval-augmented generation (RAG) pipelines.
⚙️ Features:
- Semantic web crawling using natural language input.
- Handles dynamic content rendered by JavaScript.
- Outputs clean Markdown suitable for LLM training.
💪 Benefits:
- Open-source with community-driven development.
- Scalable solutions catering to both small-scale and enterprise projects.
💰 Pricing: From $16/month.
✅ Pros:
- User-friendly interface with minimal setup required.
- Reliable dynamic content handling.
❌ Cons: Unable to scrape social media sites.
3. Crawl4AI
Crawl4AI is an open-source web crawler built for LLM training. It extracts structured data via CSS/XPath and outputs clean Markdown or JSON, with full proxy/session control.
👍 Best for: Open-source enthusiasts working on LLM training or RAG applications.
⚙️ Features:
- Parallel browser-based crawling with CSS/XPath extraction.
- Outputs structured data in Markdown or JSON formats.
💪 Benefits: Full control without vendor lock-in.
💰 Pricing: Free and open-source.
✅ Pros:
- Context-aware data extraction preserves relationships between content.
- Easy setup requiring minimal code knowledge.
❌ Cons: No built-in support for advanced scraping scenarios like authentication.
4. Jina.ai
Jina.ai turns web data into vectorized representations for AI-native search and retrieval. Used for building real-time retrieval systems.
👍 Best for: Developers building AI-native search systems or vectorized representations.
⚙️ Features:
- Semantic crawling combined with embedding generation.
- Supports diverse data types like images, videos, audio, and text.
💪 Benefits: Ideal for creating real-time retrieval systems using vectorized outputs.
💰 Pricing: Custom pricing; some tools are open-source.
✅ Pros: Highly scalable solution tailored for AI indexing/search tasks.
❌ Cons: Requires technical expertise to implement effectively.
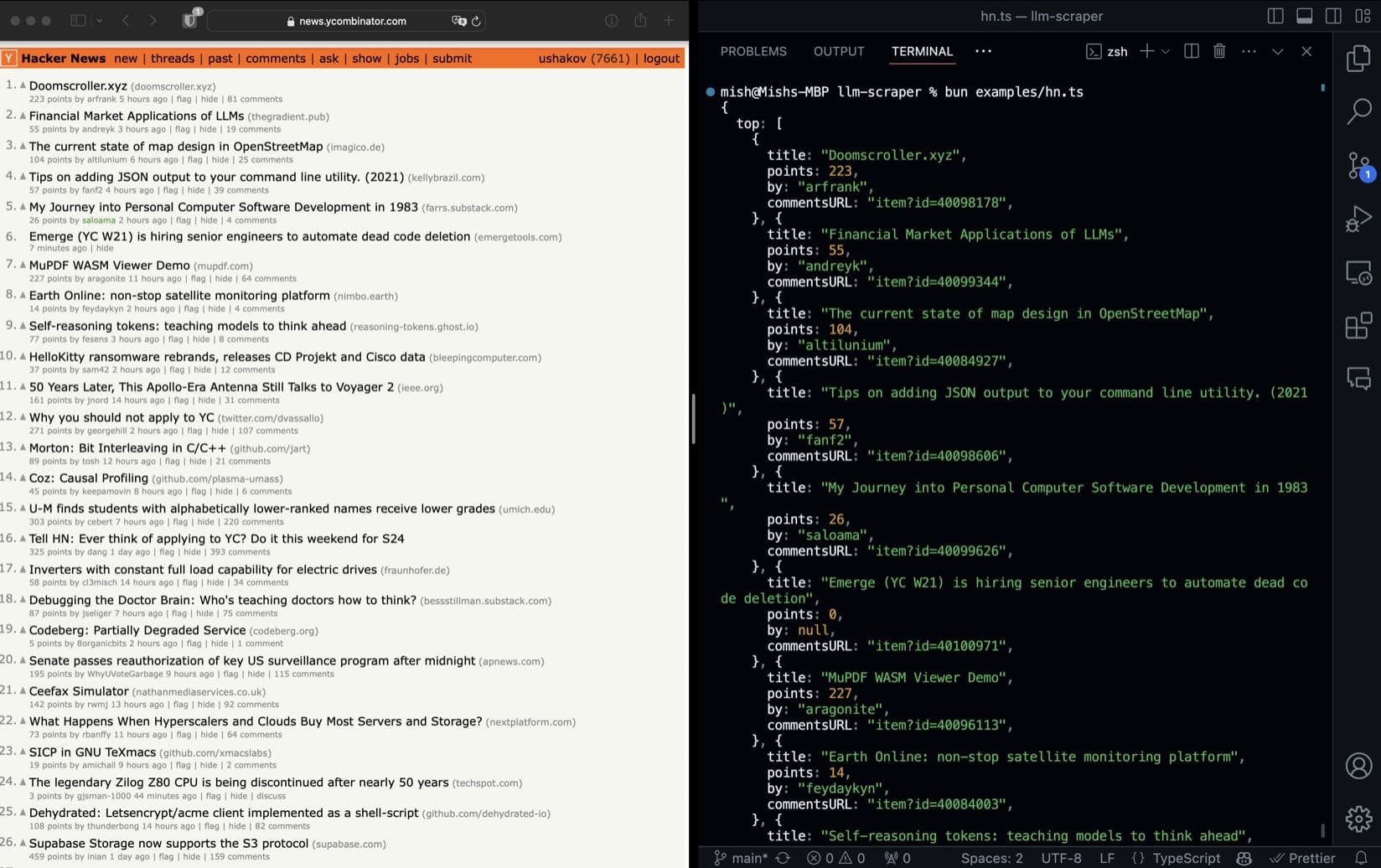
5. LLM Scraper
LLM Scraper uses function calling via LLMs to turn any webpage into structured data. It’s ideal for teams wanting quick-to-parse output from dynamic pages.
👍 Best for: Teams seeking quick-to-process structured data from dynamic webpages.
⚙️ Features: Function calling via LLMs to extract structured JSON data from web pages.
💪 Benefits: Optimized for LLM training workflows.
💰 Pricing: Free and open-source.
✅ Pros: Efficiently handles dynamic pages using TypeScript-based extraction methods.
❌ Cons: Limited scalability compared to commercial tools.
LLM development services: To build scalable and production-ready LLM solutions that go beyond data scraping, explore LLM development services focused on model training, fine-tuning, and enterprise deployment.
6. GPT Crawler
GPT Crawler combines headless browser scraping with content structuring using AI. Outputs include structured files for custom GPT model training or knowledge bases.
👍 Best for: Developers focused on large-scale AI training datasets or custom GPT model creation.
⚙️ Features: Combines headless browser scraping with AI-powered content structuring.
💪 Benefits: Tailored specifically for high-quality AI training data collection.
💰 Pricing: From $19/month
✅ Pros: Built-in semantic processing and content quality filtering enhance output relevance.
❌ Cons: Limited scalability compared to commercial tools.
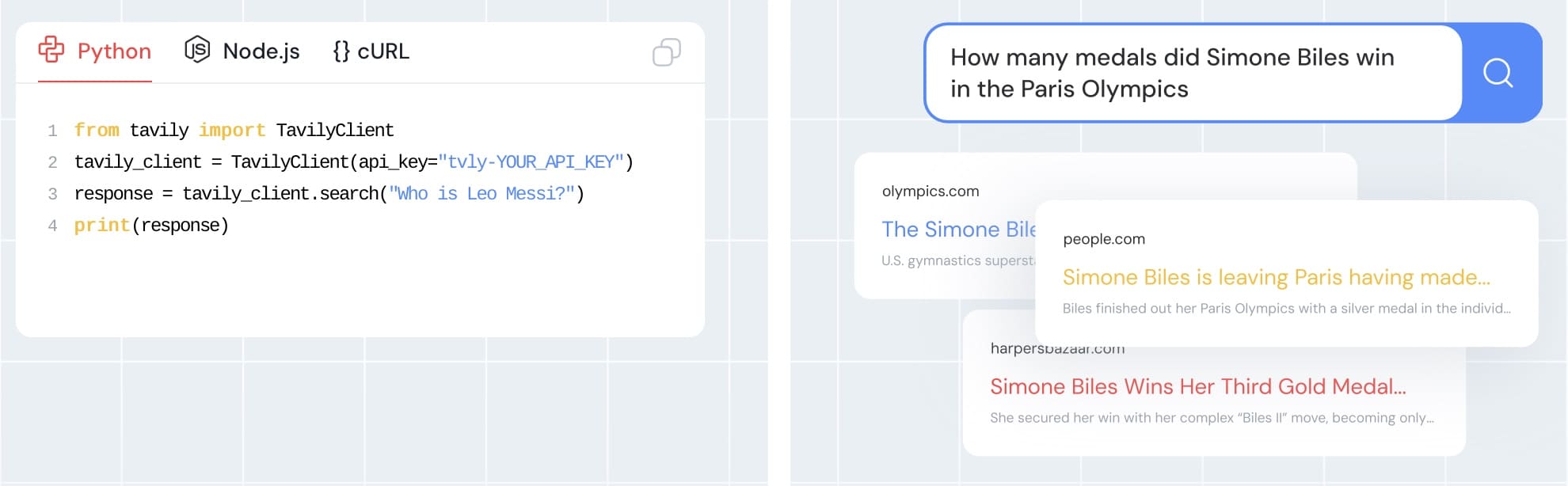
7. Tavily
Tavily is designed for real-time data aggregation, focusing on providing factual content to enhance AI model accuracy and reduce hallucinations.
👍 Best for: Developers and researchers building large language models (LLMs), retrieval-augmented generation (RAG) systems, or knowledge bases requiring real-time, factual data.
⚙️ Features:
- Provides source citations to ensure transparency and traceability.
- Integration with AI frameworks like LangChain and LlamaIndex.
- API-based access for automated workflows.
💪 Benefits:
- Reduces hallucinations in AI outputs by prioritizing factual content.
- Simplifies the process of curating high-quality, structured data.
💰 Pricing: From $30/month or a pay-as-you-go option
✅ Pros: Transparent citations improve credibility in AI outputs.
❌ Cons: Limited control over the selection of specific data sources.
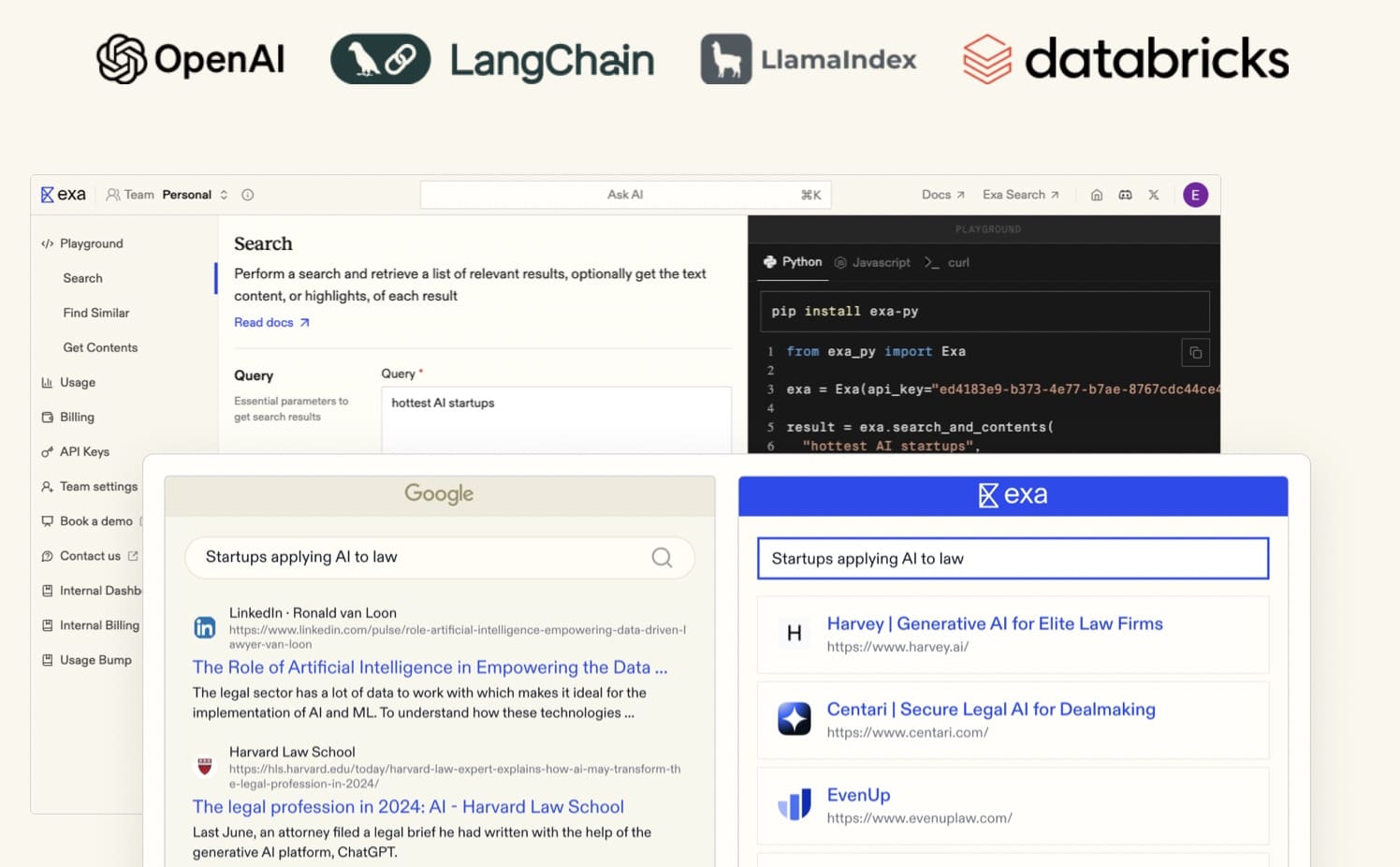
8. Exa
Exa combines real-time crawling with advanced semantic search capabilities. It offers curated datasets with features like multi-language support and similarity search, making it ideal for large-scale AI projects requiring diverse, high-quality data.
👍 Best for: Teams requiring scalable, high-quality web data for AI training, real-time applications, or semantic search systems.
⚙️ Features:
- Neural embedding-powered semantic search capabilities.
- Curated datasets with advanced filtering options (e.g., by domain, date).
- Multi-language support for global applications.
- Similarity search to find related content efficiently.
💪 Benefits: Supports large-scale projects with enterprise-grade infrastructure.
💰 Pricing: Pay-as-you-go or custom enterprise pricing for high-scale operations.
✅ Pros:
- Advanced semantic search enhances data relevance and quality.
- Multi-language support broadens applicability across global markets.
❌ Cons: Higher latency in some advanced features like similarity search.
Best AI data collection tools compared
| Tool | Collection method | Data type | Pricing | Custom scraping? |
|---|---|---|---|---|
| Apify | Web crawling/ scraping | Structured web data (e.g. e-commerce, social media, forums). Clean Markdown for LLMs, RAG, structured ML input | Free tier; paid plans from $49/mo | Yes |
| Firecrawl | Web crawling/ scraping | Contextual web data for LLMs, RAG, structured ML input, clean Markdown | Free tier; paid plans from $16/mo | No |
| Crawl4AI | Web crawling/ scraping | Clean Markdown, JSON, structured DOM content | Free and open source | No | Jina.ai | AI-native semantic + embedding | Vectorized page content for AI indexing/search | Custom pricing / OSS | Yes |
| LLM Scraper | LLM-powered extraction (TypeScript) | Structured JSON from web pages | Free and open source | No |
| GPT Crawler | Web crawling | Knowledge files and content for LLM training | Free tier; paid plans from $19/mo | Yes |
| Tavily | Search API | Real-time aggregated data | Free tier; pay-as-you-go; paid plans from $30/mo | Yes |
| Exa | Web search API | Curated datasets, embeddings | Pay-as-you-go | Yes |
Conclusion
If you're training, fine-tuning, or enriching AI models, you need data that's structured, current, and easy to process. The best tools don’t just gather data - they prep it for machine learning pipelines.
Exa, Firecrawl, and Jina.ai stand out for semantic and embedding-ready outputs and building retrieval-augmented generation systems. Open-source options like Crawl4AI, LLM Scraper, and GPT Crawler give you control without vendor lock-in. Tavily and Exa are useful for their search APIs and curated datasets.
If you want full control over web scraping and collecting clean, structured data with flexible exports for LLMs or RAG pipelines, try Apify.
Note: This evaluation is based on our understanding of information available to us as of April 2025. Readers should conduct their own research for detailed comparisons. Product names, logos, and brands are used for identification only and remain the property of their respective owners. Their use does not imply affiliation or endorsement.




