



Getting a 499 error shouldn't stop you from extracting publicly available data from any website. But if you're getting blocked by a 499 error from nginx, here are a few things you can do.
HTTP status codes are useful in web development and web scraping because they tell you how a request was handled by a server. A 499 status code, which means "client closed request" is something that you might easily come across when web scraping. The 499 status code is not part of the standard HTTP status codes defined by the Internet Assigned Numbers Authority (IANA), but you'll often come across it in environments using NGINX as a reverse proxy.
The error is common for web scraping if the browser (or web scraper) sends requests to a server behind Nginx, and Nginx closes the connection before receiving a response from the server. This scheme can be a deliberate attempt to block web scraping. So let's look into what 499 code means, what causes it, and how to navigate this issue to avoid getting blocked.
What is the 499 status code?
The 499 status code is the client-side error that occurs when the client aborts the request before the server gets the chance to respond to the API call. This code is primarily associated with Nginx, a popular reverse proxy. Nginx will log this status code when it chooses to disconnect before the server has processed nginx's request.
Unlike other client-based errors, such as 400 and 403, which are more specific in nature, the 499 error needs a bit of detective work to figure out. Since it's not directly caused by the server's end, you will have to test your assumptions about the client side of the interaction.
Why did the client choose to cancel the request? Did the server even get it? Well, it depends who's the client and who's the server here. Let's recreate the typical scenario of how that 499 error goes:
- Browser client (or your web scraper) sends an HTTP request to the website server.
- The HTTP request gets intercepted by Nginx. Nginx here acts as a reverse proxy to distribute the traffic load to the correct end server.
- Nginx server forwards the request to the end server and waits. By being the one to make the request, Nginx becomes the client in this interaction.
- The end server is not responding at all (most probably, it died during request processing or before it).
- Nginx (now as the client) aborts the request and logs the event as 499 code error.
- Nginx forwards the log to the browser client (or your web scraper).
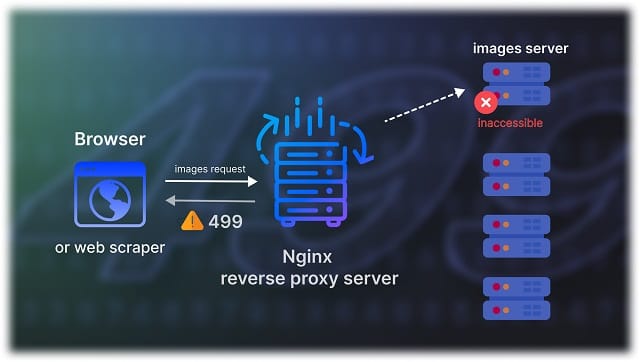
Nginx is commonly used by websites with high traffic as a reverse proxy to help distribute the traffic load more evenly. Here you thought you were sending a request directly to the server, which has the stuff you need — to see or to scrape — but you've met a middleman. Now the middleman is the one that interacts with the end server, not you or your scraper.
So when the middleman can't reach the end server and chooses to cancel the request, it will log this fact and forward it to you. Now, a simple statement of the fact "499: I canceled the request” doesn't say much to you. It doesn't inform you why nginx chose to do it, is there anything happening with the end server, so you can't adjust the behavior of your browser or scraper. And most importantly, you still haven't approached the data you need. The only discovery you make is that you're dealing with an nginx server instead of an end server.
The same happens when we replace the browser client with a web scraper or a web crawler.
The most common causes of HTTP 499 error
There are multiple reasons why the client might decide to close the connection. In no particular order, here are 5 most common reasons for triggering a 499 status code:
- User cancels the request. Most frequently, HTTP 499 errors are caused by users canceling requests by navigating away or pressing the "stop" or "cancel” button. This action interrupts the server's processing, typically when a webpage takes longer to load than the user expects.
- Browser timeouts. The purpose of a timeout is to prevent users from waiting indefinitely for a webpage to load. So when the browser reaches a preset time limit, it stops waiting for the server's response and cancels the request. A timeout, in its turn, can be caused by slow server responses or network issues.
- Network issues. Speaking of which, unstable connections or congested routers along the client-server path can easily cause dropped connections and HTTP 499 errors by disrupting data flow.
- High server loads. Overwhelming requests or unexpected spikes in visitors can delay processing and lead to timeouts. Without scalable server resources and website optimization, your website won't be able to handle the loads effectively. The server is limiting the number of open connections or rate of requests to avoid being overloaded and conserve resources.
- Automated traffic. Even benign bots like search engine crawlers or those programmed for rapid requests can trigger HTTP 499 errors. These scripts serve various purposes but can strain server resources and contribute to connection closures. If a server identifies behavior that looks like web scraping, such as a lot of requests from a single IP address, it can try to block the bots, no matter the intent.
1. Are you a website owner (you deal with servers directly) or a website user (you're web scraping)? Solving the 499 error will depend on which side of the website you are. 499 HTTP code is predominantly the log that the website owners get to see and have to act on. Only in rare cases, this is something a website user sees. Which brings us to the next question.
2. Are you sure 499 is an nginx error or is it some other type of error? Answering this question will determine your actions as well. 499 can mean any number of things because it's a non-standardized error. The internet knows it as an error caused by nginx server but in reality, it can stand for anything for any other website.
How to fix the 499 status code (5 tips for website admins)
1. Check the server error logs
Examining server error logs is crucial because it helps identify potential issues on the server-side that could lead to timeouts. By analyzing these logs you can figure out specific errors or bottlenecks occurring during data retrieval processes. This information is valuable for troubleshooting and optimizing scraping operations, ensuring smoother data extraction without disruptions.
Server applications might have error handling mechanisms that inadvertently close connections, leading to incomplete data collection. Review and refine these mechanisms. They should be robust enough to handle exceptions without disrupting the connection.
2. Check the network connection
Check the network connection: Make sure your internet connection is stable and strong to maintain consistent communication between the scraping script and the target website's servers. A shaky connection can lead to dropped requests and timeouts and throw a wrench in your scraping efforts. Without a reliable connection, scraping tasks are susceptible to disruptions, leading to HTTP 499 errors and incomplete data retrieval.
Moreover, monitoring network connectivity is crucial for adhering to scraping best practices and avoiding potential IP bans or throttling. By maintaining a stable connection, developers can minimize the likelihood of triggering server defenses that restrict access to scraping bots. This proactive approach fosters a positive relationship with website administrators and helps sustain long-term scraping operations.
3. Clear your cache
Sometimes, outdated data stored in the cache can wreak havoc on your server system. For instance, a content delivery network might reject a request if it's overwhelmed with data-related issues, such as high cache volume. And since it's now acting as a client, you will receive your HTTP error 499.
4. Disable plugins and extensions
A faulty plugin, antivirus software, or a virus on the client computer can a lead to the HTTP 499 status code error. Some users have found that specific plugins (that are part of the website) trigger this issue. To address this, deactivate all plugins on your website and then revisit your website to check if the error persists. If the error disappears, you reactivate the plugins one at a time to catch the faulty one.
5. Contact hosting and increase timeout
A slow server response can cause the client or scraping tool to time out and close the connection. If you're hitting timeout issues, it might be worth reaching out to your hosting provider to handle timeouts more efficiently. Sometimes a little tweak on their end can ensure your server has sufficient bandwidth to handle incoming and outgoing data promptly to prevent timeouts.
How to fix the 499 status code (7 tips for web scraping)
1. Do nothing
If the nginx scenario described above really takes place and the end server dies, there's nothing you can do about it regarding your crawler. It's an issue for the server side to fix, not for you to adapt to as a client. You can try checking the browser parameters to figure out what kind of server you're dealing with, and if ngnix is confirmed, then it's highly probable you've done nothing wrong, your scraper works, and this issue lies on the server side.
2. Be ethical when web scraping
It’s important to note that while 499 is primarily associated with nginx, it is still a non-standardized code. Which means that the websites can use this code to communicate any other message, including the "you're not welcome here because we think you're a bot” type of message. If you're unsure whether you're dealing with nginx here, you can double down on blocking prevention techniques and making sure you're scraping responsibly without unnecessary strain on the servers. You can do a lot to overcome 499 errors by practicing ethical web scraping and doing your best not to overwhelm a website with requests.
3. Try switching a browser or device
If things aren't working out with your current browser or device, why not give another one a shot? Sometimes changing the client is enough. Trying different browsers or devices can also help you stay under the radar when scraping. Mixing it up makes it harder for websites to detect your scraping activities, which can help you avoid getting flagged or blocked.
4. Rotate proxies when web scraping
If you continue to get 499 codes, you can also try rotating proxies. If the requests are coming from different IP addresses, the server will be less likely to recognize them as web scraping. Proxies are a reliable way to gather more data without hitting rate limits. Also, make sure your IP stays the same and stable while the request is being processed, before switching to a new IP. No server likes spontaneous network switch-ups.
5. Introduce rate limiting
Scraping websites too quickly may overwhelm the servers of smaller websites. To avoid this situation, you'll need to rate-limit your asynchronous connections. Setting a delay between requests will ensure that your scraping activities do not send requests faster than what the website's servers can handle.
6. Use client-side scripting
Using JavaScript on the client-side to interact with servers might introduce errors if not properly managed. Make sure that your scripts are well-equipped to handle errors gracefully. Your web scraping script should not terminate connections or fail silently but should provide fallback mechanisms or retry logic.
7. Browser fingerprinting as an antiblocking measure
Websites can identify and block scrapers based on their 'browser fingerprint', a unique combination of attributes like browser type, version, language settings, and more. To avoid detection, you can rotate or randomize these attributes in your scraping tools, making your requests appear to come from different users.
And if none of that works, you need to start looking at more advanced techniques, such as changing user agents, using headless browsers, and variable request rates.
FAQ
What is error code 499 in REST API?
The HTTP 499 error code in REST API signals that the client closed the connection before the API server could respond, typically due to a timeout. This happens when the browser client terminates the request prematurely, usually caused by user impatience, network issues, or both.
What is the 499 code in Nginx?
The HTTP 499 code is an error specific to Nginx API servers; it signals that the client chose to disconnect in the middle of request processing. The API call was received but the client aborted the request before the end server could complete the response. 499 error code is common for scenarios of client-side interruptions or network instability.
What is 499 status code when using proxy?
The HTTP 499 status code when using a proxy indicates that the ngnix reverse proxy server (client) closed the request before the destination server answered it. Often triggered by the destination server actually not being able to answer.
Is 499 status code triggered by timeouts?
Not when it involves a proxy server like nginx. If the website is using a proxy server and the destination server takes too long to respond, the error code will be 504 Gateway Timeout error, not 499. The difference between these is that the proxy server actually gets the chance to notice the timeout occuring and respond to it. In the case of 499 status code, the proxy server can see that the destination server dies before timeout, so it initiates canceling its request without waiting.
Does status code 499 affect SEO?
No, the status code 499 doesn’t affect SEO rankings or website visibility. The reason for this is because 499 status code is a client-side error, rather than a server error. When assessing website health for SEO purposes, search engines and SEO checker tools generally prioritize server-related status codes and errors (like errors in the 5xx range).
However, 499 can cause an indirect impact on SEO on the user engagement side. When visitors consistently cancel a request on your website page, you will soon see it reflected as a high bounce rate.
Full-stack platform for web scraping




