


This is the third in a series of articles we commissioned from an external developer (although Percival is a former Apifier). We want to create unbiased reviews of other web scraping platforms and companies as part of our continued evaluation of the industry.
Apify, Zyte, and Crawlbase all label themselves as full-stack web scraping platforms, but what does that even mean?
Unlike basic web scraping APIs like ScrapingBee or ScrapingAnt, these platforms do more than just help you pull data from websites. They let you connect with other services, save and manage your data in the cloud, and export your data in multiple formats, with the added benefit of an intuitive UI.
These are some of the features that can set full-stack platforms apart from simpler offerings on the market, but not every platform is the same.
In this article, we’ll look at what makes Apify, Zyte, and Crawlbase different and find out if any of them can even call themselves a full-stack web scraping platform.
We’ll also discuss in what scenarios you might want to choose one platform over the other.
So, without further ado, let’s kick things off with a comparison table detailing the core features of each service.
Apify, Zyte, and Crawlbase compared
| Features | Apify | Zyte | Crawlbase |
|---|---|---|---|
| Unlimited Free Plan | ✅ | ✅ (Scrapy Cloud) | ❌ (Limited to first 1,000 requests of the Crawling API or 10,000 if you provide payment info) |
| Library of pre-built web scrapers | ✅ (10,000+) | ❌ | ✅ (API endpoints for scraping data from popular websites such as Amazon, Instagram and Facebook) |
| Host code in the cloud | ✅ | ✅ (Limited to Scrapy Spiders) | ❌ |
| Available data export formats | CSV, HTML, JSON, XML, or RSS Feed | CSV, JSON, XML | JSON, HTML |
| Developer Community | ✅ (Newsletter and Discord Community with 7,200+ developers) | ✅ (Newsletter and Discord community (1700+ developers) | ❌ |
| Scrape dynamic web pages (using headless browsers) | ✅ | ✅ | ✅ |
| Geolocation Targeting | ✅ (Geolocation targeting available for every country in all plans - including free) | ✅ (Available through Zyte API) | ✅ (Available on their Scraper API Advanced plan and above) |
| Usage-based pricing | ✅ (Platform CU) | ✅ (Platform CU) | ✅ (API Credits) |
| High-scale enterprise plans | ✅ | ✅ | ✅ |
| Store data in the cloud | ✅ | ✅ | ✅ |
| Proxy rotation, browser emulation, CAPTCHA bypass | ✅ | ✅ | ✅ |
| API Access | ✅ (Full-fledged platform API) | ✅ (Zyte API for AI Scraping and Ban Handling) | ✅ (Scraping and Crawling APIs) |
| Schedule one-off or repeating extractions | ✅ (all plans) | ✅ (Restricted to organizations subscribed to Scrapy Cloud) | ❌ |
| Native integration with third-party tools | ✅ (Zapier, Make, Gmail, Google Drive, Slack, Github LangChain, and more) | ❌ (Integrations through YepCode) | ❌ |
| Open-Source contributions | Crawlee (Full-stack Node.js web scraping library) | Scrapy (Python web scraping framework) | ❌ |
| Monetization programs for developers | ✅ (Publish and monetize scrapers on Apify Store) | ❌ | ❌ |
As the feature comparison table above illustrates, Apify stands out for its comprehensive array of features.
Apify is an all-encompassing web scraping platform that supports scrapers written in any programming language, providing reliable infrastructure for scaling, distributing, and monetizing scrapers.
Zyte ranks second in terms of feature richness. It's important to note that most Zyte products are specifically designed to complement Scrapy, their popular open-source framework, making Zyte a more specialized option compared to Apify.
Crawlbase, while offering a solid API suite for web scraping, is the most limited of the three in terms of features. Its platform and user interface are visibly less polished and leave much to be desired in terms of user experience.
Aside from cloud storage for scraped data, Crawlbase’s platform does not offer any groundbreaking features beyond the basic functionalities already provided by its API services.
To better understand the unique offerings of each service, let's take a closer look into the features of Apify, Zyte, and Crawlbase.
Apify
Apify is a developer-centric, full-stack web scraping and automation cloud platform. It enables developers to build, run, and manage serverless cloud programs, known as Actors, capable of executing a wide range of tasks from simple data collection to complex automation workflows.
Below is an overview of some of the key features of the Apify platform:
Actors
At the heart of Apify are its Actors, versatile cloud programs capable of performing tasks like web scraping, data processing, and automation. Developers have the flexibility to build these Actors either locally or directly on the platform. Additionally, regular users can utilize publicly available, ready-made Actors from Apify Store.
Apify Proxy
Apify features a unique proxy solution that intelligently rotates between data center and residential IP addresses. The platform regularly checks and automatically removes dead or compromised proxies from the pool, ensuring reliable and effective scraping sessions.
SDKs and APIs
Apify offers platform JavaScript/TypeScript and Python SDKs as well as API endpoints to facilitate Actor development and integration with other applications.
Apify Store
Apify features an open store where users can access hundreds of pre-built web scrapers. Developers also have the opportunity to publish their Actors on Apify Store, potentially earning passive income when others use their creations.
Scraper performance monitoring
As a platform specifically tailored for web scraping, Apify includes a robust built-in monitoring system that helps developers track the performance of their scrapers over time.
Integrations
Actors can be integrated with a wide range of third-party applications that can significantly enhance your Actor’s functionalities.
Community and support
Apify has one of the largest and most active developer communities in the web scraping ecosystem, with over 7,000 members actively engaging on its Discord server.
Additionally, Apify provides a dedicated support team and extensive documentation replete with examples, helping developers master the platform, build Actors, and quickly address any issues they come across.
Zyte
Zyte positions itself as a comprehensive web scraping API provider, offering a vast range of APIs, including AI-powered scraping solutions. While you may not recognize the name Zyte immediately, you're likely familiar with their widely used open-source web scraping framework for Python, Scrapy. Its platform includes specialized support and cloud hosting for Scrapy Spiders.
Zyte's API also boasts essential features common among modern web scraping APIs, such as the ability to scrape dynamic page content, proxy rotation, and blocking prevention systems. Below are some of the products offered by Zyte and their respective features:
Zyte API
Zyte API is a web scraping solution that helps avoid bans, enables browser automation, and facilitates automatic data extraction. Upon creating a Zyte account and providing your payment details, you can enjoy a $5 credit to try out the API for a month.
A significant advantage of the Zyte API is its compatibility with Scrapy Spiders, enhancing their functionality by managing blocking issues, processing JavaScript content, and automating browser interactions.
Here’s an overview of how a browser automation setup looks when integrating Scrapy with Zyte API, compared to using ScraperAPI:
from scrapy import Request, Spider
class QuotesToScrapeComScrollBrowserSpider(Spider):
name = "quotes_toscrape_com_scroll_browser"
def start_requests(self):
yield Request(
"http://quotes.toscrape.com/scroll",
meta={
"zyte_api_automap": {
"browserHtml": True,
"actions": [
{
"action": "scrollBottom",
},
],
},
},
)
def parse(self, response):
for quote in response.css(".quote"):
yield {
"author": quote.css(".author::text").get(),
"tags": quote.css(".tag::text").getall(),
"text": quote.css(".text::text").get()[1:-1],
}
You can find a comprehensive tutorial on how to set up your project to run the code mentioned above in the Zyte documentation.
Scrapy Cloud
Scrapy Cloud - a Zyte product - is specifically built to host and monitor Scrapy spiders in the cloud. Designed to integrate seamlessly with Scrapy and the Zyte API, it allows developers to monitor and automate spiders at scale.
Scrapy Cloud stands out as the only product in Zyte’s suite that offers an unlimited free plan, although it comes with significant limitations.
The free plan allows only 1 concurrent job, uses a maximum of 1/2 GB of memory, limits job runtime to 1 hour, and excludes access to the job scheduling feature. These restrictions make Scrapy Cloud less suitable for substantial scraping projects without an upgrade to a paid plan.
In contrast, Apify’s free plan offers more flexibility by providing access to all platform features, including scheduling. It does not impose a maximum runtime for scraping jobs and supports a wide range of web scrapers, including Scrapy Spiders, with the only limitation being the monthly free credit limit of $5.
Crawlbase, on the other hand, does not offer a cloud hosting solution for scraping.

Developer community
Zyte's developer community is relatively new and currently consists of a bi-weekly newsletter and a growing Discord community (Extract Data Community). However, given that virtually all Zyte products are built around the Scrapy framework, Zyte’s community is intrinsically linked to that of Scrapy.
Scrapy itself boasts a large and well-established community of developers, which is reflected in the wealth of videos and content available about the framework. Another clear testament to the strength of Scrapy’s community is its GitHub recognition, where it has garnered over 51,000 stars.
Crawlbase
Crawlbase is a web scraping service offering a wide array of scraping APIs, like the Crawling API, Scraper API, Leads API, and Screenshots API. It incorporates many standard features expected of a modern web scraping API, such as proxies and anti-blocking technologies.
However, what distinguishes Crawlbase from other API services, like ScrapingBee, is its ability to store scraped data in the cloud—a feature not commonly found in most popular scraping API services.
APIs (CrawlingAPI, ScraperAPI, ScreenshotAPI…)
Crawlbase’s product suite primarily consists of various API options, each providing distinct functionalities that you can access by easily switching between the APIs in your code.
However, to handle JavaScript-heavy web pages, you need to switch API tokens.
Crawlbase provides two types of tokens: one for simple requests that do not require JavaScript handling and another for scraping pages with dynamically generated content.
This approach is less convenient compared to the usual approach adopted by other scraping APIs, which allow you to toggle this functionality on and off by simply passing a parameter. Below is an example of how you would use Crawlbase to extract data from Facebook:
from crawlbase import CrawlingAPI, ScraperAPI, LeadsAPI, ScreenshotsAPI, StorageAPI
# Replace 'CrawlingAPI' for the API you want to use.
api = CrawlingAPI({ 'token': 'YOUR_API_TOKEN' })
response = api.get("https://www.facebook.com/britneyspears")
if response['status_code'] == 200:
print(response['body'])
Data Scrapers
When using Crawlbase’s CrawlingAPI, you receive the complete page HTML, but you typically need to parse and scrape the content yourself.
However, for a few select websites, Crawlbase offers what they call 'Data Scrapers.' These tools allow you to extract data directly from a website without needing to parse the page’s HTML on your own.
These Data Scrapers are the closest offering Crawlbase has to the ready-made Actors available on Apify Store.
The code below showcases how to use the amazon-serp scraper by adding &scraper=amazon-serp to the usual API request URL.
import httpx
resp = httpx.get('&url=https://www.amazon.com/s?k=iphone+15&scraper=amazon-serp')
resp.text
Pricing
When it comes to pricing, all three services vary quite a lot due to how they structure their product offerings. So, to make it easier for me to break down the pricing, I will start with the free plans each product provides.
Free plans
- Apify
Apify stands out when it comes to free trials. Its free plan not only offers full access to all platform features but also renews its $5 credit monthly for an unlimited duration.
This means you could potentially use Apify indefinitely without any charge.
Additionally, no payment information is required to start using a free Apify account.
- Zyte
Zyte also offers a free plan, including a Scrapy Cloud option and $5 credits to try out their API services. However, the Scrapy Cloud free plan is significantly limited; it excludes key features like job scheduling and restricts scraping jobs to no more than one hour.
The $5 API credits are generous but are a one-time offer that does not renew monthly, and accessing them requires providing payment details.
- Crawlbase
Crawlbase provides 1,000 free requests on their CrawlingAPI, extendable to 10,000 requests if you provide payment information.
While this initial allocation is generous, like Zyte's offer, it is a one-time benefit without monthly renewal.
Zyte pricing
Navigating Zyte’s pricing structure can be quite challenging due to its complexity. Each product offering has a different pricing scheme, and these offerings often overlap, potentially leading to higher costs as you pay for multiple products while trying to determine the total cost for your scraping solution.
Despite its complexity, Zyte's granular pricing approach has its advantages, as it allows you to pay only for what you use, rather than investing in a full service package that includes features you may not need.
Zyte's pricing structure is very detailed, and a complete breakdown would warrant a separate post.
For reference, the image below shows the price per 1,000 requests when using Zyte API’s Ban Handling feature. So, if you are interested in a complete overview of Zyte’s pricing for each service, I recommend you visit Zyte’s pricing page.
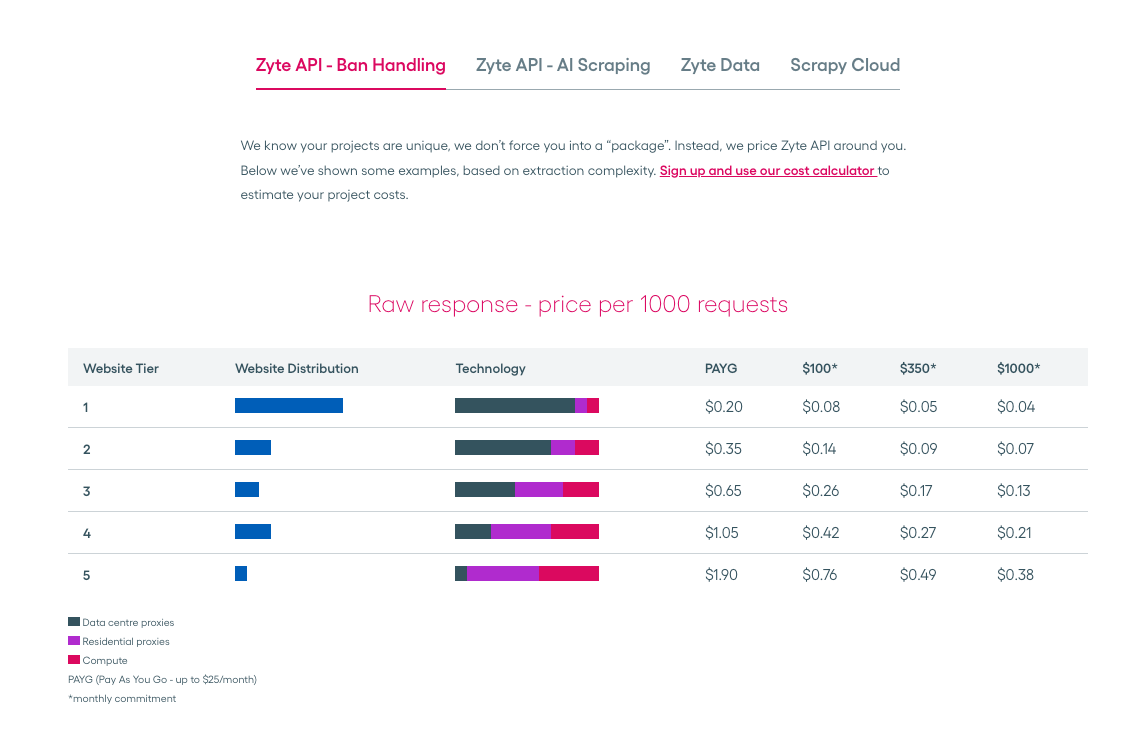
Crawlbase pricing
Crawlbase's pricing structure is arguably more complicated than Zyte's, but this complexity stems less from a desire to offer granular pricing and more from a poor user experience on their dashboard and website.
The pricing models themselves are not inherently difficult to understand; however, they are scattered across various product offerings and presented in a manner that makes it challenging for users to figure out the total investment required to get access to all the features they need.
Initially, accessing pricing information requires creating an account, which can already be frustrating for potential users. Upon registration, the dashboard presents seven product options, each with its own pricing page, adding to the confusion.
As mentioned above, one particularly puzzling aspect of Crawlbase's product offerings is that each has its own pricing page, which can either be unique or identical to other products. This redundancy can leave users wondering exactly what they are paying for.
For instance, consider the pricing page shown below. This same layout is used for both the CrawlingAPI and the Crawler pages, despite each product having its own dedicated pricing page.
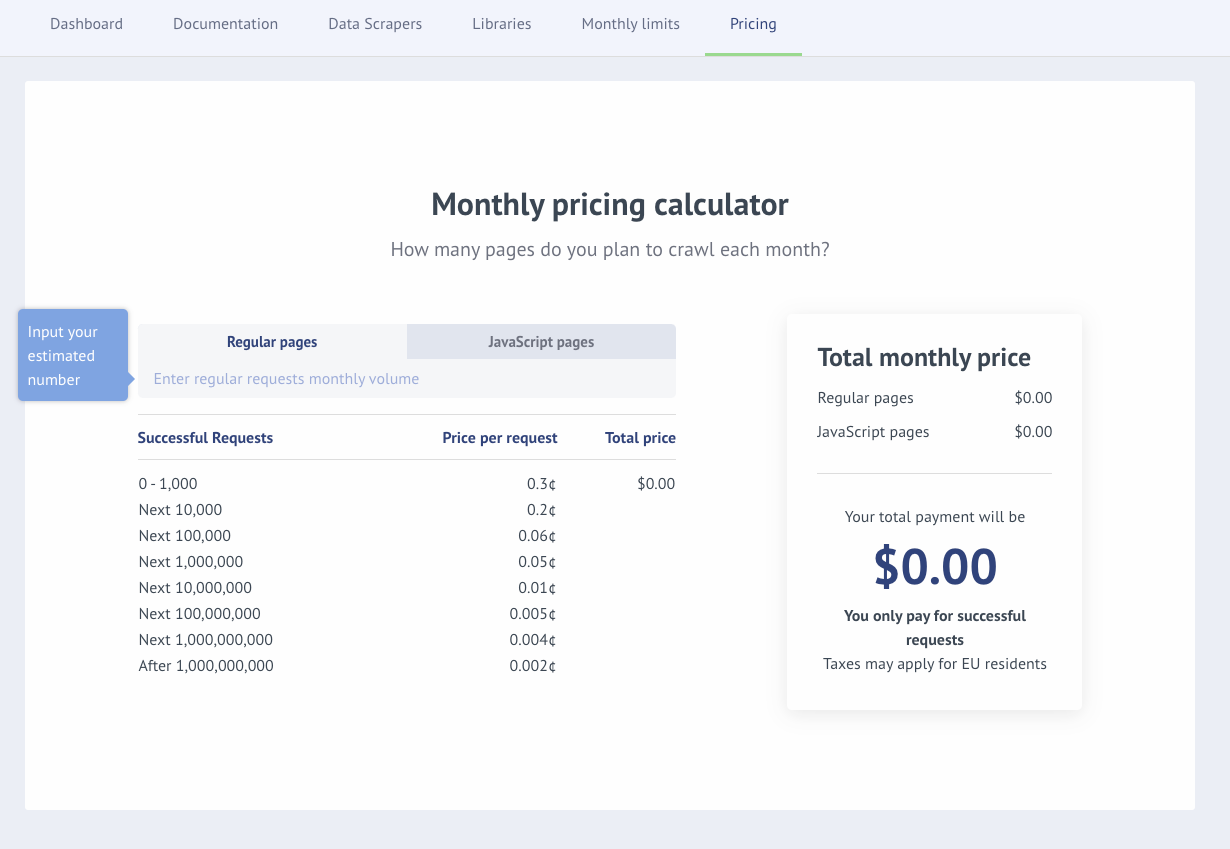
However, when you visit the ScreenshotsAPI page, you come across a completely different pricing structure.
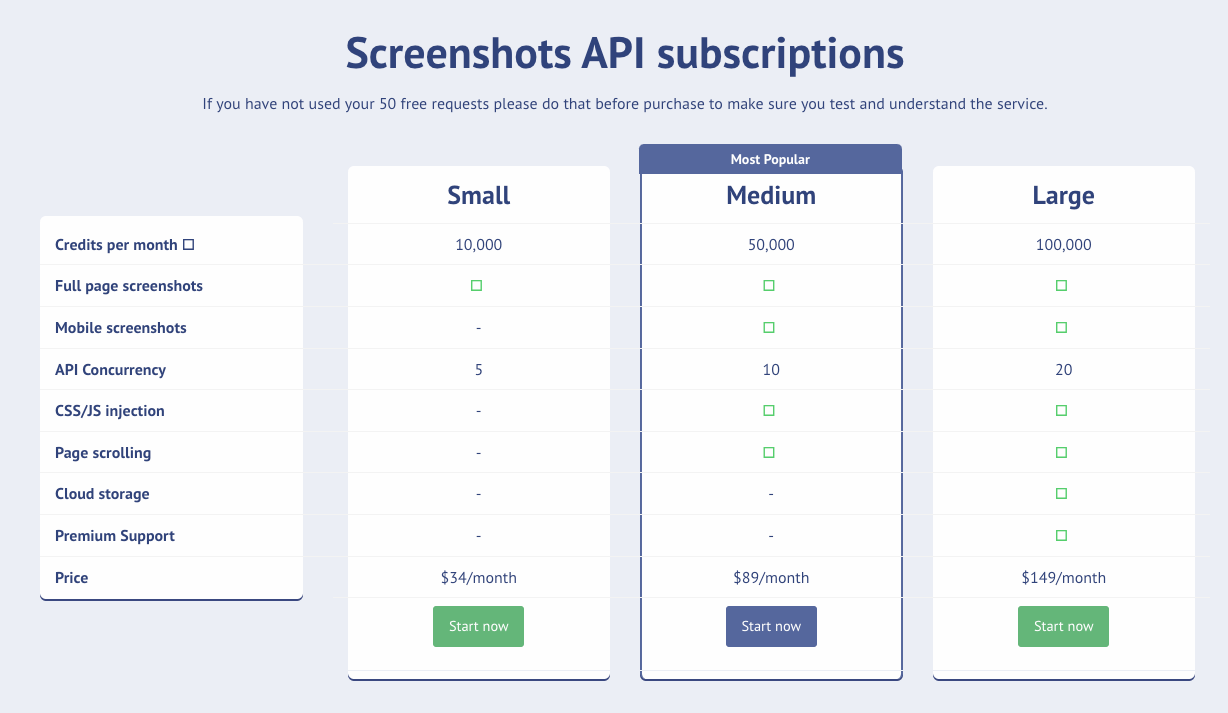
But we are not done because the LeadsAPI follows yet another unique pricing structure, continuing this pattern of inconsistency across all Crawlbase products’ pricing.
In conclusion, I would say from all the three services analyzed, Crawlbase has the most confusing and poorly organized/explained pricing structure to the point I struggle to see any benefits to how they chose to define their pricings.
Apify pricing
Apify's pricing system, though detailed and comprehensive, stands out for its straightforwardness when compared to Zyte and Crawlbase.
Apify's approach is to make all features accessible across all plans, including the free plan. The difference between the packages lies in the amount of platform credits provided and the rates charged for usage at scale.
Additionally, all paid plans feature a 'Pay as you go' option, adding flexibility by allowing users to exceed their plan’s tier limits as needed without requiring an upgrade.
For developers looking to deploy and create their own scrapers, Apify offers a special developer plan that provides $500 worth of credits for just $1 per month, though it does impose some usage restrictions on public Actors (public scrapers not developed by the user).
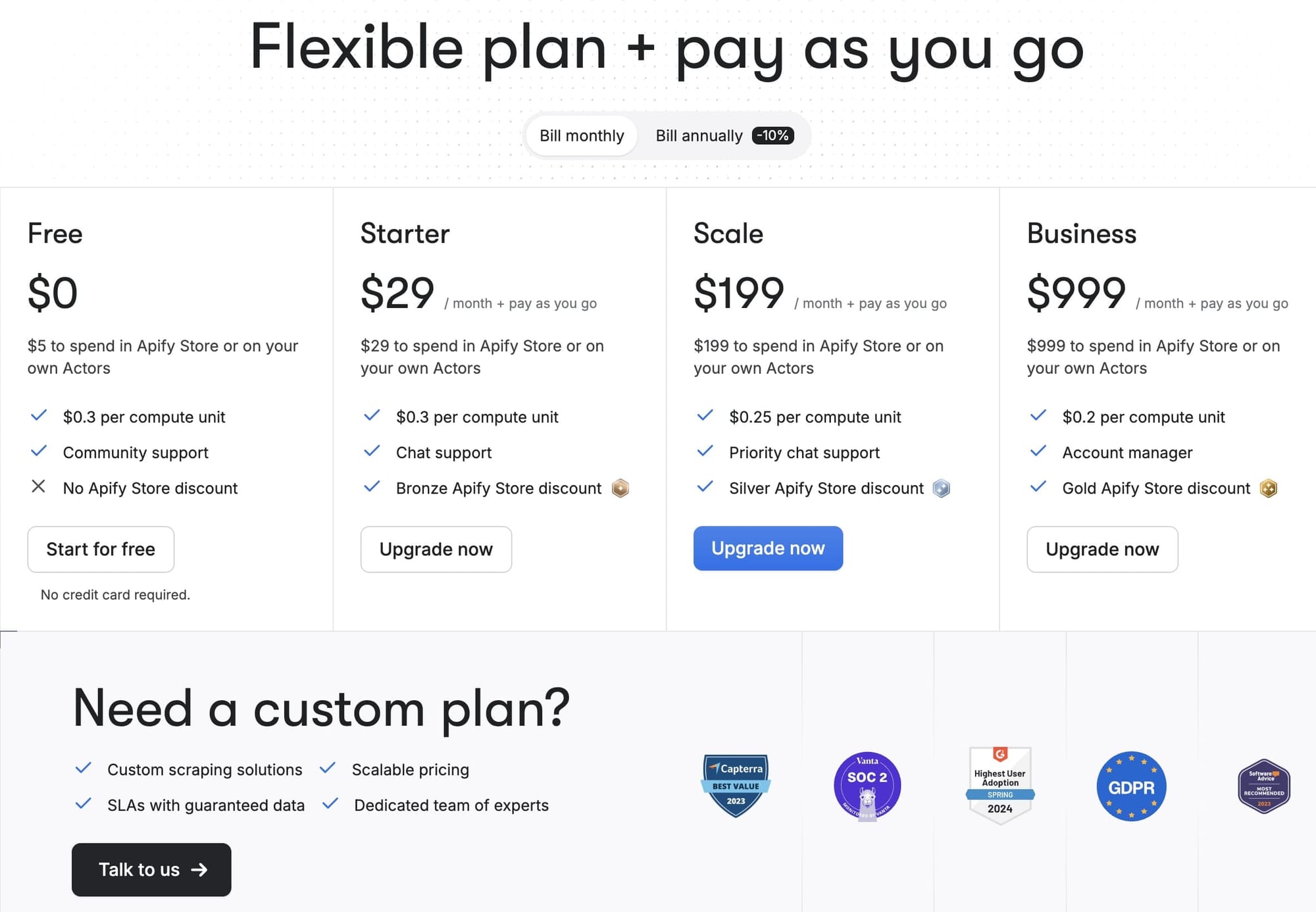
As a cloud-based platform, Apify primarily charges based on usage. Your credits are consumed based on your compute units (CU) usage within the platform, divided into categories like proxy usage, storage, Actors, and data transfer.
Apify vs. Zyte vs. CrawlBase pricing (pros & cons)
| Comparison | Apify pricing | Zyte pricing | CrawlBase pricing |
|---|---|---|---|
| ✅ Pros | • Special plan for developers with generous credit offering • Flexible and straightforward pricing options • Unlimited free plan with no strings attached • Full access to all platform features regardless of your plan tier. |
• The starter plan for some services, like Scrapy Cloud, offers an affordable entry point at $9 per month. | • The individual pricing structure for each product offering can be advantageous if you only require one specific product and prefer not to pay for additional features. |
| ❌ Cons | • Plan packages may include more features than you need, potentially making the service more expensive compared to a granular pricing structure like Zyte’s. | • Features are scattered across various products, making it challenging to predict the total investment required to get your solution fully operational. | • The pricing presentation is quite messy and difficult to grasp. Each product has its own pricing page, which may or may not resemble the pages for other products. This inconsistency makes it challenging to understand exactly what you're paying for and how the pricing packages are structured. |
Conclusion: should you choose Apify, Zyte, or Crawlbase?
To summarize, if your solution is based on Scrapy, consider Zyte or Apify.
Zyte integrates easily with Scrapy and enhances your Spider’s capabilities.
Apify also supports Scrapy Spiders, but its features are more generalized and not specifically tailored to Scrapy, which might limit customizability.
For scraping solutions using libraries or frameworks other than Scrapy, Apify is your best bet. It allows easy deployment of scrapers, cloud execution, and access to all platform features under the free plan, as well as a generous developer plan.
Crawlbase, on the other hand, is the least appealing option here. The platform is disorganized and provides a poor user experience.
While I encountered no issues with its API for extracting data from sites like Amazon and Facebook, the platform itself does not add much value beyond its API capabilities.
The only distinctive feature is cloud storage for scraped data, but even this is overshadowed by the superior user experience and features provided by Apify and Zyte.
If you still want to give Crawlbase a shot, I recommend following the instructions for your language of choice outlined in its GitHub profile first and consulting its documentation only as needed.
Read more reviews
If you want more comparisons like this, check out ScrapingBee review: is it worth it?, ScraperAPI vs. Apify, and Best ScrapingBee alternatives.
Also, check out Apify vs. other web scraping services here.




