


What is Apify?
Since its early days, Apify has been on a mission to empower people to automate mundane tasks on the web and spend their time on things that matter. We accomplish that through web scraping and automation.
The Apify platform provides users with three ways to accomplish their scraping and automation goals:
- Ready-made solutions called Actors, which you can browse for free in Apify Store to find the most suitable one for your use case.
- Custom solutions, where you can request a complete end-to-end solution for all your web scraping, data extraction, and web automation needs.
- Create your own Actors. If you are a developer, you can create solutions from scratch with the help of our open-source tools (such as the powerful Crawlee).
To bring this concept to life, imagine that you want to track the prices of your favorite tasty mozzarella so that you can always get the best deals. Of course, you could manually check the prices daily and waste precious time on that. Or, you could use the Apify platform to create an actor to handle this tedious task and notify you only when a hot sale is on.
Cool, right? But that's just the tip of the iceberg. What about using web scraping and automation to help your business?
Keeping an eye on your competitors' movements is one of the keys to ensuring that your company always has the upper hand in any market. Online businesses are constantly changing strategies, which makes manually tracking competitor movements in this virtual chessboard time-consuming and inefficient.
Using a web scraper to extract data allows you to monitor competitor prices and products, allowing you to adjust your stock and prices accordingly. In other words, it keeps the revenue flowing in the right direction: into your business rather than your competitors'.
Honestly, the possibilities are endless, and you can learn about more advantages that web scraping and automation can bring to your business by checking this article: what are the top 8 advantages of web scraping for e-commerce?
Now that you're familiar with how Apify can save you time and even boost your earnings, we can explore some of the challenges that come with operating those solutions at scale. In this regard, fairly charging users for the data traffic they generate is one of our top concerns, and the first step in ensuring fairness in this process is to monitor traffic efficiently.
Why should traffic be monitored?
Watch Matej Hamas (Software Engineer at Apify) presentation about Traffic Monitoring in Apify at STRV's Node.js meetup - from 1:55 to 27:00
Accurately monitoring traffic is one of the central challenges we face while maintaining fair billing for both Apify and the user.
Throughout the years, we've experimented with many solutions that had limitations and faced exploits that became increasingly more apparent as the scope and scale of our services grew.
That's why we think it is worth briefly exploring the history of traffic monitoring at Apify and sharing some of the lessons we have learned from our experience.
Pay per crawled page
At the very beginning, we concentrated on the crawling use case of our platform and charging users based on this functionality. The user would pay a pre-established fee for every page visited by the actor, which is a very straightforward approach from a billing point of view.
However, this simplicity comes at the cost of it being limited. For example, this method didn't allow us to properly charge users with use cases other than scraping (e.g. automation). Therefore, to better align our billing structure to the services provided, we started charging per compute unit.
Pay per unit of computation
In this new approach, the user would pay for the actor's running time. Despite being a more general approach and encompassing different use cases, it does come with a catch.
Consider a situation where the platform is used to download videos or torrents. This action would result in low computational consumption but high internet traffic, which means Apify would have to pay thousands of dollars in AWS (Amazon Web Services) fees. At the same time, the user's bill would be relatively cheap.
This raises two big problems:
- It creates a loophole in the system, which allows users to abuse the platform, resulting in serious financial drawbacks to the provider.
- It creates an unfair billing system, where users who engage in demanding computational activities pay considerably more than users who download large files and generate heavy internet traffic.
Concerned about these problems, we once again decided to change the billing structure to fairly charge users based on the resources they consume: compute units, traffic, and storage.
To better explain our current solution to monitoring traffic, we will use a little help from our partner app, Truebill, a fintech startup that helps users keep track of the services they are subscribed to. More than that, Truebill also allows users to unsubscribe from any of those services with the simple touch of a button. And that's where Apify comes in.
Using Truebill as our case study, let's now explore Apify's role in unsubscribing users from services they no longer need and find out why traffic monitoring is relevant to this process.
Handling unsubscription workflows: Truebill use case

Due to the significant increase of different subscription-based services for music, movies, and video or mobile game business models in the past few years, consumers started to face a new problem: "how to keep track of all my subscriptions?". Additionally, unsubscribing from each one of these services can be a very stressful and tedious process. As mentioned before, our partner Truebill heard your pleas and came to the rescue with an easy solution to this problem. And guess who is behind the curtains ensuring that everything is running smoothly? That's right, Apify.
Apify handles all the backend processes related to the unsubscription workflows. However, automatically unsubscribing from services on behalf of a user is not a simple task. Many challenges are associated with creating a functional workflow that can also avoid being blocked by the services.
Challenge 1 - services don't want you to unsubscribe
The first challenge is obvious: services don't want to lose customers. This means that there is no API allowing users to simply hit an endpoint and unsubscribe.
As a solution to this problem, Apify created a custom actor that emulates a real user's behavior in a virtual browser. The goal of this actor is to be able to navigate through all the steps of the unsubscription workflow without being detected as a bot.
To better understand how this process works behind the scenes, we will use a diagram:
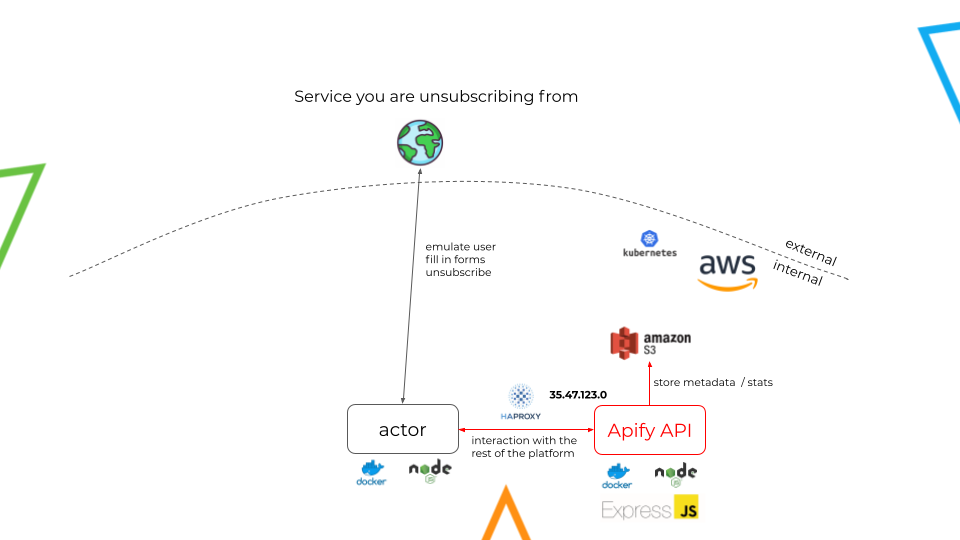
Interacting between worlds
From the diagram, it is possible to identify the dashed line establishing the boundary between the external and internal worlds. On the external side lives the public Internet (the Earth), where the service we are unsubscribing from is located. Then, on the internal side, we have Apify's cloud ecosystem running on AWS, where our actor, based on Node.js, is located.
The unsubscription flow happens in the following way:
- The actor runs and emulates the user to contact the external environment, filling in the unsubscription forms and returning with responses (metadata).
- The actor contacts Apify's API server with the help of a library called HAPROXY, which establishes the internal routing, allowing the actor to hit the IP address of the API server without leaving the internal environment.
- Finally, the API server connects with Amazon S3 and stores the metadata obtained by the actor.
By following these steps, the actor can then unsubscribe from the service. Simple, isn't it? Well, not so fast…
Challenge 2 - how services identify and block bots
When trying to unsubscribe from a service with the help of a bot, there are two main challenges to overcome: geolocation and fingerprinting.
Geolocation
Imagine you are using a service in the United States, and then, suddenly, your actor tries to run the unsubscription flow from multiple different locations around the globe. Suspicious, right? Definitely, and your service provider thinks the same way.
Fingerprinting
On top of your location, services are also constantly collecting data about your behavior on the website: Which browser do you use? What headers? How fast are the responses? What do you click?
All these factors are relevant when setting humans and bots apart.
As you can see, they really don't want you to unsubscribe, and all the metadata collected will be used to try to block bots from operating. But fear not, that's nothing Apify can't handle.
Solution - disguise the bot as a human: use proxies!
Why use a proxy? In short, a proxy acts as a middleman between the user and the internet. In other words, instead of contacting websites directly, you have the proxy do it on your behalf.
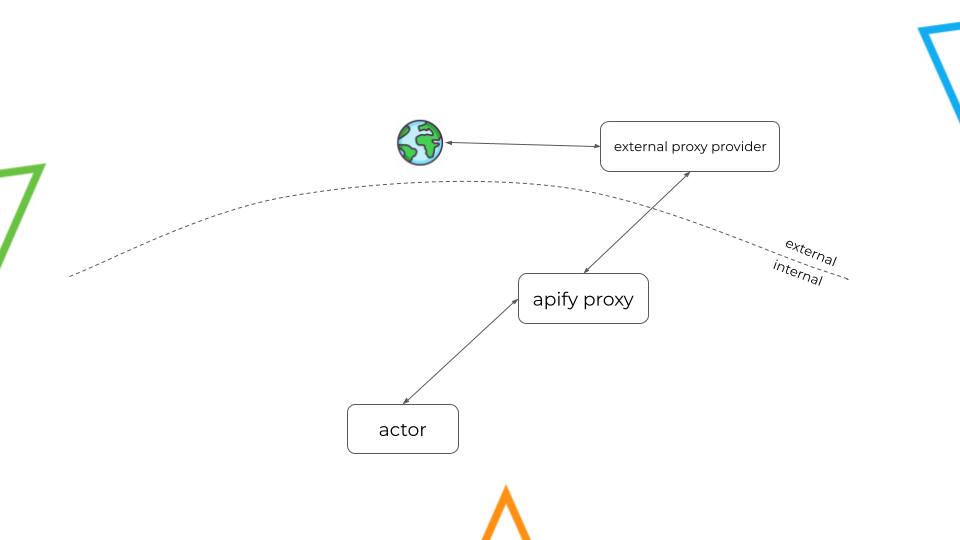
In our case, the proxy will contact the service we want to unsubscribe from on behalf of our actor. Its goal is to outsmart the geolocation and fingerprinting systems of the service provider by emulating the behavior of a real user.
To accomplish this, Apify uses its own proxy which boasts features specifically designed to disguise bots as real users.
Curious about how we do this? Check Apify Proxy for a full breakdown of our proxy's features.
Challenge 3 - unsubscribing needs to be fast!
Put yourself in the user's shoes. When you hit "Unsubscribe" you would expect instant feedback, right?
Well, staring at your screen for a few seconds until the API server connects, then starting the job actor and loading the virtual browser so it can finally process your request, is not exactly an engaging experience. But don't worry, we don't let the users go through this dreadful experience, as it is possible to speed up this lengthy process.
Solution - have the actors on standby 24/7
As mentioned before, the most time-consuming part of the process is to set up the ecosystem around the actor after receiving a request from the user. This means that if the actors are already up and running, the request is immediately processed upon arrival to the actor.

To enable this functionality, Apify built a service called "Conductor", which receives the user's request and then forwards it to the actors running non-stop.
This workflow mediated by the Conductor (left-hand side) considerably decreases the required time for the user to receive feedback compared to the traditional one (right-hand side).
A closer look at Conductor's traffic routing
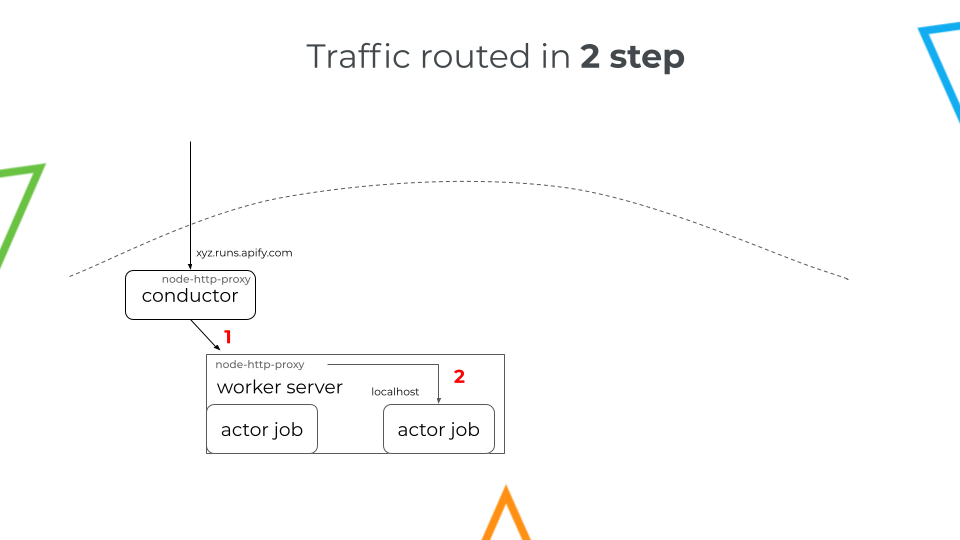
Traffic is routed in two steps:
- Conductor first routes traffic to the "Worker Server", which is running using the open-source library, node-http-proxy.
- Once inside the Worker Server, the traffic is routed to the relevant actor job.
At this point, we have addressed most of the challenges associated with building functional unsubscription workflows. So, let's do a quick recap of all of them and their respective solutions.
Summary of challenges and solutions
- Challenge 1 - There is no simple API to handle unsubscription
- Solution: Use a custom Apify actor running non-stop
- Challenge 2 - Unsubscription needs to be fast
- Solution: Connect and route traffic via Conductor
- Challenge 3 - Services will try to block the actors from running
- Solution: Use a proxy to emulate natural user behavior.
Traffic monitoring in the unsubscription workflow
In the previous sections, we took our time to explore how all the steps in an unsubscription workflow interact.
Now, we will look at the whole picture and understand how to properly monitor data traffic in this system.
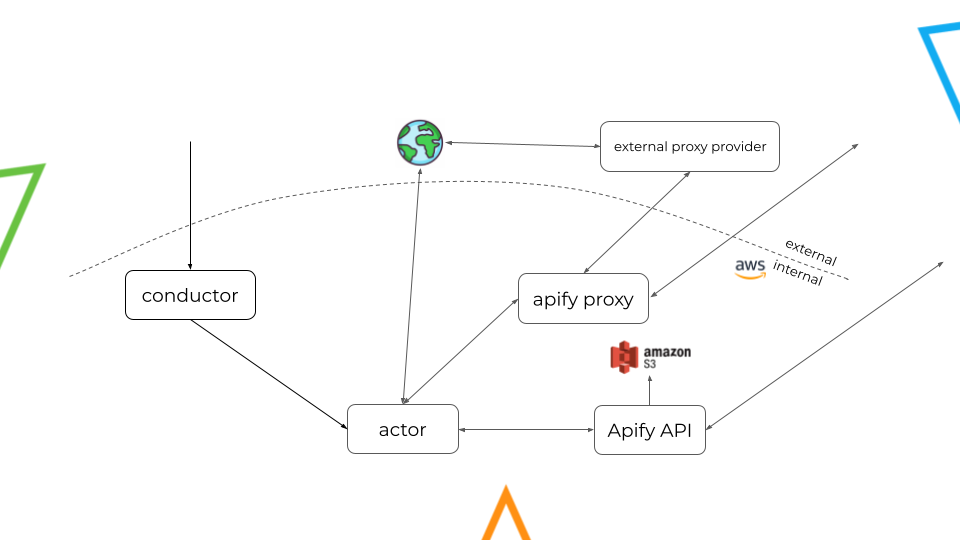
I bet that the first thought that came to your mind after looking at this diagram was: "There are so many arrows!"
I'm glad that you noticed because these arrows are precisely what we need to monitor in this situation. Each of these arrows represents the flow of data, and since AWS costs are based on data traffic, it is crucial that we identify each of these arrows.
 Marek Trunkát
Marek Trunkát
Understanding AWS pricing
When it comes to determining the price to be paid to AWS, there are a few parameters we should watch for:
Is the data coming In or out of the AWS server?
Relevance: Incoming data is not charged by AWS, but outgoing data is.
Where is the traffic going to, the internet or AWS, and to which region?
Relevance: The cost of traffic depends on whether it is moving outside AWS (to the Internet) or inside it. Also, traffic moving to different regions around the globe is priced differently.
Attribute data traffic to the right user
Relevance: To fairly charge users for the data traffic they generate, it is fundamental that we can correctly identify the users.
Desired statistics
Based on the factors influencing AWS costs, we can now know the information we need to flush to the database.

After that, there are three final challenges to be solved:
- Where is the user?
- Where do we measure traffic?
- Measure traffic persistently and in real-time.
Where is the user?
Based on the user IP and AWS IP range, it is possible to identify whether the user is connecting from the outside Internet or another AWS account.
Fetching AWS IP range
The first step in identifying the user's location is to access the AWS IP ranges. Luckily, all the AWS IPs are publicly available at this URL.

From the available data, we are particularly interested in the region and its associated prefix.
Convert the IP to binary

Following the example above, when written in binary, the IP address will display a 22-bit prefix (IP/bit), the IP range we are looking for. This means that the range will remain the same regardless of what is written after it (illustrated by the 'xs).
Build a prefix tree in binary

With the data collected from Amazon, we created an algorithm to match the AWS IP ranges (110, 111, and 10). This enables us to discern between users connecting from within AWS and users connecting from the Internet.
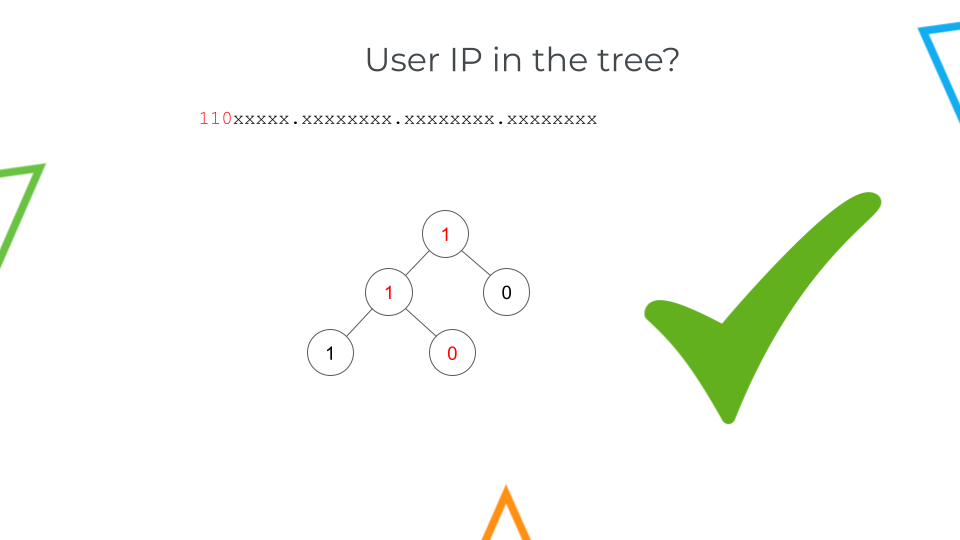
To exemplify it, if the IP starts with "110", it will be recognized as part of the tree, and we will be able to identify the region from which the user is connecting.
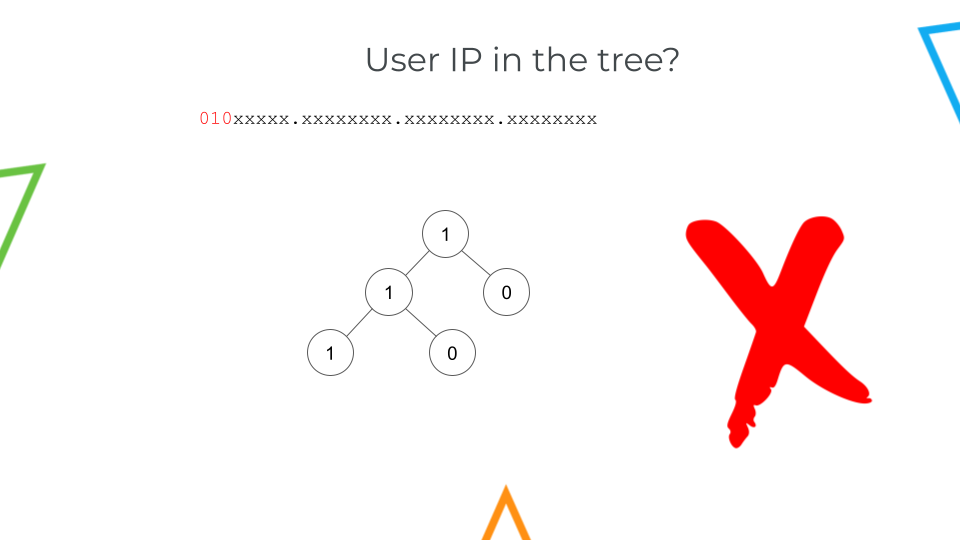
On the other hand, if the IP starts with "010", it will not be part of the tree and, thus, we will know that this user is connecting from the public Internet.
Great! So, with the help of the binary tree algorithm, we can find out where the user is, which leads us to the next challenge.
Where to measure traffic?
Back in the day, Apify only measured the traffic at the job actor. However, as other components were added to the process, such as Apify Proxy, Apify API, and Conductor, a more thorough approach was required.
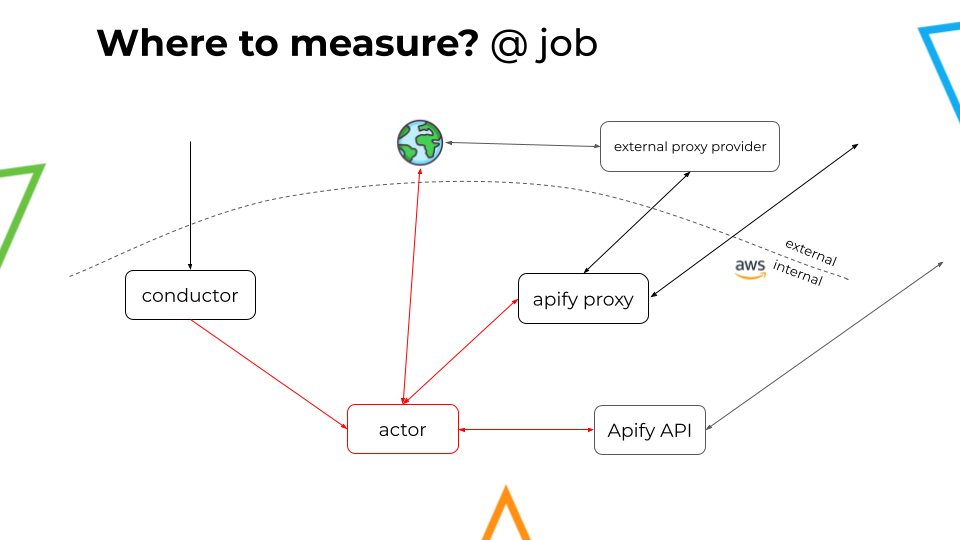
To achieve the appropriate traffic monitoring method, we now had to consider the traffic at the following points: @job, @proxy, @conductor, @API server. Additionally, we need to discard any eventual "double counting" that might occur when evaluating all these points together.
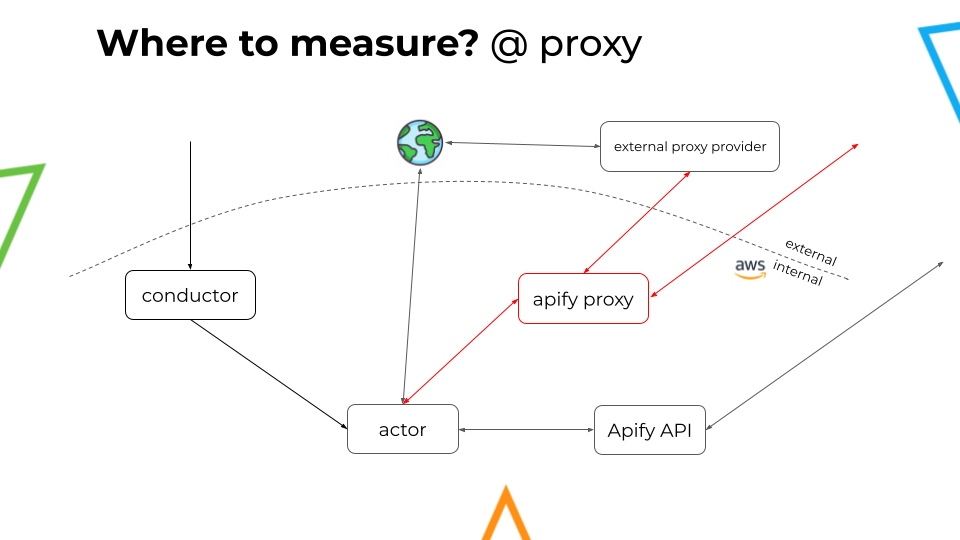
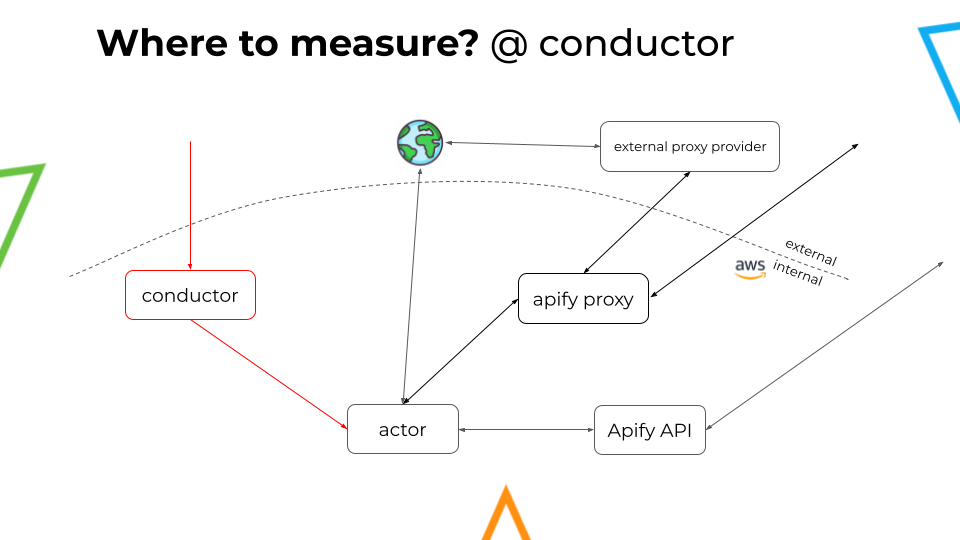

Measuring external traffic
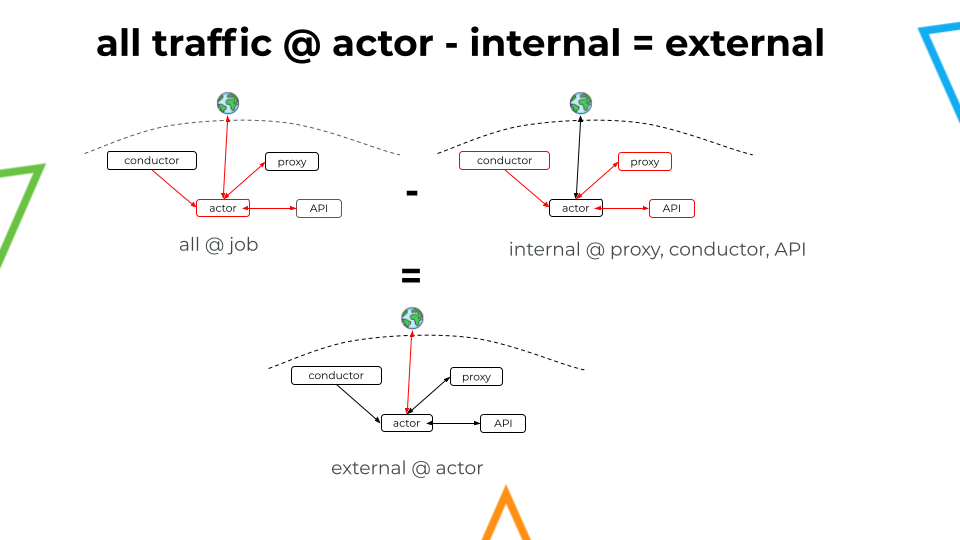
Finally, by subtracting the internal traffic (at the proxy, Conductor, and API) from all the traffic at the actor, we can avoid double counting and accurately measure the external traffic going from the actor to the public Internet.
Measure traffic persistently and in real-time
Our final challenge is to use all the collected data to measure the traffic. First, we need to ensure traffic is being measured in real-time so we have a clear picture of what is happening in the system. Additionally, the measuring needs to be persistent, which means that it should be consistent even in the face of system failures.
In practice, this happens in a two-step process:
- Buffering updates in the memory
- Regularly flushing data to the database
Buffering updates in memory

The code sample above is a simplified version of Apify's actual codebase. In this scenario, we listen to the Node.js events on the sockets and, when an event happens, we get the bytes read, and bytes written from the socket and update the statistics in the memory.
How do we know which user is generating this traffic?

Once again, attributing generated traffic to the correct user is one of our top priorities. In this case, the vast majority of the requests are authenticated, making it easy for us to identify users by their "userId"
Confusing bytes read & written can compromise our data

When a request comes to the proxy, it generates two pieces of traffic. There is traffic on both the internal and external sides, and the bytes read and written swap positions between sides. If we don't account for this swap, it will compromise the quality of the data obtained.
Yes, we know that this can be a confusing part of measuring traffic. But, the bottom line is that by recognizing this odd occurrence, we were able to adapt our system to ensure the integrity of the data obtained.
Regularly flushing data to the database

Finally, once we have obtained all the necessary data comes the easy part: flushing data to the database. To do that, we use MongoDB and update the database every 5-10 seconds to ensure that we don't lose any data.
Final thoughts - the evolution of traffic monitoring at Apify
As Apify grew and matured, we experimented with different traffic monitoring methods. We went from a simple system that charged users by crawled page to one where we can accurately map traffic to AWS costs and charge users accordingly.
Despite all the modifications and improvements we have made throughout the years, our central goal remained the same: providing the best possible service while ensuring customers are billed fairly for the resources they use.
On this note, nothing excites us more than empowering businesses like Truebill to bring their vision to reality through Apify's platform. Whether you need data for automation, product analysis, or market research, Apify got you covered.
Don't forget to check our ready-made and custom web scraping solutions so that you can easily extract data from any site. And if any of those options are not enough to bring your vision to life, don't hesitate to contact us and see how Apify can provide a custom solution for your business.
Finally, Apify will continue on its mission to make the web more programmable, and you can count on us to do it with transparency and efficiency.




