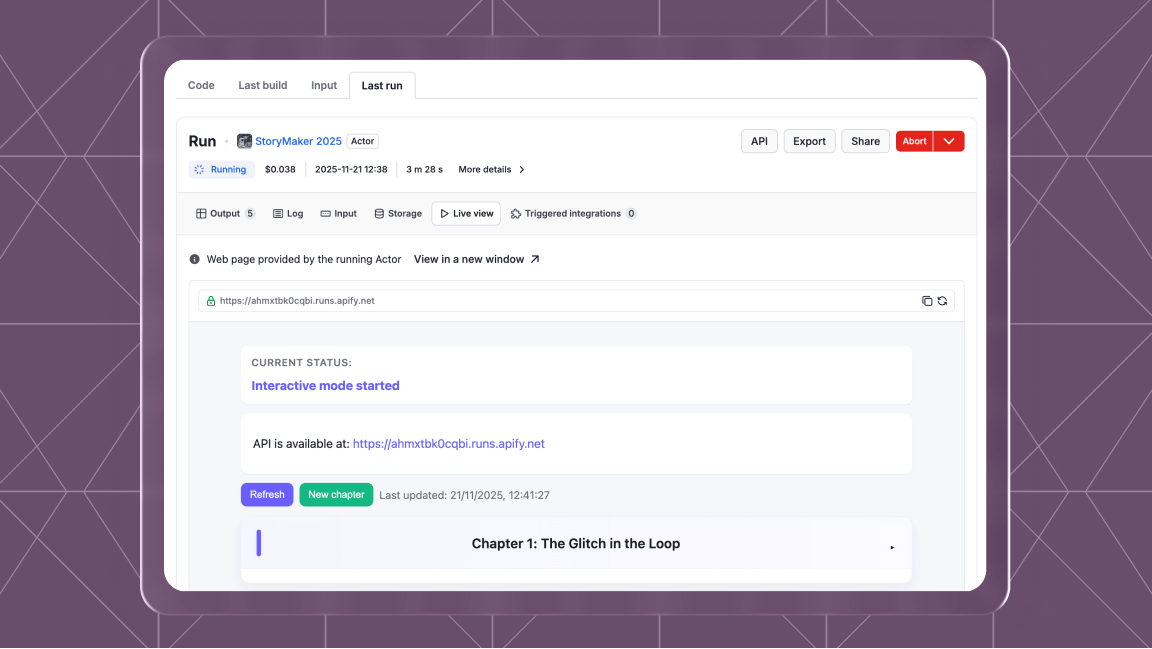
Case studies Developer community ParseForge's Actor Factory: From 1 to 1,000 Actors Daniel Lee Feb 12, 2026
AI agents Developer community MCP Introducing mcpc: A universal CLI client for MCP Jan Čurn Jan 28, 2026
Tool comparisons APIs and integrations Developer community SerpApi vs. Apify: Choose the best web scraping platform Antonello Zanini Jan 14, 2026
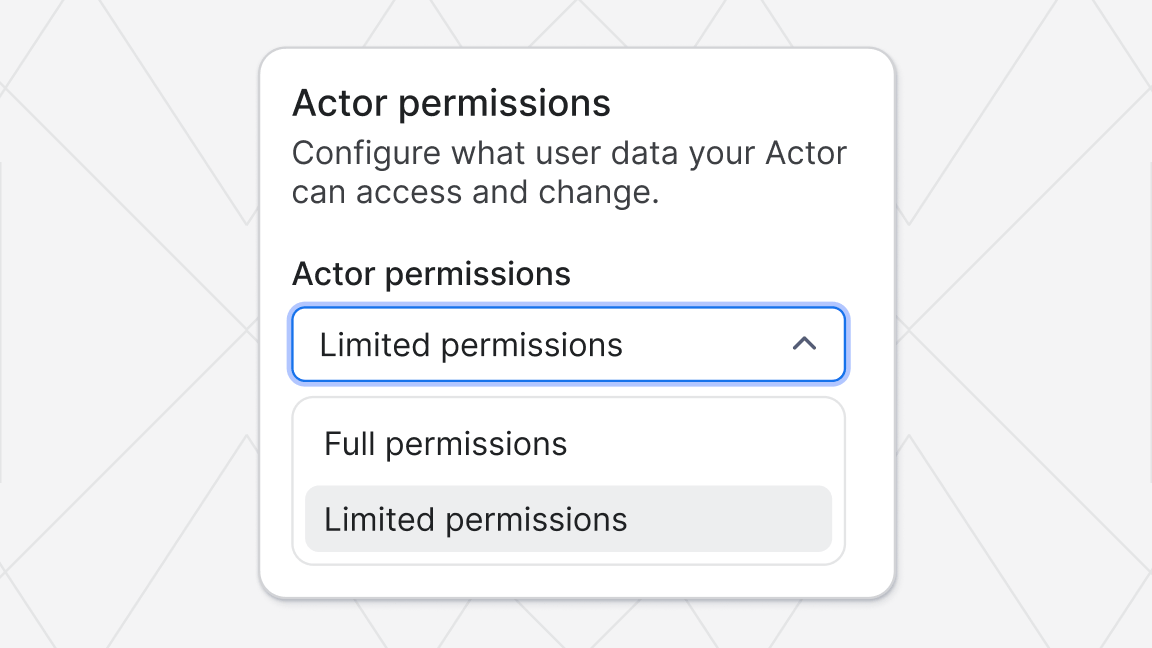
Apify updates Developer community Introducing Actor permissions: greater transparency and control for users and developers Nishad Manerikar Nov 20, 2025
APIs and integrations Tutorial Developer community How to monetize your API (and get new users) Antonello Zanini Nov 4, 2025
Developer community MCP Presenting the winners of the Apify MCP server configurator competition Fergus O'Sullivan Oct 17, 2025
Apify updates Developer community SDKs and runtimes Announcing Apify CLI v1 Patrik Braborec Aug 15, 2025
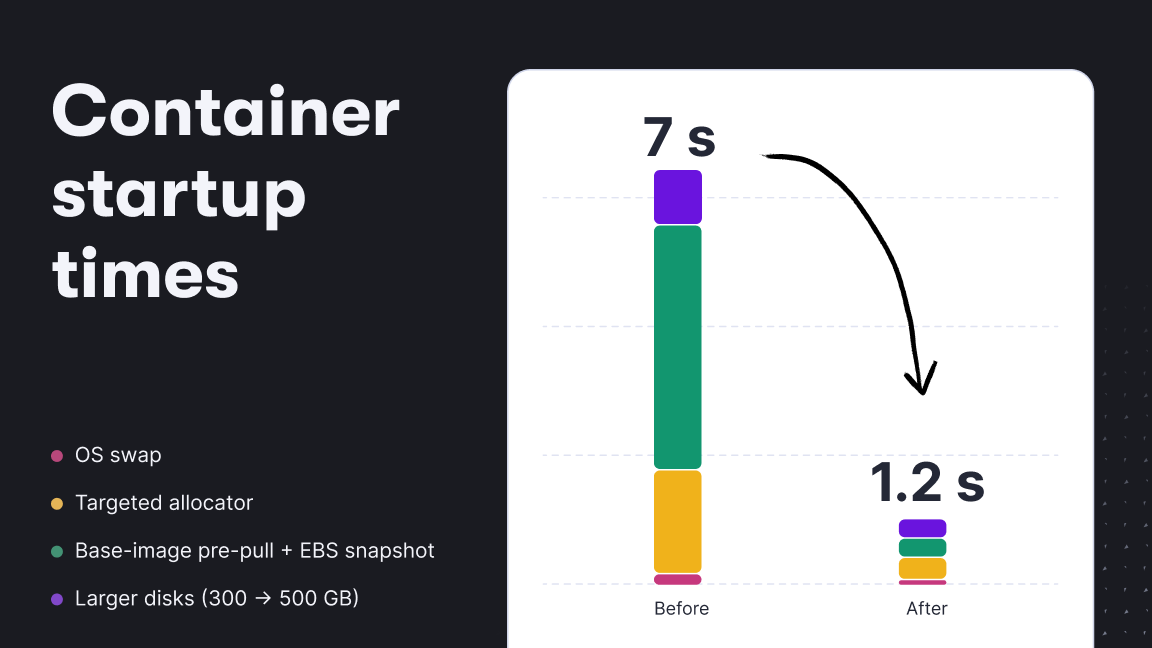
Apify updates Developer community How Apify slashed container startup times by 500% Jiří Moravčík Jun 23, 2025