


Introduction
Web scraping is part of the alternative data market, which was worth $4.9 billion in 2023 and is set to grow at an impressive 28% annual rate through 2032. The web scraping software market alone hit $1.01 billion in 2024 and is projected to more than double to $2.49 billion by 2032.
As these markets grow, so does the need for reliable and scalable web scraping solutions. By digging into our internal metrics and layering that with broader market data, we’ve uncovered some notable trends and insights about where web scraping is headed in 2025.
How we approached this (our methodology)
We used three data sources to paint a clear picture of the state of web scraping: our platform data from 2023–2024, a survey of developers, and external industry research.
1. Platform data
We looked at key metrics like API calls, scheduled runs, and Actor* builds to understand how developers are working with automated tools. The numbers show a growing focus on automation and real-time data collection. For instance, Actor runs started via API and scheduling functions have seen notable increases, signaling that scalability and efficiency are top priorities across industries.
2. Developer survey
In December 2024, we ran a survey targeting developers and web scraping professionals. It gave us a clearer view of the challenges they’re facing, what tools they prefer, and the trends shaping their work. This feedback helped validate the patterns we saw in our platform data.
3. External research
To round things out, we added insights from industry reports and public studies. This let us zoom out and see how Apify-specific trends align with the wider web scraping industry. We also explored how emerging technologies and market demands are shaping the future.
Limitations
No methodology is perfect, and ours has a few limits:
- Even though we shared and promoted the survey externally, we’re aware that the subset of developers in Apify’s reach may not fully represent the diversity of the developer community.
- Our internal data is specific to Apify’s platform, meaning it doesn’t capture the entire market’s activity.
Even with these caveats, combining internal, survey, and external data gives us a well-rounded view of where web scraping is going - and how developers can prepare for what’s next.
Market overview
Industry demands
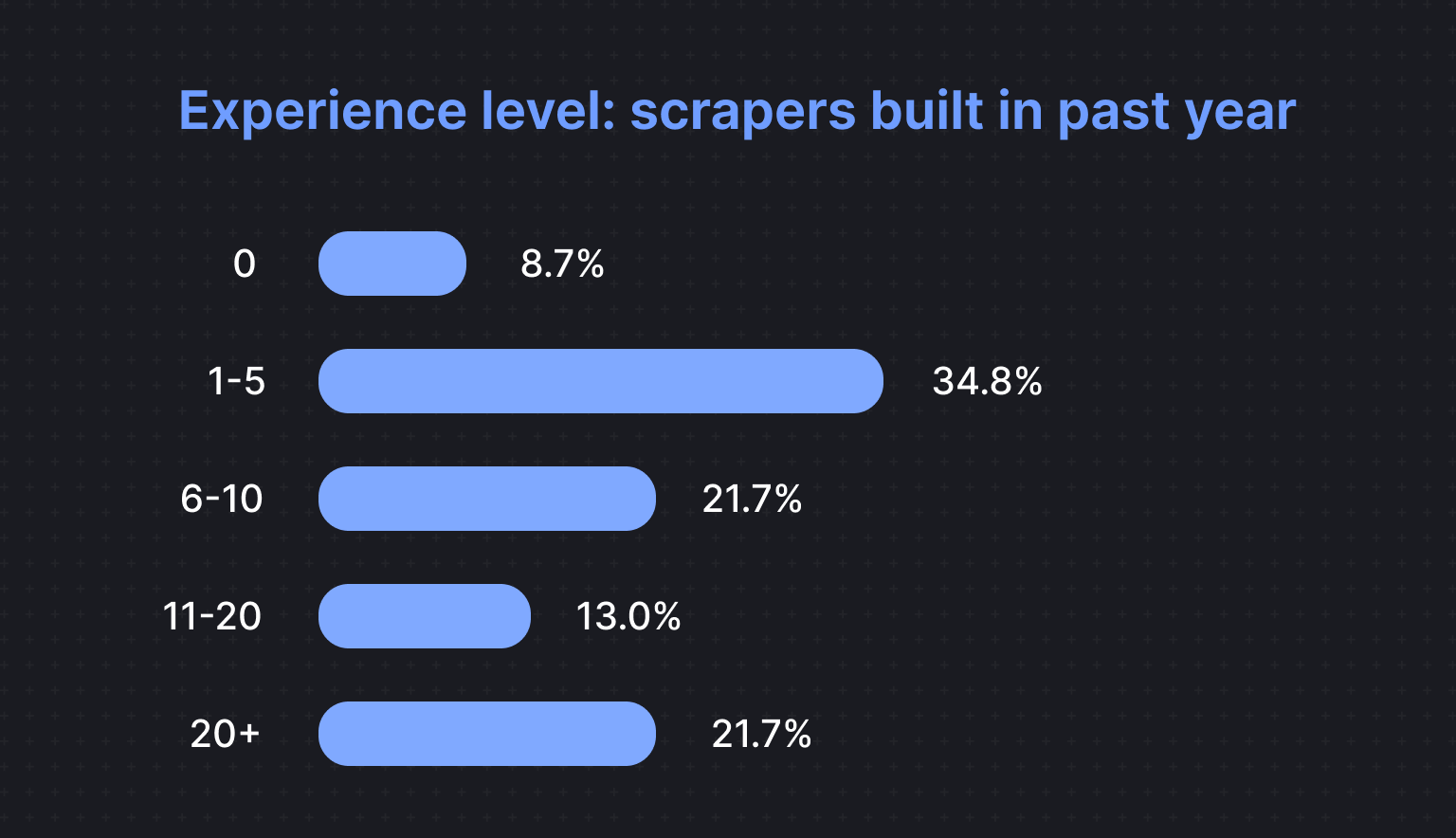
Our survey data gives a snapshot of how developers approach web scraping -everything from big, ongoing projects to smaller, more occasional tasks. About 21.7% of respondents built over 20 scrapers last year, making up the most active group of developers who clearly see scraping as central to their workflows. Another 13% created 11–20 scrapers, while 21.7% built 6–10. On the flip side, 34.8% built fewer than five scrapers, suggesting that many either use scraping sparingly or stick to targeted, smaller-scale projects.
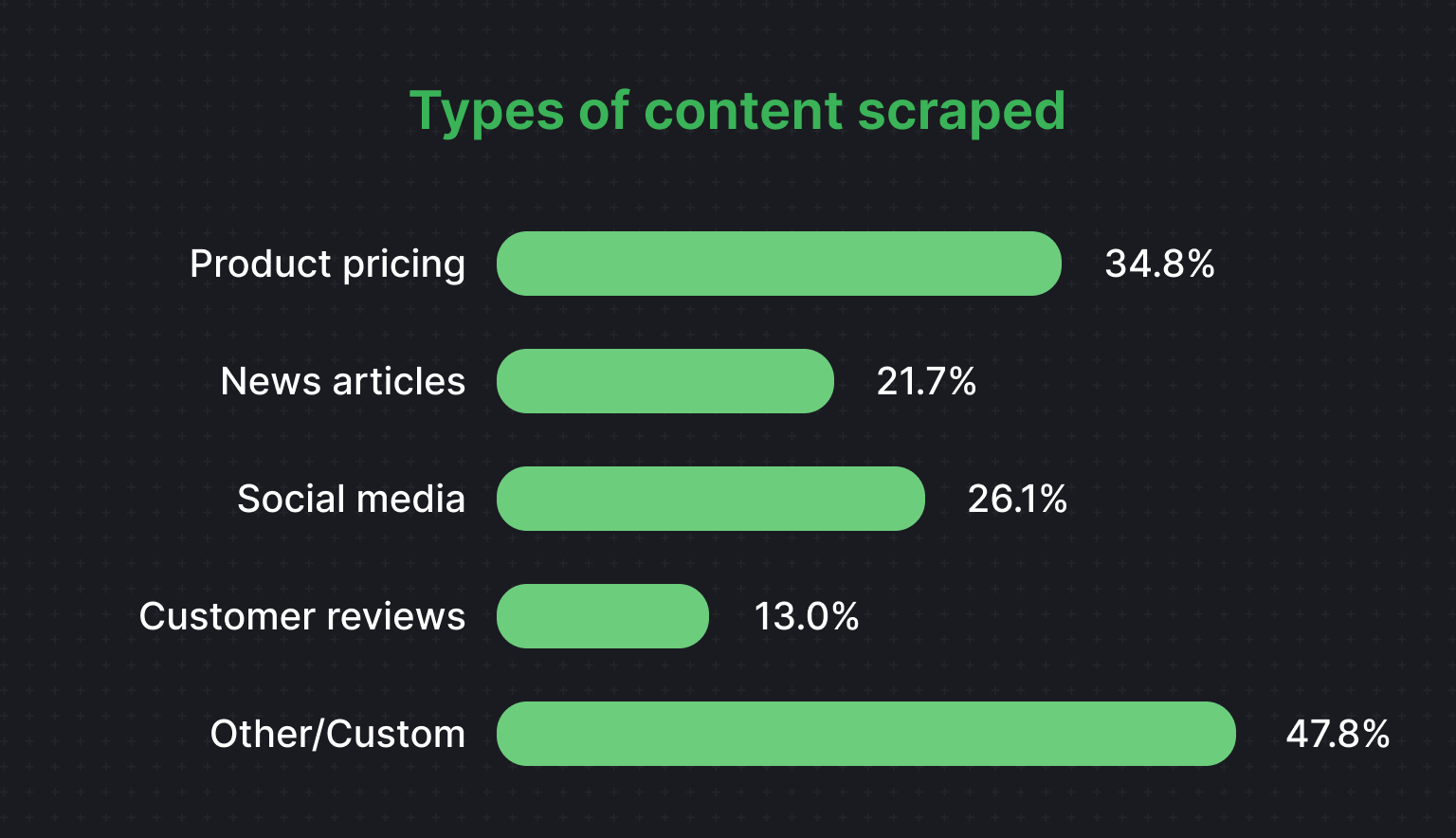
When it comes to what’s being scraped, the top targets are product pricing (34.8%), social media content (26.1%), news articles (21.7%), and customer reviews (13%). This suggests that developers are leaning heavily into scraping for trend and sentiment analysis and market insights.
External research backs up what we’re seeing. Industries like e-commerce, marketing, and real estate are leading the way in adopting web scraping tech, using it for everything from pricing optimization to tracking social sentiment. Let’s look at how some key sectors are using scraping in real-world scenarios.
- Ad tech
With third-party cookies on the decline and regulations ramping up, ad tech companies are leaning on web scraping to track competitor pricing, ad placements, and audience preferences in real time. This data powers targeted campaigns and helps detect ad fraud. (Sources: Adroit Market Research, Aloa)
- E-commerce
Big retailers like John Lewis use scraping to monitor competitor pricing, reportedly boosting sales by 4% through smarter pricing decisions. ASOS, on the other hand, uses geo-targeted scraping to tweak campaigns for specific regions, doubling its international sales. (Source: Marketing Scoop)
- Research
Market analysts and academics rely on scraping to gather large datasets for insights into consumer trends, market dynamics, and social behavior. This is especially valuable for niche industries where traditional data sources are limited. (Source: Adroit Market Research)
- Real estate
Real estate firms use scraping to pull property prices, rental trends, and neighborhood stats from platforms like Zillow, Realtor, and Trulia to help them stay ahead in a competitive market. (Source: PromptCloud)
Growth trends
Actor runs and automation
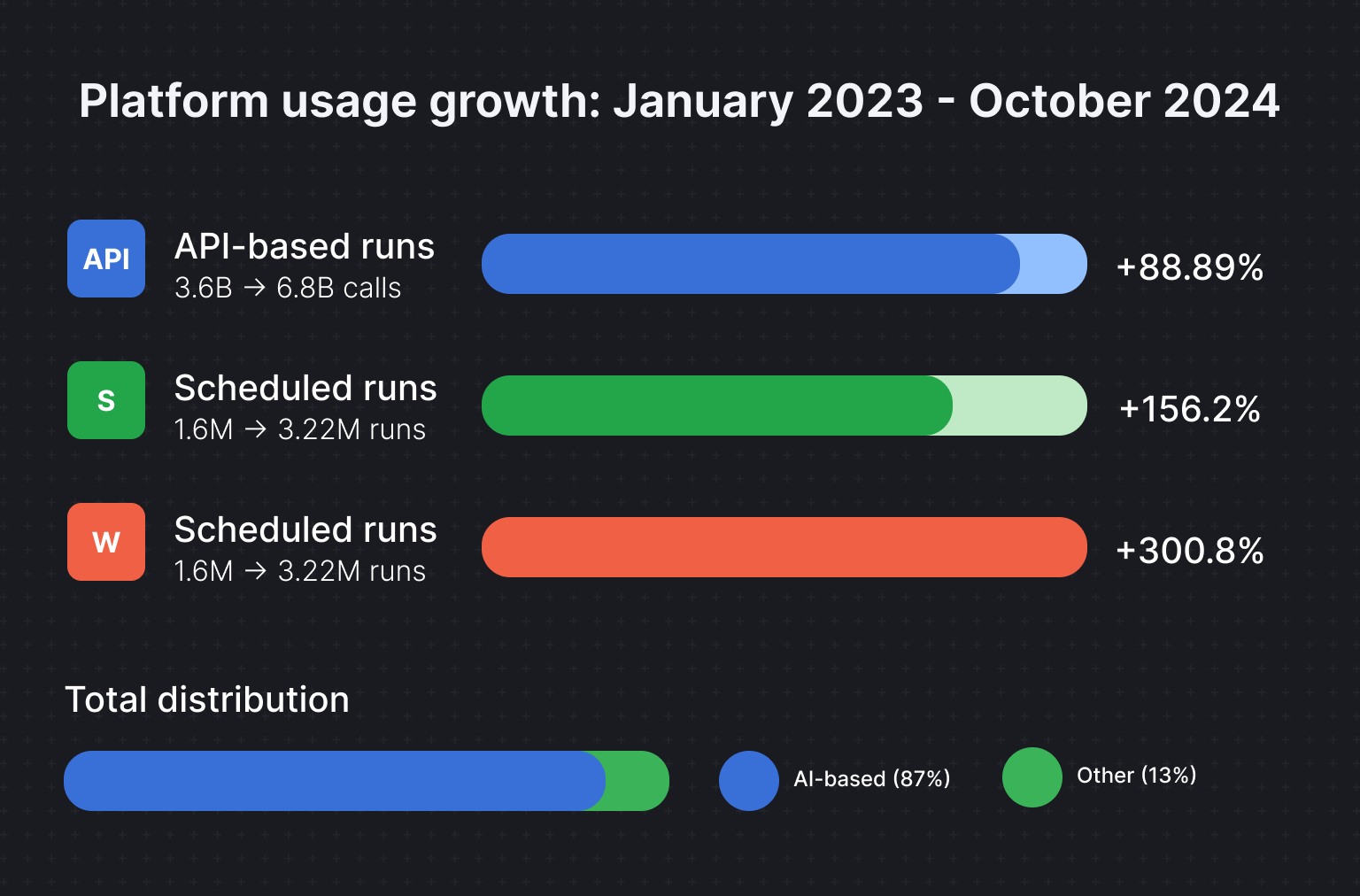
Apify’s growth offers a microscopic view of the increasing adoption of web scraping among enterprises and small businesses alike. Monthly active users rose from 20,843 in January 2024 to 50,543 by October, a growth of 142.49%. Meanwhile, Actor runs more than doubled since 2023, reaching 37 million by October 2024.
API-based Actor runs accounted for 87% of the total, with API calls increasing from 3.6 billion in January 2023 to 6.8 billion by October 2024 (an 88.89% increase). Scheduled Actor runs climbed from 1,256,973 in January 2023 to 3,221,685 in October 2024, reflecting a growth of 156.2%. Similarly, web runs surged from 73,378 to 294,100, a growth of 300.80%.
This trend signals a growing demand for automated workflows and real-time data processing.
Open source and cloud adoption
The growth of proprietary solutions like Apify complements a sustained reliance on open-source tools. Developers increasingly combine commercial platforms with open-source solutions to achieve flexibility and scalability.
This hybrid approach isn’t exclusive to web scraping. Tech giants like Meta leverage open-source projects such as React and Llama to balance community-driven innovation with enterprise reliability.
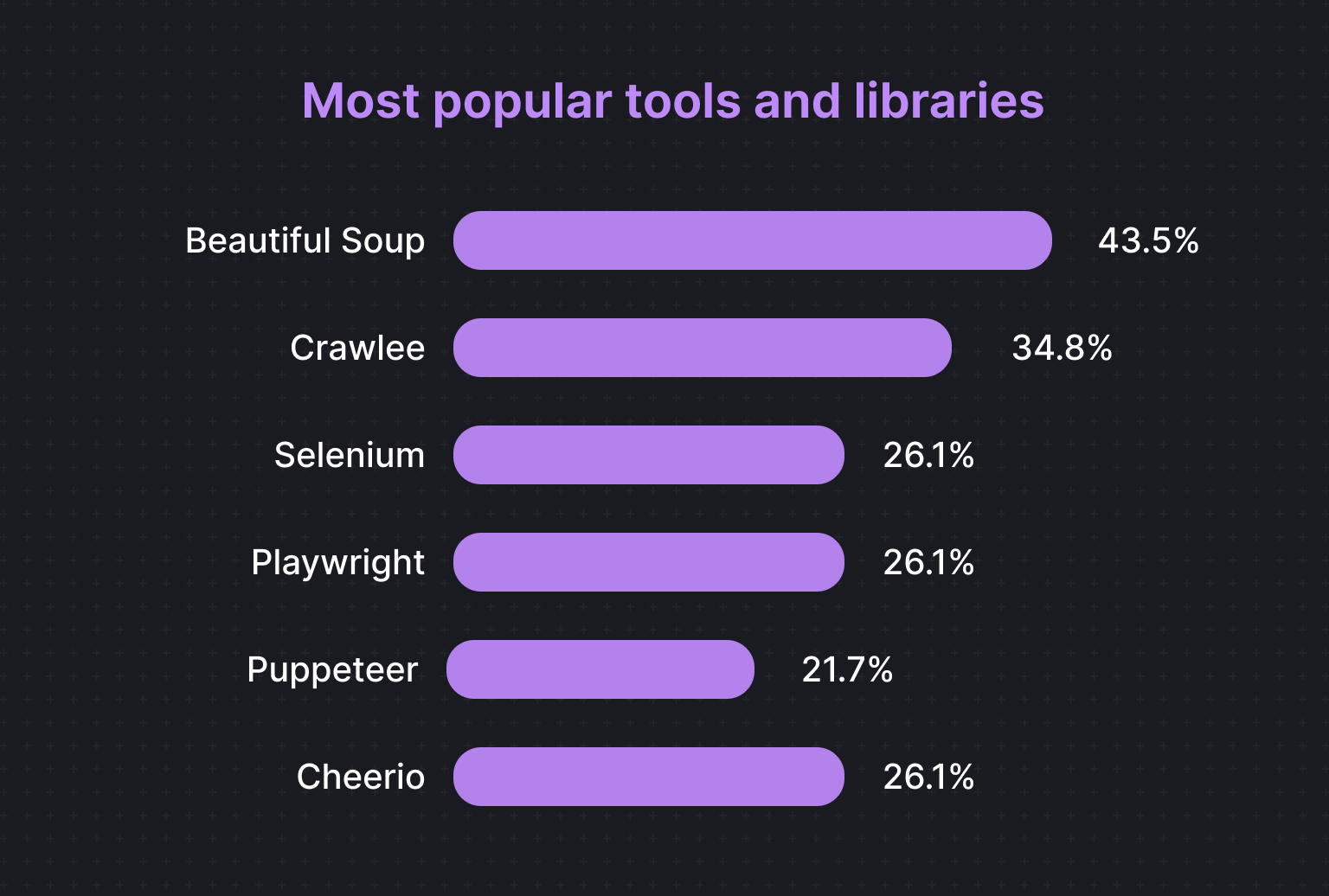
According to the developers we surveyed, the most popular open-source tools for web scraping are BeautifulSoup (43.5%), Crawlee (34.8%), Selenium (26.1%), Playwright (26.1%), Cheerio (26.1%), Puppeteer (21.7%), and Scrapy (13%).
This also corresponds with the most popular choice of programming languages for web data extraction. Python leads with 69.6% (BeautifulSoup, Crawlee, Selenium, Playwright, Scrapy), followed by JavaScript at 34.8% (Crawlee, Cheerio, Puppeteer, Playwright, Selenium).

However, despite the popularity of open-source libraries, integration challenges persist. Deploying a production-grade open-source crawler requires scalable compute to run headless browsers, global proxy servers, persistent storage, unblocking capabilities, observability, and, of course, integrations into various data pipelines.
Cloud platforms like AWS, Azure, and Google Cloud have eased some of these barriers, with 70% of open-source services relying on cloud deployments. (Source: CloudZero). Still, such cloud platforms typically provide one or two of the capabilities mentioned above, but not more. So, you have to piece your cloud infrastructure together from multiple providers, which often causes additional data transfer costs. To manage these costs effectively, implementing cloud cost optimization techniques can help streamline resources and reduce unnecessary expenditures.
The observed trends are mirrored by responses from surveyed developers, who indicated high reliance on third-party services such as:
- Proxy providers (39.1%)
- Web scraping APIs (34.8%)
- Cloud platforms (26.1%)
Note that these categories are not mutually exclusive. Some developers use multiple services, while others rely solely on their custom code without external tools.

Technical landscape
Web scraping APIs and cloud infrastructure
34.8% of surveyed developers favor web scraping APIs. These address common hurdles like rate-limiting, JavaScript rendering, and data parsing.
At the same time, cloud services tailored to web scraping needs combine the scalability and reliability of the cloud with web scraping APIs to offer a comprehensive solution for large-scale scraping.
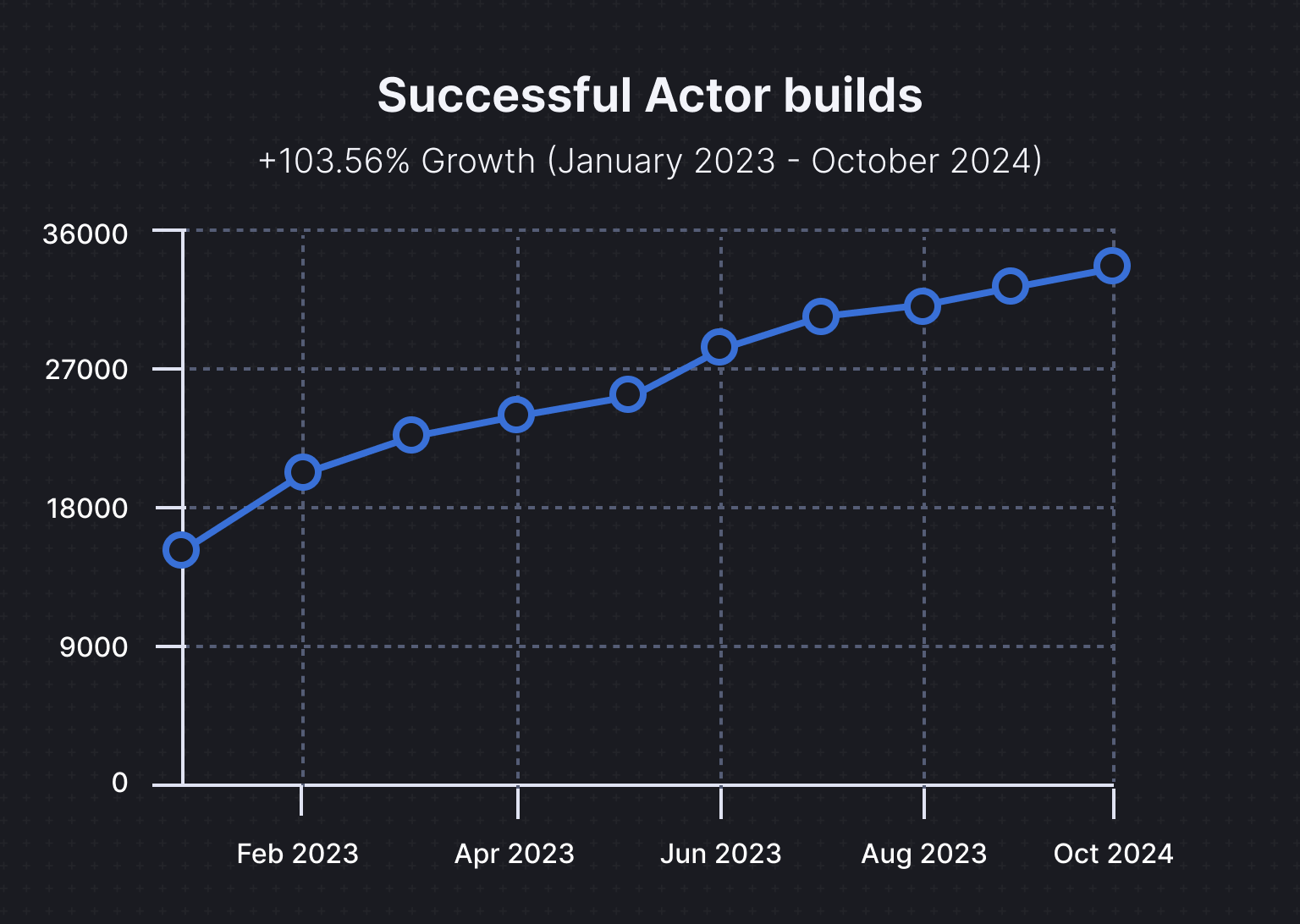
For example, the number of successful Actor builds on Apify has increased from 16,809 in January 2023 to 34,217 in October 2024, reflecting a 103.56% growth in usage. This indicates a demand for integrated solutions that simplify both web scraping and large-scale data handling.
Databases
Data storage preferences reveal 26.1% of developers opt for databases like MongoDB and PostgreSQL. These tools are particularly favored for managing large, structured datasets. While cloud providers like AWS and GCP remain popular, dedicated databases offer a tailored approach for efficient data organization and retrieval.

AI integration
The adoption of AI in web scraping is still emerging but gaining traction. Around 26.1% of developers already use AI in their processes, with another 34.8% considering its implementation.

Rapid advancements in AI with models like GPT-1o, Claude 3.5 Sonnet, and Gemini 2.0, and models with vision capabilities (GPT-4o), have driven a growing trend of using AI to tackle various challenges.
While these tools excel in natural language processing and image understanding, their effectiveness in tasks like CAPTCHA-solving often requires custom implementations, fine-tuning, and integration with specialized systems.
Other reports on AI-powered web scraping, such as this one by Expert Beacon, suggest that AI models trained on specific datasets can improve the accuracy of text extraction from poorly formatted or inconsistent web pages and recognize and categorize entities (e.g., product names, prices, or reviews) with greater precision.
Challenges and solutions
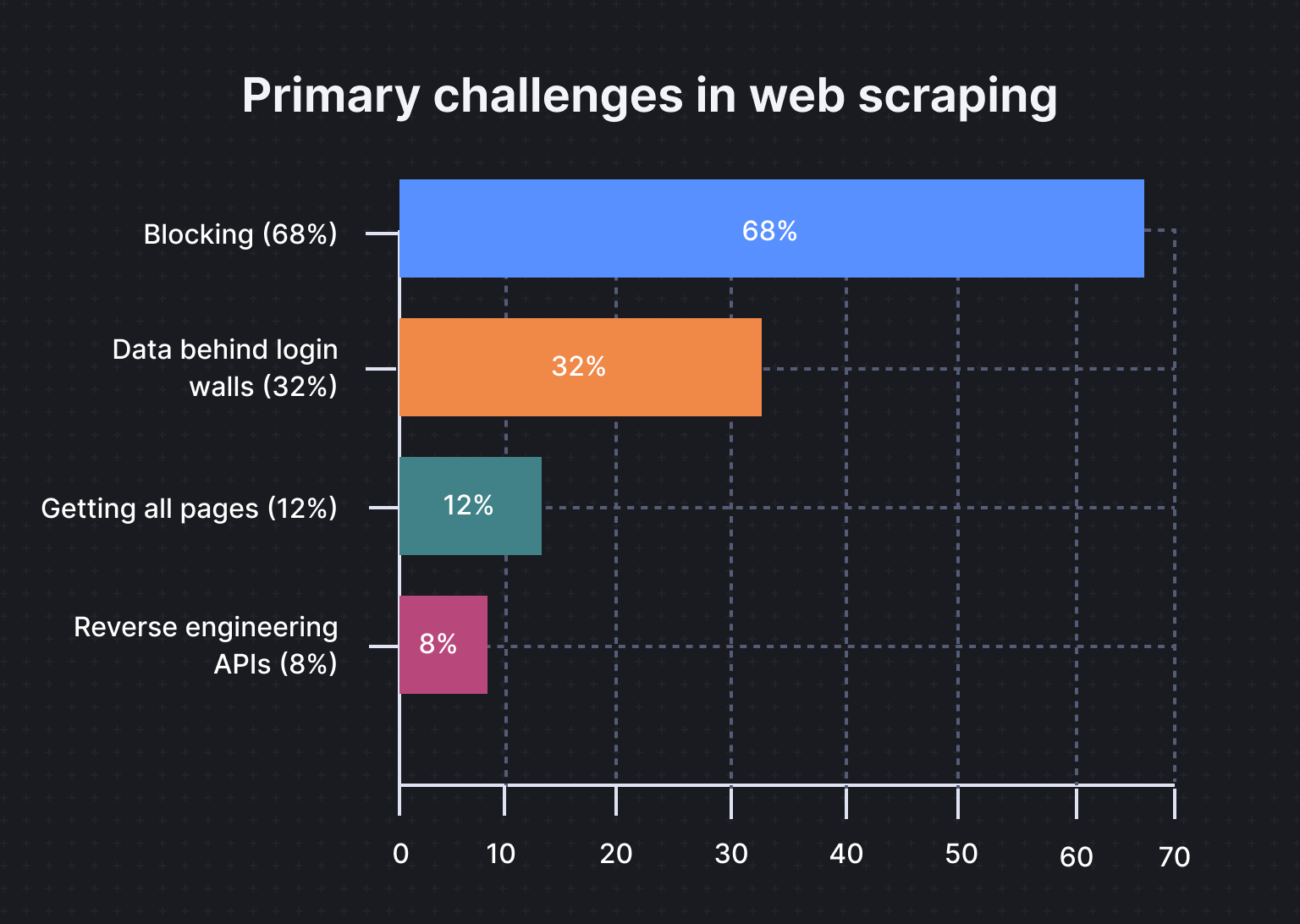
The most common obstacles developers face include blocking (68%), data behind logins (32%), getting all pages from a website (12%), and reverse engineering APIs (8%).
These barriers highlight the growing sophistication of anti-scraping mechanisms, particularly CAPTCHAs and IP blocking.
While most users don't employ dedicated browser fingerprinting tools to solve these problems, some respondents mention custom automation setups and AI tools or rely on manual techniques to handle these challenges, particularly CAPTCHA-solving.
These tactics suggest a divide in the level of technical sophistication among scrapers.
Legal and regulatory environment
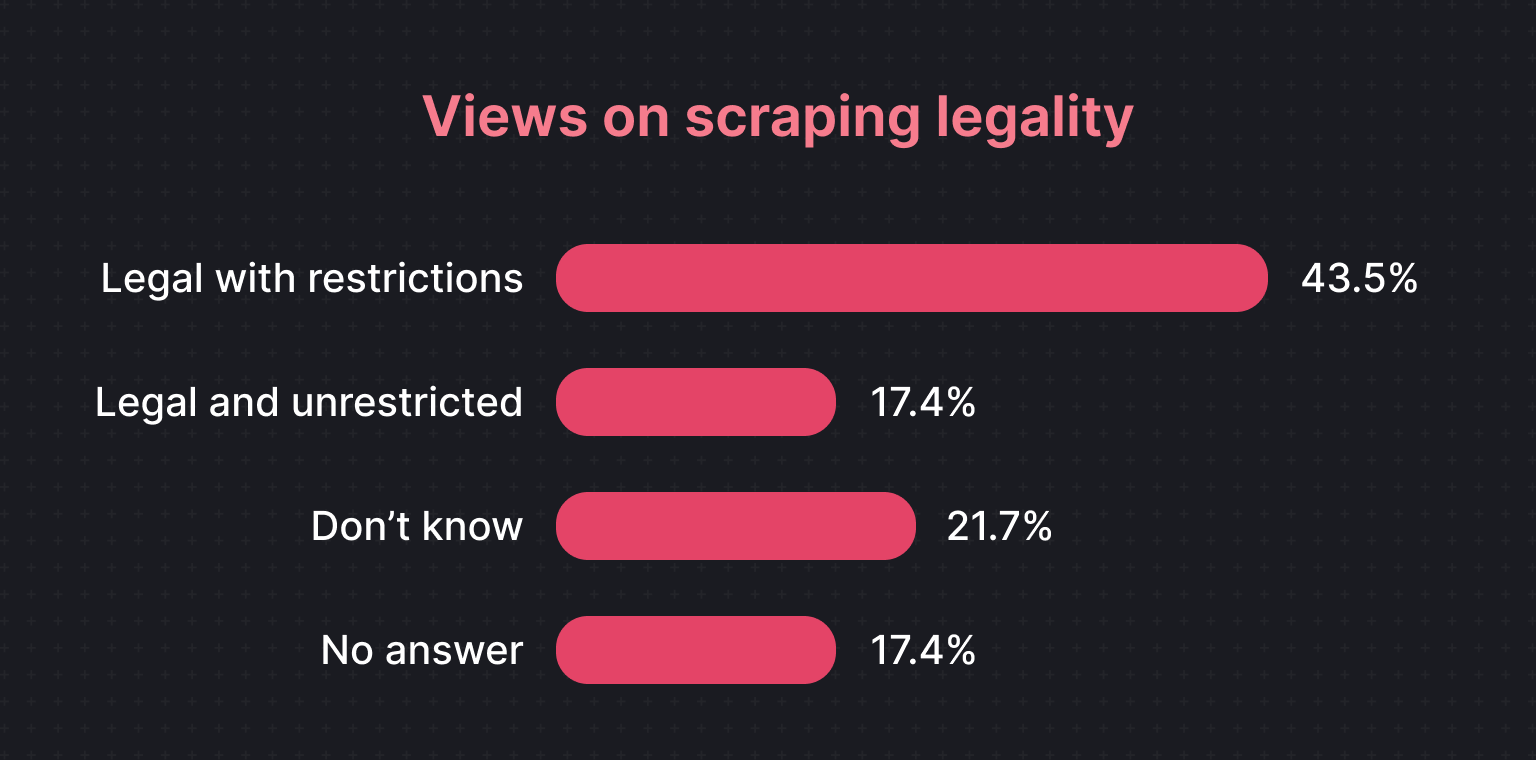
Attitudes to legal and ethical compliance are mixed. 17.4% of respondents view scraping as "legal and unrestricted," another 43.5% see it as "legal with some restrictions", and 21.7% are unsure. These responses reflect ongoing uncertainty and the need for scrapers to balance data extraction goals with adherence to legal regulations.
According to Apify's analysis of web scraping legality, most jurisdictions permit scraping publicly accessible data if it doesn’t breach copyright, violate binding terms of service, or target sensitive information without authorization.
However, court rulings on issues like intent and security bypasses highlight the importance of understanding regional laws.
This uncertainty challenges scrapers to balance data utility with legal and ethical compliance.
Future outlook
Automation, anti-blocking, and compliance
Our analysis suggests that the future of web scraping is poised to be shaped by increased demand for automation and innovations addressing complex challenges such as CAPTCHAs, browser fingerprinting, and legal compliance.
API usage and integrations
We believe that in 2025, businesses are likely to prioritize scalable, developer-friendly solutions that integrate easily with broader workflows. The projected surge in API-based Actor runs - expected to exceed 10 billion annually - underscores the growing reliance on APIs as the backbone of web data collection and integration.
Open-source and cloud-based solutions
Open-source tools will remain a cornerstone for developers seeking cost-effective and customizable solutions, but we think that proprietary platforms will gain traction for their enhanced reliability and ease of use. The dual growth of open-source and cloud-based solutions indicates an industry increasingly defined by its ability to balance flexibility with operational stability.
E-commerce, real estate, and research
Web scraping's role in supporting these sectors will further expand as organizations seek competitive insights and operational efficiencies. Organizations prepared to navigate these complex environments will not only benefit from web scraping but also set the standard for its ethical and effective application in years to come.
Read other reports about web scraping:



