When scraping a website, you'll likely encounter pages that require submitting a login form. Scrapy - the most powerful framework for web scraping in Python - provides ways to handle forms and authentication. While Web scraping with Scrapy 101 shows you how to use Scrapy's features in general, this short guide equips you with some Scrapy know-how to deal with login forms and handle token authentication.
Dealing with login forms with FormRequest
For straightforward login forms, use Scrapy's FormRequest. Here's how to do it:
- Identify how the form works: Open the login page and inspect the form using your browser's developer tools. Then, try to submit the form and inspect what request it makes and what parameters it sends. We'll use this form as an example. Note the form action URL and input field names (
uname,psw) for future steps.
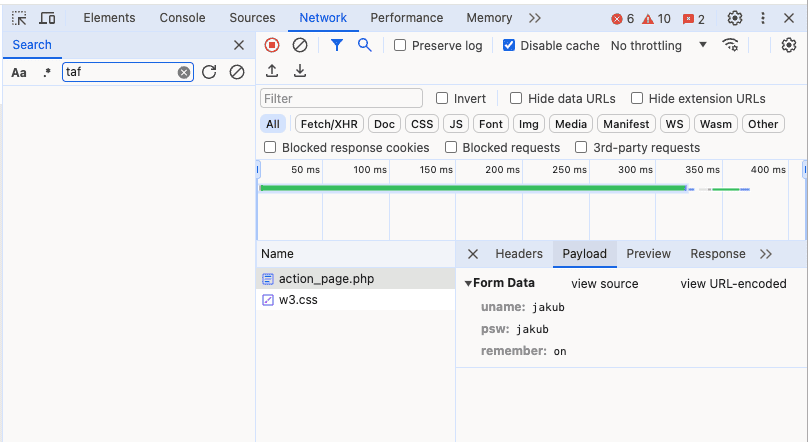
- Craft the FormRequest: In your spider's
parsemethod, useFormRequestwith the following arguments:
- URL: The login form action URL from network tab (https://www.w3schools.com/action_page.php).
- formdata: A dictionary containing login credentials (e.g.,
{'username': 'your_username', 'psw': 'your_password'}). - callback: The function to handle the response after login.
Example:
def start_requests(self):
login_url = "https://example.com/login"
yield FormRequest(login_url,
formdata={'username': 'your_username', 'password': 'your_password'},
callback=self.after_login)
def after_login(self, response):
# Check for successful login and proceed with scraping
if b'Login successful' in response.body:
# Your scraping logic here
pass
Managing complex login forms with CSFR token
Some logins involve multiple steps or dynamic elements. In such cases, we need to extend the previous example by extracting some additional data before we send the request. We can do this by using Scrapy's from_response and xpathmethod:
- Scrape the initial login page: Use a standard
Requestto fetch the login page. - Extract login details: Within your
parsemethod, use XPath or CSS selectors to extract necessary information like hidden form fields or CSRF tokens (often required for security). - Craft the FormRequest dynamically: Build a new
FormRequestusingformdatapopulated with extracted data.
Remember:
- Use
response.xpathorresponse.cssfor element selection. - Refer to Scrapy's documentation for detailed selector syntax.
Example (assuming a hidden CSRF token is present):
def start_requests(self):
login_url = "https://example.com/login"
yield Request(login_url, callback=self.parse_login)
def parse_login(self, response):
csrf_token = response.xpath('//input[@name="_csrf"]/@value').get()
yield FormRequest.from_response(response,
formdata={'username': 'your_username', 'password': 'your_password', '_csrf': csrf_token},
callback=self.after_login)
# ... after_login logic from previous example
Scrapy and token authentication
For token-based authentication, you'll need to extract the token from the login response and include it in subsequent requests:
- Extract the token: Use XPath or CSS selectors to identify the element containing the token after a successful login.
- Include the token in headers: Use the
headersargument in yourRequestobjects to send the token in the authorization header.
Example (assuming a token is stored in a hidden element):
def after_login(self, response):
token = response.xpath('//input[@id="auth_token"]/@value').get()
yield Request("https://example.com/protected-data",
headers={'Authorization': f'Bearer {
What about CAPTCHAs and JavaScript validations?
Some forms, especially signup forms, may have CAPTCHAs or JavaScript validations that need to be handled. Here are a few solutions to these issues.
CAPTCHAs
- Manual solving: For low-volume tasks, you might manually solve CAPTCHAs when they appear. This is the simplest approach, but doesn't scale well.
- ReCAPTCHA tokens: For sites using Google's reCAPTCHA, some services can generate tokens based on site keys. These tokens can then be submitted with your form.
- Avoidance (recommended): The best way to deal with CAPTCHAs is to avoid getting them in the first place. You can avoid CAPTCHAs by mimicking human behavior more closely (e.g., randomizing click locations and intervals, using a browser with a full execution environment like Selenium). The best framework for getting your bots to emulate human behavior is Crawlee, as it automates the process. It's a Node.js library, but support for Python is coming very soon!
JavaScript validations
- Headless browsers: Tools like Playwright, Selenium, or Puppeteer can automate a real browser, including executing JavaScript. This means JavaScript validations and dynamically generated tokens can be handled almost as they would be in a manual browsing session.
- AJAX handling: If validations involve AJAX requests, you can mimic those requests directly in your script. You can use the Developer Tools in Chrome or Firefox to inspect what requests are made.
- API endpoints: Sometimes, the functionality behind form submissions (especially validations) is powered by API endpoints. These can sometimes be used directly to bypass the need for dealing with the form or its JavaScript validations on a web page.
Moving your Scrapy project to the cloud
If you want to take your web scraping projects to the next level with the Apify cloud platform so you can take advantage of its proxies, scheduling features, storage, code templates, and more, here are some useful resources that might help you: