


Social media is a key component in today's marketing and research strategies. While it's challenging to establish a presence on these platforms, an exciting opportunity lies in web scraping to unearth a wealth of insights from the data these platforms offer.
Social media scrapers are designed to extract and analyze data from platforms such as Instagram, TikTok, Facebook, Reddit, and YouTube. Utilizing these tools for consistent and large-scale data extraction allows marketers, researchers, and business professionals to deeply understand their audience, leading to more strategic engagement decisions.
⚙️ What is web scraping?
Web scraping is an automated way to gather data from a website. It involves getting the website's HTML code and then looking through it to find specific information like text, images, or prices. This process allows for quick and organized data collection from the web. Find out more in our complete guide to how web scraping works.
 Natasha Lekh
Natasha Lekh
Want to export tweets? Check out this short tutorial.
🧑⚖️ Is it legal to scrape data from social media?
Before diving into social media scraping, it's essential to understand that scraping responsibly and ethically is crucial for maintaining the integrity of the open web and the robustness of the platforms themselves. It is important to know each platform's terms of use, legal considerations, and privacy regulations and act in compliance with those rules. You can start by reading our comprehensive guide on the legality of web scraping.
Generally, social media scraping is a gray area on the legal map (compared to scraping other types of websites) since it involves scraping personal data such as names. However, there are many cases when web scraping social media is not only allowed but needed. Here's one of them:
Theo Vasilis
When web scraping Facebook pages and AI face recognition come to the rescue
There's a reason why scraping social media remains one of the top use cases in the data extraction industry. Scraping comments from social media can be used for various purposes, offering valuable insights and opportunities for businesses and researchers.
So here is how you can export comments from YouTube using a web scraper + Google Drive integration. If you need visual guidance of how to set up the Google Doc integration, we have a video for you here to help out:
📑 How to download social media comments into a Google Doc
Let’s make our YouTube Scraper deliver extracted comments straight to your Google Docs. How? Well, by creating a small integration for your run. Let’s see how anybody can do that using the example of comments from YouTube.
Natasha Lekh
You might need to scrape the YouTube comments first (before integrating them into your Google Drive)
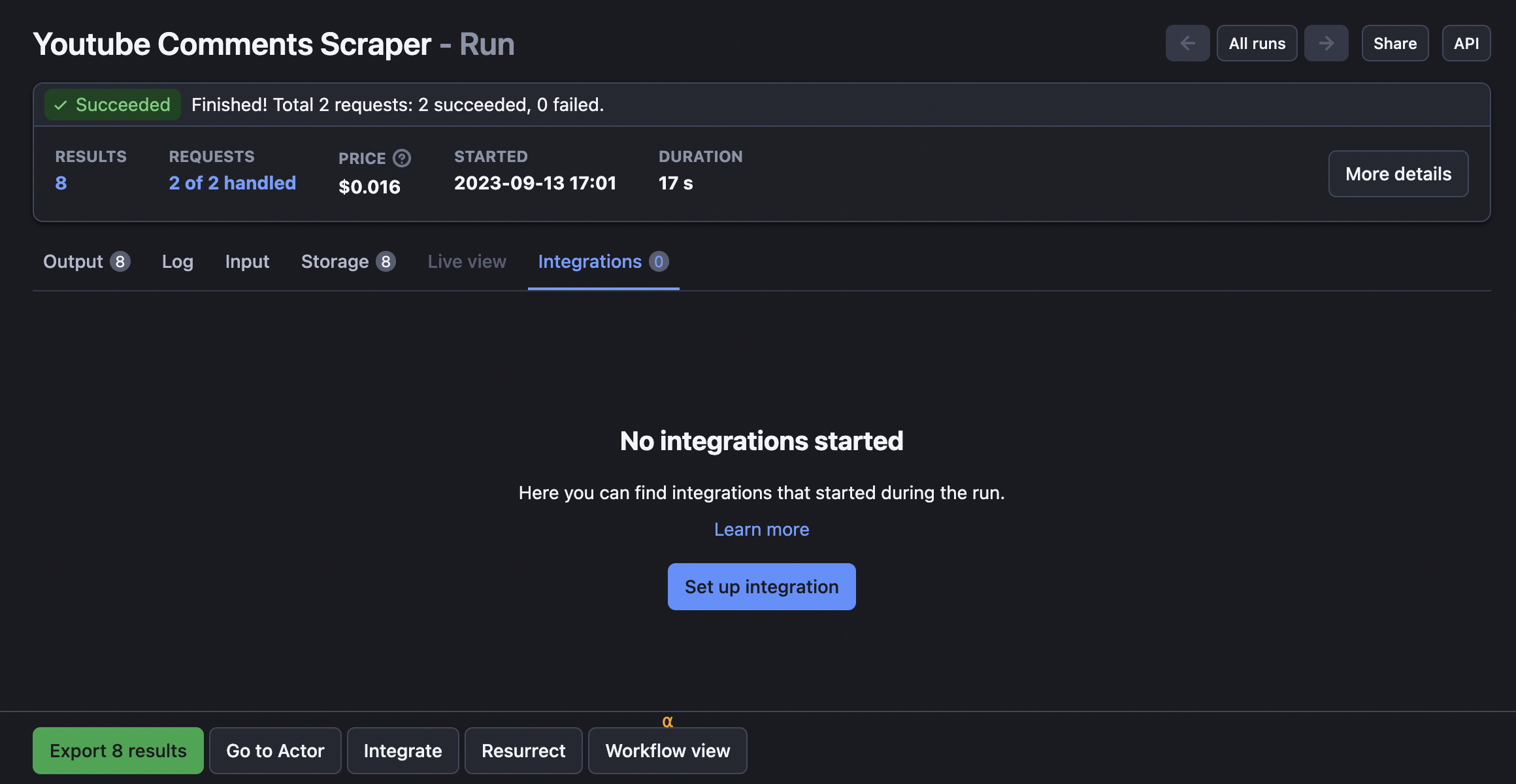
Step 1. Find the Integrations tab
On your scraper panel, click on the Integrations tab. You don’t have to scrape data beforehand; it’s enough to set up the Google Drive integration once per scraper.
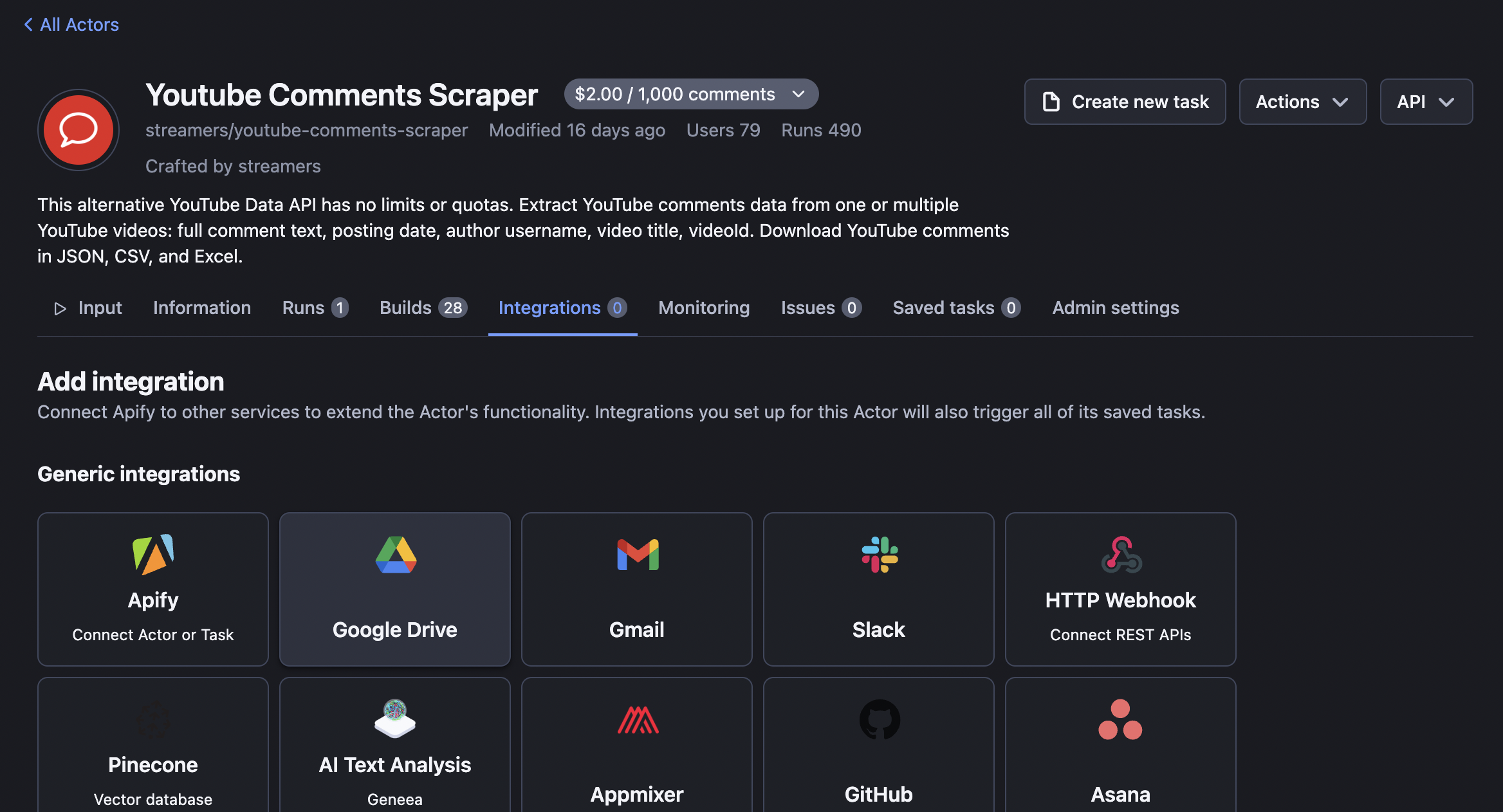
Step 2. Add Google Drive integration
Within the Integrations tab, select Google Drive and click Configure. You will be redirected to the configuration page.
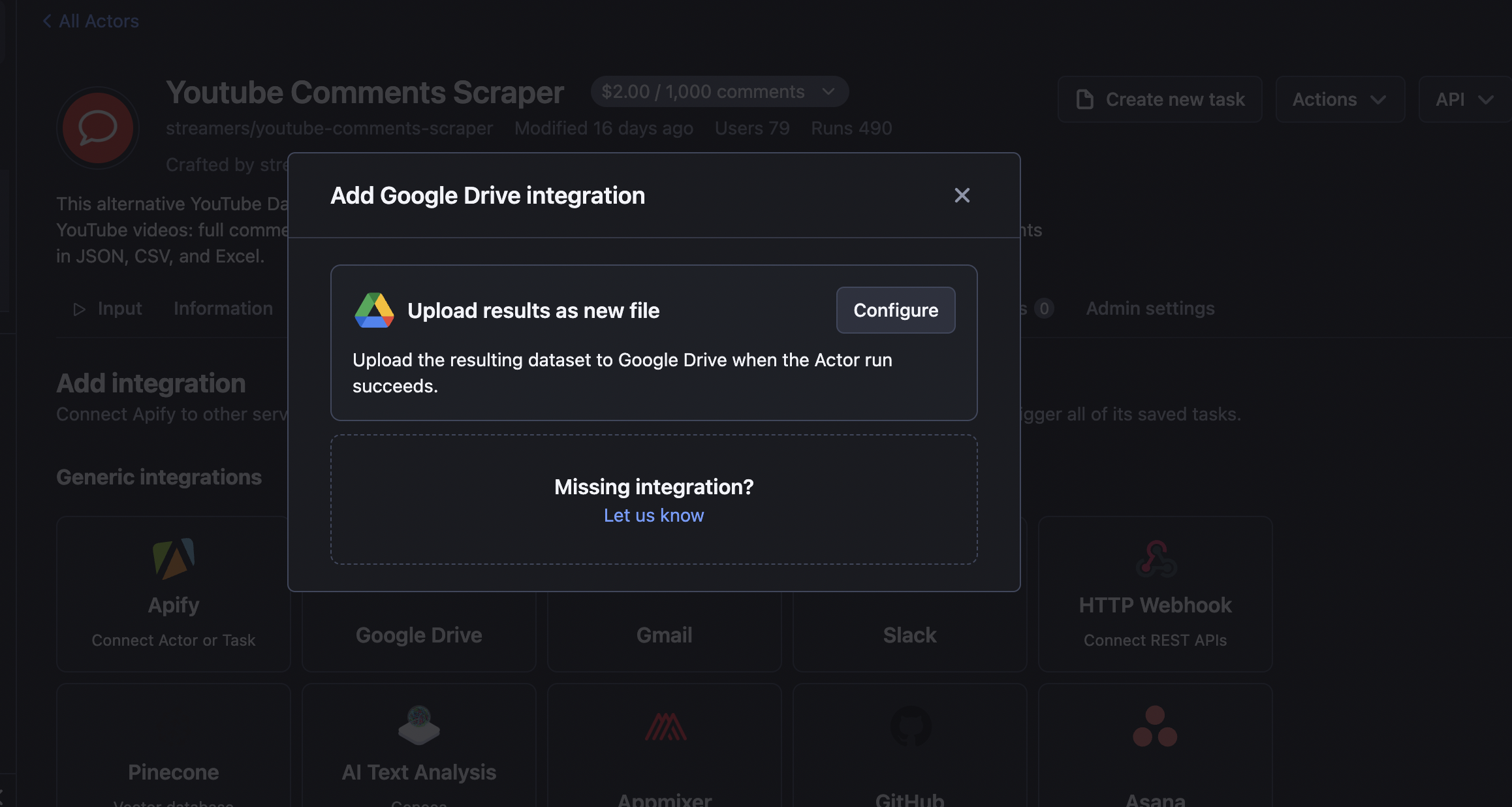
Step 2. Add Google Drive integration
Step 3. Sign in with your Google account
This is done to establish the link between the Apify platform and your Google Drive. Once you log in and give the necessary permissions for the files to be saved on your Google Drive, you won’t have to do it again. Now name your future file and select the format you want the data to be delivered in: XLS, CSV, HTML, XLXS, JSON, or even RSS.
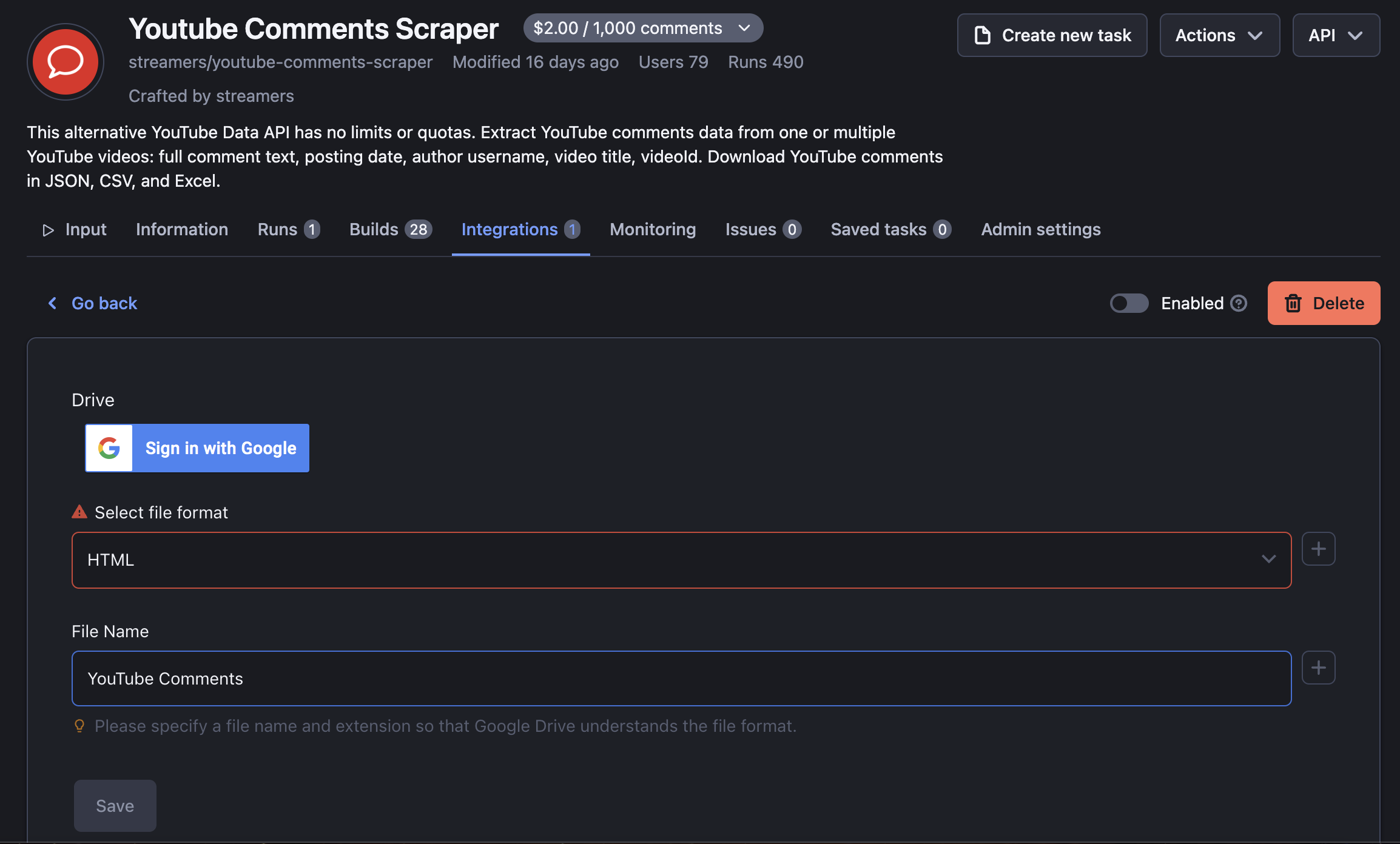
Step 4. Enable your integration and run the scraper
Once logged in, make sure the integration has been enabled by using the toggle button. And that’s it! Run the scraper with the same input one more time to trigger the integration.
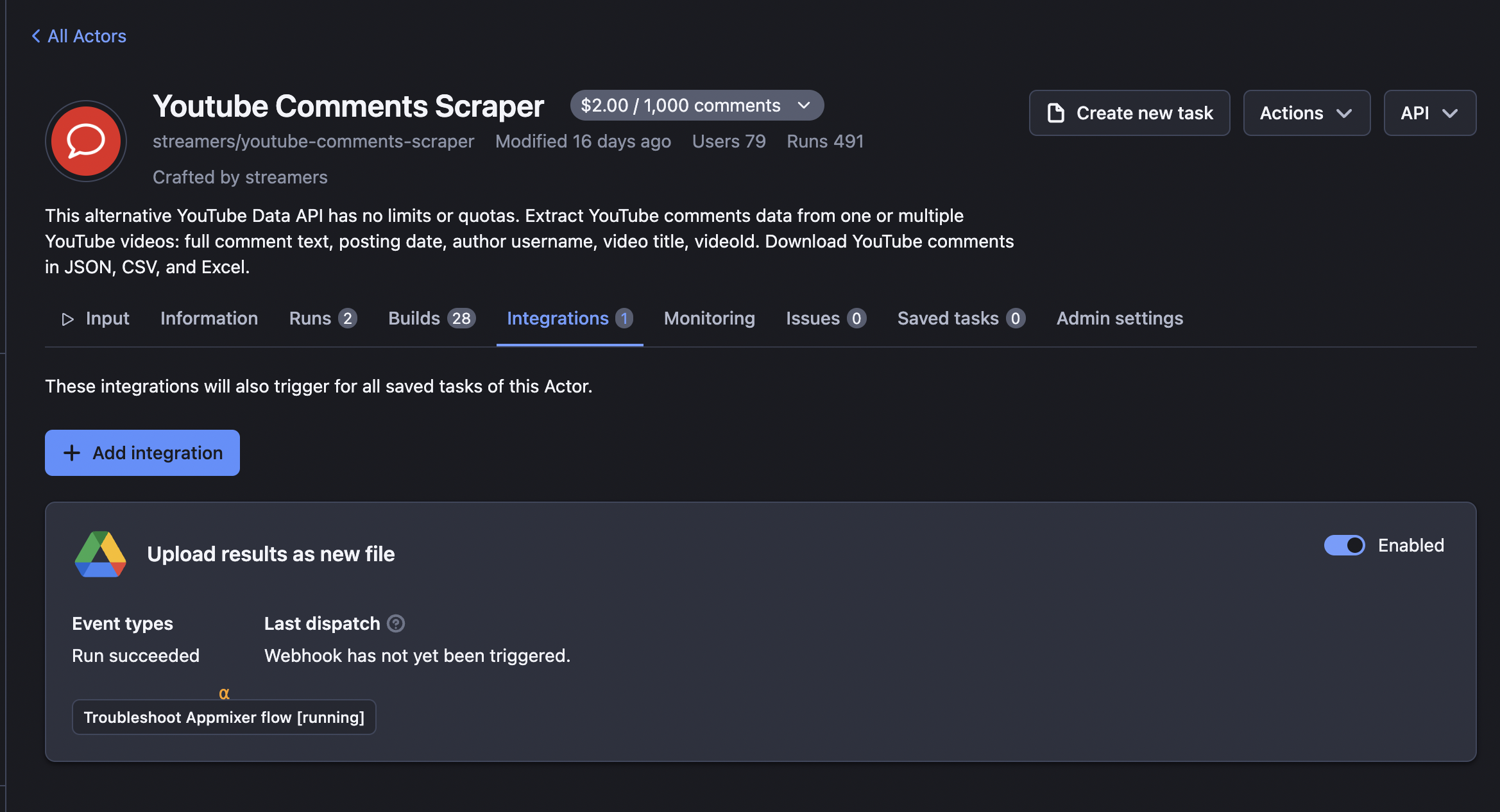
Step 5. Check your Google Docs for scraped comments
After integration is enabled, you can head over to your Google Docs to check for imported data. The file will have the same name and formatted data as you’ve chosen.
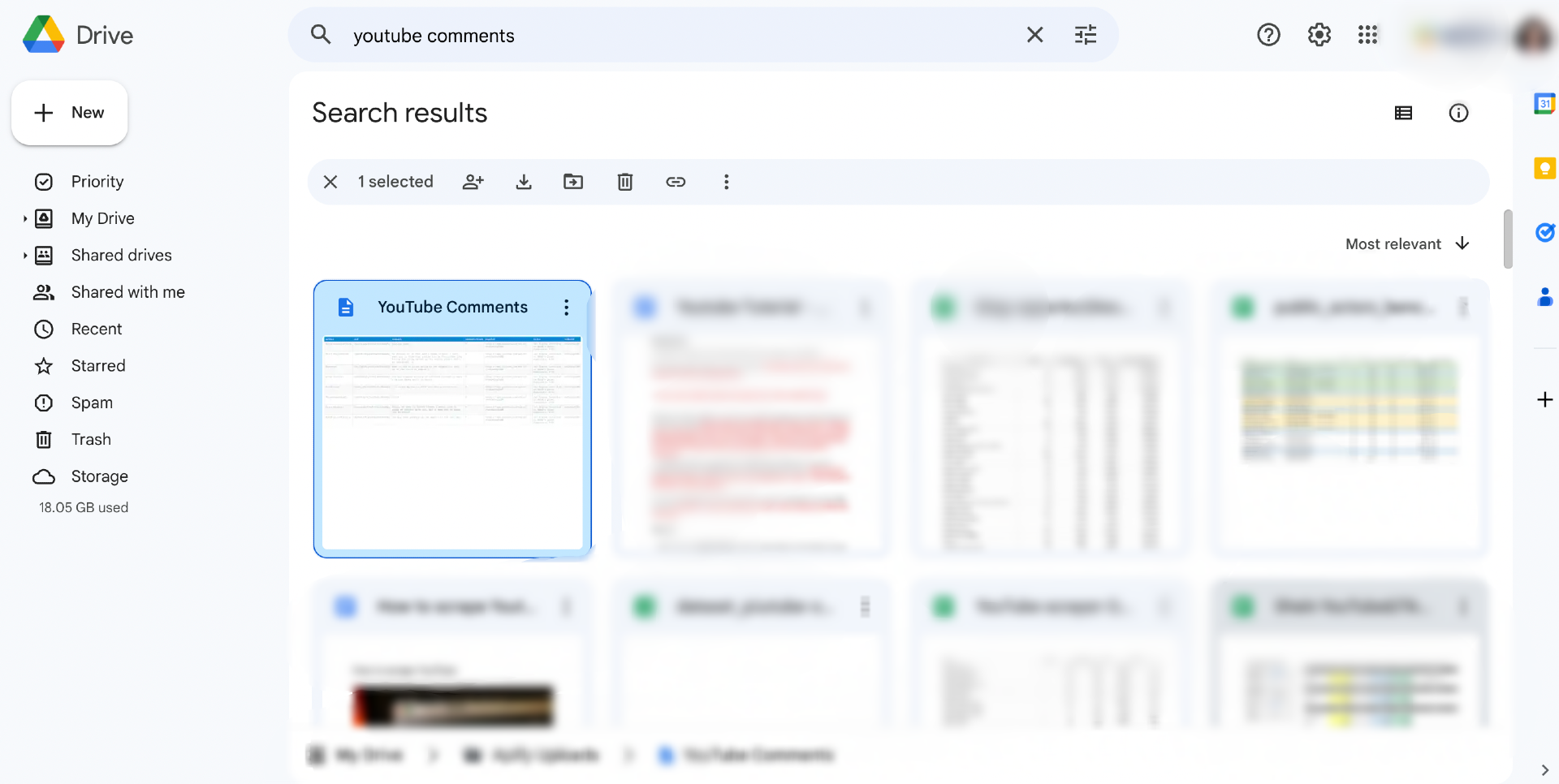
If you also choose to schedule your scraper, the scraped data will get imported to Google Drive every time the scraper finishes a run. Watch this short video to quickly learn how to schedule your scraper to run and get comments from the websites automatically.





