


Following our review of ScrapingBee, let's now shift our focus to ScraperAPI. However, before diving into the review, let's address the elephant in the room: Apify, being a web scraping service, might raise concerns about bias when reviewing another service.
While we hold Apify in high regard and take pride in the value it offers our users, the purpose of this review is to provide an impartial assessment of other services, highlighting their strengths and weaknesses. It's important to recognize that Apify may not be the perfect fit for everyone, and that's perfectly okay. Our top priority is ensuring customer satisfaction and transparency. We don't aim to push Apify onto users who may find a better match elsewhere.
However, if Apify does align with your needs and preferences, we'd be thrilled to have you as a user, and we're confident you'll have a positive experience. The aim of this article is to assist you in determining whether ScraperAPI or Apify is the best choice for your specific use case. So, let's take a closer look at ScraperAPI and see how it stacks up against Apify.
ScraperAPI vs. Apify comparison table
To kick off our review, let's begin with a quick overview of both services using a comparison table. We'll then take a closer look into each feature described in the table in the following sections.
| Features | Apify | ScraperAPI |
|---|---|---|
| Unlimited Free Plan | ✅ | ✅ |
| Library of pre-built web scrapers | ✅ (10,000+) | ✅ (<10) |
| Host code in the cloud | ✅ | ❌ |
| Available data export formats | CSV, HTML, JSON, XML, or RSS Feed | JSON, CSV |
| Developer Community | ✅ (Discord) | ❌ |
| Scrape dynamic web pages (using headless browsers) | ✅ | ✅ |
| Geolocation Targeting | ✅ (Geolocation targeting available for every country in all plans - including free) | ✅ (Geolocation targeting is restricted to US and EU, except on business plan) |
| Usage-based pricing | ✅ (Platform CU) | ✅ (API credits) |
| High-scale enterprise plans | ✅ | ✅ |
| Store and manage data in the cloud | ✅ | ❌ |
| Proxy rotation, browser emulation, CAPTCHA bypass | ✅ | ✅ |
| API Access | ✅ (Full-fledged platform API) | ✅ (Scraping API endpoints) |
| Schedule one-off or repeating extractions | ✅ | ✅ |
| Integration with third-party tools | ✅ (Zapier, Make, Gmail, Google Drive, Slack, Github LangChain, and more) | ❌ |
As evident from the one-to-one feature comparison, Apify holds an advantage when it comes to the number of features. This is because Apify is a comprehensive web scraping platform, whereas ScraperAPI focuses solely on providing an API solution for web scraping.
Nevertheless, even when both solutions share similar features, there are notable differences that set each service apart.
To gain a clearer understanding of what each service offers, let's explore some of the features that make both Apify and ScraperAPI unique.
Apify
Apify is, at its core, a developer-focused full-stack web scraping and automation cloud-based platform. It allows users to build, run, and manage serverless cloud programs, known as Actors, which can perform tasks ranging from simple data collection to complex automation workflows. Here is a breakdown of some of the core features of the Apify platform:
Actors
Central to Apify are its Actors, which are cloud programs that can perform a variety of tasks, such as web scraping, data processing, and automation. Developers can build their own Actors locally or directly on the platform. Regular users can also benefit from using publicly available ready-made Actors on Apify Store.
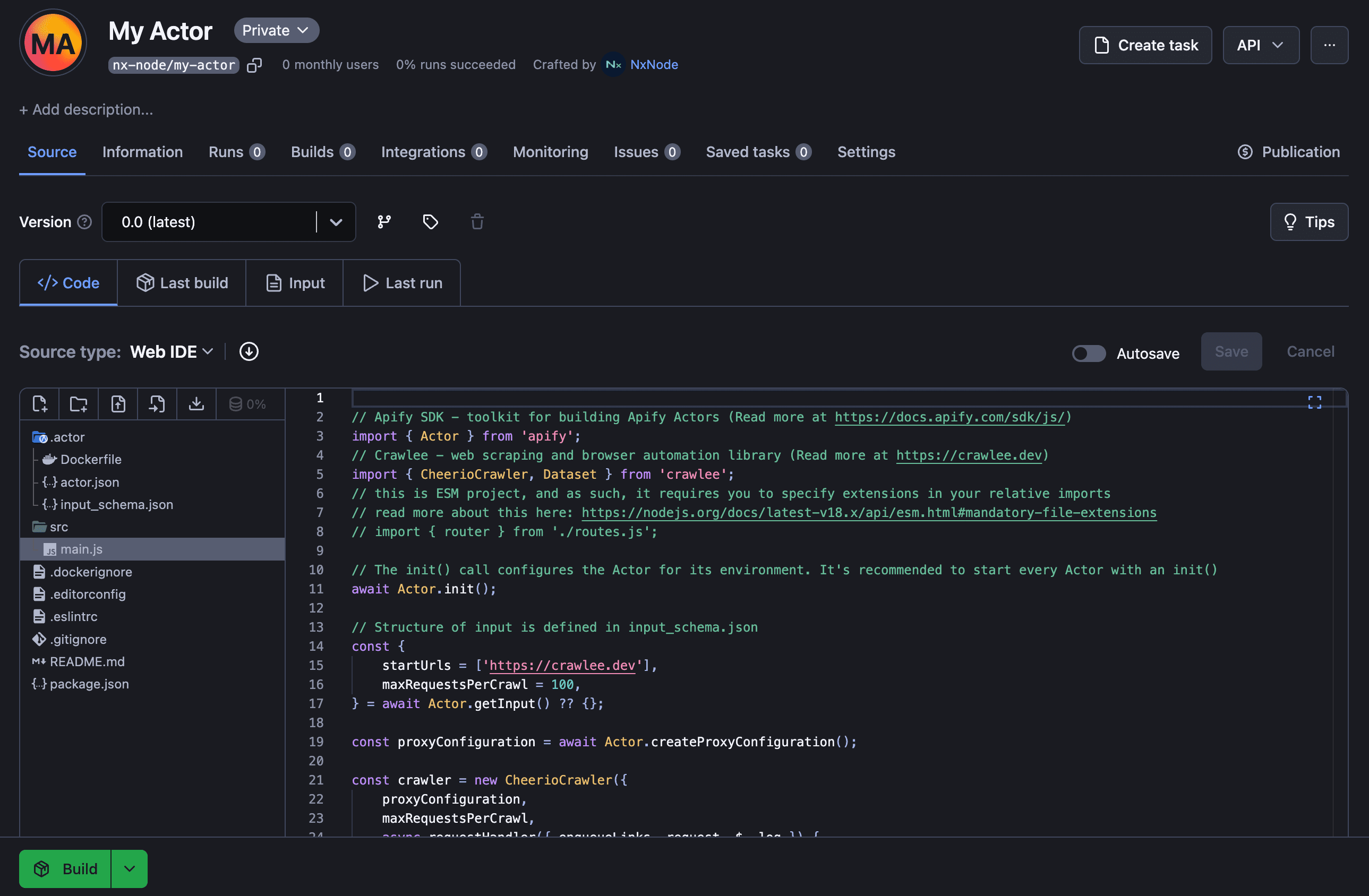
Apify Proxy
A unique proxy solution that smartly rotates between data center and residential IP addresses. Apify regularly checks the IP addresses, with dead or burned proxies automatically removed from the pool, ensuring healthy and reliable scraping sessions.
SDKs and APIs
Apify provides a wide range of SDKs and APIs to facilitate the development of new Actors and integration with other applications, especially for JavaScript/TypeScript and Python.

SuperScraper API
SuperScraper API is a versatile, open-source REST API designed for web scraping. It offers compatibility with ScraperAPI, ScrapingBee, and ScrapingAnt interfaces. That means the Actor can be used as a potentially cheaper drop-in replacement for ScraperAPI.
SuperScraper API lets you extract fully rendered HTML from any URL using a headless browser to effectively handle dynamic content.

Apify Store
An open store for Actors where platform users can choose from hundreds of pre-built web scrapers and developers can publish their Actors on Apify Store, potentially earning passive income through their usage by others.

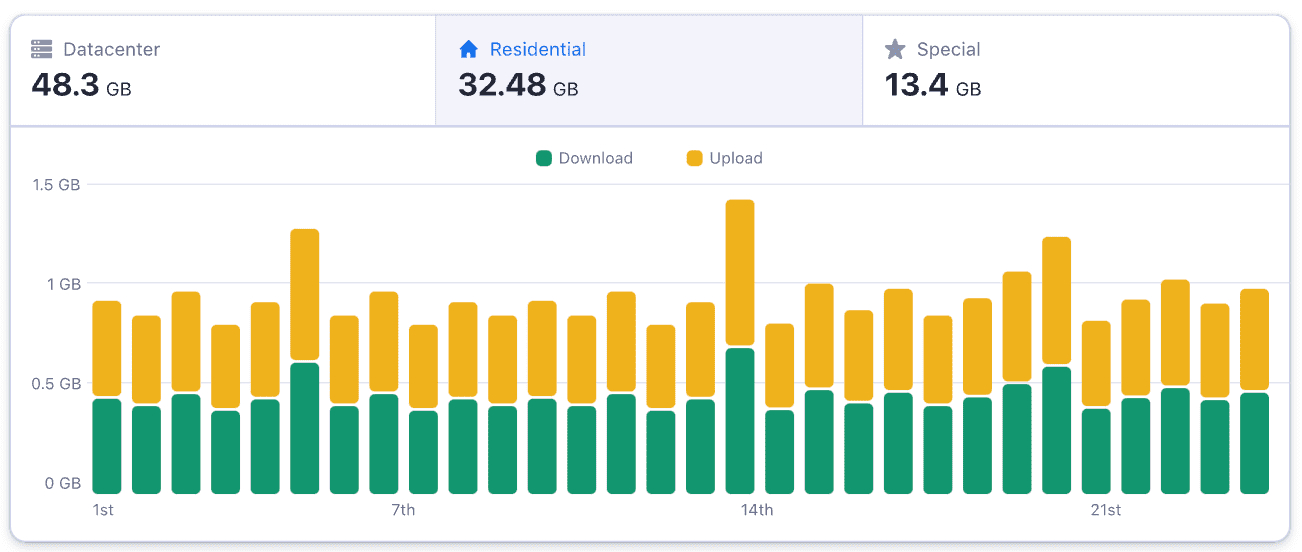
Scraper performance monitoring
Modern websites often undergo regular updates. This directly affects any web scraping solution, which can quickly become outdated or experience significant performance issues as a result of these updates. As a platform designed for web scraping, Apify features a robust built-in monitoring system to assist developers in tracking their scraper's performance over time.
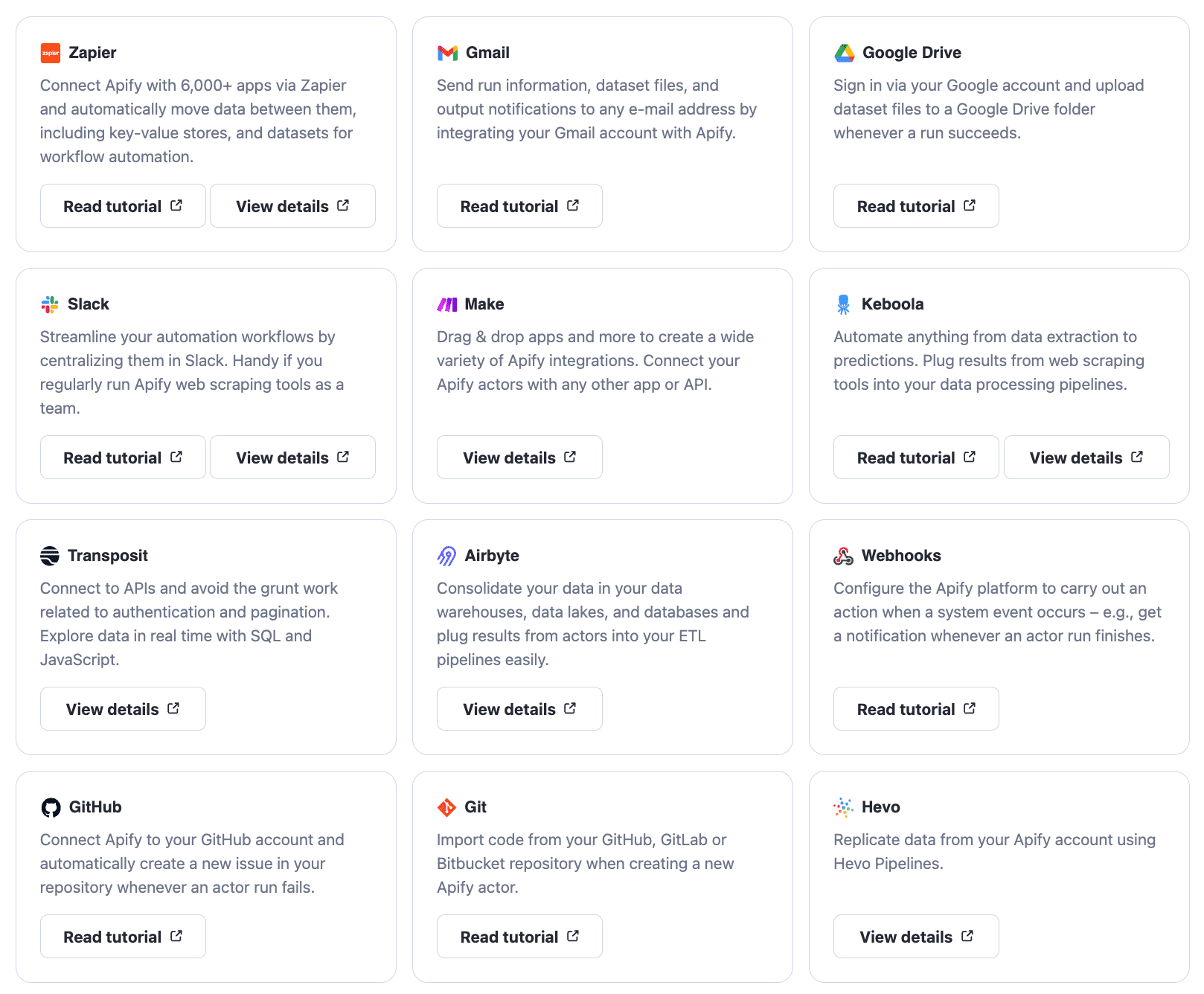
Integrations and task automation
Actors can be integrated with an extensive list of third-party applications and triggered manually, through the API, or via scheduling.
Community and support
Apify boasts one of the largest and most active developer communities in the web scraping space. Furthermore, Apify offers its users a dedicated support team and extensive documentation filled with examples to assist developers in learning the platform, developing Actors, and troubleshooting issues.
The official developer community of Apify and Crawlee
ScraperAPI
ScraperAPI is, as its name suggests, an API-driven web scraping solution. Its main selling point is its ability to automatically tackle common web scraping obstacles, such as CAPTCHAs, JavaScript content, and proxy server management. This ensures that users can reliably extract data using their API without needing extensive expertise in web scraping. Here are some of the key features of ScraperAPI:
API driven
As expected, at the core of ScraperAPI’s product is its API solution. It enables users to scrape data from generic web pages while also providing specific API endpoints to fetch data from a limited list of popular websites such as Google Search and Amazon. This is what a simple request to the ScraperAPI looks like:
import requests
payload = { 'api_key': 'YOUR_API_KEY', 'url': 'https://httpbin.org/' }
r = requests.get('https://api.scraperapi.com/', params=payload)
print(r.text)
Proxy mode & geolocation targeting
ScraperAPI allows users to utilize its curated pool of proxies to aid in anonymous and uninterrupted web scraping, effectively handling IP rotation and geolocation targeting. These features are not automatically included in all requests; you need to specify proxies as an option in your API request. In the example below, I'm sending an API request with the geolocation target set to "US" while enabling proxy mode.
import requests
proxies = {
"https": "scraperapi.country_code=us:{YOUR_API_KEY}@proxy-server.scraperapi.com:8001"
}
r = requests.get('https://httpbin.org/', proxies=proxies, verify=False)
print(r.text)
JavaScript rendering
Another feature of ScraperAPI is the capability of rendering JavaScript-heavy pages, allowing users to scrape data from dynamic web applications. You can enable this feature by passing render=True to your API request.
import requests
payload = { 'api_key': '85561e7b6537a2ce4da24a299c2b4a4f', 'url': 'https://httpbin.org/', 'render': True, 'autoparse': True }
r = requests.get('https://api.scraperapi.com/', params=payload)
print(r.text)
API playground
Another feature of ScraperAPI is its visual API request builder. Although still in beta, this feature already offers a much more user-friendly way to build and test custom API requests before integrating them into your code.
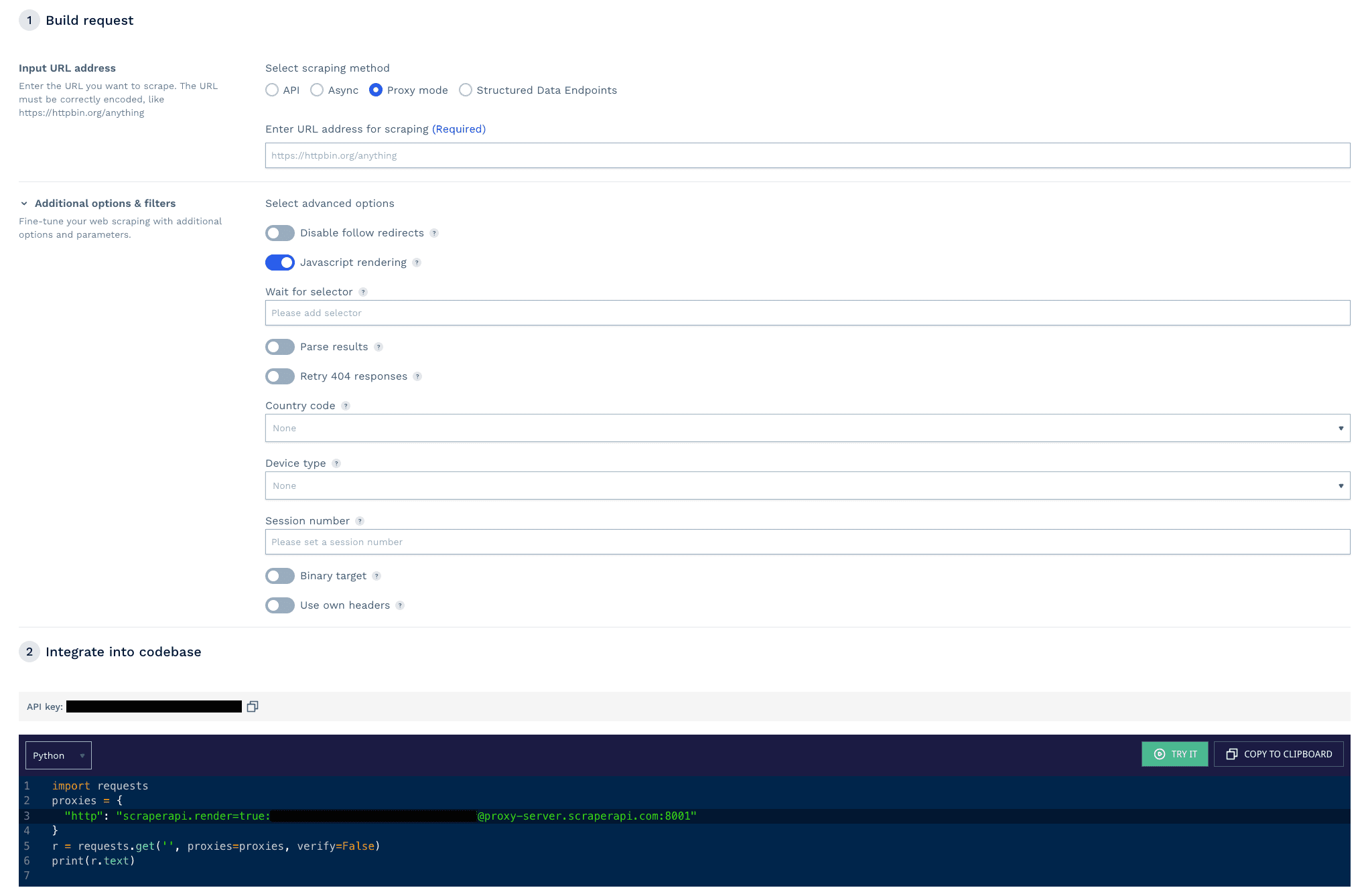
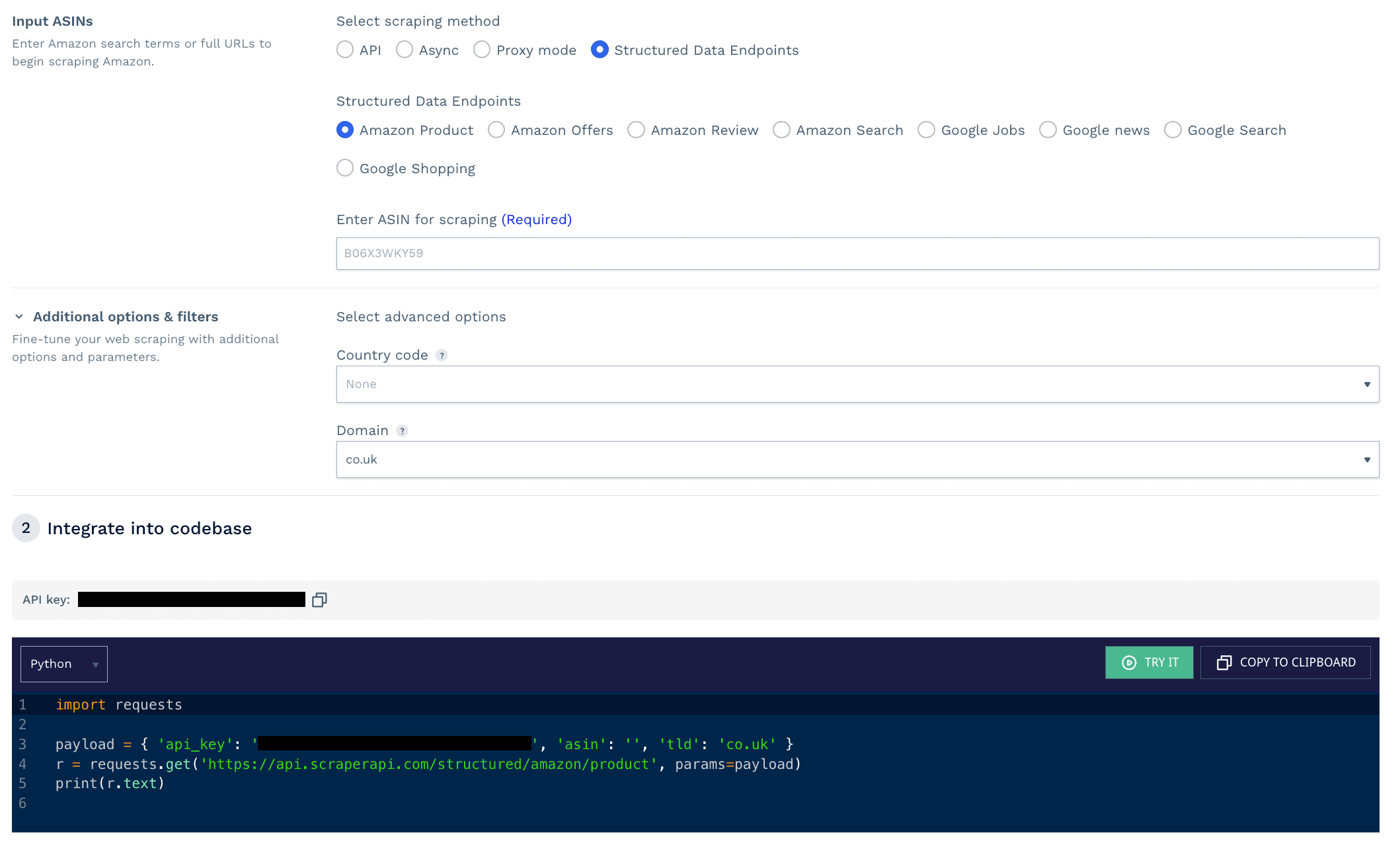
Structured data endpoints
Apart from offering a general API for scraping custom URLs, ScraperAPI also offers pre-configured endpoints designed for specific popular websites such as Amazon and Google Search.
Accessing the "Structured Data Endpoints" tab in the API playground allows you to utilize a custom user interface to help construct your API request for each available structured data endpoint.
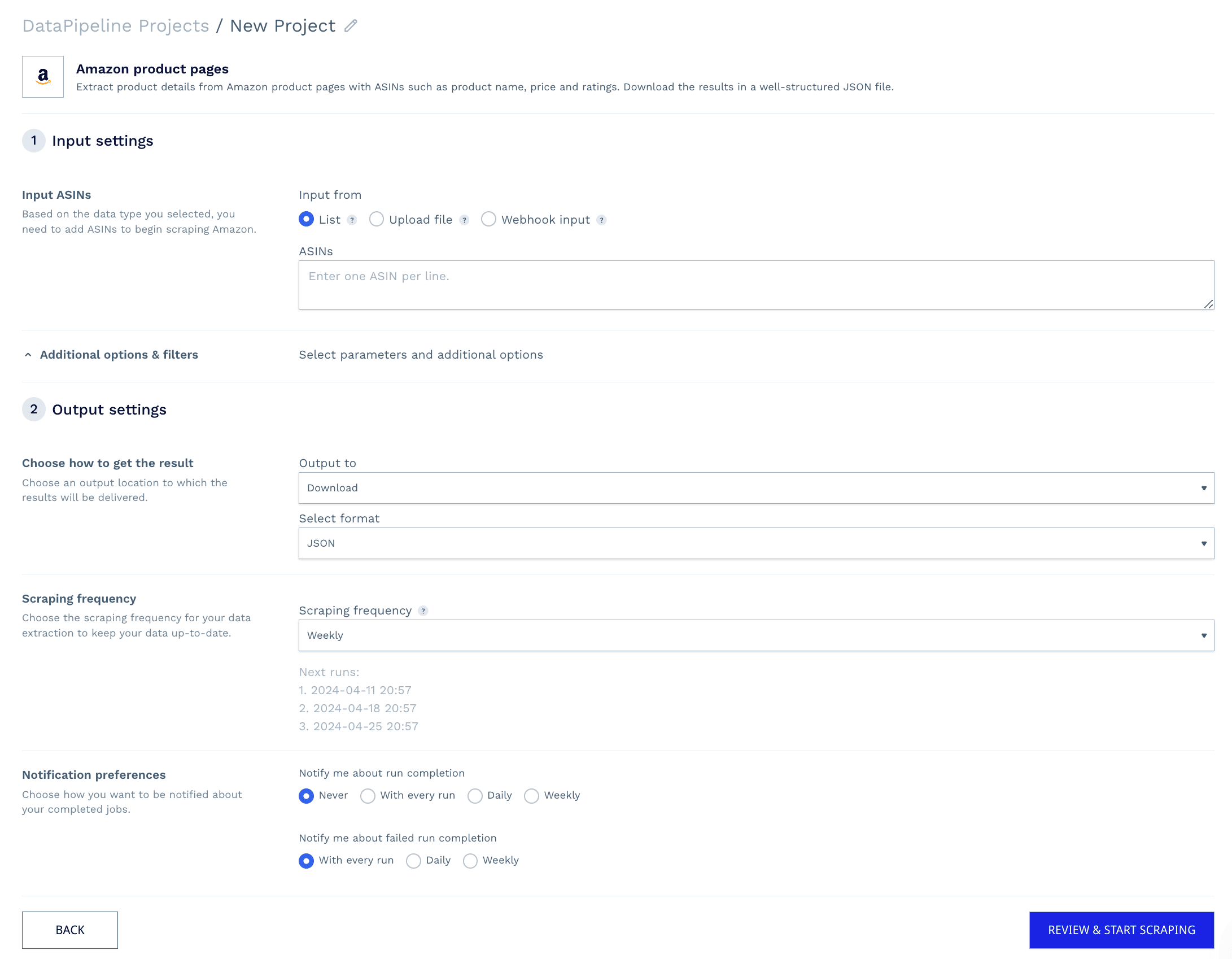
DataPipeline
Yet another feature, still in beta but already significantly improving the user experience for ScraperAPI users, is the DataPipeline. With DataPipeline, users can schedule pre-configured jobs for both custom URLs and structured data endpoints.
Pricing
When it comes to pricing, both services provide generous unlimited free plans that you can utilize without needing to provide a credit card. This is a significant advantage for both ScraperAPI and Apify because users can easily test each service before determining which one best suits their use case. However, the free plan is just one component of each service’s pricing structure. So, let's see what you can get from the price tags of both platforms.
Apify pricing
Apify provides a standard, unlimited free plan that grants you $5 worth of Apify credits per month, allowing you to utilize the platform as you wish. Additionally, for developers, Apify offers a special plan providing $500 worth of credits for just $1 per month, albeit with some usage restrictions. Beyond these, all paid plans offer the flexibility to occasionally exceed your plan limits and pay only for the extra usage, a system referred to as "Pay as you go" by Apify.
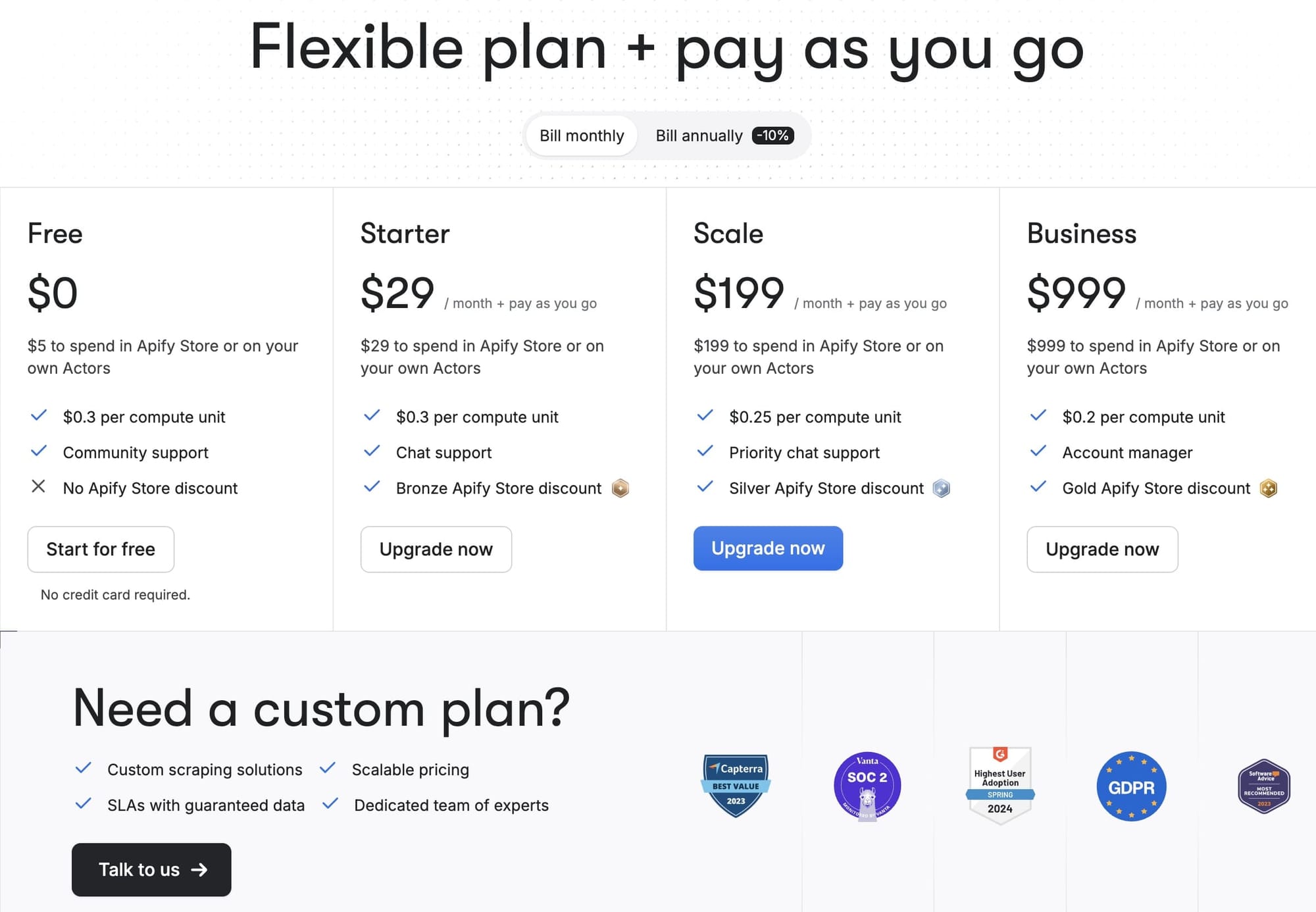
Apify's pricing system is highly detailed and comprehensive. While this level of detail may be beneficial for technical users or those familiar with the platform, it can, admittedly, be somewhat confusing for new users.
Apify credit consumption
As Apify offers a cloud-based solution with a primary emphasis on platform usage, your credits will be used according to your compute units (CU) consumption within the platform. Credit consumption is divided into Proxy usage, storage, Actors, and Data transfer. Although Apify provides a detailed breakdown of costs, accurately predicting your credit consumption before using the service can be challenging.
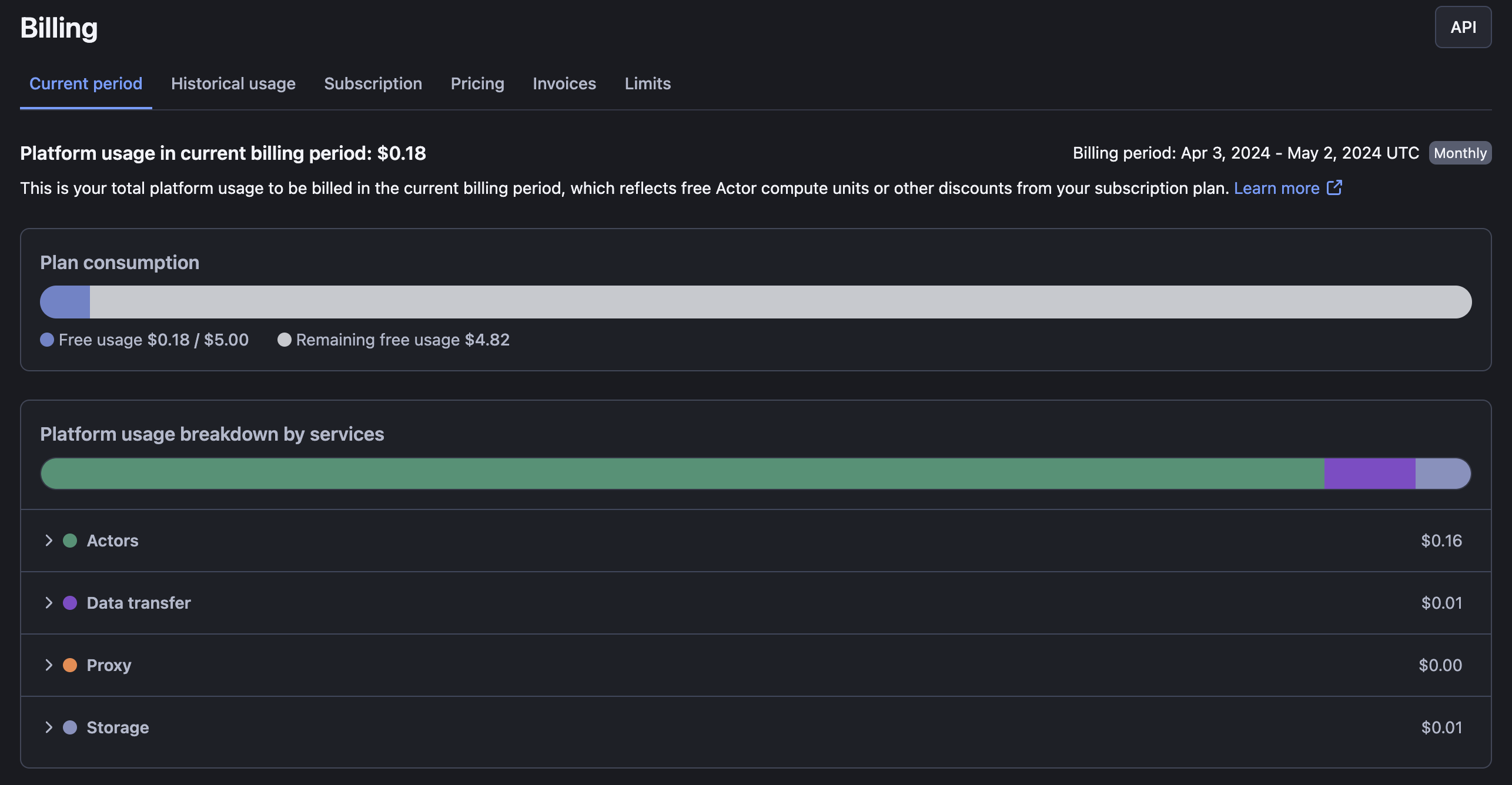
This is why Apify has introduced "pay-per-event" pricing. With this model, an Apify Actor charges for specific actions rather than just results. For example, a scraper that charges $5 per run start and $2 per 1,000 results would cost $15 for 5,000 results. This can make large-scale scraping jobs cheaper in the long run.
ScraperAPI pricing
ScraperAPI offers a special free trial of 5,000 API requests (limited to 7 days), transitioning to their standard free plan of 1,000 API credits thereafter.
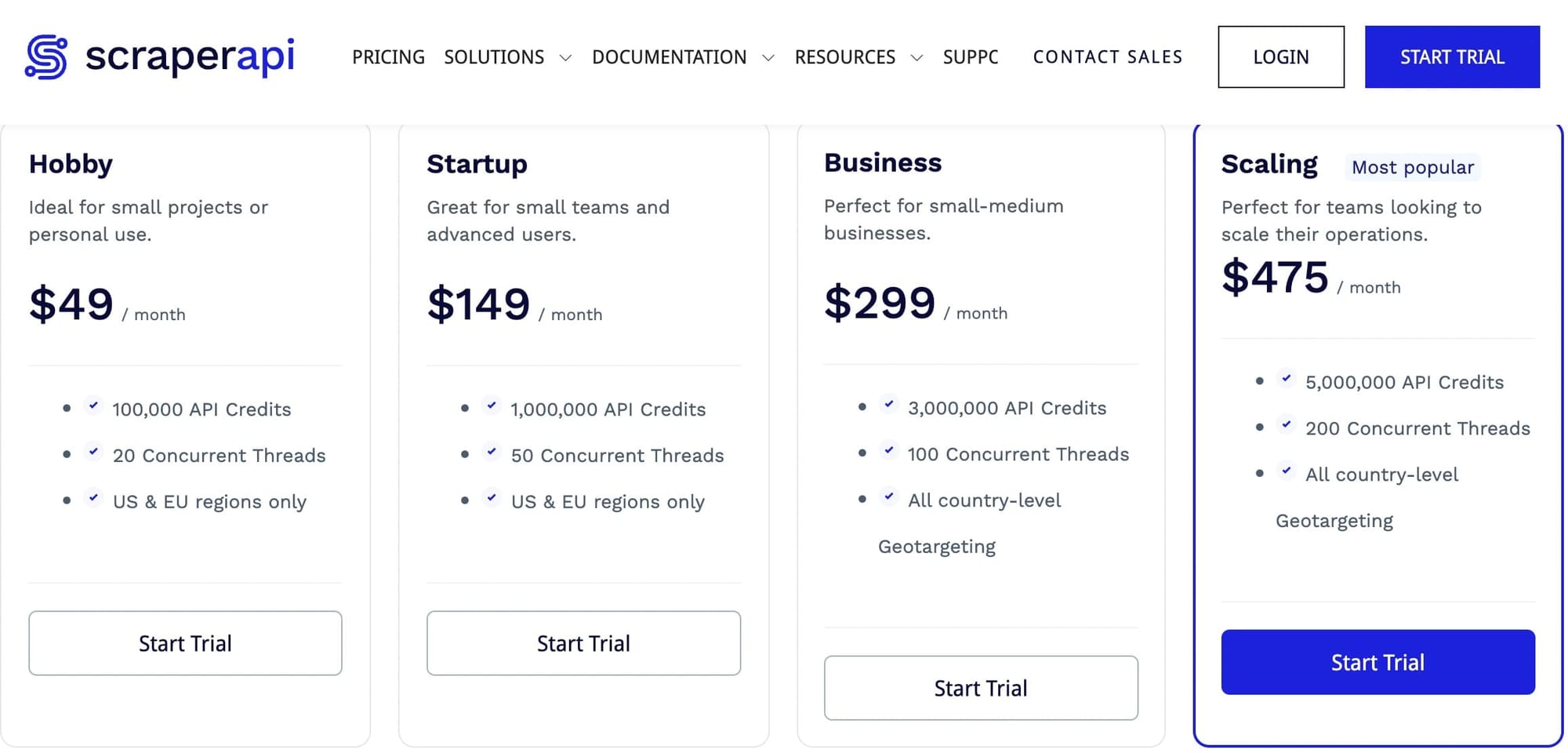
One notable drawback is the limited geotargeting options, restricted to "US" and "EU" on all plans below the Business plan, which comes with a steep price tag of $299/month. This limitation could potentially deter users seeking to scrape regions beyond these without committing to their top-tier plan.
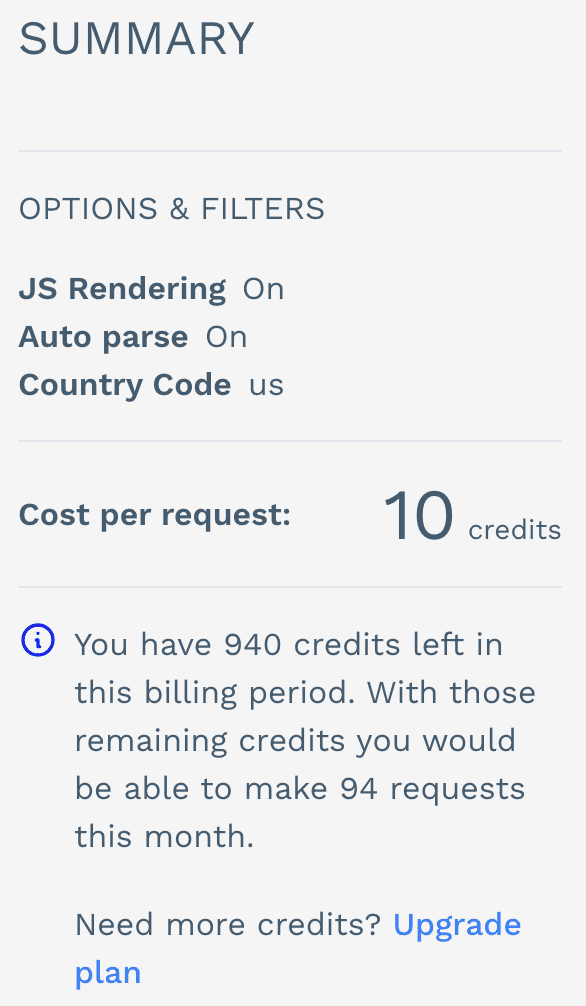
ScraperAPI credit consumption
ScraperAPI charges a predefined amount of credits per request. The amount of credits consumed varies according to the parameters you use in the request. This system is more straightforward than Apify’s, and the ScraperAPI website can help you accurately estimate your API credit consumption even before making the requests.
Apify vs. ScraperAPI pricing - pros & cons
| Comparison | Apify pricing | ScraperAPI pricing |
|---|---|---|
| Pros |
|
|
| Cons |
|
|
Conclusion: should you choose Apify or ScraperAPI?
Both services offer reliable and powerful scraping capabilities. The choice between Apify or ScraperAPI ultimately depends on your user profile and requirements. Overall, Apify provides a wide array of features with greater flexibility within the platform. However, this versatility comes with a steeper learning curve and more complex systems to navigate. Conversely, ScraperAPI excels in simplicity, from setup to pricing structure.
My suggestion is that if you're seeking the most comprehensive web scraping solution and are willing to invest time in learning and adapting to the platform, then Apify is the way to go. Apify also suits seasoned web scraper developers or those eager to delve deeper into web scraping.
On the flip side, if you just want to leverage your existing skills to extract data without the hassle of learning the intricacies of web scraping or adapting to a new service, ScraperAPI might be a better fit, especially if you have a very specific budget and are looking for a service with straightforward pricing structures.
Need a ScraperAPI alternative that's scalable and versatile?
This is the second in a series of articles we commissioned from an external developer (although Percival is a former Apifier). We want to create unbiased reviews of other web scraping platforms and companies as part of our continued evaluation of the web scraping industry.



