Email addresses are still among the most valuable pieces of information, especially in marketing and lead generation. Manually capturing this information at scale is obviously too time-consuming. That's why we'll show you how to automate the process with web scraping.
In this guide, you’ll learn how to build an email scraper in Python that works across any site. We’ll walk you through the entire process, from setting up your project to handling email obfuscation challenges!
If you want a quicker, easier method, and don't need to build a custom scraper, skip to the using pre-built email scrapers section and learn how to scrape emails with Email & Phone Extractor
Complete guide to email scraping
In this tutorial, we'll retrieve emails from the “Wikimedia Foundation Privacy Policy” page:

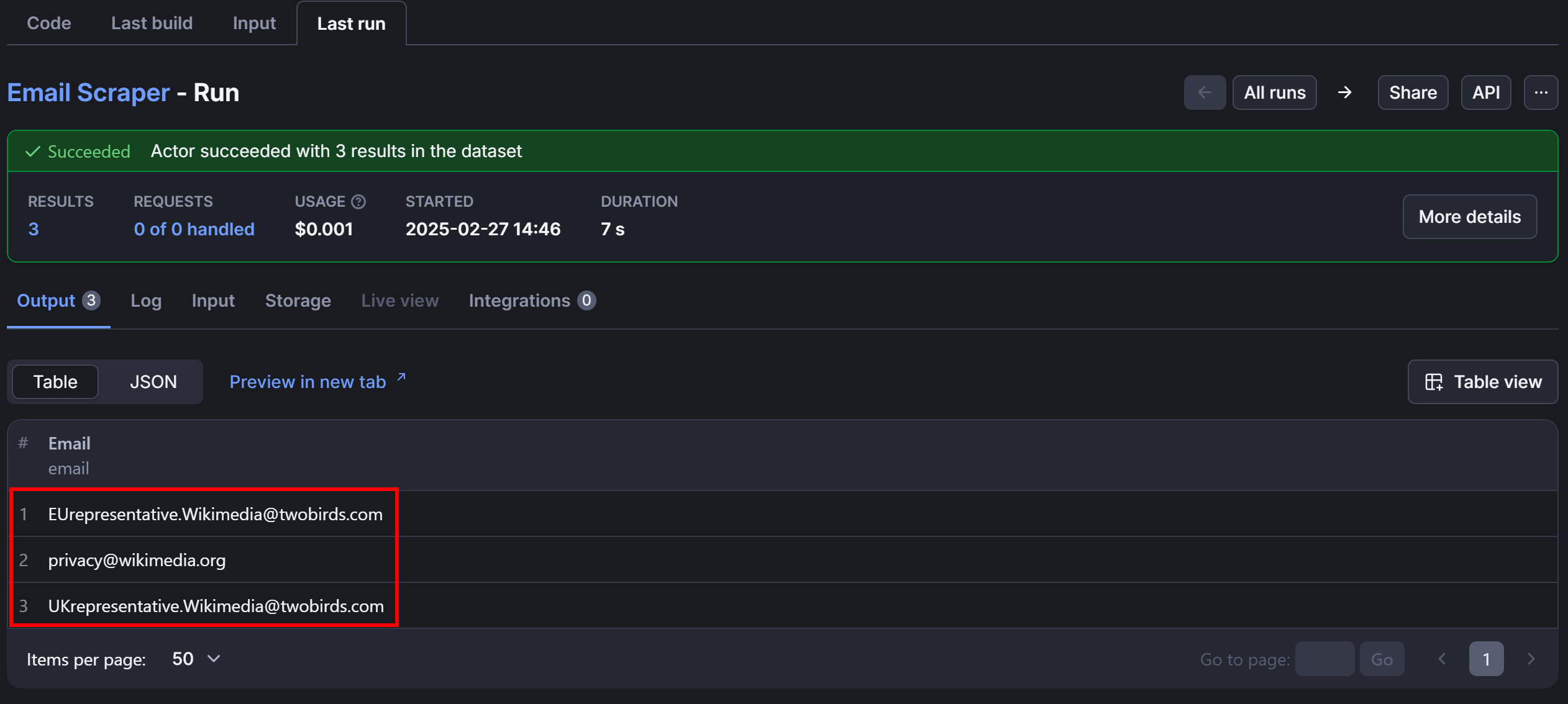
At the time of writing, the page contains these three unique email addresses:
EUrepresentative.Wikimedia@twobirds.comprivacy@wikimedia.orgUKrepresentative.Wikimedia@twobirds.com
The method shown here can be applied to any other site.
We'll walk through the process step by step:
- Prerequisites and project setup
- Understanding email storage on the target site
- Building the basic email scraper
- Exporting the scraped email to CSV
- Complete code
1. Prerequisites and project setup
To follow along with this tutorial, it’s better if you meet these prerequisites:
- A basic understanding of how the web works, including HTTP requests, status codes, and JavaScript rendering
- Familiarity with the DOM, HTML, and CSS selectors
- Basic knowledge of web scraping
- Some experience with Python, async programming, and browser automation
- Awareness of the differences between a static site and a dynamic site
Thanks to its powerful web scraping libraries, Python is the programming language chosen for this guide. For a local setup, you'll need:
- Python 3+ installed
- A Python IDE, such as Visual Studio Code with the Python extension or PyCharm
To create a Python project, create a new folder and initialize a virtual environment inside it:
mkdir email_scraper
cd email_scraper
python -m venv venv
On Windows, activate the virtual environment with:
venv\\Scripts\\activate
On Linux/macOS, run:
source venv/bin/activate
In an activated virtual environment, install the libraries used for email scraping with:
pip install httpx beautifulsoup4 lxml
In particular, the two dependencies are:
httpx: A fast, modern HTTP client for making web requestsbeautifulsoup4: A library for parsing HTML and extracting datalxml: The underlying HTML parsing library used by Beautiful Soup
Now, load the project in your IDE and create a scraper.py file where to add the scraping logic.
If you instead prefer a cloud-based approach for building your email scraper, consider utilizing Apify. That eliminates the need for local installation and configuration. In this case, the additional requirements are:
- An Apify account
- A basic understanding of how Apify works
To initialize a new email scraping project on Apify:
- Log in
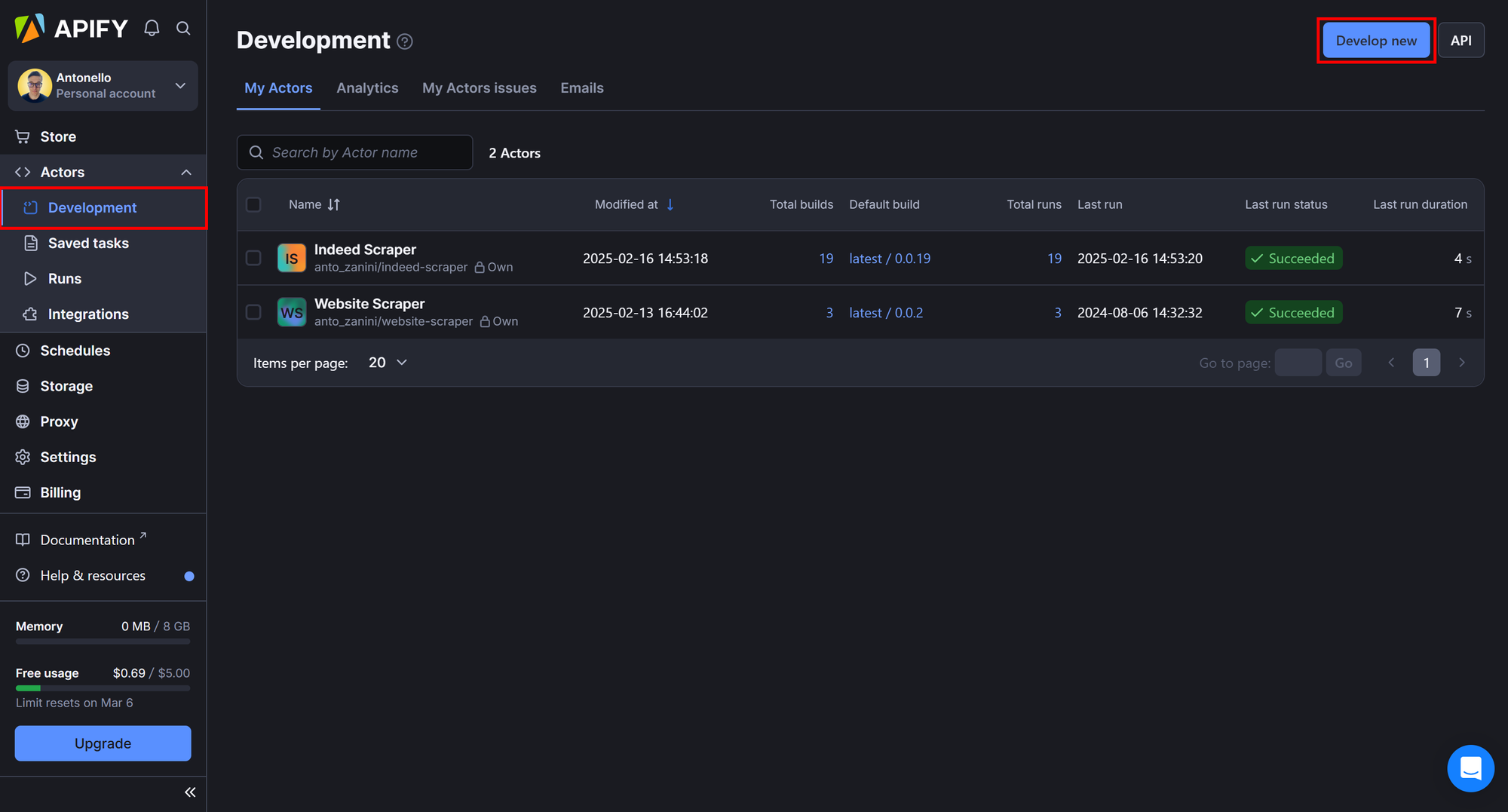
- Reach the Console
- Under the "Actors" dropdown, select "Development" and click the “Develop new” button:
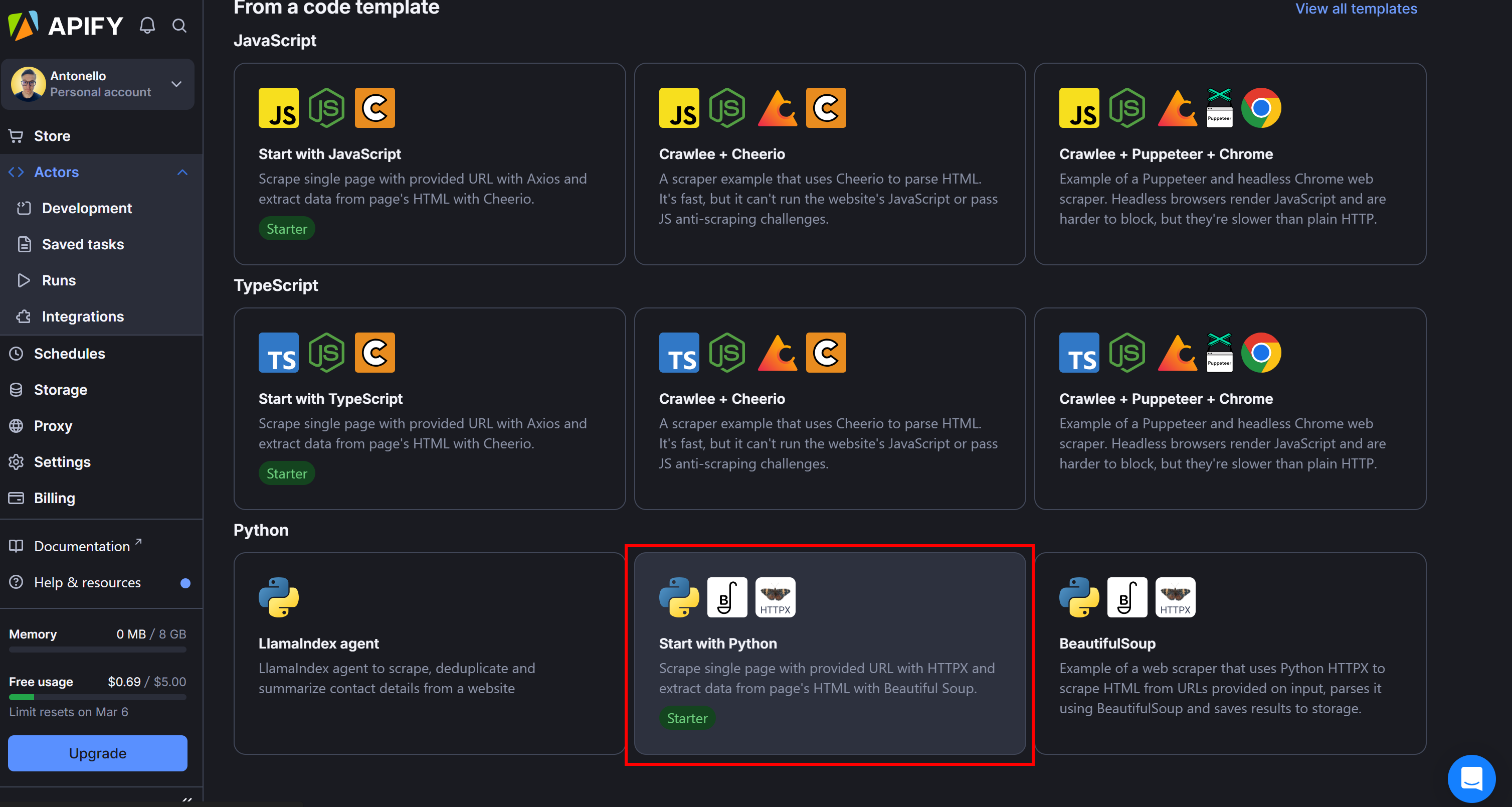
Next, choose the "Start with Python" template, which sets up a Python Actor using HTTPX and Beautiful Soup:
Inspect the starter project code and select "Use this template" to fork it:
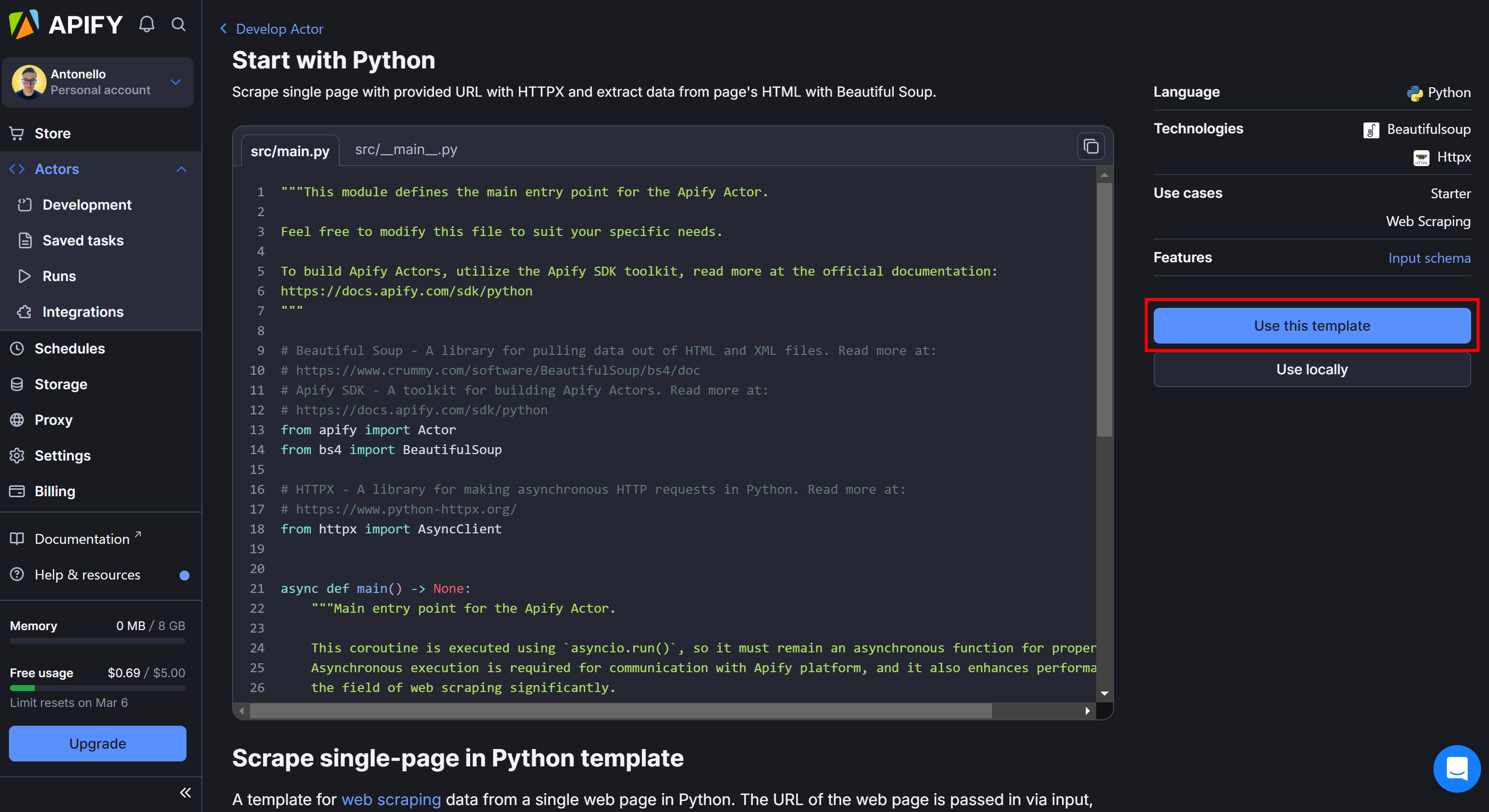
You’ll then be redirected to an online IDE, where you can customize your Actor and write your code directly in the cloud—no need to install libraries or configure an environment locally:
2. Understanding email storage on the target site
Before diving into email extraction logic, it makes sense to take a step back and study how emails are typically presented on web pages. In most cases, emails can be found on the following pages/sections:
- Contact Us
- About
- Footer section (common across all pages of a site)
- Privacy Policy
- Terms and Conditions
- Career/Jobs pages
- Help or Support pages
Typically, emails are displayed as plain text within HTML elements like this:
<p>Contact us at <span class="email">support@example.com</span></p>
Another common format is using mailto: links, which open the user's default email client when clicked:
<a href="mailto:support@example.com">Email us</a>
In this case, the email may not appear as plain text on the page but instead be embedded within the href attribute of an <a> node.
In general, when you see an email address or a call-to-action (CTA) for email communication on a web page, it's helpful to right-click on it in your browser and select "Inspect" to view its HTML structure in DevTools:
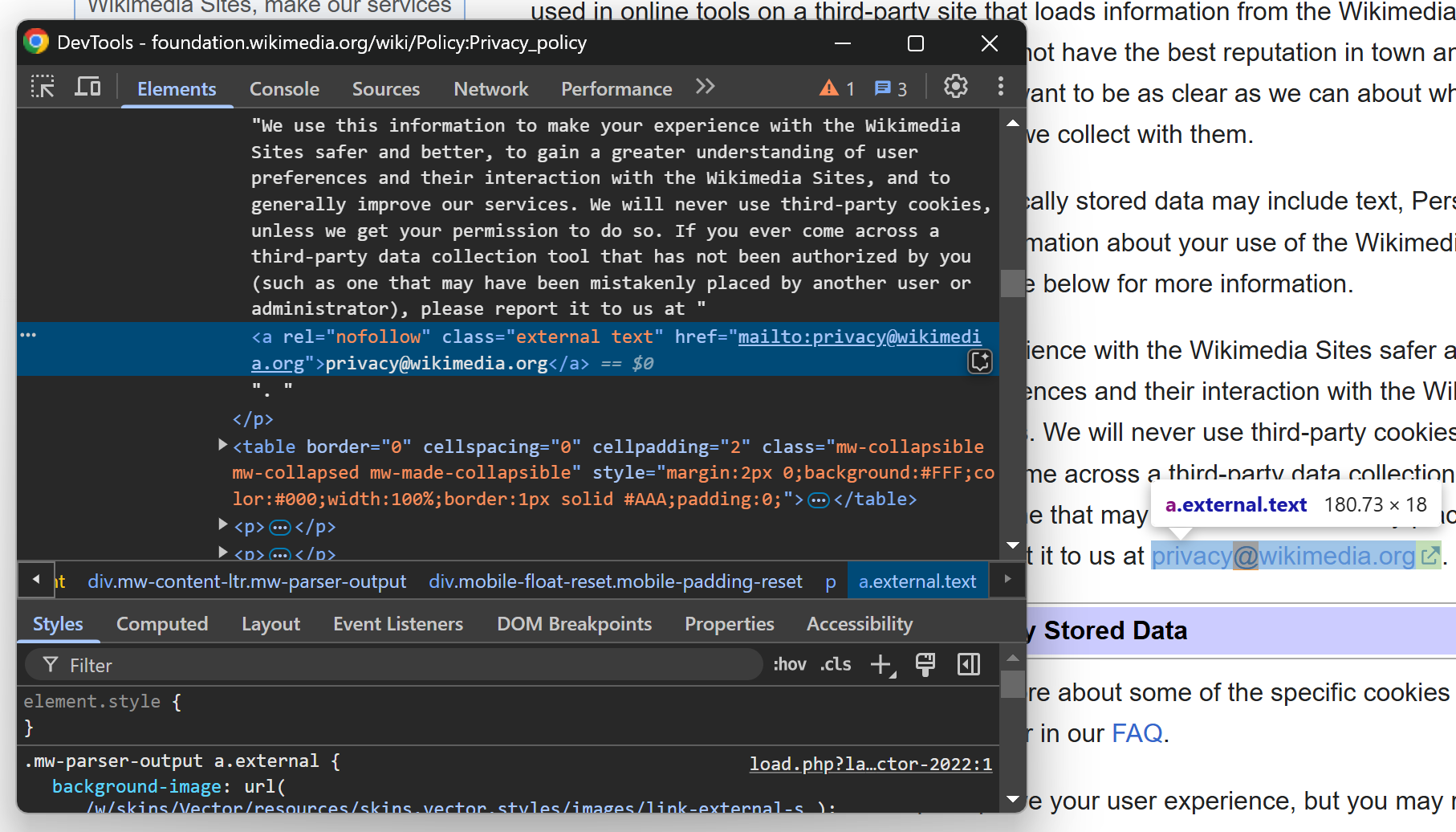
As you can see, this allows you to determine whether the email is directly present in the HTML or dynamically inserted using JavaScript.
If you're using a static HTML parser, compare the HTML structure in DevTools with the actual source code returned by the server. To do that, right-click anywhere on the page and select "View page source", then search for the email address:
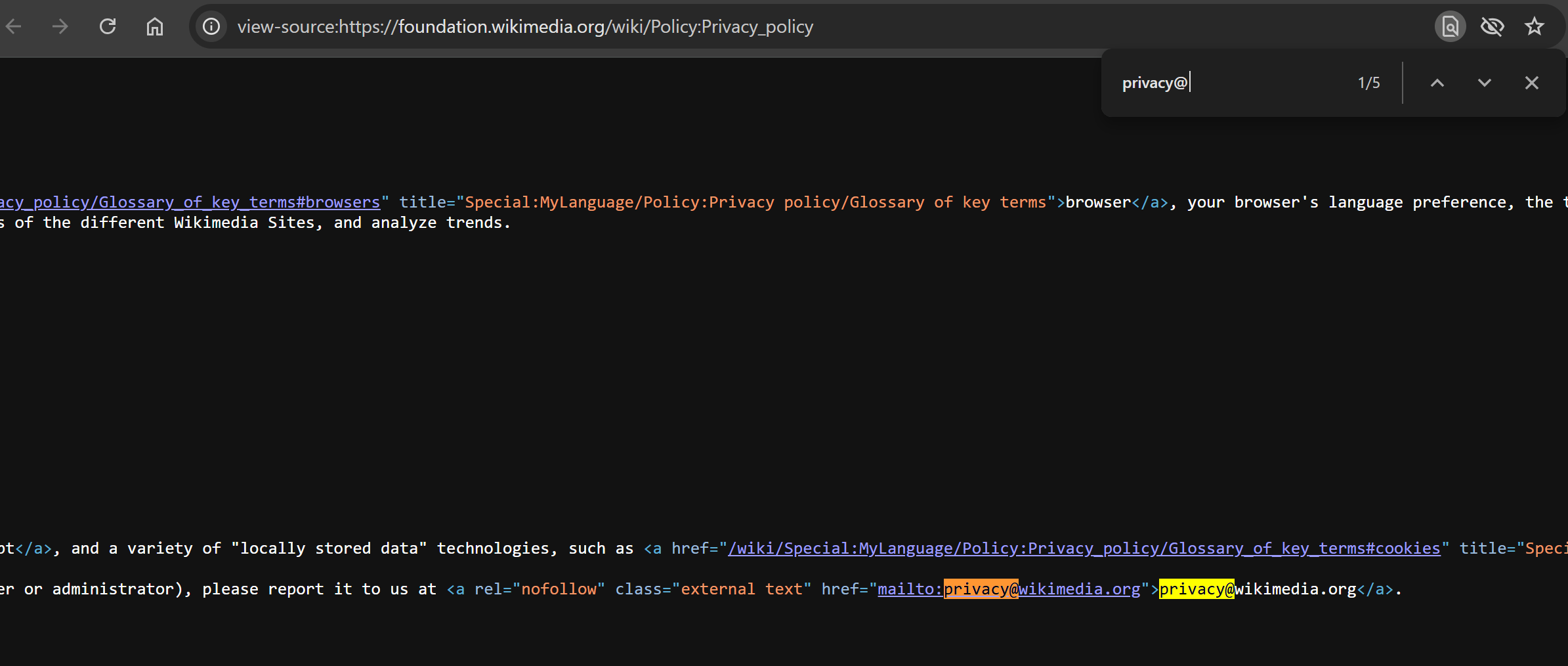
This final step is important because the "Inspect" tool shows the rendered DOM, which may include JavaScript modifications. In contrast, "View page source" displays the original HTML returned by the server—which is what a static scraper (like Beautiful Soup) will process.
By comparing both, you can determine whether an email is directly available in the HTML or if JavaScript processing is needed to extract it.
3. Building the basic email scraper
To extract email addresses from a webpage using Python, follow this procedure:
- Retrieve the HTML document of the page using HTTPX.
- Parse the HTML content with Beautiful Soup.
- Search for text nodes containing patterns that match typical email formats.
- Identify
<a>nodes withmailto:links. - Extract email addresses from these elements.
- Store the scraped emails in a set to avoid duplicates.
Before implementing the email extraction logic, set up the basic structure of your scraper:
import asyncio
import httpx
from bs4 import BeautifulSoup
async def main():
# The URL of your target page
url = "https://foundation.wikimedia.org/wiki/Policy:Privacy_policy" # Replace with your the target URL
# Make an HTTP GET request to the target server
async with httpx.AsyncClient() as client:
response = await client.get(url, follow_redirects=True)
# Parse the HTML document returned by the server
soup = BeautifulSoup(response.content, 'lxml')
# Scraping logic...
# Run the asyncio event loop
if __name__ == "__main__":
asyncio.run(main())
Before extracting emails, it's important to recognize valid email structures. A typical email address follows a format like this:
user@domain.com
According to RFC 5322, the vast majority of email addresses can be matched using this regex:
(?:[a-z0-9!#$%&'*+/=?^_`{|}~-]+(?:\\.[a-z0-9!#$%&'*+/=?^_`{|}~-]+)*|"(?:[\\x01-\\x08\\x0b\\x0c\\x0e-\\x1f\\x21\\x23-\\x5b\\x5d-\\x7f]|\\\\[\\x01-\\x09\\x0b\\x0c\\x0e-\\x7f])*")@(?:(?:[a-z0-9](?:[a-z0-9-]*[a-z0-9])?\\.)+[a-z0-9](?:[a-z0-9-]*[a-z0-9])?|\\[(?:(?:25[0-5]|2[0-4][0-9]|[01]?[0-9][0-9]?)\\.){3}(?:25[0-5]|2[0-4][0-9]|[01]?[0-9][0-9]?|[a-z0-9-]*[a-z0-9]:(?:[\\x01-\\x08\\x0b\\x0c\\x0e-\\x1f\\x21-\\x5a\\x53-\\x7f]|\\\\[\\x01-\\x09\\x0b\\x0c\\x0e-\\x7f])+)\\])
You can use the re module to extract email addresses from text using the above regex as in the example below:
import re
EMAIL_REGEX = r"""(?:[a-z0-9!#$%&'*+/=?^_`{|}~-]+(?:\\.[a-z0-9!#$%&'*+/=?^_`{|}~-]+)*|"(?:[\\x01-\\x08\\x0b\\x0c\\x0e-\\x1f\\x21\\x23-\\x5b\\x5d-\\x7f]|\\\\[\\x01-\\x09\\x0b\\x0c\\x0e-\\x7f])*")@(?:(?:[a-z0-9](?:[a-z0-9-]*[a-z0-9])?\\.)+[a-z0-9](?:[a-z0-9-]*[a-z0-9])?|\\[(?:(?:25[0-5]|2[0-4][0-9]|[01]?[0-9][0-9]?)\\.){3}(?:25[0-5]|2[0-4][0-9]|[01]?[0-9][0-9]?|[a-z0-9-]*[a-z0-9]:(?:[\\x01-\\x08\\x0b\\x0c\\x0e-\\x1f\\x21-\\x5a\\x53-\\x7f]|\\\\[\\x01-\\x09\\x0b\\x0c\\x0e-\\x7f])+)\\])"""
text = "You can contact us at support@example.com or info@domain.org."
emails = re.findall(EMAIL_REGEX, text)
print(emails) # Output: ['support@example.com', 'info@domain.org']
The email regex from RFC 5322 is stored in the EMAIL_REGEX variable and is then passed to the re.findall() function, which scans the provided text and extracts all occurrences that match the email pattern.
Now, encapsulate the logic above in a dedicated email extraction function:
def extract_emails(soup):
# Where to store the scraped emails
emails = set()
# Get all text content from the page
text_content = soup.get_text()
EMAIL_REGEX = r"""(?:[a-z0-9!#$%&'*+/=?^_`{|}~-]+(?:\\.[a-z0-9!#$%&'*+/=?^_`{|}~-]+)*|"(?:[\\x01-\\x08\\x0b\\x0c\\x0e-\\x1f\\x21\\x23-\\x5b\\x5d-\\x7f]|\\\\[\\x01-\\x09\\x0b\\x0c\\x0e-\\x7f])*")@(?:(?:[a-z0-9](?:[a-z0-9-]*[a-z0-9])?\\.)+[a-z0-9](?:[a-z0-9-]*[a-z0-9])?|\\[(?:(?:25[0-5]|2[0-4][0-9]|[01]?[0-9][0-9]?)\\.){3}(?:25[0-5]|2[0-4][0-9]|[01]?[0-9][0-9]?|[a-z0-9-]*[a-z0-9]:(?:[\\x01-\\x08\\x0b\\x0c\\x0e-\\x1f\\x21-\\x5a\\x53-\\x7f]|\\\\[\\x01-\\x09\\x0b\\x0c\\x0e-\\x7f])+)\\])"""
# Use regex to find all email addresses in the text content
found_emails = re.findall(EMAIL_REGEX, text_content, text_content, re.IGNORECASE)
# Add the scraped emails to the set
for email_address in found_emails:
emails.add(email_address)
return emails
This works by first extracting all the text content from the page using BeautifulSoup's get_text() method. Then, it passes this text to the regular expression for detecting email addresses, returning all the unique matches found.
To implement the "mailto:" approach, write the following lines of code:
# Select all <a> elements whose "href" attribute starts with "mailto:"
mailto_links = soup.find_all('a', href=re.compile(r"^mailto:"))
for link in mailto_links:
# Extract the email address from the list
email_address = link.get('href').split(':')[1]
# Add the new emails to the current list
found_emails.append(email_address)
This snippet harnesses soup.find_all() to locate all <a> elements on the page whose href attribute starts with mailto:using a regex, For each of these links, it extracts the email address by splitting the href value at the colon (:) and taking the second part. Finally, the email addresses are added to the found_emails list produced earlier.
Next, it makes sense to validate the scraped emails using a dedicated library. The Python Standard Library includes a built-in email package that provides RFC-backed validation capabilities. Take advantage of it to validate the raw emails extracted with this logic:
# Verify that the emails are valid before adding them to the set
for email_address in found_emails:
try:
# Check if the email is valid
email.utils.parseaddr(email_address)
# Add the email to the set
emails.add(email_address)
except:
# Here you can log any error or handle them as you prefer...
pass
This code iterates over each email address in the found_emails list and uses the email.utils.parseaddr() method to check if the email address is valid with a try-except block. If the email address is valid, it is added to the emails set.
This way, you can be sure that all the scraped email addresses are valid according to RFC standards.
So, the final snippet for the email parsing function will look like this:
def extract_emails(soup):
# Where to store the scraped emails
emails = set()
# Get all text content from the page
text_content = soup.get_text()
EMAIL_REGEX = r"""(?:[a-z0-9!#$%&'*+/=?^_`{|}~-]+(?:\\.[a-z0-9!#$%&'*+/=?^_`{|}~-]+)*|"(?:[\\x01-\\x08\\x0b\\x0c\\x0e-\\x1f\\x21\\x23-\\x5b\\x5d-\\x7f]|\\\\[\\x01-\\x09\\x0b\\x0c\\x0e-\\x7f])*")@(?:(?:[a-z0-9](?:[a-z0-9-]*[a-z0-9])?\\.)+[a-z0-9](?:[a-z0-9-]*[a-z0-9])?|\\[(?:(?:25[0-5]|2[0-4][0-9]|[01]?[0-9][0-9]?)\\.){3}(?:25[0-5]|2[0-4][0-9]|[01]?[0-9][0-9]?|[a-z0-9-]*[a-z0-9]:(?:[\\x01-\\x08\\x0b\\x0c\\x0e-\\x1f\\x21-\\x5a\\x53-\\x7f]|\\\\[\\x01-\\x09\\x0b\\x0c\\x0e-\\x7f])+)\\])"""
# Use regex to find all email addresses in the text content
found_emails = re.findall(EMAIL_REGEX, text_content, text_content, re.IGNORECASE)
# Select all <a> elements whose "href" attribute starts with "mailto:"
mailto_links = soup.find_all('a', href=re.compile(r"^mailto:"))
for link in mailto_links:
# Extract the email address from the list
email_address = link.get('href').split(':')[1]
# Add the new emails to the current list
found_emails.append(email_address)
# Verify that the emails are valid before adding them to the set
for email_address in found_emails:
try:
# Check if the email is valid
email.utils.parseaddr(email_address)
# Add the email to the set
emails.add(email_address)
except:
# Here you can log any error or handle them as you prefer...
pass
return list(emails)
To make it work, do not forget to import email and re:
import re
import email
You can call the extract_emails() function in the Python script after HTML parsing with:
emails = extract_emails(soup)
4. Exporting the scraped email to CSV
You now have the scraped emails stored in a Python list. You can export them into a simple CSV file where each email address occupies a row as follows:
with open('emails.csv', mode='w', newline='') as file:
writer = csv.writer(file)
# Write the header
writer.writerow(['email'])
# Write each email in a new row
for email in emails:
writer.writerow([email])
Do not forget to import the csv package from the Python Standard Library:
import csv
If you're working on Apify, you don't need to do that manually since data export in multiple formats is handled for you. All you need to do is push the data to the Actor's dataset using the push_data() method:
for email in emails:
await Actor.push_data({'email': email})
Note that you need to iterate over the emails list and create objects, as the push_data() method only accepts objects.
5. Complete code
This is what your local Python email scraper should look like:
import asyncio
import httpx
from bs4 import BeautifulSoup
import re
import email
import csv
def extract_emails(soup):
# Where to store the scraped emails
emails = set()
# Get all text content from the page
text_content = soup.get_text()
EMAIL_REGEX = r"""(?:[a-z0-9!#$%&'*+/=?^_`{|}~-]+(?:\\.[a-z0-9!#$%&'*+/=?^_`{|}~-]+)*|"(?:[\\x01-\\x08\\x0b\\x0c\\x0e-\\x1f\\x21\\x23-\\x5b\\x5d-\\x7f]|\\\\[\\x01-\\x09\\x0b\\x0c\\x0e-\\x7f])*")@(?:(?:[a-z0-9](?:[a-z0-9-]*[a-z0-9])?\\.)+[a-z0-9](?:[a-z0-9-]*[a-z0-9])?|\\[(?:(?:25[0-5]|2[0-4][0-9]|[01]?[0-9][0-9]?)\\.){3}(?:25[0-5]|2[0-4][0-9]|[01]?[0-9][0-9]?|[a-z0-9-]*[a-z0-9]:(?:[\\x01-\\x08\\x0b\\x0c\\x0e-\\x1f\\x21-\\x5a\\x53-\\x7f]|\\\\[\\x01-\\x09\\x0b\\x0c\\x0e-\\x7f])+)\\])"""
# Use regex to find all email addresses in the text content
found_emails = re.findall(EMAIL_REGEX, text_content, text_content, re.IGNORECASE)
# Select all <a> elements whose "href" attribute starts with "mailto:"
mailto_links = soup.find_all('a', href=re.compile(r"^mailto:"))
for link in mailto_links:
# Extract the email address from the list
email_address = link.get('href').split(':')[1]
# Add the new emails to the current list
found_emails.append(email_address)
# Verify that the emails are valid before adding them to the set
for email_address in found_emails:
try:
# Check if the email is valid
email.utils.parseaddr(email_address)
# Add the email to the set
emails.add(email_address)
except:
# Here you can log any error or handle them as you prefer...
pass
return list(emails)
async def main():
# The URL of your target page
url = "https://foundation.wikimedia.org/wiki/Policy:Privacy_policy" # Replace with your the target URL
# Make an HTTP GET request to the target server
async with httpx.AsyncClient() as client:
response = await client.get(url, follow_redirects=True)
# Parse the HTML document returned by the server
soup = BeautifulSoup(response.content, 'lxml')
# Scrape email addresses from the page
emails = extract_emails(soup)
# Export the scraped data to CSV
with open('emails.csv', mode='w', newline='') as file:
writer = csv.writer(file)
# Write the header
writer.writerow(['email'])
# Write each email in a new row
for email in emails:
writer.writerow([email])
# Run the asyncio event loop
if __name__ == "__main__":
asyncio.run(main())
Execute it with the following command:
python scraper.py
After running the script, the result will be an emails.csv file containing the scraped email addresses:
If you worked with Apify, the equivalent final code for your email scraping Actor is:
"""This module defines the main entry point for the Apify Actor.
Feel free to modify this file to suit your specific needs.
To build Apify Actors, utilize the Apify SDK toolkit, read more at the official documentation:
<https://docs.apify.com/sdk/python>
"""
# Beautiful Soup - A library for pulling data out of HTML and XML files. Read more at:
# <https://www.crummy.com/software/BeautifulSoup/bs4/doc>
# Apify SDK - A toolkit for building Apify Actors. Read more at:
# <https://docs.apify.com/sdk/python>
from apify import Actor
from bs4 import BeautifulSoup
# HTTPX - A library for making asynchronous HTTP requests in Python. Read more at:
# <https://www.python-httpx.org/>
from httpx import AsyncClient
import re
import email
def extract_emails(soup):
# Where to store the scraped emails.
emails = set()
# Get all text content from the page.
text_content = soup.get_text()
EMAIL_REGEX = r"""(?:[a-z0-9!#$%&'*+/=?^_`{|}~-]+(?:\\.[a-z0-9!#$%&'*+/=?^_`{|}~-]+)*|"(?:[\\x01-\\x08\\x0b\\x0c\\x0e-\\x1f\\x21\\x23-\\x5b\\x5d-\\x7f]|\\\\[\\x01-\\x09\\x0b\\x0c\\x0e-\\x7f])*")@(?:(?:[a-z0-9](?:[a-z0-9-]*[a-z0-9])?\\.)+[a-z0-9](?:[a-z0-9-]*[a-z0-9])?|\\[(?:(?:25[0-5]|2[0-4][0-9]|[01]?[0-9][0-9]?)\\.){3}(?:25[0-5]|2[0-4][0-9]|[01]?[0-9][0-9]?|[a-z0-9-]*[a-z0-9]:(?:[\\x01-\\x08\\x0b\\x0c\\x0e-\\x1f\\x21-\\x5a\\x53-\\x7f]|\\\\[\\x01-\\x09\\x0b\\x0c\\x0e-\\x7f])+)\\])"""
# Use regex to find all email addresses in the text content.
found_emails = re.findall(EMAIL_REGEX, text_content, text_content, re.IGNORECASE)
# Select all <a> elements whose "href" attribute starts with "mailto:"
mailto_links = soup.find_all('a', href=re.compile(r"^mailto:"))
for link in mailto_links:
# Extract the email address from the list.
email_address = link.get('href').split(':')[1]
# Add the new emails to the current list.
found_emails.append(email_address)
# Verify that the emails are valid before adding them to the set.
for email_address in found_emails:
try:
# Check if the email is valid.
email.utils.parseaddr(email_address)
# Add the email to the set.
emails.add(email_address)
except:
# Here you can log any error or handle them as you prefer...
pass
return list(emails)
async def main() -> None:
"""Main entry point for the Apify Actor.
This coroutine is executed using `asyncio.run()`, so it must remain an asynchronous function for proper execution.
Asynchronous execution is required for communication with Apify platform, and it also enhances performance in
the field of web scraping significantly.
"""
async with Actor:
# Retrieve the input object for the Actor. The structure of input is defined in input_schema.json.
actor_input = await Actor.get_input() or {'url': '<https://apify.com/>'}
url = actor_input.get('url')
if not url:
raise ValueError('MiRssing "url" attribute in input!')
# Create an asynchronous HTTPX client for making HTTP requests.
async with AsyncClient() as client:
# Fetch the HTML content of the page, following redirects if necessary.
Actor.log.info(f'Sending a request to {url}')
response = await client.get(url, follow_redirects=True)
# Parse the HTML content using Beautiful Soup and lxml parser.
soup = BeautifulSoup(response.content, 'lxml')
# Scrape email addresses from the page.
emails = extract_emails(soup)
# Save the extracted emails to the dataset, which is a table-like storage.
for email in emails:
await Actor.push_data({'email': email})
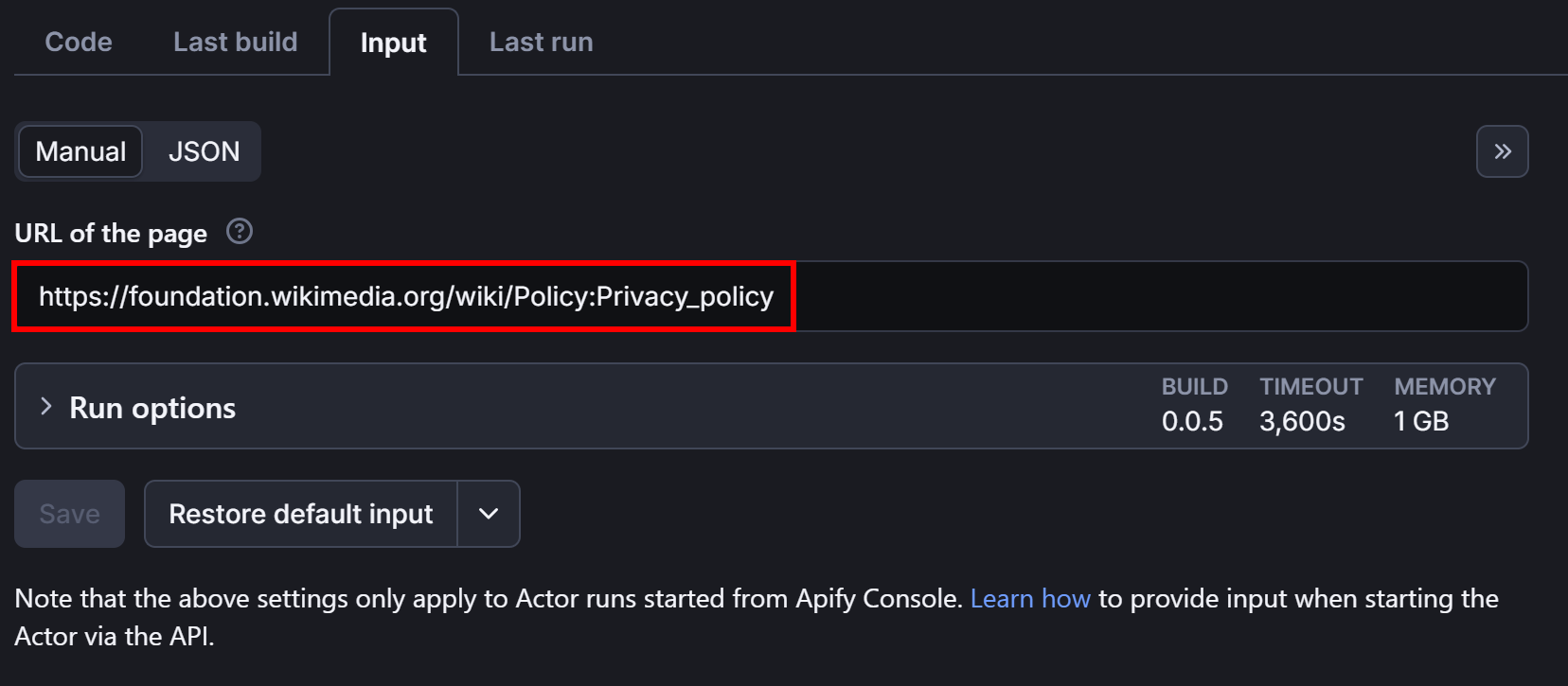
Before launching it, configure the URL where the Actor will operate in the "Input" section:
Once configured, start the Actor by pressing the "Start" button:
The result will be the same as before:
The main difference is that you can easily export the scraped data in various formats such as JSON, CSV, Excel, HTML Table, RSS, and more, or even expose it via an API:
Et voilà! You’ve successfully performed email scraping in Python.
Next steps: Scaling and optimization
This tutorial has covered the basics of web scraping emails. To enhance your script, consider implementing these advanced techniques:
- Handle multiple pages: In some cases, your email scraper may not know in advance which pages contain the email addresses. To address that limitation, you need to extend your logic to crawl all the links on a given site, iterating through each page (possibly in parallel). For step-by-step guidance, check out our blog post on web crawling in Python.
- Avoid rate-limiting issues: If you implement the above technique, your script will make many requests to the same site, potentially triggering rate-limiting issues and leading to blocks or IP bans. To avoid this, always respect the
robots.txtfile for ethical crawling and integrate proxies to distribute requests. This is easy to do if you're using Apify, as explained in the official documentation. - Add logging: Since the script operates autonomously as an email scraping bot, adding logging will help track its progress. Log which pages it has visited, how many emails it has retrieved, which invalid emails were discarded, and more.
- Introduce customizations: Currently, the target page in the local script is hardcoded. Just like it happens on your Actor on Apify, it would be great to enable configurations to be read from the command line or, if using Apify, via the input schema.
Email scraping challenges and solutions
Many email obfuscation techniques have been developed over the years to prevent scrapers from extracting emails for spam or other purposes.
Email obfuscation, the practice of disguising email addresses to make them harder for bots to detect while keeping them visible to humans, is one of the biggest challenges in email scraping.
Below, we’ll explore the three most common email obfuscation techniques and how to bypass them. For further reading, refer to Spencer Mortensen’s blog.
Challenge #1: AT and DOT format
Instead of displaying an email address in its raw format (e.g., user@example.com), websites often replace symbols with words to prevent direct scraping. One of the most common formats is:
user [at] example [dot] com
or:
user[at]example[dot]com
Similarly, some variations include just [at]:
user[at]example.com
Or just [dot]:
user@example[dot]com
To extract emails in these formats, you can this custom regular expression to detect and clean them:
[a-z0-9.+-]+(@|\\s*\\[\\s*at\\s*\\]\\s*)[a-za-z0-9._-]+(\\.|\\s*\\[\\s*dot\\s*\\]\\s*)[a-z]*
As you can see, this regex works like a charm:
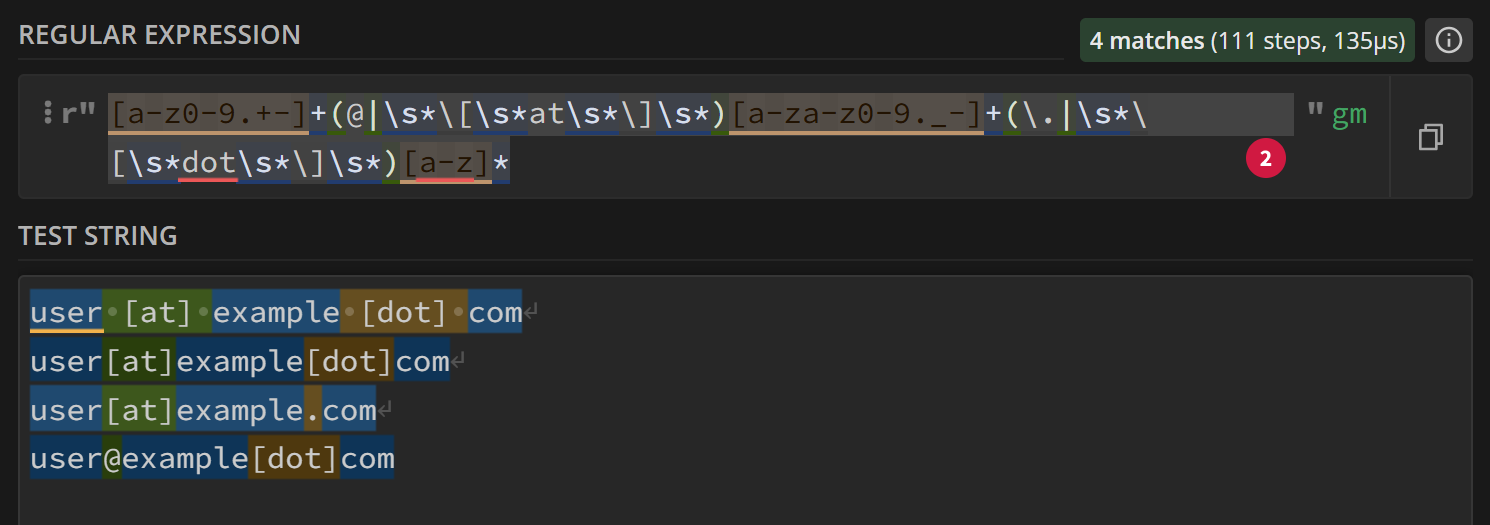
In detail, you can extract the three matched groups from the regex and use them to reconstruct standard email addresses:
import re
# Replace obfuscated parts with proper characters
def replace_match(match):
return f"{match.group(1)}@{match.group(2)}.{match.group(3)}"
def clean_obfuscated_email(text):
# Regular expression to detect obfuscated email patterns
pattern = r'[a-z0-9.+-]+(@|\\s*\\[\\s*at\\s*\\]\\s*)[a-za-z0-9._-]+(\\.|\\s*\\[\\s*dot\\s*\\]\\s*)[a-z]*'
# Find and clean obfuscated emails
return re.sub(pattern, replace_match, text, flags=re.IGNORECASE)
# sample text with emails in all formats of interest
text = """
Contact us at user [at] example [dot] com or support[at]example[dot]com.
For sales, email sales@example[dot]org.
"""
cleaned_text = clean_obfuscated_email(text)
print(cleaned_text)
The result of the above script will be:
Contact us at user@example.com or support@example.com.
For sales, email sales@example.org.
The pre-processed text can then be passed to the email scraping function built earlier.
Challenge #2: JavaScript-rendered emails
Some web pages use JavaScript to assemble and render email addresses dynamically in the browser. For example, they use JS scripts like this:
<script>
// select the "email" element
const emailElement = document.getElementById("email");
// construct the email dynamically to prevent scraping
const user = "user";
const domain = "example";
const tld = "com";
// populate the email element
emailElement.textContent = `${user}@${domain}.${tld}`;
</script>
This makes it difficult for traditional scrapers, like the one we built here, since they can only interact with static HTML documents.
The solution for scraping JavaScript-rendered emails is to use a browser automation tool like Playwright, which can execute JavaScript. Find out more in our tutorial on how to scrape the web with Playwright.
To demonstrate the effectiveness of this approach, let's target the “Contact Us" page from the Yellow Pages site:
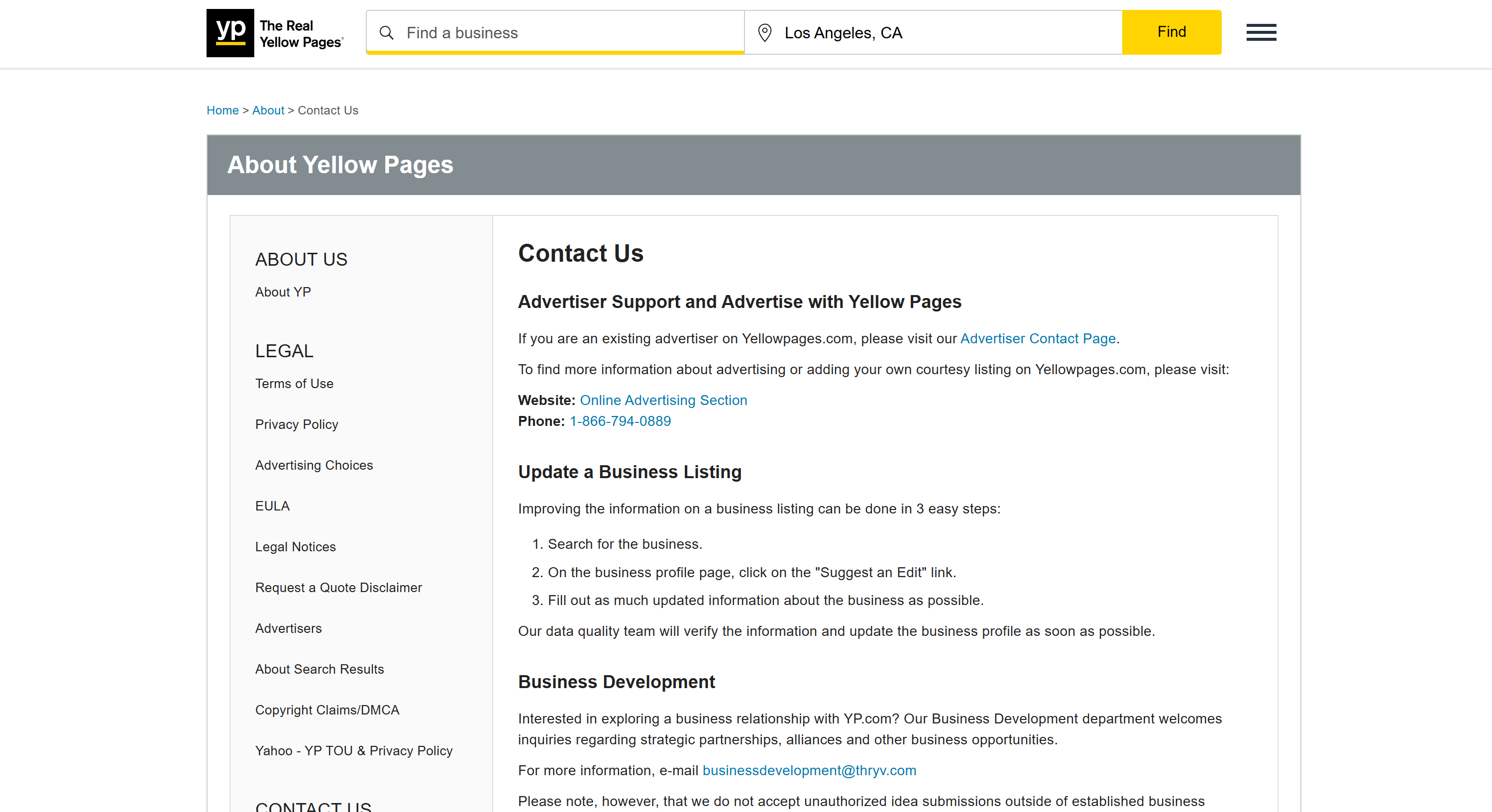
This page contains an email address, but if you search for it in the page’s source code, you won't find it because it is dynamically added via JavaScript:
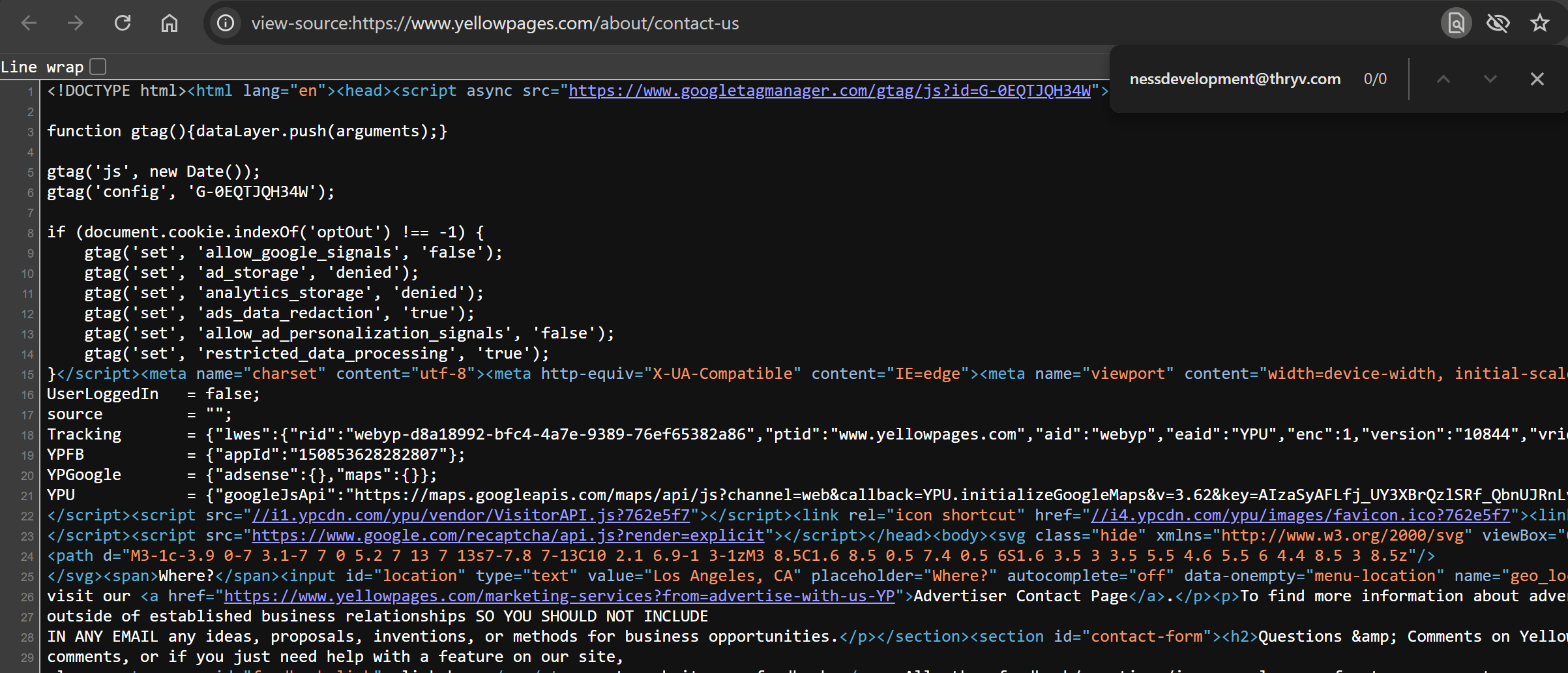
You can scrape that email with Playwright as follows:
# pip install playwright
# playwright install
import re
import email.utils
from playwright.sync_api import sync_playwright
def extract_emails(page):
# Where to store the scraped emails
emails = set()
# Get the page content after JavaScript execution
text_content = page.content()
EMAIL_REGEX = r"""(?:[a-z0-9!#$%&'*+/=?^_`{|}~-]+(?:\\.[a-z0-9!#$%&'*+/=?^_`{|}~-]+)*|"(?:[\\x01-\\x08\\x0b\\x0c\\x0e-\\x1f\\x21\\x23-\\x5b\\x5d-\\x7f]|\\\\[\\x01-\\x09\\x0b\\x0c\\x0e-\\x7f])*")@(?:(?:[a-z0-9](?:[a-z0-9-]*[a-z0-9])?\\.)+[a-z0-9](?:[a-z0-9-]*[a-z0-9])?|\\[(?:(?:25[0-5]|2[0-4][0-9]|[01]?[0-9][0-9]?)\\.){3}(?:25[0-5]|2[0-4][0-9]|[01]?[0-9][0-9]?|[a-z0-9-]*[a-z0-9]:(?:[\\x01-\\x08\\x0b\\x0c\\x0e-\\x1f\\x21-\\x5a\\x53-\\x7f]|\\\\[\\x01-\\x09\\x0b\\x0c\\x0e-\\x7f])+)\\])"""
# Use regex to find all email addresses in the text content
found_emails = re.findall(EMAIL_REGEX, text_content, re.IGNORECASE)
# Select all <a> elements whose "href" attribute starts with "mailto:"
mailto_links = page.locator('a[href^="mailto:"]')
# Extract the email addresses from the mailto links
for link in mailto_links.all():
email_address = link.get_attribute('href').split(':')[1]
found_emails.append(email_address)
# Verify that the emails are valid before adding them to the set
for email_address in found_emails:
try:
# Check if the email is valid
email.utils.parseaddr(email_address)
# Add the email to the set
emails.add(email_address)
except:
# Handle any invalid email or log the error
pass
return list(emails)
with sync_playwright() as p:
# Launch a Chromium browser in headed mode to avoid Cloudflare issues
browser = p.chromium.launch(headless=False)
# Open a new page in the controlled browser
page = browser.new_page()
# Navigate to the target page and wait for JavaScript to execute
page.goto("<https://www.yellowpages.com/about/contact-us>")
# Extract email addresses using the updated function
emails = extract_emails(page)
# Print extracted emails
print(emails)
# Close the browser and free resources
browser.close()
Note how the extract_emails() function has been adapted for Playwright. Also, remember that the goto() function automatically waits for the page to fully load in the browser, so you don’t need to worry about dynamically added emails on the page.
The result will be:
['businessdevelopment@thryv.com']
Awesome! That's exactly the email address you were looking for.
Now, considering that this approach works with both static and dynamic pages, you might wonder why we initially used Beautiful Soup—which only works with static pages. The reason is that browser automation tools require managing and launching browsers, which can be resource-intensive and introduce other complexities.
Thus, browser automation is not always the best solution, especially for something as simple as an email scraper.
Challenge #3: URL encoding or HTML entities
Some websites encode email addresses using hexadecimal entities, making them unreadable in plain text. Example:
<a href="mailto:%61%64%6d%69%6e%40%65%78%61%6d%70%6c%65%2e%63%6f%6d">email</a>
Or HTML entities:
<span>user@email.com</span>
To decode email addresses in these special formats, you can use the html.unescape() and urllib.parse.unquote()methods:
import re
import html
from urllib.parse import unquote
# Function to decode emails from hexadecimal or HTML entities
def decode_emails(text):
# Decode HTML entities
decoded_html = html.unescape(text)
# Decode hexadecimal encoded emails like %61%64%6d...
decoded_text = unquote(decoded_html)
return decoded_text
# Sample HTML with both hexadecimal and HTML-encoded emails
html_text = """
Contact us at <a href="mailto:%61%64%6d%69%6e%40%65%78%61%6d%70%6c%65%2e%63%6f%6d">email</a> or
<span>user@email.com</span>
"""
# Extract and decode emails from the HTML text
emails = decode_emails(html_text)
# Output the decoded emails
print(emails)
The result will be:
Contact us at <a href="mailto:admin@example.com">email</a> or
<span>user@email.com</span>
You can then parse the emails from this text as explained earlier in this article.
Using pre-built email scrapers
As shown earlier, email scraping can quickly become tricky, which is why it makes sense to rely on pre-built solutions like Apify Actors.
Apify Actors are cloud-based automation tools that can perform specific web scraping and data extraction tasks, including email scraping.
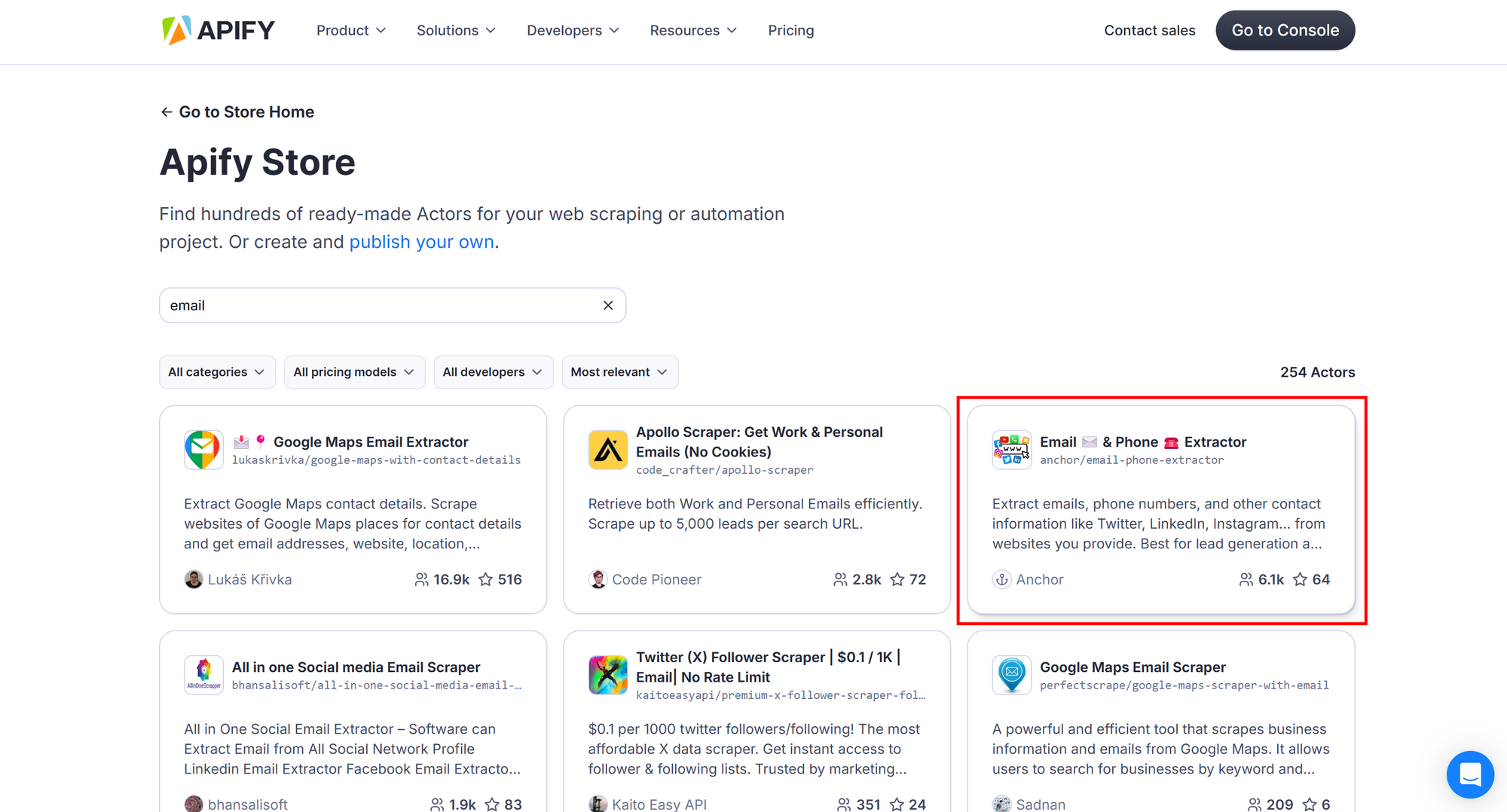
To get started with email scraping via an Actor, visit the Apify Store, which offers over 4,000 Actors for different websites and use cases. Search for “email” and select one of the 250+ available Actors, such as “Email ✉️ & Phone ☎️ Extractor”:
On the Actor page, click “Try for free” to get started:
Once in your Apify Console, click “Start” to rent the Actor:
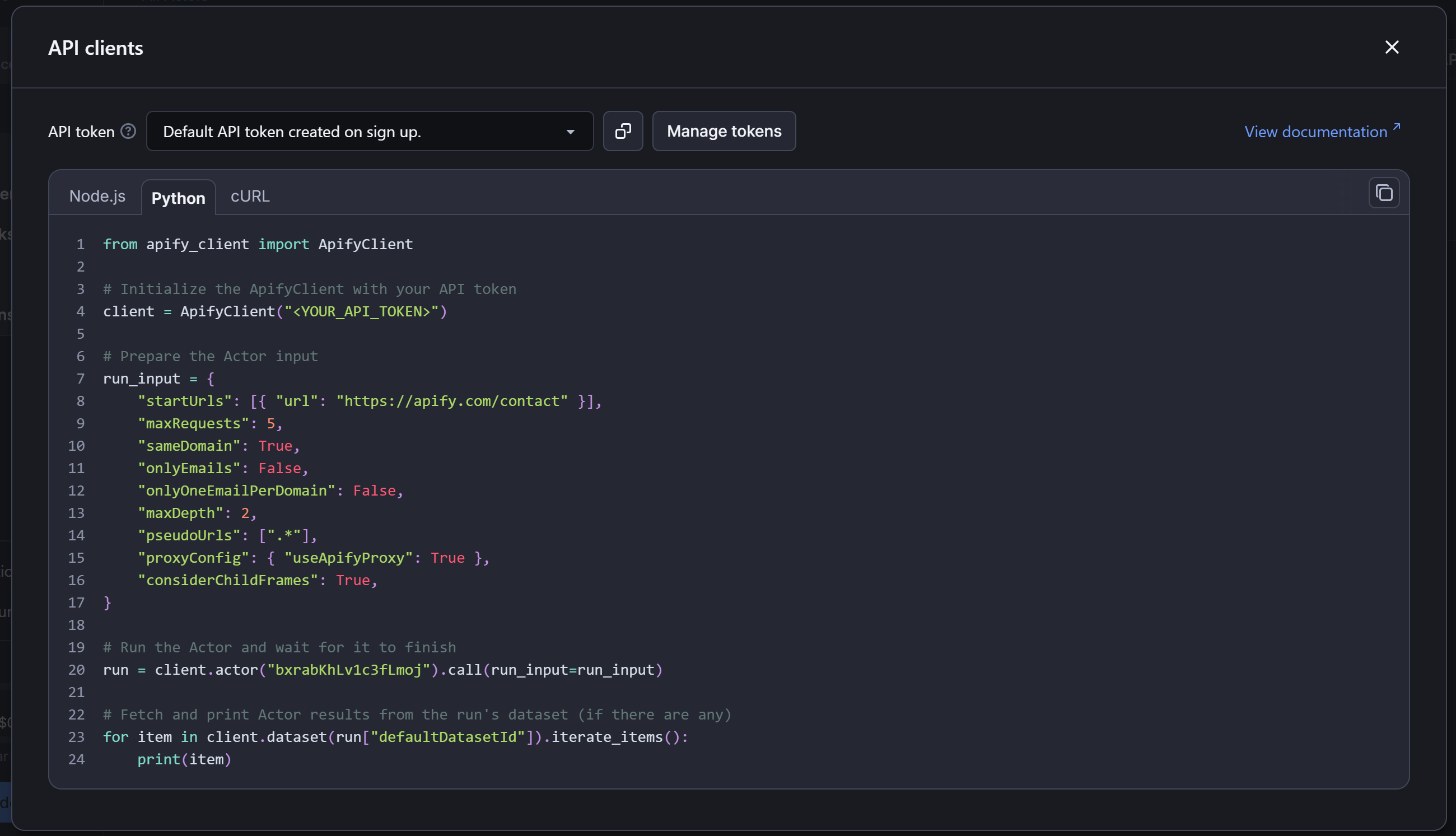
Now, suppose you want to call the Actor via API in a Python script. To do so, navigate to “API > API clients” option in the Apify Console:

Select the “Python” tab, copy the provided code, and replace <YOUR_API_TOKEN> with your Apify Token:
Set the onlyEmails option to True and launch the script. The result will include:
{
"depth": 0,
"referrerUrl": null,
"url": "https://apify.com/contact",
"domain": "apify.com",
"image": "https://apify.com/favicon.ico",
"emails": [
"hello@apify.com"
]
}
And that’s it! You’ve successfully scraped emails without writing custom logic while bypassing obfuscation anti-scraping challenges.
Conclusion
In this tutorial, you learned how to create an automated email-collecting bot in Python, either as a local script or in the cloud via Apify. You also explored how to handle common email obfuscation techniques to maximize your data extraction results.
As covered here, using a pre-built email scraping Actor like “Email ✉️ & Phone ☎️ Extractor “ is the recommended approach to simplify email retrieval. To test additional web scraping and automation capabilities, explore other code templates.
Frequently asked questions
Is it legal to scrape emails from websites?
Yes, it is legal to scrape emails from websites as long as you follow privacy compliance and best practices. This includes avoiding scraping data behind login pages or any content that violates the website's terms of service or relevant data protection laws, such as GDPR.
How to scrape emails ethically?
To scrape emails ethically, respect website terms of service, follow the privacy policies and adhere to robots.txt. Avoid scraping personal or private emails and flooding the target servers with too many requests.
What are the best tools for email scraping?
The best tools for email scraping are HTML parsers like Beautiful Soup, regex for pattern matching, and browser automation tools like Playwright or Selenium. HTML parsers work for static documents, regex for specific patterns, and browser automation for dynamic content.