


Want to extract hotel listings from Expedia without hitting a wall of JavaScript and anti-scraping protections? If you’ve tried scraping dynamic travel sites before, you know how challenging it can be. Between endless network calls, lazy-loaded content, and frequent layout changes, scraping Expedia isn’t a beginner-level task.
In this guide, you’ll learn how to build an Expedia scraping script in Python using the Apify CLI. We’ll walk you through the entire process, from setting up the project to deploying your Expedia scraper on the Apify platform!
Deploying your Expedia web scraping script to Apify unlocks cloud execution, API access, and scheduling capabilities. This lets you run your scraper reliably at scale, without having to manage any infrastructure yourself.
In the end, we'll also cover an alternative approach: using a ready-made Expedia scraper. This doesn't allow as much customization as building your own, but all the hard work has been done for you.
How to scrape Expedia using Python
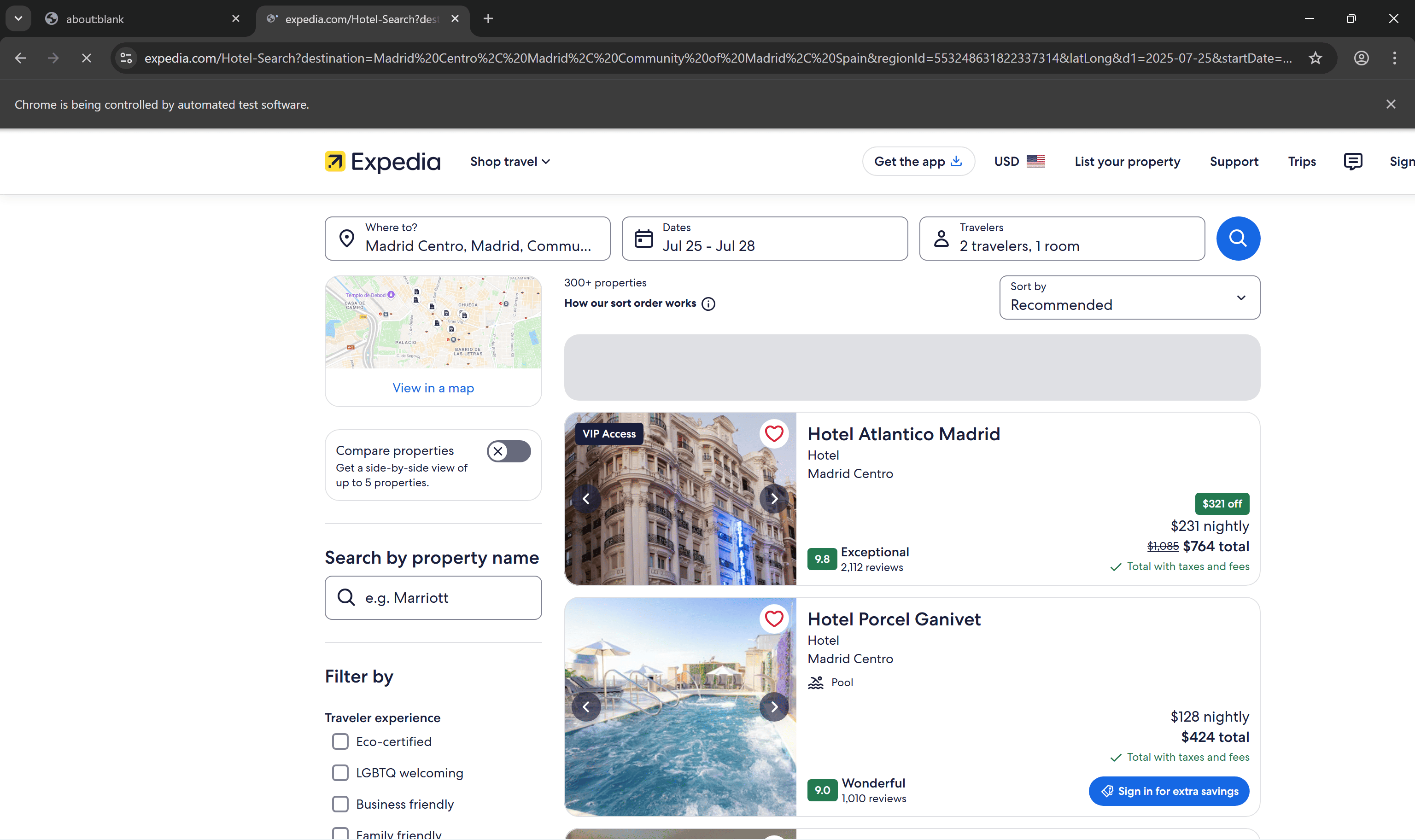
In this step-by-step tutorial, you’ll see how to scrape the following Expedia hotel search page for Madrid Centro:
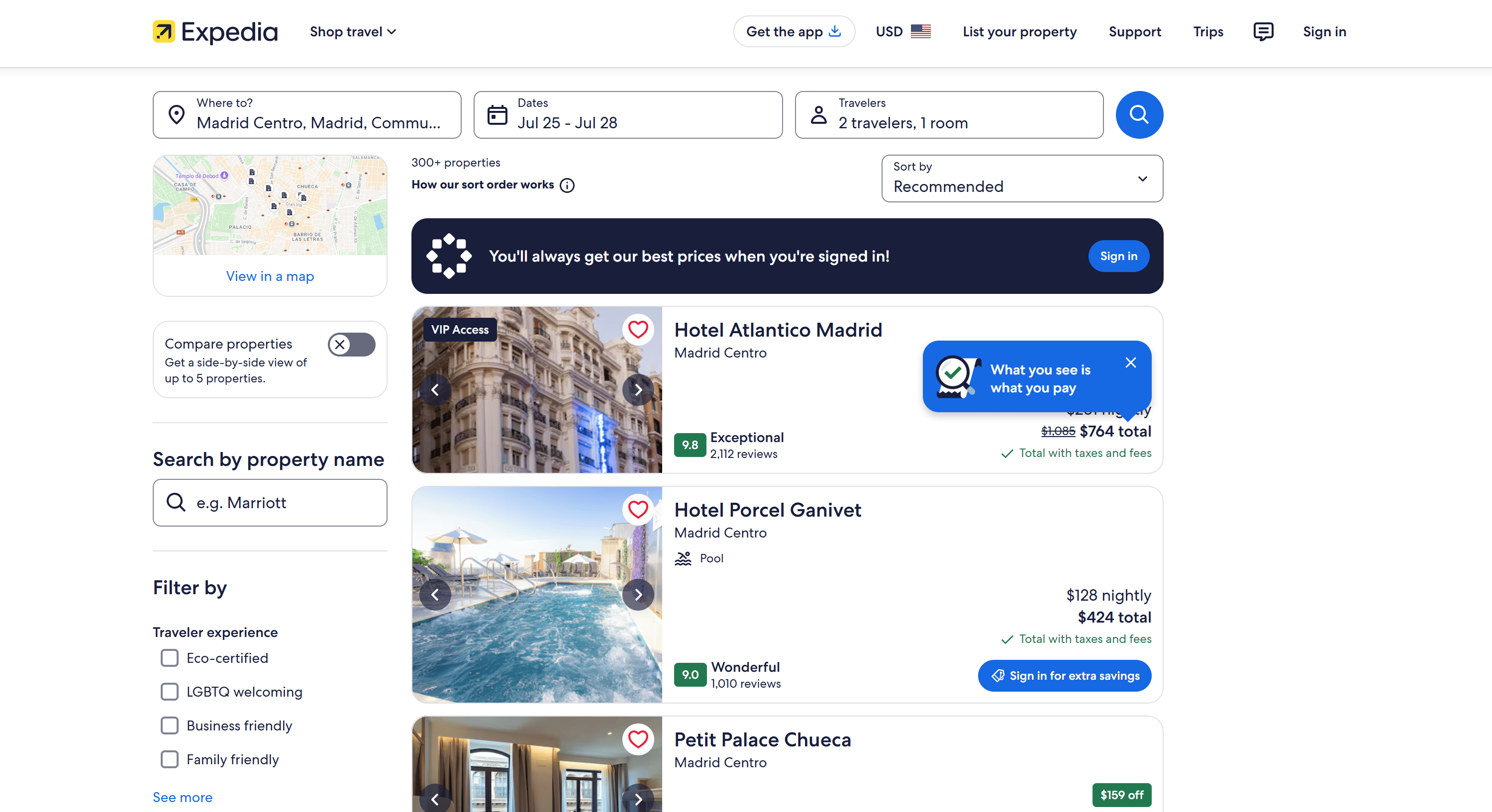
We'll guide you through the Expedia scraping process with these steps:
- Select the scraping libraries
- Create the Python project
- Configure input reading
- Initialize
PlaywrightCrawler - Complete the scraper infrastructure
- Prepare to scrape hotel listings
- Implement the hotel listing scraping logic
- Store the scraped data
- Integrate residential proxies
- Put it all together
- Bonus step: Deploy to Apify
We'll then show you the no-code approach using an off-the-shelf Expedia Scraper on Apify Store.
Prerequisites
To follow along with this tutorial, make sure you meet the following prerequisites:
- A solid grasp of how the web works, including HTTP requests, status codes, and JavaScript-driven pages
- Familiarity with the DOM, HTML, and CSS selectors
- An understanding of the difference between static and dynamic sites
Since Python is the programming language used for this guide, you’ll need:
- Python 3+ installed locally
- A Python IDE like Visual Studio Code with the Python extension or PyCharm
- Basic experience with Python, async programming, and browser automation
- Elementary knowledge of how Crawlee works
- Minimal familiarity with the Playwright Python API
Finally, you'll deploy your Expedia scraper to Apify. So, you'll also require:
- Node.js set up locally (to install the Apify CLI)
- An Apify account
- A basic understanding of how Apify works
Step 1: Select the scraping libraries
Before jumping into coding, take a moment to familiarize yourself with the target Expedia page. The goal here is to understand how the page loads its data so you can choose the right web scraping tools.
Open the target page in your browser (preferably in incognito mode to ensure a fresh session), and you'll see something like this:

That initial loading screen already suggests that hotel data may be loaded dynamically. Now, scroll down to the end of the hotel listings. There, you should see a “Show more” button. Click it to see what happens:
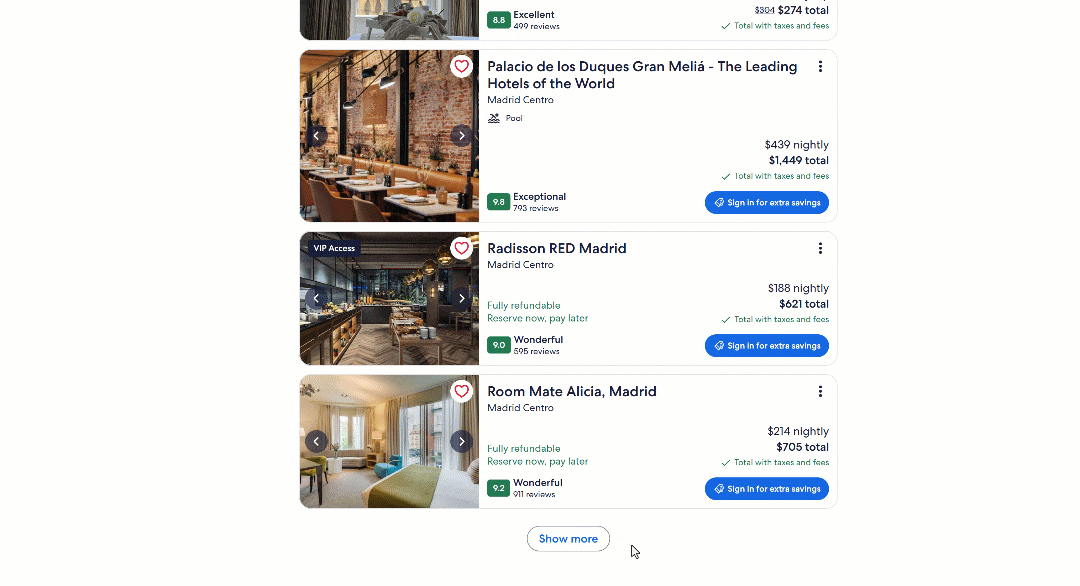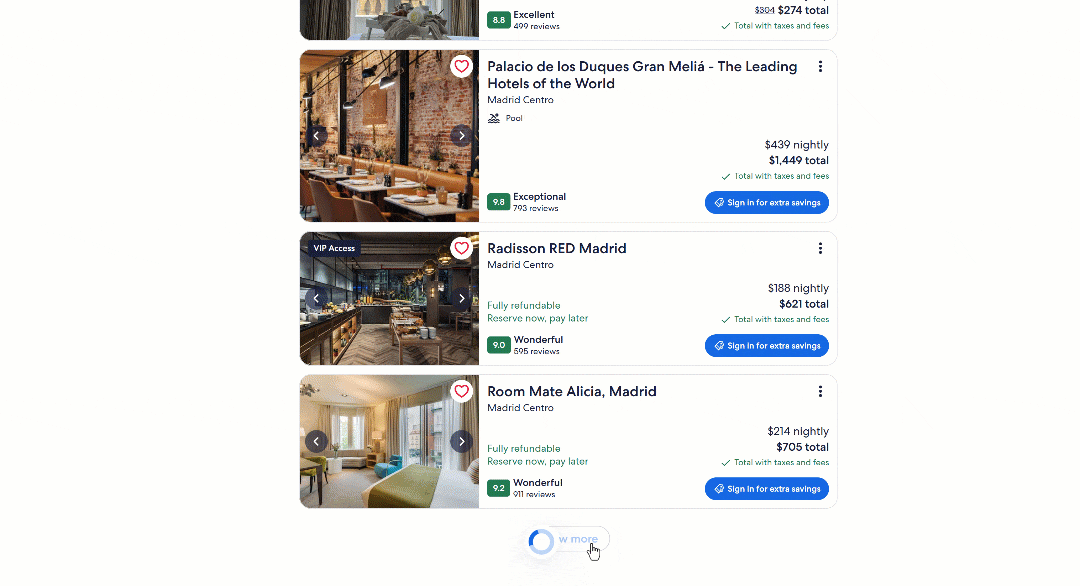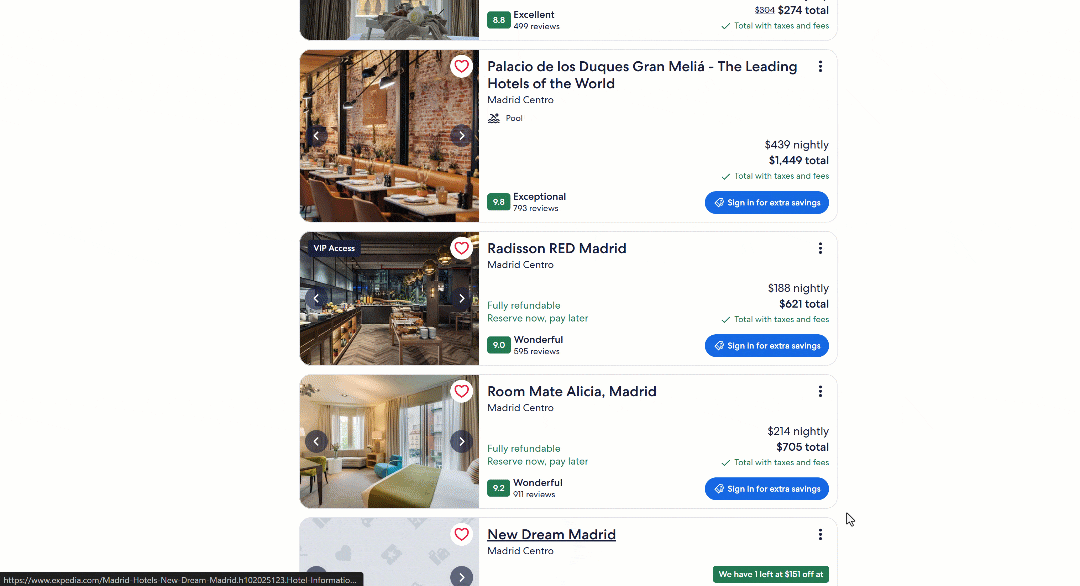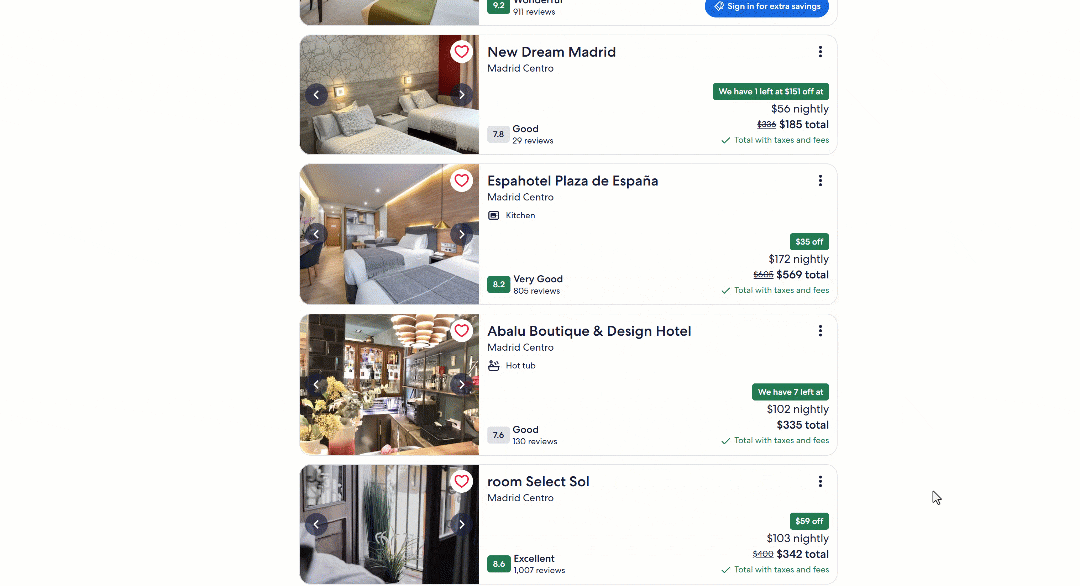
At this point, it’s clear that the page loads data directly in the browser. You can confirm that by right-clicking anywhere on the page and selecting "Inspect" to open your browser’s Developer Tools. Then, reload the page and watch the network activity:
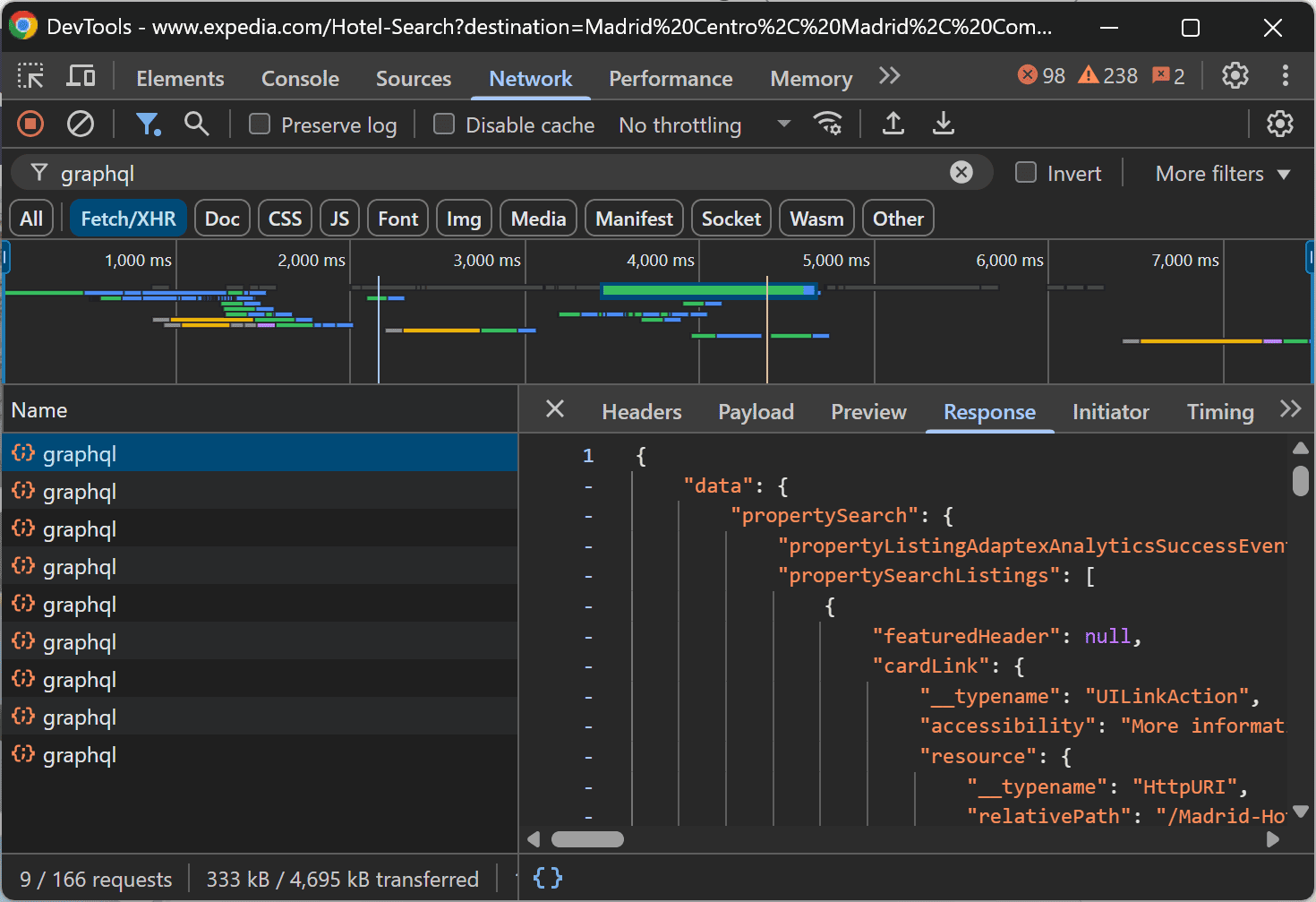
You’ll notice several GraphQL requests being made during page rendering to fetch hotel data. This confirms that you need a browser automation tool (like Selenium or Playwright) to scrape Expedia. That’s because the scraper must be able to fully render the page (JavaScript included), not just parse the static HTML.
However, using a vanilla Playwright approach to scraping can be challenging. The reason is that it requires you to manually handle things like proxy rotation, retries, concurrency, and more. That’s why using Playwright through Crawlee is faster and easier.
Crawlee is a web scraping framework for Python (and JavaScript) that handles blocking detection, crawling logic, proxies, and browser orchestration out of the box. That way, you can focus on scraping, not infrastructure. Plus, it's deeply integrated with Apify.
Step 2: Create the Python project
Before building your Expedia scraper, you need to set up your environment. Since the script will be deployed on Apify, start by installing the Apify CLI globally using the following command:
npm install -g apify-cli
This installs the Apify CLI globally on your system so you can create and manage Actors easily.
Run the following command to create a new Apify Actor:
apify create
You’ll be prompted to answer a few configuration questions. Use the following answers:
✔ Name of your new Actor: expedia-scraper
✔ Choose the programming language of your new Actor: Python
✔ Choose a template for your new Actor. Detailed information about the template will be shown in the next step. Crawlee + Playwright + Chrome
✔ Do you want to install the following template? Y
This will generate a Python-based Apify Actor inside the expedia-scraper folder, using the “Crawlee + Playwright + Chrome” template. This template sets you up with everything you need to scrape dynamic websites using Playwright.
Once created, your expedia-scraper folder should contain the following file structure:
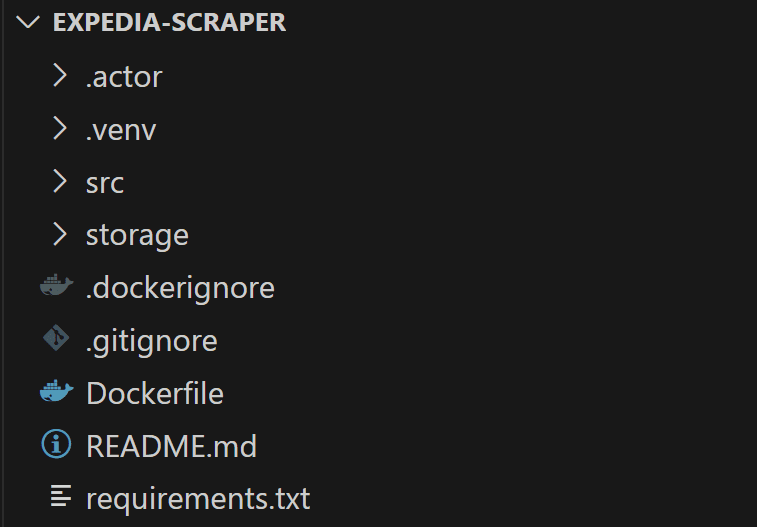
The Apify CLI automatically creates a .venv folder containing a Python virtual environment. Activate it with:
source .venv/bin/activate
Or, equivalently, on Windows, run:
.venv\\Scripts\\activate
Once the virtual environment is active, launch the command below to download the browsers required by Playwright:
python -m playwright install
This downloads the necessary browser binaries so Playwright can automate browser interactions.
Now, navigate to the src/ folder and open the main.py file. You’ll find a section that starts with async with Actor, which currently contains sample Playwright automation logic. Clear that section and prepare to replace it with your custom logic to scrape Expedia:
# src/main.py
from __future__ import annotations
from apify import Actor
from crawlee.crawlers import PlaywrightCrawler, PlaywrightCrawlingContext
async def main() -> None:
async with Actor:
# Your Expedia Actor scraping logic...
Don’t forget that you can launch your Actor locally for testing purposes with:
apify run
Step 3: Configure input reading
To read the target URL from the Actor’s input arguments, add the following code under the async with Actor block:
# Retrieve the Actor input, and use default values if not provided
actor_input = await Actor.get_input() or {}
# Extract URLs from the start_urls inout array
urls = [
url_object.get("url") for url_object in actor_input.get("start_urls")
]
# Exit if no URLs are provided
if not urls:
Actor.log.info("No URLs specified in Actor input, exiting...")
await Actor.exit()
If the start_urls field is missing or empty, the Actor exits immediately using Actor.exit(). Otherwise, it retrieves and extracts the list of provided URLs.
To set the target Expedia scraping page, update the INPUT.json file located at /storage/key_value_store/default/with the following JSON content:
{
"start_urls": [
{
"url": "https://www.expedia.com/Hotel-Search?destination=Madrid%20Centro%2C%20Madrid%2C%20Community%20of%20Madrid%2C%20Spain®ionId=553248631822337314&latLong&d1=2025-07-25&startDate=2025-07-25&d2=2025-07-28&endDate=2025-07-28&adults=2&rooms=1&children=&pwaDialog=&daysInFuture&stayLength&sort=RECOMMENDED&upsellingNumNightsAdded=&theme=&userIntent=&semdtl=&upsellingDiscountTypeAdded=&categorySearch=&useRewards=false"
}
]
}
With this configuration, the urls array will contain a single URL (the URL that points to the desired Expedia hotel search page for Madrid).
Step 4: Initialize PlaywrightCrawler
Now that you have access to the target scraping URLs in your code, initialize a PlaywrightCrawler instance as below:
crawler = PlaywrightCrawler(
headless=True, # Set to False during development to observe scraper behavior
browser_launch_options={
"args": ["--disable-gpu", "--no-sandbox"], # Required for Playwright on Apify
},
max_request_retries=10,
concurrency_settings = ConcurrencySettings(
min_concurrency=1,
max_concurrency=1,
),
)
This sets up a browser-based Crawlee crawler that runs in headless mode, retries failed requests up to 5 times, and enforces a concurrency of 1 (which is suitable in this example, since there's only one page to scrape). The remaining argspassed to the browser are necessary for running Playwright in Apify’s cloud environment.
Note: While developing locally, you should set headless=False to visually debug and better understand how your Expedia scraper interacts with the target page.
Don’t forget to import ConcurrencySettings with:
from crawlee import ConcurrencySettings
Step 5: Complete the scraper infrastructure
Crawlee relies on request handlers, which are user-defined functions responsible for processing individual requests and their corresponding responses. To scrape the target Expedia page, add a handler like this:
@crawler.router.default_handler
async def request_handler(context: PlaywrightCrawlingContext) -> None:
# Retrieve the page URL from the Playwright context
url = context.request.url
Actor.log.info(f"Scraping {url}...")
# Expedia scraping logic...
Then, after defining the function but still inside the async with Actor block, write the following line to start the crawler:
await crawler.run(urls)
The run() function launches the crawler and processes all the URLs provided. In other words, it passes the target URLs to the Playwright crawler, which handles them as specified in request_handler().
Step 6: Prepare to scrape hotel listings
It's time to start writing the actual scraping logic in request_handler(). Before diving into code, take a moment to understand the behavior and structure of the target Expedia page by opening it in your browser.
If that's your first visit, you'll likely encounter a modal like this:
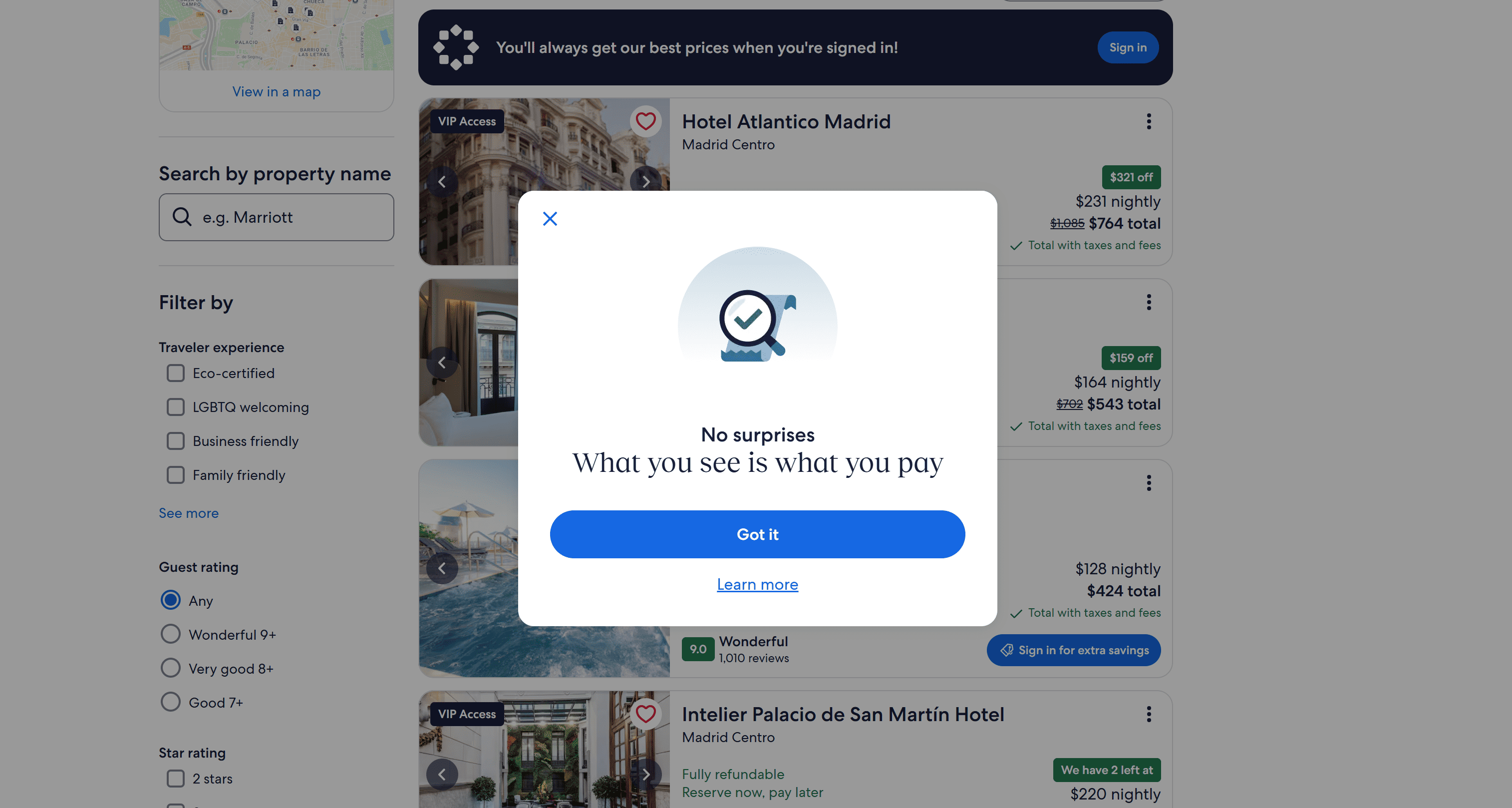
This modal blocks interaction with the rest of the page, interfering with your Playwright scraper. If it shows up, you need to close it. Right-click on the “×" (close button) and select the “Inspect” option:
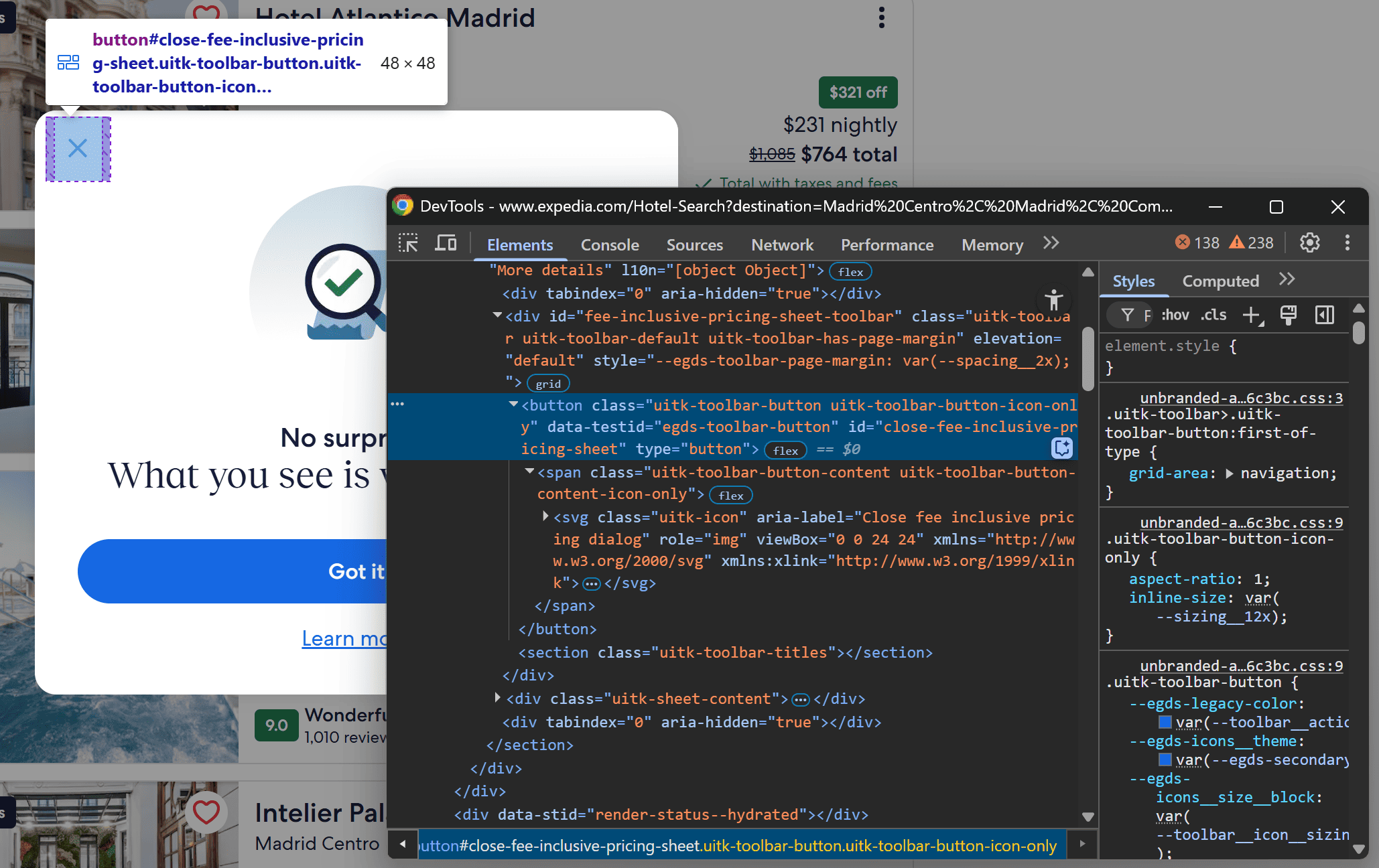
You'll see that the close button can be selected using the following CSS selector:
#close-fee-inclusive-pricing-sheet
So, in your request_handler(), add logic to close the modal if it appears:
try:
# Wait up to 10 seconds for the modal to appear and close it if it shows up
modal_close_button_element = context.page.locator("#close-fee-inclusive-pricing-sheet")
await modal_close_button_element.click(timeout=10000)
except TimeoutError:
print("Modal close button not found or not clickable, continuing...")
When using click() or similar actions, Playwright applies an auto-wait mechanism by default (with a 30-second timeout). In this case, you can reduce the timeout to 10 seconds so the scraper doesn't wait too long for a modal that might not appear.
If the modal appears, it’ll be closed by clicking the close button. If it doesn’t, Playwright will throw a TimeoutError, which is caught to avoid stopping your scraper.
Don’t forget to import the TimeoutError class with:
from playwright.async_api import TimeoutError
With the modal out of the way, you can now access the hotel listing cards beneath it. Right-click and inspect one of the hotel cards:
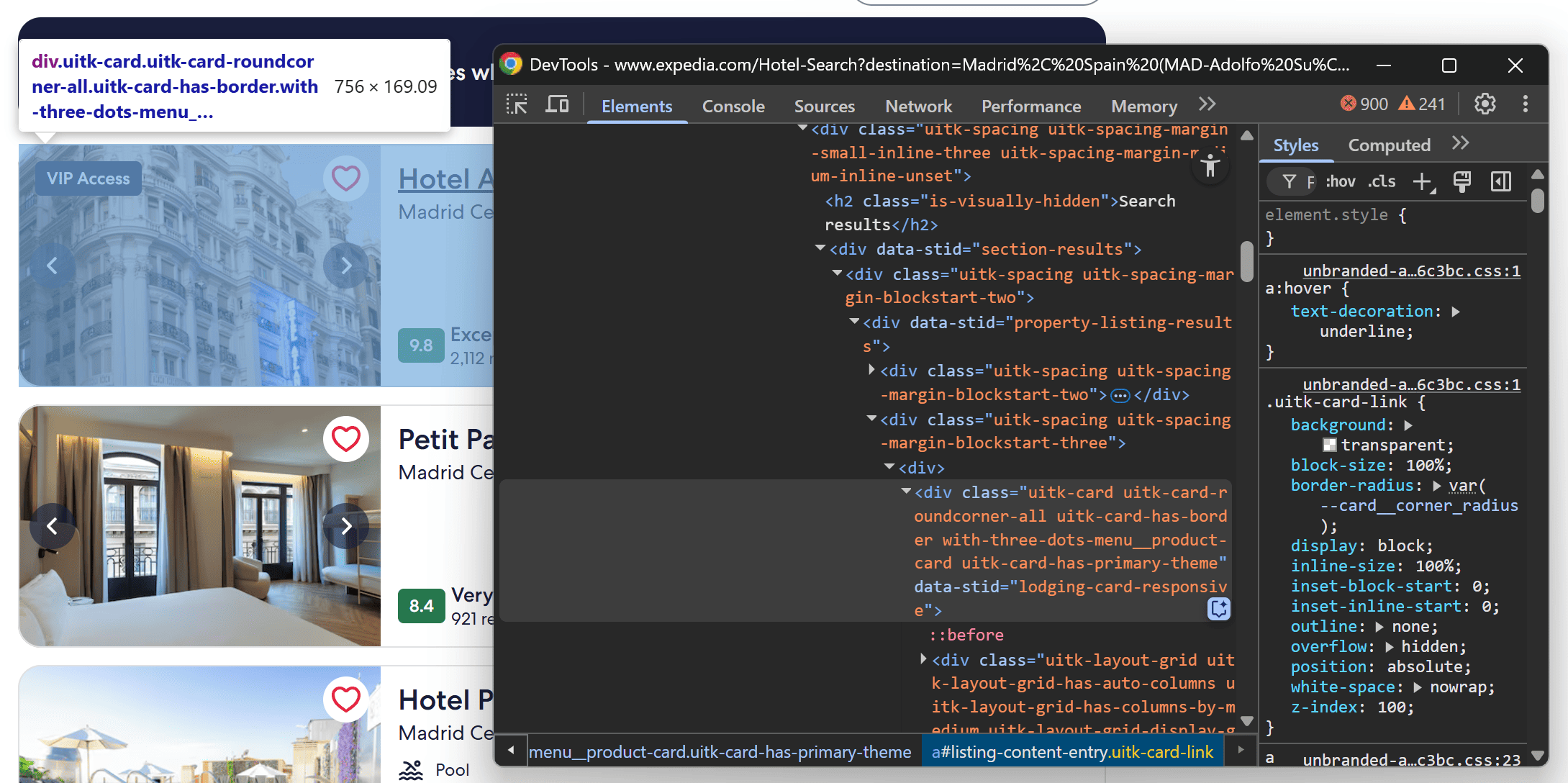
From inspection, you’ll notice that each hotel card can be selected using the following CSS selector:
[data-stid="property-listing-results"] [data-stid="lodging-card-responsive"]
Targeting data-* attributes is a best practice in scraping because they tend to remain stable across deployments. These attributes are often added specifically for testing and automation, unlike CSS class names that may change frequently.
Select the hotel listing cards and prepare them for scraping:
# Select all HTML hotel card elements on the page
card_elements = context.page.locator("[data-stid=\\"property-listing-results\\"] [data-stid=\\"lodging-card-responsive\\"]")
# Wait for the elements to be rendered on the page
await card_elements.nth(5).wait_for(state="attached", timeout=10000)
# Iterate over all card elements and apply the scraping logic
for card_element in await card_elements.all():
# Hotel card scraping logic...
Since the hotel listing cards are loaded dynamically, you must wait for them to be attached to the DOM. Expedia initially shows around 3 hotel listings and then renders more shortly afterward. Waiting for the 5th card is enough to verify that all listings are attached to the DOM before scraping.
Currently, Expedia loads up to 100 listings by default, with an option to load more using the “Show more” button at the bottom. So, the expected result is a dataset of hotel listing data with 100 entries.
Step 7: Implement the hotel listing scraping logic
Inside the for loop, you now have to select all relevant HTML elements from each hotel listing card and extract the data.
Start by inspecting a single hotel card, focusing on the link element:
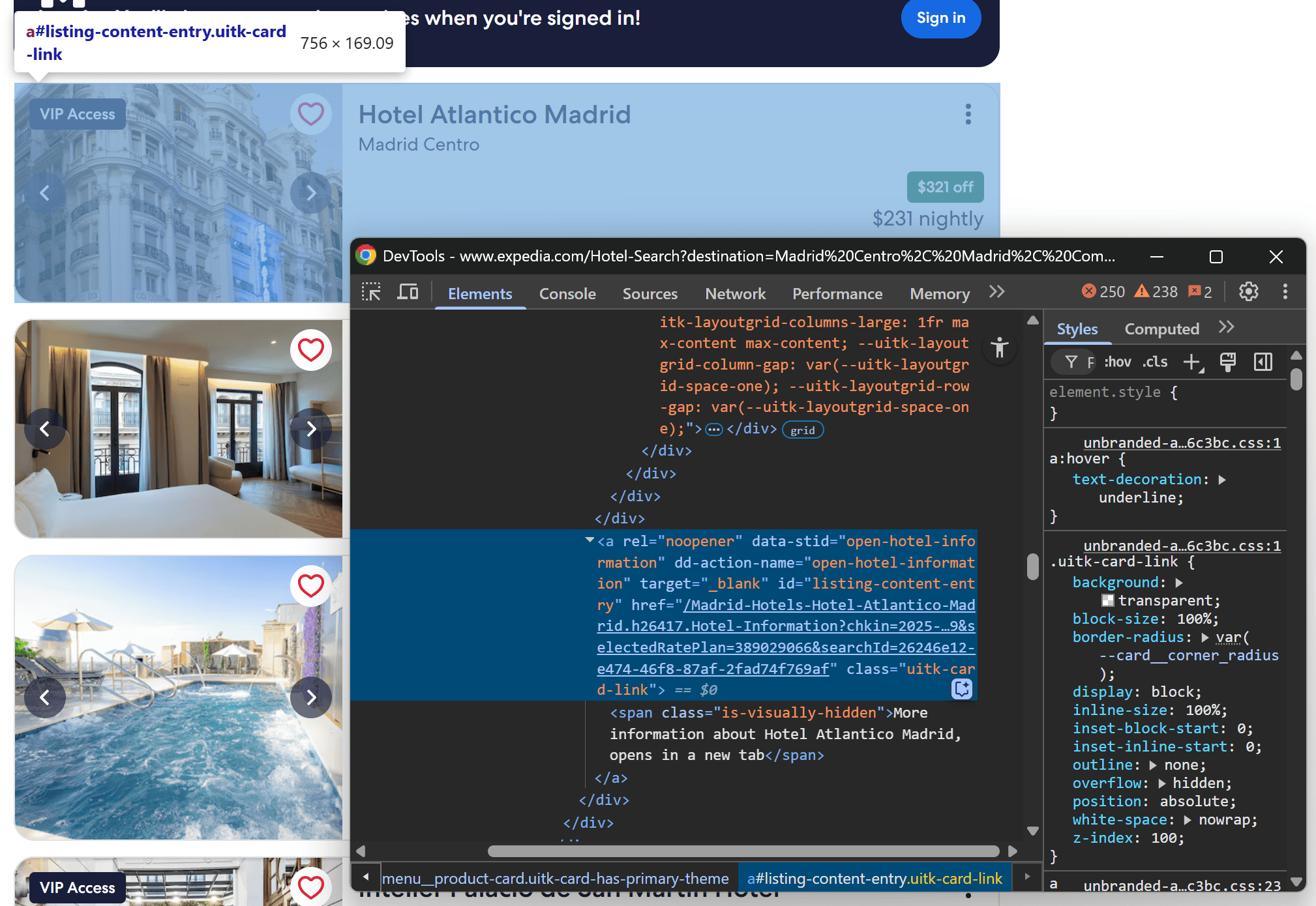
You can select the link and extract the hotel listing URL with:
url_element = card_element.locator("[data-stid=\\"open-hotel-information\\"]")
hotel_url = "https://expedia.com" + await url_element.get_attribute("href")
Note that the <a> tag contains a relative URL, so you must prepend the base domain (https://expedia.com) to convert it into an absolute URL.
Next, inspect the hotel name and location:
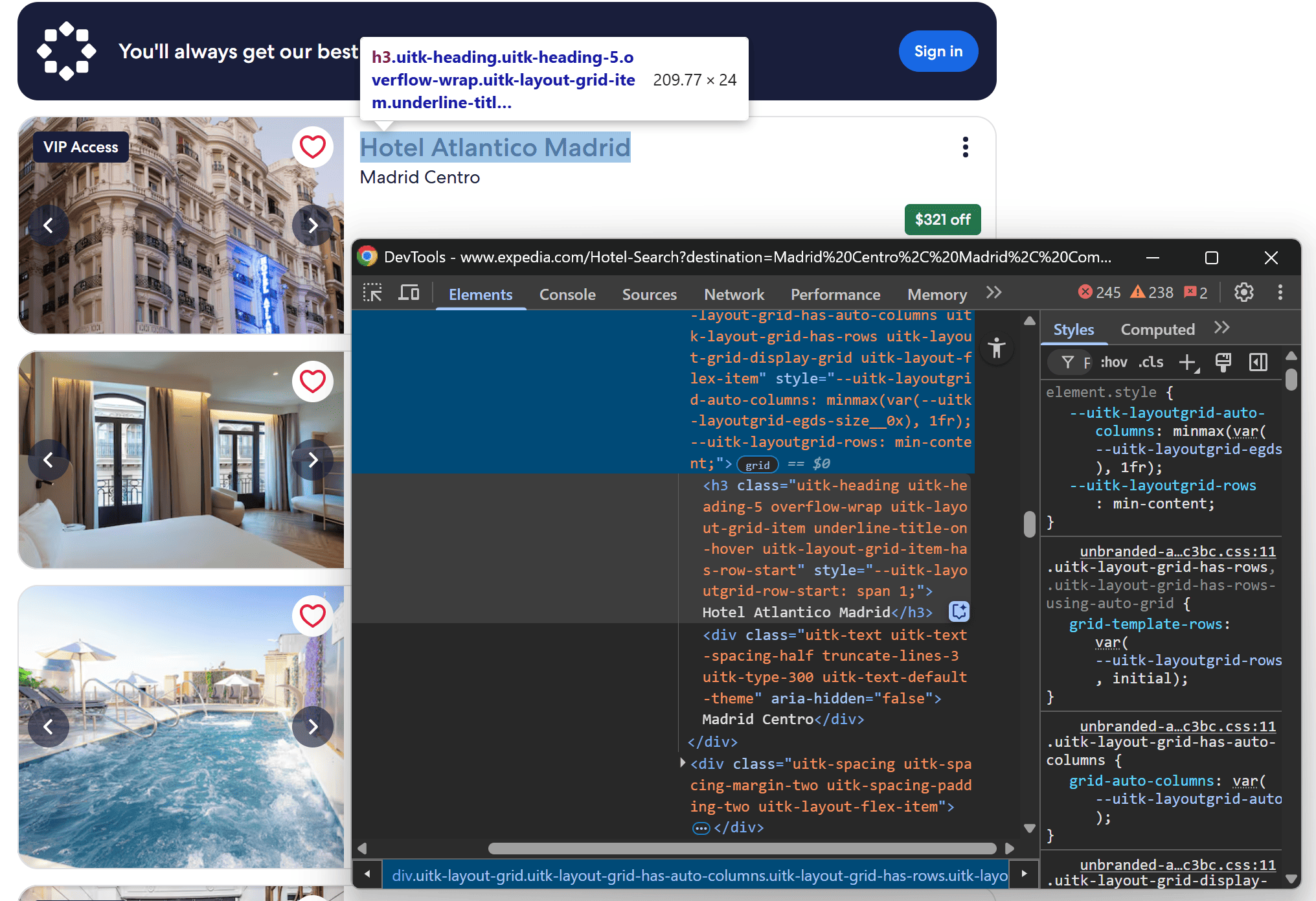
Collect them both with:
name_element = card_element.locator("h3.uitk-heading")
name = await name_element.first.text_content()
location_element = card_element.locator("h3.uitk-heading + div")
location = await location_element.first.text_content()
Since there's no unique selector for the location, use the + div CSS selector to grab the next sibling <div> following the hotel name heading.
Then, extract the review score and number of reviews:
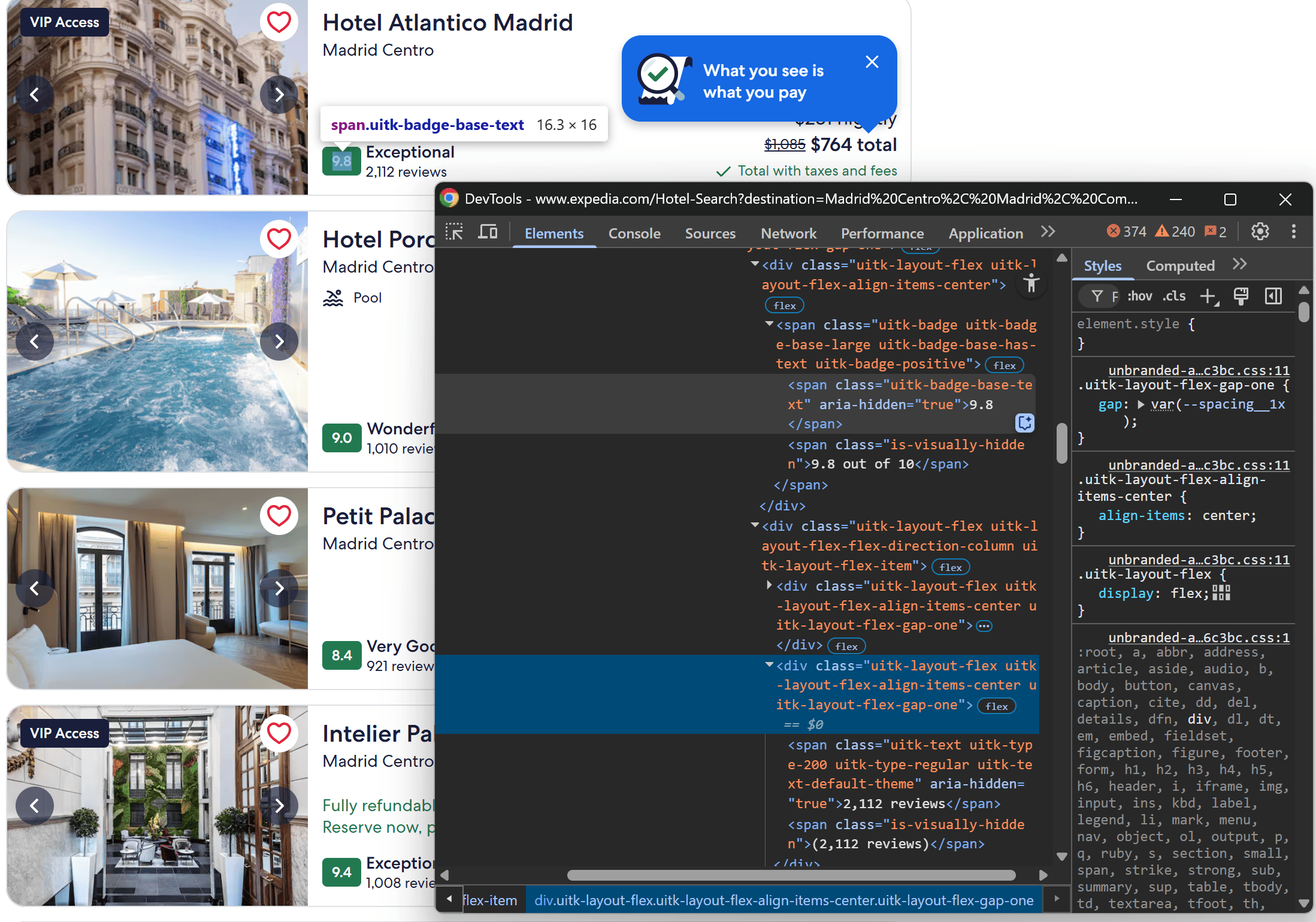
Selecting the element that contains the number of reviews is a bit challenging, as there isn’t a direct and reliable CSS selector. So, you can select all .uitk-type-200 elements and filter the one that contains the word “reviews” like this:
review_score_element = card_element.locator(".uitk-badge-base-text[aria-hidden=\\"true\\"]")
review_score = await review_score_element.first.text_content()
review_number = None
# Locate all elements that might contain the number of reviews
possible_review_number_elements = card_element.locator(".uitk-type-200")
for possible_review_number_element in await possible_review_number_elements.all():
possible_review_number_element_text = await possible_review_number_element.first.text_content()
# If the text contains "reviews", extract the number
if "reviews" in possible_review_number_element_text:
# Extract the number, remove commas, and convert to int
review_number = int(possible_review_number_element_text.split()[0].replace(",", ""))
break
Finally, tackle the price elements:
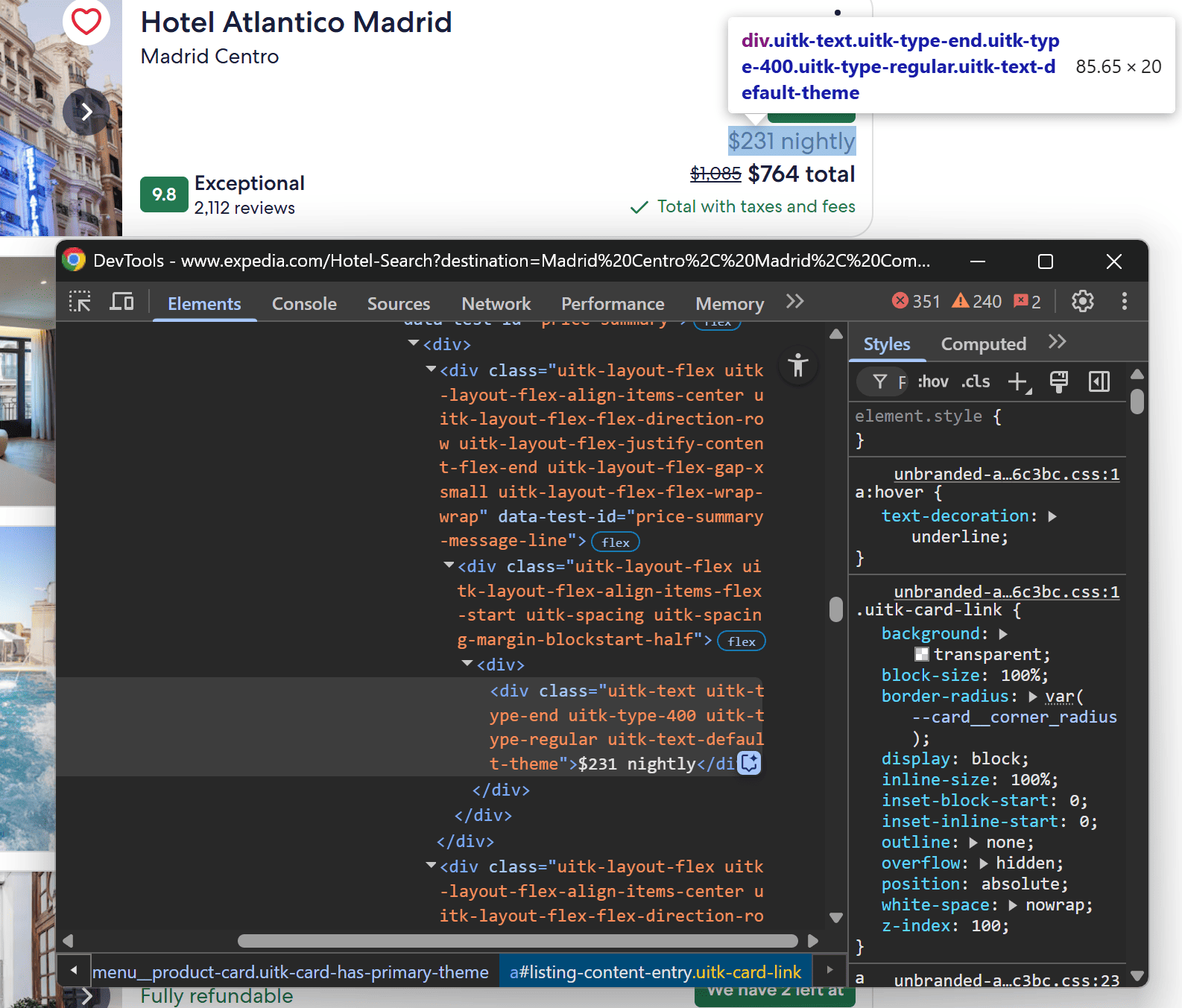
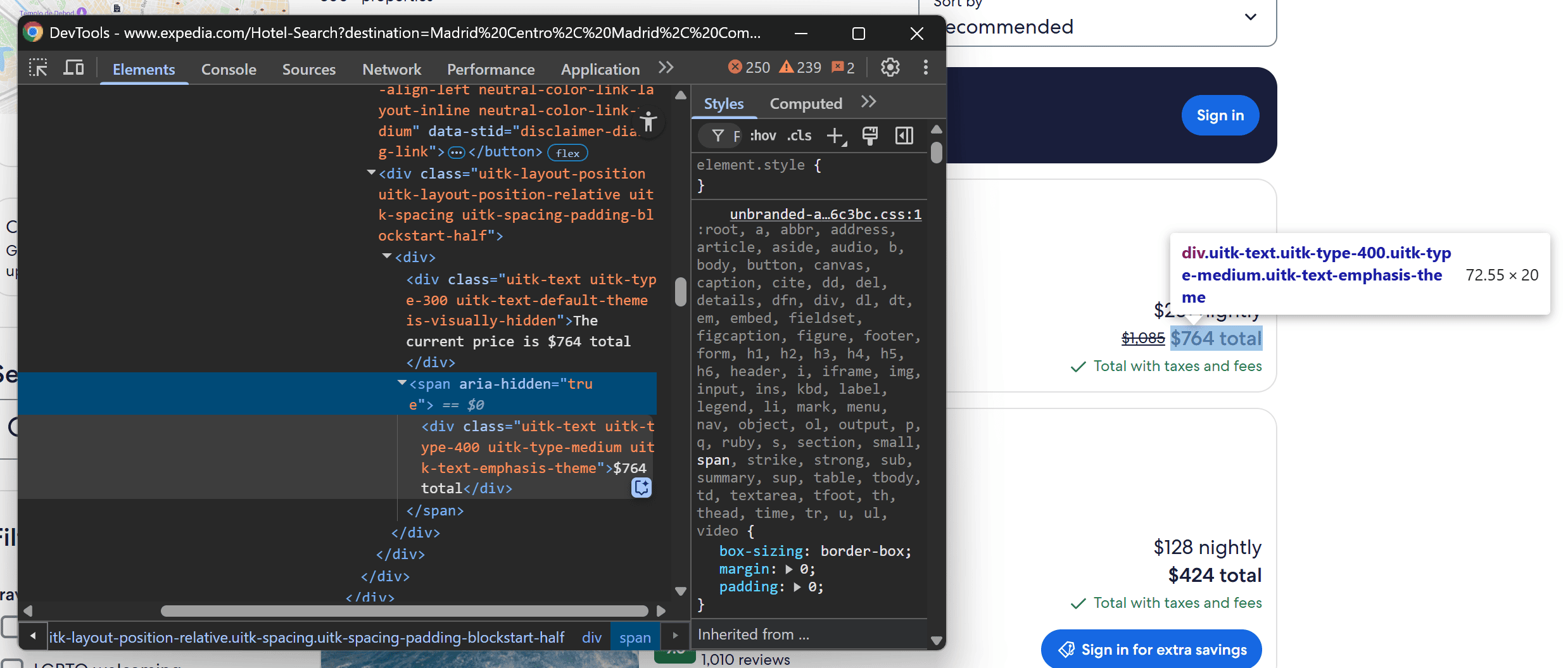
Again, you can apply a similar scraping logic as we did before:
price_summary_element = card_element.locator("[data-test-id=\\"price-summary-message-line\\"]")
price_summary = await price_summary_element.first.text_content()
total_price = None
# Locate all elements that might contain the total price
possible_total_price_elements = card_element.locator(".uitk-type-400")
for possible_total_price_element in await possible_total_price_elements.all():
possible_total_price_element_text = await possible_total_price_element.first.text_content()
# If the text contains "total", extract the price
if "total" in possible_total_price_element_text:
total_price = possible_total_price_element_text.split()[0]
break
Step 8: Store the scraped data
Inside the for loop, create a new hotel object with the scraped data and append it to the Actor dataset through the push_data() method:
hotel = {
"url": hotel_url,
"name": name,
"location": location,
"review_score": review_score,
"review_number": review_number,
"price_summary": price_summary,
"total_price": total_price,
}
await context.push_data(hotel)
Once the for loop completes, the Actor dataset should contain all 100 hotel listings from the target page. After deploying the Actor to Apify, you’ll be able to explore the scraped data directly from your account. Additionally, you’ll be able to access it via the API.
Step 9: Integrate residential proxies
If you deploy your Expedia scraper on a server and run it, you’ll likely encounter an Expedia error page. Alternatively, after just a few requests, you might start receiving 429 Too Many Requests errors.
To overcome this limitation, you can route your requests through residential proxies. These allow you to make your traffic appear as if it’s coming from real users, while also providing IP rotation capabilities to avoid rate limits and blocks.
Keep in mind that Apify offers residential proxies, even on the free plan. Alternatively, you can also bring your own proxies, as explained in the documentation.
To use Apify's residential proxies, create a proxy configuration with create_proxy_configuration() as below:
proxy_configuration = await Actor.create_proxy_configuration(
groups=["RESIDENTIAL"],
country_code="US",
)
This sets up a proxy integration using US-based residential IPs. Based on our tests, US residential proxies tend to work best when scraping Expedia.
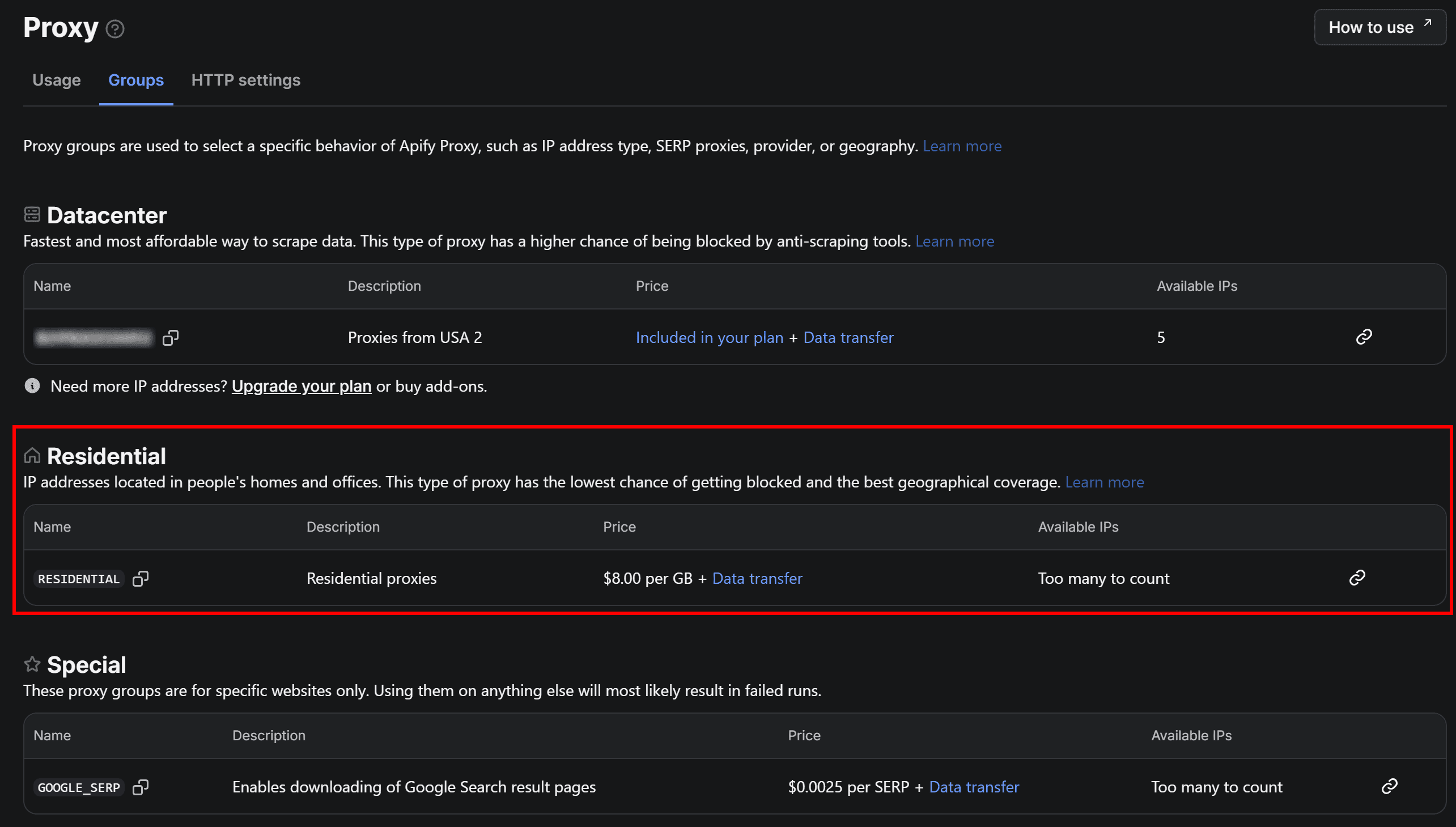
If you’re wondering, the "RESIDENTIAL" group name corresponds to the residential proxy group in your Apify dashboard. You can verify it under the “Proxy > Groups” page in the Apify dashboard:
Next, pass the proxy_configuration object in the PlaywrightCrawler constructor:
crawler = PlaywrightCrawler(
# other congifs..
proxy_configuration=proxy_configuration
)
PlaywrightCrawler will now route requests through the configured residential proxies.
Step 10: Put it all together
The main.py file should contain this code:
# src/main.py
from __future__ import annotations
from apify import Actor
from crawlee.crawlers import PlaywrightCrawler, PlaywrightCrawlingContext
from crawlee import ConcurrencySettings
from playwright.async_api import TimeoutError
async def main() -> None:
async with Actor:
# Retrieve the Actor input, and use default values if not provided
actor_input = await Actor.get_input() or {}
# Extract URLs from the start_urls inout array
urls = [
url_object.get("url") for url_object in actor_input.get("start_urls")
]
# Exit if no URLs are provided
if not urls:
Actor.log.info("No URLs specified in Actor input, exiting...")
await Actor.exit()
# Residential proxy integration
proxy_configuration = await Actor.create_proxy_configuration(
groups=["RESIDENTIAL"],
country_code="US",
)
# Create a Playwright crawler through Crawlee
crawler = PlaywrightCrawler(
headless=True, # Set to False during development to observe scraper behavior
browser_launch_options={
"args": ["--disable-gpu", "--no-sandbox"], # Required for Playwright on Apify
},
max_request_retries=10,
concurrency_settings = ConcurrencySettings(
min_concurrency=1,
max_concurrency=1,
),
proxy_configuration=proxy_configuration
)
# Define a request handler, which will be called for every URL
@crawler.router.default_handler
async def request_handler(context: PlaywrightCrawlingContext) -> None:
# Retrieve the page URL from the Playwright context
url = context.request.url
Actor.log.info(f"Scraping {url}...")
try:
# Wait up to 10 seconds for the modal to appear and close it if it shows up
modal_close_button_element = context.page.locator("#close-fee-inclusive-pricing-sheet")
await modal_close_button_element.click(timeout=10000)
except TimeoutError:
print("Modal close button not found or not clickable, continuing...")
# Select all HTML hotel card elements on the page
card_elements = context.page.locator("[data-stid=\\"property-listing-results\\"] [data-stid=\\"lodging-card-responsive\\"]")
# Wait for the elements to be rendered on the page
await card_elements.nth(5).wait_for(state="attached", timeout=10000)
# Iterate over all card elements and apply the scraping logic
for card_element in await card_elements.all():
url_element = card_element.locator("[data-stid=\\"open-hotel-information\\"]")
hotel_url = "<https://expedia.com>" + await url_element.get_attribute("href")
name_element = card_element.locator("h3.uitk-heading")
name = await name_element.first.text_content()
location_element = card_element.locator("h3.uitk-heading + div")
location = await location_element.first.text_content()
review_score_element = card_element.locator(".uitk-badge-base-text[aria-hidden=\\"true\\"]")
review_score = await review_score_element.first.text_content()
review_number = None
# Locate all elements that might contain the number of reviews
possible_review_number_elements = card_element.locator(".uitk-type-200")
for possible_review_number_element in await possible_review_number_elements.all():
possible_review_number_element_text = await possible_review_number_element.first.text_content()
# If the text contains "reviews", extract the number
if "reviews" in possible_review_number_element_text:
# Extract the number, remove commas, and convert to int
review_number = int(possible_review_number_element_text.split()[0].replace(",", ""))
break
price_summary_element = card_element.locator("[data-test-id=\\"price-summary-message-line\\"]")
price_summary = await price_summary_element.first.text_content()
total_price = None
# Locate all elements that might contain the total price
possible_total_price_elements = card_element.locator(".uitk-type-400")
for possible_total_price_element in await possible_total_price_elements.all():
possible_total_price_element_text = await possible_total_price_element.first.text_content()
# If the text contains "total", extract the price
if "total" in possible_total_price_element_text:
total_price = possible_total_price_element_text.split()[0]
break
# Initialize a new hotel entry with the scraped data
hotel = {
"url": hotel_url,
"name": name,
"location": location,
"review_score": review_score,
"review_number": review_number,
"price_summary": price_summary,
"total_price": total_price,
}
# Store the extracted data in the Actor dataset
await context.push_data(hotel)
# Run the Playwright crawler on the input URLs
await crawler.run(urls)
In around 100 lines, you've built a Python-based hotel listing Actor to scrape Expedia.
Run it locally to verify that it works with:
apify run
Note that on a free Apify plan, you can only use residential proxies on deployed Actors. If you try to run the Actor locally, the connection to the proxy server will fail, and you’ll get this error:
The "Proxy external access" feature is not enabled for your account. Please upgrade your plan or contact support@apify.com
So, if you're on a free plan, you need to deploy your Actor to test it (we’ll show you how in the next step).
If you configure the Playwright crawler to start in headed mode, you’ll see:
In the terminal, you’ll notice an output like this:
[apify] INFO Initializing Actor...
[crawlee.crawlers._playwright._playwright_crawler] INFO Current request statistics:
┌───────────────────────────────┬──────────┐
│ requests_finished │ 0 │
│ requests_failed │ 0 │
│ retry_histogram │ [0] │
│ request_avg_failed_duration │ None │
│ request_avg_finished_duration │ None │
│ requests_finished_per_minute │ 0 │
│ requests_failed_per_minute │ 0 │
│ request_total_duration │ 0.0 │
│ requests_total │ 0 │
│ crawler_runtime │ 0.011538 │
└───────────────────────────────┴──────────┘
[crawlee._autoscaling.autoscaled_pool] INFO current_concurrency = 0; desired_concurrency = 2; cpu = 0; mem = 0; event_loop = 0.0; client_info = 0.0
[apify] INFO Scraping https://www.expedia.com/Hotel-Search?destination=Madrid%20Centro%2C%20Madrid%2C%20Community%20of%20Madrid%2C%20Spain®ionId=553248631822337314&latLong&d1=2025-07-25&startDate=2025-07-25&d2=2025-07-28&endDate=2025-07-28&adults=2&rooms=1&children=&pwaDialog=&daysInFuture&stayLength&sort=RECOMMENDED&upsellingNumNightsAdded=&theme=&userIntent=&semdtl=&upsellingDiscountTypeAdded=&categorySearch=&useRewards=false...
[crawlee.crawlers._playwright._playwright_crawler] INFO Final request statistics:
┌───────────────────────────────┬────────────┐
│ requests_finished │ 1 │
│ requests_failed │ 0 │
│ retry_histogram │ [0, 1] │
│ request_avg_failed_duration │ None │
│ request_avg_finished_duration │ 30.639641 │
│ requests_finished_per_minute │ 1 │
│ requests_failed_per_minute │ 0 │
│ request_total_duration │ 30.639641 │
│ requests_total │ 1 │
│ crawler_runtime │ 75.402857 │
└───────────────────────────────┴────────────┘
[apify] INFO Exiting Actor ({"exit_code": 0})
These logs confirm that your Expedia scraper ran successfully. In the datasets/default/ folder, you should find 100 JSON files:
Each contains the data scraped from an individual hotel listing.
Great! It only remains to deploy your Expedia scraping script to Apify and run it in the cloud.
Bonus step: Deploy to Apify
Now we'll show you how to deploy your scraper to the Apify platform. This unlocks cloud execution, API access, and scheduling capabilities, so you can run the scraper at scale without managing infrastructure.
First, log in to your Apify account in the CLI with this command:
apify login
Then, you can deploy your Actor to Apify with:
apify push
Access your Apify dashboard and navigate to the Actors page. You’ll see your newly deployed “Expedia Scraper“ Actor:
Click on it, and in the Actor page, open the “Input” tab to configure it. In the “Start URLs” field, replace the default URL with the target Expedia URL:
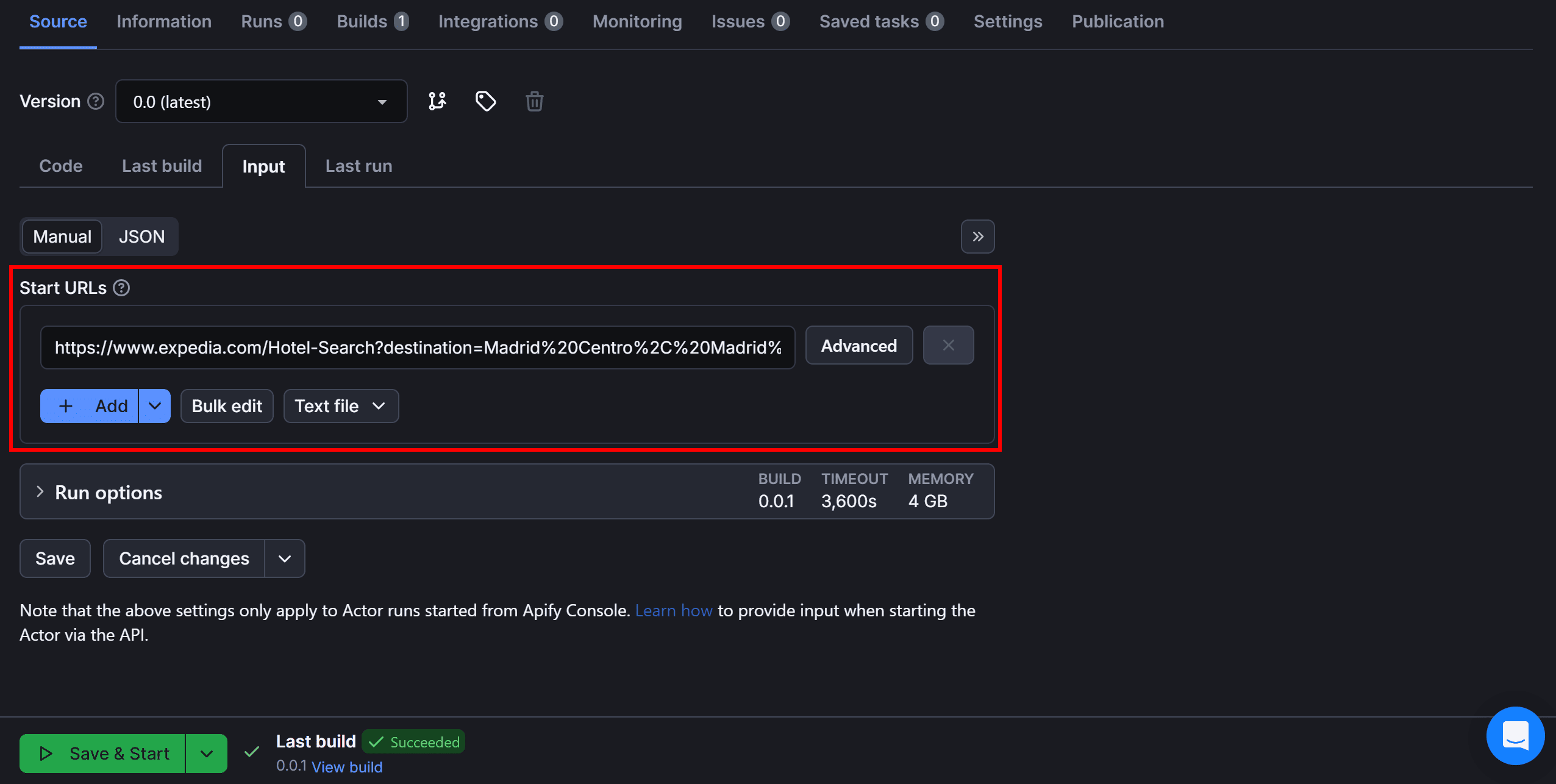
Once done, press the “Save & Start” button to run your Expedia scraping Actor in the cloud. After a few seconds of running, that’s what you should see:
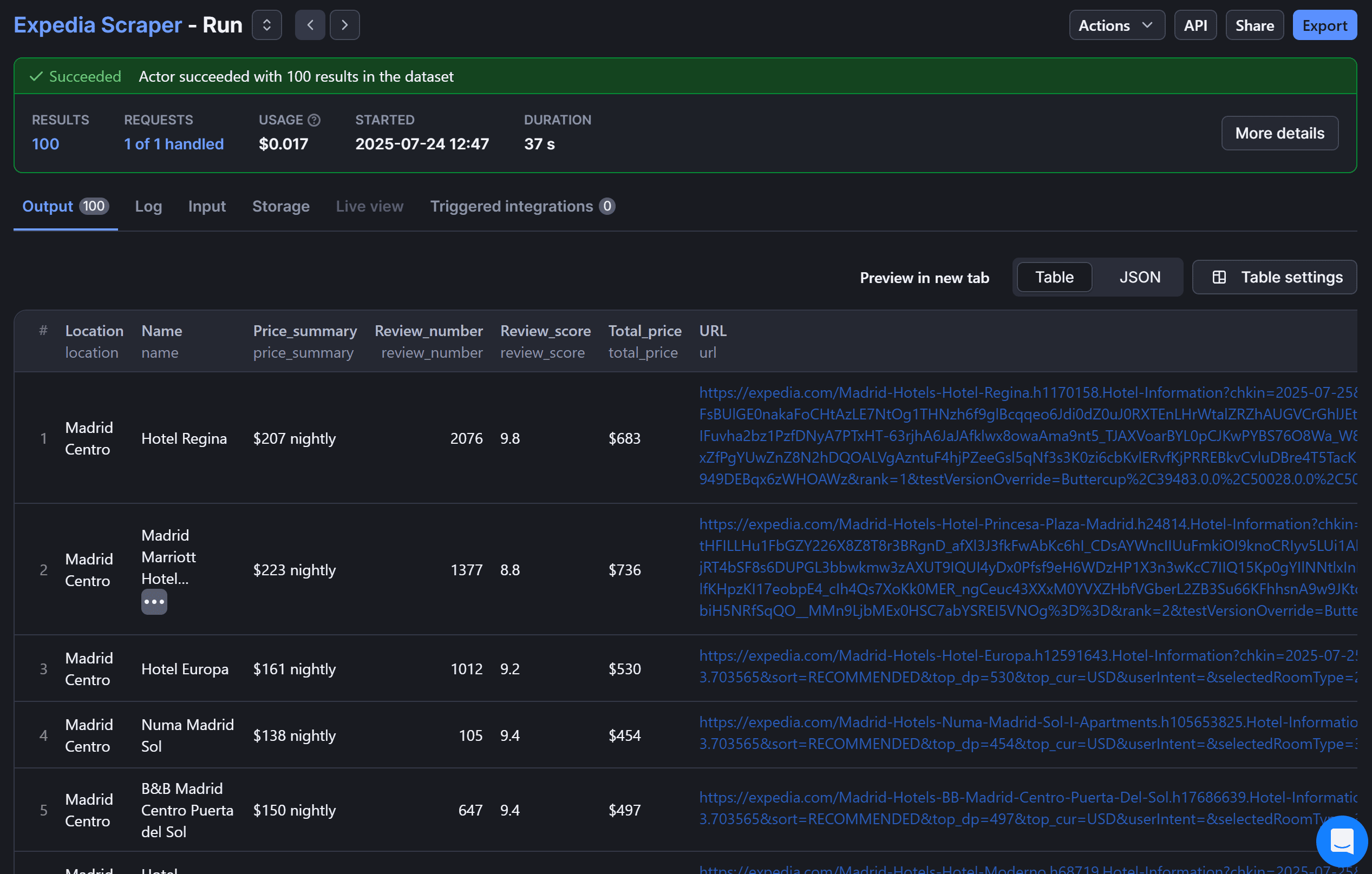
The “Output” tab now contains 100 hotel listings in structured format, just as expected. To download the scraped data, click the “Export” button in the top right corner. You can export the dataset in various formats, including:
- JSON
- CSV
- XML
- Excel
- HTML Table
- RSS
- JSONL
For example, export it as a CSV file, open it, and you’ll see the extracted hotel listings neatly organized:
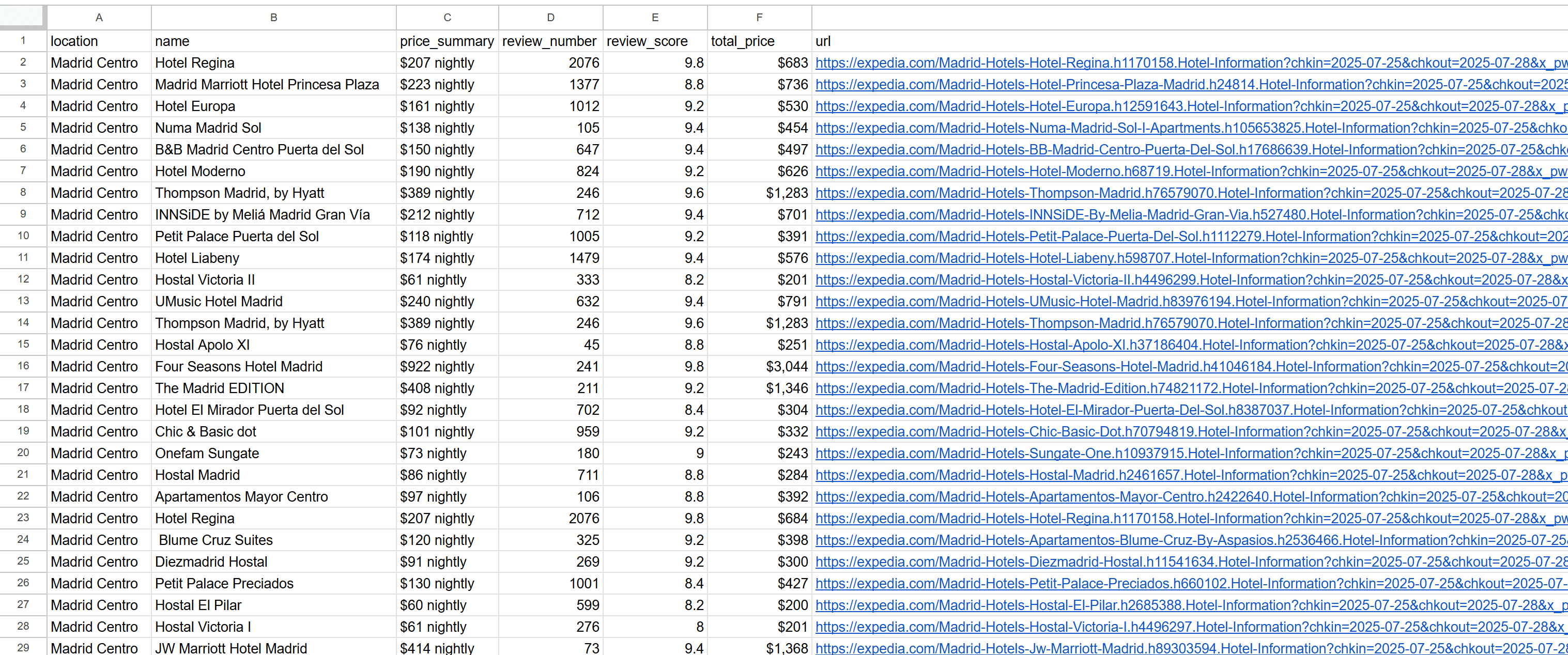
Et voilà! You’ve successfully scraped hotel data from Expedia.
Next steps
This tutorial covered the basics of scraping Expedia. To level up your script, explore these advanced techniques:
- Automated interaction: Use Playwright to interact with optional filters (e.g., star ratings or amenities) to refine hotel listings before scraping.
- Load More: Automate clicking the "Show more" button to load additional listings and ensure you're capturing the full dataset.
Using a ready-made Expedia scraper
Building a production-ready travel data scraper for Expedia is no easy task. One of the main challenges is that the Expedia site frequently changes its pages, forcing you to update your parsing logic. Also, too many requests can trigger anti-scraping mechanisms.
The easiest way to overcome them is by using a pre-made scraper that handles everything for you. Apify offers over 6,000 web scraping tools (Actors) for various websites, including around 40 specifically for Expedia.
If you want to scrape Expedia listings without building a scraper from scratch, just go to Apify Store and search for the "Expedia” keyword:
Select the “Expedia Hotels 3.0a" Actor and click "Try for free" on its public page:
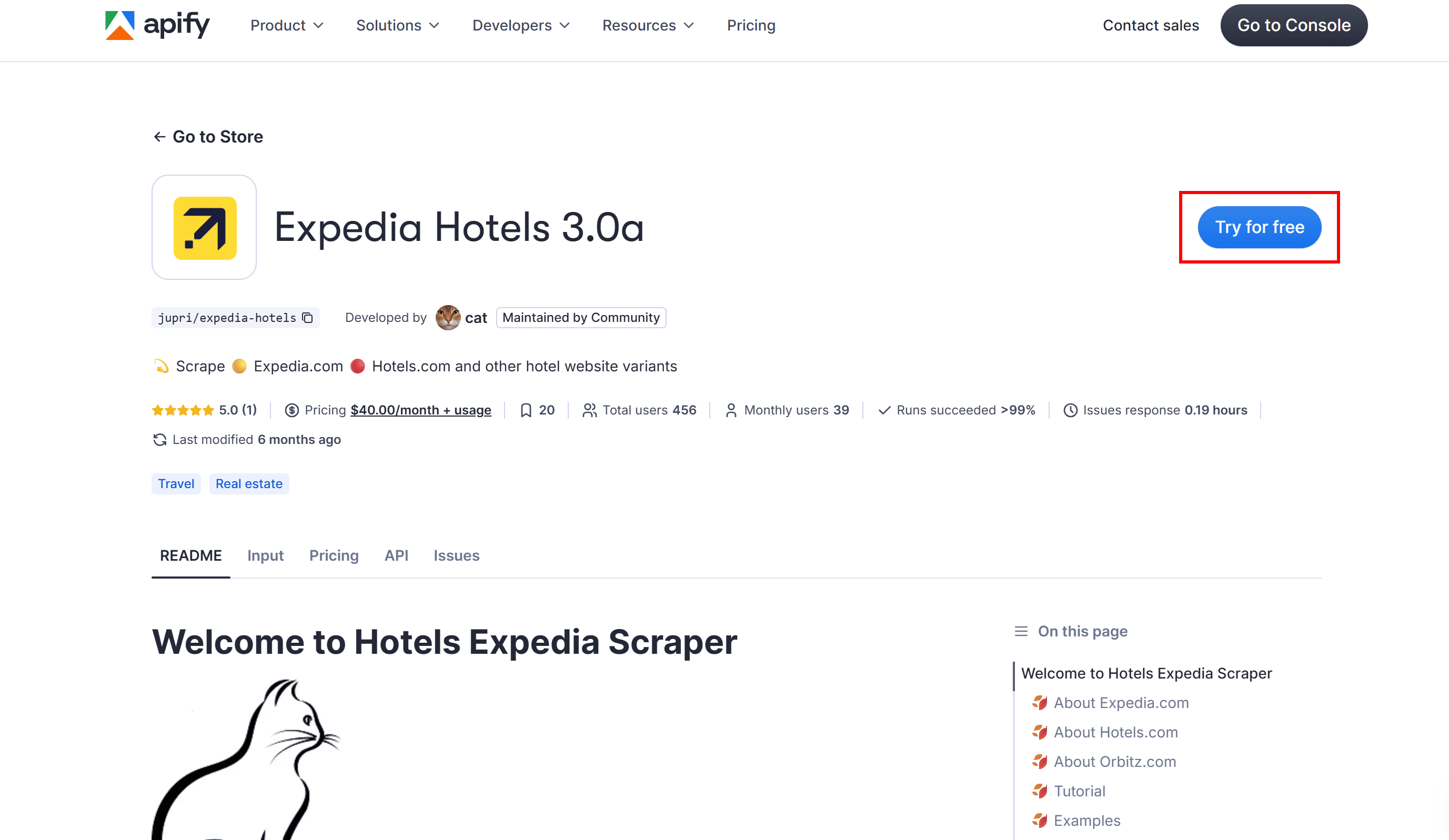
The Actor will be added to your Apify dashboard. Configure it based on your needs and click "Start" to launch it:
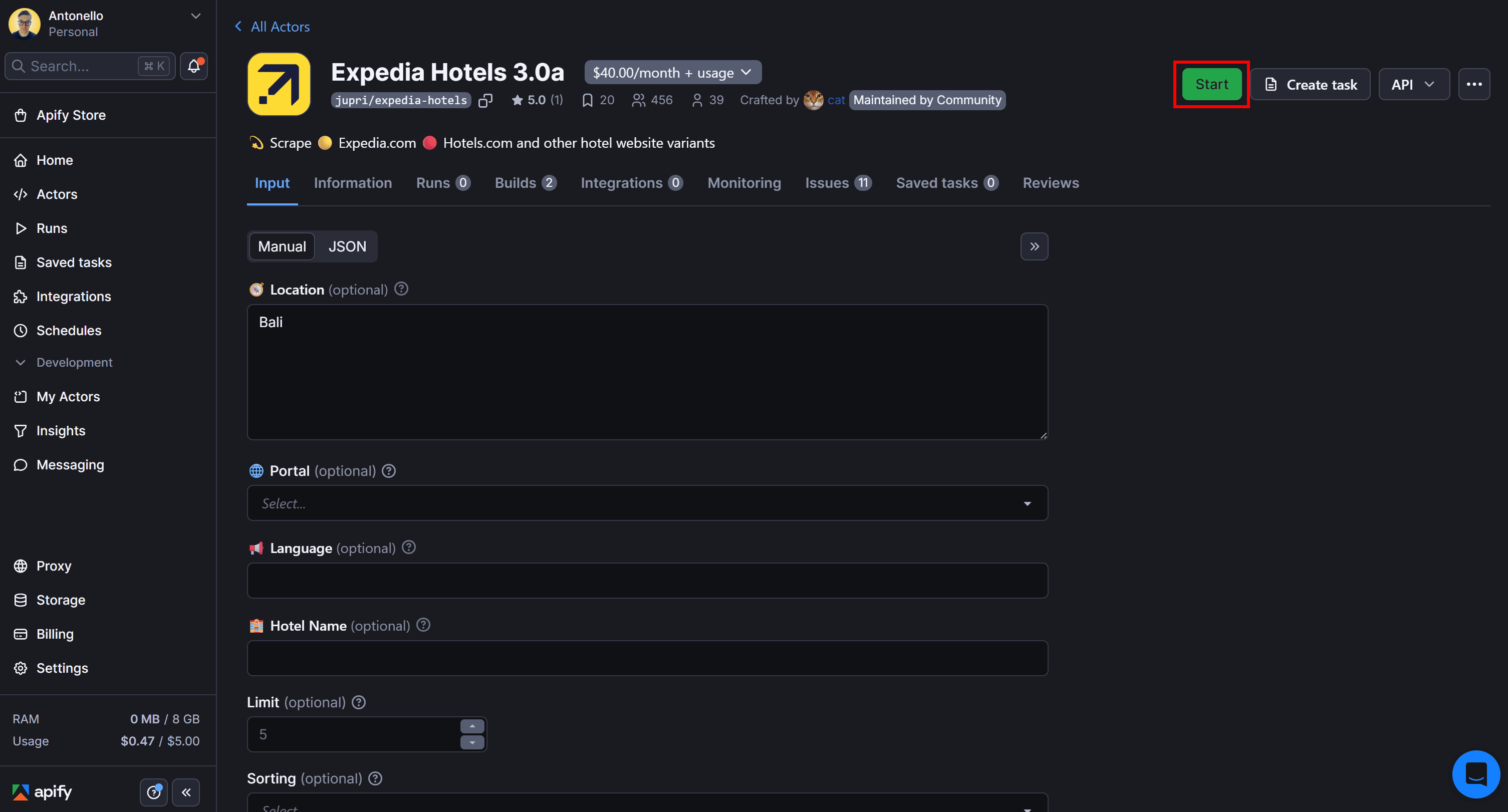
To test it for free, you must rent the Actor by clicking the “Rent” button:
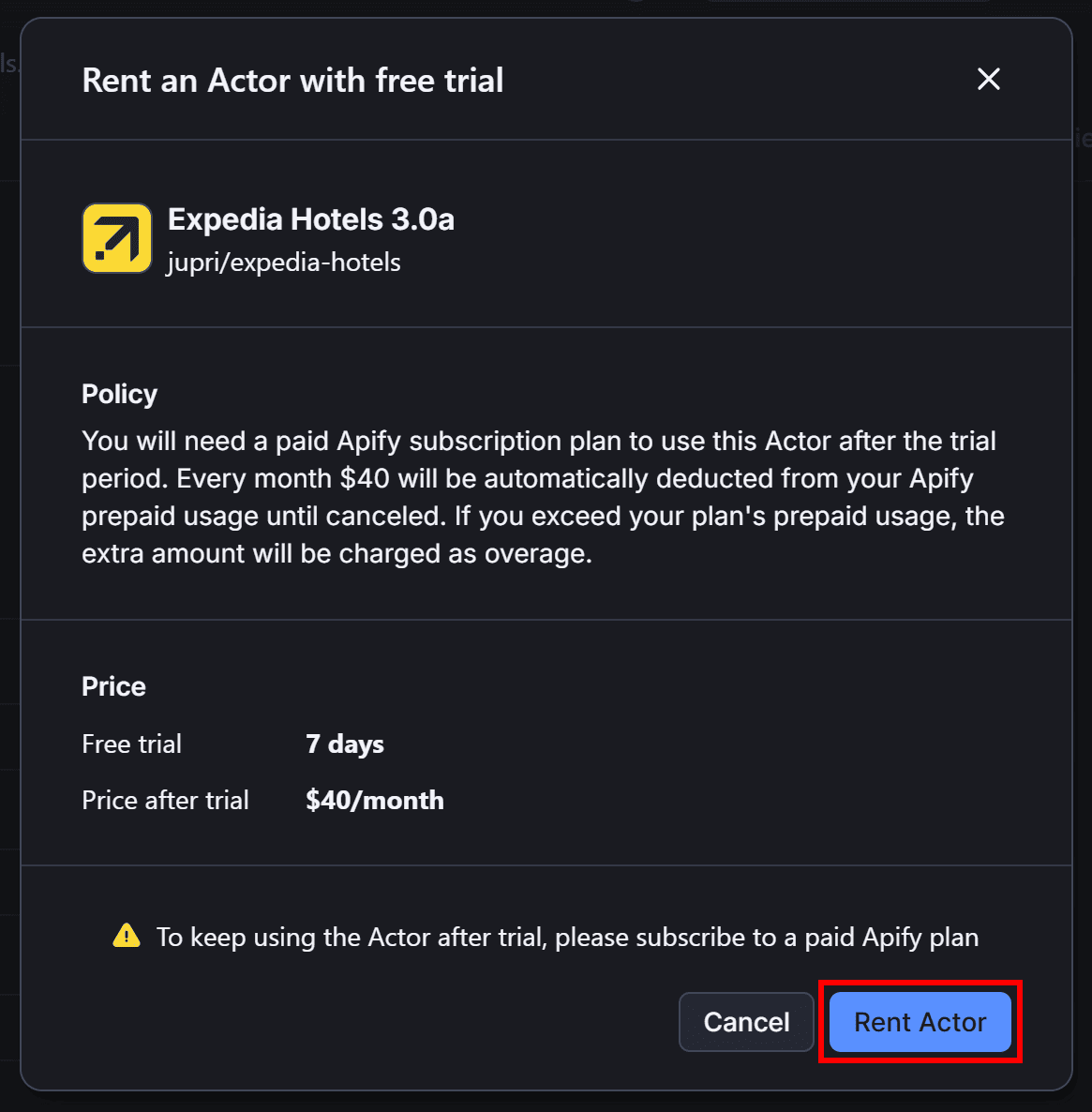
Then, press the “Save & Start” button:

Within seconds, you’ll see hotel listing data like this:
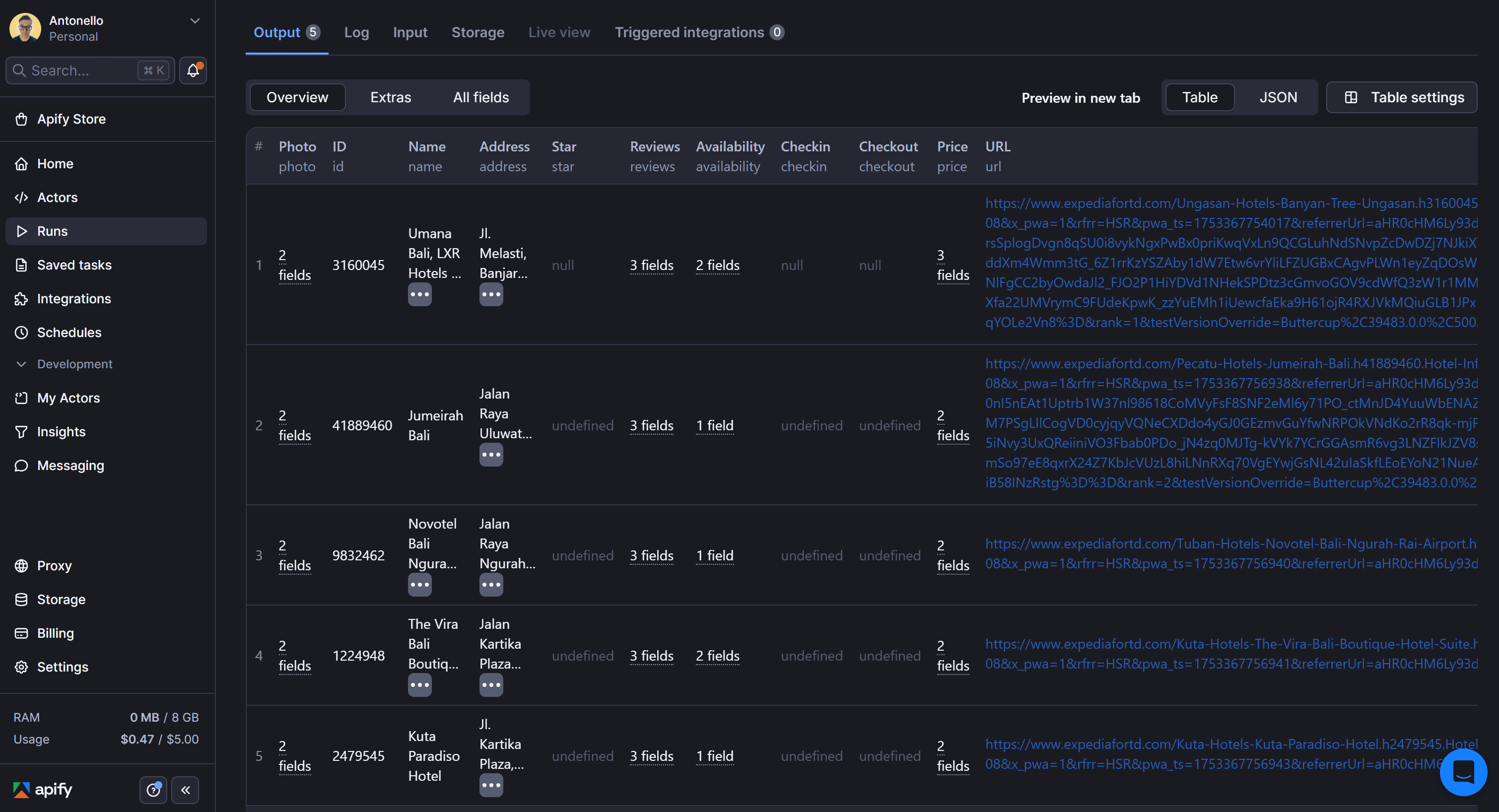
And that's it! You’ve successfully scraped Expedia hotel listings in just a few clicks. Note that you can also call any Actor programmatically via API integration.
Conclusion
In this tutorial, you used Apify’s “Crawlee + Playwright + Chrome” template to build an Expedia web scraper. With this, you extracted hotel listings from the platform and deployed the scraper on Apify.
This project demonstrated how Apify enables efficient, scalable web scraping while saving development time. You can explore other templates and SDKs to try additional scraping and automation features.
As shown here, using a pre-built Expedia Actor is the recommended way to simplify travel data extraction.
Frequently asked questions
Why scrape Expedia?
You want to scrape Expedia because it hosts millions of hotel listings worldwide, along with support for car rentals and flight bookings. This makes it a treasure trove of travel data that helps you build market analysis insights on pricing, availability, reviews, and more.
Can you scrape Expedia?
Yes, you can scrape Expedia using browser automation tools like Playwright, Selenium, and Puppeteer. That's required because Expedia loads data dynamically via JavaScript, so you must render its page in a browser. Also, you need tools that can support user interaction simulation.
Is it legal to scrape Expedia?
Yes, it is legal to scrape Expedia as long as you focus only on public data (data that isn’t behind a login wall). You can learn more in this detailed guide to the legality of web scraping.
How to scrape Expedia?
To scrape Expedia, use browser automation tools like Playwright. This helps you handle dynamic content and JavaScript rendering. Navigate to the target page, handle potential pop-ups, and apply the parsing logic to collect hotel listings. Integrate proxies to avoid blocks.




