


If you build lead-gen tools for local service businesses, you already know Craigslist is still one of the quickest ways to find people actively asking for help. The problem is scale: refreshing dozens of category pages - city by city - burns hours, and still misses posts that disappear within minutes.
This tutorial shows you how to solve that problem and turn Craigslist into a lead pipeline. You’ll learn how to:
- Write a Python scraper that extracts every key field - title, price, location, date, description, image URL - from any Craigslist category or city.
- Deploy it to Apify’s full-stack cloud platform, turning a local script into an always-on data feed with proxy rotation, scheduled runs, and one-click exports.
- Prefer a zero-code path? Run a ready-made Craigslist scraper and get the same structured dataset in minutes.
How to scrape Craigslist using Python
We’ll show you how to build a scraper locally and then deploy it to the cloud in 4 steps:
- Setting up the environment.
- Understanding the Craigslist web structure
- Writing the Python code
- Deploying to Apify (Optional but recommended)
We'll then show you the no-code option.
1. Setting up the environment
To start building:
- Make sure you've installed Python 3.9 or higher.
- Create a virtual environment (optional but recommended): It’s always a good practice to create a virtual environment (
venv) to isolate dependencies and avoid conflicts between packages.
python -m venv myenv
source myenv/bin/activate # On macOS/Linux
myenv\\\\Scripts\\\\activate # On Windows
- Required libraries:
beautifulsoup4,selenium,webdriver-manager,pandas. Install them by running the command below in your terminal:
pip install beautifulsoup4 selenium webdriver-manager pandas
To import the libraries, use the following code:
import time
import pandas as pd
from bs4 import BeautifulSoup
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.chrome.options import Options
from webdriver_manager.chrome import ChromeDriverManager
If you want to avoid local downloads and set-up, skip the process and deploy on Apify.
2. Understanding the Craigslist web structure
Before scraping any website, a rule of thumb is to inspect and understand its inner structure. To do that on Craigslist, go to craigslist.org > right-click on any element > inspect. Or else, you can press the F12 key to open Developer Tools.
When you visit Craigslist.com, it will automatically redirect you to your location’s dedicated subdomain, like newyork.craigslist.org. On the home page, you can see the categories of listings, such as services, housing, jobs, etc.
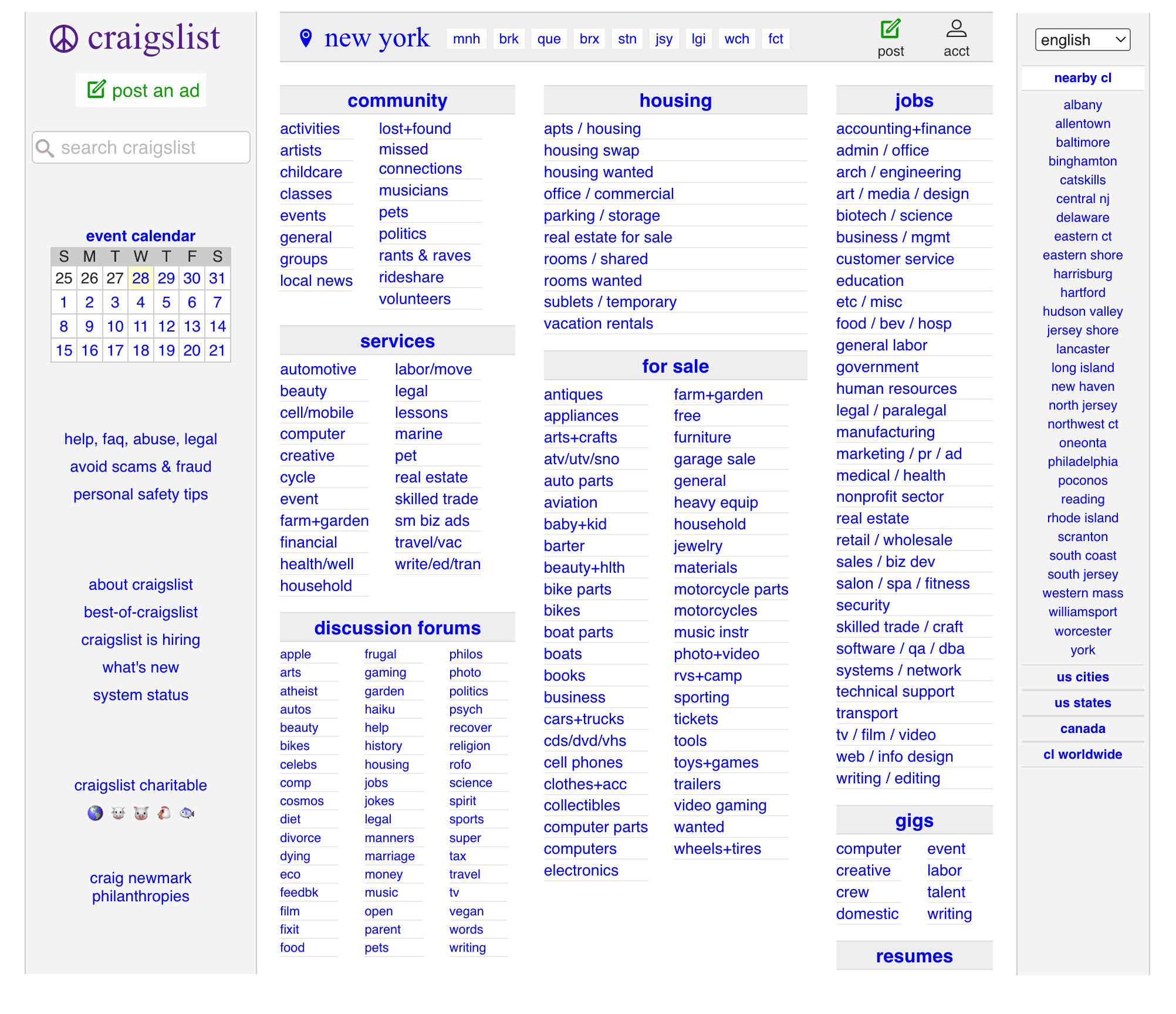
From there, select a category you want to scrape and inspect it. For this tutorial, we’ll be scraping the “Computer” category in the “Services list”.
- Note that while the names of the elements may change from one category to another, the method for scraping the information remains the same. So if you want to scrape some other category, like Job listings, follow the same steps on that specific page.
When inspecting the web structure, you’ll notice that these listings follow this pattern:
- Every listing is inside a
<div>class with thecl-search-result cl-search-view-mode-thumbclasses. - The location is in a plain
<div>element, inside its parent<div>with the classresult-info - The title of the listing is also inside the
<div>element with the classresult-info, in a<a>element with the classestext-only posting-title. - The timestamp of the listing is inside the
<div>element with the classmeta.
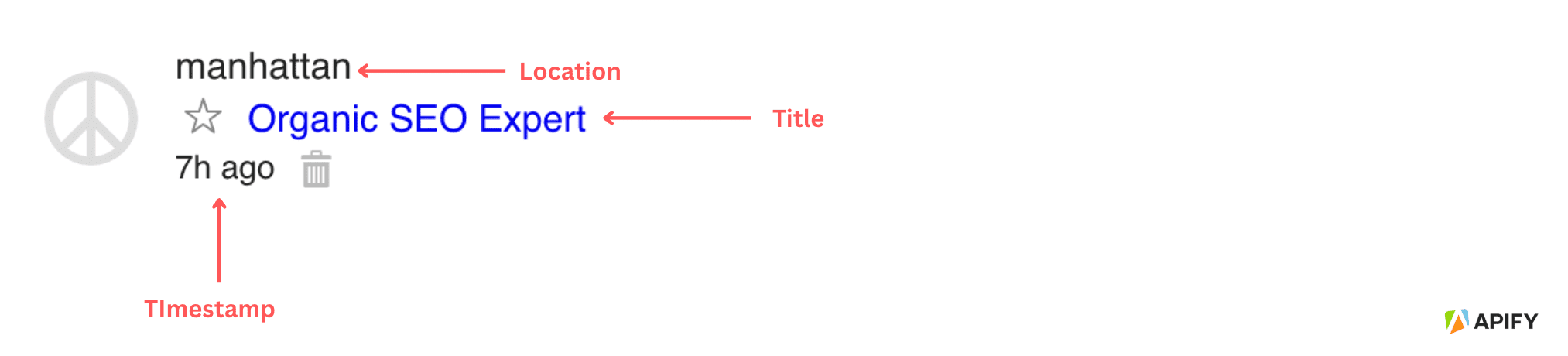
Now that you have a clear understanding of the structure of the website, we can proceed to writing the code for scraping craigslist.org.
3. Writing the scraper code
Now that you've set up the library imports, you can start with the base configuration:
base_url = "https://newyork.craigslist.org/search/cps#search=2~thumb~0"
target_listings_count = 50
all_listings_data = []
print("Initializing Selenium WebDriver...")
selenium_options = Options()
selenium_options.add_argument('--headless') # Run in headless mode (no browser window)
selenium_options.add_argument('--disable-gpu') # Recommended for headless
selenium_options.add_argument('--window-size=1920,1080') # Specify window size
selenium_options.add_argument(
"user-agent=Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36")
BASE_URL is the URL of the page you want to scrape, and USER_AGENT is defined to mimic an actual browser request. Then we configure the webdriver to run in headless mode, which means it won’t open a browser window in your interface.
Note that you can change the target_listing_count to any number you want, depending on how many listings you want to scrape.
Next up, you have to initiate the webdriver:
driver = None # Initialize driver to None for the finally block
try:
service = Service(ChromeDriverManager().install())
driver = webdriver.Chrome(service=service, options=selenium_options)
# --- Fetch and Parse the First Page ---
print(f"Fetching listings from: {base_url}")
driver.get(base_url)
# Wait for the page to load (feel free adjust sleep time if necessary, or implement explicit waits for more robustness)
print("Waiting for page content to load...")
time.sleep(5)
soup = BeautifulSoup(driver.page_source, 'html.parser')
The above code initiates the webdriver to navigate to the target URL, and then uses BeautifulSoup to parse the fully rendered HTML content. This approach is often used for websites that rely on JavaScript to dynamically load data, like Craigslist.
Then you can extract the information based on the class names inspected on Craigslist. While you can use the same procedure to scrape anything on any page by simply changing the class names and base URL, for the sake of this tutorial, we’ll scrape 3 important parts of the Computer Services page: Posting title, location, and date posted.
listings_on_page = soup.find_all('div', class_='cl-search-result')
if not listings_on_page:
print("No listings found. The website structure might have changed.")
else:
print(f"Found {len(listings_on_page)} listings. Processing up to {target_listings_count}...")
for listing_item in listings_on_page:
if len(all_listings_data) >= target_listings_count:
print(f"Collected {len(all_listings_data)} listings. Target reached.")
break
title = 'N/A'
post_url = 'N/A'
location = 'N/A'
date_posted = 'N/A'
result_info = listing_item.find('div', class_='result-info')
if result_info:
# Extract Title and URL
title_anchor = result_info.find('a', class_='posting-title')
if title_anchor:
title = title_anchor.text.strip()
if title_anchor.has_attr('href'):
post_url = title_anchor['href']
title_blob = result_info.find('div', class_='title-blob')
if title_blob:
# The location is in a plain <div> that is the previous sibling of the title-blob div.
location_element = title_blob.find_previous_sibling('div')
if location_element:
location = location_element.text.strip()
# Extract Date Posted
meta_div = result_info.find('div', class_='meta')
if meta_div:
date_span = meta_div.find('span', title=True)
if date_span:
date_posted = date_span.text.strip()
all_listings_data.append([title, location, date_posted, post_url])
if len(all_listings_data) < target_listings_count:
print(f"Collected {len(all_listings_data)} listings. Target of {target_listings_count} not reached from this page.")
Above, all the listings are extracted first, and then the title, post URL, location, and date posted are extracted based on the class names. At the end, a log of the number of listings extracted is printed.
Finally, write the code to quit the webdriver and save the extracted data to a pandas dataframe:
except Exception as e:
print(f"An error occurred during scraping: {e}")
finally:
if driver:
print("Quitting Selenium WebDriver...")
driver.quit()
# --- Store Data in Pandas DataFrame ---
if all_listings_data:
print(f"\\n--- Creating DataFrame with {len(all_listings_data)} Listings ---")
df = pd.DataFrame(all_listings_data, columns=['Title', 'Location', 'Date Posted', 'URL'])
print("First 5 rows of the DataFrame:")
print(df.head())
print(f"\\nTotal listings in DataFrame: {len(df)}")
else:
print("No data was scraped to create a DataFrame.")
If you want to save the results to a CSV file, use this code:
try:
df.to_csv('craigslist_jobs.csv', index=False)
print("\\nData saved to craigslist_jobs.csv")
except Exception as e:
print(f"Error saving to CSV: {e}")
And voila! You've successfully created a Craigslist scraper that can effectively scrape Craigslist’s Computer services script (and any other page with minor tweaks). Once run, you’ll see an output like this:
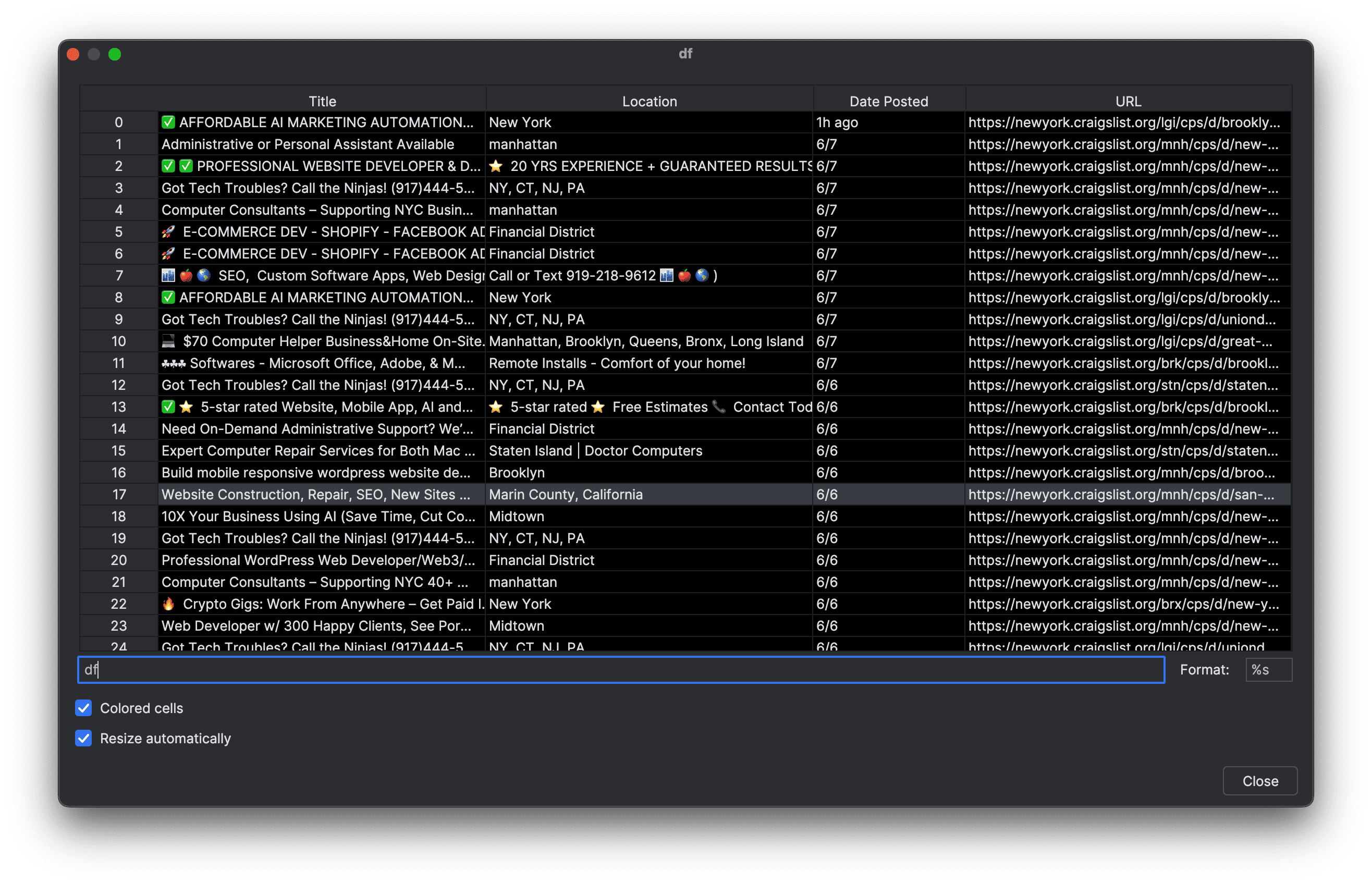
4. Deploying to Apify
Creating and running a scraper locally is great, but it’s not without issues, like automating runs and downloading the data in different formats. It’s not impossible to write code to do the above, but why bother when you can just deploy the scraper on a cloud platform like Apify that offers advanced features?
To deploy the Craigslist scraper we built above on Apify, just follow these steps:
#1. Create an Apify account
- You can get a forever-free plan - no credit card is required.
#2. Create a new Actor
- First, install Apify CLI using NPM or Homebrew in your terminal.
- Create a new Actor with Apify’s empty Python template as the base so that you don’t have to create every file from scratch.
apify create my-craigslist-actor -t python-empty
- Change the directory to the Actor:
cd my-craigslist-actor
#3. Update requirements.txt and DOCKERFILE
This can be found in the root folder, and it contains the dependencies to be installed. Replace the files with the following.
- requirements.txt:
apify
beautifulsoup4
selenium
webdriver-manager
- DOCKERFILE:
FROM apify/actor-python:3.13
RUN apt-get update && apt-get install -y --no-install-recommends \\
gnupg \\
ca-certificates \\
fonts-liberation \\
libasound2 \\
libatk-bridge2.0-0 \\
libatk1.0-0 \\
libcups2 \\
libdbus-1-3 \\
libdrm2 \\
libgbm1 \\
libgconf-2-4 \\
libgtk-3-0 \\
libnspr4 \\
libnss3 \\
libpango-1.0-0 \\
libx11-6 \\
libx11-xcb1 \\
libxcb1 \\
libxcomposite1 \\
libxcursor1 \\
libxdamage1 \\
libxext6 \\
libxfixes3 \\
libxi6 \\
libxrandr2 \\
libxrender1 \\
libxss1 \\
libxtst6 \\
lsb-release \\
wget \\
xdg-utils \\
&& rm -rf /var/lib/apt/lists/*
RUN wget -q -O - https://dl-ssl.google.com/linux/linux_signing_key.pub> | apt-key add - \\
&& echo "deb [arch=amd64] http://dl.google.com/linux/chrome/deb/> stable main" > /etc/apt/sources.list.d/google.list \\
&& apt-get update \\
&& apt-get install -y google-chrome-stable --no-install-recommends \\
&& rm -rf /var/lib/apt/lists/*
COPY requirements.txt ./
RUN echo "Python version:" \\
&& python --version \\
&& echo "Pip version:" \\
&& pip --version \\
&& echo "Installing dependencies:" \\
&& pip install -r requirements.txt \\
&& echo "All installed Python packages:" \\
&& pip freeze
COPY . ./
RUN python3 -m compileall -q src/
RUN useradd --create-home apify && \\
chown -R apify:apify ./
USER apify
CMD ["python3", "-m", "src"]
#4. Change the main.py file
In order to deploy on Apify, you’ll have to make some minor changes to the main.py script. Some of the critical changes are as follows:
- Integrating the Apify SDK: The script now uses the Apify library, wrapping the logic in
async def main()andasync with actor(which is the required structure for any Apify Actor) - Changing data output: Instead of the local list and dataframe, which are not detected by Apify as output, we use
apify.push_datato store the outputs in Apify itself. - Removing Local WebDriver Management: The webdriver-manager library was removed. The script now relies on the pre-configured Selenium environment provided by Apify, a necessary change for running in the cloud.
You can find the main.py in the src found in your Actor. Change it to the script with the above changes, which you can find on GitHub.
#5. Deploy
- Once files are ready to go, log in to Apify using the
apify logincommand in your terminal. You can log in via the web browser or the API key - Use the
apify pushcommand to complete the deployment, and you’re good to go!
You can now view your Actor in Apify Console. Locate the Actor and click the “Start” button.
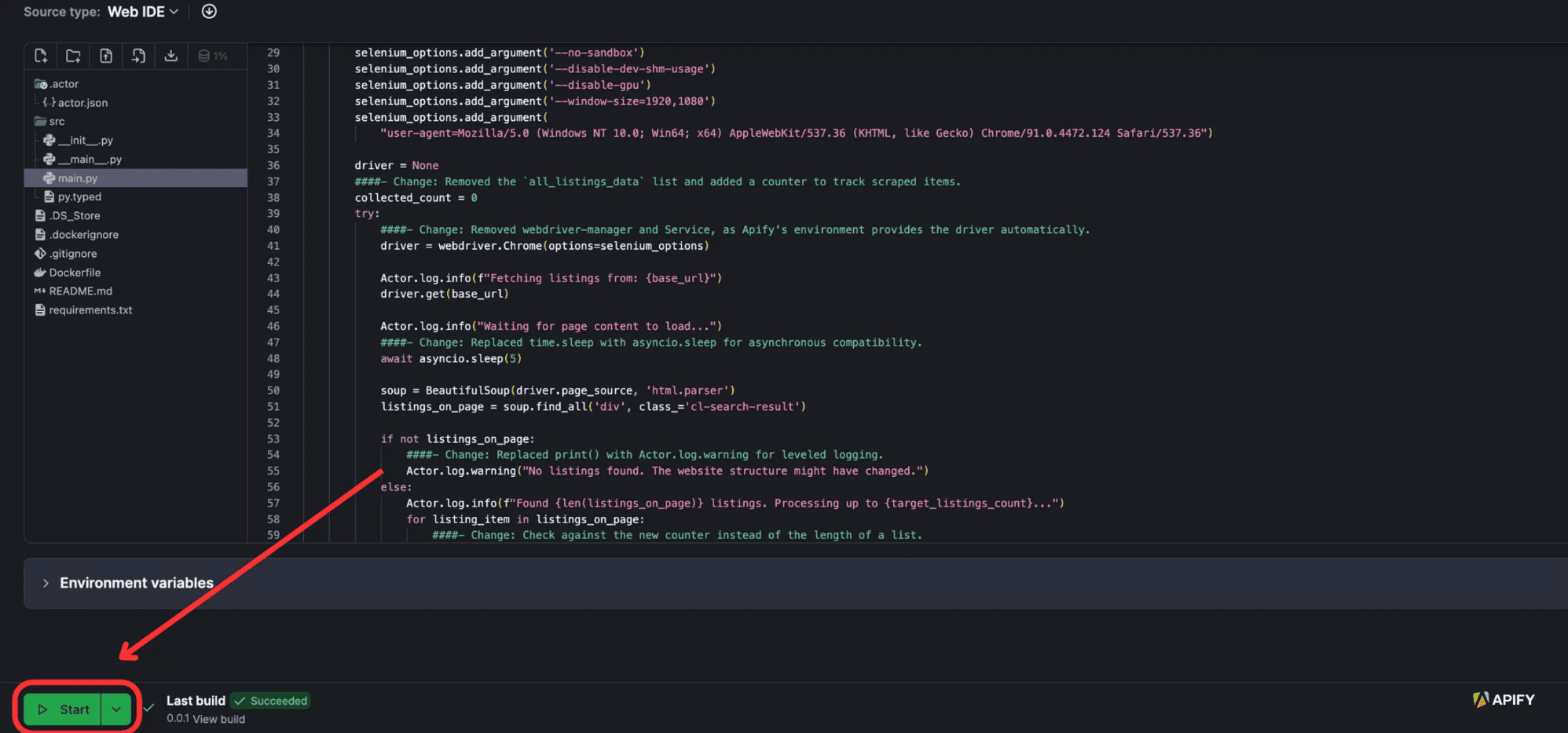
When the Actor is built and run, you can see the outputs on the “Output” tab, which will look like this:
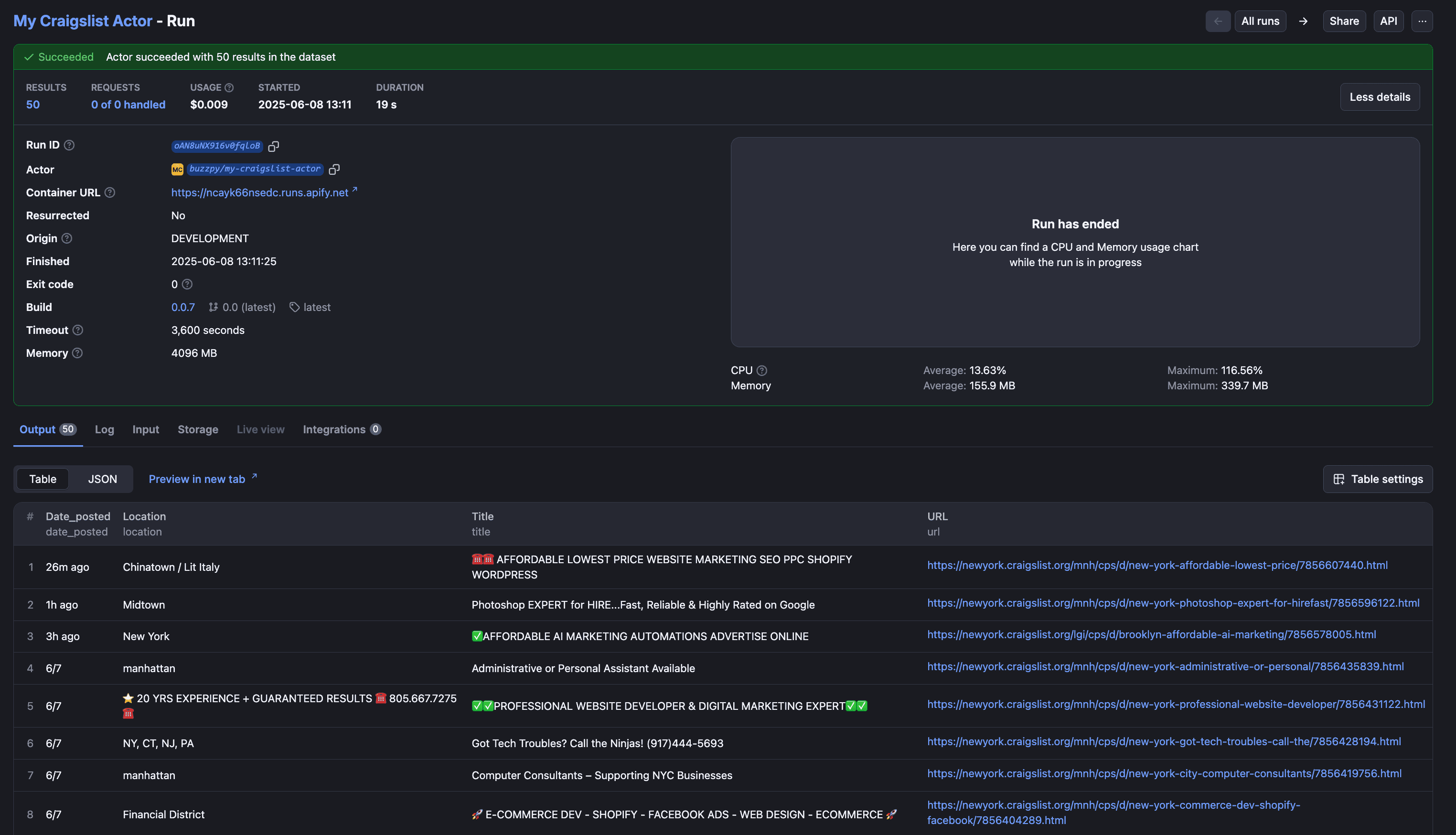
Use a ready-made Craigslist scraper
Building a scraper from scratch is a great way to learn, but it can get exhausting, especially when you have to deal with CAPTCHAs and other bot prevention algorithms. In fact, it has more downsides than upsides, like managing response parsing when the website structure changes, debugging silent failures (due to dynamic JavaScript rendering), and dealing with inconsistent or incomplete data from poorly structured pages.
If you want to avoid going through all this trouble and possible headaches, you can simply use a ready-made scraper on a platform like Apify. With an off-the-rack solution like Apify’s Craigslist scraper, you can just choose which section/page of Craigslist you want to scrape and run the scraper.
To try it out, go to Craigslist Scraper on Apify and click Try for free. If you don't have an Apify account, you'll be prompted to sign up for a forever-free plan first (no credit card required).
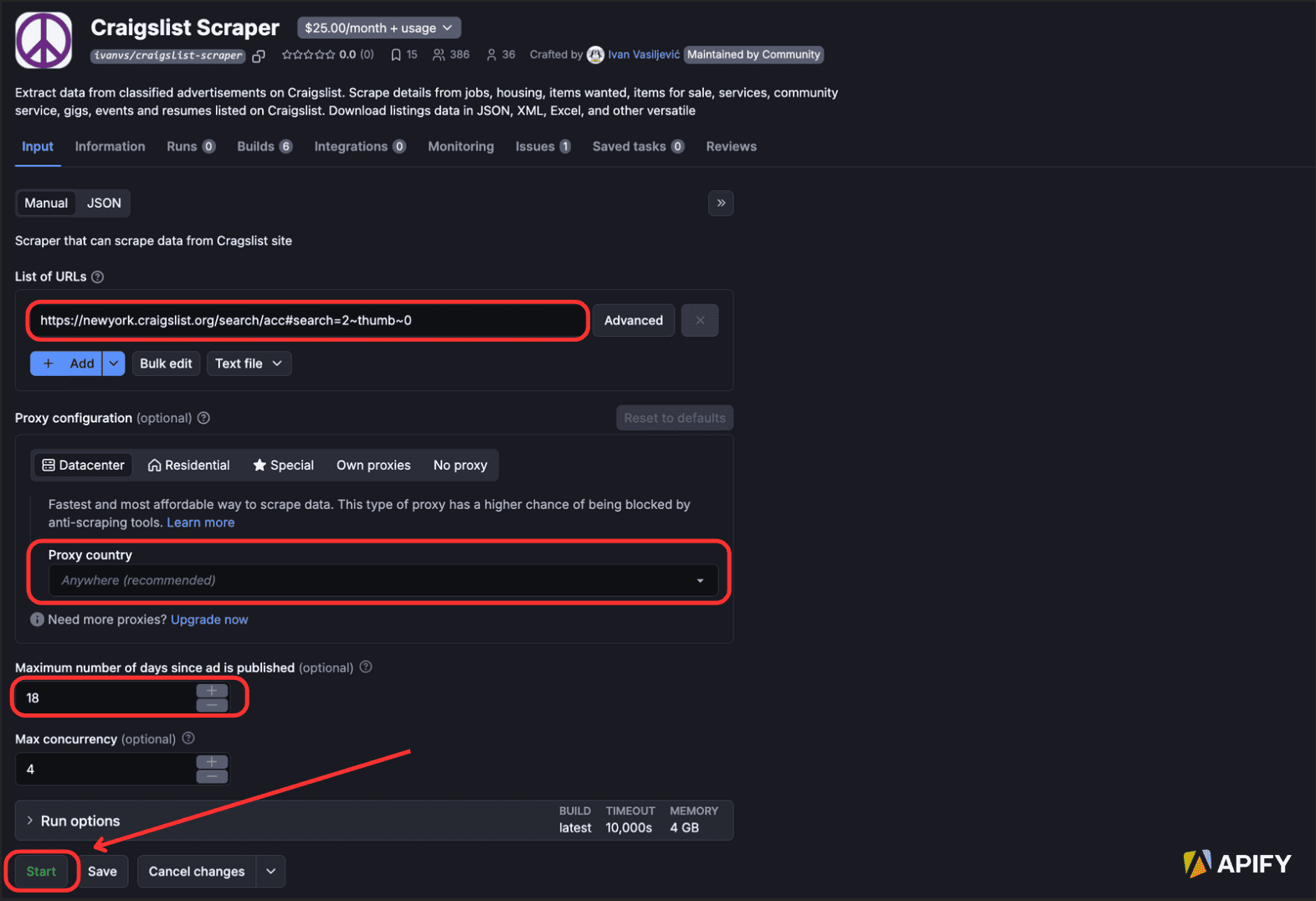
You'll then be taken to the Craigslist Scraper page in Apify Console where you can fill out the entries as desired (URL, posted date range, proxies, etc.). Click “Run” to start the scraper.
Once run, you’ll see an output like this:
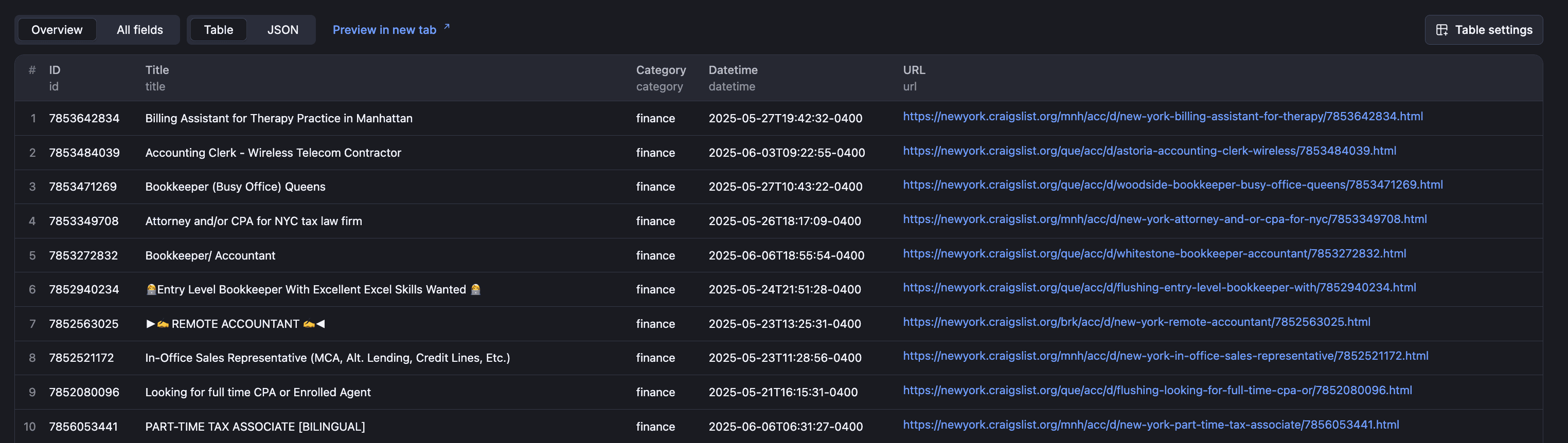
You can import the output in different formats using the “Export output” button, and also automate the Actor to run automatically on schedules.
- Note: This takes minutes, whereas you need at least an hour to build a scraper from scratch with these features
A quick recap
In this tutorial, we scraped Craigslist using two methods:
- 1) building a scraper from scratch with Python code, and
- 2) using a ready-made scraping tool.
The first option allows you to create a customized scraper for your particular use case, while the second saves you the time and effort of handling the complexities of web scraping.
Frequently Asked Questions
Can you scrape Craigslist?
Yes, you can scrape Craigslist to extract data like listings or prices by using programming libraries like BeautifulSoup or Selenium to locate image tags, extract their source URLs, and download them using HTTP requests. Or else, you can use a ready-made scraper on Apify.
Why scrape Craigslist?
There are a lot of reasons that one would need to scrape an extensive website like Craigslist. Notable ones would be the extraction of data for Market research, data analysis & visualization, or just web scraping as a hobby. You can also use it to filter out and extract information about paid gigs, if you’d like to earn some extra cash.
Is it legal to scrape Craigslist?
Yes. Web scraping is legal if you scrape data that is publicly available on the internet. However, some kinds of data are protected by terms of service or national and even international regulations, so take great care when scraping data behind a login, personal data, intellectual property, or confidential data.
How to scrape Craigslist?
To scrape Craigslist, you can use Apify's Craigslist scraper. It allows you to scrape metadata from Craigslist, such as titles, prices, locations, posting dates, and links to listings, while also supporting advanced proxy features.




