Fresh, structured web data is the fuel for AI, including agents, RAG pipelines, competitive‑intelligence dashboards, and change‑monitoring services. Two platforms dominate that space in 2026:
- Firecrawl – an API‑first crawler that turns any URL into LLM‑ready Markdown/JSON in seconds.
- Apify – a full‑stack scraping platform with thousands of reusable data collection tools.
We'll go deep into the differences and what they do best, so you can choose (or combine) wisely.
Let's kick off with a table of each platform’s features, benefits, and trade‑offs so you can see where each one excels.
| Firecrawl | Apify | |
|---|---|---|
| Core value prop | Fast, semantic scraping API geared for AI | End-to-end scraping platform (6,000+ data collection tools, proxies, compliance) |
| Stand‑out features |
Pre-warmed browsers NL extraction AGPL OSS & self-host Stealth proxies |
Scraper marketplace JS/TS & Py SDKs Global proxy pool + CAPTCHA Cron-scheduler, retries, webhooks SOC 2 Type II and GDPR compliance |
| Primary benefits |
Sub-second latency on cached pages Prompt-based (no selectors) Predictable credit pricing |
Fine‑grained session & proxy control No‑code operation for analysts; devs extend via code |
| Pros |
✔ Fast single‑page fetches ✔ Self‑host to avoid vendor lock‑in ✔ Low entry cost (free + $16 Hobby tier) |
✔ Breadth: 10,000 off-the-shelf scrapers ✔ Effective anti‑blocking technology ✔ Monetize your own scrapers; earn rev‑share |
| Cons |
✖ Credits can disappear fast on large crawls ✖ Limited built-in scheduling ✖ AGPL copyleft for forks |
✖ Actors / CU concepts add a learning curve ✖ Consumption costs can spike with inefficient code ✖ Cold-start ≈1.5s |
Pricing
Firecrawl’s pricing model
Firecrawl uses a simple credit-based model: 1 page = 1 credit (under standard conditions). That makes it very easy to predict costs. The free tier lets you scrape up to 500 pages before committing financially (no credit card required). Paid plans range from $16 to $333 for standard pricing. Extraction tasks that go beyond simple scraping consume additional credits or tokens.
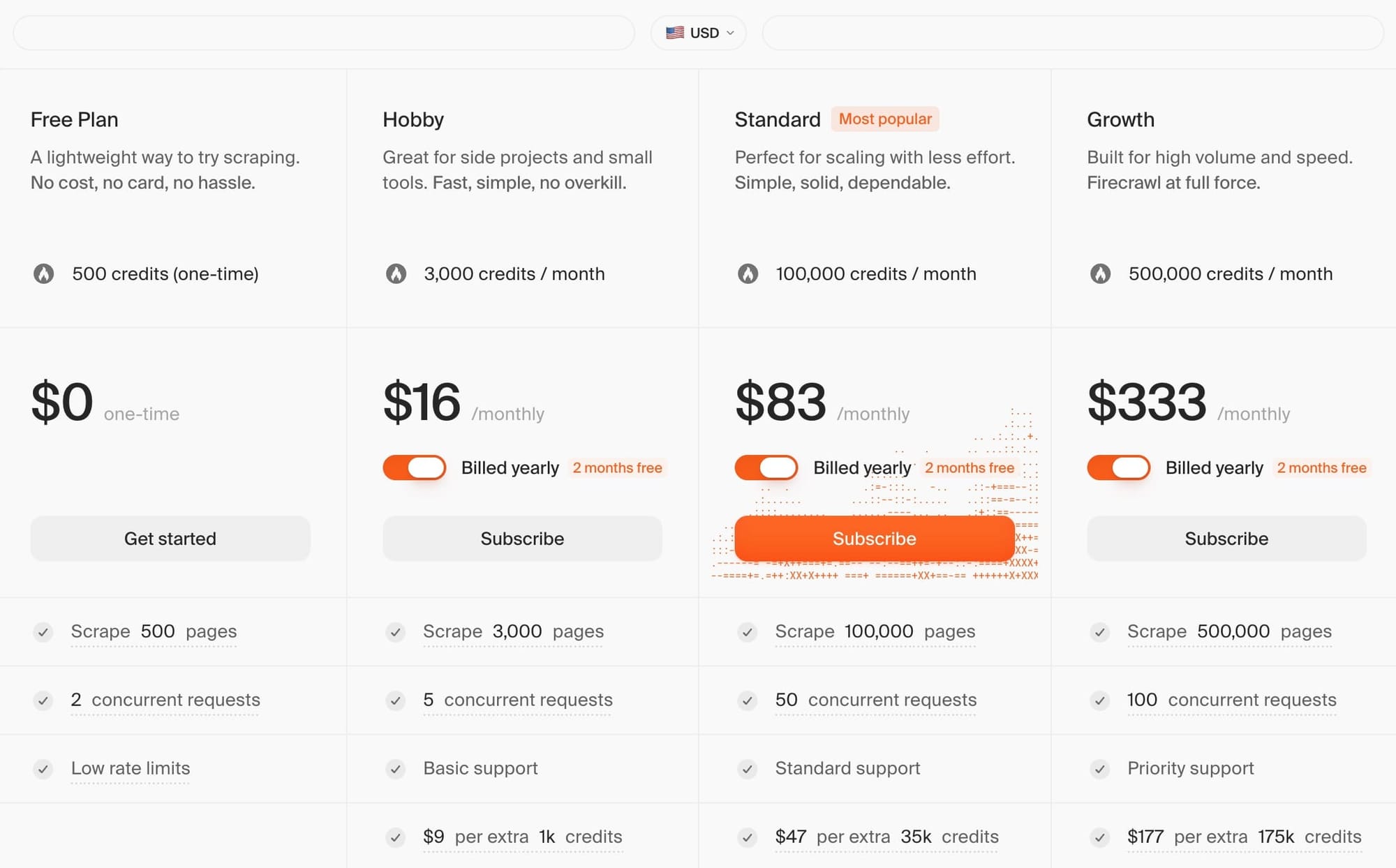
Apify’s pricing model
Apify combines a subscription and consumption model. You get a base amount of platform credit with each pricing plan, but the consumption rate depends on the resources used. 1 compute unit = 1 gigabyte-hour of RAM.
It’s harder to predict costs this way because scraping a JavaScript-rendered site that requires browser automation consumes a lot more than a simple HTML scraper.
That’s why Apify has introduced pay-per-event pricing. Scrapers with this pricing model charge for specific actions rather than just results. For example, a scraper that charges $5 per run start and $2 per 1,000 results would cost $15 for 5,000 results. This can make large-scale scraping jobs cheaper in the long run.
Apify's forever-free tier gives you $5 of credit that renews automatically every month, so you can test any scraper on Apify Store without financial commitment (no credit card required). Paid plans range from $29 to $999 per month.
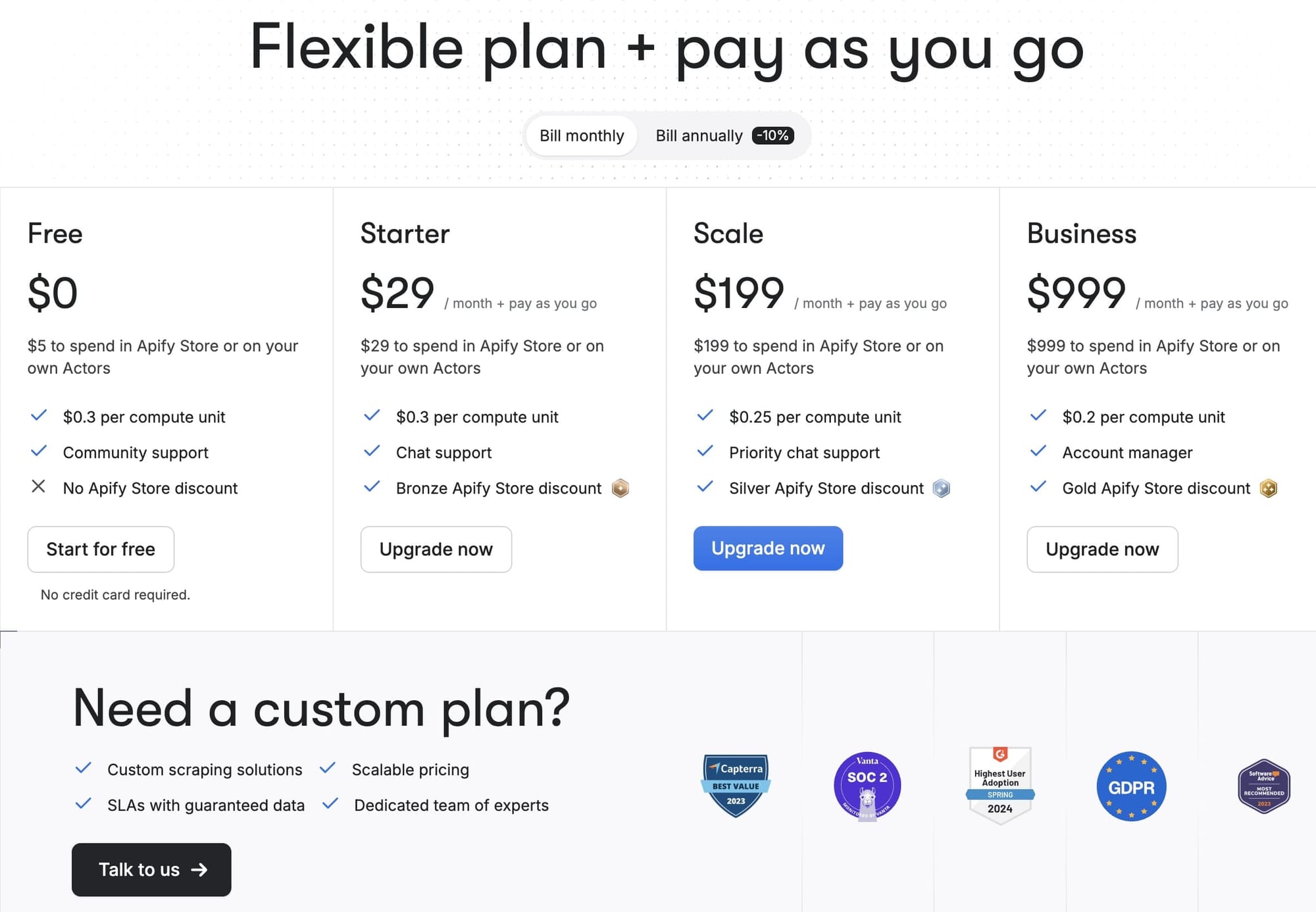
Firecrawl and Apify pricing compared
| Firecrawl (flat credits) |
Apify (pre-paid credit+CU) |
|
|---|---|---|
| Up to 3,000 pages | Hobby: $16 ✅ | Starter: $29 ✅ |
| Up to 100,000 pages | Standard: $83 ✅ | Scale: $199 ✅ |
| Up to 500,000 pages | Growth: $333 or Enterprise | Business: $999 or Enterprise |
| Summary |
Under 500k pages/month? Firecrawl is usually cheaper. Millions of lightweight pages or heavy anti‑bot workflows? A well‑optimized Apify scraper can win on total cost. |
|
Performance
Firecrawl: Unified AI-driven scraping
Firecrawl offers a single, consistent API that handles scraping, crawling, and AI‑driven site navigation, so developers never have to juggle multiple endpoints or bespoke parameters.
When you request a page, the service decides on‑the‑fly whether it needs a headless browser, waits for all dynamic elements to render, and then applies extraction models that automatically ignore ads, menus, and other noise.
Instead of writing brittle CSS or XPath rules, you ask for the data in plain language — “product prices and availability,” for example — and Firecrawl returns a clean JSON block that stays stable even when the site’s markup changes.
The same intelligence powers the crawler: it goes through internal links without sitemaps, skips duplicate content, and can infer which pages matter most from their position in the site hierarchy and linking patterns, all while respecting any boundaries you set.
For sites that hide information behind clicks, forms, or paginated views, you can enable the FIRE‑1 agent. It mimics human behavior by clicking “Load More,” filling search fields, and even solving simple CAPTCHA, eliminating special‑case code.
Performance optimizations run throughout the platform. Recently scraped pages come from cache in milliseconds, hundreds of URLs can be batched in a single call for parallel processing, and converting HTML to lightweight Markdown cuts the token count for downstream LLMs by roughly two‑thirds. The net effect is faster, lower‑maintenance data collection that remains reliable as websites evolve.
Apify: A comprehensive, flexible ecosystem
Apify approaches web scraping as an ecosystem problem rather than a single‑tool exercise. Its foundation is the Actor system — self‑contained programs that run in Apify’s cloud with uniform input/output, shared storage, and common scheduling and monitoring. Because every Actor behaves the same way, you can link them into multistep workflows just by passing data from one to the next.
This standardization fuels Apify Store, a marketplace of more than 10,000 pre‑built scrapers and automation tools maintained by domain specialists. If you need Amazon product data, Instagram follower stats, or a one‑off government registry crawl, chances are an Actor already exists and is kept up to date as site layouts change, so you rarely start from a blank page.
When an off‑the‑shelf Actor doesn’t fit, you can build your own with the Apify SDK (also released as the open‑source Crawlee library). The SDK offers high‑level helpers — request queues, automatic retries, error handling, parallel processing — while still letting you drop down to raw Puppeteer, Playwright, or HTTP calls when necessary. It supports both JavaScript/TypeScript and Python, making it easy to slot into existing codebases.
Infrastructure management is largely hands‑off. Apify autoscales compute instances, rotates datacenter or residential proxies by geography, and applies anti‑detection tactics such as browser‑fingerprint randomization, human‑like delays, and outsourced CAPTCHA solving. Enterprise‑grade features cover the operational side: detailed run statistics, alerting, conditional scheduling (e.g., “scrape 100 sites at 06:00 only if yesterday’s run succeeded”), real‑time webhooks for downstream systems, and configurable result retention to satisfy compliance audits or historical analyses.
In practice, the platform lets teams mix and match ready‑made Actors, custom code, and reliable infrastructure to solve diverse scraping tasks without rebuilding each time.
| Technical feature | Firecrawl | Apify |
|---|---|---|
| API surface | Single base URL with multiple HTTP/JSON endpoints under one uniform API | Each Actor exposes a standard REST interface: you POST to the “run” endpoint with a JSON input and then GET results from key‑value stores or datasets |
| Dynamic‑content handling | Automatically spins up a headless browser when JS rendering is detected, with no extra configuration | You choose per Actor: Puppeteer, Playwright, Cheerio, raw HTTP, etc. |
| Extraction approach | “Zero‑selector” extraction: ML/NLP models parse pages into JSON or Markdown out‑of‑the‑box | Code‑based extraction inside each Actor using Crawlee's page handlers or raw selectors |
| Workflow composition | In a single request you can switch between scrape, crawl, or the FIRE‑1 “agent” mode using flags | Chain Actors/tasks asynchronously using shared storage, datasets, or webhooks to build multistep pipelines |
| Browser automation / navigation | FIRE‑1 agent clicks buttons, paginates, fills forms, solves simple CAPTCHAs | Automation coded per Actor; CAPTCHA solving baked in |
| Anti‑detection & proxy support | Fully managed proxies, rotating sessions, fingerprint spoofing and geotargeting are all built‑in | Apify Proxy (datacenter & residential) with session rotation, geo‑targeting and spoofing; you enable it per Actor |
| Caching & batching | Global intelligent cache for recently fetched pages; supports batching hundreds of URLs in one API call | Request queues with autoscaled parallelism; per‑Actor caching logic is up to you (e.g. dataset dedupe, custom cache) |
| Scalability | Firecrawl auto‑scales browser instances for concurrent requests | Platform scales Actors and browser instances elastically according to queue depth and configured concurrency limits |
| Monitoring & scheduling | Metrics and scheduling built into the single API dashboard | Per‑Actor run metrics, alerts, conditional scheduling, and webhook triggers via Apify Console |
| Data format optimization | Converts HTML → Markdown to cut LLM tokens by ≈ 67% | Returns whatever the Actor emits (HTML, JSON, CSV, etc.); no built‑in token reduction |
| Language / SDK support | Any language that can call HTTP/JSON (official clients in Python, Node, Go, Rust, C#, etc.) | Official SDKs in JavaScript/TypeScript and Python (Apify SDK / Crawlee); other languages via raw REST calls |
How each platform scales
Firecrawl
Firecrawl scales like a classic SaaS API. Your subscription tier defines a fixed pool of headless‑browser workers, and the service queues requests behind those workers. Because the queueing and resource allocation are handled centrally, you get stable latency and never touch infrastructure. Even the mid‑tier plans can move thousands of pages per minute thanks to caching and smart routing, so the raw worker counts rarely become a choke point.
Apify
Apify takes a looser, cloud‑native approach. You launch as many Actors as your budget allows, and the platform spins up containers to run them in parallel. That “elastic infinity” is perfect for bursty jobs — say, crawling an entire retail catalog overnight or tracking tens of thousands of social‑media accounts — because you can flood the platform with work and pay only for the compute you burn. Automatic retries and detailed run logs keep large Actor swarms reliable.
The marketplace magnifies Apify’s scale advantage: if your project hits 50 different sites, chances are someone has already published an Actor for most of them. You trade weeks of scraper authoring for coordination logic — managing many Actors’ versions, schedules, and output formats — but you gain speed and capacity on day one.
Integrations
Integrating Firecrawl into AI pipelines
Firecrawl treats integration the same way it treats scraping: make the routine path effortless and keep the escape hatches open.
Official SDKs for Python, JavaScript, Rust, and Go expose idiomatic methods, but the real strength lies in direct hooks to AI tooling. A native LangChain loader, for example, can be wired up in just a few lines; it fetches pages, paginates automatically, preserves attribution metadata, and delivers chunks that are ready for embeddings or other RAG workflows. LlamaIndex receives similar first‑class support with retrievers that fetch, de‑duplicate, and format content for chatbots or summarization agents while keeping token counts under control.
Outside pure code, Firecrawl blocks appear in Make.com and Zapier, so non‑developers can drag‑and‑drop flows — say, watch a competitor’s site, extract new product data in plain English, and update a shared spreadsheet — without touching a script. The result is a scraper that plugs into AI stacks and no‑code tools with equal ease.
Apify integrations for production workflows
Apify’s connectors reflect a more mature, enterprise‑centric agenda: it's designed to sit inside CI/CD pipelines and data‑engineering stacks, not just trigger one‑off jobs.
The Zapier app goes beyond “run an Actor” by adding triggers for job completion, built‑in data filters, and error‑handling branches, so a sales team can scrape LinkedIn, enrich leads with a second Actor, and post qualified prospects to a CRM in a single Zap.
The GitHub integration lets teams treat scraper code like any other service — commit, test, review, and deploy via GitHub Actions — bringing familiar DevOps discipline to crawling logic.
For AI tooling, Apify has loaders for LangChain and LlamaIndex, and integrations for HuggingFace, Pinecone, Haystack, Qdrant, and other vector databases.
For data pipelines, Apify ships connectors that push results straight into S3, GCS, or Azure Blob, or stream them through webhooks to Kafka or Pub/Sub, turning the platform into a managed data‑ingestion layer that feeds downstream analytics with no extra glue code.
| Integration feature | Firecrawl | Apify |
|---|---|---|
| Official SDKs | Python, JavaScript/TypeScript (official), Rust, Go (community) | JavaScript/TypeScript & Python (via Apify SDK / Crawlee) |
| AI‑framework hooks | Native loaders/retrievers for LangChain and LlamaIndex (handles pagination, chunking, metadata, token‑cost control) | Official loaders for LangChain and LlamaIndex; individual Actors may embed extra AI logic |
| No‑code / automation tools | Make and Zapier blocks for drag‑and‑drop flows | Zapier app with branching, filters, and error handling for complex automations |
| DevOps / CI · CD | – | GitHub/Bitbucket integration for version control, tests, and CI‑based deployments |
| Data‑pipeline connectors | – (pull via API or SDK) | Export Actors to S3, GCS, Azure; real‑time streaming to Kafka/Pub/Sub/webhooks |
| Webhook support | Crawl/scrape lifecycle webhooks for async callbacks | Webhooks on Actor events; plus metamorph & transform steps for streaming |
| Token‑usage optimization | HTML→Markdown plus loader‑level chunk sizing & token‑budget helpers | Up to individual Actor / downstream loader; no platform‑wide token controls |
Picking the right platform for your workload
When Firecrawl is the better fit
Choose Firecrawl when low‑latency access to web data and tight coupling with AI pipelines are top priorities. Its uniform API, natural‑language extraction, and sub‑second response times let you build chatbots, RAG systems, or research agents without wrestling with scraping logic. Pricing is credit‑based and predictable. If you know you’ll process about 50k pages a month, you can budget the spend to the dollar and count on the same performance every day. The open‑source core offers a self‑host option for teams with data‑residency mandates or those who simply want an exit ramp from the hosted service.
When Apify delivers more value
Apify is the best option when breadth, flexibility, and enterprise guarantees matter. Its marketplace of 10,000‑plus maintained Actors means you can cover dozens of sites in hours instead of building each scraper yourself. Non‑developers can launch and schedule those Actors through a web UI, while engineering teams still have full SDK control when needed. SOC 2 compliance, GDPR alignment, and a history of large‑scale deployments satisfy procurement checklists, and the platform’s elastic Actor model handles everything from tiny HTML scrapes to overnight catalog crawls without manual capacity planning.
Note: This evaluation is based on our understanding of information available to us as of January 2026. Readers should conduct their own research for detailed comparisons. Product names, logos, and brands are used for identification only and remain the property of their respective owners. Their use does not imply affiliation or endorsement.