Data collection services remove distractions from your product roadmap. Without the headache of building and maintaining scrapers in-house or relying on API limits, your technical teams can focus on model design, deployment, and product features instead of spending time gathering and cleaning raw data.
By outsourcing data collection, you can avoid the technical challenges and the hidden costs that in-house data collection can generate over time. Customized data acquisition solutions include scrapers built for your unique use case, ready-to-use datasets, tailored pipelines, automation workflows, and even clean, LLM-ready outputs.
A quick look at the most common data collection strategies
Not all data collection methods fit every need. Pre-collected datasets may work well for research, benchmarking, or early prototypes, but many applications demand fresher inputs. Teams building AI-powered systems, financial models, market intelligence platforms, or consumer-facing apps often require data that is larger in scale, continuously updated, and structured for their use case — whether that means training large language models, tracking competitor prices, monitoring news sentiment, or powering real-time recommendations.
| Method | How it works | Pros | Cons | Best for |
|---|---|---|---|---|
| Public APIs | Pull data from official APIs | Structured, reliable, stable access | Rate limits, restricted fields, many sites don’t offer APIs | Companies with access to official APIs |
| Scrapers built in-house | Customized scripts using tools like Scrapy, BeautifulSoup, Puppeteer | Full control, highly customizable | Requires coding, high maintenance, resource-heavy | Tech-savvy teams, long-term in-house projects |
| Web scraping platforms & managed services | Platforms like Apify, Bright Data, Zyte | Scalable, automation-ready, anti-blocking features | Reliance on external platform | SMEs, enterprises, startups needing speed and scale |
| Data marketplaces / pre-collected datasets | Buy pre-made datasets (e.g. Bright Data, Oxylabs) | Instant access, no setup needed | May be outdated, limited customization | Quick research, prototyping, benchmarking |
| AI-powered crawlers and AI agents | LLM-driven agents that decide what & how to scrape | Adaptive, reduces human input, good for sites that change frequently | Still experimental, can be unpredictable or expensive | AI-driven pipelines |
Data collection challenges
Every use case comes with its own data collection challenges. Still, no matter your industry, you’ll inevitably face some of the most common technical hurdles of web scraping:
1. Frequent website changes. Websites update layouts, HTML structures, or APIs often. Even a small change can break a scraper in use. These changes require constant maintenance, and teams end up working on a never-ending cycle of fixes to keep their scrapers active.
2. Anti-scraping measures. Many websites use CAPTCHAs, IP blocking, rate limits, and bot detection to prevent scrapers from running.
3. JavaScript-heavy websites, where the content is fetched dynamically, are notoriously hard to scrape.
4. Scalability. Collecting small amounts of data might be straightforward, but scraping millions of records at scale requires a strong infrastructure: distributed systems, proxy management, and storage.
5. Hidden costs. Maintenance of the scraping tools has to be covered by a dedicated engineering team.
6. Slower time-to-market. Building an in-house scraping pipeline delays the development of your product.
Data collection challenges in your domain
Beyond the common technical issues in data acquisition, some challenges are highly specific to your industry - especially if you’re building AI tools.
E-commerce
If you’re creating AI-powered recommendations, want to optimize pricing, or prepare demand forecasting, you need a custom solution that can tackle:
- Inconsistent product attributes in product listings
- Pagination and infinite scroll, which requires smart navigation handling
- Variants: the same product might come in multiple colors/sizes
Market research and social intelligence
Sentiment analysis, trend prediction, or brand monitoring find their data sources on social media platforms. These typically come with the following issues:
- Data from social media posts, comments, forums, or reviews is unstructured and noisy
- Infinite scroll on social media platforms loads more content based on user interaction
- Bias in scraped user-generated text fed to AI models can skew model training
Real estate intelligence
Data for automated property valuation models, rental price predictions, or recommendations for buyers/renters in real estate is not easy to scrape:
- Property data is fragmented: you will get different formats from different sites, listing platforms, and local agencies
- Processing property images is as important as processing the text
- Geographic data should be added to the listings to keep them in order
Financial services
For predictive trading models, credit scoring, or fraud detection, you need precise data, which gets updated daily, per hour, or even per minute:
- Financial datasets often require real-time or near-real-time streaming
- Some websites feature high-frequency updates (e.g. stock tickers)
- Extreme precision is needed in parsing numbers, tables, and reports without error
Successful data collection projects require tailored strategies that can adapt to the complexity of your market.
Apify’s data collection services
Apify offers two paths for your data collection strategy - each designed for different use cases. You can either choose a quick, pre-made solution from Apify Store, or let the Apify experts handle the whole process for you, providing you with a fully customized end-to-end data collection solution. Here’s an overview of both approaches.
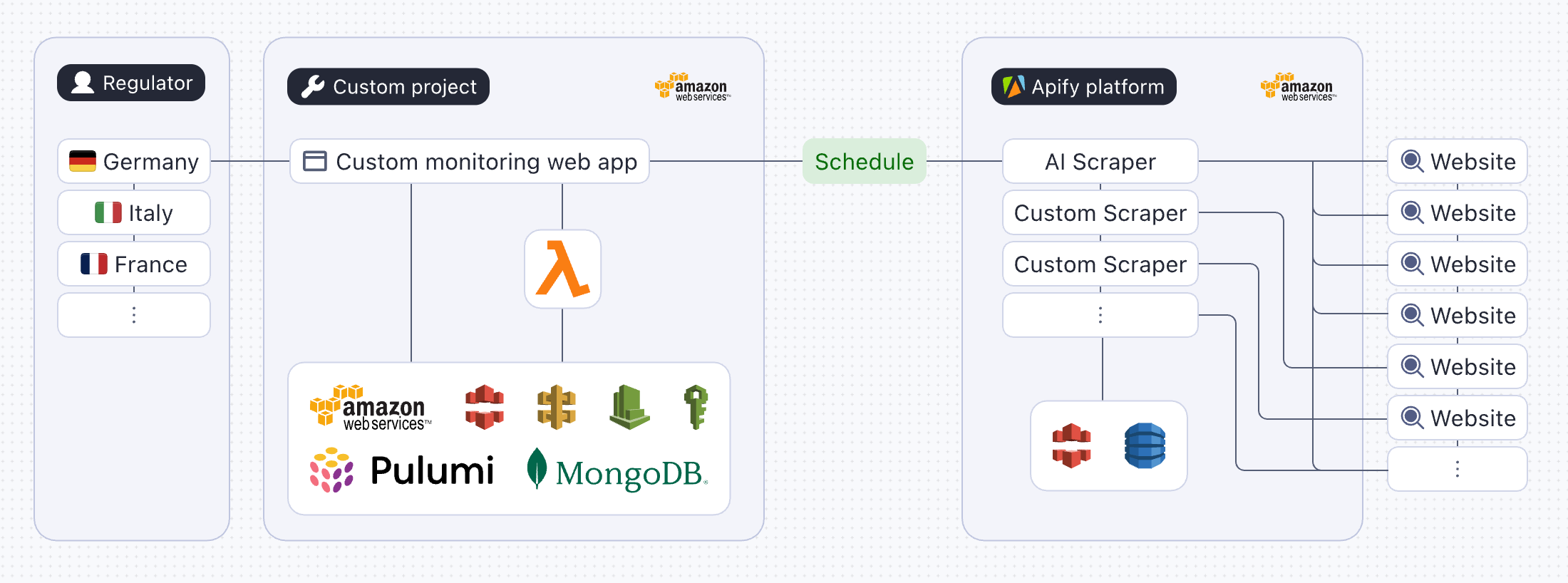
Apify Professional Services
Imagine taking data collection completely off your plate. Apify Professional Services does just that: Instead of struggling with code, proxies, storage, and maintenance, you get a full team on your side to handle all the technical challenges for you. With the Account Manager who understands your needs, the Technical Project Manager, the Lead Engineer, and a team of developers, Apify can take on even the most complex scraping projects. Here’s what’s included:
- Integrations support. The Apify team can orchestrate ready-made integrations with third-party platforms such as Zapier, Make, Google, etc., or build a custom integration for your specific data pipeline.
- AI experience. Apify teams are experienced in building complex AI workflows and creating AI agents.
- Scalability. The Apify platform can easily scale to hundreds of millions of web pages per month and terabytes of data.
- Migration support. If you already have code hosted externally, the Apify team will help you move your project to the Apify platform.
- Monitoring suite. An automated monitoring system checks for data quality, completion, and delivery confirmation. The Apify team is also ready to fix any potential issues if they occur.
Prefer a quick, ready-made solution? Apify Store is for you.
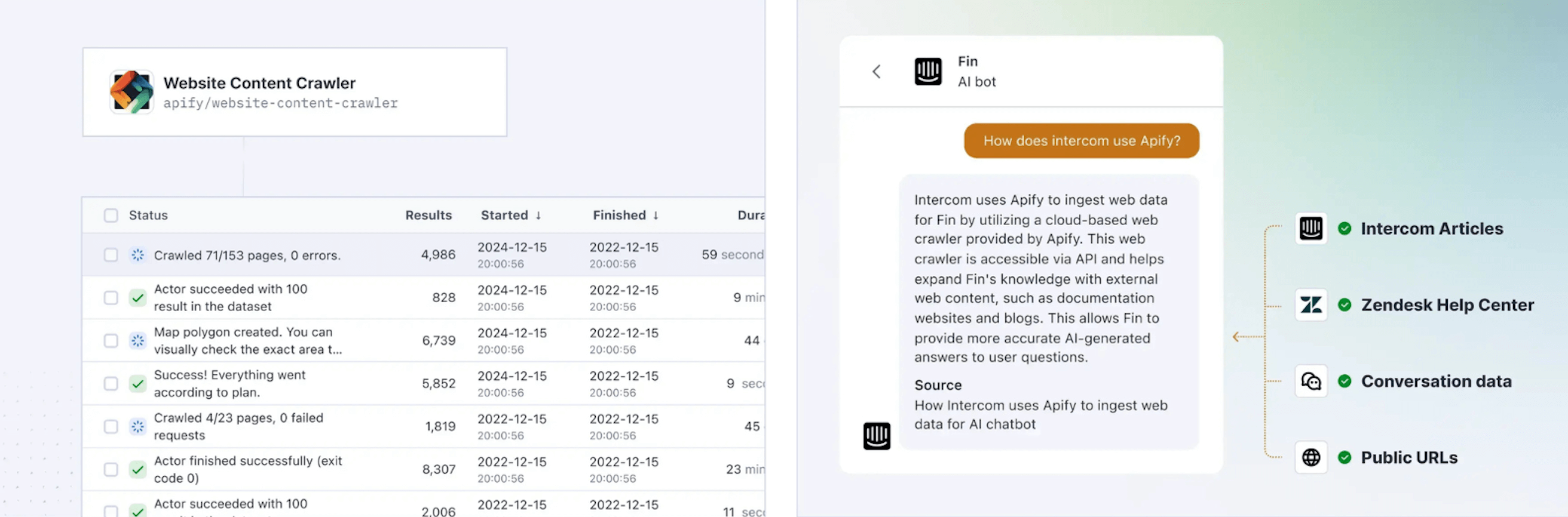
Apify Store is the world’s largest marketplace for scrapers, offering over 6,000 specialized Actors that you can start using immediately. Each Actor is designed for a very specific task, and you can search for them using a service type (e.g., Amazon, Google Maps, Instagram). Whatever website you need to scrape, chances are a solution already exists, so you don’t have to start from a blank page.
Actors take minutes to set up, they require no code, and you get structured data output (JSON, CSV, Excel) at the end of the run. What makes them a great choice for quick tasks:
- The proxy management, scheduling features, and storage are already built in.
- All scrapers are created by experts and maintained by them - you don’t have to worry about your workflow breaking because of a website update.
- Actors have anti‑detection tactics such as browser‑fingerprint randomization, human‑like delays, and outsourced CAPTCHA solving built in.
How Apify powers AI data collection
Apify solutions help you extract text content from the web to feed your vector databases or fine-tune and train your LLMs. With Apify Actors and custom solutions from Apify Professional Services, you can:
- Run hundreds (or even thousands) of extraction tasks in parallel, gathering massive datasets in hours instead of weeks, while eliminating fluff such as duplicate entries and irrelevant information.
- Target niche domains with specialized Actors, such as scrapers for social media platforms, Google Maps, or e-commerce, and extract specific fields.
- Fetch fresh data by scheduling scrapers to run hourly, daily, or weekly, with automatic updates pushed to your cloud storage.
- Send data directly into a language model endpoint.
- Export outputs in multiple formats natively consumed by the LLMs, such as CSV or JSON.
Try Apify’s data collection services
Your data collection strategy depends on specific requirements, resources, and timeline:
Opt for Apify Professional Services if you require custom logic, integrations, or AI workflows. This option is ideal for teams that need guaranteed uptime, continuous monitoring, and SLA-backed support. It’s a fully managed, hands-off approach backed by expert guidance, so that you can focus on using data, instead of chasing it.
Go with Apify Store if you need a quick, low-effort solution and your use case is already supported by existing Actors. This option works best for users who are comfortable managing usage and monitoring on their own.