


A CAPTCHA (Completely Automated Public Turing test to tell Computers and Humans Apart) is a challenge specifically designed to be easy for humans to solve but complex for bots. Usually, it’s used to distinguish between human users and automated scripts.
To prevent automated abuse, many sites are increasingly adopting CAPTCHAs. This trend has negatively impacted user experience to the point where large e-commerce platforms now resemble government portals, requiring extra steps even for legitimate users.
This guide will teach you how to bypass CAPTCHAs in your scraping script using Python. By the end, you'll have a thorough understanding of how to automate CAPTCHA resolution.

How to bypass CAPTCHA in web scraping
Most sites and web applications are now protected by a WAF (Web Application Firewall) such as Cloudflare or Akamai. Among the many features these solutions offer is anti-bot protection.
For example, Cloudflare performs underlying checks whenever you access a page. If the system suspects you're a bot, you might be shown a page like this:
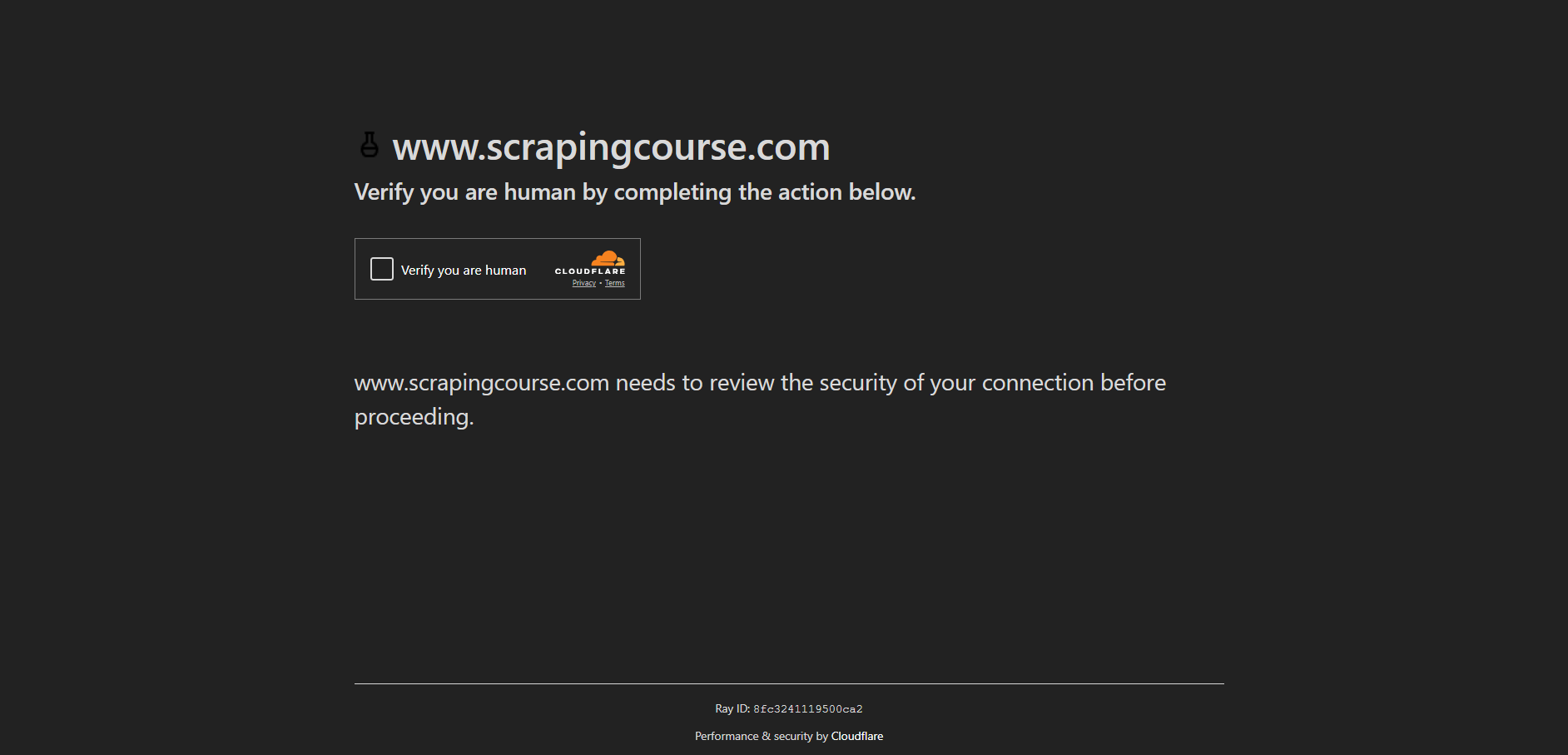
This webpage includes a checkbox CAPTCHA known as Cloudflare Turnstile. As of now, it’s one of the most widely used CAPTCHAs on the market and one of the most annoying for web scrapers.
In this step-by-step guide, you’ll learn how to bypass CAPTCHA using Python.
Step 1: Setup a Python project
Before getting started, make sure you meet the following prerequisites:
- Python 3 installed on your machine
- A Python IDE, such as Visual Studio Code with the Python extension or PyCharm
- Basic knowledge of Python and async programming
Create a folder for your project, enter it, and initialize a Python virtual environment inside it:
mkdir captcha-bypass
cd captcha-bypass
python -m venv env
Load the project folder in your Python IDE and add a scraper.py file inside it. This is what your project file structure will look like:
In the IDE’s terminal, activate the virtual environment with the command command:
./env/bin/activate
Equivalently, on Windows, execute:
env/Scripts/activate
Wonderful! You now have a Python setup in place.
Step 2: Configure SeleniumBase
SeleniumBase is a Python library built on top of Selenium and optimized for web automation tasks. It includes features tailored for bypassing CAPTCHAs, which makes it an excellent tool for achieving the goal of this guide.
SeleniumBase works just like Selenium but offers a slightly different and more feature-rich API. For more information on browser automation in Python, read our Selenium web scraping guide.
Install SeleniumBase via the seleniumbase pip package with this command:
pip install seleniumbase
Then, import it into your scraper.py script with:
from seleniumbase import SB
You can then initialize a self-closing SelenumBase instance with:
with SB() as sb:
# Scraping logic...
sb exposes the browser automation API to control a browser (Chrome by default), while the with statement ensures that the browser will be closed when no longer needed, helping to save system resources.
Step 3: Connect to the target page
The target webpage for this example will be the "Antibot Challenge" from Scraping Course. This features a Cloudflare setup that consistently displays a Turnstile CAPTCHA on the first visit.
Use the open() method from SeleniumBase to instruct the controlled Chrome instance to connect to the target page:
sb.open("https://www.scrapingcourse.com/antibot-challenge")Note that, as opposed to vanilla Selenium, you don’t have to worry about web driver management. SeleniumBase will automatically handle that for you on the first run.
If you execute the script, this is what you should see for a second before the browser is closed:
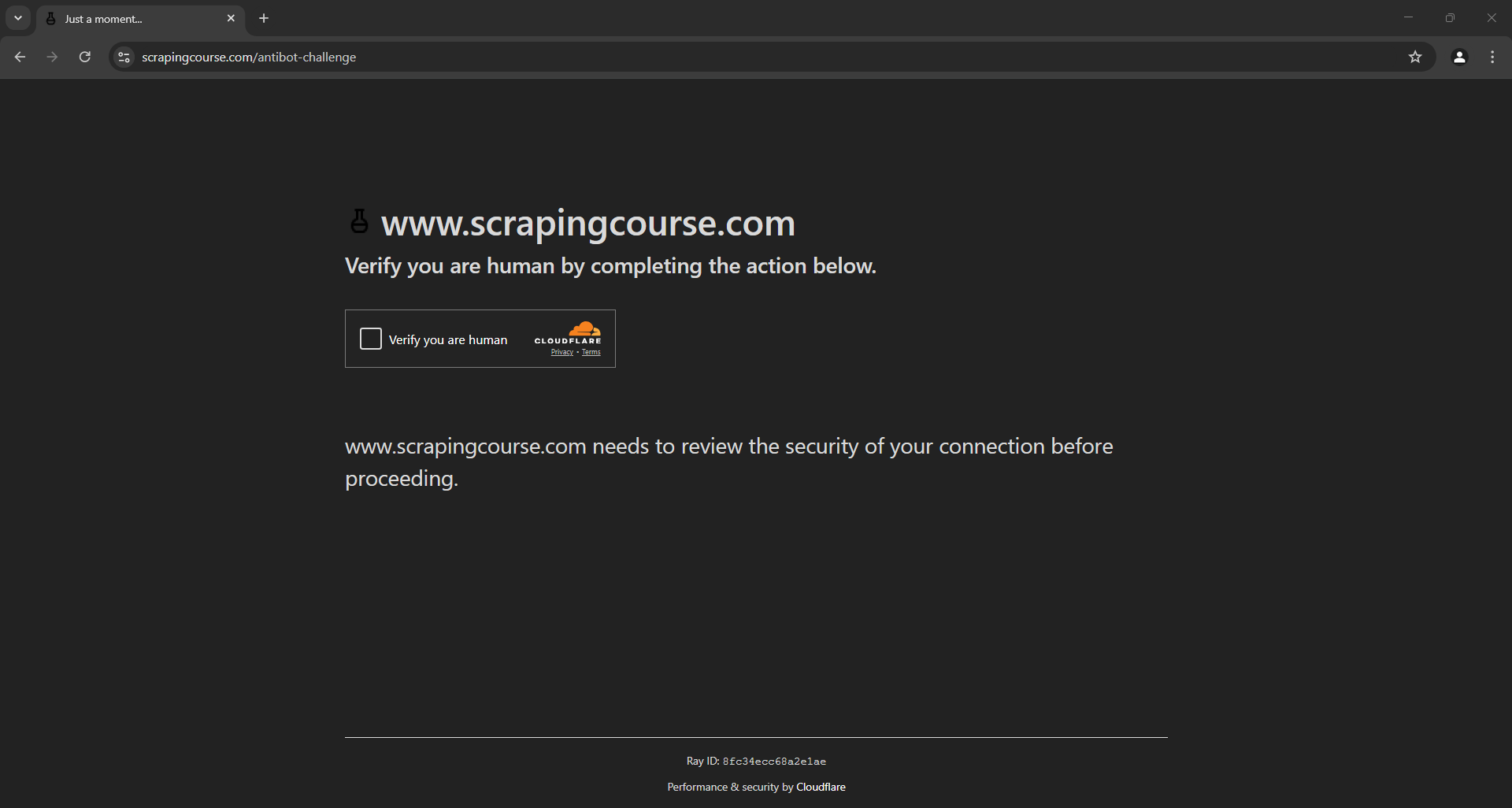
The CAPTCHA is there, ready to stop your scraping script. If you attempt to bypass it with custom logic to click the checkbox, you'll either be blocked or presented with another challenge. That happens because your automation logic wouldn’t behave like a regular user. Also, your automated browser fingerprint doesn't match that of a standard browser.
Step 4: Bypass the CAPTCHA
SeleniumBase comes with a feature called UC Mode (Undetected-Chromedriver Mode). When enabled, this mode uses the undetected-chromedriver library to make your script appear like a regular human user.
Undetected-Chromedriver is an optimized Selenium ChromeDriver patch that doesn’t trigger most anti-bot services. On top of that, UCMode includes further updates, fixes, and improvements. Using that mode can be enough to fool anti-bot solutions into thinking you're a human user so that they don’t even show CAPTCHAs.
To enable UCMode, pass the uc flag to the WebDriver constructor. After that, you have to connect to the target page using the uc_open_with_reconnect() method:
sb.uc_open_with_reconnect("https://www.scrapingcourse.com/antibot-challenge")
If you run the script and still encounter a CAPTCHA, it means the UC mode optimizations alone aren’t enough. In this case, use the uc_gui_click_captcha() method to let SeleniumBase handle the checkbox CAPTCHA for you:
sb.uc_gui_click_captcha()
Now, launch the scraping script and verify that it works as expected. You’ll see the browser reload the page and automatically click the "Verify you are human" checkbox by simulating mouse movement.
Under the hood, uc_gui_click_captcha() uses the PyAutoGUI library to move the mouse for you. You don’t have to install it, as SeleniumBase will automatically download it during the first run. In the terminal, you’ll see the following message :
PyAutoGUI required! Installing now...
You can now implement the element selection and data extraction logic as explained in our Python web scraping guide.
Step 5: Put it all together
Here's what your complete Python bypass CAPTCHA logic looks like:
# scraper.py
from seleniumbase import SB
# Initialize a controllable browser instance in UC mode
with SB(uc=True) as sb:
# Connect to the target page containing a CAPTCHA
sb.uc_open_with_reconnect("https://www.scrapingcourse.com/antibot-challenge")
# Click on the CAPTCHA to bypass it
sb.uc_gui_click_captcha()
# Scraping logic...
To run the script, launch:
python script.py
Next steps
Wonderful! You’ve just learned how to bypass CAPTCHAs in Python using SeleniumBase. That’s just one of the many approaches you can follow. However, don’t forget that complex CAPTCHAs involving images, text, or puzzle-like challenges (e.g. challenges from reCAPTCHA or hCAPTCHA) cannot be bypassed using this method alone.
Also, the source code of SeleniumBase is publicly available since it's an open-source library. This means it's a "cat and mouse" game with Cloudflare and other WAFs as they continue to improve their anti-bot measures by studying what bot bypass libraries are doing.
For more reliable and consistent solutions, check out Apify's anti-captcha solutions.
Bypassing CAPTCHA: Other techniques
You just saw how to overcome one-click CAPTCHAs used by a WAF solution like Cloudflare, but there are several other more general techniques you should keep in mind:
- Simulate human interaction: Write custom JavaScript scripts to execute on the webpage or use libraries that mimic human-like mouse movements, clicks, and typing patterns. This works well only for simple CAPTCHAs.
- TLS fingerprinting: Use tools like
curl-impersonateto make your scraping automated HTTP requests appear as if they’re coming from a regular browser. That helps you avoid CAPTCHA triggers from bot detection systems. - Rate limit testing: Study how the target web server reacts to a set of requests to identify any request limits. Stay within those thresholds so that pages do not show CAPTCHAs.
- Third-party services: Integrate AI-based CAPTCHA-solving services into your script to outsource CAPTCHA-solving to AI models or human workers, helping streamline the process.
- Browser fingerprinting: Configure your headless browser with plugins like Playwright Stealth or Puppeteer Stealth to make it look like a legitimate browser. This may be enough to circumvent simple bot detection technologies.
- Session handling: To prevent CAPTCHAs from appearing, sites tend to create a “valid” session that lasts for a given amount of time. So, maintaining active sessions across scraping requests helps avoid triggering repeated CAPTCHAs.
Different types of CAPTCHA
Before seeing the list of CAPTCHAs you’re likely to encounter while doing web scraping, you must understand how these challenges have been evolving due to AI.
Older CAPTCHAs focused solely on accuracy, determining whether the user was human or a bot based on test results. Instead, modern CAPTCHAs also consider how tasks are carried out by the user.
This shift has been driven by advancements in AI, which can now solve even reCAPTCHA v2 challenges—as proven by a study from ETH Zurich. Still, the way an AI model tackles a challenge may differ a lot from regular human behavior.
That’s why modern CAPTCHA tests involve elements like overshoots, dragging dynamics, and realistic mouse movements. Behind the scenes, they collect data on how challenges are approached, using this information to identify new AI-powered bots.
You're now ready to explore the list of the most common types of CAPTCHAs—which may evolve over time due to these advancements.
1. Invisible CAPTCHA
Invisible CAPTCHAs are mostly used by WAF systems to determine if a user is a bot based on a set of parameters (e.g., browser fingerprint, device fingerprint, TLS fingerprint, installed fonts, etc.) without displaying any visual challenges. If the system suspects you’re a bot, then a visual CAPTCHA may appear on the page.
Note that some WAFs refer to these as "JavaScript challenges” or “browser challenges.”
2. Checkbox CAPTCHA

CAPTCHAs can be frustrating and degrade the user experience. Providers are aware of that, so most of them offer a one-click checkbox CAPTCHA where users can be verified as human or a bot with a single click. If there’s any doubt, a more complex challenge is typically presented.
Popular options for this type of CAPTCHA include Cloudflare Turnstile and the "I’m not a robot" reCAPTCHA.
3. Text-based CAPTCHA
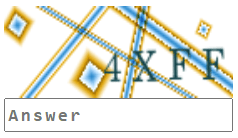
Text-based CAPTCHAs display a combination of random letters, characters, or numbers in a distorted format, often rotated, scaled, or warped to make them hard to read. Some also include lines, blurs, or noise to further obscure the characters. To solve them, users must enter the correct combination in an input field.
These used to be the most widely used types of CAPTCHAs, but AI advancements have made them easier to solve. So, they're now used only in old or legacy sites.
4. Image-based CAPTCHA

There are several types of image-based CAPTCHAs, but the most common ones come from Google's reCAPTCHA. In those tests, you're presented with a grid of images and asked to click on the ones containing a specific object or scenario.
These challenges were once considered difficult for bots, but AI models have now been successfully trained to solve them.
5. Audio-based CAPTCHA
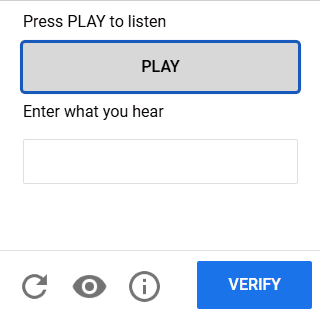
In audio-based CAPTCHAs, users need to listen to an audio clip and transcribe the word or sentence they hear in an input box. Generally, you can choose from multiple languages, and the audio tends to include distortion or background noise to make detection harder.
In most cases, this is simply an accessibility option. Requiring users to listen to audio to access a page or submit a form can be too intrusive.
6. Math-based CAPTCHA
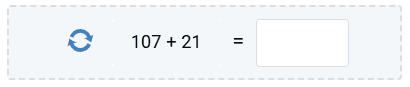
Math-based CAPTCHAs present a simple math problem (e.g., an addition, subtraction, multiplication, or division between two numbers) that most human being can easily solve—regardless of their education level.
These challenges can be made harder by distorting or obscuring numbers, or by using more complex operations.
7. Puzzle-based CAPTCHA
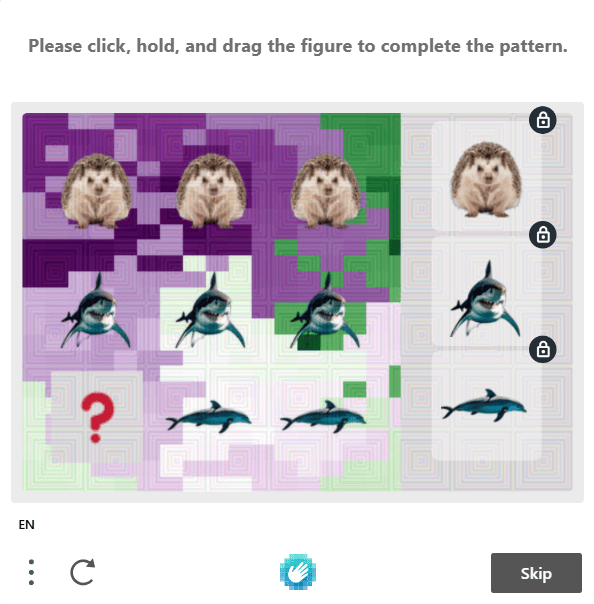
Puzzle-based CAPTCHAs involve tasks like identifying or continuing patterns in images, rotating images to the correct orientation, solving simple riddles (e.g., "Select all animals that are omnivores in the image"), dragging puzzle pieces into place, solving basic mazes and more.
These challenges are the natural evolution of traditional audio, image, and text-based CAPTCHAs, which can be solved by AI models. As mentioned earlier, the focus here is less on finding a solution to the test and more on collecting data to understand how they’re solved. In today’s AI-driven world, that information is what matters for detecting bots.
Conclusion
To bypass CAPTCHA challenges, you must use solutions that either prevent them from triggering in the first place or are equipped with advanced—even AI-powered—interaction algorithms to solve them. This guide showed you how to address the very common checkbox CAPTCHAs used by most sites to protect pages and forms.
Frequently asked questions
Can you bypass CAPTCHA?
Yes, you can bypass CAPTCHAs by avoiding them entirely through simulating trustworthy browser fingerprints, overcoming them with automation scripts for one-click CAPTCHAs, or using machine learning and AI models to mimic human behavior to solve the underlying challenge.
Why do websites use CAPTCHAs?
Websites use CAPTCHAs to block automated spam from bots, prevent abuse, and verify that users are human. Thanks to challenges built to distinguish bots from humans, CAPTCHAs protect forms, login pages, and payment transactions and are often utilized by WAF services to stop malicious activities.
Why are CAPTCHAs so challenging in web scraping?
CAPTCHAs are challenging in web scraping because they’re specifically designed so that only humans can solve them. This means they can easily disrupt automated workflows and reduce scraping efficiency as a result. Modern CAPTCHAs achieve that by presenting challenges whose solution is difficult to automate.
Is it illegal to automate CAPTCHA?
No, it’s not explicitly illegal to automate CAPTCHA, as there are no specific laws prohibiting it. At the same time, keep in mind that legality varies by jurisdiction. Automating CAPTCHAs may become a legal issue when it’s part of activities that violate terms of service and copyright laws or lead to other unlawful actions.
Can AI outsmart CAPTCHAs?
Yes, AI can outsmart CAPTCHAs, as some recent research papers have proven. That’s possible due to machine learning models for pattern matching, image recognition, and real-time text interpretation. This is also why CAPTCHA providers are creating more complex challenges, making it harder to train AI models to solve them effectively.



