



Free public proxies for web scraping
Proxies and web scraping go together like a hand and glove.
Web scraping is a data acquisition method that involves using bots to open websites to retrieve data and turn it into a structured format for data analysis and many other purposes. Since many websites have measures in place to safeguard against malicious bots, you need proxies, which mask IP addresses, so as not to seem suspicious to the websites you're scraping and avoid getting blocked.
Most seasoned web scraping developers are aware of the power of proxies. At Apify, various types of proxies play a huge role in helping us appear as different users in different locations with different machines when making hundreds - and sometimes thousands - of requests in a single scraping job. This is done by switching (or "rotating") through a list of proxies every few requests. Making our bots appear human, or as if they are in another location, helps avoid detection. This can even help maintain anonymity and encourage digital freedom in countries with restrictive internet policies.
The challenge of free working proxies
To help simplify the complexities of proxies for the ever-growing web scraping community, we developed Apify Proxy, which can automatically rotate through dozens of proxy groups and their corresponding proxies. Some of these proxy groups are free, and others (the super-reliable ones) are premium.
Check out the 7 best proxy providers in 2024
All of this is absolutely fantastic, but then we started to ask ourselves 🤔
What about all of the free public proxies available on various websites such as Geonode? Those could be utilized with this intelligent proxy-rotating logic as well! The more the merrier, right?
And so, we began a quest to build a proxy scraper and proxy group entirely from public proxies. We learned two things during this process:
- There are a whole lot of free public proxies out there 🎉
With one Google search of free proxy list, you'll quickly discover that there are many free public proxies available for use. Sites like Geonode and free-proxy-list.net are among the many which provide large lists of proxies that are updated and checked daily.
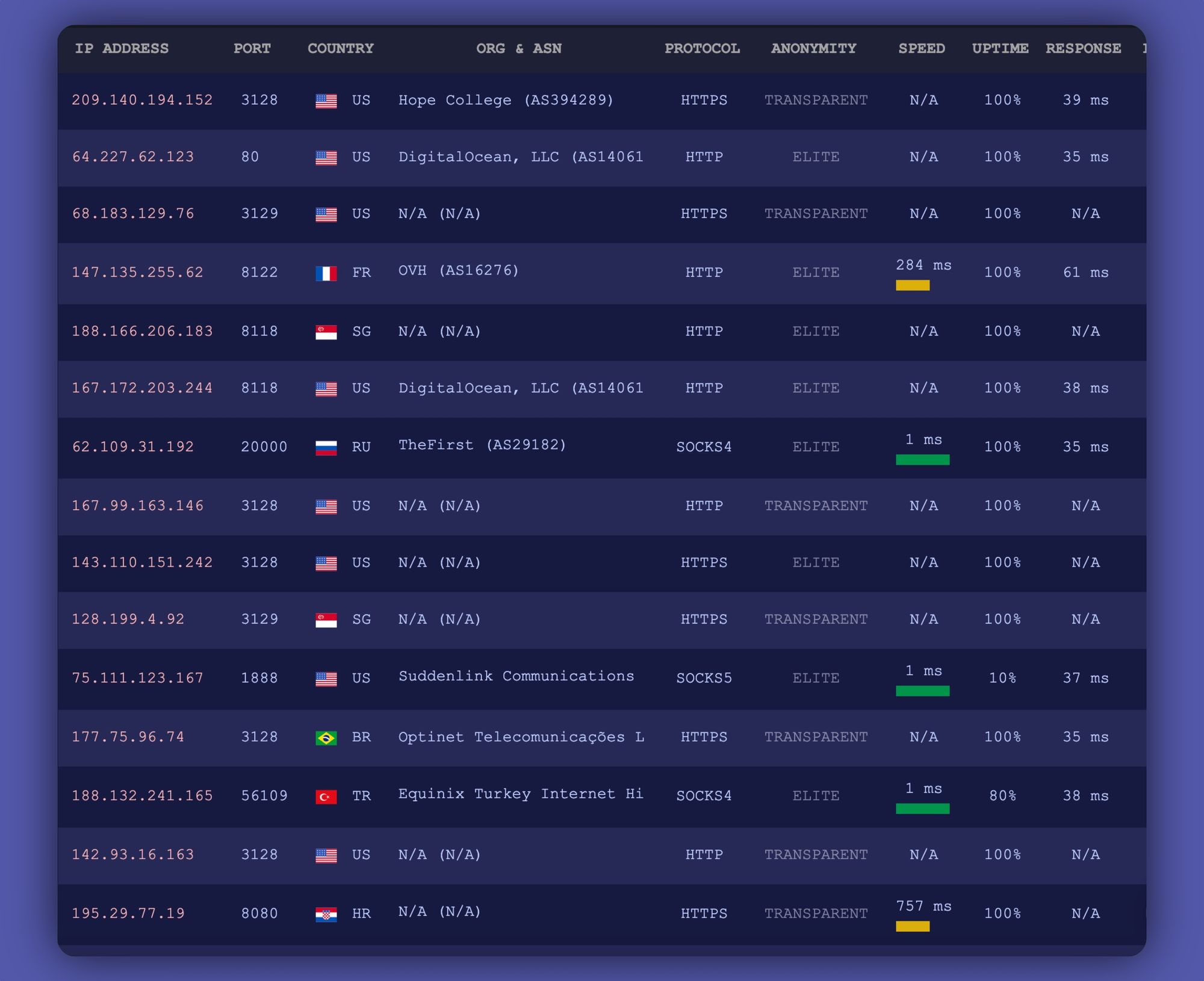
All proxies from these sites vary in quality based on anonymity, protocol, and speed, but you can find some really good ones in there!
- Many of those proxies don't work 😭
It's a bummer, but most of those proxies simply don't work. Either they're down (permanently or temporarily), or they're much too slow to use in any sort of serious project. Because of this, anyone searching through free proxy list websites might have to search for quite a while before finding even just one reliable and usable one.
Related: Datacenter proxies: when to use them and how to make the most of them
How to get a good proxy list: Proxy Scraper 💪
The result of these discoveries is Proxy Scraper: an Actor on Apify Store that takes both of these important factors into account and does two main tasks in every run:
1. Scrapes all currently available proxies from 17 different free proxy websites and APIs
- Each site request is optimized to return the highest quality proxy results.
- See the full list of sites here.
2. Individually tests each proxy
- Once all sites have been scraped, each proxy is tested by using it to send a request to a user-specified target website.
- If a request fails (for any reason), the proxy being tested is removed from the list, which will eventually be outputted.
- All duplicate proxies are removed from the list.

With an incredibly simple configuration process, fast run times, and reliable outputs, Proxy Scraper is the best way to quickly obtain a list of working public proxies. It makes the process of retrieving data from websites containing free public proxies much more accessible, as it removes the need to check each and every one manually.
Related: Get proxies: 10 free or low-cost proxy services
How can you use Proxy Scraper to find working public proxies?
Since the end output of the Actor is usable proxies, we can use it for any of the many use cases of proxies. However, there are some specific ways this Actor can be utilized:
1. Calling the Actor via API within your own project
Within your own project, you can call the Proxy Scraper Actor via Apify API. Once you call the Actor and retrieve its output dataset, it's completely up to you what you do with the proxies! There are a few available options:
Apify.call()with the Apify SDK.client.actor('mstephen190/proxy-scraper')with the Apify API client for JavaScript (This is recommended if you want a JavaScript API but aren't going to use the SDK for anything else).- Directly using Apify's RESTful API to call the Actor.
Each item in the outputted dataset will look something like this:
{
"host": "164.27.6.74",
"port": 8080,
"full": "164.27.6.74:8080"
}
A short video tutorial to guide you through the pitfalls of retrieving data using API
2. Setting up a scheduled task for the Actor
As a step up from #1, you could further automate your proxy retrieval process by setting up a new schedule on your Apify account, which can be configured to call Proxy Scraper at an interval (every hour, every day, etc.) with your own specified inputs.
It's important to note that, in order to reap the full rewards of running this Actor on a schedule, you should set pushToKvStore to true within the 'Storages' configuration. This means that every time your custom schedule runs, the previous proxy data in your named key-value store will be overwritten with the most up-to-date working public proxies. You can learn more about the difference between named and unnamed storage in the Apify documentation.
free-proxy-store. Additionally, using the key-value store gives you access to the data in JSON format and text/plain format.Try Proxy Scraper for free
Proxy Scraper currently finds anywhere from 20 to 60 reliable proxies out of the 2,500 that it scrapes in every run (that's because most of them don't work). But it's the quickest and easiest way to find free public proxies that do work. Discover the power of Proxy Scraper by trying it out for free on the Apify platform!



