In this post, I will explain the motivation for these new features, what are they good for, how they can be used, and where we’re going with them. If you only want to learn about the new features, you can skip straight to the Bringing actors closer to people section below.
The original crawler
The first product that Apify launched was a crawler (the company was called Apifier at that time). Our crawler was great for simple data extraction jobs. You only need to specify one or more start URLs, a regular expression matching the URLs on the website that you’d like the crawler to visit, and a short piece of front-end JavaScript code that is executed on every web page in order to extract data from it. And then you click ▶️ Run and get your scraped data from all the HTML documents.
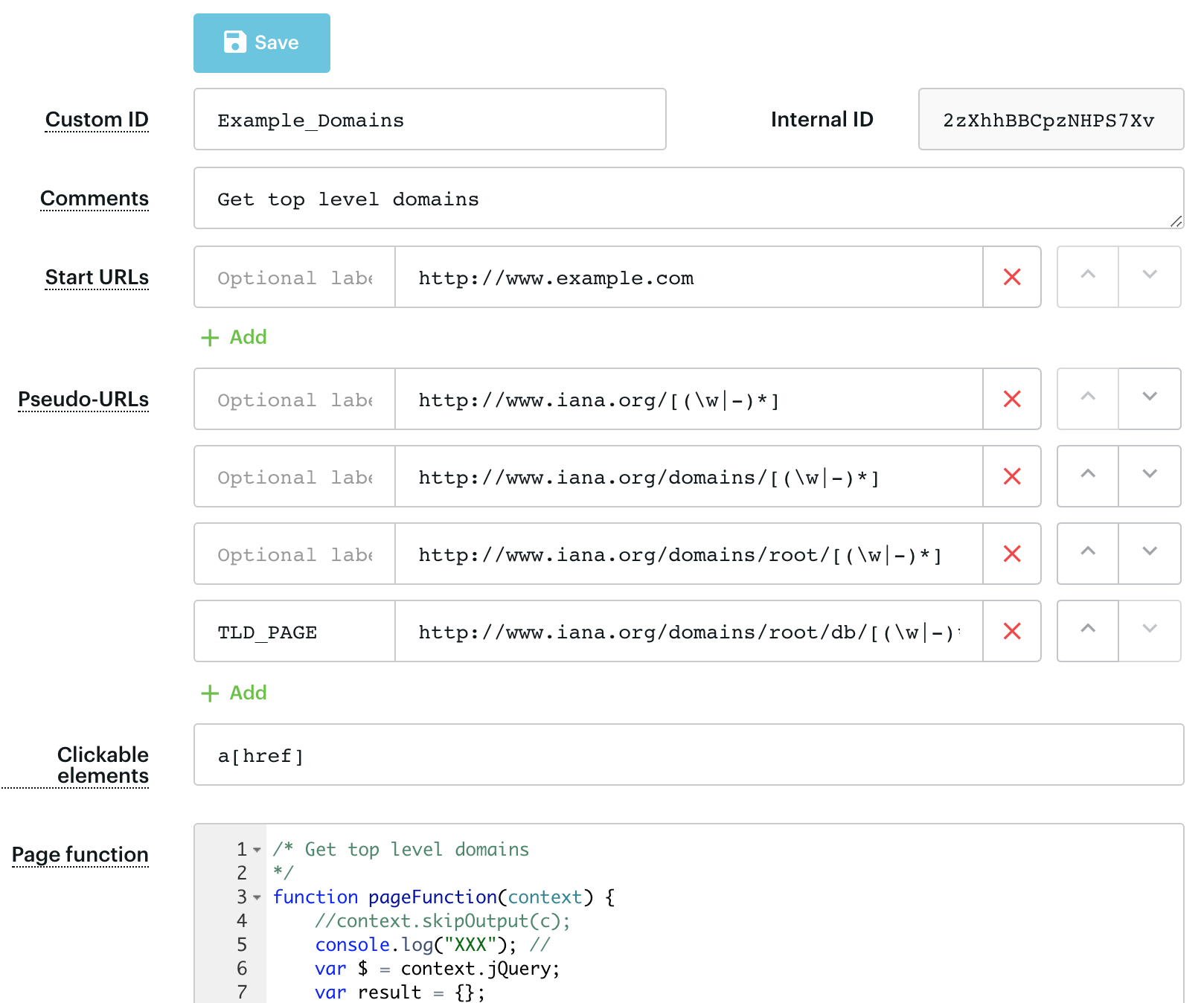
Although the crawler has a very simple design, it proved to be a powerful web scraping tool that can extract data from a surprisingly large number of websites. And more importantly, it can be used even by people with only basic software development skills. However, the crawler has several shortcomings, especially when users want to apply it to more complicated use cases. For example, to upload crawling results to a Google spreadsheet, send an email when the results are not valid or save screenshots of web pages. To implement these more complicated workflows in the crawler, users often had to resort to real hacking wizardry, while some other workflows were downright impossible.
Improving the crawler
Clearly, we needed to build a better product. One approach was just to add more features to the crawler for all different use cases, but there was a fair chance that eventually the product would become bloated, hard to use and impossible to maintain.
The second option was to create one or more new products better suited for several common use cases and hope our users wouldn’t come up with new use cases we didn’t predict (spoiler: they always do). This path would have brought us closer to tools like Zapier.
But we asked ourselves a question: Why should we think that the crawler or some single-purpose tool that we might ever design will become a sort of ideal, universal product for our users that could solve their often unimaginable use cases? And why should we limit people in the ways they can use Apify?
Perhaps, we asked ourselves, if we provided our users with the right set of basic tools and enough freedom, they will be able to achieve much more than with a set of closed, predefined products. After all, even Bill Gates says that
If you give people tools, and they use their natural abilities and their curiosity, they will develop things in ways that will surprise you very much beyond what you might have expected
So we took a different approach…
Actors
Instead of keeping a few boxes on a closed shelf of products, we chose to open the shelf to everyone. We created an open computing platform where anyone can create, host, share and run their own crawlers, web automation jobs or in fact any software apps. And since these apps are quite different from what other computing platforms offer and they can play all kinds of different roles, we decided to call them Actors.
Technically speaking, an Actor is a serverless microservice that accepts input, performs its job and generates output or some other result (view docs). Under the hood, Actors use Docker containers and can run any code that can be packaged as a Docker image. But unlike other serverless platforms such as AWS Lambda, Google Cloud Functions or Zeit Now, Actors are useful for batch jobs since they can run for an arbitrarily long time. Actors can be restarted on errors or even migrated to another server and restarted there. The system guarantees the job will get done.
Besides that, we built several tools and services that work nicely with Actors and greatly enhance what you can do with them:
- Apify Library — A place where you can find Actors built by the Apify team and community and share Actors that you have built yourself. Running an Actor from the library is just one click or API call away, and you don’t need to install or deploy any software. And as the author of an Actor, you don’t need to worry about the hosting costs — it’s completely free for you to host your Actors in the library, regardless of how many users they have.
- Apify SDK and its successor Crawlee — An open-source scalable web crawling and scraping library for JavaScript. Enables the development of data extraction and web automation jobs (not only) with headless Chrome, Puppeteer and Playwright. The library got over 1300 stars on GitHub in just two weeks after the official launch.
- Apify Command-line client (CLI) — helps you create, develop, build and run Actors, and manage the Apify Cloud from a local machine.
- Apify Storage — Enables Actors to store their state, screenshots, the queue of web pages to crawl or crawling results. Users can easily download the results in formats such as CSV, Excel or JSON.
- Apify Proxy — Allows Actors to hide their origin when extracting data from websites or to access them from different countries. It supports both residential and datacenter proxies, as well as Google search engine results pages (SERPs).
- Apify SDK for Python — Provides useful features like Actor lifecycle management, local storage emulation, and Actor event handling in Python.
- Web scraping code templates to get you started with TypeScript/JavaScript and Python templates to help you quickly set up a web scraping project.
Additionally, over the past year, we have accumulated a huge amount of feedback from our users and released a large number of new features and improvements for the Actor platform. These have made Actors extremely powerful and applicable to a large number of use cases.
However, something was still missing. Our users loved the original crawler since it was simple to use and they only needed basic knowledge of front-end JavaScript to get started. Many of these users felt intimidated by the low-level nature of Actors and the necessity to write much more complex code in Node.js to achieve the same results as with the crawler. Also, the library didn’t offer that many existing Actors for their use cases and even if they found one, they had to write its input configuration in JSON, which is tedious.
Bringing Actors closer to people
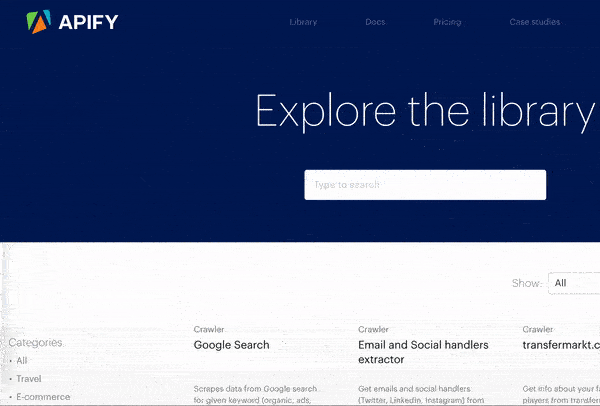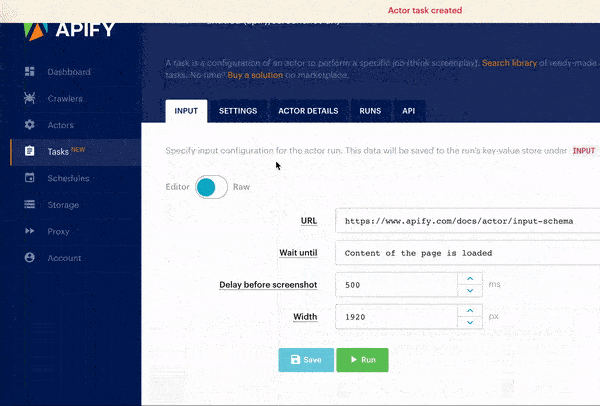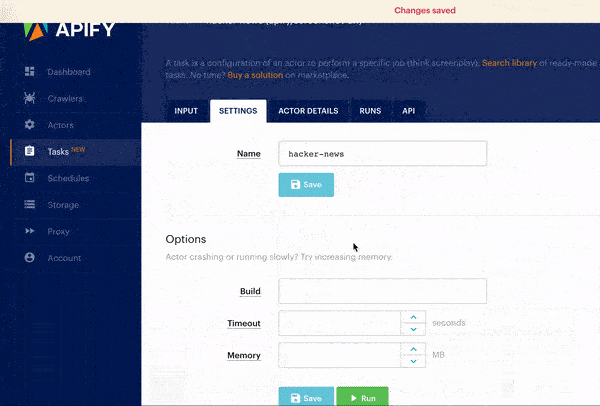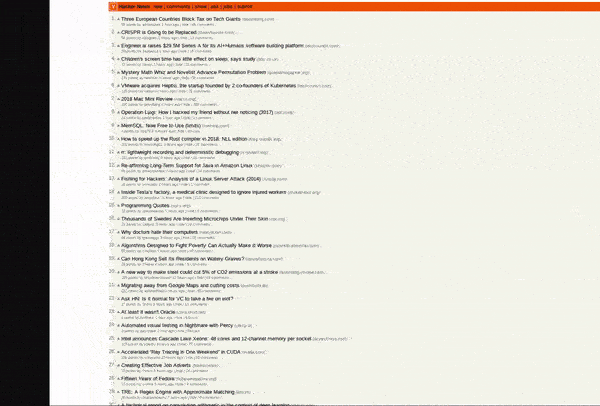
There was a gap between the simplicity of the original crawlers and new Actors that we had to close. Therefore, this week we have launched a new feature that enables developers to add a user interface to their Actors. This can be achieved simply by adding a file called INPUT_SCHEMA.json to the Actor's source code. The file contains a definition (schema) of the input for the Actor. The Apify app then uses this file to automatically generate a human-friendly input editor for users of the Actors. Of course, users can still run the Actor by providing input configuration in JSON or using the API, and the system automatically checks that the input is valid according to the schema.
For example, the jaroslavhejlek/kickstarter-search Actor normally takes input configuration as a JSON file:
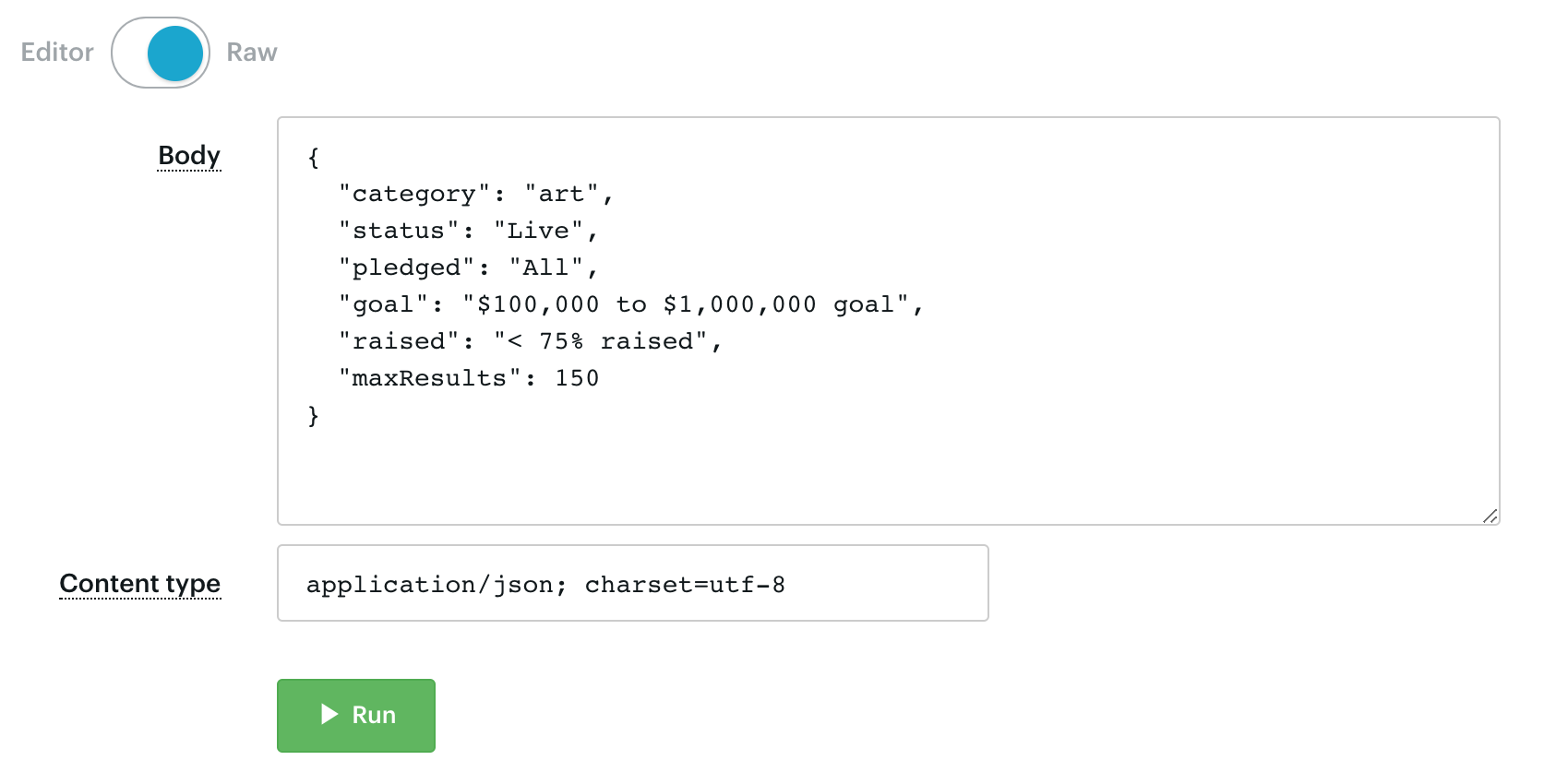
Thanks to the new input schema and auto-generated user interface, the user can now enter the input configuration in a much friendlier editor:
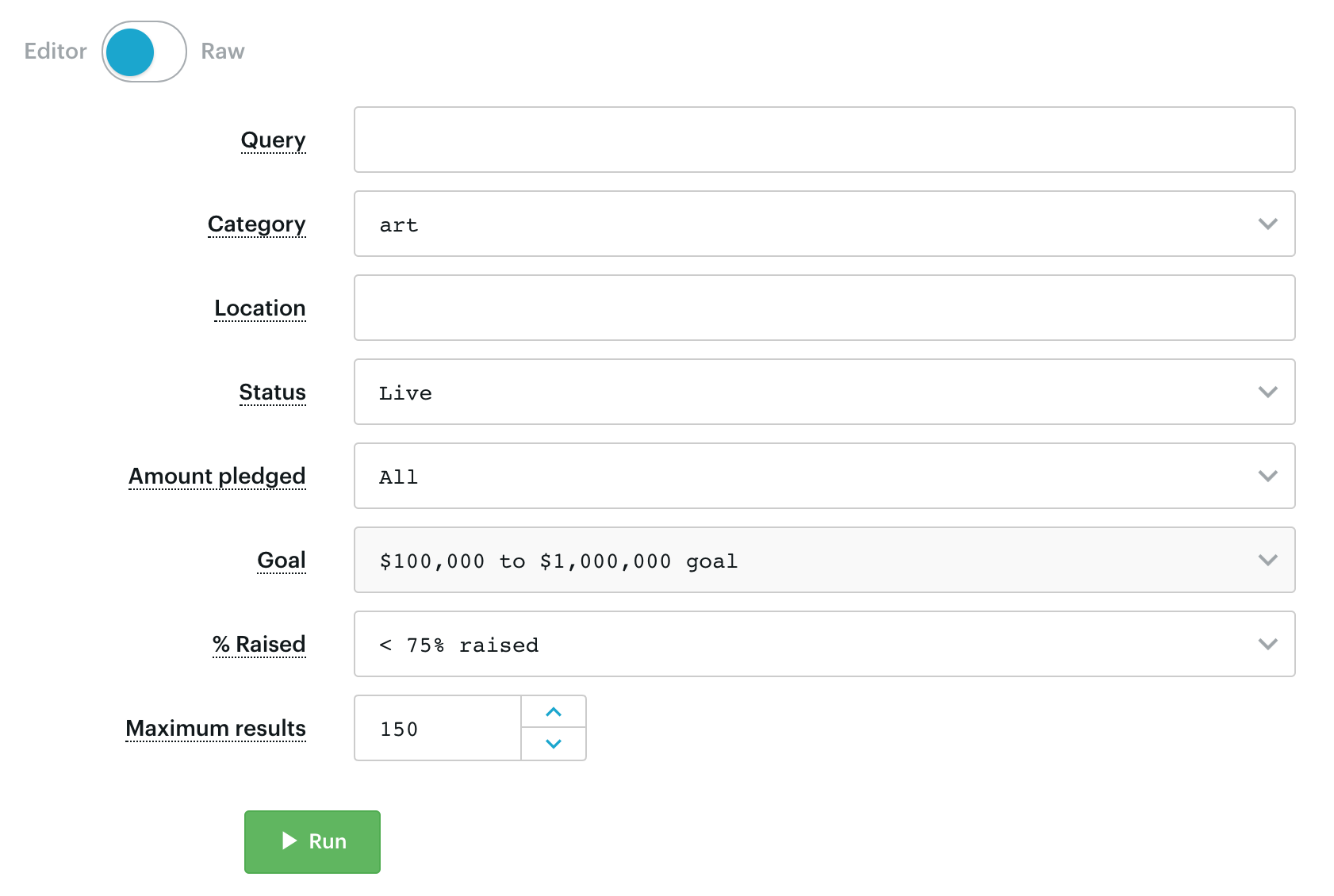
Then you just click ▶️ Run and get your scraped data. It’s that simple! Read more about schema in Actor docs.
Moreover, we have also launched a new feature called Tasks, which enables users to save the input configuration for an Actor and then run it later using API, scheduler or manually in the app.
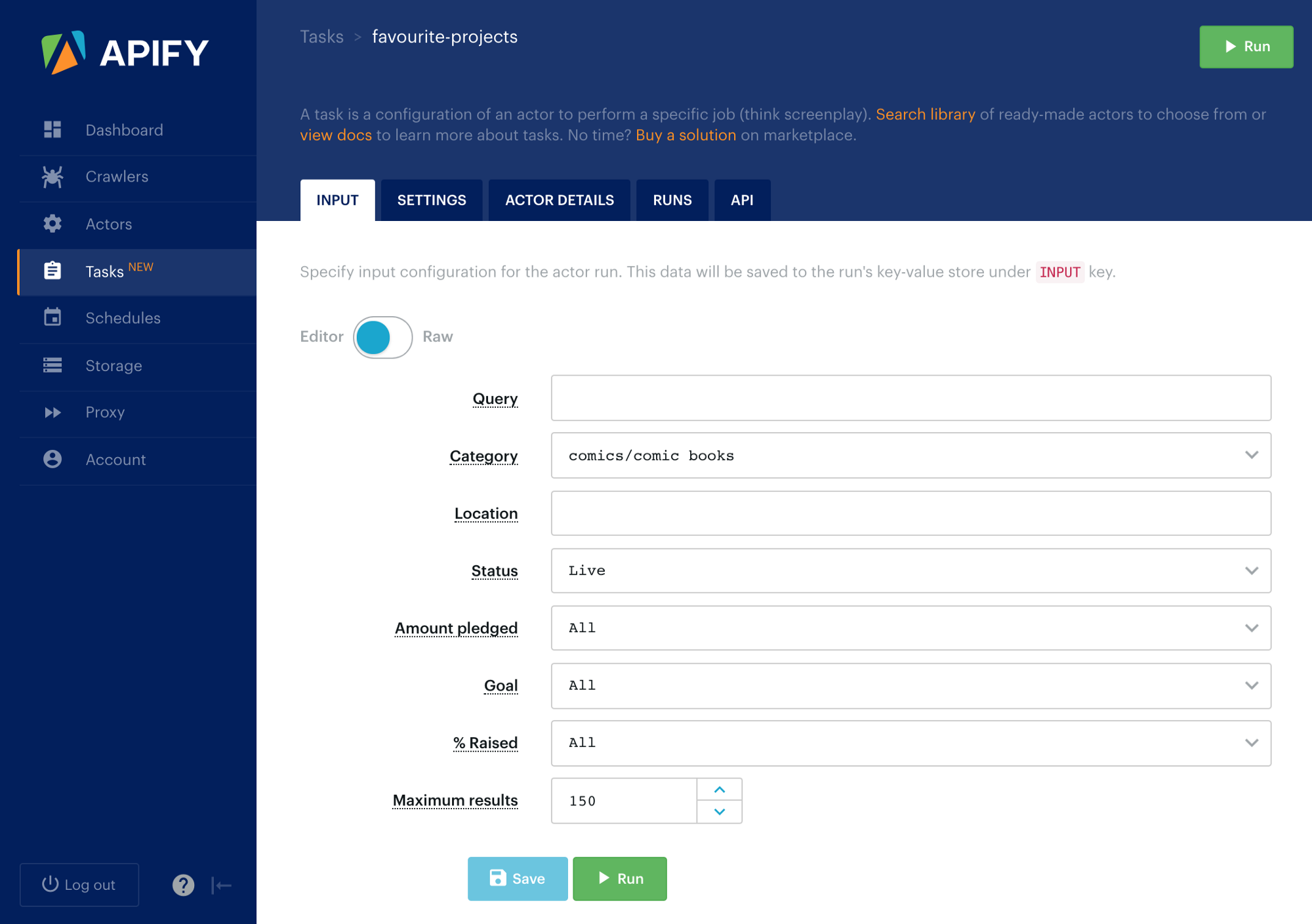
Tasks are great since they enable you to save Actor configurations for various scenarios and use them later. You can think of a task as a screenplay for an Actor to be performed over and over again, sometimes even in a different theater 😃 Read more in Task docs.
Thanks to the auto-generated user interfaces and the tasks, Actors now combine the full-power and flexibility of the underlying cloud platform, while putting on a human-friendly face for their users. Also, the extensive usage of Actors in all kinds of projects over the past year has given us an extreme level of confidence in their performance and applicability to a large scale of real-world web automation, data extraction and robot processes automation use cases. Therefore, today we’re proudly removing the “beta” flag from Actors.
What’s next?
By now you can probably guess what is going to happen to the original crawler. Our goal is to replace it with an open-source Actor in the library that will have exactly the same input configuration and an auto-generated user interface as the crawler configuration editor. Yes, that means we will be open-sourcing the crawler 🙌🎉 So instead of creating a new crawler configuration, you will be creating a new task for the Actor.
But we won’t stop there. Over the coming weeks and months, we’ll be releasing a number of general- and specific-purpose Actors for all kinds of use cases. We hope you will take our Actors for a good spin. Just start in the library and if you don’t find what you’re looking for, either build a new Actor yourself or let us know and we’ll help you bring it to life.
Happy web automation with Apify Actors!