


If you want to get data from some website into a structured form, you would probably start by parsing the website’s HTML using CSS selectors. That’s a common approach and will work on most websites. But there are typically much easier ways to extract data, mainly on modern dynamic websites. In this article I’m going to describe the four methods I always check are available on a website I want to scrape: Schema.org Microdata, JSON Linked Data, internal JavaScript variables, and XHRs.
If you’re not into developing web scrapers yourself and prefer to order a turnkey web scraping or automation solution from expert developers, you can simply submit your project on Apify Marketplace, get a quote and get your project done in a week or two.
Let’s start with an example: scraping basic restaurant info with reviews on Yelp. A straightforward way is to get HTML and parse it using libraries like Cheerio (server-side jQuery) or Beautiful Soup (in Python). Alternatively, you can load the page in a headless browser like PhantomJS or headless Chrome and scrape data by evaluating JavaScript in the context of the page. This lets you use libraries like jQuery to access the data.
Check out this up-to-date 2022 guide to scraping any website with our Cheerio Scraper for the latest tips.
To figure out CSS selectors, you can use Chrome DevTools (the easiest way is to right-click on the text you want to get and choose Inspect). The image below shows this approach for restaurant’s address.
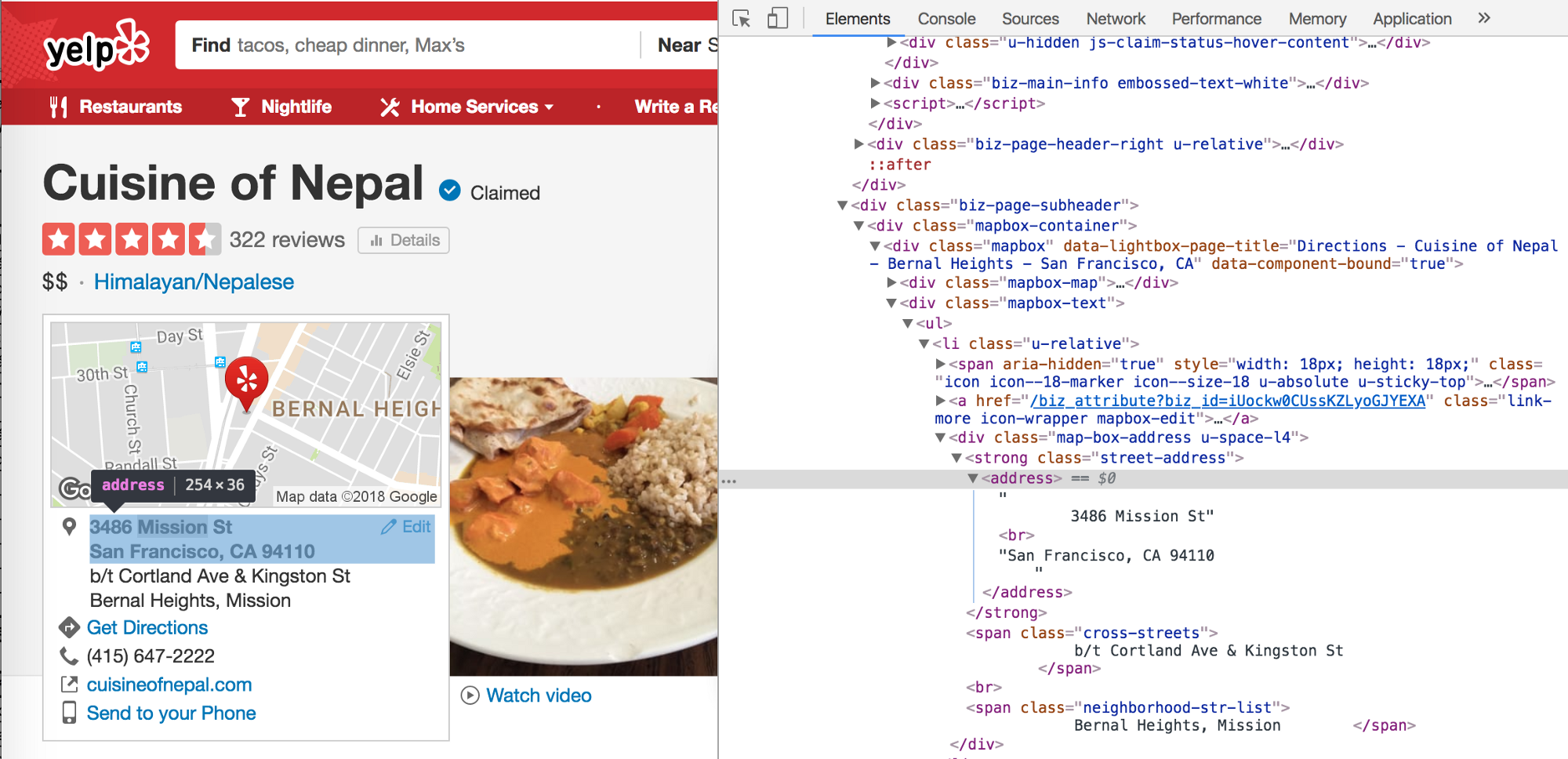
To scrape this address, you can use a jQuery selector such as
$('.street-address').text().trim()and get this result:
“3486 Mission StSan Francisco, CA 94110”This isn’t ideal, so you would probably use something like
$('.street-address address').html().trim().replace('<br>', ', ')to get:
"3486 Mission St, San Francisco, CA 94110"Good enough, so we could continue to use this method with other selectors. Or, we can analyze the website and try to get the same data elsewhere much easier. Some websites make this easy for us by supporting semantic web approaches such as Schema.org Microdata or JSON for Linked Data.
Schema.org Microdata
If you look for ”3486 Mission St” in the example page’s source code, you would also find it in a hidden element with Schema.org Metadata:
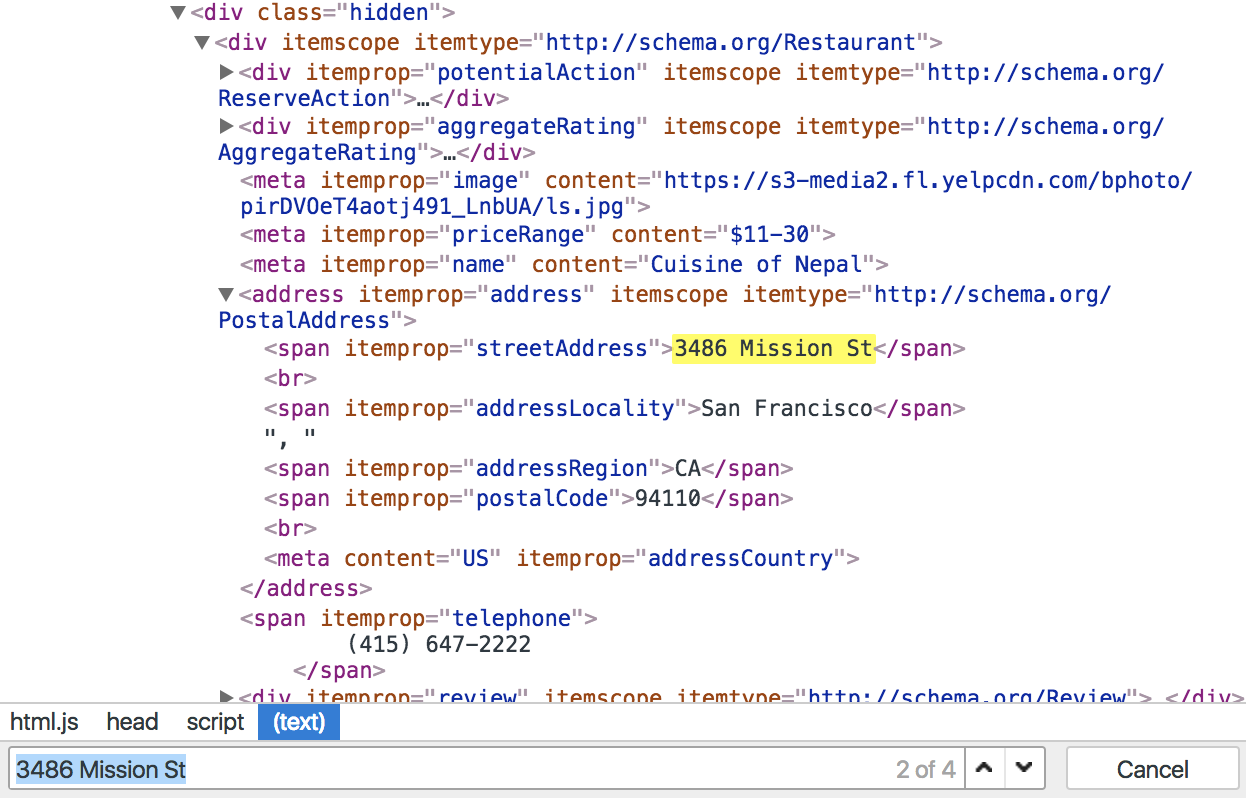
Then you can use a generic parser to get these data. Here is one example using jQuery:
If you run this function in the context of our page, you would also get basic info about the restaurant along with other data:
...
"priceRange": "$11-30",
"name": "Cuisine of Nepal",
"address": {
"_type": "http://schema.org/PostalAddress",
"streetAddress": "3486 Mission St",
"addressLocality": "San Francisco",
"addressRegion": "CA",
"postalCode": "94110",
"addressCountry": "US"
},
"telephone": "(415) 647-2222",
...Here you can find the complete output from the schemaOrgParser() function. By the way, you can also find there the last 20 Yelp reviews of the restaurant.
JSON-LD
Similar to Schema.org, some websites are using JSON for Linking Data to structure their content. Just look for a script with application/ld+json type. We’re lucky on Yelp, here’s how it looks on our page:
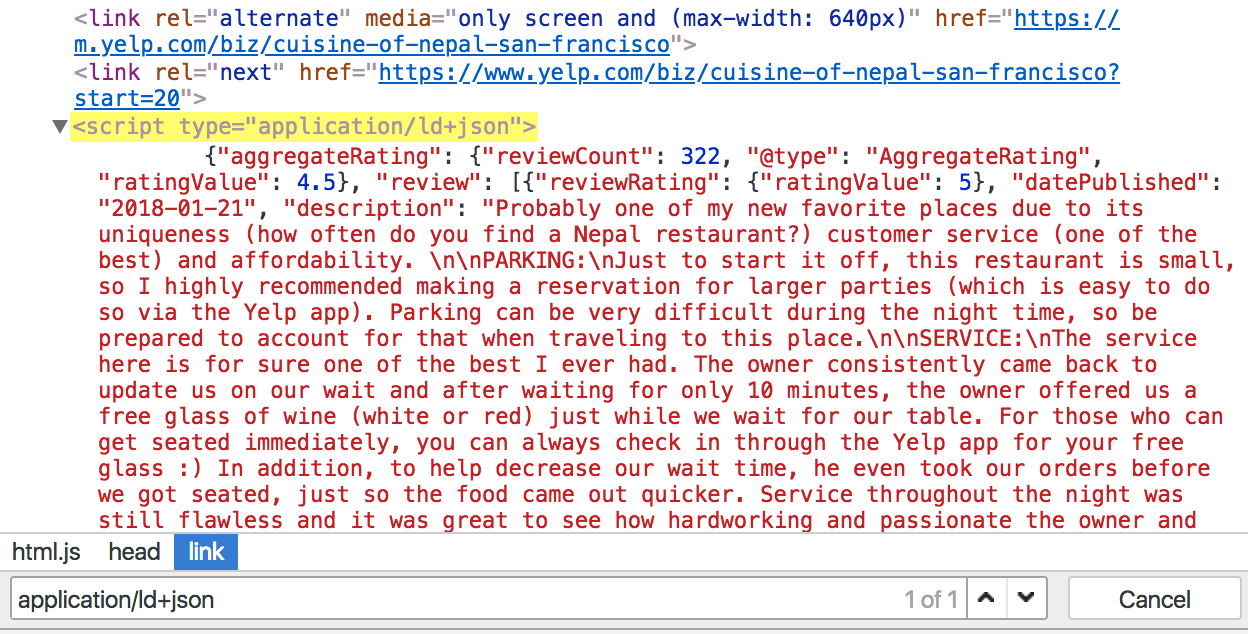
Since the data are already in JSON, we can easily extract them with these two lines of JavaScript code:
var jsonLD = $('script[type="application/ld+json"]');
return JSON.parse(jsonLD.html());And get almost the same data we got using Schema.org Microdata:
...
"servesCuisine": "Himalayan/Nepalese",
"priceRange": "$11-30",
"name": "Cuisine of Nepal",
"address": {
"addressLocality": "San Francisco",
"addressRegion": "CA",
"streetAddress": "3486 Mission St",
"postalCode": "94110",
"addressCountry": "US"
},
"@context": "http://schema.org/",
"image": "https://s3-media2.fl.yelpcdn.com/bphoto/pirDVOeT4aotj491_LnbUA/ls.jpg",
"@type": "Restaurant",
"telephone": "+14156472222",
...The full result (also including the latest reviews) is available here.
Internal JavaScript variables
This is my favorite. You have to load the page in a headless browser such as PhantomJS or headless Chrome (typically with Puppeteer), but once it’s loaded, you can just return the variable available on a page.
If you look for a restaurant name on our Yelp page, you can also find it in the following <script> tag on the page:
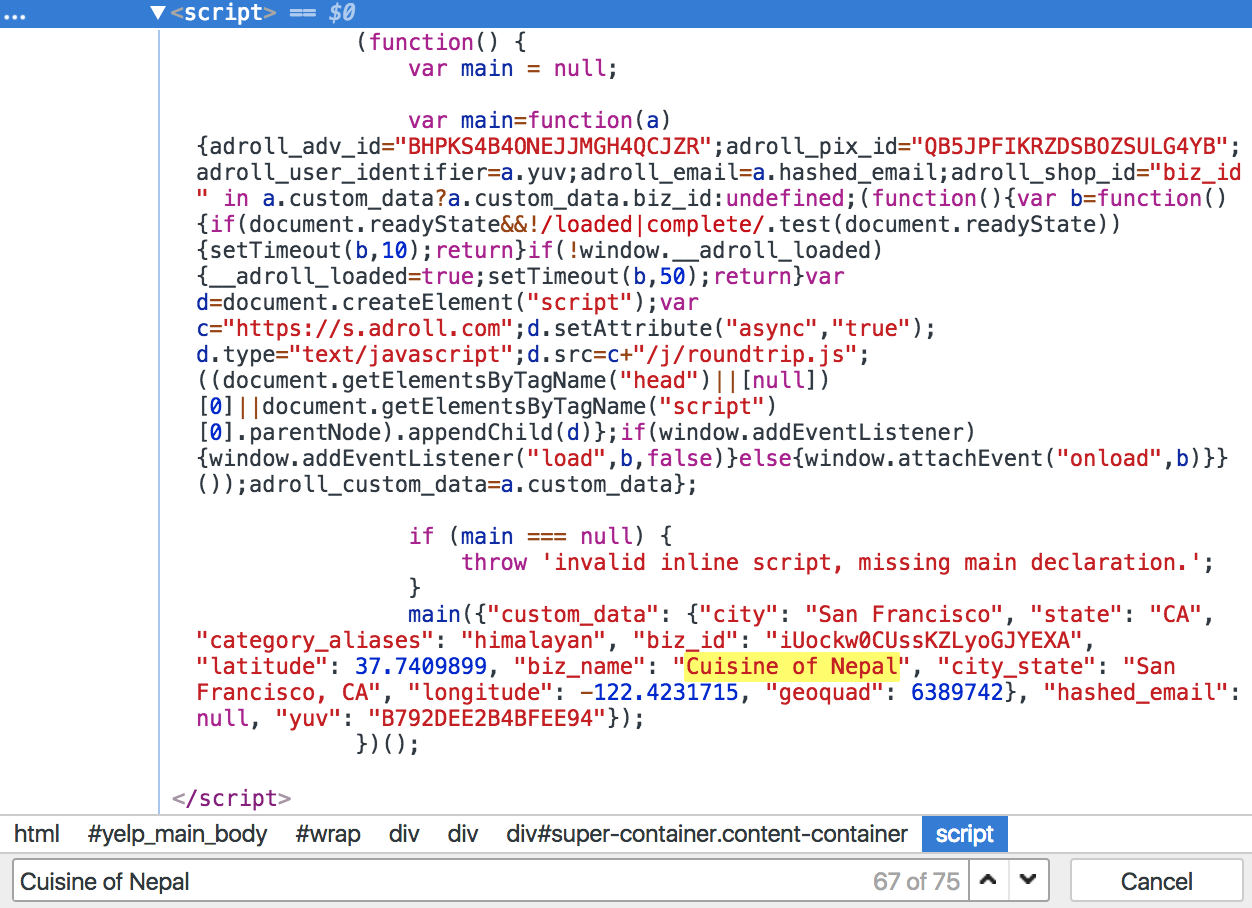
The script sets some custom data to the adroll_custom_data variable when the page is loaded. So, within the page context, you can just call:
return adroll_custom_data;And get this object:
{
"city": "San Francisco",
"state": "CA",
"category_aliases": "himalayan",
"biz_id": "iUockw0CUssKZLyoGJYEXA",
"latitude": 37.7409899,
"biz_name": "Cuisine of Nepal",
"city_state": "San Francisco, CA",
"longitude": -122.4231715,
"geoquad": 6389742
}This does not include all the data we got using previous methods, but you also get geographic coordinates, which can’t be found elsewhere on the web page except in the map data.
For example, on booli.se (a Swedish portal with real estate offers), you can get hundreds of attributes for every offer listed using one internal JS variable called property:
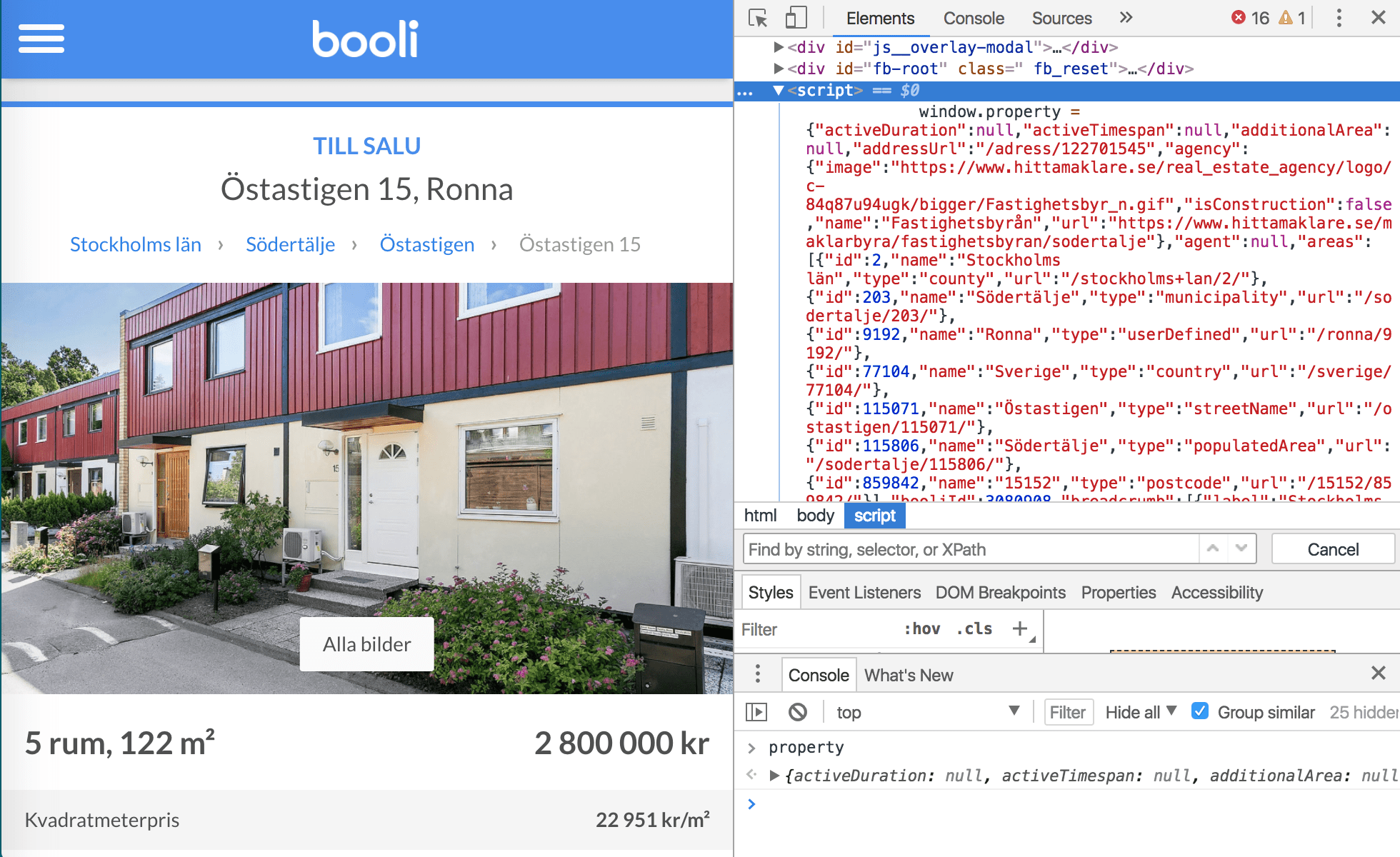
All you have to do is:
return property;And here is the result you would get. Using this approach on Apify, you can scrape all of booli’s more than 40k listings with all their attributes on this portal using a crawler written in just 20 lines of JavaScript code:
This crawler and many others are available at the Apify Store, so you can find the best solution for your use case, copy it to your account, and hit the Run button.
If you want to explore more options for web scraping and crawling in JavaScript, have a look at Apify SDK — an open-source library that enables the development of data extraction and web automation jobs (not only) with headless Chrome and Puppeteer.
XHRs
Another favorite, although it typically involves more hacking.
If the website loads data dynamically, it typically uses XMLHttpRequests (XHRs). When the browser is using an API to get data from the server, why can’t we use it in just the same way?
Here’s a nice example — topshop.com. This website uses infinite scroll and every time you scroll down to last products it calls this XHR:
http://www.topshop.com/webapp/wcs/stores/servlet/CatalogNavigationAjaxSearchResultCmd?storeId=12556&catalogId=33057&langId=-1&dimSelected=/en/tsuk/category/clothing-427/N-82zZdgl?No=20&Nrpp=20&siteId=%2F12556&categoryId=203984You can check this in the Network section of Chrome DevTools (XHR tab):
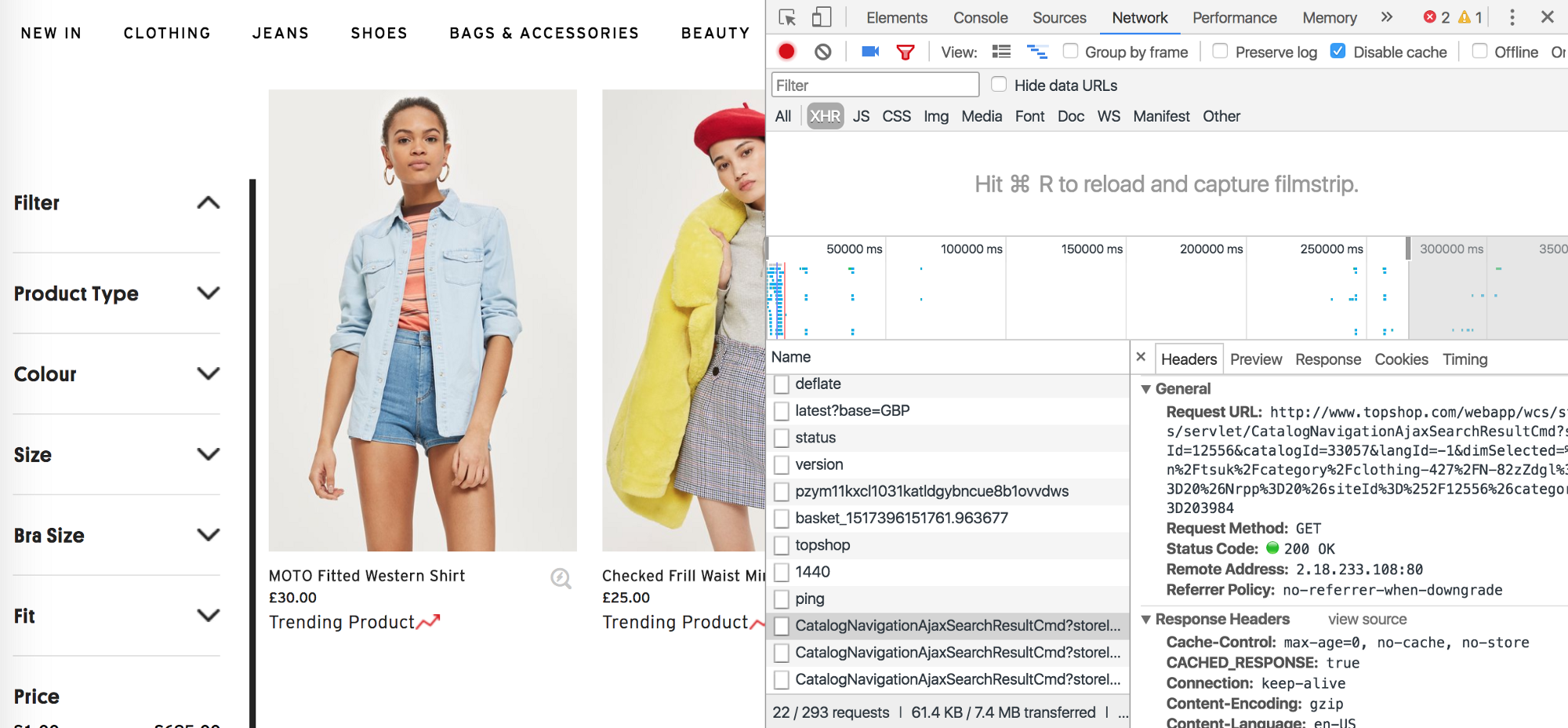
This XHR is a GET request which even works outside of the website. You can try it here.
If you scroll down in a category page again and compare new XHR with the previous one, the only change is in No parameter (No=20 and No=40). This parameter obviously means offset in the product list. So, if you want to get all products listed there (more than 4,000 in the clothing category), you can just iterate the No parameter by 20 and send a GET request for each of them. So you get 20 products with all attributes from each request. Here’s a complete crawler for that on Apify:
This crawler is available in the Apify library, and you can check the example output here.
That was easy, but what if the website uses POST requests that only work within the context of the loaded page (secured by cookies, headers, tokens, etc.)? Then you can use a headless browser, load the first page and send the POST requests from there.
This approach can be used to get app reviews from Google Play Store. In the image below, you can see a POST request along with its data, which is being sent for each 40 reviews you want to view.
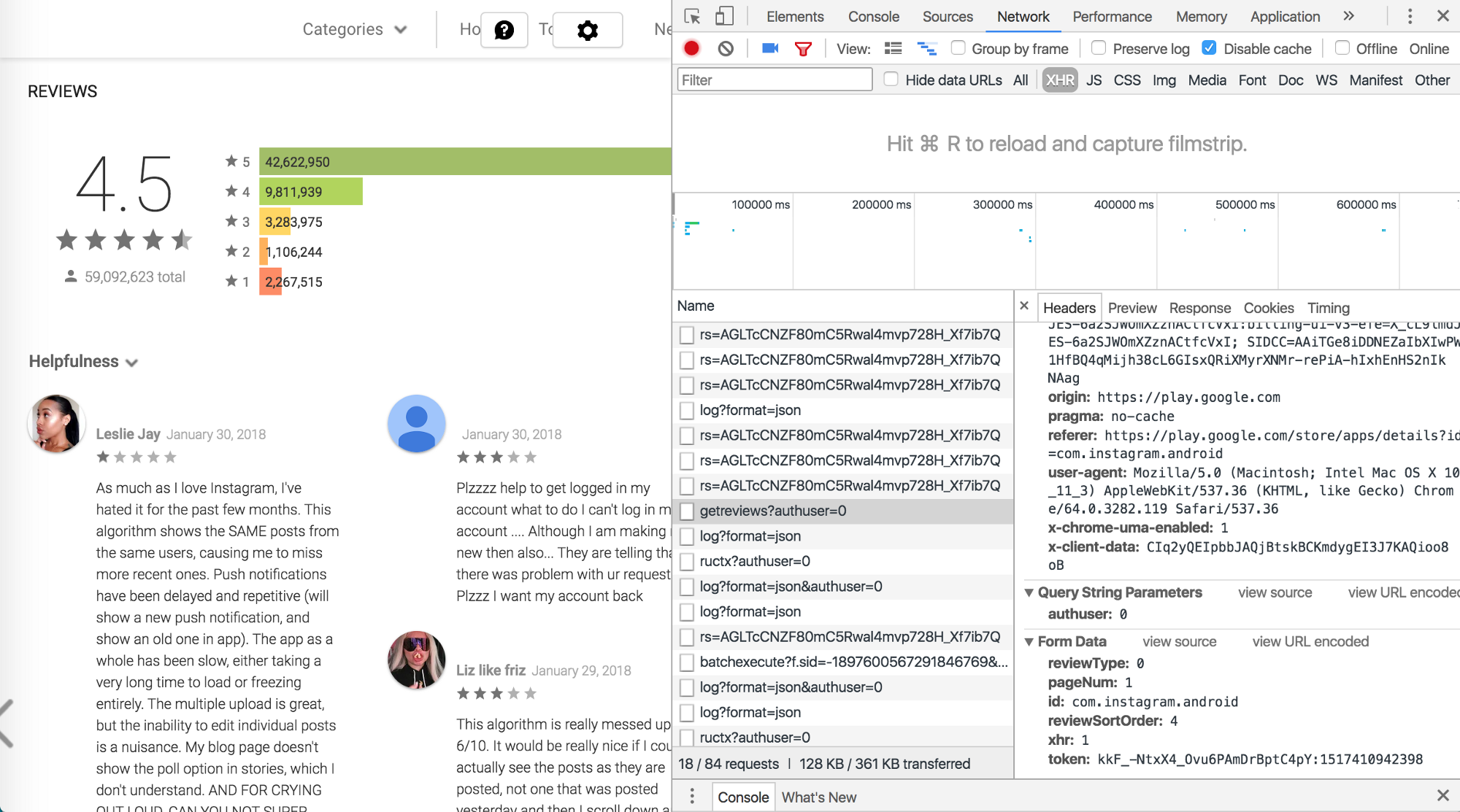
To send a POST request we can use jQuery.ajax() and call it from the context of the page loaded in a headless browser. To get more than 40 reviews, you can iterate the page parameter as we did in the previous example. XHR in this case returns HTML data instead of JSON, so we have to parse them and use selectors.
Here’s a complete crawler that extracts 4,000 reviews for a given app on Google Play Store in a few seconds:
You can also find it in Apify library. Here’s an example output.
BTW, in a browser console you see the token that is sent within POST data. It also works without this token, but if you want to add it there, you can scrape it first using window._uc variable:
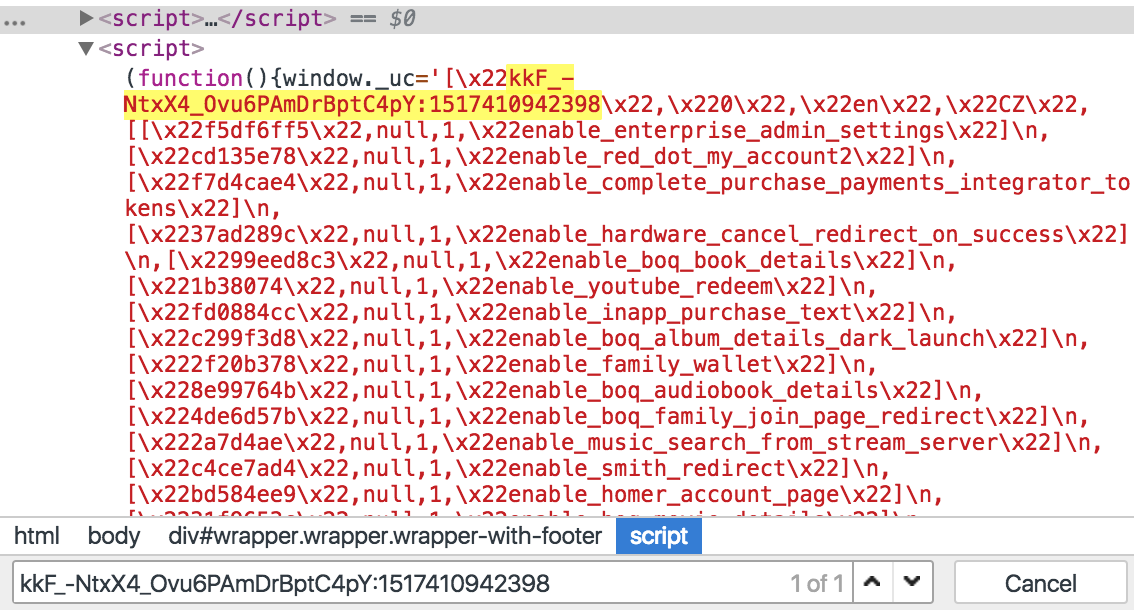
This approach can be used for scraping data from Airbnb. You don’t even need to open the page in a headless browser, you just need to get the token first and then use their API:
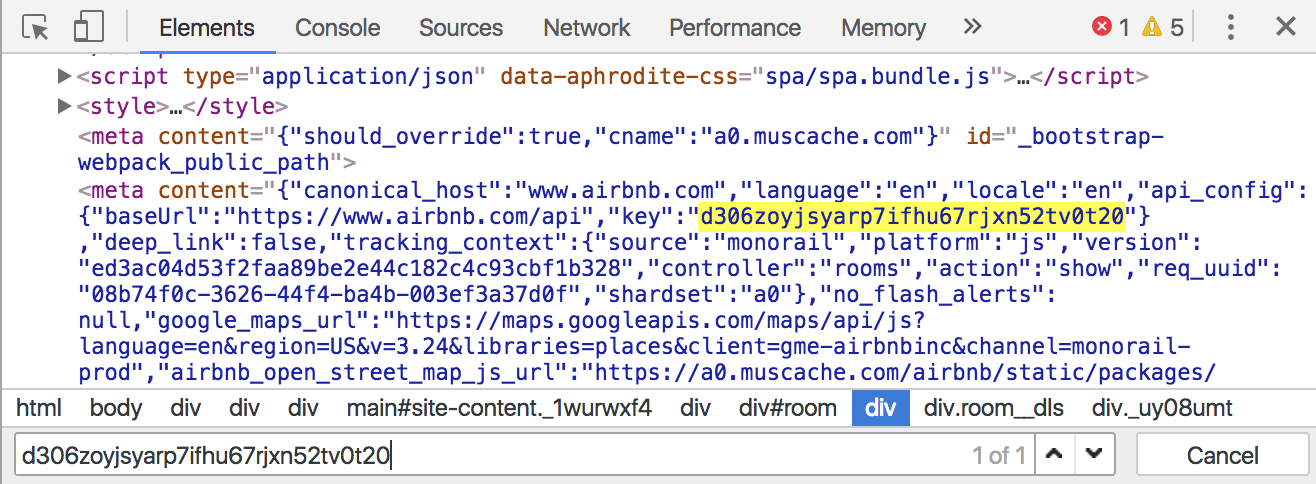
With this token you can use the Airbnb API to get prices, availability or reviews. Here’s an example GET request to get the first seven reviews for a given listing:
https://www.airbnb.com/api/v2/reviews?key=d306zoyjsyarp7ifhu67rjxn52tv0t20¤cy=USD&locale=en&listing_id=1720832&role=guest&_format=for_p3&_limit=7&_offset=0&_order=language_country(note that this probably doesn’t work now due to the expired token).
Then you can just iterate through offset and get all reviews for any listing you want. Here’s a complete crawler for that (example output available here):
BTW, here’s a crawler in the Apify library which scrapes info about all listings from Airbnb for a given area.
Page analyzer
And now here’s a little reward for anyone who has read this far. At the beginning of this post I mentioned that I always check the availability of the methods described above. But I don’t have to check manually anymore. We’ve just launched a tool called Page Analyzer which does this automatically for us. And for you as well — it’s free for everyone! It runs on Apify and uses this Apify Actor act (also available on GitHub).
Page Analyzer is available here. Just enter the URL of the page you want to check and click Analyze:





