


In this guide, you'll learn how to create a TikTok scraper in Python, step-by-step. It doesn’t require any prior experience in web scraping. As long as you’re able to follow the steps, you'll have built a Python TikTok scraper by the end of the guide.
How to build a TikTok scraper using Python
Here are the steps you should follow to build your TikTok scraper.
1. Setting up your environment
Here's what you’d need to continue with this tutorial:
• Python 3.5+: Make sure you have installed Python 3.5 or higher and set up the environment.
• Required libraries: Install them by running the command below in your terminal — selenium , pandas and webdriver-manager .
pip install selenium webdriver-manager pandas
To import the libraries to your script, use the following code
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.chrome.service import Service
from webdriver_manager.chrome import ChromeDriverManager
import pandas as pd
# Importing built-in libraries
import re
import time
2. Understanding TikTok’s web structure
Before scraping any website, it’s important to understand its web structure and where you can scrape data from.
The two TikTok pages mainly contain useful information for web scraping purposes.
#1. Trending Now page: https://www.tiktok.com/channel/trending-now?
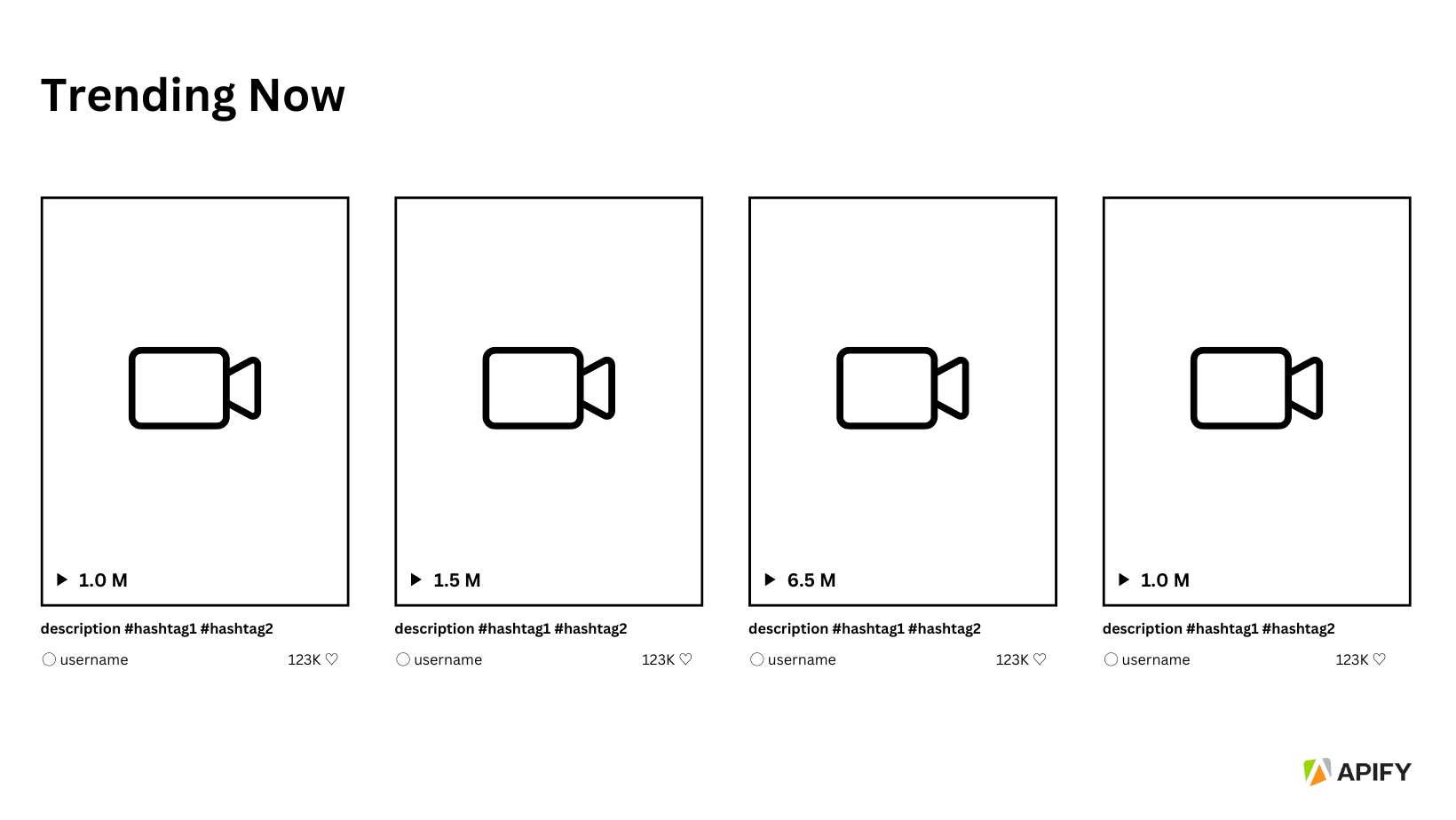
Data available: Trending videos, including their hashtags, uploaded users, number of likes, and views count.
Page structure:
- This page consists of a card-like structure which consists of trending videos on TikTok. These are inside a
<div>container with the class oftiktok-559e6k-DivItemContainer e1aajktk28 - Inside each video card is a <strong> element which includes the total view count, with the class
tiktok-ksk56u-StrongLikes e1aajktk9. - The bottom of the video card includes the description, which includes the relevant hashtags with the class
tiktok-1anth1x-DivVideoDescription.e1aajktk10. Please note that both the video description text and hashtags are included in one class, which could be a problem when they should be extracted separately. - The user name is nested within an
<a>tag inside the parent<div>, with the<a>tag containing a<p>element having the attributedata-e2e="video-user-name"(XPath:..//a/p[@data-e2e="video-user-name"]). - The like count is found within a nested span element, where the outer span has the class
tiktok-10tcisz-SpanLikes e1aajktk13and the inner span has the classtiktok-dqro2j-SpanLikeWrapper e1aajktk24(XPath:..//span[contains(@class, "tiktok-10tcisz-SpanLikes") and contains(@class, "e1aajktk13")]).
Remember: We use XPATH instead of normal CSS Selectors to navigate complex structures— like the username and likes count in the nested <div> container— more accurately and easily.
#2. User-pages: https://www.tiktok.com/@username
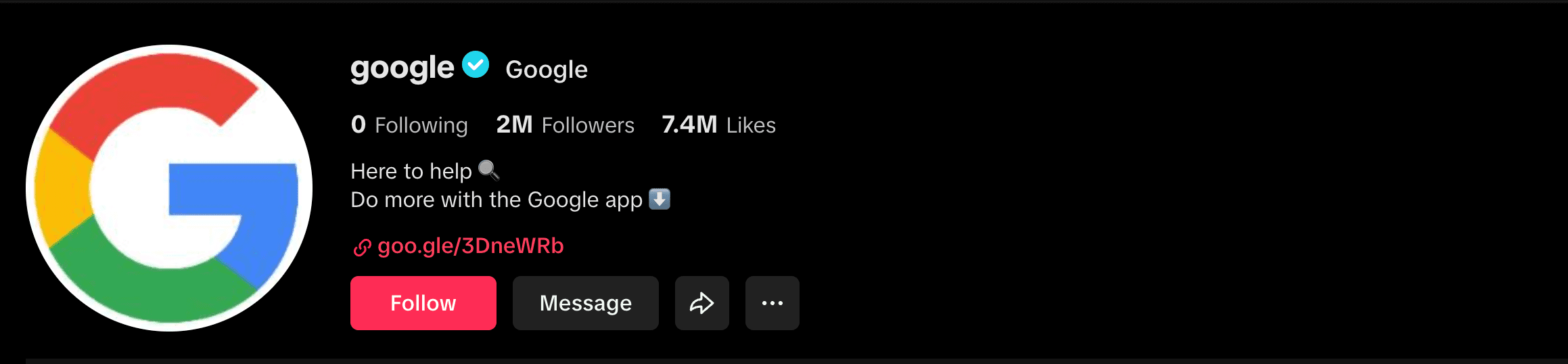
Data available: Follower count, following count, and likes count of a specific user.
Page structure:
- Username is an
<h1>element with the attributecss-1xo9k5n-H1ShareTitle e1457k4r8 - Followers count is within an
<div>element with the classcss-1ldzp5s-DivNumber e1457k4r1. - The following count is inside an
<strong>element with the attributedata-e2e="following-count". - The likes count is also in an
<strong>element with the attributedata-e2e="likes-count". - The bio is located within an
<h2>element with the attributedata-e2e="user-bio".
3. Writing the scraper code
Now that you know how to access the required elements on the TikTok website, we can start writing the code.
While the libraries requests and beautifulsoup are commonly used for web scraping, they're not the the best option when it comes to websites with dynamically loaded content, like TikTok. That's why it’s best to use a web driver like ChromeDriver along with Selenium.
You can either download ChromeDriver manually or use the following code, which includes the install() function to download and set up ChromeDriver. However, make sure you have the Chrome browser installed already.
# Initializing the WebDriver using webdriver-manager
service = Service(ChromeDriverManager().install())
options = webdriver.ChromeOptions()
driver = webdriver.Chrome(service=service, options=options)
After initializing the web driver, you can use the following function to extract data, using the selectors mentioned in the previous section.
Scraping the Trending Now page
As mentioned before, the information on this page has a bit of a complex structure. Therefore, we will need two types of selectors to scrape data: CSS selectors and XPath.
Furthermore, since the video description text and hashtags both have one class, you will need functions to do the following:
- Detect and separate hashtags: Hashtags can be detected by the
#symbol. If a word starts with#and there’s no space between the first and the rest of the characters, it’s a Hashtag. - Remove hashtag from description text: One detected the
relibrary can replace hashtags with blank text in the description text.
Here are the two functions for the above tasks:
# Function to extract hashtags from description
def extract_hashtags(description):
hashtags = re.findall(r'#\\w+', description)
return hashtags
# Function to remove hashtags from description
def remove_hashtags(description):
return re.sub(r'#\\w+', '', description).strip()
Once the above functions are ready, you can write the rest of the code as below:
# Function to scrape trending videos
def scrape_trending_videos_with_selenium(url):
driver.get(url)
time.sleep(5) # Waiting for the page to load
videos = []
scroll_pause_time = 2 # Pausing to allow content to load
while len(videos) < 50:
video_description = driver.find_elements(By.CSS_SELECTOR, 'div.tiktok-1anth1x-DivVideoDescription.e1aajktk10')
for video in video_description[len(videos):]:
video_data = {}
description_element = video.find_element(By.XPATH, '..')
description_text = video.text
video_data['Description'] = description_text # Capture description with hashtags
# Extracting views
if description_element.find_elements(By.CSS_SELECTOR, 'strong.tiktok-ksk56u-StrongLikes.e1aajktk9'):
video_data['Views'] = description_element.find_element(By.CSS_SELECTOR, 'strong.tiktok-ksk56u-StrongLikes.e1aajktk9').text
else:
video_data['Views'] = 'N/A'
# Extracting username
try:
user_element = description_element.find_element(By.XPATH, '..//a/p[@data-e2e="video-user-name"]')
video_data['User'] = user_element.text
except Exception as e:
video_data['User'] = 'N/A'
# Extracting likes
try:
likes_element = description_element.find_element(By.XPATH, '..//span[contains(@class, "tiktok-10tcisz-SpanLikes") and contains(@class, "e1aajktk13")]')
video_data['Likes'] = likes_element.text.split()[-1] # Extract the last part assuming it's the like count
except Exception as e:
video_data['Likes'] = 'N/A'
videos.append(video_data)
if len(videos) >= 50:
break
# Scrolling down to load more videos
driver.execute_script("window.scrollTo(0, document.body.scrollHeight);")
time.sleep(scroll_pause_time) # Wait for new videos to load
return videos
# URL for the page
trending_videos_url = 'https://www.tiktok.com/channel/trending-now?lang=en'
trending_videos = scrape_trending_videos_with_selenium(trending_videos_url)
# Convert to DataFrame and save to CSV
# (for easier conversion and better accessibility)
df_videos = pd.DataFrame(trending_videos)
df_videos.to_csv('trending_videos_selenium.csv', index=False)
print('Data scraped and saved to trending_videos_selenium.csv')
driver.quit()
Result:
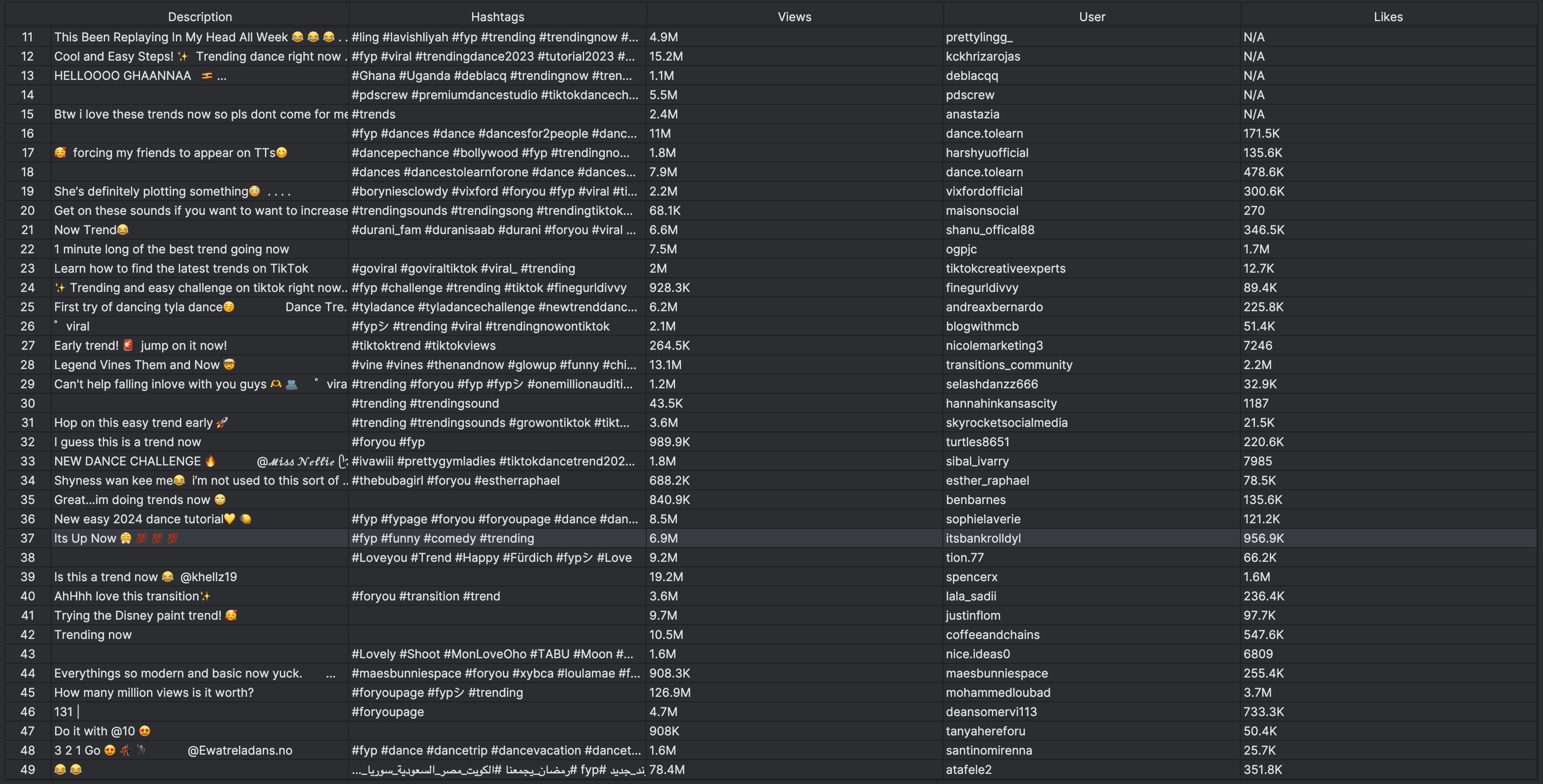
Scraping user pages
Unlike the Trending Now page, TikTok user pages follow a simple structure that can be navigated easily using CSS selectors.
# Function to scrape user pages
def scrape_user_page_with_selenium(url):
driver.get(url)
time.sleep(5) # Waiting for the page to load
user_data = {}
# Extracting follower count
try:
follower_count = driver.find_element(By.CSS_SELECTOR, 'strong[data-e2e="followers-count"]').text
user_data['Follower Count'] = follower_count
except Exception as e:
user_data['Follower Count'] = 'N/A'
# Extracting following count
try:
following_count = driver.find_element(By.CSS_SELECTOR, 'strong[data-e2e="following-count"]').text
user_data['Following Count'] = following_count
except Exception as e:
user_data['Following Count'] = 'N/A'
# Extracting likes count
try:
likes_count = driver.find_element(By.CSS_SELECTOR, 'strong[data-e2e="likes-count"]').text
user_data['Likes Count'] = likes_count
except Exception as e:
user_data['Likes Count'] = 'N/A'
# Extracting bio
try:
bio = driver.find_element(By.CSS_SELECTOR, 'h2[data-e2e="user-bio"]').text
user_data['Bio'] = bio
except Exception as e:
user_data['Bio'] = 'N/A'
# Extracting username
try:
username = driver.find_element(By.CSS_SELECTOR, 'h1[data-e2e="user-title"]').text
user_data['Username'] = username
except Exception as e:
user_data['Username'] = 'N/A'
return user_data
# List of user page URLs to scrape
user_page_urls = [
'https://www.tiktok.com/@google',
'https://www.tiktok.com/@nba',
# Add more URLs if needed
]
# Scrape data for each user page
user_data_list = []
for url in user_page_urls:
user_data = scrape_user_page_with_selenium(url)
user_data['URL'] = url # Add URL to the data for reference
user_data_list.append(user_data)
# Convert to DataFrame and save to CSV
df_user = pd.DataFrame(user_data_list)
df_user.to_csv('user_pages_selenium.csv', index=False)
print('Data scraped and saved to user_pages_selenium.csv')
driver.quit()
Result:

4. Deploying to Apify
There are several reasons for deploying your scraper code to a cloud platform like Apify. In this specific case, it helps you automate the data extraction process efficiently by regulating data collection and provides a convenient way to store and download your data.
To deploy your code to Apify, follow these steps:
- #1. Create an account on Apify
- #2. Create a new Actor
- First, install Apify CLI using NPM or Homebrew in your terminal.
- Create a new directory for your Actor.
mkdir my-tiktok-scraper
cd my-tiktok-scraper
- Then initialize the Actor by typing
apify init. - After that, create a JSON file as package.json.
touch package.json
- Edit the package.json file, including the following:
{
"name": "my-tiktok-scraper",
"version": "1.0.0",
"description": "A scraper for TikTok using Apify",
"main": "main.py",
"dependencies": {
"apify": "^2.0.0",
"selenium-webdriver": "^4.0.0",
"webdriver-manager": "^3.0.0"
},
"scripts": {
"start": "python main.py"
},
"author": "",
"license": "ISC"
}
- #3. Create the main.py script
Note that you would have to make some changes to the previous script to make it Apify-friendly. Such changes are: importing Apify SDK, adding headless options for web drivers, and updating input/output handling. You can find the modified script on GitHub.
- #4. Create the
Dockerfileandrequirements.txt- Dockerfile:
FROM apify/actor-python
# Install system dependencies
RUN apt-get update && apt-get install -y \\
wget \\
unzip \\
libnss3 \\
libgconf-2-4 \\
libxss1 \\
libappindicator1 \\
fonts-liberation \\
libasound2 \\
libatk-bridge2.0-0 \\
libatk1.0-0 \\
libcups2 \\
libgbm1 \\
libgtk-3-0 \\
libxkbcommon0 \\
xdg-utils \\
libu2f-udev \\
libvulkan1 \\
&& rm -rf /var/lib/apt/lists/*
# Install ChromeDriver
RUN wget -q -O /tmp/chromedriver.zip <https://chromedriver.storage.googleapis.com/114.0.5735.90/chromedriver_linux64.zip> \\
&& unzip /tmp/chromedriver.zip -d /usr/local/bin/ \\
&& rm /tmp/chromedriver.zip
# Install Google Chrome
RUN wget -q -O - <https://dl-ssl.google.com/linux/linux_signing_key.pub> | apt-key add - \\
&& sh -c 'echo "deb [arch=amd64] <http://dl.google.com/linux/chrome/deb/> stable main" >> /etc/apt/sources.list.d/google-chrome.list' \\
&& apt-get update \\
&& apt-get install -y google-chrome-stable \\
&& rm -rf /var/lib/apt/lists/*
# Copy all files to the working directory
COPY . ./
# Install necessary packages
RUN pip install --no-cache-dir -r requirements.txt
# Set the entry point to your script
CMD ["python", "main.py"]
- requirements.txt:
selenium
webdriver_manager
apify-client
- #5. Deploy to Apify
- Type
apify loginto log in to your account. You can either use the API token or verify through your browser. - Once logged in, type
apify pushand you’re good to go.
- Type
To run the deployed Actor, go to Apify Console > Actors > Your Actor. Then click the “Start” button, and the Actor will start to build and run.
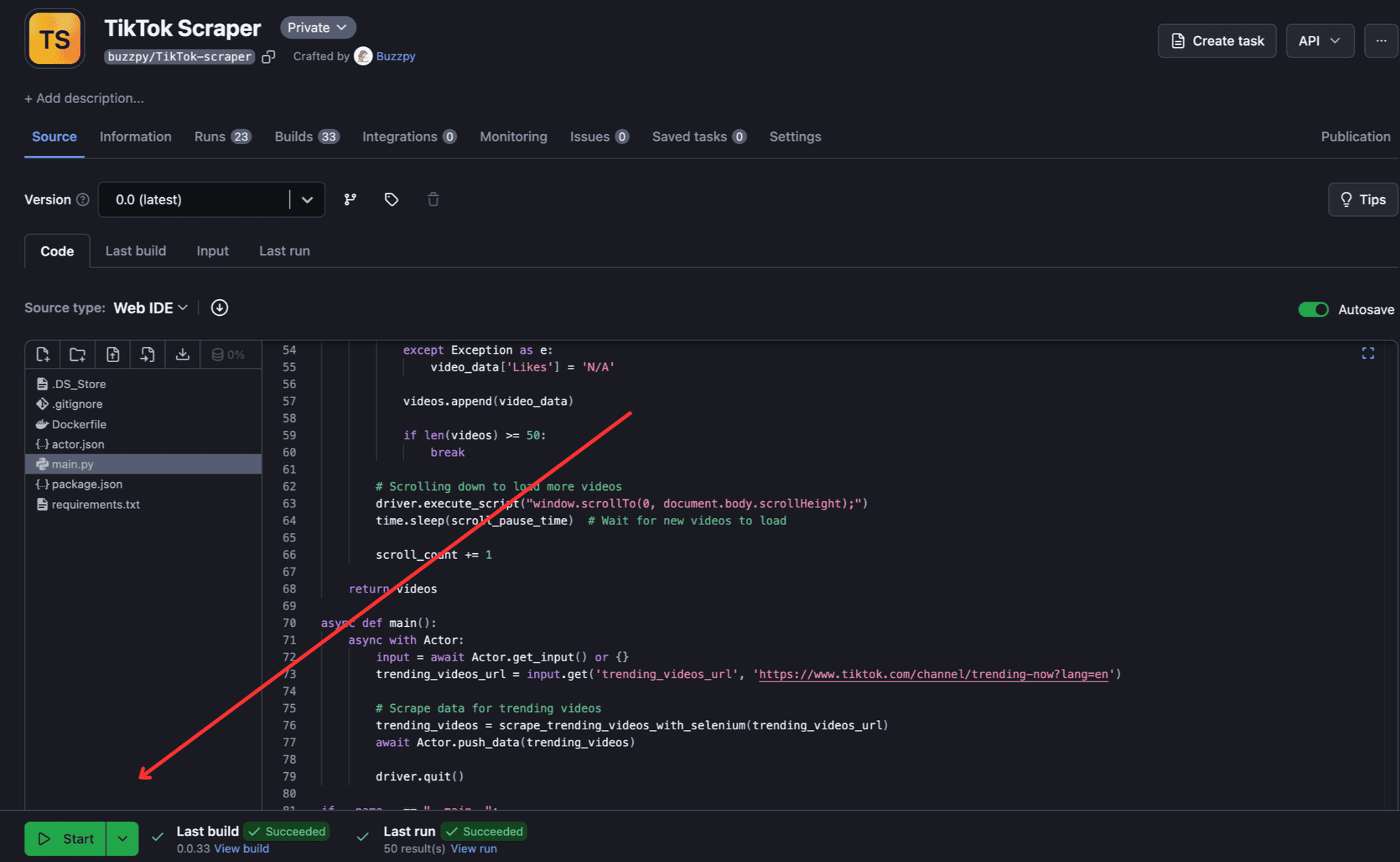
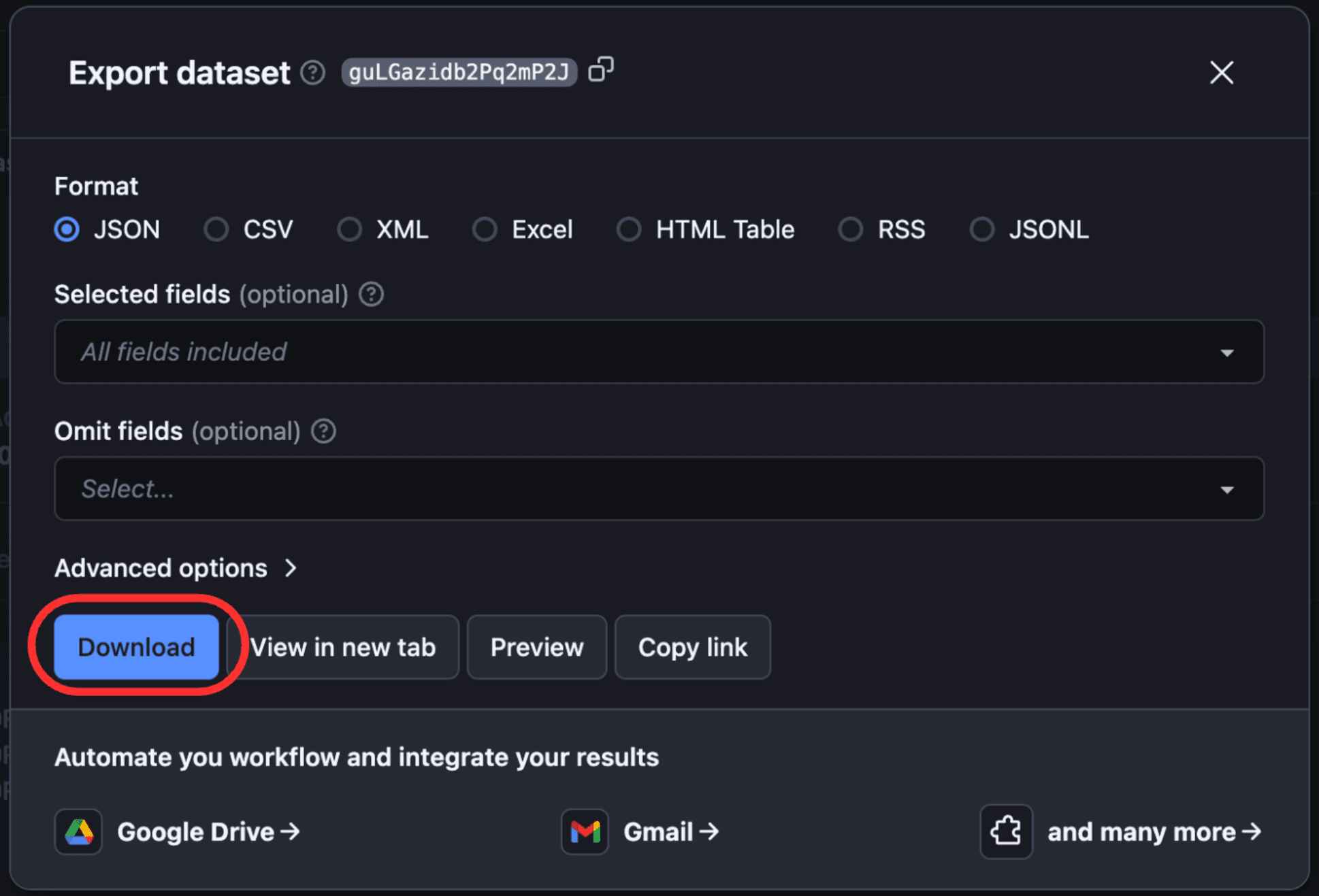
To view and download output, click “Export Output”.
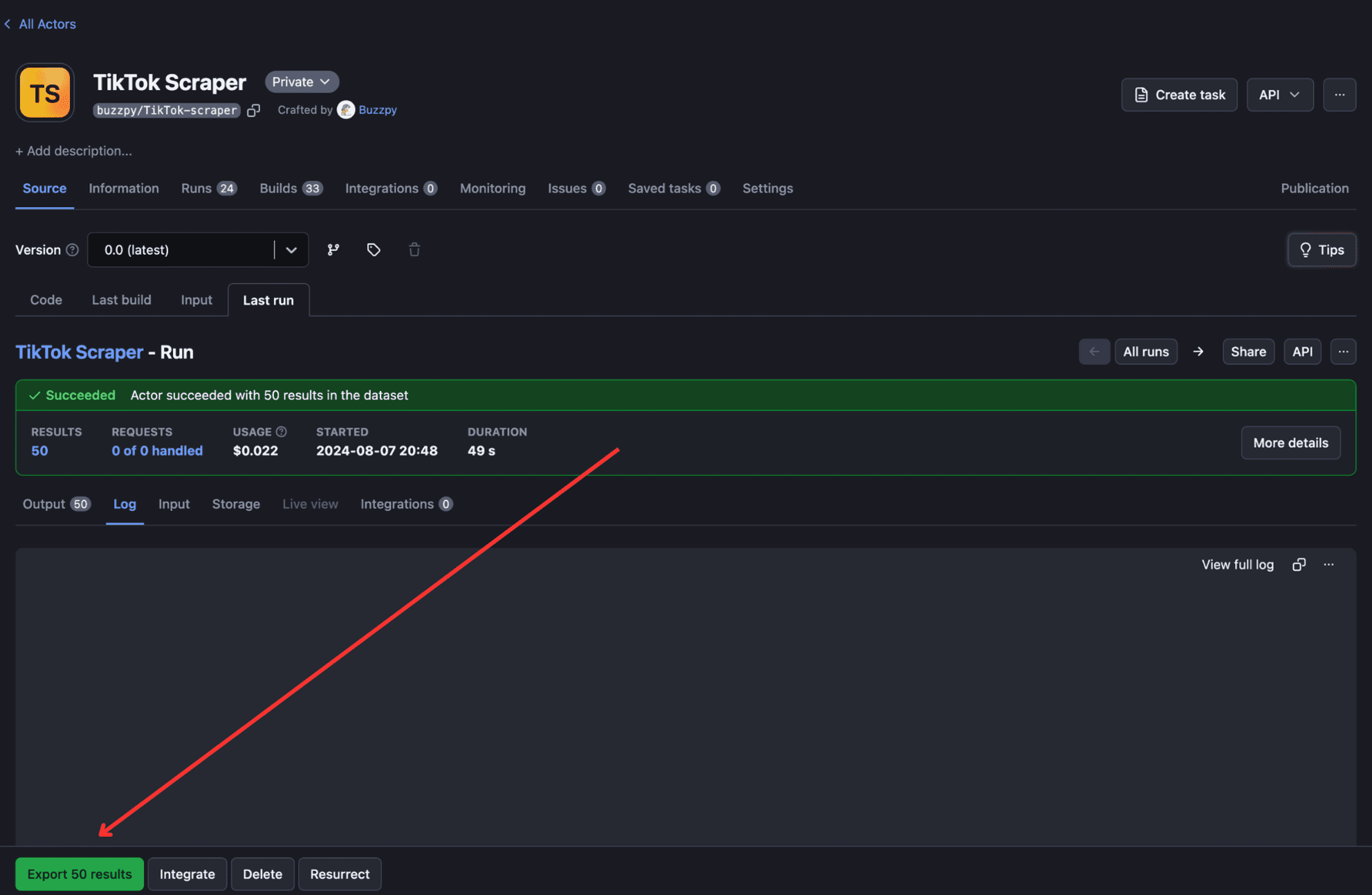
If required, you can select/omit sections and download the data in different formats such as CSV, JSON, Excel, etc.
And that’s it. You've successfully built and deployed a TikTok web scraper.
How to scrape TikTok via API
Does TikTok have an API?
TikTok does have an API, but unfortunately, it has some restrictions and other drawbacks, especially when it comes to data access and functionality. For example, the API for TikTok has a rate limit and a data scope limit (no access to comments and other user interactions).
However, using a ready-made Actor on Apify will save you the hassle. It doesn't have the limitations of rate limits or data access, so it provides more comprehensive data scraping capabilities.
How to scrape TikTok with an Apify Actor
Here’s how you can use a TikTok data scraping Actor to extract TikTok data easily.
- Install
apify-clientSDK (unless already done).
pip install apify-client
- Import Apify SDK and initialize the client.
from apify_client import ApifyClient
client = ApifyClient('YOUR_API_TOKEN')
You can find your API Token in Apify Console > Settings > Integrations.
- Give the Actor input and create a new run for the Actor.
run_input = {
# Feel free to add other queries.
"hashtags": ["api"],
"resultsPerPage": 100,
}
# Run the Actor and wait for it to finish
run = client.actor("clockworks/free-tiktok-scraper").call(run_input=run_input)
- Print the results from the dataset:
dataset_items = client.dataset(run["defaultDatasetId"]).list_items()
for item in dataset_items.items:
print(item)
Give the Actor input and create a new run for the Actor.
Once run, the above code would scrape TikTok video information with the hashtag “#api”. You can also add other parameters if needed.
Scrape TikTok with no code
As you can see, using an Actor in Apify Console is even easier than using the APIs, and it doesn’t need code either.
Here's a list of ready-made, no-code-required Actors to easily scrape TikTok.
- TikTok Video Scraper: Easily scrape TikTok videos.
- TikTok Profile Scraper: Scrape TikTok user pages for posts, follower counts, and more.
- TikTok Comments Scraper: Scrape comments on TikTok videos.
- TikTok Ads Scraper: Extract and analyze competitor TikTok ads.
- TikTok Sound Scraper: Extract information from all the videos that use a certain soundtrack easily.
- TikTok Hashtag Scraper: Find insights on hashtags for your audience.
- TikTok Discover Scraper: Extract all the video information using a certain tag on the tiktok.com/discover page.
For more information on how to use these no-code solutions, visit Apify Docs.
Watch our webinar on TikTok scraping to learn how to use all these scrapers and how they can help you.
A quick recap
We've demonstrated two effective methods of scraping TikTok data: 1) using Python code and 2) using an Apify TikTok scraper via API. Whichever approach you prefer, what you've learned here will surely help you in your own TikTok scraping projects. Good luck!




