


Google News is one of the most trusted and popular platforms to gather real-time, verified news updates. For the same reason, scaping Google News can be a reliable way to collect the latest news articles, trending topics, and related metadata for data analysis, research, or simply reading news. If you want to take things to a higher level, scraping Google News can also help you build your own personalized news application through real-time web scraping.
This step-by-step guide will walk you through the process of scraping Google News using Python, from setup to deployment on Apify. Keep reading to build your own Google News scraper.
Guide for scraping Google News
For building this scraper, we’ll be using beautifulsoup library along with Apify for the deployment of our scraper. At the end of the tutorial, you’ll have built a Google News scraper that can also be scheduled to run daily, weekly, or annually using Apify’s features.
1. Prerequisites and setup
To start scraping Google News in Python, you’ll need:
- Python 3.7+ installed and ready to use.
- A basic knowledge of Python
beautifulsoupinstalled.
You can use the following command to install beautifulsoup :
pip install requests beautifulsoup4
To set up the project, import the above-installed beautifulsoup and the built-in library, requests as below:
import requests
from bs4 import BeautifulSoup
However, note that if you’re unable to use an IDE and install these libraries (or just want to skip the hustle), you can directly deploy the complete script on Apify for free.
2. Fetching Google News
Before starting to scrape, you should fetch the Google News website first.
For this tutorial, we’ll be scraping the World News Page on Google News. But also note that this code works for other pages as well (Business News, for example), you just have to replace the link in the URL variable.
To start fetching content from Google News, use the following code:
def get_google_news():
url = "https://news.google.com/topics/CAAqJggKIiBDQkFTRWdvSUwyMHZNRGx1YlY4U0FtVnVHZ0pWVXlnQVAB?ceid=US:en&oc=3"
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/120.0.0.0 Safari/537.36'
}
response = requests.get(url, headers=headers)
soup = BeautifulSoup(response.content, 'html.parser')
news_items = []
# Finding all story containers
containers = soup.find_all('div', class_='W8yrY')
# Scraping at least 10 headlines
for container in containers:
try:
# Getting the primary article in each container
article = container.find('article')
if not article:
continue
# Extracting headline
headline_elem = article.find('a', class_='gPFEn')
headline = headline_elem.get_text(strip=True) if headline_elem else 'No headline'
# Extracting source
source_elem = article.find('div', class_='vr1PYe')
source = source_elem.get_text(strip=True) if source_elem else 'Unknown source'
# Extracting and converting the source URL
relative_link = headline_elem['href'] if headline_elem else ''
absolute_link = f'<https://news.google.com>{relative_link.split("?")[0]}' if relative_link else ''
news_items.append({
'source': source,
'headline': headline,
'link': absolute_link
})
# Stop if we have 10 items
if len(news_items) >= 10:
break
except Exception as e:
print(f"Error processing article: {str(e)}")
continue
return news_items
This code contains the following elements to ensure all the relevant information related to a certain news is extracted.
- HTTP GET request: Uses the
requestslibrary to send an HTTP GET request to the specified Google News URL. - Custom headers: The
headersdictionary includes aUser-Agentstring that mimics a real browser (Chrome on Windows, in this case). This helps you avoid potential blocks or content restrictions by making the request look like it comes from a human user. - Parsing HTML content:
beautifulsoupis used to parse the HTML content returned by the request, enabling easy extraction of data from the page.
3. Extracting the headlines, sources, and URLs
After fetching the Google News page, you can start scraping the content by using the following script:
# Find all story containers
containers = soup.find_all('div', class_='W8yrY')
# Scrape at least 10 headlines
for container in containers:
try:
# Get the primary article in each container
article = container.find('article')
if not article:
continue
# Extract headline
headline_elem = article.find('a', class_='gPFEn')
headline = headline_elem.get_text(strip=True) if headline_elem else 'No headline'
# Extract source
source_elem = article.find('div', class_='vr1PYe')
source = source_elem.get_text(strip=True) if source_elem else 'Unknown source'
# Extract and convert link
relative_link = headline_elem['href'] if headline_elem else ''
absolute_link = f'https://news.google.com{relative_link.split("?")[0]}' if relative_link else ''
news_items.append({
'source': source,
'headline': headline,
'link': absolute_link
})
# Stop if we have 10 items
if len(news_items) >= 10:
break
except Exception as e:
print(f"Error processing article: {str(e)}")
continue
return news_items
Here’s a breakdown of the above code:
- Extracting story containers: The code searches for all
<div>elements with the class'W8yrY', which serve as containers for individual news stories. Note that in Google News, one container contains the same news from different sources. - Iterating over containers: Loops through each container to locate the primary
<article>element, instead of fetching the same news from different sources. - Extracting headline and source: Retrieves the headline from an anchor tag with the class
'gPFEn'and the source from a<div>with the class'vr1PYe'.Uses the.get_text(strip=True)method to cleanly extract text content. - Building absolute URLs: Converts relative URLs from the
hrefattribute into absolute URLs by prependinghttps://news.google.comand stripping query parameters. - Error handling: Implements a
try-exceptblock to handle any exceptions during parsing, making sure that the script continues to process the remaining articles. - Limiting to 10 items: The loop stops after successfully extracting 10 news items, but you can customize it according to your needs.
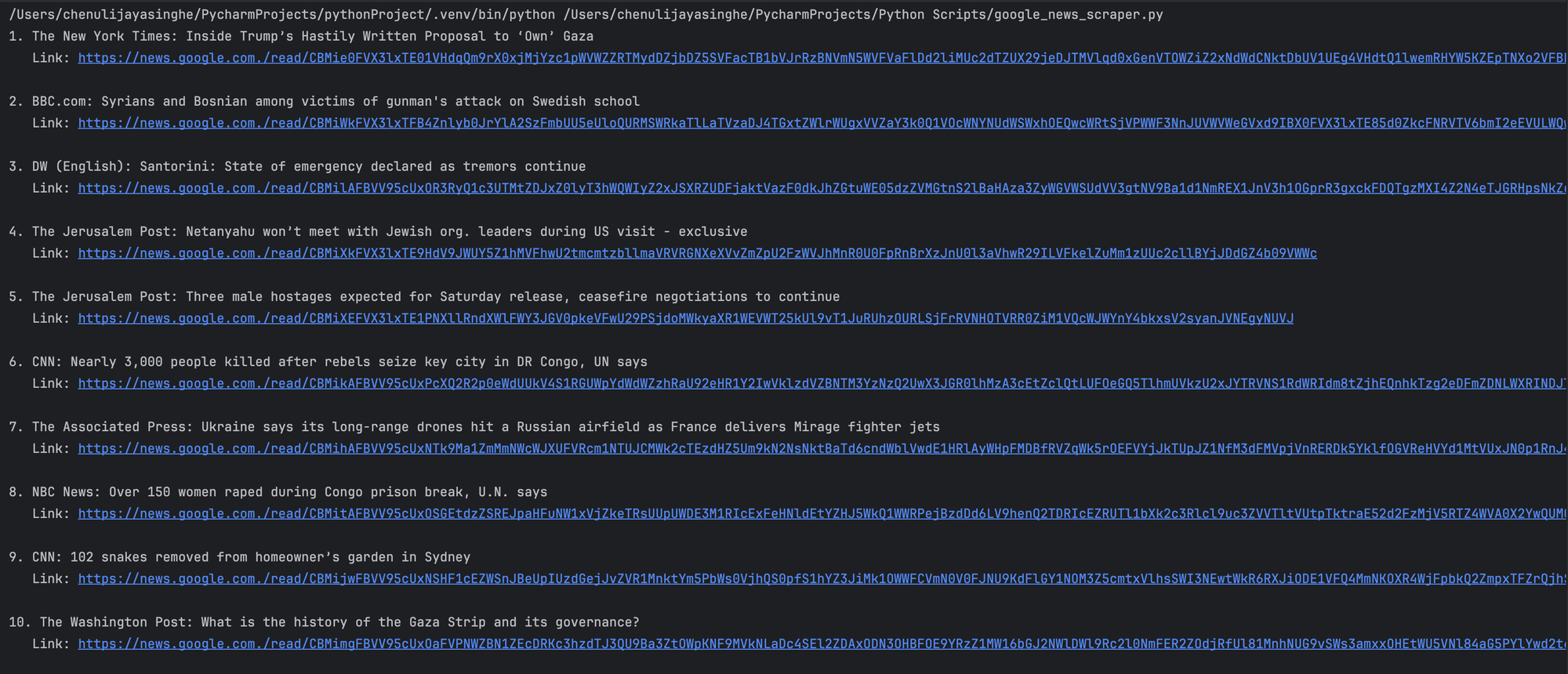
The code for scraping Google News is now ready to run. To print the extracted content and run the functions, make sure to include the following code:
if __name__ == "__main__":
news = get_google_news()
for idx, item in enumerate(news, 1):
print(f"{idx}. {item['source']}: {item['headline']}")
print(f" Link: {item['link']}\\n")
Once run, the above code would generate a clearly formatted output as shown in the following image:
4. Deploying to Apify
There are several reasons to deploy your scraper code to a platform like Apify. In this specific case, deploying code to Apify helps you automate the data scraping process efficiently by scheduling your web scraper to run daily or weekly. It also offers a convenient way to store and download your data.
To deploy your code to Apify, follow these steps:
#1. Create an account on Apify
- You can get a forever-free plan - no credit card required.
#2. Create a new Actor
- First, install Apify CLI using NPM or Homebrew in your terminal.
- Create a new directory for your Actor:
mkdir google-news-scraper
cd google-news-scraper
- Then initialize the Actor by typing
apify init.
#3. Create the main.py script
- Note that you would have to make some changes to the previous script to make it Apify-friendly. Such changes are: importing Apify SDK and updating input/output handling.
- You can find the modified script on GitHub.
#4. Create the Dockerfile and requirements.txt
- Dockerfile:
FROM python:3.9-slim
# Set the working directory
WORKDIR /app
# Copy the requirements file
COPY requirements.txt ./
# Install Python dependencies
RUN pip install --no-cache-dir -r requirements.txt
# Copy the rest of the application code
COPY . .
# Set the entry point to your script
CMD ["python", "main.py"]
- requirements.txt:
beautifulsoup4==4.9.3
requests==2.25.1
apify
#5. Deploy
- Type
apify loginto log in to your account. You can either use the API token or verify through your browser. - Once logged in, type
apify pushand you’re good to go.
Once deployed, head over to Apify Console > Your Actor > Click “Start” to run the scraper on Apify.
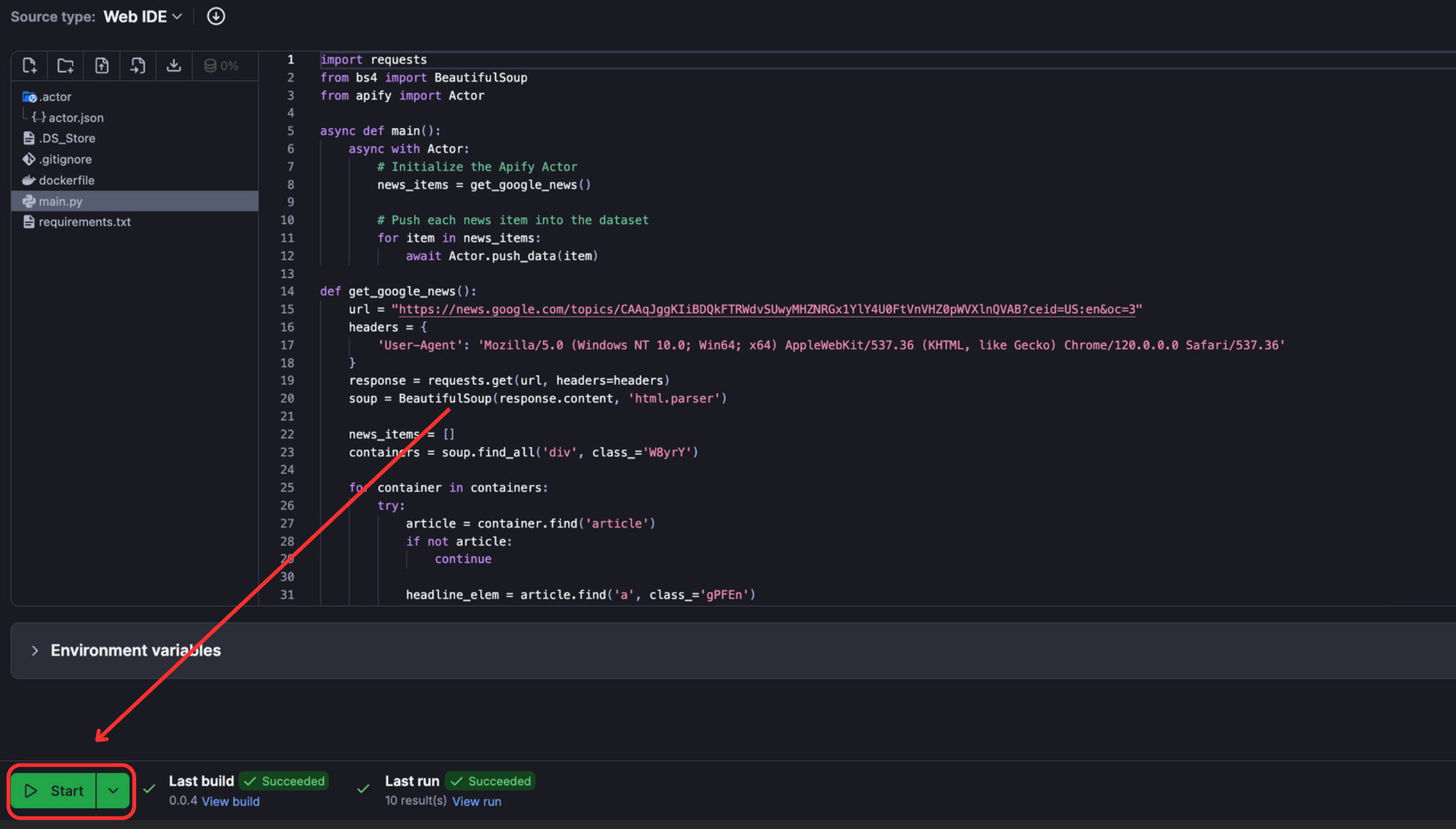
Once the run is successful, you can view the output of the scraper on the “Output” tab.
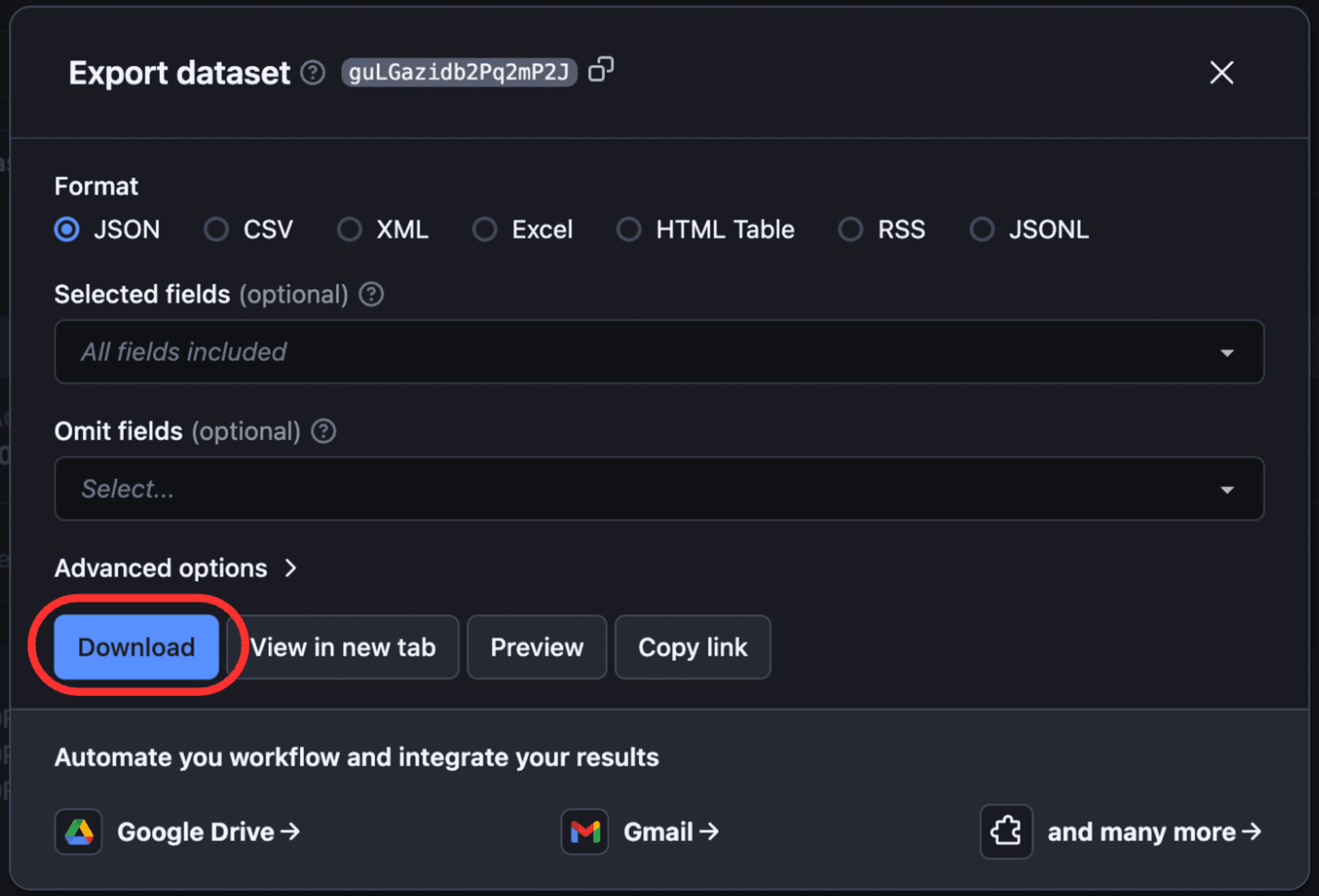
To view and download output, click “Export Output”.
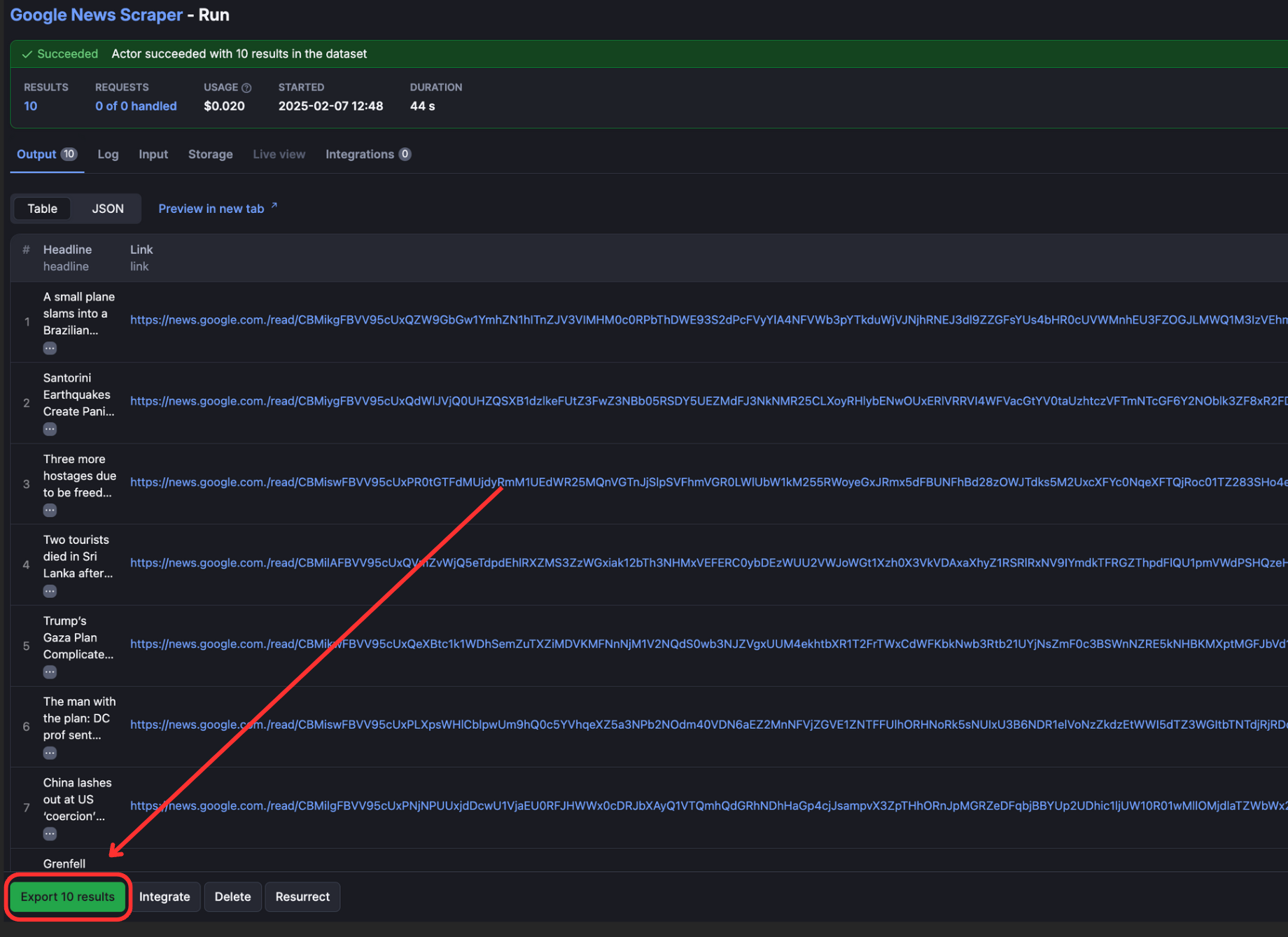
You can select/omit sections and download the data in different formats such as CSV, JSON, Excel, etc.
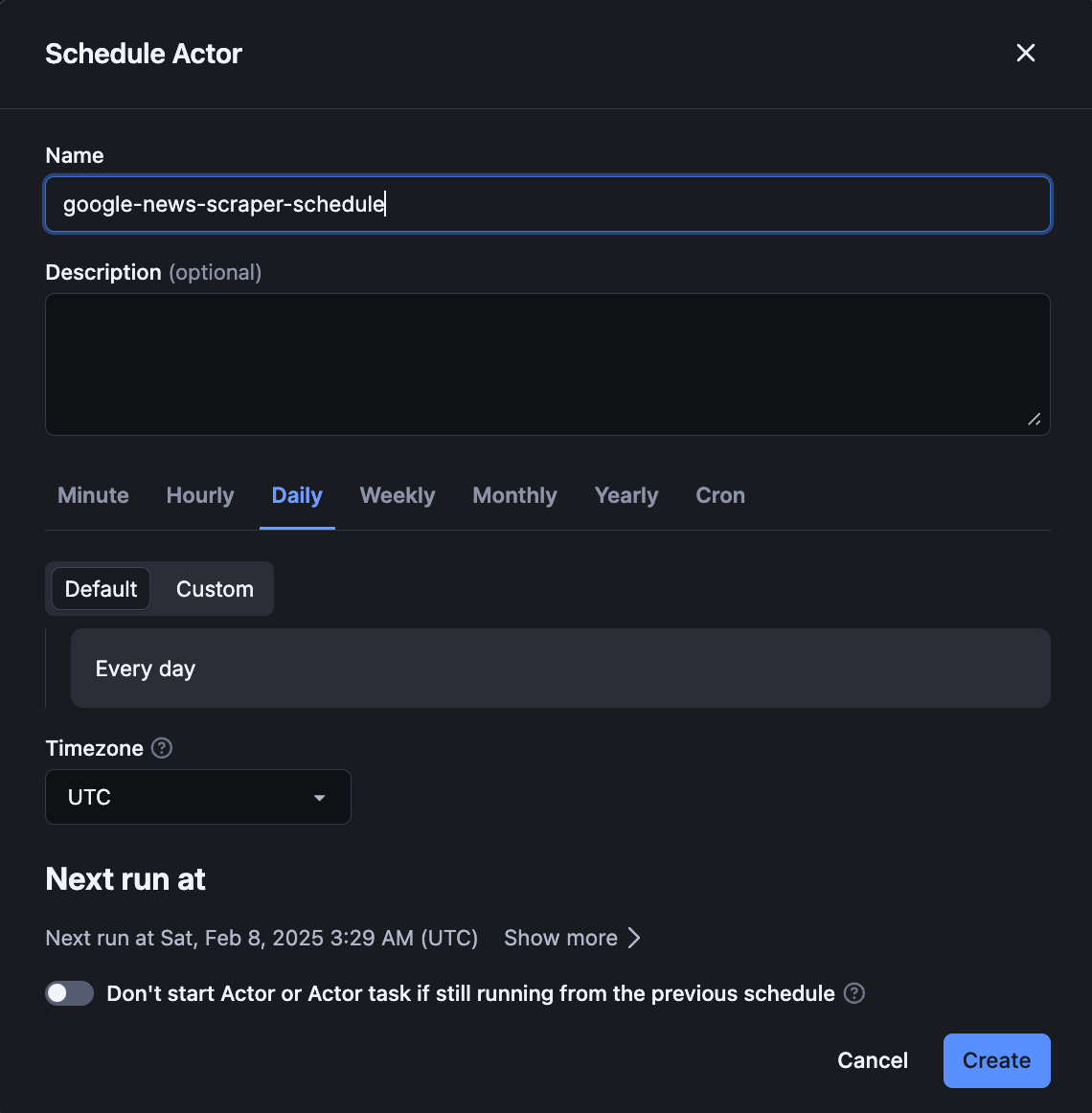
You can also schedule your Actor by clicking the three dots (•••) in the top-right corner of the Actor dashboard > Schedule Actor option.
The complete code
Here's the complete script for building a Google News scraper with beautifulsoup.
import requests
from bs4 import BeautifulSoup
def get_google_news():
url = "https://news.google.com/topics/CAAqJggKIiBDQkFTRWdvSUwyMHZNRGx1YlY4U0FtVnVHZ0pWVXlnQVAB?ceid=US:en&oc=3"
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/120.0.0.0 Safari/537.36'
}
response = requests.get(url, headers=headers)
soup = BeautifulSoup(response.content, 'html.parser')
news_items = []
# Finding all story containers
containers = soup.find_all('div', class_='W8yrY')
# Scraping at least 10 headlines
for container in containers:
try:
# Getting the primary article in each container
article = container.find('article')
if not article:
continue
# Extracting headline
headline_elem = article.find('a', class_='gPFEn')
headline = headline_elem.get_text(strip=True) if headline_elem else 'No headline'
# Extracting source
source_elem = article.find('div', class_='vr1PYe')
source = source_elem.get_text(strip=True) if source_elem else 'Unknown source'
# Extracting and converting the URLs
relative_link = headline_elem['href'] if headline_elem else ''
absolute_link = f'<https://news.google.com>{relative_link.split("?")[0]}' if relative_link else ''
news_items.append({
'source': source,
'headline': headline,
'link': absolute_link
})
# Stop if you have 10 items
if len(news_items) >= 10:
break
except Exception as e:
print(f"Error processing article: {str(e)}")
continue
return news_items
# Running and printing the results
if __name__ == "__main__":
news = get_google_news()
for idx, item in enumerate(news, 1):
print(f"{idx}. {item['source']}: {item['headline']}")
print(f" Link: {item['link']}\\n")
Using a ready-made Google News Scraper
Although building your own program to scrape Google News sounds like a good option, there are many downsides to doing so - dealing with website blocking (as the website identifies your script as a bot and refuses crawling), and of course, hours of debugging and headaches.
The best way to avoid the above is to use a ready-made scraper on a platform like Apify. By doing so, you can not only scrape the Google news page but also scrape news related to certain search queries, schedule runs, and extract news items of a certain period of time.
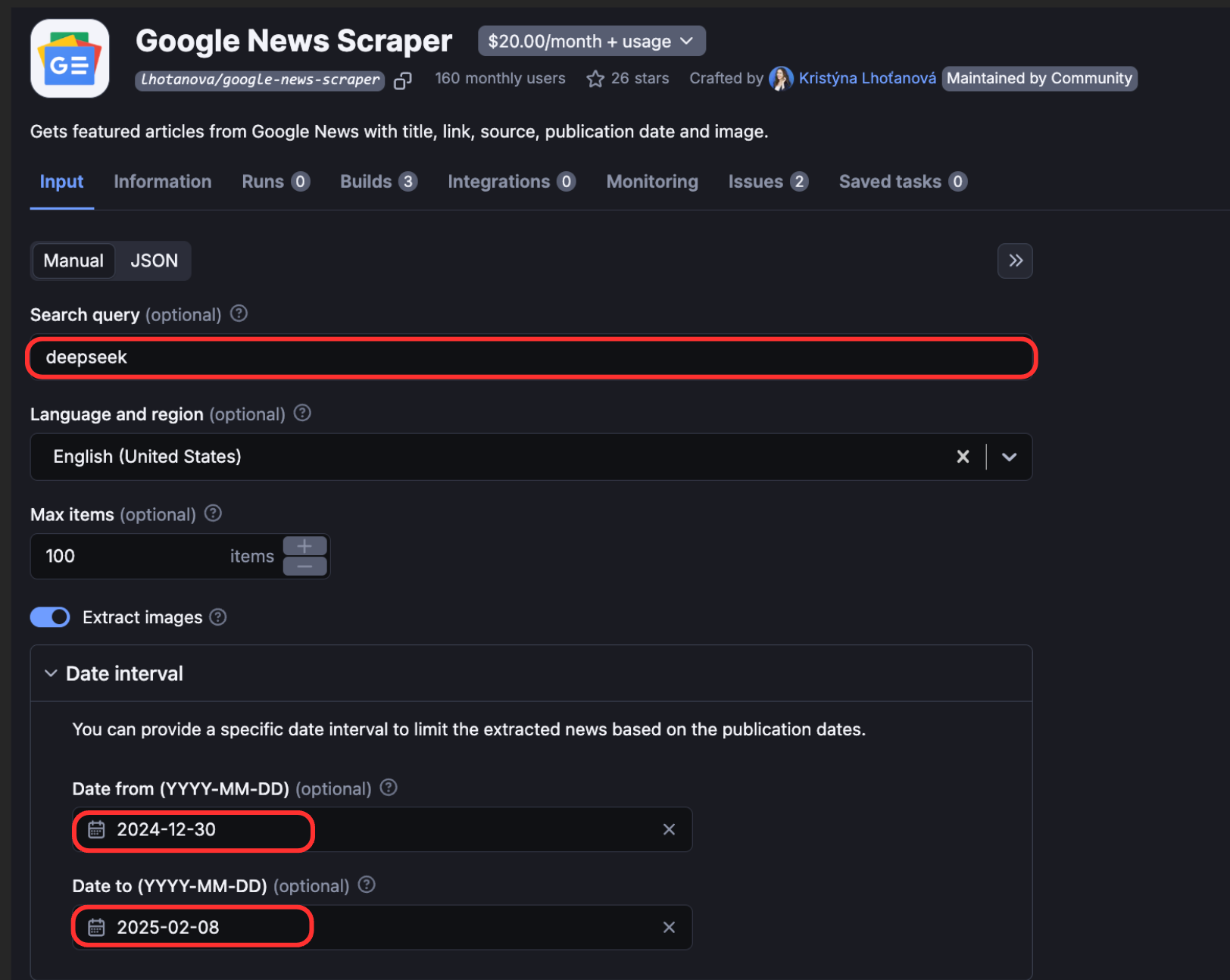
For example, if you want to scrape news about DeepSeek in a certain time period, you can go to Google News Scraper on Apify > Try for free, and fill in the input fields below:
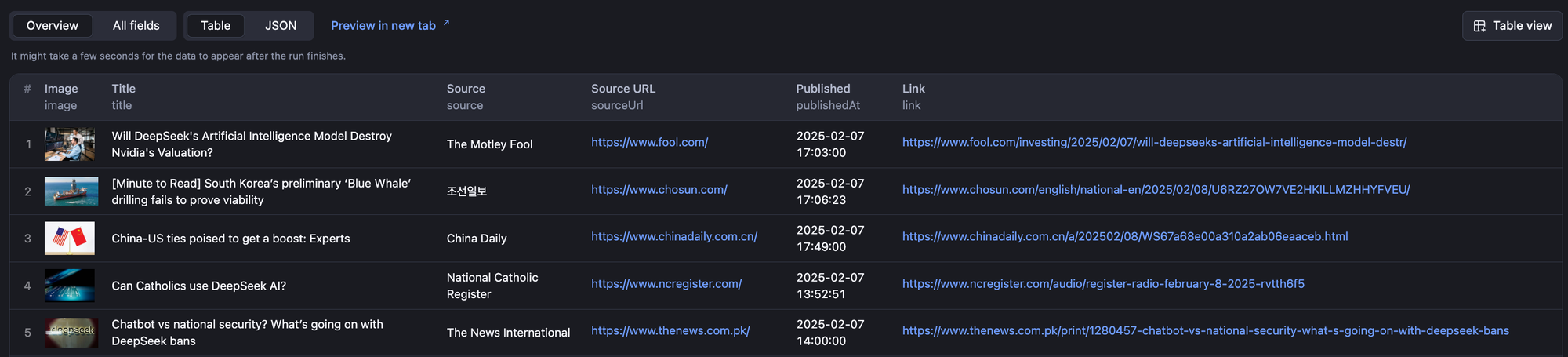
Once run, it’ll return the scraped information as follows:
Conclusion
In this tutorial, we built a program that can scrape Google News using Python’s beautifulsoup library and deployed it on Apify for easier management. We also showed you an easier way, which is to run an off-the-shelf Actor designed for the task: Google News Scraper. The first option gives you the flexibility to create the scraper you want. The second makes it easy to get data quickly and easily without building a scraper from scratch.
Frequently asked questions
Can you scrape Google News?
Yes, you can scrape Google News using 2 ways:
- Building a scraper from scratch: However, in order to handle issues like dynamic content parsing, you’ll have to implement techniques like using headless requests.
- Using ready-made scrapers on platforms like Apify.
Is it legal to scrape Google News?
Yes, it is legal to scrape Google News, as it is publicly available information. But you should be mindful of local and regional laws regarding copyright and personal data. If you want some solid guidance on the legality and ethics of web scraping, Is web scraping legal? is a comprehensive treatment of the subject.
How to scrape Google News?
To scrape Google News, you can use Apify’s Google News Scraper. It allows you to scrape metadata from Google News, such as headlines, images, and URLs, while also supporting query-based search options.




