


Scraping Amazon product data can be daunting due to constantly changing page layouts, anti-bot measures, and deeply structured product information. This is one of those situations where managing custom scraping scripts is much harder due to maintenance issues than adopting a ready-to-use solution.
In this guide, you’ll learn how to bypass those challenges thanks to Amazon Product Scraper - a cloud-based Amazon data extraction tool. You’ll see how to use it visually on the Apify platform, as well as integrate it into Python to retrieve Amazon product data via API.
Specifically, you’ll be guided through the following steps:
- Python project setup
- Select the Actor (Amazon Product Scraper) from Apify Store
- Test the scraper with the UI (no code needed)
- Set up the API integration
- Prepare your Python script for Amazon product data scraping integration
- Retrieve and set your Apify API token
- Complete code
If you only want to scrape with the user interface, you just need step 3.

Why scraping Amazon is so challenging
As an Amazon user, you know that while the basic user interactions are consistent across products, each product page can display very different types of information.
Some pages include images and videos to showcase the product, others feature detailed descriptions with additional media, and some even include comparison tables highlighting different variants.
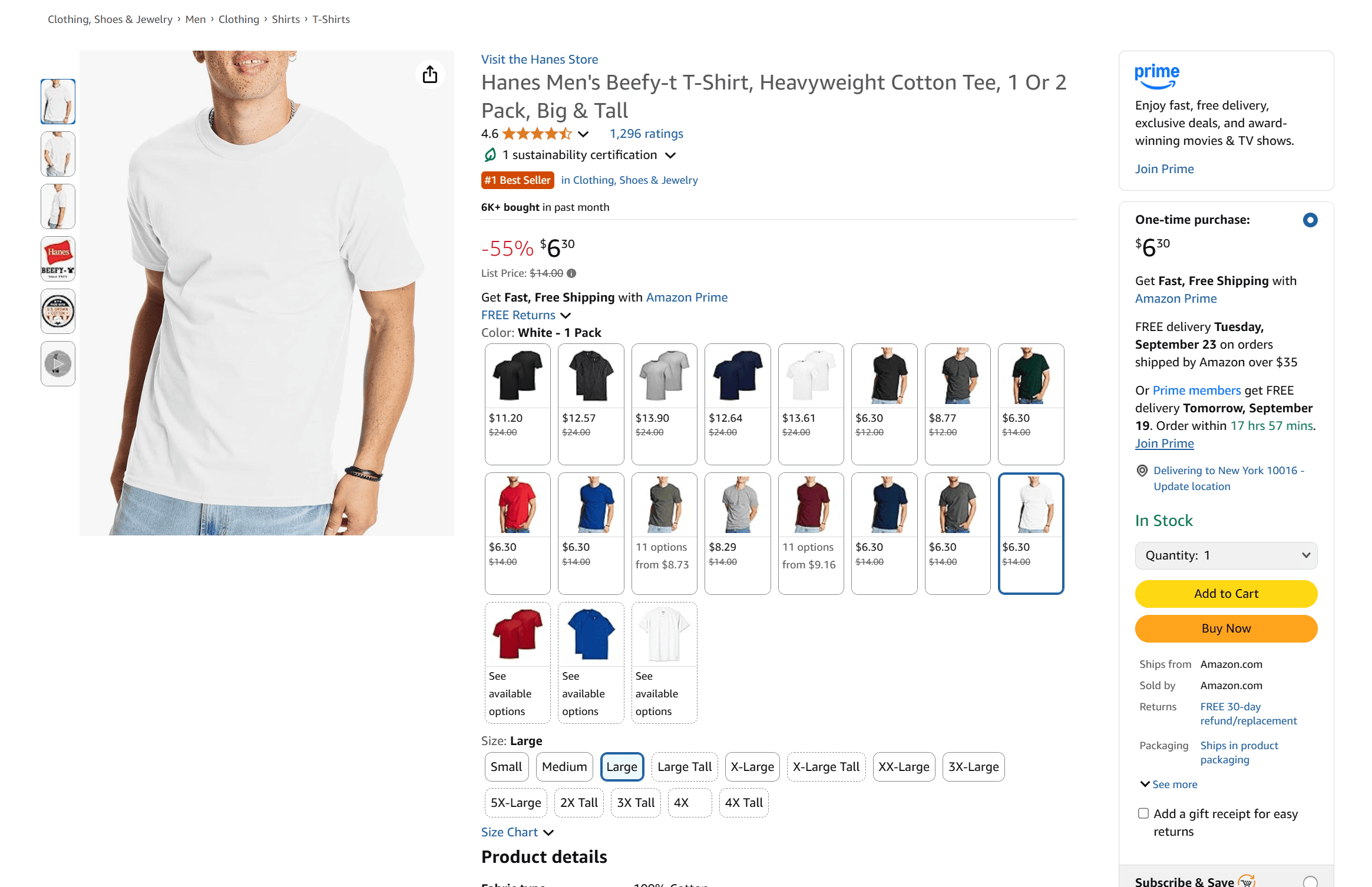
This variability poses a major challenge for web scraping because it’s difficult to define data parsing rules that can work across all product pages. Developing a scraper that can handle all those variations reliably requires writing numerous custom rules and logic to cover every possible edge case.
This dramatically increases maintenance costs. On top of that, Amazon actively blocks web scraping bots, often stopping automated requests after only a few attempts by showing error pages or triggering Amazon CAPTCHA challenges:
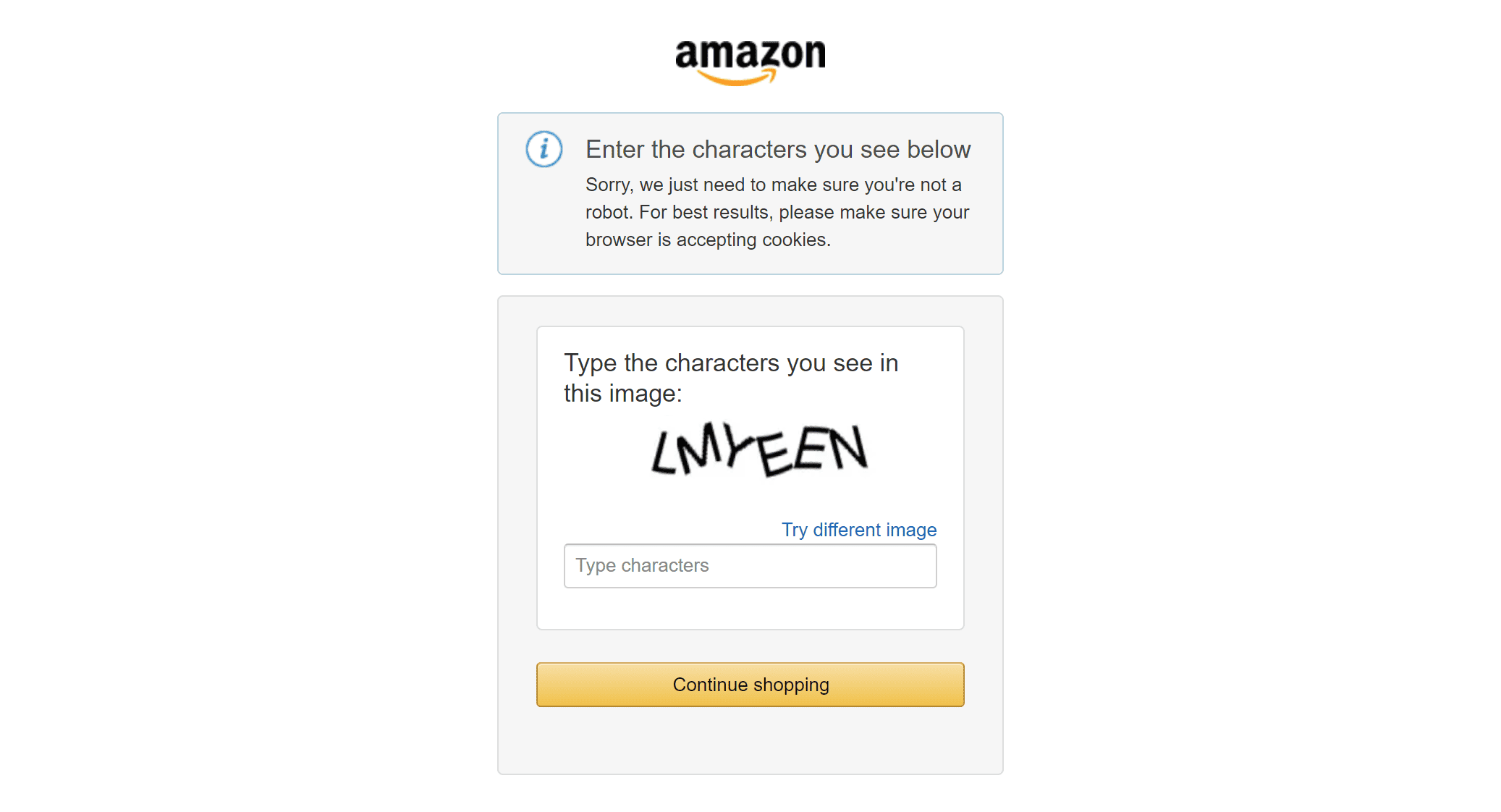
Taken together, these challenges make it much more practical to rely on a cloud-based Amazon scraper accessible via API. Such a service handles IP rotation, CAPTCHA solving, and - most importantly - manages edge cases and ongoing maintenance for you.
How to scrape Amazon product data via API in Python
In this step-by-step section, you’ll see how to use an Apify Actor to scrape Amazon via API. If you’re not familiar, an Apify Actor is a cloud-based scraper that runs on the Apify platform.
Apify currently offers over 960 Actors for Amazon scraping. Here, you’ll see how to connect to one of those Actors via API to programmatically scrape Amazon product data in a Python script.
Prerequisites
To follow this tutorial, make sure you have:
- An Apify account
- Basic understanding of how Apify Actors work when called via API
This tutorial uses Python for scraping Amazon product data, so you’ll also need:
- Python 3.10+ installed on your machine
- A Python IDE (e.g., Visual Studio Code with the Python extension or PyCharm)
- Familiarity with Python syntax
1. Python project setup
If you don’t already have a Python project set up, follow these steps to create one.
Begin by creating a new folder for your Amazon product data scraper:
mkdir amazon-product-scraperNavigate into the folder and set up a virtual environment inside it:
cd amazon-product-scraper
python -m venv .venv
Load the project in your Python IDE and create a new file named scraper.py. That’s where you’ll add the API-based scraping logic.
To activate the virtual environment on Windows, run this command in the IDE's terminal:
.venv\Scripts\activateEquivalently, on Linux/macOS, execute:
source .venv/bin/activate2. Select the Actor (Amazon Product Scraper) from Apify Store
To get started with Amazon product data scraping via API, log in to your Apify account (or sign up for free if you don't have one), reach Apify Console, and select Apify Store from the left-hand menu:
On Apify Store, search for “Amazon” and press Enter:
As you can see, there are over 960 Amazon scraping Actors available. Since you’re specifically interested in product data, select Amazon Product Scraper:
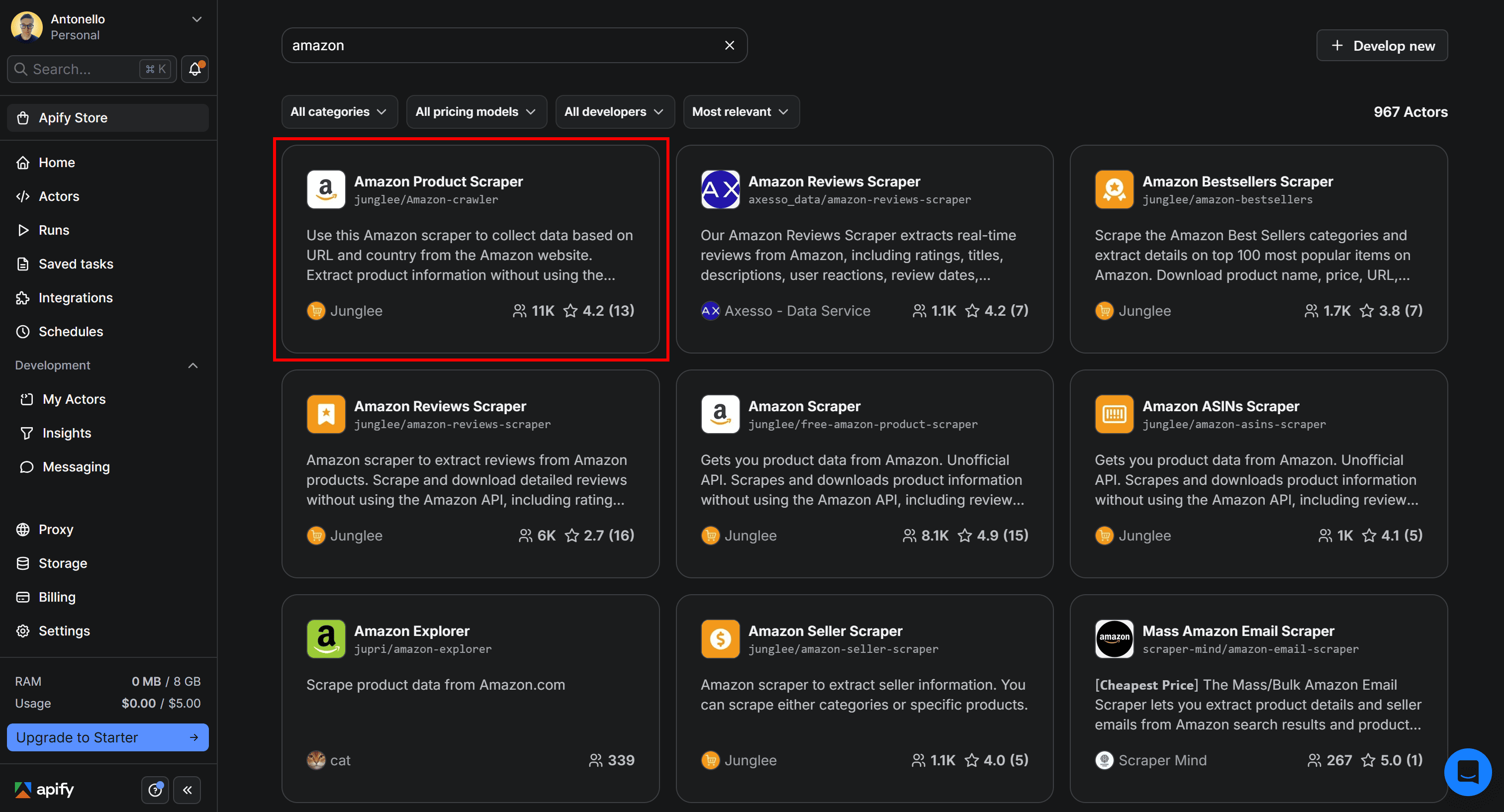
You’ll then be redirected to the Actor page for the Amazon Product Scraper Actor:
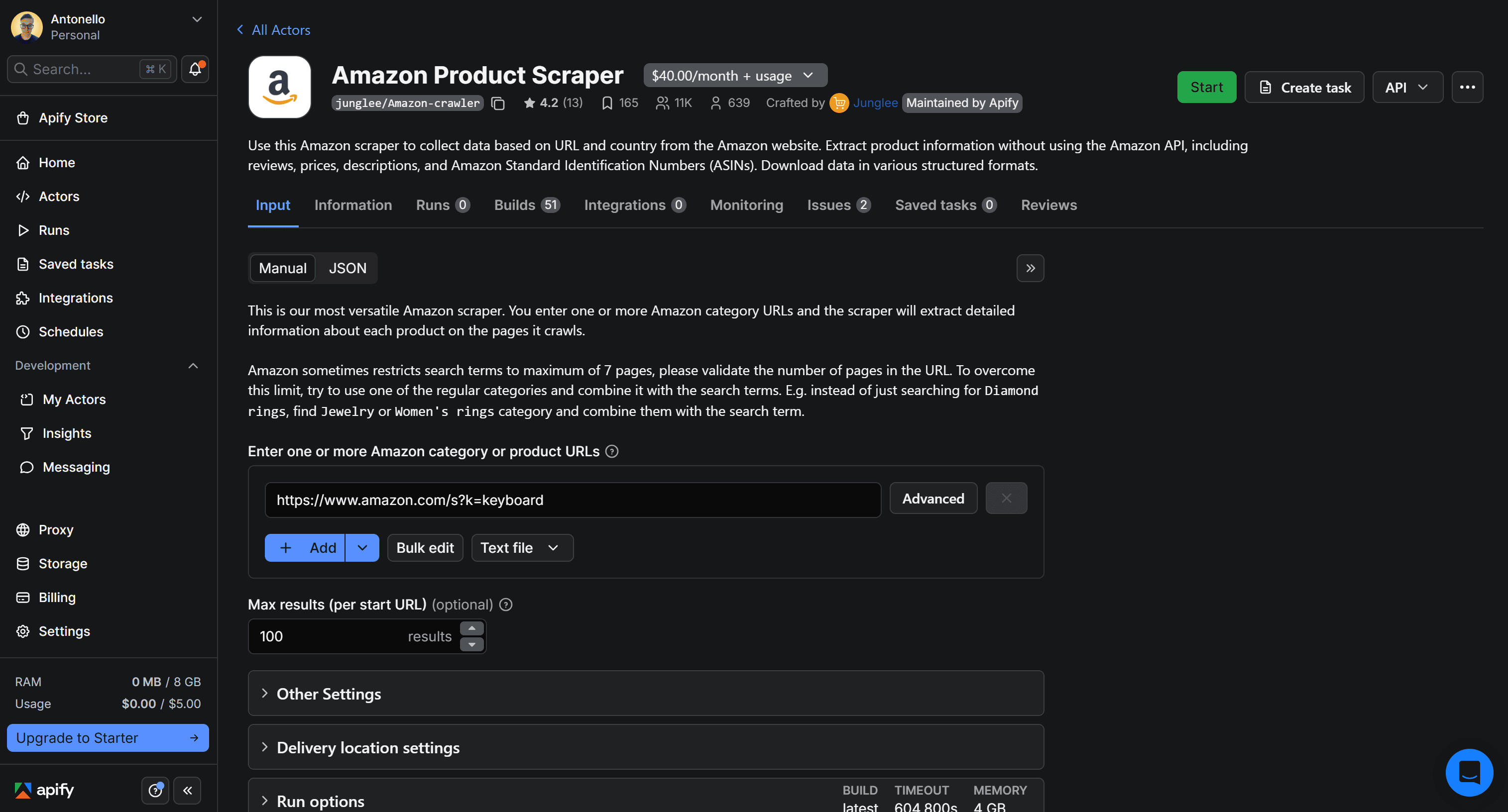
3. Test the scraper with the UI (no code needed)
The goal of this scraping tutorial is to retrieve Amazon product data via API, through an Apify Actor. But before doing that, let’s first test the chosen Actor in Apify Console to make sure it works as expected.
First, click the Start button to begin renting the Actor:

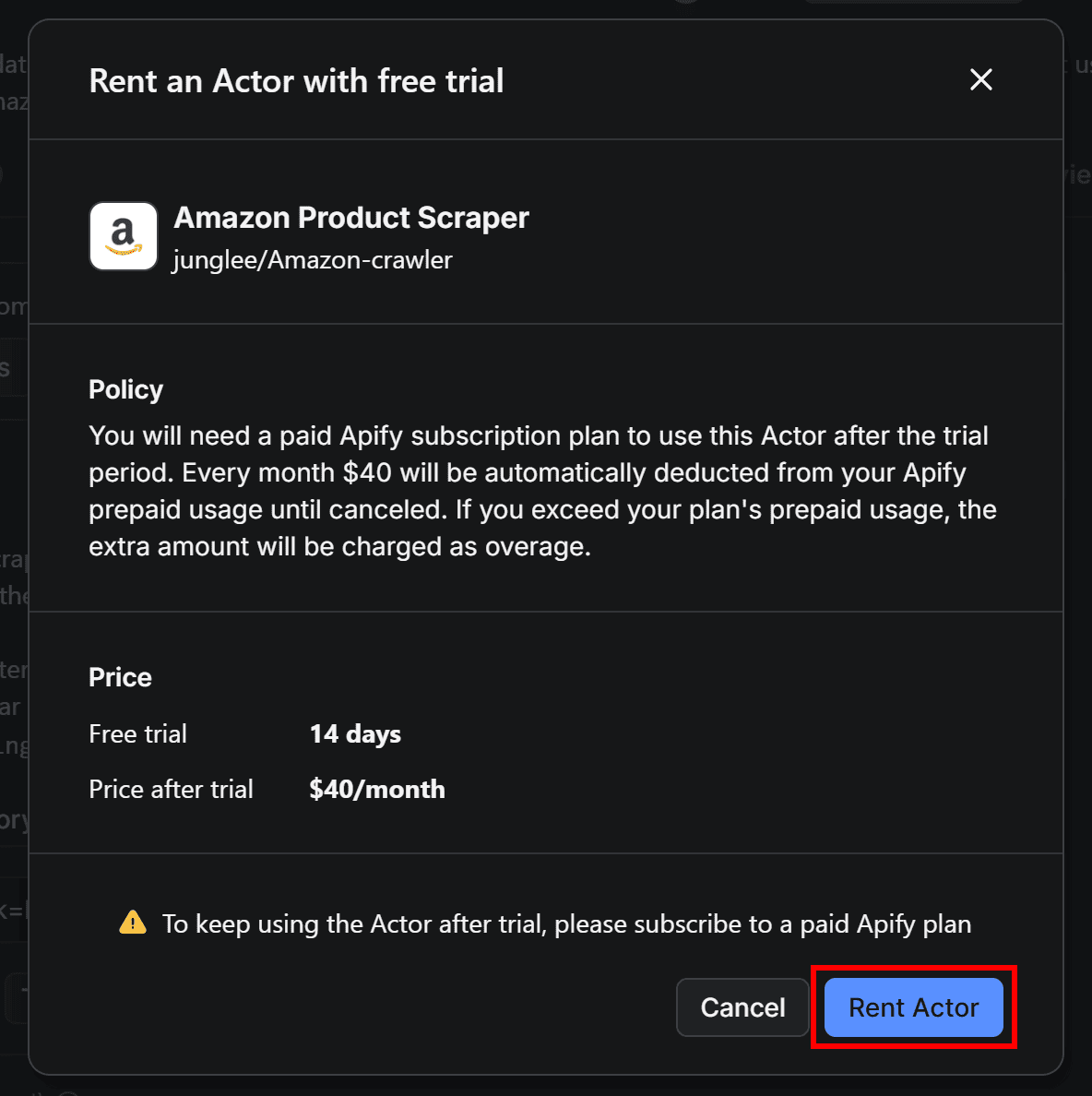
Then, confirm by pressing the Rent Actor button:
You’ll now be able to launch the Actor directly in Apify Console by clicking Save & Start:
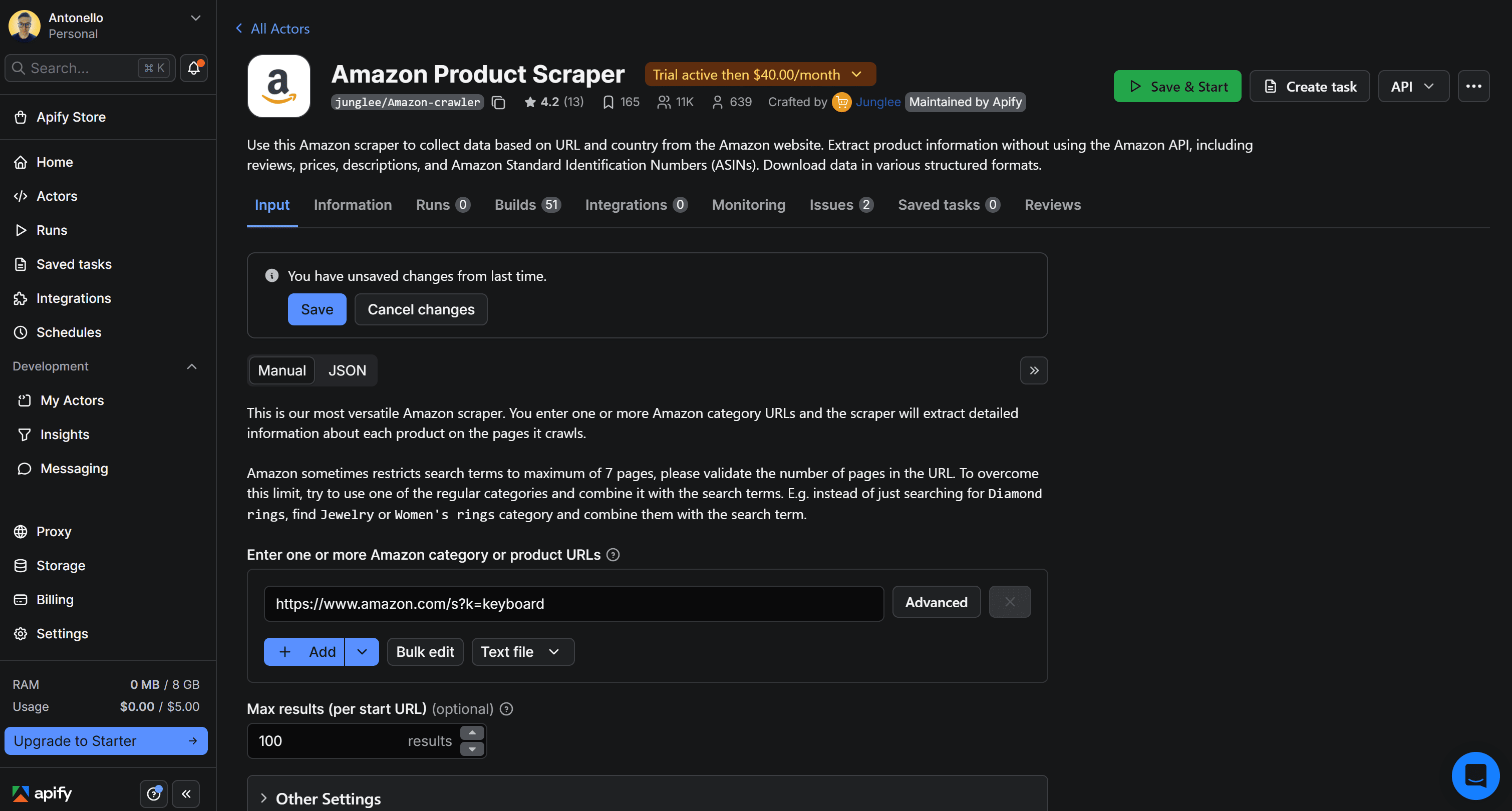
Before doing so, configure the Actor with a specific product URL. For example, enter the URL of the Nintendo Switch 2 Amazon product page in the Enter one or more Amazon category or product URLs input field. Then, click Save & Start to launch the Actor:
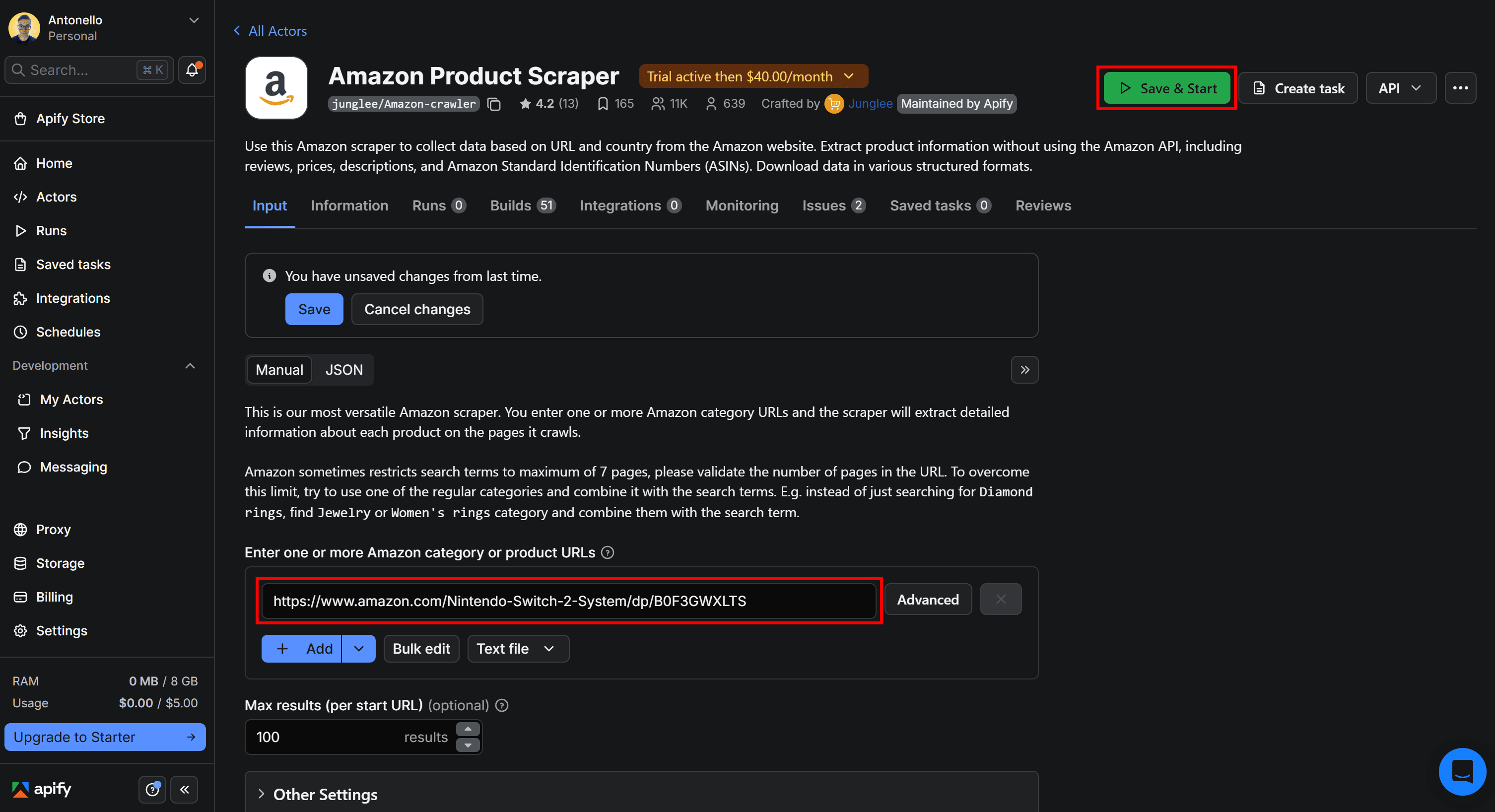
This is what you should see:
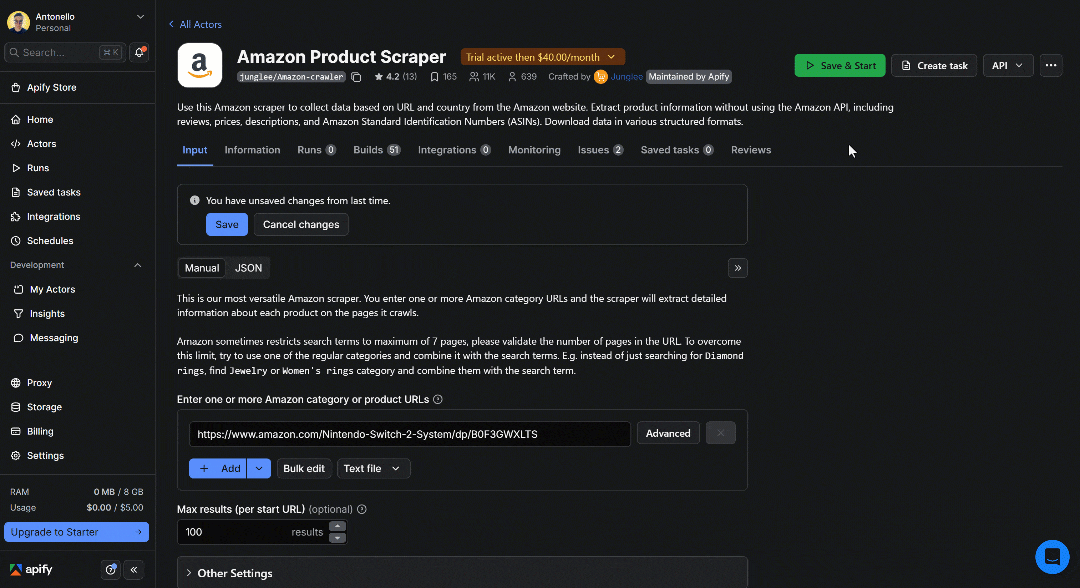
Once the Actor finishes, you’ll view the scraped product data in the Output tab. The table displays exactly the product information extracted from the provided URL. For a closer look, switch to the All fields view and scroll horizontally through the table row:
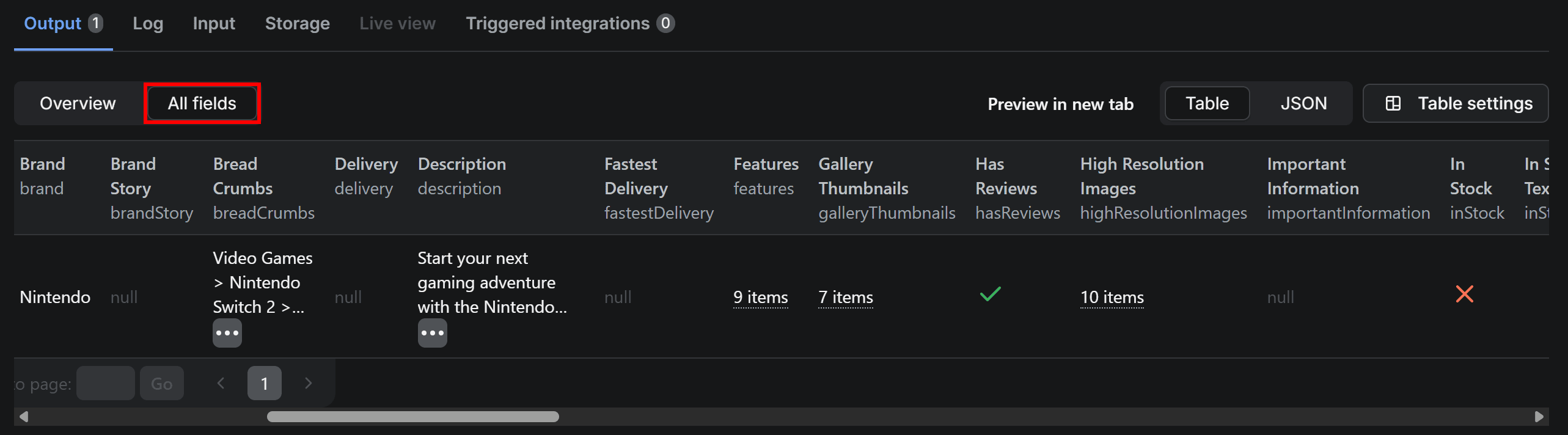
All the data in the table's row matches what’s shown on the Nintendo Switch 2 Amazon product page:
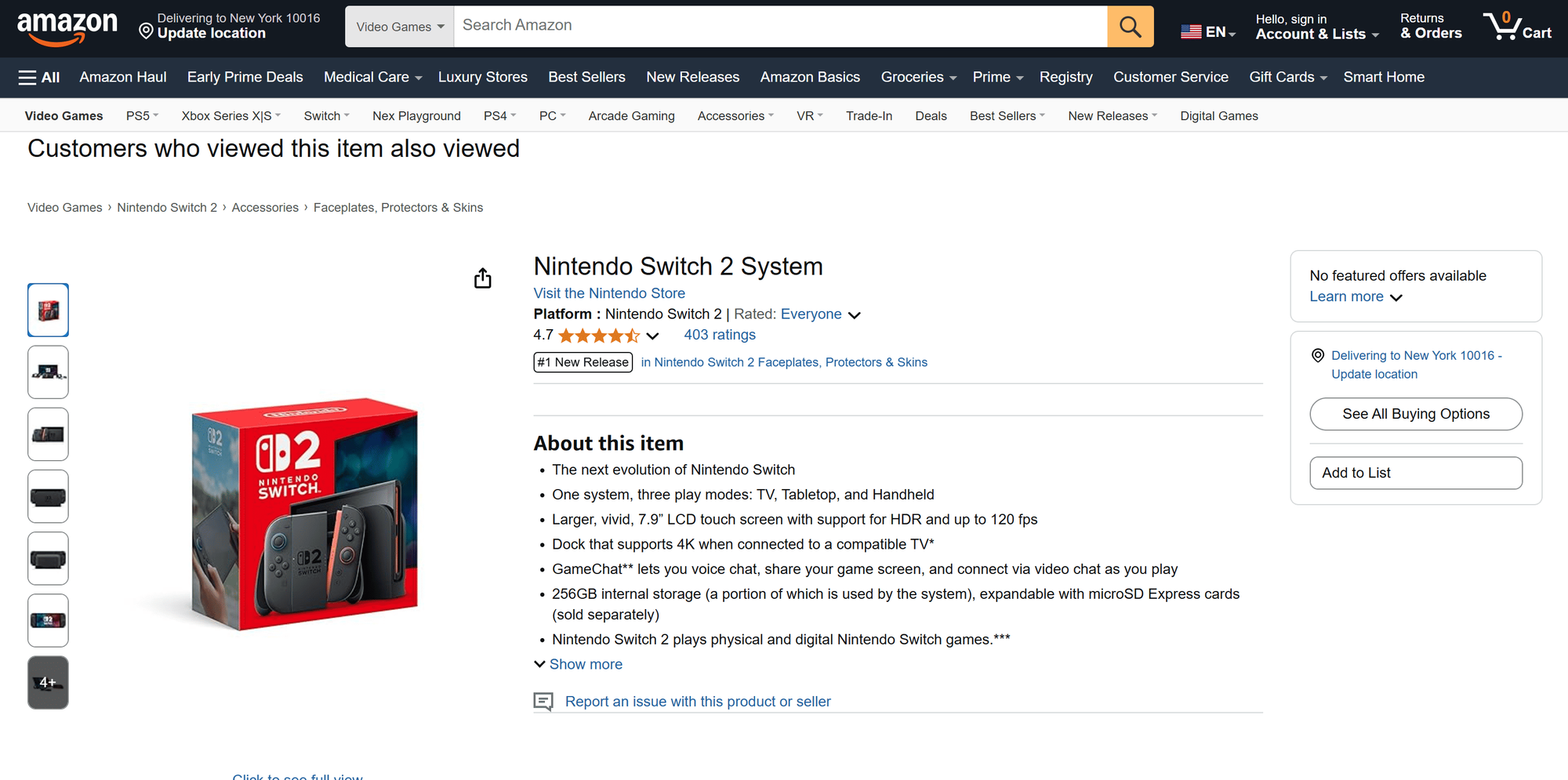
As you can see, Amazon Product Scraper works perfectly and retrieves product data as intended. This is a no-code approach to Amazon product scraping.
4. Set up the API integration
Now that you’ve confirmed the Actor works correctly, it’s time to configure it so you can call it via API.
On the Amazon Product Scraper page, open the API dropdown in the top-right corner and select the API clients option:
This will open the following modal:
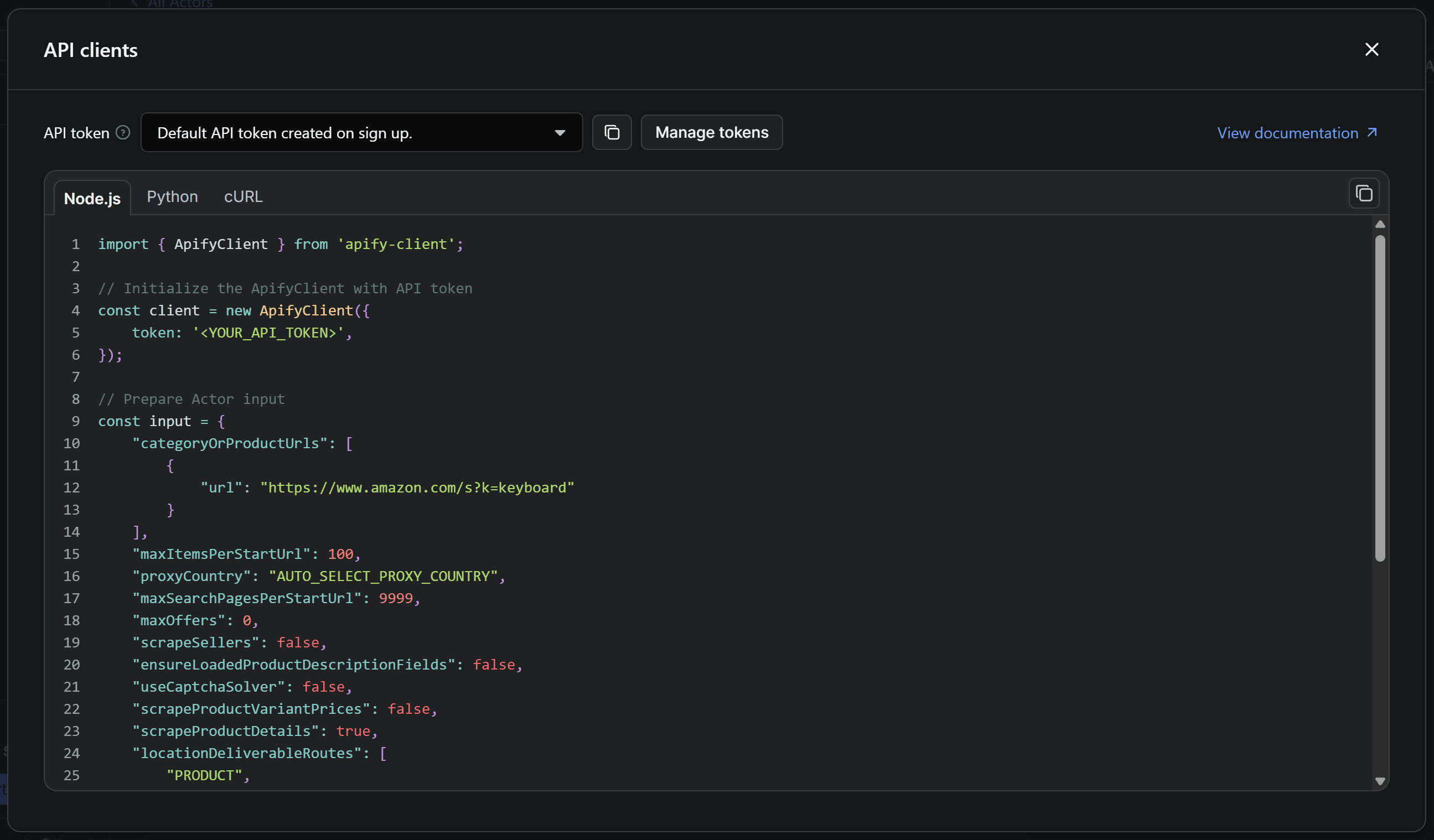
The modal provides a ready-to-use code snippet for calling the selected Actor via API with the Apify API client. By default, it displays the Node.js version of the snippet. Since you’ll be working in Python, switch to the Python tab:
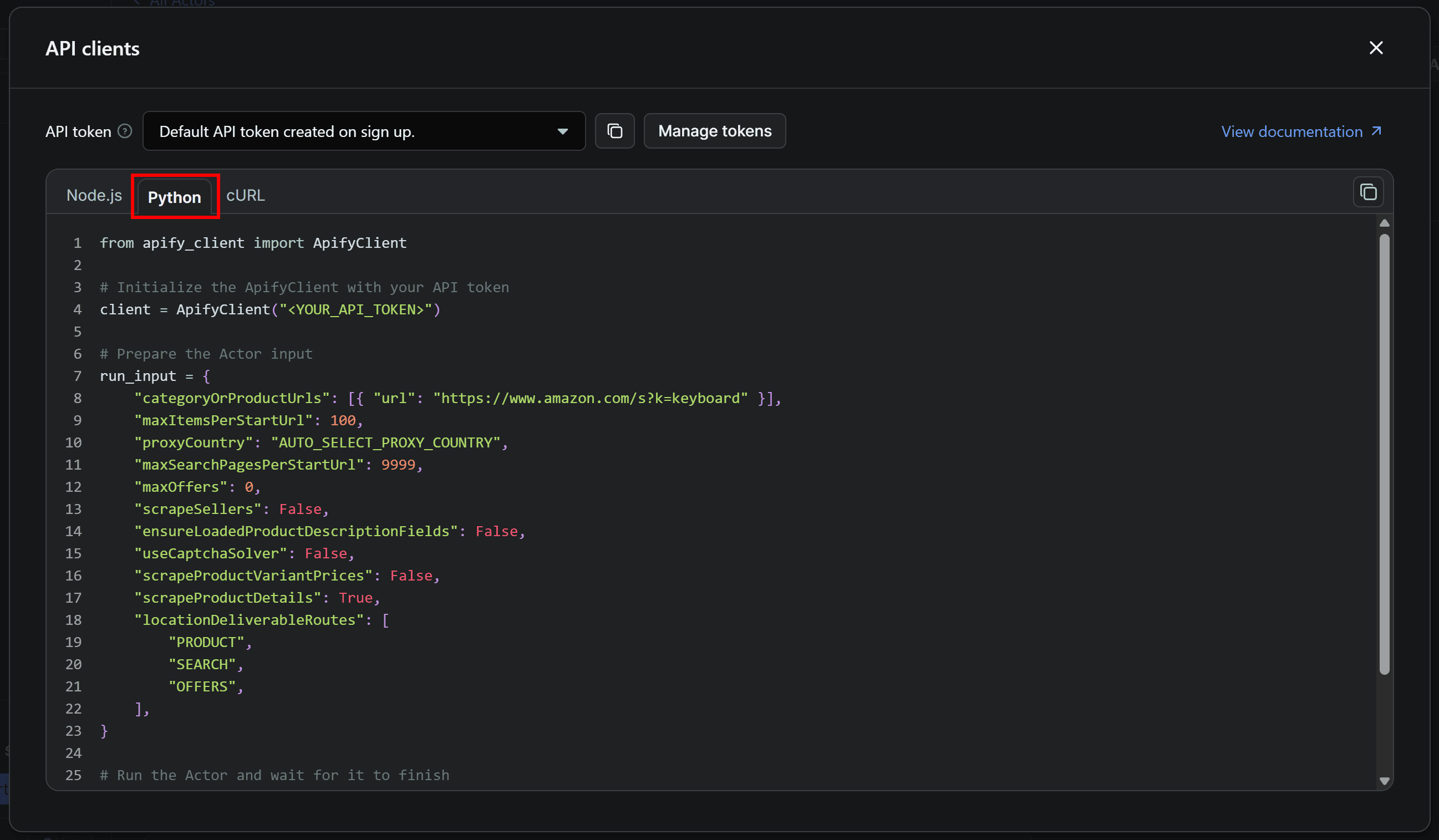
Finally, copy the Python snippet and paste it into your scraper.py file. Keep the modal open, as we’ll come back to it shortly.
5. Prepare your Python script for Amazon product data scraping integration
If you look at the code snippet copied from Apify Console, you’ll see it relies on the apify-client Python library. To install it, in your activated virtual environment, run:
pip install apify_client
In the snippet, you’ll also notice a placeholder for your Apify API token. That's a secret required to authenticate API calls made by the Apify API client.
The best practice is to never hard-code secrets directly in your code. Instead, you should store them in environment variables. To do that, we’ll use the python-dotenv library, which lets you load environment variables from a .env file.
In your activated environment, install it with:
pip install python-dotenv
Next, create a .env file in your project’s root folder. Your project should look like this:
amazon-product-scraper/
├── .venv/
├── .env # <-----
└── scraper.py
Add the APIFY_API_TOKEN environment variable to the .env file:
APIFY_API_TOKEN="YOUR_APIFY_API_TOKEN"
"YOUR_APIFY_API_TOKEN" is just a placeholder for your Apify API token. You’ll see how to retrieve the actual value and set it in the next step.
Now, update scraper.py to load environment variables from .env and read the APIFY_API_TOKEN env:
from dotenv import load_dotenv
import os
# Load environment variables from .env file
load_dotenv()
# Read the required env
APIFY_API_TOKEN = os.getenv("APIFY_API_TOKEN")
The load_dotenv() function loads envs from the .env file, and os.getenv() lets you read them in your code.
Finally, pass the Apify API token to the client constructor:
client = ApifyClient(APIFY_API_TOKEN)
# ...
Your Amazon scraper is now properly configured for secure authentication.
6. Retrieve and set your Apify API token
The next step is to retrieve your Apify API token and add it to your .env file. This is the final piece needed to complete the Amazon scraping integration.
Back in the Amazon Product Scraper's API clients modal, click the Manage tokens button:
You’ll be redirected to the API & Integrations tab of the Settings page. Here, click the Copy to clipboard icon on the Default API token created on sign up section:
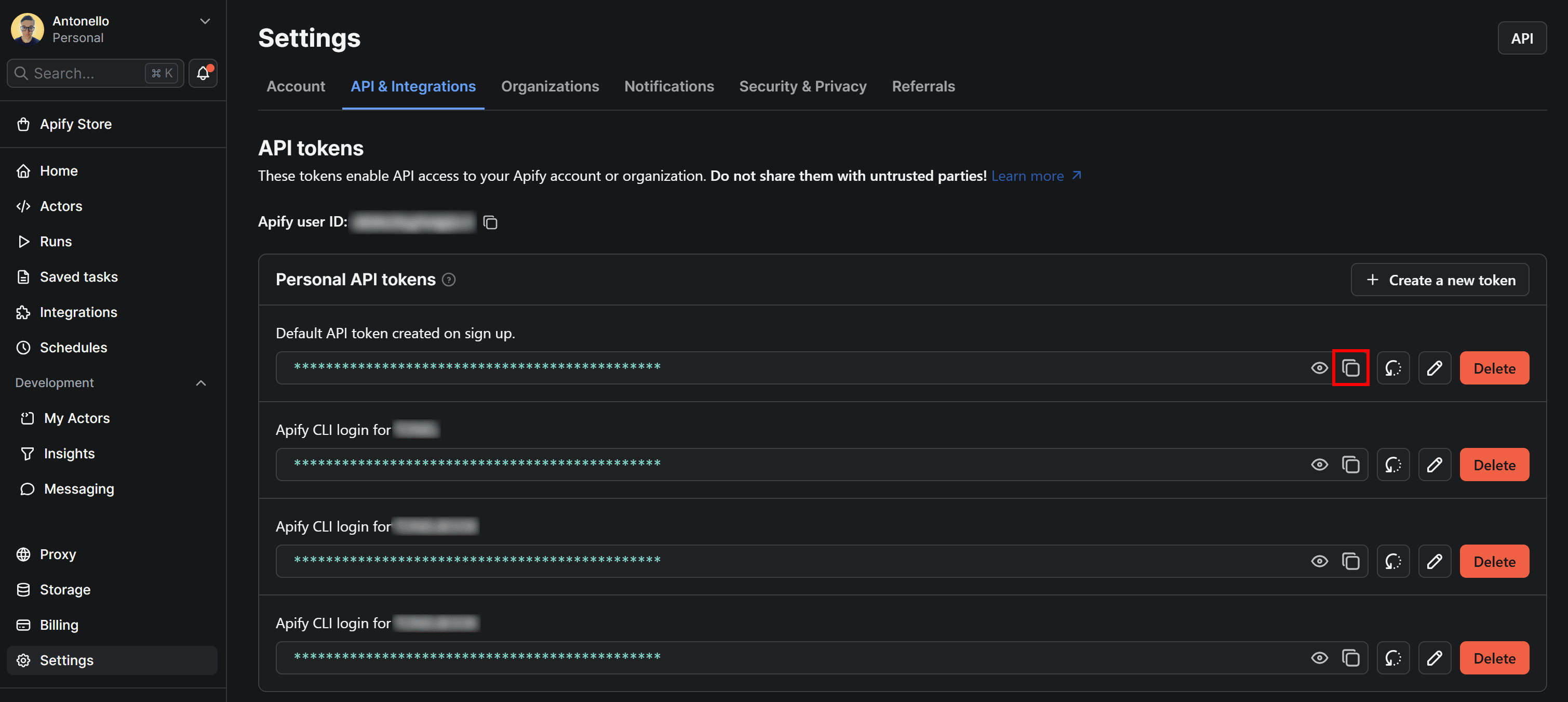
Now, paste the token into your .env file like this:
APIFY_API_TOKEN="PASTE_YOUR_TOKEN_HERE"
Be sure to replace PASTE_YOUR_TOKEN_HERE with the actual token you just copied.
7. Complete code
Below's the complete scraper.py Python script that scrapes Amazon product data by calling an Actor via the Apify API:
from apify_client import ApifyClient
from dotenv import load_dotenv
import os
# Load environment variables from .env file
load_dotenv()
# Read the required env
APIFY_API_TOKEN = os.getenv("APIFY_API_TOKEN")
# Initialize the ApifyClient with your API token
client = ApifyClient(APIFY_API_TOKEN)
# Prepare the Actor input
run_input = {
"categoryOrProductUrls": [{ "url": "https://www.amazon.com/s?k=keyboard" }],
"maxItemsPerStartUrl": 100,
"proxyCountry": "AUTO_SELECT_PROXY_COUNTRY",
"maxSearchPagesPerStartUrl": 9999,
"maxOffers": 0,
"scrapeSellers": False,
"ensureLoadedProductDescriptionFields": False,
"useCaptchaSolver": False,
"scrapeProductVariantPrices": False,
"scrapeProductDetails": True,
"locationDeliverableRoutes": [
"PRODUCT",
"SEARCH",
"OFFERS",
],
}
# Run the Actor and wait for it to finish
run = client.actor("BG3WDrGdteHgZgbPK").call(run_input=run_input)
# Fetch and print Actor results from the run's dataset (if there are any)
for item in client.dataset(run["defaultDatasetId"]).iterate_items():
print(item)
Instead, your .env file should look like this:
APIFY_API_TOKEN="apify_api_XXXXXXXXXXXXXXXXXXXXX"
The run_input object defines the configuration supported by the Actor, as well as the input Amazon product page URLs. In the example above, the input is the “keyboard” search results page on Amazon, and the output is limited to 100 products.
For a simpler configuration, you can set up the Actor directly in the Input tab of Apify Console. Then, click the JSON button to see the configuration in JSON format:
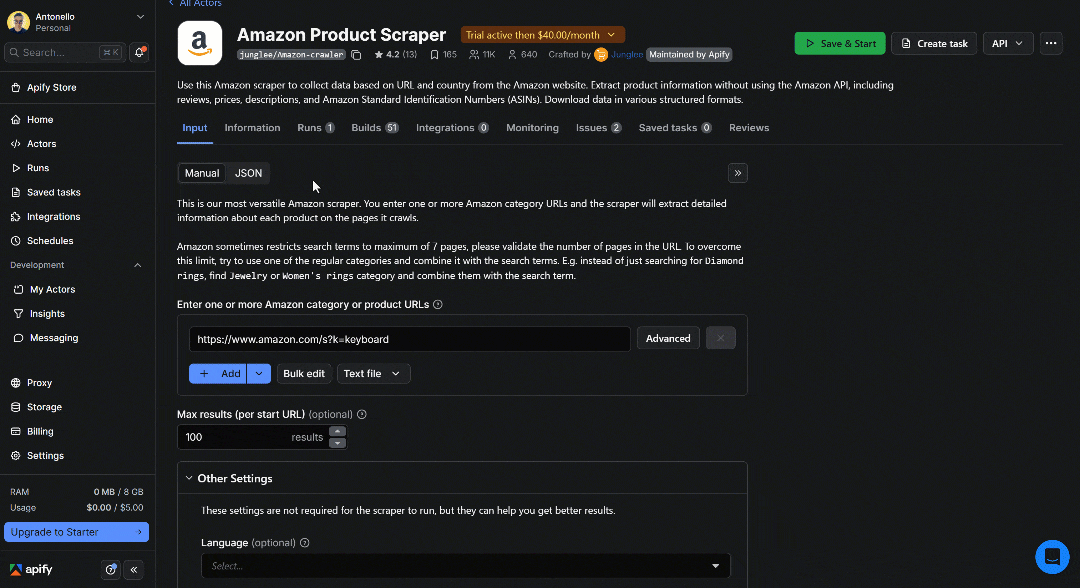
That JSON can easily be converted into a Python run_input object.
Run the Amazon product data scraping script with:
python scraper.py
The execution may take a while, so be patient.
In the terminal, after the execution logs, you should see an output like this:
[
{
"title": "Retro Wireless Keyboard with Round Keycaps, 2.4GHz Full-Size USB Cute Wireless Keyboard Mouse for Computer, Desktop, Laptop and Computer (Pink-Colorful)",
"url": "https://www.amazon.com/dp/B0D7H2FXG5",
"asin": "B0D7H2FXG5",
"originalAsin": "B0D7H2FXG5",
"price": {
"value": 19.99,
"currency": "$"
},
"inStock": true,
"inStockText": "In Stock",
"listPrice": null,
"brand": "XISOGUU",
"author": null,
"shippingPrice": null,
"stars": 4.2,
// Omitted for brevity...
},
// 98 remaining products...
{
"title": "TECKNET Gaming Keyboard, USB Wired Computer Keyboard, 15-Zone RGB Illumination, IP32 Water Resistance, 25 Anti-ghosting Keys, All-Metal Panel (Whisper Quiet Gaming Switch)",
"url": "https://www.amazon.com/dp/B0D17C3ZVJ",
"asin": "B0D17C3ZVJ",
"originalAsin": "B0D17C3ZVJ",
"price": {
"value": 29.89,
"currency": "$"
},
"inStock": true,
"inStockText": "In Stock Only 2 left in stock - order soon.",
"listPrice": {
"value": 39.99,
"currency": "$"
},
"brand": "TECKNET",
"author": null,
"shippingPrice": null,
"stars": 4.4,
// Omitter for brevity...
}
]In detail, the script will return up to 100 Amazon products that match the keyword search. These correspond to the products shown on the search results page on Amazon. The output contains the same product details you see on that page, but in a structured format.
Once the run completes, the dataset is available in your Apify account for 6 days by default. You can find it under the Storage > Datasets section of your account:
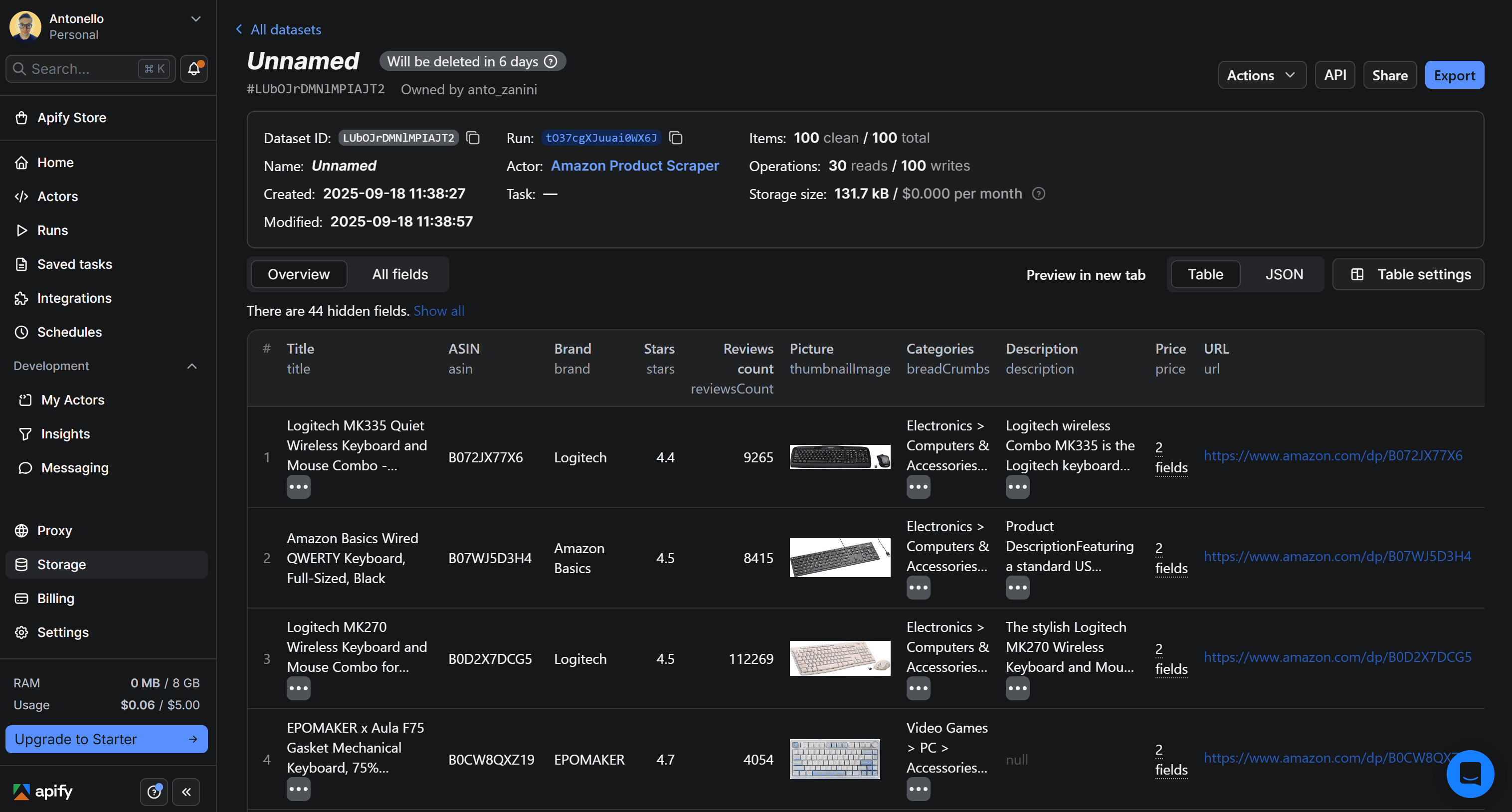
You can view the results in tabular format or as raw JSON, and export the dataset to several formats.
Et voilà! Your scraper is ready.
Next steps
This tutorial has walked you through the basics of scraping Amazon product information via the Apify API. To take your scraper to the next level, consider these advanced techniques:
- Data export: Save the scraped data to a JSON file or store it in a database for later analysis.
- Data analysis: Process and visualize the data retrieved from Amazon using Python’s rich ecosystem of data processing and visualization libraries.
- Automated execution: Schedule your Actor to run automatically at regular intervals to keep your data up-to-date, leveraging the
ScheduleClientclass.
Conclusion
This project demonstrated how an always-up-to-date Apify Actor makes it possible to collect data from platforms that are otherwise difficult to scrape due to advanced anti-bot protections and constantly changing page structures - just like Amazon.
Feel free to explore other Actors and Apify SDKs to further expand your automation toolkit.
Frequently asked questions
Why scrape Amazon product data?
Scraping Amazon product data allows you to cover several use cases, from monitoring prices and tracking competitors to analyzing customer reviews and gathering product information at scale. That data supports smarter decision-making, dynamic pricing, market research, and many other scenarios.
Is it legal to scrape Amazon product data?
Yes, it's legal to scrape Amazon as long as you only extract publicly available data. Also, be responsible by avoiding excessive requests that could overload or throttle their servers.
How to scrape Amazon product data in Python?
To scrape Amazon product data in Python, considering the high variability of product pages, it’s recommended to rely on a dedicated scraping solution. Such a solution is always up to date to handle all edge cases and deal with anti-bot bypasses for you.




