Playwright is a browser automation library developed and released by Microsoft in 2020. Since then, it has become one of the most popular libraries in automated testing of web applications and general browser automation tasks. However, it also plays a critical role in web scraping, especially in dealing with modern JavaScript-rendered websites where traditional HTML parsing tools like Beautiful Soup fall short.
Playwright's main API was originally written in Node.js, but it supports other languages, including Python, which we're going to use in this blog post.
Setting up your environment
First, let's set up our development environment. The setup process involves a few straightforward steps:
python --version && pip --version
Python 3.12.2
pip 23.3.2 from /home/vdusek/.local/lib/python3.12/site-packages/pip (python 3.12)
- Optionally, create some form of separate Python environment, e.g. by using Virtualenv:
virtualenv --python python3.12 .venv
created virtual environment CPython3.12.2.final.0-64 in 102ms
creator CPython3Posix(dest=/home/vdusek/Projects/playground/python_asyncio_tutorial/.venv, clear=False, no_vcs_ignore=False, global=False)
seeder FromAppData(download=False, pip=bundle, via=copy, app_data_dir=/home/vdusek/.local/share/virtualenv)
added seed packages: pip==24.0
activators BashActivator,CShellActivator,FishActivator,NushellActivator,PowerShellActivator,PythonActivator
source .venv/bin/activate
- Install PyPI packages which we are going to use in this blog post (Playwright, Pytest, and Pytest-Playwright).
pip install \
playwright==1.42.0 \
pytest==8.0.2 \
pytest-playwright==0.4.4
- Run the following command to install the necessary browser binaries.
playwright install
- Check that Playwright is successfully installed:
playwright --version
Version 1.42.0
Your first script with Playwright in Python
Playwright provides capabilities for browser automation that go beyond simple page navigation, including network interception, file downloads, and handling various input types. But before we look at these, let's begin with creating a straightforward synchronous script.
The primary purpose here is to open a browser using Playwright, go to a URL, and extract the website’s title. It's worth mentioning that we don't need a tool like Playwright for such a simple task. However, we're starting with simple examples to help you understand the fundamentals before diving into more complex scenarios.
from time import sleep
from playwright.sync_api import Playwright, sync_playwright
def run(playwright: Playwright, *, url: str) -> dict:
"""This function navigates to a given URL using a browser and returns
the page's URL and title."""
# Launch the Chromium browser in non-headless mode (visible UI) to see
# the browser in action.
browser = playwright.chromium.launch(headless=False)
# Open a new browser page.
page = browser.new_page(viewport={'width': 1600, 'height': 900})
# Short sleep to be able to see the browser in action.
sleep(1)
# Navigate to the specified URL.
page.goto(url)
sleep(1)
# Retrieve the title of the page.
title = page.title()
# Close the browser.
browser.close()
# Return the page's URL and title as a dictionary.
return {'url': url, 'title': title}
def main() -> None:
# Use sync_playwright context manager to close the Playwright instance
# automatically
with sync_playwright() as playwright:
result = run(playwright, url='https://crawlee.dev')
print(result)
if __name__ == '__main__':
main()
Save this script as sync_playwright.py and run it as a script via the terminal:
python sync_playwright.py
{'url': 'https://crawlee.dev', 'title': 'Crawlee · Build reliable crawlers. Fast. | Crawlee'}
Now, let's advance to Playwright’s asynchronous interface.
Playwright's async API and Asyncio
Asynchronous programming can be particularly beneficial when dealing with I/O-bound tasks such as web scraping, as it allows us to do other stuff while waiting for some I/O operation (like waiting for an HTTP response, storing data to the file, and so on).
We'll transform our initial script into an asynchronous version using Playwright's async API and Asyncio, a standard Python library that supports working with asynchronous I/O, event loops, coroutines, and tasks.
If you don’t know much about asynchronous programming or the Asyncio library, check out our Python asyncio tutorial.
import asyncio
from playwright.async_api import Playwright, async_playwright
async def run(playwright: Playwright, *, url: str) -> dict:
"""This function navigates to a given URL using a browser and returns
the page's URL and title."""
# Launch the Chromium browser in non-headless mode (visible UI), to see
# the browser in action.
browser = await playwright.chromium.launch(headless=False)
# Open a new browser page.
page = await browser.new_page(viewport={'width': 1600, 'height': 900})
# Short sleep to be able to see the browser in action.
await asyncio.sleep(1)
# Navigate to the specified URL.
await page.goto(url)
await asyncio.sleep(1)
# Retrieve the title of the page.
title = await page.title()
# Close the browser.
await browser.close()
# Return the page's URL and title as a dictionary.
return {'url': url, 'title': title}
async def main() -> None:
# Use async_playwright context manager to close the Playwright instance
# automatically.
async with async_playwright() as playwright:
result = await run(playwright, url='https://crawlee.dev')
print(result)
if __name__ == '__main__':
asyncio.run(main())
Save the script as async_playwright.py and run it as a script via the terminal:
python async_playwright.py
{'url': 'https://crawlee.dev', 'title': 'Crawlee · Build reliable crawlers. Fast. | Crawlee'}
By converting to asynchronous code, we've managed to maintain the script's efficiency while preparing it for more complex and time-consuming web scraping tasks.
Playwright in Python for browser automation and testing
Now let’s explore how Playwright can be used in Python for automated testing, focusing on its features such as locators and selectors. We'll also create a simple end-to-end testing task on a website, incorporating the Pytest library to write the tests. If you have followed the instructions in the Setting up your environment section, you should have all the packages installed.
Understanding Playwright locators and selectors
Playwright simplifies the identification elements on a web page by using locators and selectors. A selector is a string that identifies a web element, such as text='Login', #username, or .submit-button. Playwright's ability to handle various types of selectors, including CSS, XPath, and text selectors, makes it highly versatile.
Locators, on the other hand, are more powerful abstractions provided by Playwright. They allow you to perform actions or assertions on elements. The beauty of Locators lies in their resilience: they can survive changes in the page's layout or content, making your tests more stable and reliable.
Writing tests with Playwright and Pytest
Let's create a simple test for the Crawlee website. Our objective is to navigate to the site, interact with the "Get Started" button, and confirm that it behaves as expected. For demonstration purposes, we are going to test the “Get Started” button.
To begin, use the browser's developer tools to inspect the "Get Started" button. Take note of its text content, the URL it redirects (href attribute), and CSS styles assigned to it, as these elements will be tested.
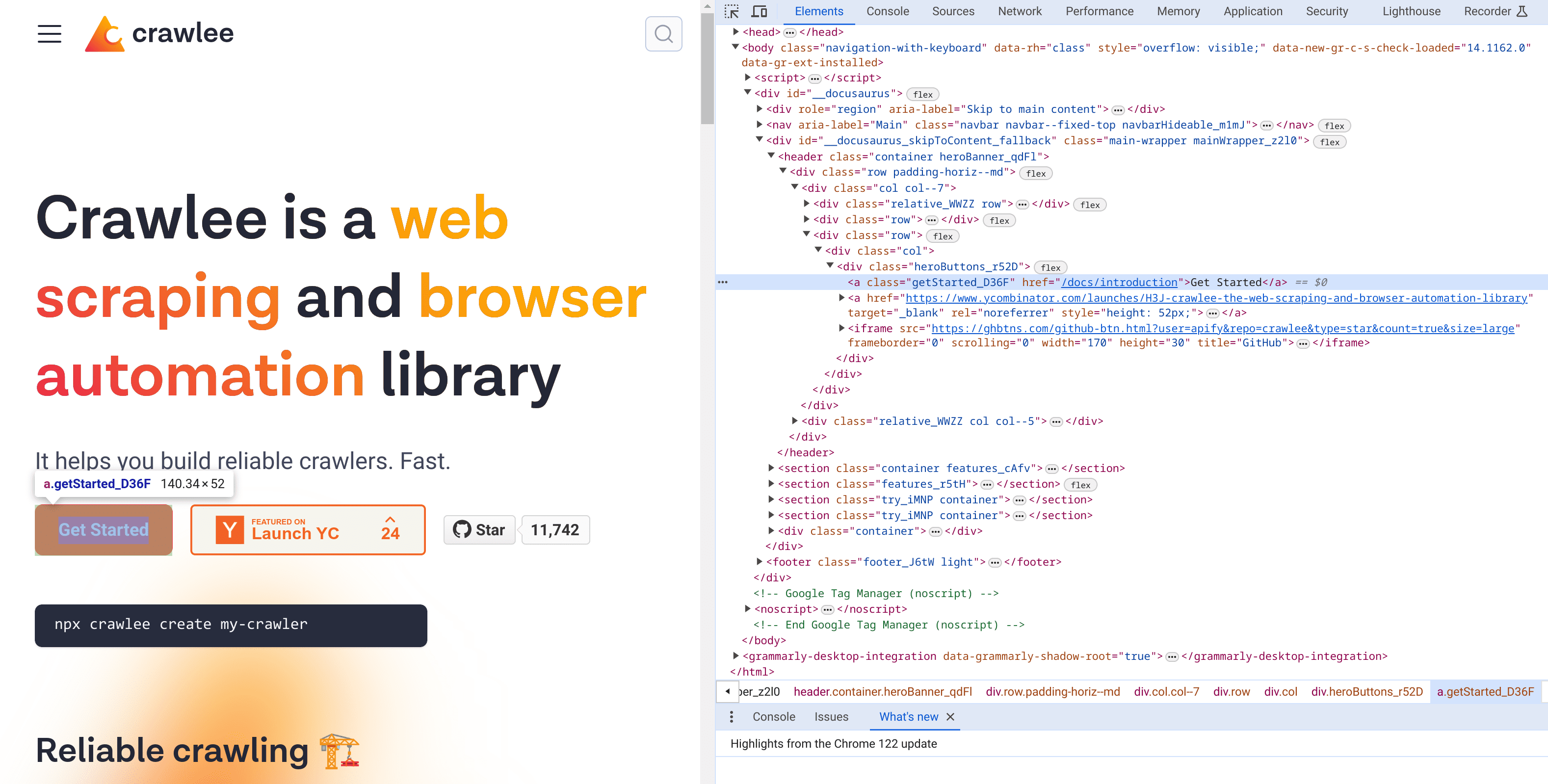
Open dev tools in your browser and inspect the "Get Started" button.
First, create a new Python file named test_crawlee_dev.py. Within this file, define a function test_get_started_button dedicated to validating the functionality and styling of the button. Our test will verify the existence, visibility, and proper hyperlinking of the button, alongside checking its assigned CSS properties.
from playwright.sync_api import Page
def test_get_started_button(page: Page) -> None:
# Navigate to the 'Crawlee' website.
page.goto('https://crawlee.dev')
# Create a locator for the 'Get Started' button on the page.
button = page.locator('text=Get Started')
# Assert that exactly one 'Get Started' button exists.
assert button.count() == 1
# Assert that the button is visible to the user.
assert button.is_visible()
# Assert that the button is enabled and can be clicked or interacted with.
assert button.is_enabled()
# Assert the button's href attribute points to the expected URL path.
assert button.get_attribute('href') == '/docs/introduction'
# Validate the button's CSS styling to ensure it matches the expected design.
assert button.evaluate('el => window.getComputedStyle(el).backgroundColor') == 'rgb(237, 53, 69)'
assert button.evaluate('el => window.getComputedStyle(el).borderRadius') == '8px'
assert button.evaluate('el => window.getComputedStyle(el).color') == 'rgb(255, 255, 255)'
assert button.evaluate('el => window.getComputedStyle(el).fontSize') == '18px'
assert button.evaluate('el => window.getComputedStyle(el).fontWeight') == '600'
assert button.evaluate('el => window.getComputedStyle(el).lineHeight') == '28px'
assert button.evaluate('el => window.getComputedStyle(el).padding') == '12px 24px'
Playwright’s Page object is supplied through the Pytest-Playwright plugin. It allows test environment isolated interaction within the website. Leveraging Playwright's cross-browser testing capabilities, we can easily evaluate our web application across multiple browsers using the same test script. Execute the test with the Pytest command below to see it run in Chromium, Firefox, and Webkit (Safari).
pytest test_crawlee_dev.py \
--verbose \
--browser chromium \
--browser firefox \
--browser webkit
In the output, we can see the results. Our single testing function was executed 3 times - for every browser we specified.
============================================================= test session starts =============================================================
platform linux -- Python 3.12.2, pytest-8.0.2, pluggy-1.4.0 -- /home/vdusek/Projects/playground/.venv/bin/python
cachedir: .pytest_cache
rootdir: /home/vdusek/Projects/playground
plugins: anyio-4.3.0, base-url-2.1.0, playwright-0.4.4
asyncio: mode=Mode.STRICT
collected 3 items
test_crawlee_dev.py::test_get_started_button[chromium] PASSED [ 33%]
test_crawlee_dev.py::test_get_started_button[firefox] PASSED [ 66%]
test_crawlee_dev.py::test_get_started_button[webkit] PASSED [100%]
============================================================== 3 passed in 6.90s ============================================================== [100%]
Additionally, there is a Pytest-Asyncio plugin that enables you to write asynchronous tests using Asyncio. However, this is beyond the scope of this article.
Python Playwright for web scraping
Now let’s utilize Playwright for web scraping. While tools like Beautiful Soup are great for static content, they fall short when dealing with dynamic content generated by executing JavaScript code. For these cases, Playwright is your best bet since you can automate browser interactions to scrape dynamic web content.
You can use Playwright to operate real browsers, click buttons, press keyboard keys, and execute JavaScript, just like in a regular browsing session. This makes it ideal for scraping data from websites that rely on JavaScript to render their content, such as modern web applications or pages with significant user interaction.
For our demonstration task, we're going to scrape Nike products from their official website. Specifically men’s shoes.
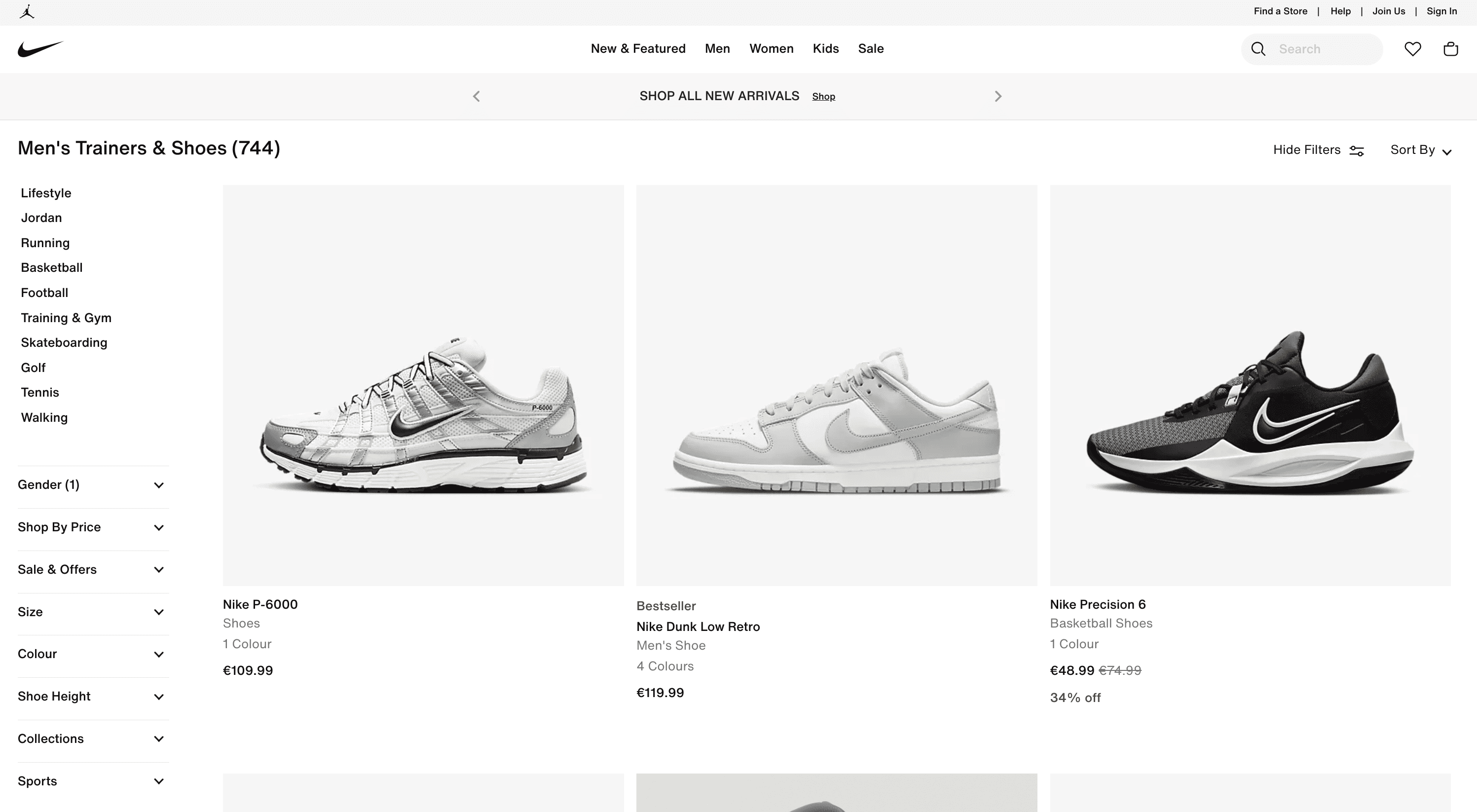
Using Playwright to scrape dynamically loaded content
As you scroll down the page, you'll observe that additional shoes are continuously loaded. This is an example of the concept of infinite scrolling. During this process, the website initiates more requests as you navigate, particularly when you scroll downwards. In the context of our scraping project, we aim to extract all product data from this dynamically loading content.
Let’s use the same code structure we used at the beginning of this article.
import asyncio
from playwright.async_api import Playwright, async_playwright
async def scrape_nike_shoes(playwright: Playwright, url: str) -> None:
# Launch the Chromium browser in non-headless mode (visible UI), to see
# the browser in action.
browser = await playwright.chromium.launch(headless=False)
# Open a new browser page.
page = await browser.new_page(viewport={'width': 1600, 'height': 900})
# Short sleep to be able to see the browser in action.
await asyncio.sleep(1)
# Navigate to the specified URL.
await page.goto(url)
# TODO
await asyncio.sleep(1)
# Close the browser.
await browser.close()
async def main() -> None:
async with async_playwright() as playwright:
await scrape_nike_shoes(
playwright=playwright,
url='https://www.nike.com/cz/en/w/mens-shoes-nik1zy7ok',
)
if __name__ == '__main__':
asyncio.run(main())
Let's execute our script now. By utilizing the non-headless mode, we will see Playwright launching the browser and navigating to the Nike website. Shortly thereafter, a cookie consent popup will appear. To continue, we'll need to click on the "Accept All" button to remove this popup and proceed further.
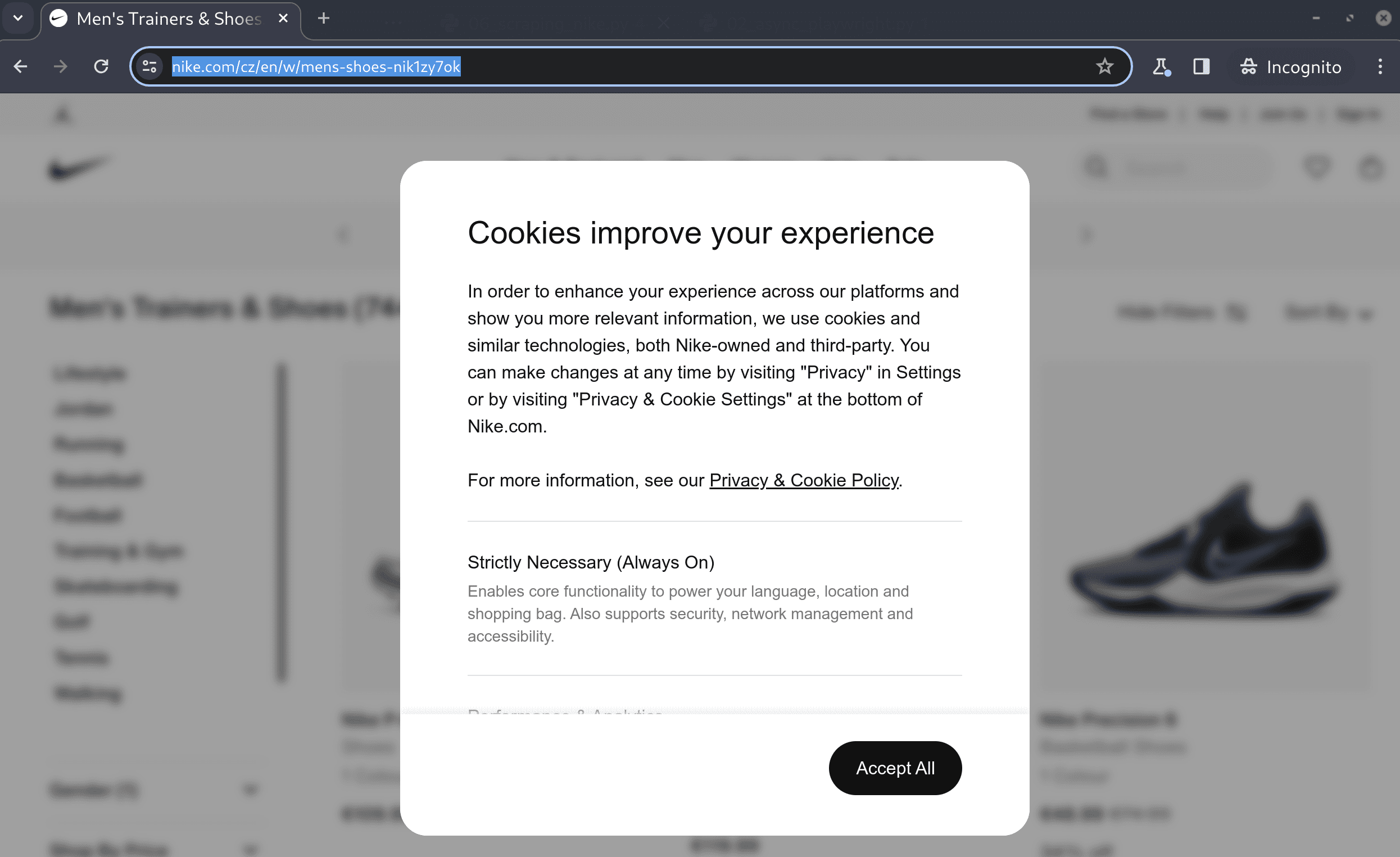
So let’s make Playwright click on the "Accept All" button. We can inspect the page, but in this case, it would be enough to identify the element just by the text “Accept All”.
# Click the "Accept All" button to accept the cookies.
await page.click('text=Accept All')
In our scraping script, we aim to ensure that all products are loaded by navigating to the bottom of the webpage. We can reach this goal by executing JavaScript code, which will command the browser to scroll to the page's bottom. To start, we'll perform this action once.
# Scroll to the bottom of the page.
await page.evaluate('window.scrollTo(0, document.body.scrollHeight);')
await asyncio.sleep(1)
When we run the script, we observe that Playwright successfully scrolls to the bottom of the page. However, as new content loads dynamically, we need to scroll multiple times to reach the true bottom. To address this, let's create a dedicated helper function named scroll_to_bottom. This function will repeatedly scroll the page until there is no more new content to load, ensuring we have reached the absolute end of the page.
async def scroll_to_bottom(page: Page) -> None:
# Get the initial scroll height
last_height = await page.evaluate('document.body.scrollHeight')
i = 1
while True:
print(f'Scrolling page ({i})...')
# Scroll to the bottom of the page.
await page.evaluate('window.scrollTo(0, document.body.scrollHeight);')
# Wait for the page to load.
await asyncio.sleep(1)
# Calculate the new scroll height and compare it with the last scroll height.
new_height = await page.evaluate('document.body.scrollHeight')
if new_height == last_height:
break # Exit the loop when the bottom of the page is reached.
last_height = new_height
i += 1
After implementing this scrolling functionality, execute the script once more. During this process, you may notice a new advertisement popup. Take a moment to inspect this popup and identify an element that can be used to close it, typically a button. In our current scenario, the close button can be recognized by its class name .bluecoreCloseButton. We'll make our script to await this specific selector's presence before proceeding to click the close button, dismissing the advertisement.
Here's the code snippet:
# Wait for the popup to be visible to ensure it has loaded on the page.
await page.wait_for_selector('.bluecoreCloseButton')
# Click on the close button of the advertisement popup.
await page.click('.bluecoreCloseButton')
When we run the script, it will first handle the cookie consent popup by closing it. Subsequently, the browser will systematically scroll down the page multiple times. Finally, the script will detect and close any advertisement popup that appears. Now we should have the page loaded with all the data we want.
import asyncio
from playwright.async_api import Page, Playwright, async_playwright
async def scroll_to_bottom(page: Page) -> None:
# Get the initial scroll height
last_height = await page.evaluate('document.body.scrollHeight')
i = 1
while True:
print(f'Scrolling page ({i})...')
# Scroll to the bottom of the page.
await page.evaluate('window.scrollTo(0, document.body.scrollHeight);')
# Wait for the page to load.
await asyncio.sleep(1)
# Calculate the new scroll height and compare it with the last scroll height.
new_height = await page.evaluate('document.body.scrollHeight')
if new_height == last_height:
break # Exit the loop when the bottom of the page is reached.
last_height = new_height
i += 1
async def scrape_nike_shoes(playwright: Playwright, url: str) -> None:
# Launch the Chromium browser in non-headless mode (visible UI), to see
# the browser in action.
browser = await playwright.chromium.launch(headless=False)
# Open a new browser page.
page = await browser.new_page(viewport={'width': 1600, 'height': 900})
await asyncio.sleep(1)
# Navigate to the specified URL.
await page.goto(url)
await asyncio.sleep(1)
# Click the "Accept All" button to accept the cookies.
await page.click('text=Accept All')
await asyncio.sleep(1)
# Scroll to the bottom of the page to load all the products.
await scroll_to_bottom(page)
# Wait for the popup to be visible to ensure it has loaded on the page.
await page.wait_for_selector('.bluecoreCloseButton')
# Click on the close button of the advertisement popup.
await page.click('.bluecoreCloseButton')
# TODO: extract data
await asyncio.sleep(1)
# Close the browser.
await browser.close()
async def main() -> None:
async with async_playwright() as playwright:
await scrape_nike_shoes(
playwright=playwright,
url='https://www.nike.com/cz/en/w/mens-air-max-lifestyle-shoes-13jrmza6d8hznik1zy7ok',
)
if __name__ == '__main__':
asyncio.run(main())
Playwright's network events feature
At this point, you need to understand what's happening under the hood.
Each time we scroll down, the browser sends a series of HTTP requests to fetch new data, which is then rendered on the page. As our goal is to extract this data, we can streamline the process by directly intercepting these requests rather than reading the information from the HTML.
To pinpoint the exact requests we need to monitor, we'll revisit the browser's dev tools. Open the 'Network' tab and scroll through the page to trigger the data-loading requests.
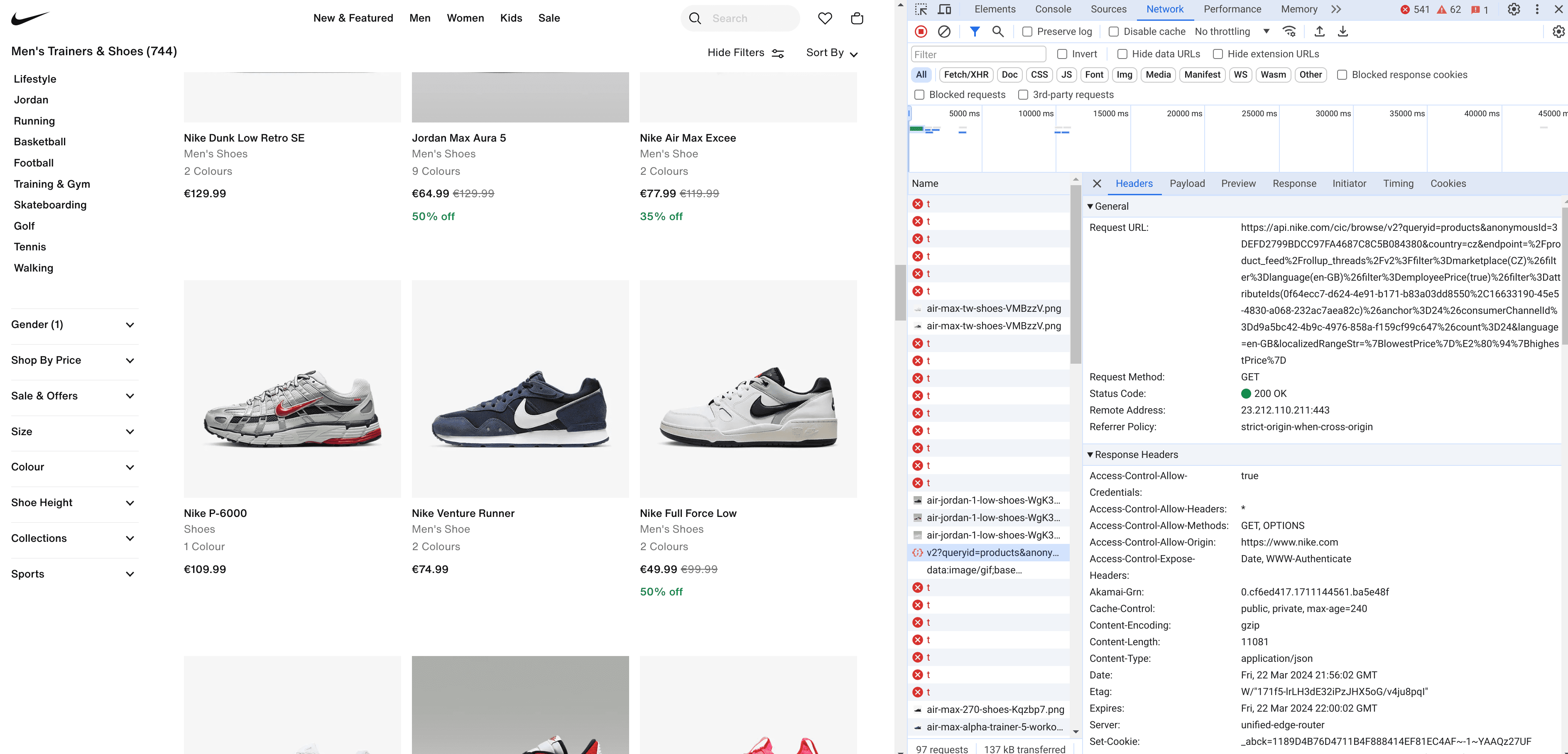
Upon reviewing the network activity, we'll notice that the requests containing the parameter “queryid=products” are particularly relevant to our interests. By navigating to the 'Response' section within these requests, we can see the precise data we need.
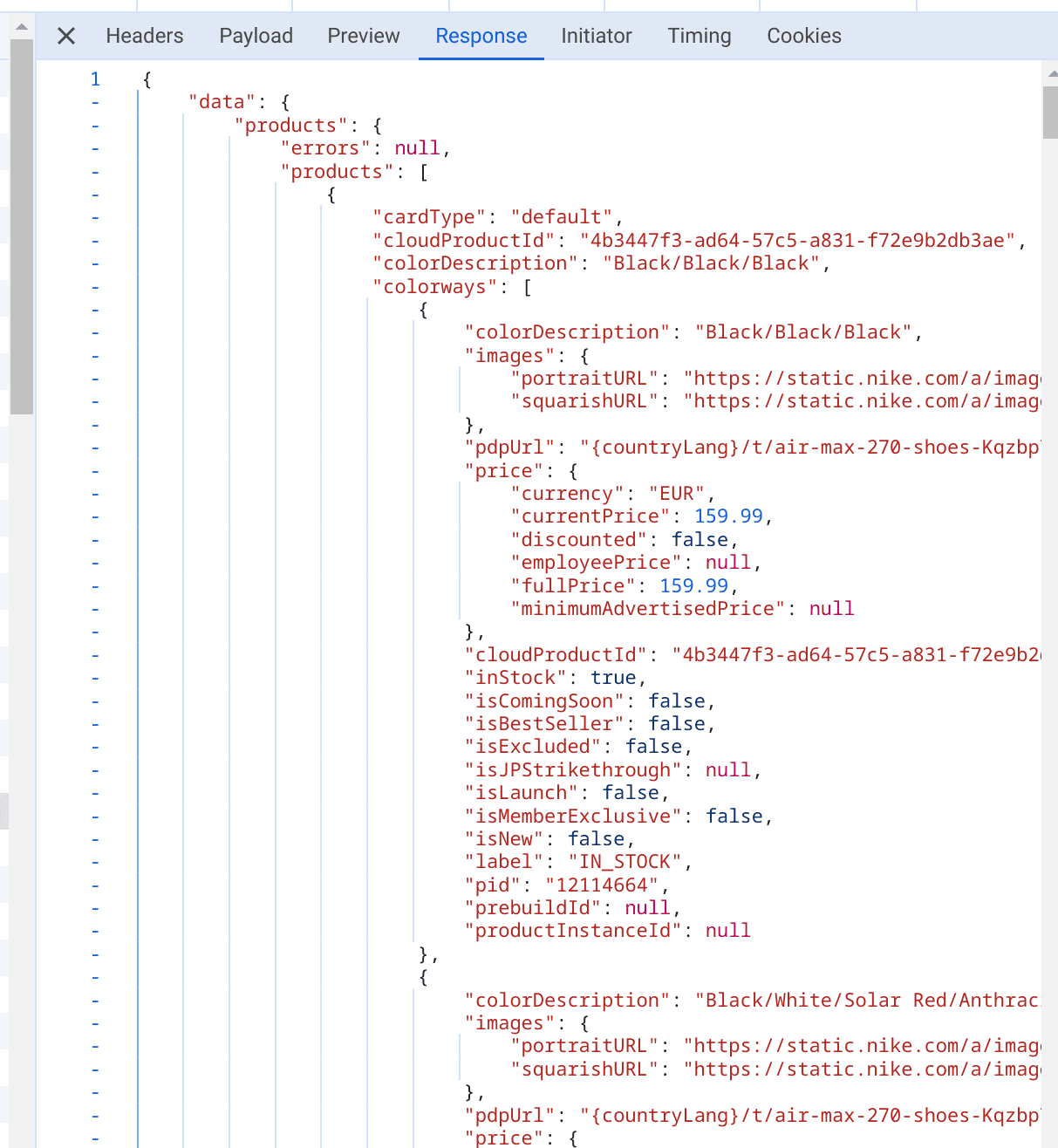
We'll now enhance our script to analyze these specific requests each time they're made. To achieve this, we'll utilize Playwright's network events feature, which allows us to listen to and react to network activities, particularly the HTTP response events.
Right after initiating a new browser page with browser.new_page(), we'll set up this network event monitoring. This will enable us to intercept the relevant requests and extract the data we're interested in directly from these network interactions.
# Use network event to set up a handler for the response event, which
# will extract the data.
page.on(event='response', f=lambda response: maybe_extract_data(response))
Let's create the maybe_extract_data function to identify and extract relevant data from network responses. Within this function, we'll utilize the standard library urllib to parse each response's URL, specifically checking for the presence of queryid=products. If this query is found, indicating that the response contains the data of interest, we'll convert the response content into JSON format using the response.json() method. Finally, the extracted JSON data will be printed to the standard output for review and further processing.
from urllib.parse import parse_qs, urlparse
from playwright.async_api import Page, Playwright, Response, async_playwright
async def maybe_extract_data(response: Response) -> None:
parsed_url = urlparse(response.url)
query_params = parse_qs(parsed_url.query)
# Check if 'queryid=products' is in the URL
if 'queryid' in query_params and query_params['queryid'][0] == 'products':
data = await response.json()
print('JSON data found in: ', response.url)
print('data: ', data)
Now, run the script once more and carefully observe the output. This allows us to pinpoint the specific data fields we wish to extract and refine our maybe_extract_data function accordingly. Additionally, consider directing the output into a file for record-keeping or further analysis.
We should also handle potential KeyErrors: if any product data lacks certain fields, we'll skip over that product.
Here's the updated version of our complete script after incorporating these enhancements.
import asyncio
import json
from contextlib import suppress
from urllib.parse import parse_qs, urlparse
from playwright.async_api import Page, Playwright, Response, async_playwright
async def scroll_to_bottom(page: Page) -> None:
# Get the initial scroll height
last_height = await page.evaluate('document.body.scrollHeight')
i = 1
while True:
print(f'Scrolling page ({i})...')
# Scroll to the bottom of the page.
await page.evaluate('window.scrollTo(0, document.body.scrollHeight);')
# Wait for the page to load.
await asyncio.sleep(1)
# Calculate the new scroll height and compare it with the last scroll height.
new_height = await page.evaluate('document.body.scrollHeight')
if new_height == last_height:
break # Exit the loop when the bottom of the page is reached.
last_height = new_height
i += 1
async def maybe_extract_data(response: Response) -> None:
parsed_url = urlparse(response.url)
query_params = parse_qs(parsed_url.query)
# Check if 'queryid=products' is in the URL
if 'queryid' in query_params and query_params['queryid'][0] == 'products':
data = await response.json()
print('JSON data found in: ', response.url)
extracted_info = []
with suppress(KeyError):
for product in data['data']['products']['products']:
product_info = {
'colorDescription': product['colorDescription'],
'currency': product['price']['currency'],
'currentPrice': product['price']['currentPrice'],
'fullPrice': product['price']['fullPrice'],
'inStock': product['inStock'],
'title': product['title'],
'subtitle': product['subtitle'],
'url': product['url'].replace('{countryLang}', '<https://www.nike.com/en>'),
}
print(f'Extracted product: {product_info}')
extracted_info.append(product_info)
# Define the file name where data will be stored
file_name = 'extracted_data.json'
# Open a file in write mode (will create the file if it doesn't exist)
# and dump the data into it in JSON format.
with open(file_name, 'w') as file:
json.dump(extracted_info, file, indent=4)
async def scrape_nike_shoes(playwright: Playwright, url: str) -> None:
# Launch the Chromium browser in non-headless mode (visible UI), to see
# the browser in action.
browser = await playwright.chromium.launch(headless=False)
# Open a new browser page.
page = await browser.new_page(viewport={'width': 1600, 'height': 900})
# Use network event to set up a handler for response event to extract
# the data.
page.on(event='response', f=lambda response: maybe_extract_data(response))
await asyncio.sleep(1)
# Navigate to the specified URL.
await page.goto(url)
await asyncio.sleep(1)
# Click the "Accept All" button to accept the cookies.
await page.click('text=Accept All')
await asyncio.sleep(1)
# Scroll to the bottom of the page to load all the products.
await scroll_to_bottom(page)
# Wait for the popup to be visible to ensure it has loaded on the page.
await page.wait_for_selector('.bluecoreCloseButton')
# Click on the close button of the advertisement popup.
await page.click('.bluecoreCloseButton')
await asyncio.sleep(1)
# Close the browser.
await browser.close()
async def main() -> None:
async with async_playwright() as playwright:
await scrape_nike_shoes(
playwright=playwright,
url='https://www.nike.com/cz/en/w/mens-shoes-nik1zy7ok',
)
if __name__ == '__main__':
asyncio.run(main())
Execute it and see the file extracted_data.json for the results.
[
{
"colorDescription": "White/Sail/Gum Light Brown/Light Blue",
"currency": "EUR",
"currentPrice": 104.99,
"fullPrice": 149.99,
"inStock": true,
"title": "Nike Zoom GP Challenge 1",
"subtitle": "Women's Hard Court Tennis Shoes",
"url": "https://www.nike.com/en/t/zoom-gp-challenge-1-hard-court-tennis-shoes-kN2XfG/FB3148-105"
},
{
"colorDescription": "White/Black/Hyper Pink/Volt",
"currency": "EUR",
"currentPrice": 129.99,
"fullPrice": 129.99,
"inStock": true,
"title": "Tatum 2",
"subtitle": "Basketball Shoes",
"url": "https://www.nike.com/en/t/tatum-2-basketball-shoes-XMG4J0/FZ8824-100"
},
...
]
Best practices and final tips
When using Playwright with Python to automate web interactions, following these best practices and tips will help enhance efficiency, reduce errors, and make your code more maintainable:
Structured data management
Utilize data classes or similar Python structures to manage and manipulate data efficiently and safely. This approach promotes cleaner code and makes it easier to read, debug, and maintain. These data classes automatically generate special methods like __init__, __repr__, and __eq__, reducing boilerplate code. When your script extracts data from web pages, structuring this data into well-defined classes can simplify subsequent data handling and processing.
from dataclasses import dataclass
@dataclass
class Shoe:
color_description: str
currency: str
current_price: float
full_price: float
in_stock: bool
title: str
subtitle: str
url: str
Asynchronous programming
When web scraping, you'll frequently encounter I/O operations. Optimizing these operations through non-blocking commands can greatly enhance your code's performance and maintain your application's responsiveness. Therefore, it's advisable to use the asynchronous interface of Playwright whenever possible.
This approach is particularly beneficial for tasks such as making additional HTTP requests, file system interactions, or database communications. To manage such asynchronous tasks effectively, utilize Python's Asyncio standard library. Furthermore, adopt task-specific asynchronous libraries: e.g. HTTPX for HTTP communications, Aiofiles for file system operations, and a suitable asynchronous database engine like Psycopg for PostgreSQL. These tools help ensure that your scraping operations are efficient and scalable.
Script optimization and resource management
Optimize your Playwright scripts by minimizing unnecessary page loads and interactions. Use selectors efficiently, and avoid waiting for arbitrary time intervals—instead, wait for specific elements or conditions to be met. This reduces execution time and improves the reliability of your tests or automation tasks. Also, use headless mode in production.
You should also keep in mind proper resource management by closing browsers, pages, and other resources when they're no longer needed. This helps prevent memory leaks and ensures that your scripts run smoothly without consuming excessive system resources.
Recap and next steps
We've explored the combination of Playwright and Python for automating browser tasks and end-to-end testing, and performing web scraping operations.
Now you know how to use Playwright with Python to:
- Navigate through web pages
- Execute JavaScript
- Manage asynchronous requests, and
- Intercept network communications to extract essential data.
Along the way, you also learned how to configure Playwright, carry out various navigation and interaction tasks, utilize data classes for structured data handling, and employ asynchronous I/O operations to enhance the efficiency and performance of our scripts.
Web scraping Playwright templates