If you’ve ever done any web scraping, you’ve probably stumbled upon the problem that if you send too many requests to a website from a single IP address, the website will start blocking access from that address, or start showing CAPTCHA, scrambling the data, etc. To work around that, you quickly figure out that you need to send your requests from a number of rotating IP addresses. So you purchase a number of dedicated or shared proxy servers from one of the proxy providers out there and start crawling again.
But soon things start to get complicated. The proxy servers die out from time to time, damaging your crawling results. Your large-scale parallel crawlers send too many requests and your proxies get burned, i.e. blocked for a long time by the target website. You buy proxies located in Germany, but the website you access thinks your browser comes from France. You share the proxies with other users and they burn them for you. The list could go on and on…
Our users had to deal with these kinds of issues all the time, so it was time for us to fix it.
Today we’re announcing Apify Proxy, a new HTTP proxy server endpoint that provides access to Apify’s large pool of proxies. Without further ado, here’s how to use it:
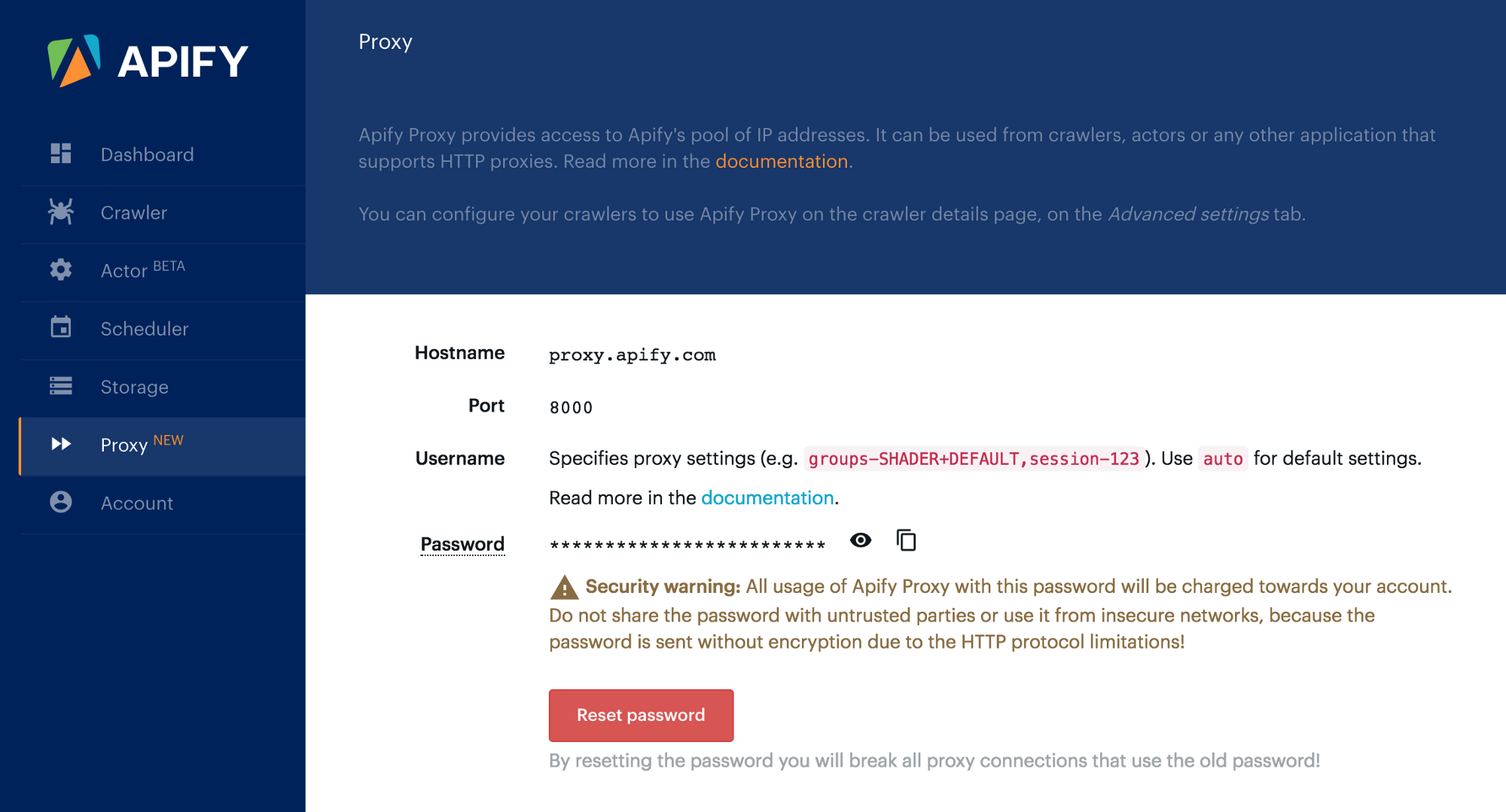
Hostname: proxy.apify.com
Port: 8000
Proxy type: HTTP
Username: Specifies parameters of the connection (see below)
Password: Your proxy password, see https://my.apify.com/proxyThe username defines various settings of the proxy connection. For the default behavior, simply use auto. For more advanced settings, see the Apify Proxy documentation.
We also added a new Proxy tab to the app, where you can view all the details about Apify Proxy, including the list of groups of proxy servers that you have access to:
So what exactly does Apify Proxy do? In short, it provides access to Apify’s large pool of IP addresses, without allowing misbehaving users to affect the crawls of other users. Here’s a full list of features:
- Periodic health checks of proxies in the pool to ensure requests are not forwarded via dead proxies.
- Intelligent rotation of IP addresses to ensure target hosts are accessed via proxies that have accessed them the longest time ago, in order to reduce the chance of blocking.
- Periodically checks on whether proxies are banned by selected target websites, and if they are, stops forwarding traffic to them in order to get the proxies unbanned as soon as possible.
- Ensures proxies are located in specific countries using IP geolocation.
- Allows selection of groups of proxy servers with specific characteristics.
- Supports persistent sessions that enable you to keep the same IP address for certain parts of your crawls.
- Measures statistics of traffic for specific users and hostnames.
Apify Proxy can be accessed not only from the Apify platform, but from any application that supports HTTP proxies. That means you can also use it in crawls performed on your own infrastructure. Oh, by the way, your Apify crawlers already run over Apify Proxy by default.
Your Apify subscription plan now shows the number of proxies from our pool that are available for your crawling. For details, see our Pricing page. If you need a custom plan with more proxies, just let us know at support@apify.com
But that’s not all. It would not be possible to build Apify without all the open-source software out there. To show our gratitude and to give something back to the community, we’ve released the core of the Apify Proxy — the proxy-chain package — as open-source on NPM and GitHub. Feel free to give it a star if you like it :)
If you have any questions, feedback or request for features, just let us know at support@apify.com