If you're a developer or data engineer scraping data at scale, you've likely run into roadblocks like:
- Websites blocking your requests, even when using proxies
- Bot detection systems that recognize your scraper as an automated client
- The need to run a full browser, which slows everything down and eats up resources
- Cloud environments complicating browser-based scraping with complex setups
These issues make large-scale data extraction slow, costly, and unreliable.
impit is built to solve these problems. It lets you send HTTP requests that look identical to real browser traffic without actually running a browser. By mimicking browser behavior on both the HTTP and TLS levels, impit helps your requests avoid detection and pass as legitimate user traffic.
In this article, you'll learn how modern antibot detection works, why existing solutions fall short, and how impit makes browser impersonation simple, fast, and effective.
The problem with using a browser for web scraping
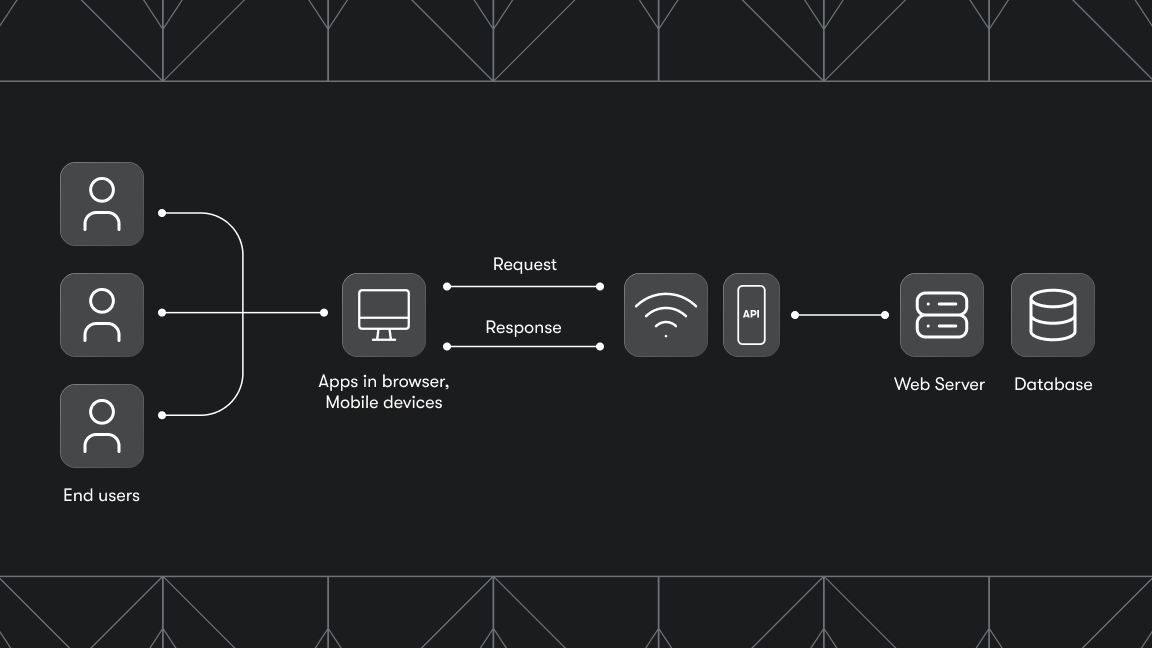
Web scraping can range from simple to complex. On the simpler end, raw HTTP requests can fetch data efficiently. However, challenges arise when websites implement bot detection mechanisms that require a browser to pass verification, render JavaScript, or both.
Running a browser in these cases introduces several issues:
- High resource consumption (memory, CPU)
- Controlling headless browsers can be difficult (Playwright and Puppeteer help but don't solve everything)
- Execution slows down significantly, limiting scalability
- In cloud environments, setting up browsers is even more complex, requiring Docker or other solutions
Direct HTTP requests are generally preferable because they’re faster, consume fewer resources, and allow more concurrent requests. However, modern antibot services detect and block non-browser clients.
How antibot services detect scrapers
Antibot services analyze incoming requests to differentiate between human users and automated traffic. The first request itself is often scrutinized before any JavaScript is executed. This approach:
- Improves user experience by avoiding additional challenges like CAPTCHAs or redirects
- Reduces server load by rejecting automated requests before page rendering begins
HTTP fingerprinting
Different clients send different User-Agent strings, making detection straightforward:
"User-Agent": "curl/7.81.0" // curl user agent
"User-Agent": "node" // Node fetch user agent
"User-Agent": "Mozilla/5.0 (X11; Linux x86_64; rv:135.0) Gecko/20100101 Firefox/135.0" // Mozilla Firefox 135 on Linux
Although easy to spoof, modern bot detection goes beyond simple User-Agent checks:
- Different browsers send different headers (e.g., Chromium-based browsers send
Sec-CH-UA-*headers in secure contexts) - Antibot services compare User-Agent values with expected header sets to detect inconsistencies
- Header order can also reveal automated clients since different browsers have specific header order patterns, whereas libraries like Node's
undicimay use a different order - HTTP/2 settings and pseudo-header orders are additional fingerprinting techniques
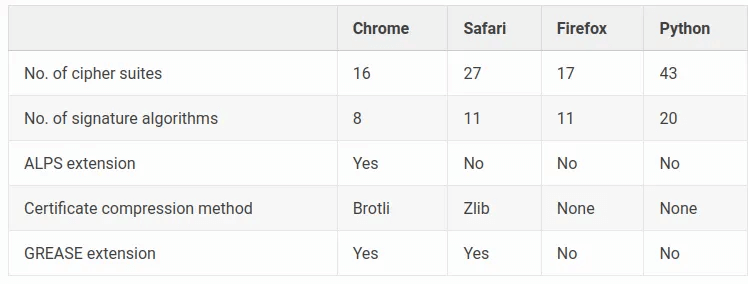
TLS fingerprinting
Before HTTP requests occur, the client and server establish a secure connection via TLS. This handshake process involves the ClientHello message, which contains:
- Supported cipher suites
- TLS extensions (e.g., ALPN, certificate compression)
- Other cryptographic details that vary by browser and version
Antibot services maintain databases of TLS fingerprints, categorizing them as "good" (belonging to real browsers) or "bad" (associated with libraries like Node.js HTTP clients, Python requests, or known malware).

Using TLS fingerprinting provides additional advantages over HTTP-based detection:
- Faster verification (TLS fingerprints appear early in the connection)
- Identifies client capabilities (unlike with user-agent (or other) headers, the client cannot send arbitrary values here, as it needs to implement the “advertised” cryptographic functions. Fake cipher suites can lead to failed handshakes)
- Harder to manipulate, as most HTTP libraries expose header modification options but not TLS settings
Solution: a lightweight browser impersonation library
To bypass these detection methods, a solution must:
- Make HTTP requests while appearing identical to a real browser
- Mimic TLS settings of actual browsers
- Support HTTP/1.1, HTTP/2, and HTTP/3
The problem with existing solutions
Several projects attempt to solve this problem:
curl-impersonate: A modified curl that mimics browser behavior. However, there are downsides:
- Lacks prebuilt binaries for Windows/Mac aarch64
- Poor documentation and compatibility issues with native JavaScript bindings
- The project is no longer actively maintained
cycletls: A Go-based HTTP client with TLS fingerprinting emulation support. It has a Node.JS package, but:
- It uses a wrapper script rather than native bindings
- It has a large npm package (81 MB), as it bundles binaries for all the supported architectures / OSs
- Calling the binaries through
child-processinstead of using Node’s native addon interface leads to a performance hit and possible issues with the child process management and serialization / deserialization of data
How impit simplifies browser impersonation
impit handles browser impersonation challenges by addressing the core limitations of existing tools like curl-impersonate and cycletls. Here’s how it improves on them:
1. Eliminates dependencies on different C libraries
Problem with curl-impersonate: Relies on a rather complicated build setup with different SSL libraries (nss, BoringSSL), which complicates builds, introduces compatibility risks, and limits cross-platform support.
impit’s solution:
rustls: Uses a modern TLS library written in Rust, patched to enable mimicking browser TLS fingerprints without modifying system-level dependencies.reqwest: Uses a high-level HTTP client that handles browser-like HTTP/2 and HTTP/3 behavior natively. This avoids fragile C library patches and ensures portability.
2. Cross-platform binaries & smaller size
Problem with curl-impersonate: No available prebuilt binaries for Windows/macOS ARM (aarch64). Building the project from sources is complicated due to incomplete documentation.
Problem with cycletls: Massive 81 MB npm package due to bundling all the executable binaries for all the supported platforms.
impit’s solution:
- Rust compiles to native binaries for all major platforms (Windows, macOS, Linux, aarch64/x86_64).
- Small npm packages (~ 5 - 10 MB) built with via
napi-rs, which compiles Rust to lightweight Node.js addons. - Binaries for different platforms are published as optional dependencies of the main package, so the package manager picks the correct package automatically.
- Python bindings via
pyo3are similarly efficient.- We publish prebuilt wheels to
pipfor all major platforms, as well as the source distribution for building the package from source (requires Maturin setup)
- We publish prebuilt wheels to
3. Native bindings, no subprocesses
Problem with cycletls: Uses a Go binary + Node.js wrapper script, leading to:
- Performance overhead: JSON serialization between Go/Node.js.
- Error-prone implementation: Custom websocket message-passing IPC implementation is brittle.
impit’s solution:
- Native bindings via
napi-rs(Node.js) andpyo3(Python):- Directly embeds Rust code into Node.js/Python, avoiding subprocesses.
- Enables true async/thread-safe concurrency.
- Zero serialization overhead - the binary data is passed using the native interfaces, skipping the serialization / deserialization and copying (where possible).
Key differentiators at a glance
| Feature | curl-impersonate | cycletls | impit |
|---|---|---|---|
| Windows/macOS ARM bins | ❌ | ❌ | ✅ |
| Node.js package | ❌ | 🟡 (only a child-process wrapper) |
✅ |
| Python package | ❌ | ❌ | ✅ |
| HTTP/3 Support | ✅ (with recent curl versions) | ❌ | ✅ (reqwest experimental) |
| Package size | ~20 MB | 81 MB | ~8 MB (platform dependent, on average) |
Get started with impit
impit for Node.js
Available on npm: impit
Installation:
npm i impit
Usage
import { Impit, Browser } from 'impit';
const impit = new Impit({
browser: Browser.Firefox,
proxyUrl: "http://proxy.url.com:8080",
http3: true,
});
const resp = await impit.fetch(
"https://heavily.protected.site/api",
);
const json = await resp.json();
/// consume the JSON API response
impit for Python
Installation:
pip install impit
Usage:
import asyncio
from impit import AsyncClient
async def main():
client = AsyncClient(http3=True, browser='chrome', proxy='http://proxy.url.com:8080')
response = await client.get(
"https://heavily.protected.site/api",
);
print(response.status_code)
print(response.text)
print(response.http_version)
asyncio.run(main())
impit CLI
For quick testing without writing code, impit-cli mimics curl:
impit --impersonate=firefox -H "Authorization: Basic ..." "https://heavily.protected.site/api"
Prebuilt binaries are available from GitHub Actions: impit releases.