


At Apify Engineering, we believe that to work efficiently, we need to be able to focus on the product we are making instead of getting hindered by technological obstacles and ineffective procedures. Our development process should hide its complexities and let us effectively iterate new features and quickly reproduce and fix bugs reported by our users. So how do we do that?
All of our applications are written in JavaScript (or TypeScript), enabling all of our teams to be full-stack, working end-to-end on front and backend features, usually across multiple applications.
Having to deploy our code to the cloud each time we make changes to be able to see them live would introduce too much friction to the development process. Working in a remote development environment would be too expensive and complicated to set up for each developer. So to achieve our goal, we must be able to develop the Apify platform locally; no compromises here.
That brings with it the need to be able to run all of our products and all of their dependencies directly on our computers, with as few differences from the production environment as possible, minimal needed setup, quick rebuilds and reloads on code changes, and the option to run the full battery of our integration tests against the local environment. Sounds like a great challenge.
Third-party dependencies
This is no easy feat, as the Apify platform is a complex network of interconnected products and tools - Apify Console for managing your account on our platform, Apify API for programmatic access to your Actors and data, Apify Proxy providing access to our proxy services, worker machines executing users’ jobs, web servers hosting our website and documentation, and many other smaller applications.
These, in turn, utilize a wide range of complex third-party services, such as MongoDB and PostgreSQL as general databases, DynamoDB and S3 for storing large amounts of data, multiple Redis Clusters for caching and synchronization, Algolia for a search engine, SQS as a message broker, New Relic for application metrics tracking, and many others.
Fortunately, many dependencies we use have official support for local execution, like MongoDB, PostgreSQL, Redis, and DynamoDB. Others don’t, though, and to make our platform fully functional, we have to substitute them with compatible services.
To substitute Amazon SQS, we are using elasticmq 🔗, an in-memory message queue that is API-compatible with SQS, and can serve as its full equivalent.
As an alternative to Algolia, we use algolite 🔗, a lightweight emulation of Algolia with a compatible REST API. It does not support all Algolia features, and we had to fork it to fix a few bugs, but it is close enough for local development.
The most formidable challenge was to find a replacement for S3. Many storage services can run locally and offer an S3-compatible API, but in the end, we settled on fake-s3 🔗, as it was the only one that could generate pre-signed URLs that work with CORS.
We also want to verify that our application metric tracking works correctly locally. Since New Relic does not support running their data collector and dashboards application locally, we replace it with prometheus 🔗, an open-source service monitoring system. Since we collect and export our metrics via OpenTelemetry, no code change is needed; we just configure a different metrics collector destination.
The Apify Dev Stack
To minimize the needed setup for these services, we run all of them containerized via Docker. This way, we don’t have to install any libraries or other prerequisites (like Java or Ruby), making it much simpler to keep everything unified across operating systems.
We've made running the services as simple as possible by developing an internal tool we call the Apify Dev Stack. It consists of a Docker Compose project, which groups all the needed services together, builds them, ensures they start in the right order, and configures them, and a collection of shell scripts that take care of the Compose project lifecycle and other necessary actions, such as configuring network rules between the containerized services and the host machine and managing the stack data. Everything is done automatically, all you need to do is run one script, and that’s it!
Running TypeScript code efficiently
Most of our platform runs on Node.js, and just like everyone else these days, we are slowly migrating our codebase from plain JavaScript to TypeScript. This has many benefits, from preventing bugs to better code autocompletion, but there's one drawback: you have to transpile your code to JavaScript to run it.
Naturally, we wanted to avoid that obstacle, so we decided on running our code via ts-node 🔗, a robust TypeScript execution engine for Node.js. This approach worked fairly well in our main monorepo, with minimal setup, but gradually became slower as we migrated more and more code to TypeScript. It turned out the slowness was caused by ts-node transpiling each TypeScript file when it was first encountered during execution and not caching the transpilation results between successive invocations.
We wanted to solve these execution performance issues while keeping the one-command simplicity of the ts-node setup, so we used concurrently 🔗 to run the TypeScript compilation and execute the resulting JavaScript code together. The TypeScript codebase is built incrementally using tsc --build --watch, compiling all packages in the monorepo in the correct topological order, and recompiling them on any source file change. The resulting JavaScript is then executed via nodemon 🔗, which restarts the executed app whenever the compiled files change. This ensures that whenever we change our TypeScript code, we see the results of the change within a few seconds.
Meteor hot module replacement
There is one exception to the above, and that is Apify Console, which is running on top of the Meteor framework 🔗. Meteor utilizes its own build system and file watcher, which achieves zero-effort application rebuilding and reloading.
With a large codebase, the rebuilds can be slow, but fortunately, Meteor recently introduced a hot module replacement option, making the process even more painless.
Whenever we change the Apify Console codebase, the application gets rebuilt. Only the rebuilt packages are replaced within the running application in the browser without reloading the whole application. This way, we do not lose the application state on code changes and can test them even faster.
Storybook
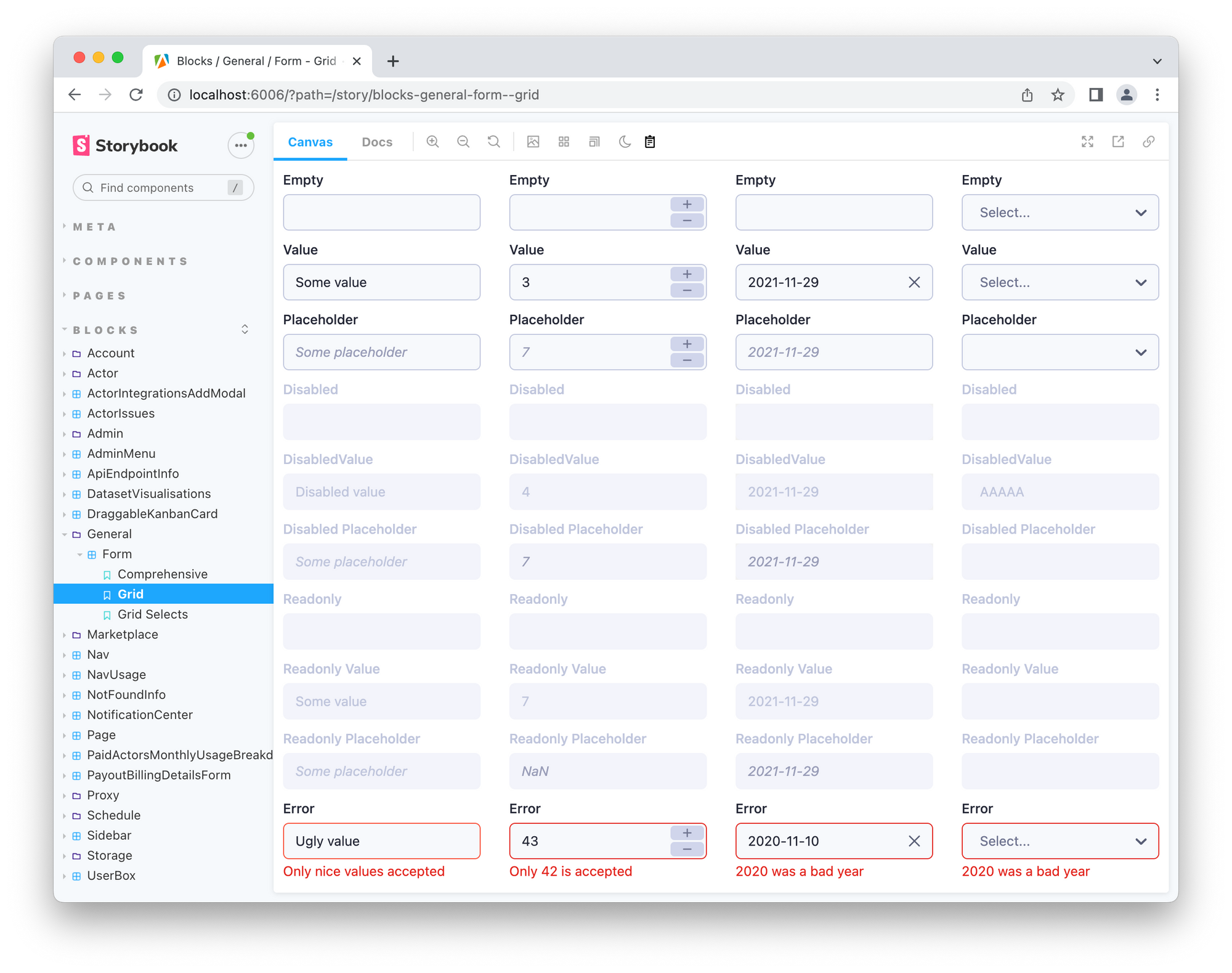
Still, whenever we create a new component, we need to test it under many different scenarios, which is tedious. For example, when creating a Form component with many possible types of inputs, with each type of input having several possible states, it is almost impossible (and undoubtedly impractical) to test all the combinations directly in a real-world application.
To streamline that process, we use storybook 🔗, a modern development environment for UI components. It allows us to render each component with many pre-defined combinations of attributes in parallel, so we can quickly inspect the effect some change would have on all the component states.
Join us and strive for excellence
This was just a quick sneak peek behind the scenes of the Apify platform engineering team. Like our development process? Join us, and you can be a part of it too.
Or would you do things differently? Tell us on Discord.




