Duplicates can be a real problem when web scraping. Deduplication is the process of getting rid of duplicates in data - in other words, making sure that we don’t have the same thing recorded multiple times. We're going to use Apify Actors to make the process easier.
Step 1. Choose an Actor to build a dataset
We’re going to use Contact Details Scraper 🔗 to build a dataset containing unique email addresses extracted from various websites. If everything goes well, we’ll end up with a setup that incrementally - whenever it runs - adds newly scraped emails to a single dataset. The result will look like this:
[
{ email: 'name@example.com' },
{ email: 'name2@example.com' },
// ...
]
Expected shape of output data
Let’s start by creating a task for Contact Details Scraper and giving it the input, just a URL to begin with and a reasonable number of maximum pages:
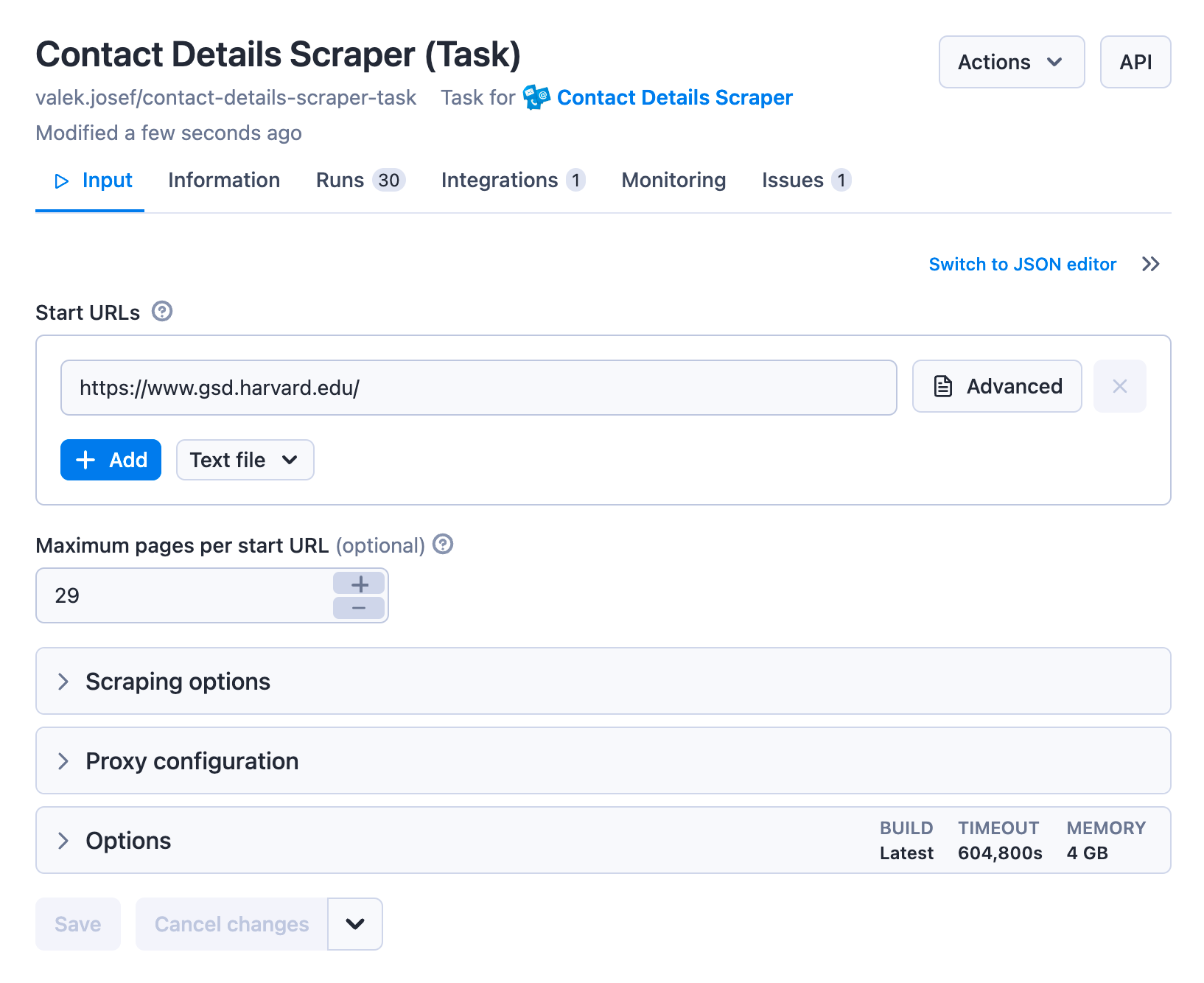
When we run it, we can see that the information in the dataset looks something like this.
{
"depth": 1,
"originalStartUrl": "<http://www.gsd.harvard.edu/>",
"referrerUrl": "<http://www.gsd.harvard.edu/>",
"url": "<https://www.gsd.harvard.edu/doctoral-programs/>",
"domain": "harvard.edu",
"emails": [
"melissa_hulett@gsd.harvard.edu",
"mmoore@gsd.harvard.edu",
"thorstenson@gsd.harvard.edu"
],
"facebooks": [
"<http://www.facebook.com/HarvardGSD>",
"<https://www.facebook.com/HarvardGSD/>"
],
"youtubes": [
"<http://www.youtube.com/user/TheHarvardGSD>",
"<https://www.youtube.com/TheHarvardGSD>"
]
}
Example of item in dataset produced by Contact Details Scraper
Scraping the data looks fairly easy, let’s continue with the deduplication and transformation. In this case, that’s the hard part.
Step 2. Find an Actor to deduplicate datasets
Luckily, there's already an Actor on Apify Store that deals with this issue: Merge, Dedup & Transform Datasets. Its functionality is quite advanced and exceeds just deduplication, so feel free to explore its other features, such as moving data to key-value stores.
Step 3. Create an integration between the two Actors
Go to the Integrations page and add Integration with Actor and connect the right one (up top in this screenshot).
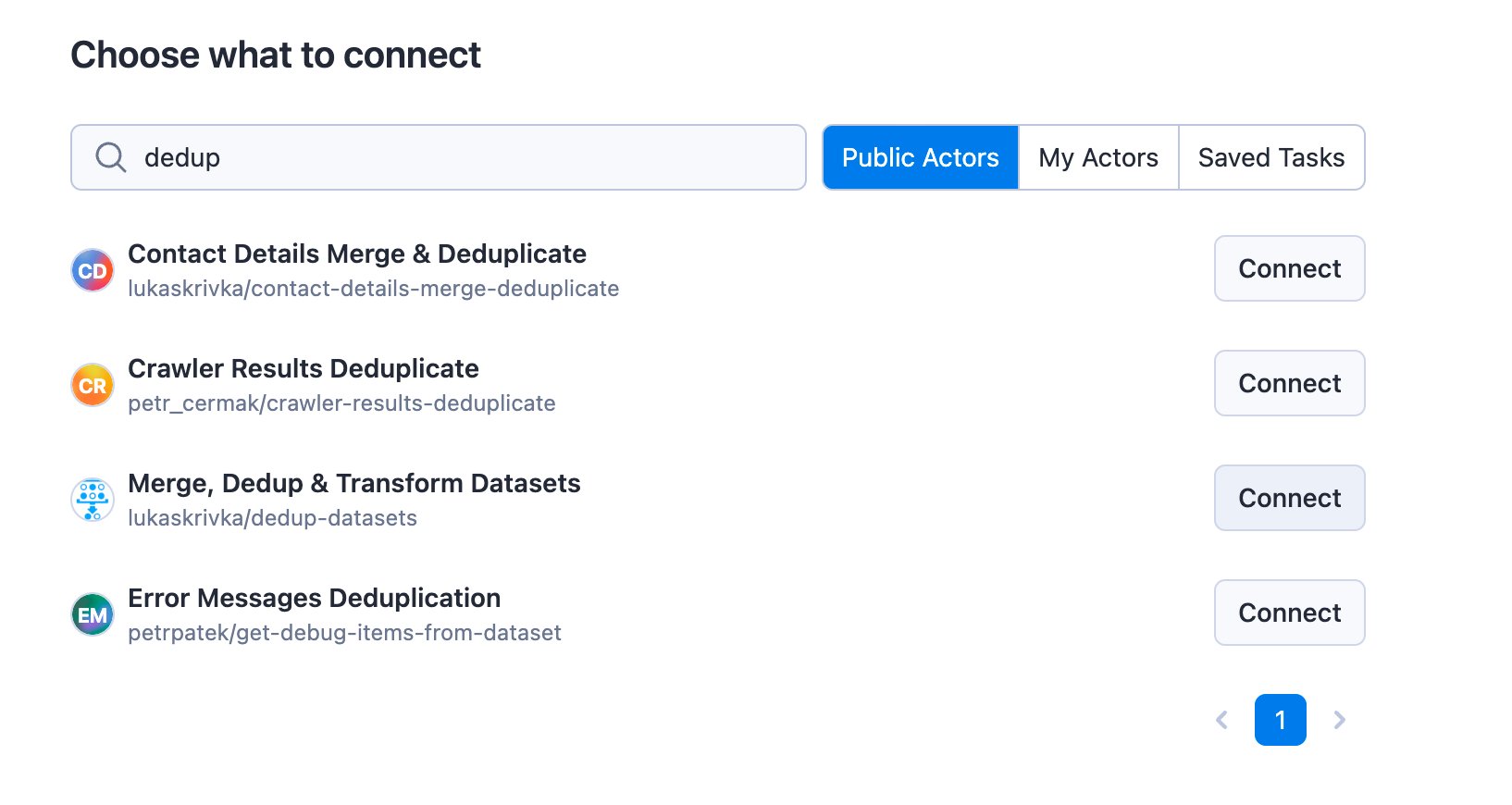
We only need to set values for a few fields and leave the defaults for others:
- Dataset IDs - we need to add one id,
{{resource.defaultDatasetId}}- this is a variable representing the id of the dataset produced by the task run. - Fields for deduplication - we need to add just
email - Mode - for our example, we don’t care about the order of items, so we can choose faster
Dedup as loading - Output dataset ID or name - here we need to give the name of the dataset where we want to keep the deduplicated data, let’s say
emails-on-the-internet. - Hiding in the Advanced section of input - Dataset IDs for just deduping. Here we need to put the same name we put as output dataset name, prefixed with
~(the Actor internally calls Apify API, which allows it to use~to access named datasets). This is what makes sure that we ignore the duplicates from previous runs too, not just duplicates in the current run. So let’s put in~emails-on-the-internet - In the Transforming functions section, we need to fill Pre dedup transform function. This one is going to be a bit more complex. If you're interested, read the comments.
// We are working with datasets of two shapes.
// The items produced by Contact Details Scraper look something like this
// { url: 'example.com', emails: ['name@example.com', 'name2@example.com'], facebooks: [...]}
// The items we want on the output would look like this:
// [ {email: 'name@example.com'}, {email: 'name2@example.com'}]
// The transformation makes sure that we always use the output format
async (items, { Apify }) => {
// No items at all, empty array can be returned.
if (items.length === 0) return [];
// If the items have the output format already, just return them
if (items[0].email) return items;
// Otherwise assume Contact Details Scraper shape and convert it.
return items.reduce((acc, {emails}) => {
const datasetItems = (emails || []).map(email => ({email}) );
acc.push(...datasetItems);
return acc;
}, []);
}
Pre dedup transform function
This JSON contains the fields set to proper values:
{
"datasetIds": [
"{{resource.defaultDatasetId}}"
],
"datasetIdsOfFilterItems": [
"~emails-on-the-internet"
],
"fields": [
"email"
],
"mode": "dedup-as-loading",
"outputDatasetId": "emails-on-the-internet",
"postDedupTransformFunction": "async (items, { Apify }) => {\\n return items;\\n}",
"preDedupTransformFunction": "// We are working with datasets of two shapes.\\n// The items produced by Contact Details Scraper look something like this\\n// { url: 'example.com', emails: ['name@example.com', 'name2@example.com'], facebooks: [...]}\\n// The items we want on the output would look like this:\\n// [ {email: 'name@example.com'}, {email: 'name2@example.com'}]\\n// The transformation makes sure that we always use the output format\\nasync (items, { Apify }) => {\\n // No items at all, empty array can be returned.\\n if (items.length === 0) return [];\\n // If the items have the output format already, just return them\\n if (items[0].email) return items;\\n // Otherwise assume Contact Details Scraper shape and convert it.\\n return items.reduce((acc, {emails}) => {\\n const datasetItems = (emails || []).map(email => ({email}) );\\n acc.push(...datasetItems);\\n return acc;\\n }, []);\\n}",
"verboseLog": false
}
Input for Dedup Actor when used as integration
- The Actor has quite a high default memory, for our use case it’s going to be enough to set it to
1GB.
The setup is complete; let’s check if it works.
Step 4. Check your integration setup
Now, let’s see what happens when we run the task. We can see it has finished and produced 30 results. But only some of them actually contain email addresses.

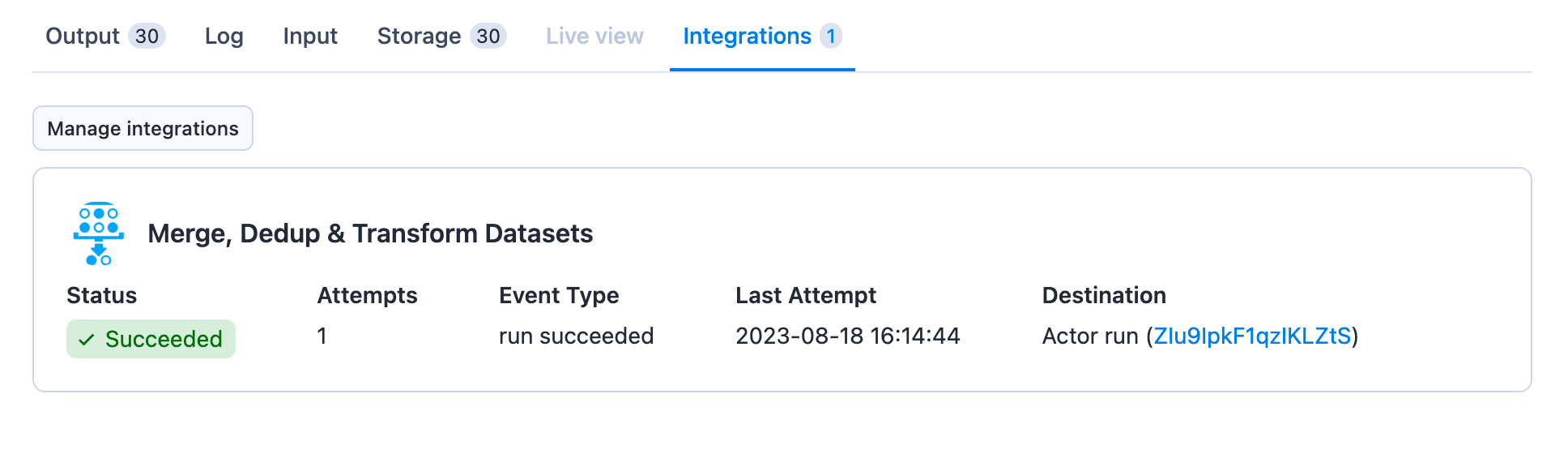
On the Integrations tab of the run, we can see that the Dedup Actor was triggered:
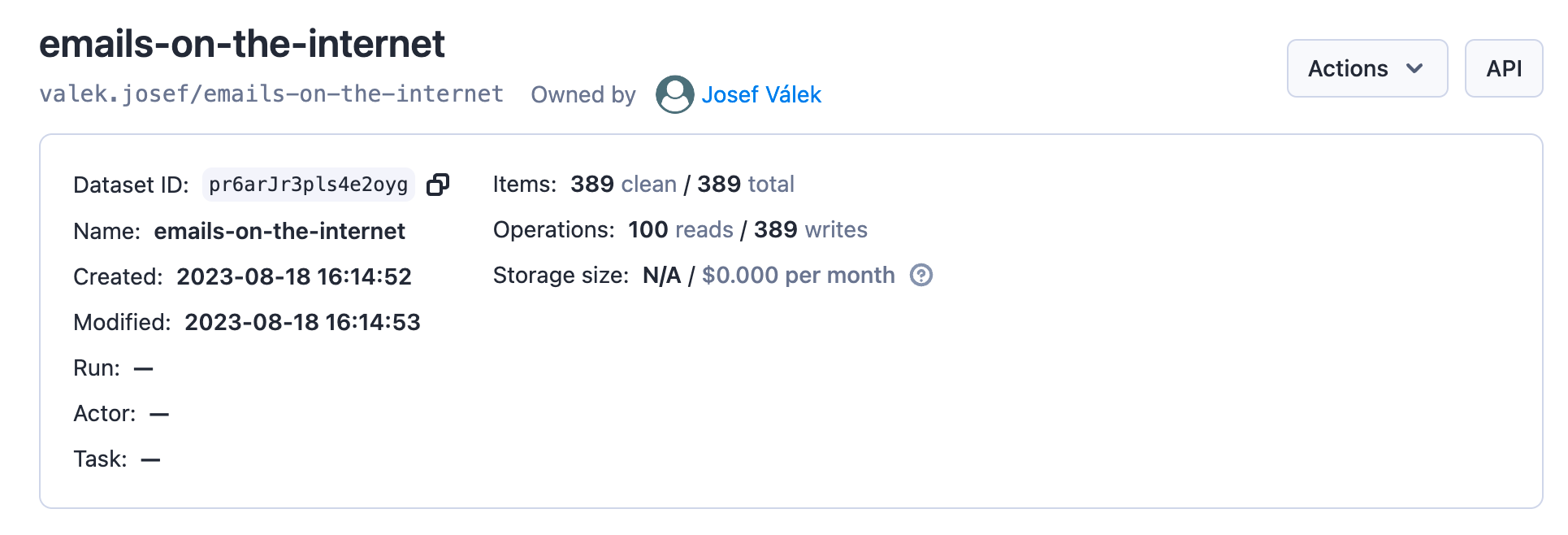
When we check the named dataset (under Storages), we can see that we have 389 unique emails:
Now let’s increase the Maximum number of pages per start URL input field on the task. Most likely, it’s going to find the same emails, and probably few more that we yet have not seen. In our case, we got five new emails.
Now, whenever you run the task again, only previously unseen emails will make it to the named dataset and you don’t have to worry about it containing the duplicates.
That's it! Remember that you can set up your own Actor-to-Actor or Actor-to-other-service Integration from scratch. See this video for example: