If you’ve ever tried to scrape Google Flights to get real‑time fare data for a pricing dashboard or market study, you may have run into Google Flights’ maze of client‑side rendering and bot defenses. Unlike traditional booking engines, Google Flights hides prices behind obfuscated JavaScript bundles, geo‑sensitive endpoints, and the occasional CAPTCHA.
This step-by-step guide will walk you through the process of scraping Google Flights using Python. By the end, you’ll have a fully functional scraper that can extract flight data, including prices, airlines, departure times, and more.
In the end, we’ll show you how to run your scraper on Apify to give you cloud scaling, rotating proxies, webhook alerts, and hands‑free scheduling, so you can have hourly fare monitoring or deal‑alert services, without managing a single Chrome instance yourself.
How to scrape Google Flights using Python
For building this scraper, we’ll be using Selenium and BeautifulSoup libraries in Python. Here are the steps you should follow to build your Google Flights scraper:
- Set up the environment
- Understand Google Flight’s structure
- Write the scraper code
We'll then show you how to deploy the scraper to Apify.
1. Set up the environment
Here's what you’ll need to continue with this tutorial:
- Python 3.9+: Make sure you have installed Python 3.9 or higher.
- Create a virtual environment (optional but recommended): It’s always a good practice to create a virtual environment (
venv) to isolate dependencies and avoid conflicts between packages.
python -m venv myenv
source myenv/bin/activate # On macOS/Linux
myenv\\Scripts\\activate # On Windows
- Required libraries: Since Google Flights is a dynamic website, we’ll be using Selenium Webdriver along with BeautifulSoup to write the scraper.
pip install selenium webdriver-manager pandas beautifulsoup4
To import the libraries into the script, use this:
import time
from selenium import webdriver
from selenium.webdriver.chrome.service import Service as ChromeService
from webdriver_manager.chrome import ChromeDriverManager
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from bs4 import BeautifulSoup
import pandas as pd # for saving data to a CSV file
2. Understanding Google Flights’ structure
The very first step in web scraping is to inspect and understand how the website is formed so that you can understand which data to scrape and how.
In this tutorial, we’ll be writing a script to scrape flight information for any trip on Google Flights. To start off, go to https://www.google.com/travel/flights and enter your trip details to scrape information from.
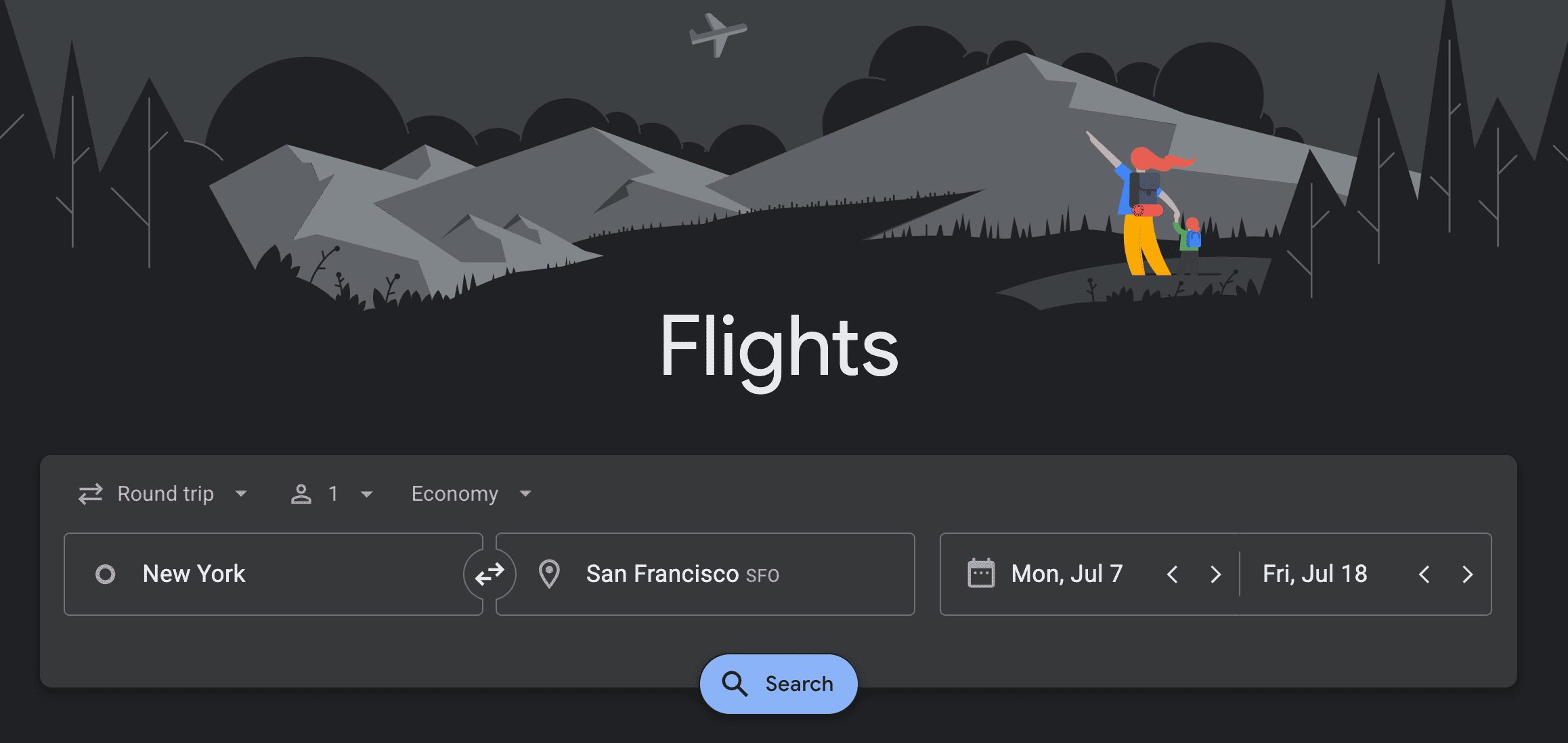
There are two sections in each trip search: Top departing flights and other departing flights. The top flights contain the top 5 flights that match your search based on a combination of factors like price, duration, number of stops, and airline reputation. The other departing flights are a comprehensive list of all other flights that match your search criteria. It includes a range of options.
Luckily, both of these sections have the same structure, so you do not have to scrape the top flights and other flights individually.
When inspected, you’ll see that Google Flights follows a web structure as below:
- Each flight's information, both in “Top Departing Flights” and the “Other Flights” section, is stored with a list item element with the class
pIav2d
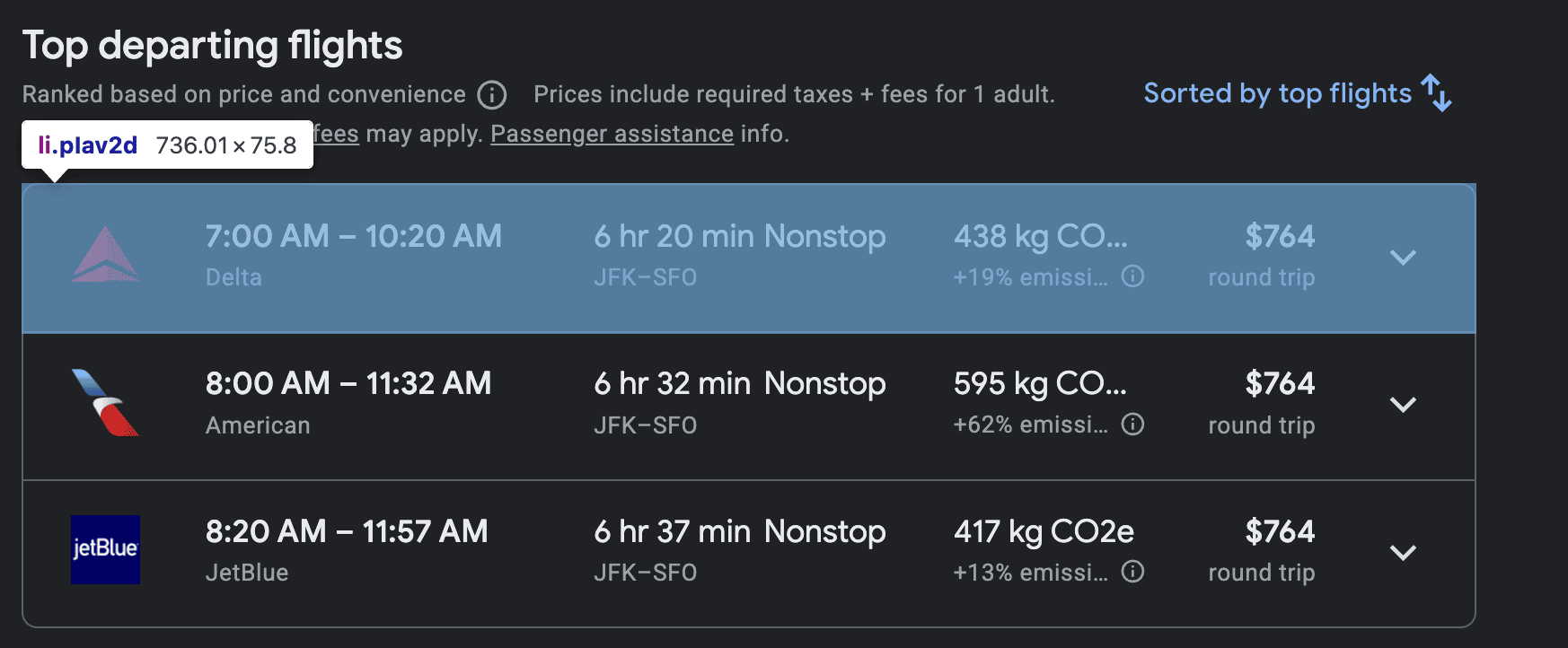
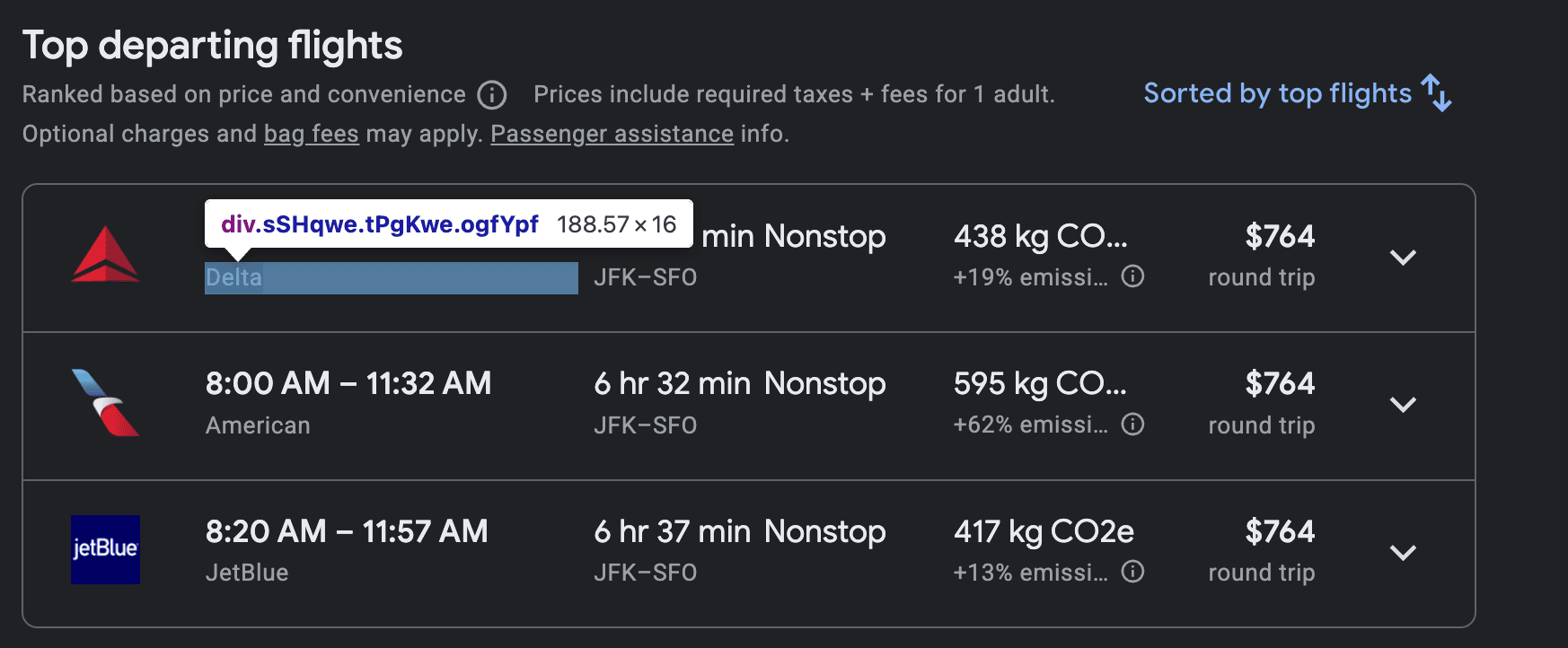
- The airline’s name is found in a
<div>element that has the classsSHqwe.
- The departure and arrival times are located within
<span>elements that have a specificaria-labelattribute for accessibility. - The total duration of the flight is inside a
<div>element with the classgvkrdb.
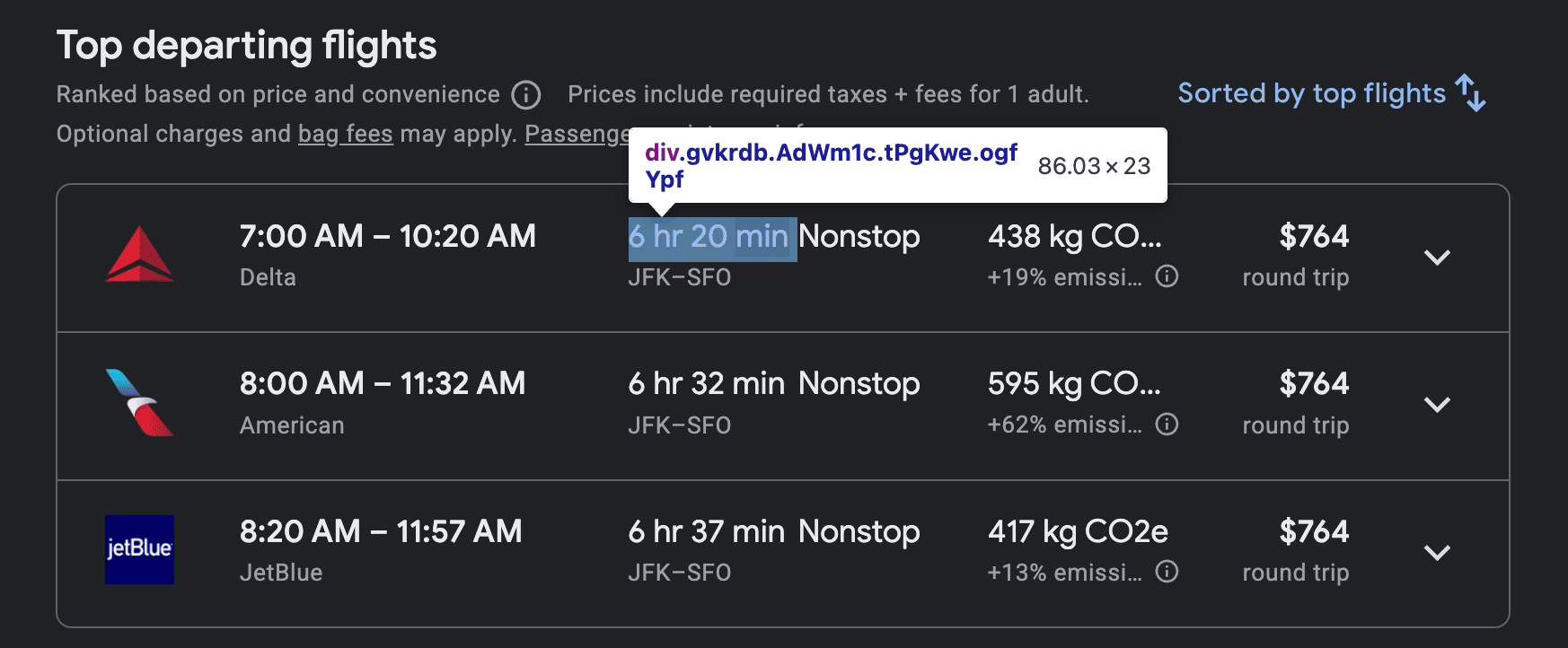
- The number of stops of the flight is within a
<span>element, which is itself inside a<div>with the classEfT7Ae.
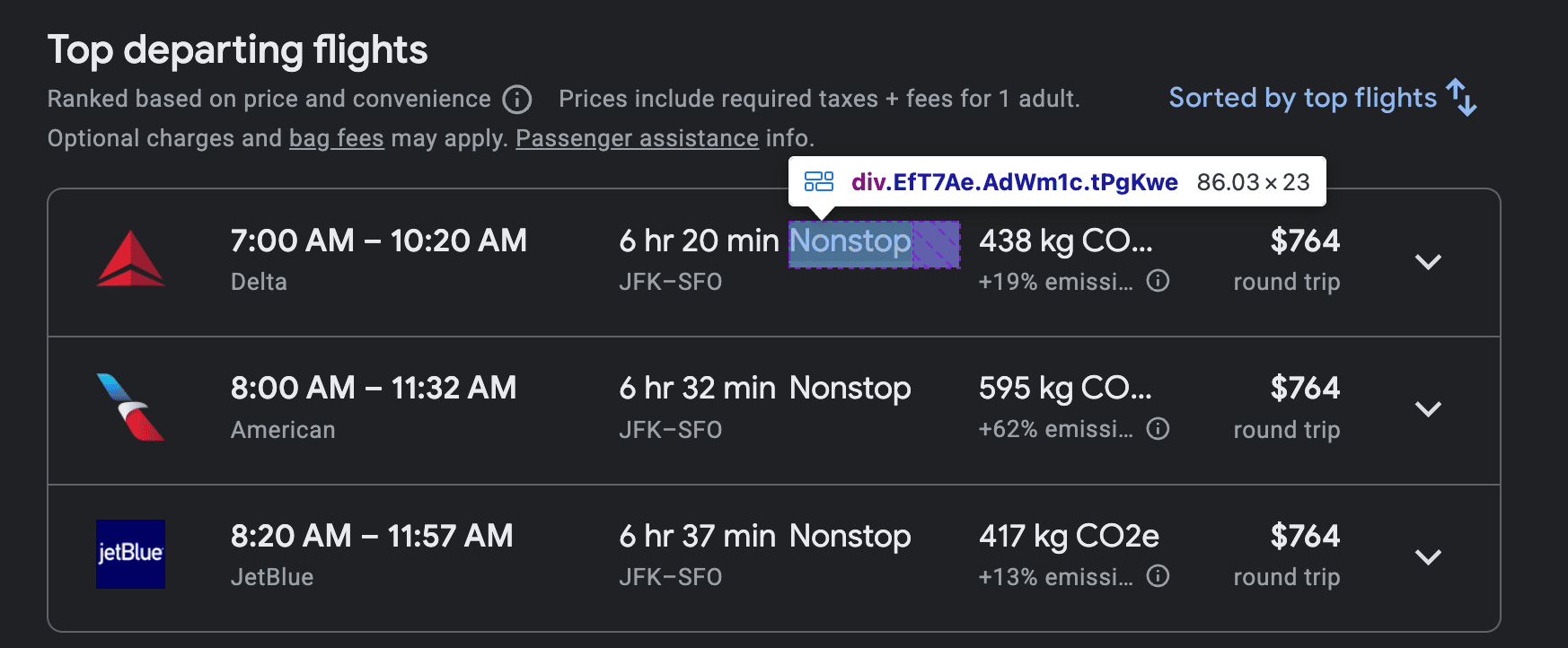
- The flight price is located in a
<span>element inside a<div>with the classFpEdX.
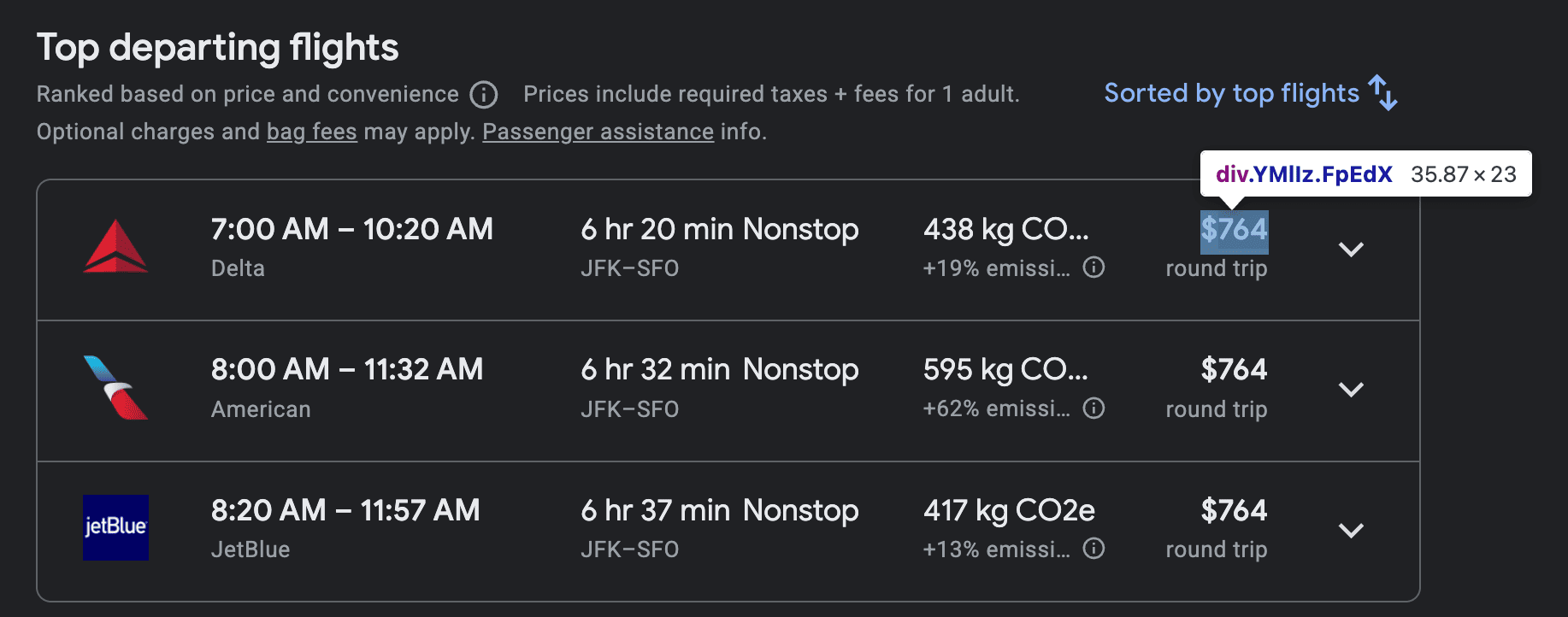
3. Writing the scraper code
Now that you know how to access the required elements on Google Flights, we can start writing the code.
First, write a function, define a common user agent, and then open the URL (which we will define later) like this:
def scrape_google_flights(url):
options = webdriver.ChromeOptions()
options.add_argument("--headless=new") # Runs Chrome without a visible browser window
options.add_argument("--window-size=1920,1080")
options.add_argument(
"user-agent=Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/125.0.0.0 Safari/537.36")
driver = webdriver.Chrome(service=ChromeService(ChromeDriverManager().install()), options=options)
driver.get(url)
What’s happening here is that Selenium opens a Chrome window with the provided user agent information and fetches the URL given, just like you do, only without showing it in the GUI.
Next, write a try-except block to make sure the full page is loaded by looking for the zISZ5celement (which is the main container of the website). If any error occurs, the program will stop with a message.
If successfully loaded, it should use beautifulsoup to parse the full page and then quit the driver as it’s no longer needed— this helps to free up resources.
try:
wait = WebDriverWait(driver, 20) # Wait up to 20 seconds
wait.until(EC.presence_of_element_located((By.CSS_SELECTOR, 'div.zISZ5c')))
except Exception as e:
print(f"Error waiting for flight results: {e}")
print("The website's structure may have changed, or the page didn't load.")
driver.quit()
return []
soup = BeautifulSoup(driver.page_source, 'html.parser')
driver.quit()
Now that beautifulsoup has parsed the HTML of the webpage, you can create an empty list to store the flight data and then extract flight elements through the li.pIav2d element.
flights_data = []
flight_elements = soup.select('li.pIav2d')
if not flight_elements:
print("No flight elements were found. The CSS selectors may be outdated.")
return []
After flight elements are in one list, you can write a for loop to extract information (airline name, departure and arrival times, prices, stops, and duration) for each flight, and clean the formatting of that data like below:
for flight in flight_elements:
# Selectors using attributes like 'aria-label' are often more stable than class names.
airline = flight.select_one('div.sSHqwe')
departure_time = flight.select_one('span[aria-label*="Departure time:"]')
arrival_time = flight.select_one('span[aria-label*="Arrival time:"]')
duration = flight.select_one('div.gvkrdb')
stops = flight.select_one('div.EfT7Ae span')
price = flight.select_one('div.FpEdX span')
flights_data.append({
"airline": airline.get_text(strip=True) if airline else "N/A",
"departure_time": departure_time.get_text(strip=True) if departure_time else "N/A",
"arrival_time": arrival_time.get_text(strip=True) if arrival_time else "N/A",
"duration": duration.get_text(strip=True) if duration else "N/A",
"stops": stops.get_text(strip=True) if stops else "N/A",
"price": price.get_text(strip=True) if price else "N/A",
})
return flights_data
Note that for the departure and arrival times, we have used aria-label because it's a stable accessibility tag that describes an element's function. This makes it a much more reliable target for scraping than temporary CSS class names, which change frequently.
However, the aria-label values in Google Flights vary based on the user’s location and language settings. The values in this example work only for English-language regions; otherwise, you’d need to adapt them to the translated aria-label values.
Once everything is clean, you can finally write the main check code to save the scraped data to a CSV file, like below:
if __name__ == "__main__":
# Note: Google Flights URLs can be volatile. This URL may need to be updated.
target_url = "https://www.google.com/travel/flights/search?tfs=CBwQAhoeEgoyMDI2LTAxLTEyagcIARIDSkZLcgcIARIDU0ZPGh4SCjIwMjYtMDEtMjlqBwgBEgNTRk9yBwgBEgNKRktAAUABSAFwAYIBCwj___________8BmAEB"
output_filename = "Google_flights_data.csv"
# 1. Scrape the data
print("Scraping flight data...")
scraped_flights = scrape_google_flights(target_url)
# 2. Save the results to a CSV file
if scraped_flights:
df = pd.DataFrame(scraped_flights)
df.to_csv(output_filename, index=False)
print(f"\nSuccessfully scraped and saved {len(scraped_flights)} flights to '{output_filename}'.")
else:
print("Scraping did not return any data.")
The target URL is just the URL of your flight search, which will start with https://www.google.com/travel/flights/search? . This Google Flights scraper can scrape any flight search URL you want to scrape. Feel free to change it as desired.
Once run, you’ll see an output like below:
And that’s it! You have successfully built a Google Flights scraper with Python that can successfully scrape flight information of any trip with it’s URL.
from selenium import webdriver
from selenium.webdriver.chrome.service import Service as ChromeService
from webdriver_manager.chrome import ChromeDriverManager
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from bs4 import BeautifulSoup
import pandas as pd # for saving data to a CSV file
def scrape_google_flights(url):
# --- WebDriver Configuration ---
options = webdriver.ChromeOptions()
options.add_argument("--headless=new") # Runs Chrome without a visible browser window
options.add_argument("--window-size=1920,1080")
options.add_argument(
"user-agent=Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/125.0.0.0 Safari/537.36"
)
driver = webdriver.Chrome(
service=ChromeService(ChromeDriverManager().install()), options=options
)
driver.get(url)
# --- Wait for Page to Load ---
try:
wait = WebDriverWait(driver, 20) # Wait up to 20 seconds
# Wait for the main container of flight results to be present
wait.until(EC.presence_of_element_located((By.CSS_SELECTOR, 'div.zISZ5c')))
except Exception as e:
print(f"Error waiting for flight results: {e}")
print("The website's structure may have changed, or the page didn't load.")
driver.quit()
return []
# --- Parse Page Content ---
soup = BeautifulSoup(driver.page_source, 'html.parser')
driver.quit() # Quit the driver as soon as it's no longer needed
# --- Extract Flight Data --
flights_data = []
flight_elements = soup.select('li.pIav2d') # Selector for each flight item
if not flight_elements:
print("No flight elements were found. The CSS selectors may be outdated.")
return []
for flight in flight_elements:
# Selectors for individual data points within a flight item
airline = flight.select_one('div.sSHqwe')
departure_time = flight.select_one('span[aria-label*="Departure time:"]')
arrival_time = flight.select_one('span[aria-label*="Arrival time:"]')
duration = flight.select_one('div.gvkrdb')
stops = flight.select_one('div.EfT7Ae span')
price = flight.select_one('div.FpEdX span')
flights_data.append({
"airline": airline.get_text(strip=True) if airline else "N/A",
"departure_time": departure_time.get_text(strip=True) if departure_time else "N/A",
"arrival_time": arrival_time.get_text(strip=True) if arrival_time else "N/A",
"duration": duration.get_text(strip=True) if duration else "N/A",
"stops": stops.get_text(strip=True) if stops else "N/A",
"price": price.get_text(strip=True) if price else "N/A",
})
return flights_data
if __name__ == "__main__":
# Note: Google Flights URLs can be volatile. This URL may need to be updated.
target_url = "https://www.google.com/travel/flights/search?tfs=CBwQAhoeEgoyMDI2LTAxLTEyagcIARIDSkZLcgcIARIDU0ZPGh4SCjIwMjYtMDEtMjlqBwgBEgNTRk9yBwgBEgNKRktAAUABSAFwAYIBCwj___________8BmAEB"
output_filename = "Google_flights_data.csv"
# 1. Scrape the data
print("Scraping flight data...")
scraped_flights = scrape_google_flights(target_url)
# 2. Save the results to a CSV file
if scraped_flights:
df = pd.DataFrame(scraped_flights)
df.to_csv(output_filename, index=False)
print(f"\nSuccessfully scraped and saved {len(scraped_flights)} flights to '{output_filename}'.")
else:
print("Scraping did not return any data.")
How to deploy your scraper to Apify
Although running the above Google Flights scraper locally is effective, it’s not the most efficient way to collect data regularly, as it can’t be truly automated; you’d have to run the script each time manually to scrape real-time data.
But if you deploy it on a platform like Apify, you can schedule it to run automatically on a daily, weekly, or monthly basis, with no human input required. Plus, you get the chance to store and download the data conveniently.
Follow these steps to deploy the scraper on Apify:
#1. Create an Apify account
You can set up a free account with your email or GitHub. No credit card required.
#2. Create a new Actor
- First, install Apify CLI using NPM or Homebrew in your terminal
- Create an Actor using Apify’s Python template:
apify create google-flights-actor --template python-selenium
- Then, you can navigate to the created folder.
cd google-flights-actor
#3. Replace the code in main.py script
To deploy the Google flights scraper code on Apify, you’ll need to make some changes as follows:
- Include
apifyandasynciomodules in anasync def main()function, to initialize the actor and to use Apify’s features like logging, input, and output. - Add
--no-sandboxand--disable-dev-shm-usagetoChromeOptionsfor Selenium to run inside Apify's sandboxed Docker environment. - Replace all the
print()statements with Actor.log functions to make sure logs appear correctly in Apify console. - Use
await Actor.call(scrape_google_flights,...)to run the synchronous scraping function, preventing the synchronous, long-running web scraping code from blocking the actor’s main asynchronous process. - Replace Pandas dataframe creation and
to_csv()logic withActor.push_data()to push the collected data directly to the default Apify output, where you can view and export it in various formats (CSV, JSON, etc.).
Locate the main.py file in the src folder of your actor’s folder and change it to this modified script, found on GitHub.
#4. Edit the requirements.txt with necessary libraries
webdriver_manager
apify-client
beautifulsoup4[lxml]
#5. Deploy
- Type
apify loginto log in to your account. You can either use the API token or verify through your browser. - Once logged in, type
apify pushand you’re good to go.
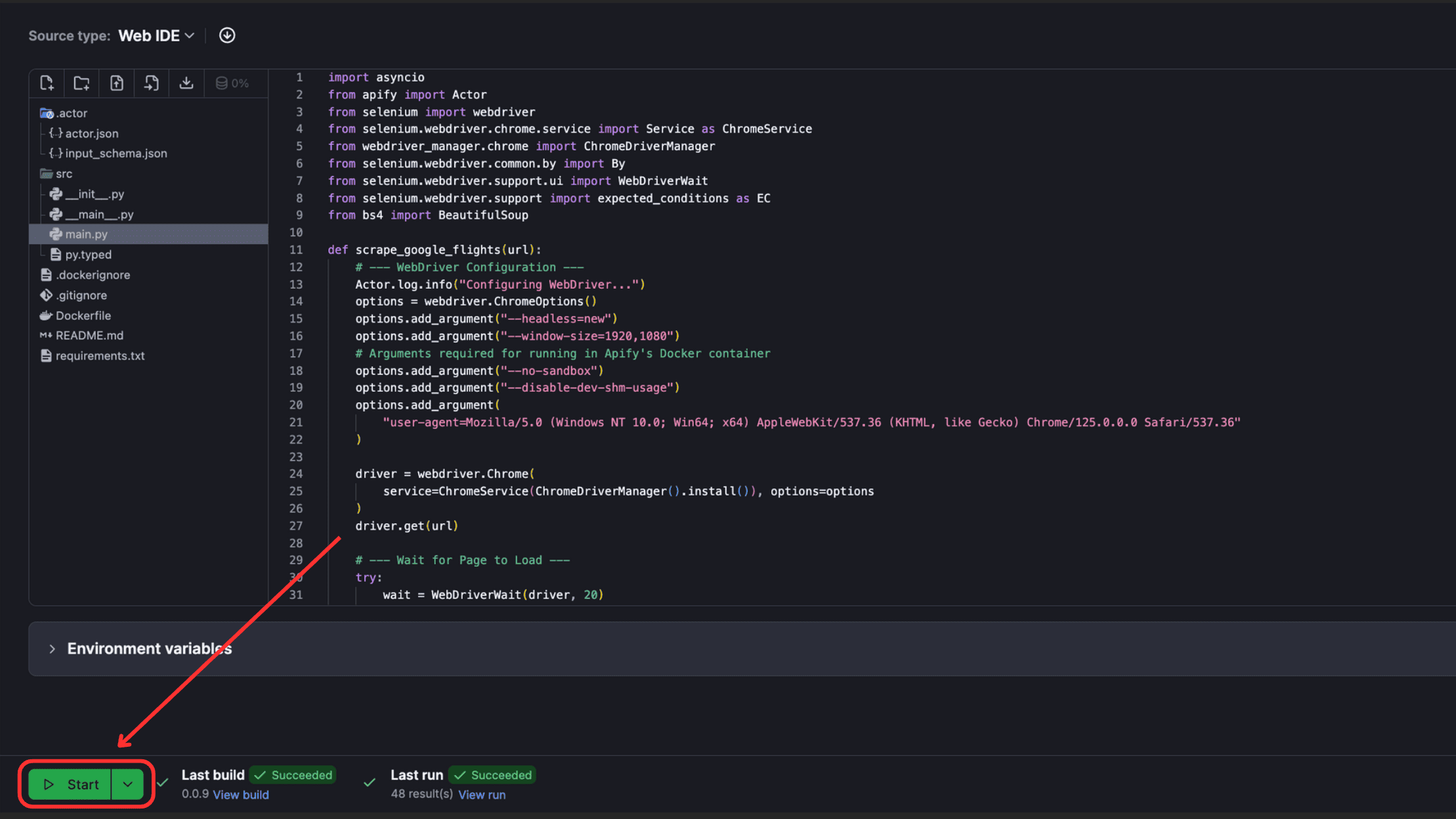
If you visit Apify Console after the deployment, you’ll see your scraper on the Actors tab. Click on your Actor and then click the “Start” button at the bottom.
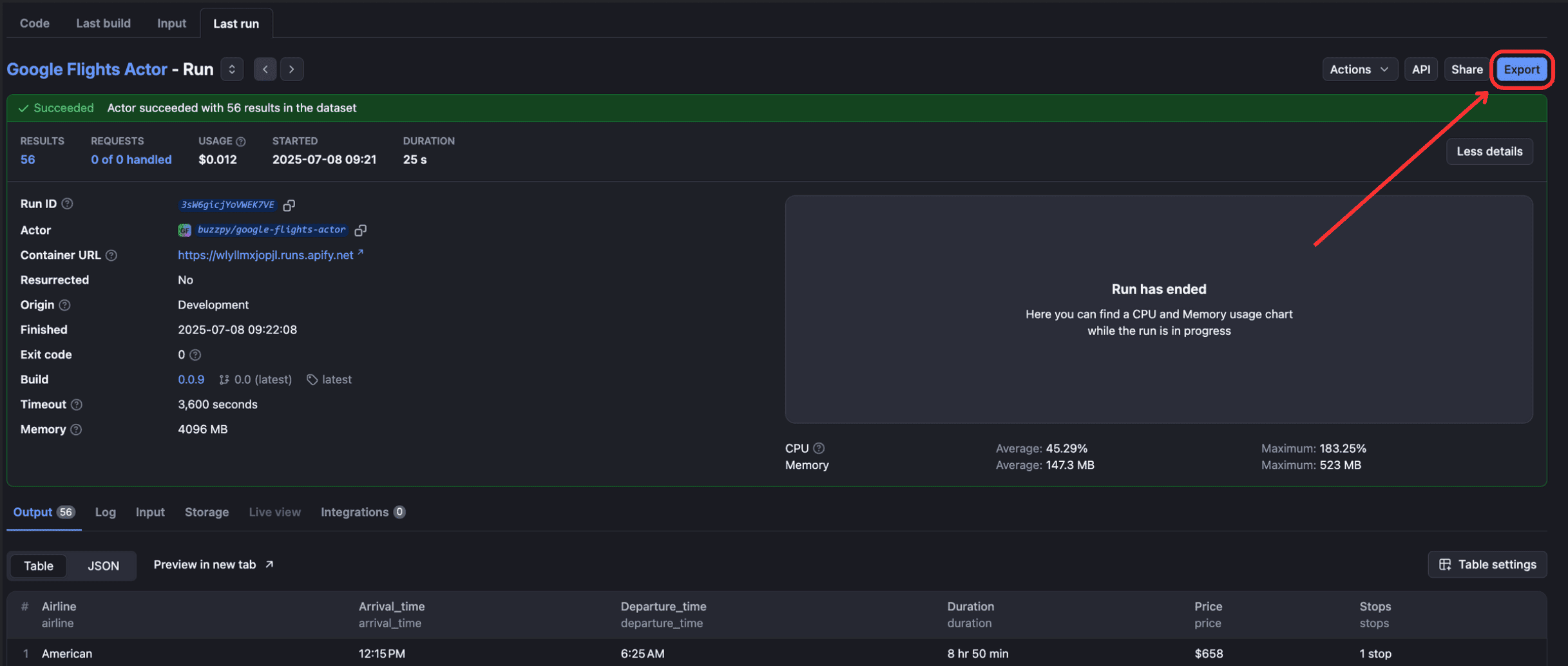
When run, you’ll see the output of the Actor on the “Output” tab.
To view and download output, click “Export Output”.
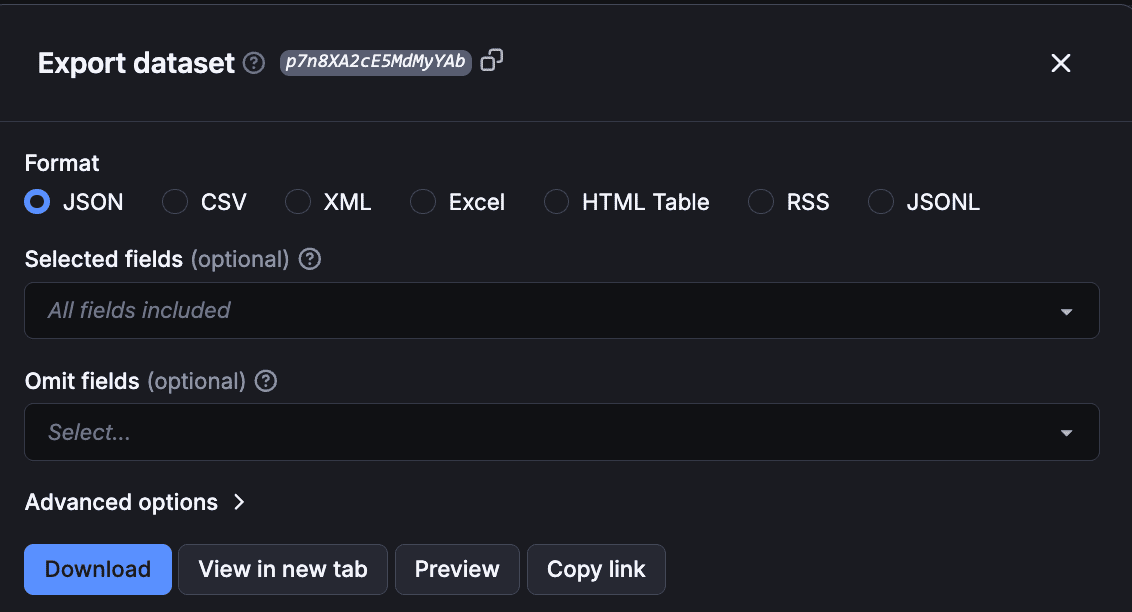
Using the export option, you can select/omit sections and download the scraped Google Flights data in different formats such as CSV, JSON, Excel, etc.
To schedule your Actor (to run automatically without human input), click the three dots (•••) in the top-right corner of the Actor dashboard > Schedule Actor option.
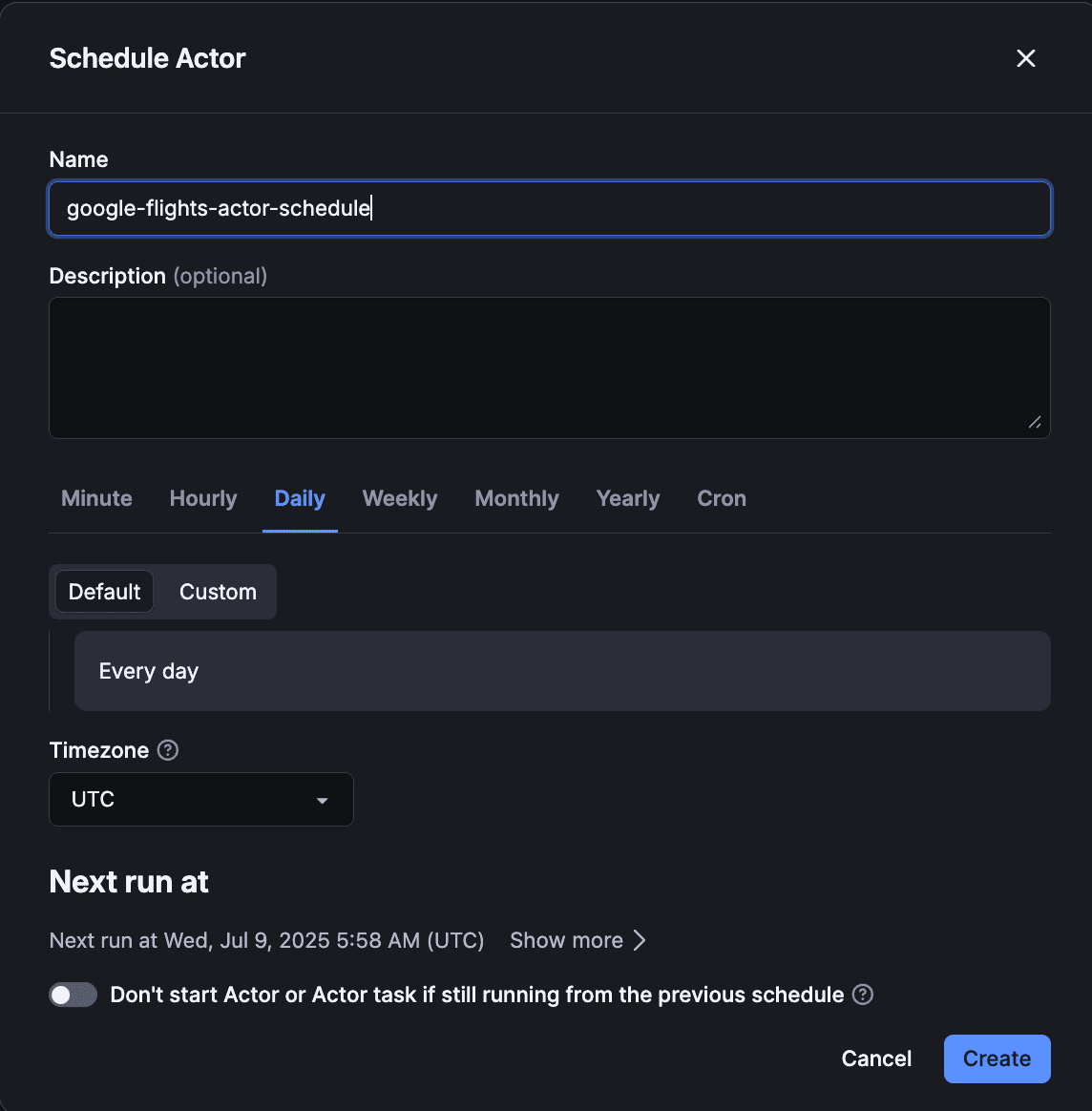
And congrats, you have successfully deployed your Google Flights scraper on Apify!
Recap
In this tutorial, we created a Google Flights scraper with Python’s two powerful web scraping libraries— Selenium (to load the URL dynamically) and BeautifulSoup (to parse the HTML of the website). It can successfully extract information about Flights of any trip, just with their URL.
Deploying the scraper to Apify enables cloud scaling, rotating proxies, webhook alerts, and hands‑free scheduling. That way, you can automate monitoring for fares or deal alerts, without managing a single Chrome instance yourself.
FAQs
Is it legal to scrape Google Flights?
Yes, it’s legal to scrape Google Flights for personal, non-commercial purposes like price tracking or academic research. But make sure you always operate at a respectful crawl rate and focus on gathering data for your own analysis or price-watching.
Why scrape Google Flights?
Scraping Google Flights can help you track flight prices over time, analyze pricing trends for data projects, or integrate real-time flight data into a custom dashboard. Overall, it’s a great platform for gathering comprehensive, up-to-date flight information.