


Crunchbase is easily one of the largest private and public company data providers out there. The official Crunchbase API has its limits, so using an alternative such as Crunchbase Scraper will help you extract Crunchbase data rapidly, at scale, and whenever you need it.
With a vast database of business information, Crunchbase has firmly established itself as a go-to online platform for professionals, investors, and entrepreneurs. It offers users the opportunity to access and manage detailed profiles of companies, discover potential investment opportunities, and stay informed about the latest developments in the business world. Extracting and harnessing this wealth of public information efficiently can be achieved through web scraping Crunchbase.
👩💼 What data can I get with Crunchbase Scraper?
Crunchbase Scraper is essentially a tool for web scraping – extracting visible data from websites and downloading it in a structured format. The scraper can get the following Crunchbase data for you:
- Organization details : number of employees, about page, technology, summary, people working, or the investment details of an organization.
- Person details: title, name, CB Rank, primary organization, jobs, or the related hubs of a person.
- Event details: speakers, name, location, date, venue, and registration links of an event.
- Hub details: the number of founders, name, founded date, acquired percentage, and more.
- Data by keyword: use location keywords to search specific search lists.
All in all, this scraping tool is created to extract data from Crunchbase pages, presenting them to you in an organized list, ready for download as structured data. All you have to do is type in the name of the company or provide a list of pages you wish to extract data from. The scraper will visit the Crunchbase.com website for you and extract that data into a dataset making the process quick, straightforward, and cost-effective.
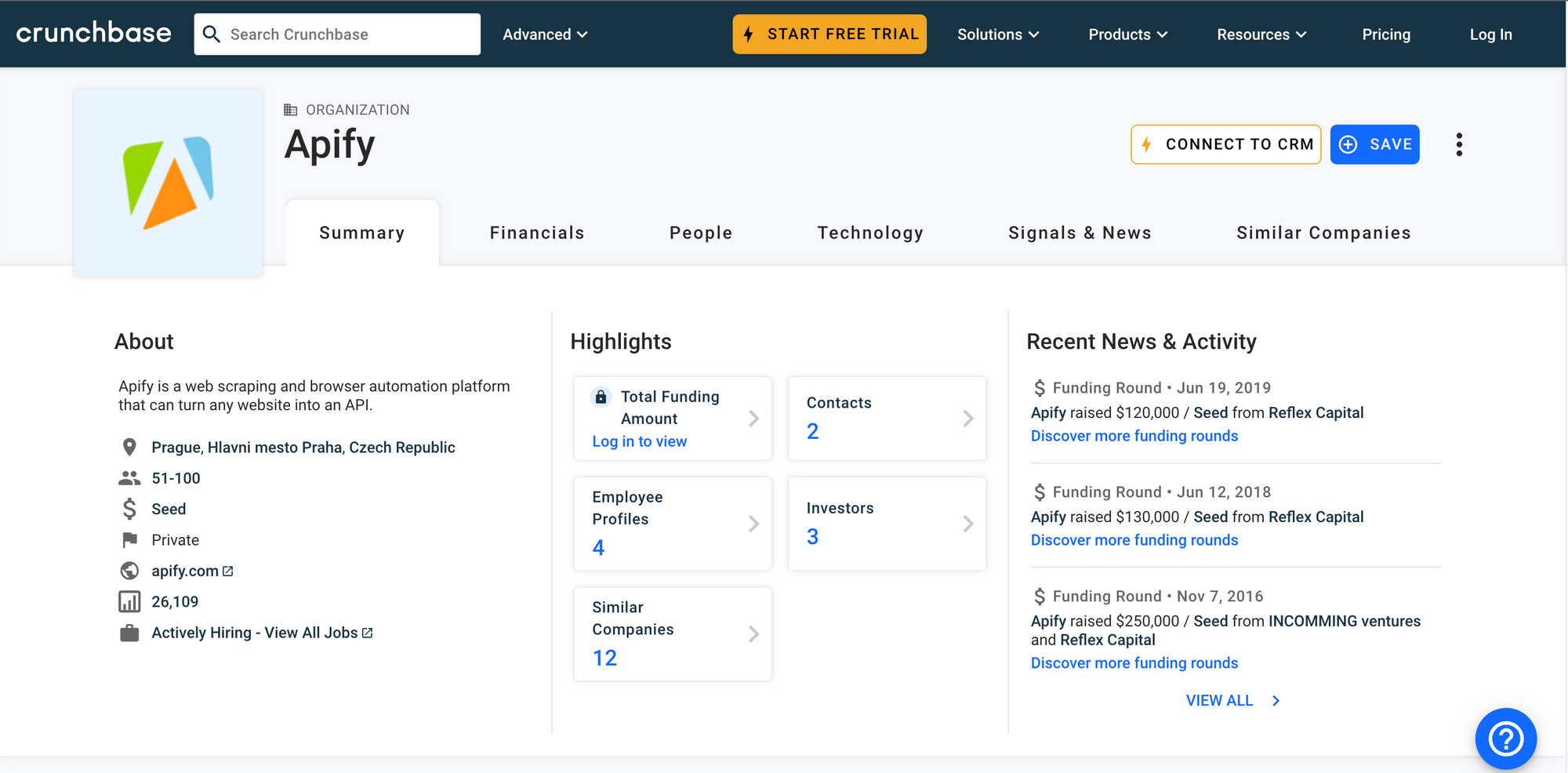
👨🏼💼 Why would anybody scrape organizations on Crunchbase?
Having Crunchbase data about companies, or you're interested in offers numerous advantages. Here are the four most frequent use cases:
- Investment research. For investors, having a complete overview of companies of interest streamlines the research process. Instead of manually searching for company pages each time you explore investment opportunities, you can maintain an easily accessible list. This list can be organized in a spreadsheet or database, enabling quick access to company profiles and efficient investment analysis.
- Due diligence. Crunchbase is a valuable platform for evaluating potential investment targets. Having their Crunchbase profiles readily available simplifies the process of reviewing their financials, funding history, and key personnel.
- BizDev. Crunchbase serves as a valuable networking tool for building a database of potential business partners or clients. Equipping your sales or business development team with a list of Crunchbase pages enhances efficiency, as manual searches for Crunchbase profiles can be time-consuming. With this scraper, your team can quickly access contacts, allowing them to focus on forging partnerships and generating business leads.
- Market research. Data extracted from Crunchbase will enable you to stay informed about your competitors and industry trends. Having a comprehensive overview of Crunchbase company or people profiles in such conditions is invaluable.
 Mariachiara Faraon
Mariachiara Faraon
Don't stop at Crunchbase, scrape LinkedIn company profiles as well.
📋 How to scrape Crunchbase company pages: quick guide
Using Crunchbase Scraper 🔗 is quite straightforward even if you've never extracted data from the web before. Here's a step-by-step guide:
Step 1. Find Crunchbase Scraper
Visit the Crunchbase Scraper page on the Apify Store and click the Try for free button.
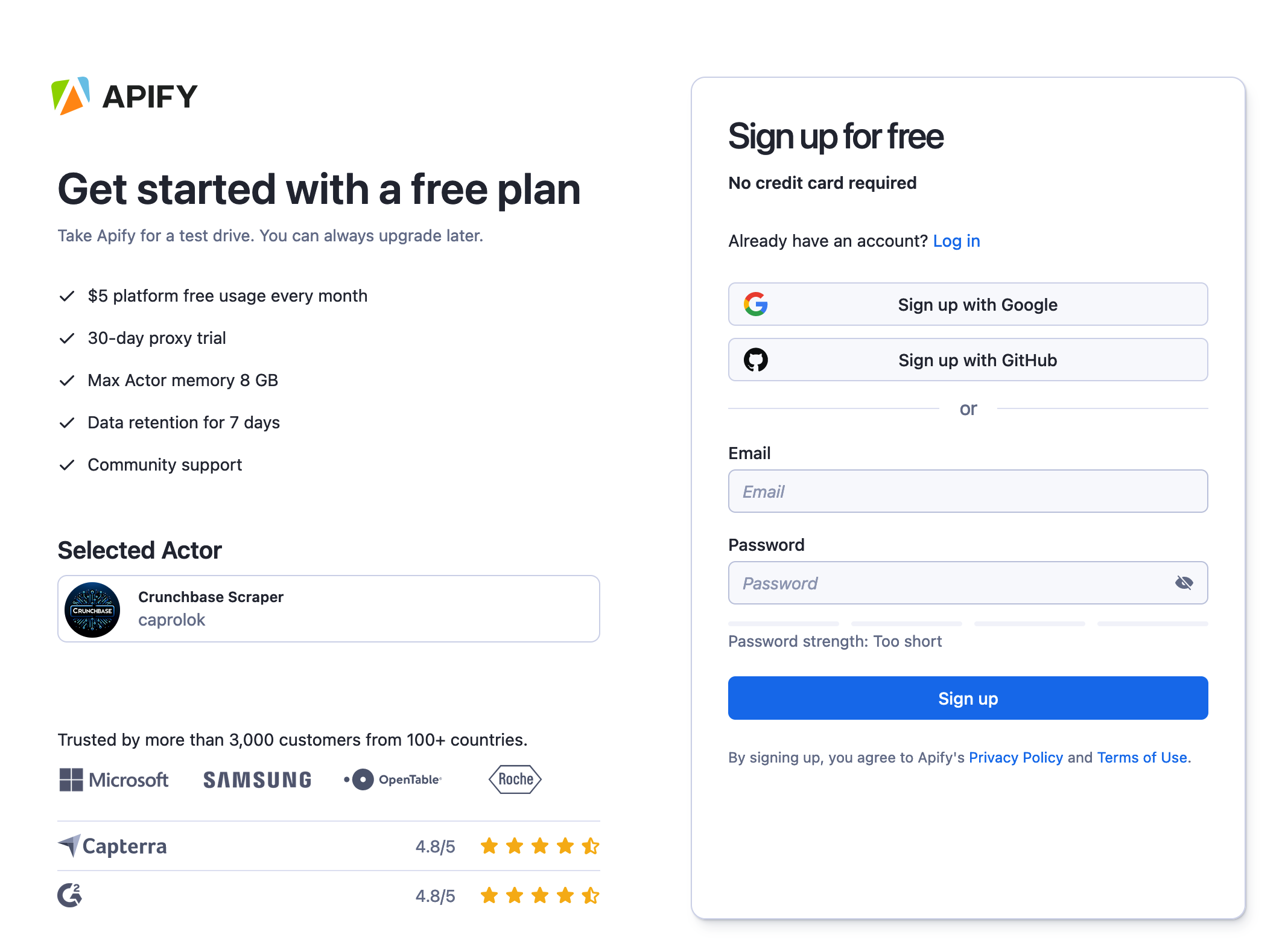
If you're not signed in yet, you'll be directed to the sign up page where you can use your email, Google, or GitHub account to register.
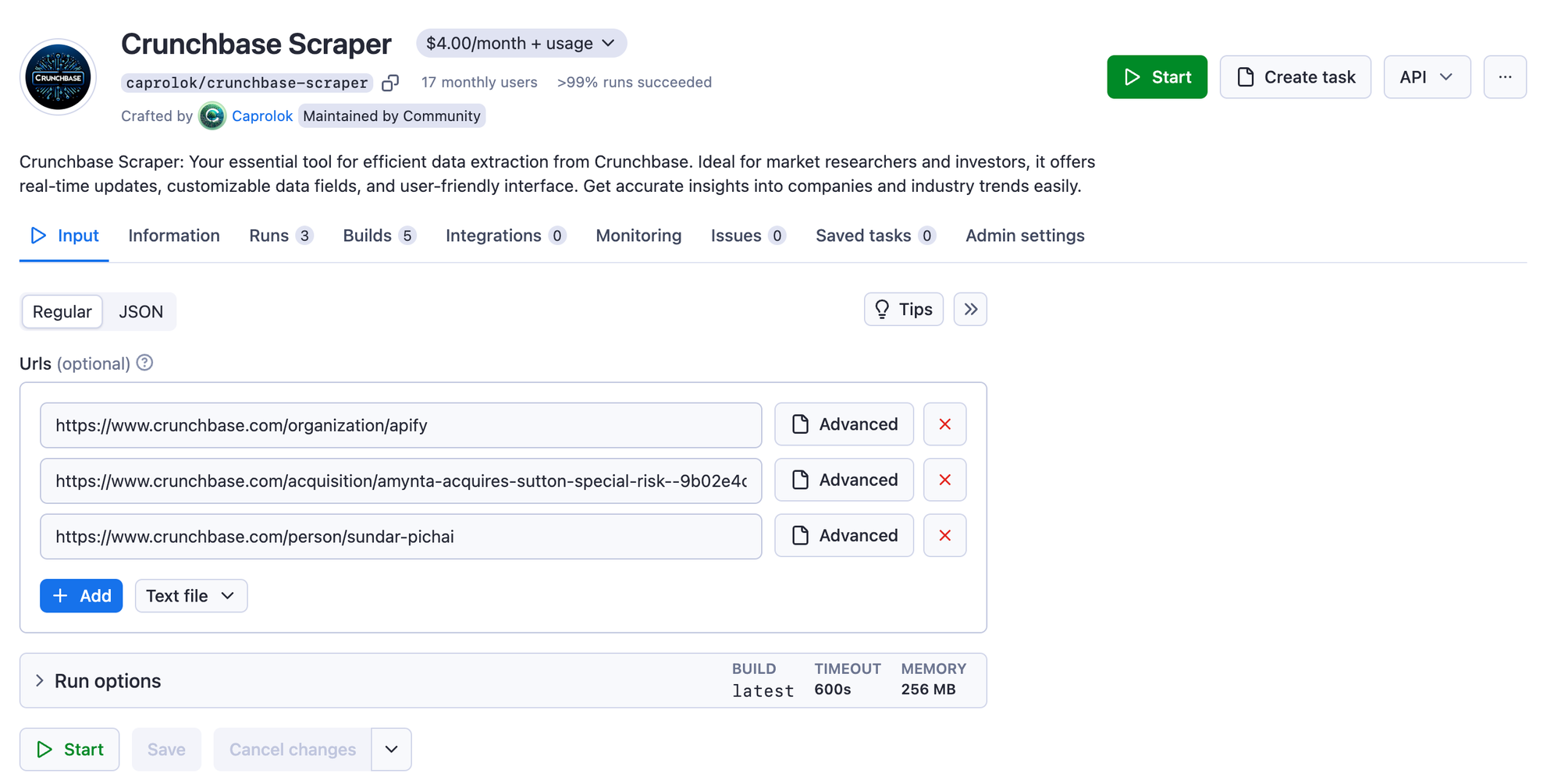
Step 2. Choose search terms or URLs
The easiest way to extract data from Crunchbase isby using direct URLs from Crunchbase.com website. Head over to the website itself and pick an organization, a person, a hub, or an event you want to extract data from. Or pick all of them at once – it won't make a difference for this scraping tool. Copy the URLs of those pages and paste them into the Start URLs field.
Step 3. Click Start to begin scraping
Once you've configured your inputs, click the Start button. The task status will change to Running 🏃🏻♀️, and you'll only have to wait a short while before it switches to Succeeded 🏁.
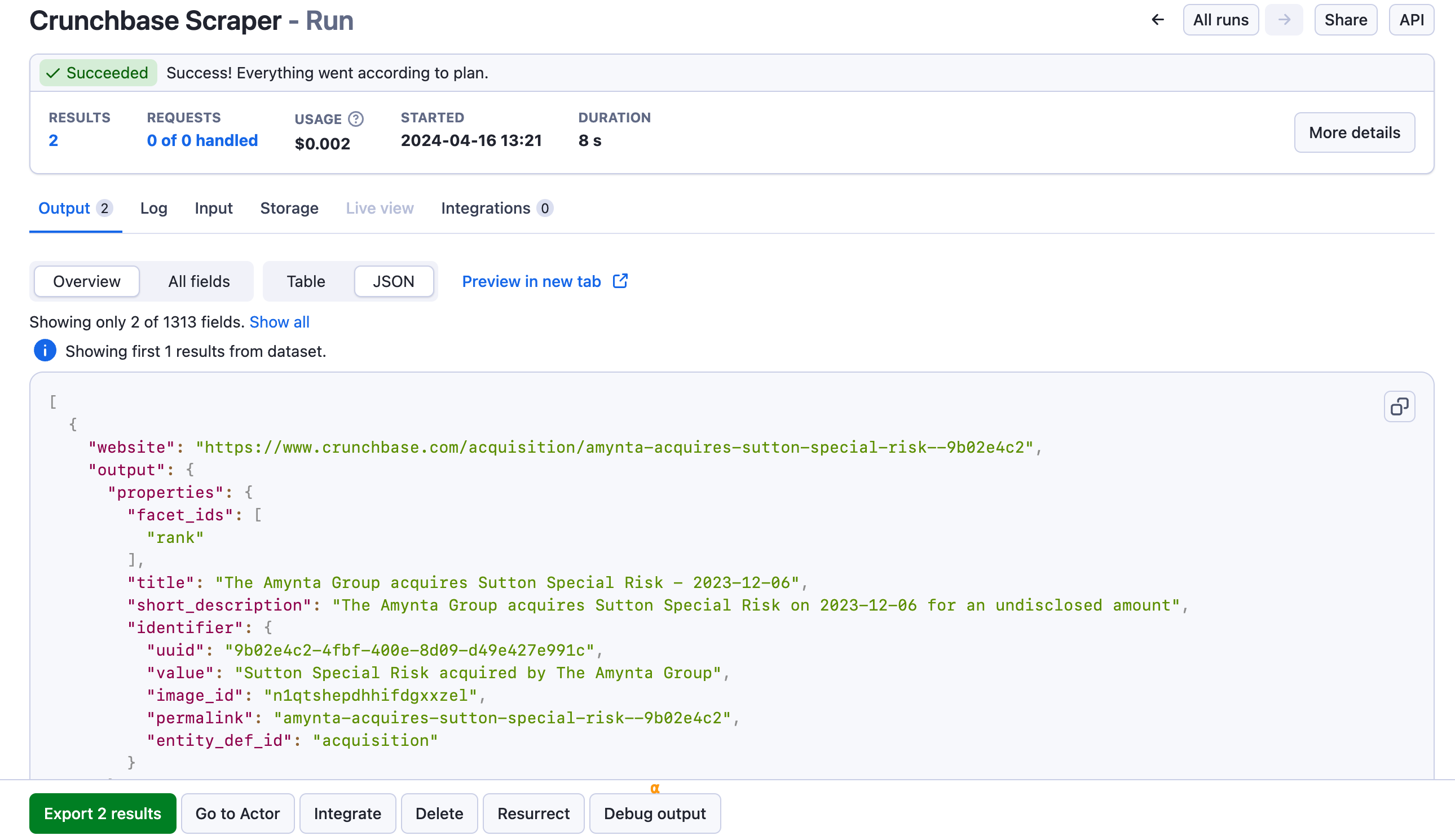
Step 4. View scraped data
The scraper will generate results corresponding to the number of companies you specified in the input phase. To access the data, navigate to the Storage tab, where you'll find it in various formats, including JSON, CSV, Excel, XML, and RSS feed. You can preview or view the data in a new tab if it's extensive.
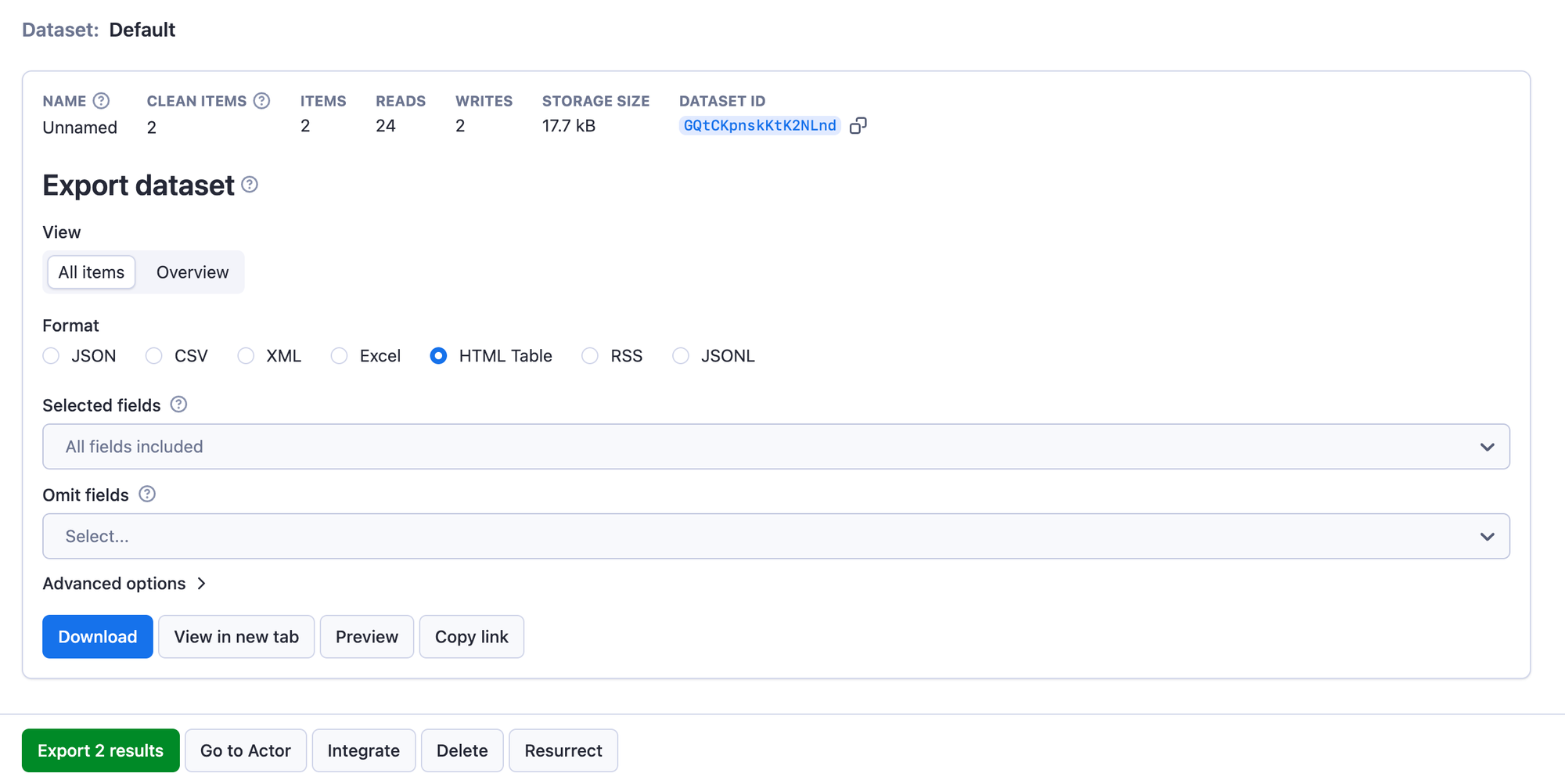
Step 5. Download data in Excel, JSON, HTML or CSV
As mentioned, the search will get results for each company or page you listed. You can preview the data or view it in a new tab. Finally, you can pre-filter it and download it for further use in apps, spreadsheets, and data projects.
Crunchbase scraping tools provide a powerful means to access and leverage Crunchbase's extensive database of business information. Whether you're an investor, market researcher, business analyst, or entrepreneur, these tools streamline the process of obtaining Crunchbase data for companies and individuals of interest. The possibilities for efficiently managing and utilizing this data are endless, making web scraping a valuable addition to your professional toolkit.
So this is how Crunchbase Scraper can help you get business information from Crunchbase's extensive database. Whether you're looking to invest, do a bit of market research, analyze projections, or start your own company, tools like this web scraper are a great way to save time and make smarter decisions. The possibilities for efficiently managing and using data extracted from Crunchbase are endless, making web scraping a valuable addition to your professional toolkit.
Natasha Lekh
And complete your collection of company profiles with Indeed.
Check them out!
🔍 How to scrape Crunchbase using search terms?
Apify Store provides several Crunchbase scrapers designed to diversify the process of gathering public Crunchbase data. To scraper Crunchbase's search results, pick a scraper that provides that way of scraping, like Crunchbase Search Scraper. You can use this scraper differently – choose keywords you want to scrape by in Company and choose a search category in Process




