


Hey, we're Apify. You can build, deploy, share, and monitor any data extraction tools on the Apify platform. Check us out.
If you’re thinking of gathering many articles about one or several topics (say, the latest news on the economy) and then building a corpus from them, simply doing a Google search on a selected website every time is highly impractical.
A faster and more efficient way to extract content from a website for analysis and research is with a tool designed to collect and download news articles. One such tool is Smart Article Extractor, and in this article, we'll show you how to use it:
We'll break it up into two sections:
- A detailed breakdown of the features and how to configure Smart Article Extractor.
- A simple step-by-step demonstration of Smart Article Extractor downloading news articles.
How to extract text and download news articles
First, we'll take you through the configuration options of the extractor, and then we'll show you a real-world example of scraping and downloading data from a website. So, let’s go through the different options step by step.

1. Choose start URLs or article URLs
Once you've logged in to your Apify account, you can go to Smart Article Extractor and configure the scraper in Apify Console.
Begin by choosing start URLs in the website/category URLs input field. Article pages are detected and crawled from these, and they can be any category or subpage URL, for example, https://www.bbc.com/
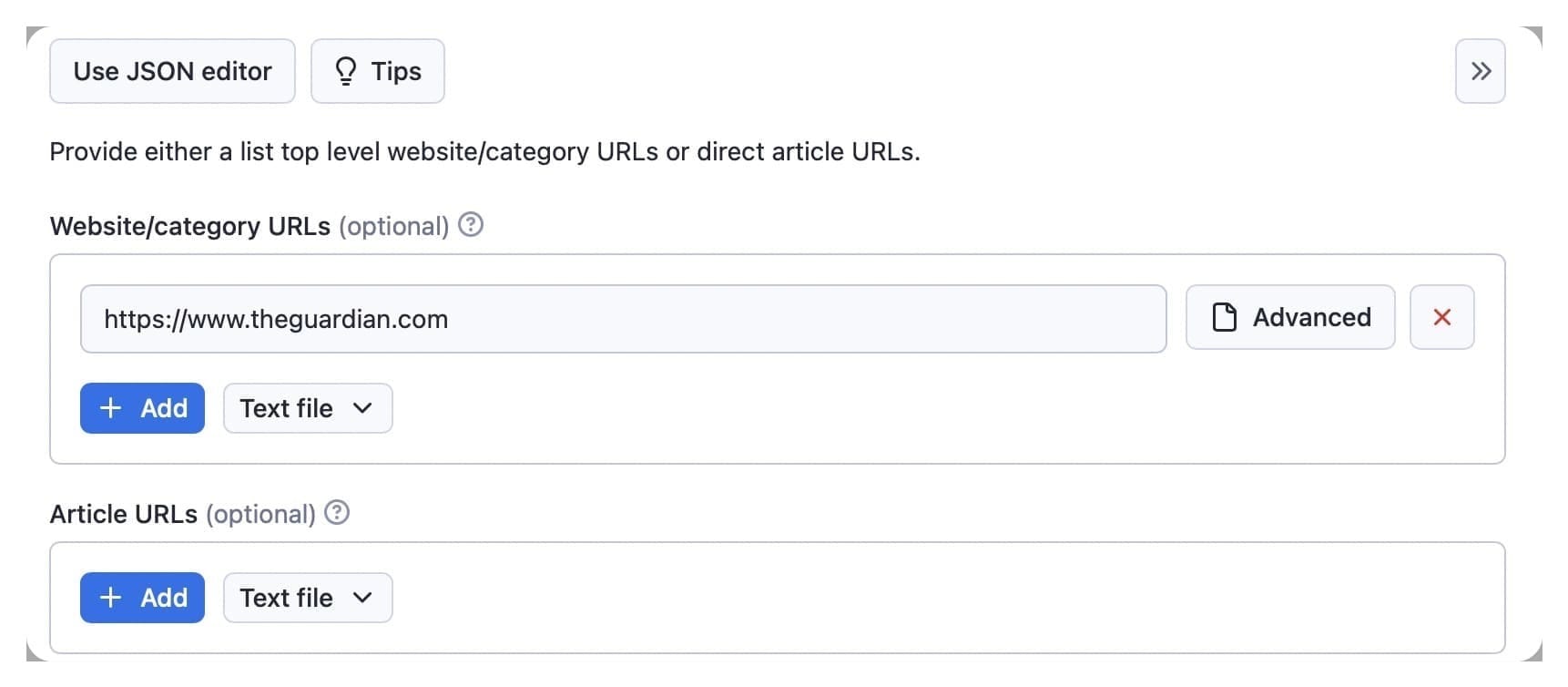
Alternatively, you can insert article URLs in the second input field. These are direct URLs for the articles to be extracted, for example, https://www.bbc.com/uk-62836057. No extra pages are crawled from article pages.
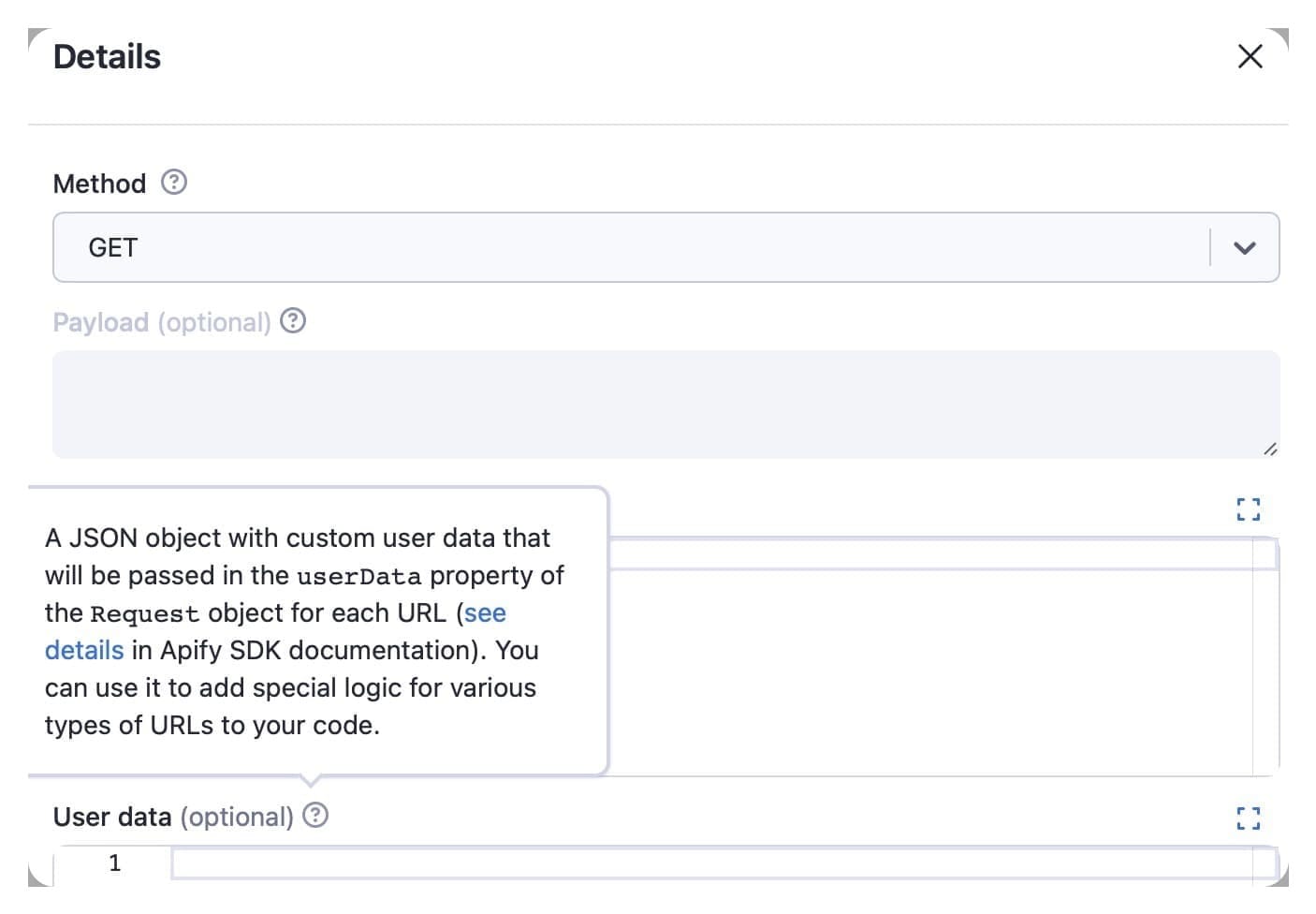
Use the advanced options to select the HTTP method to request the URLs and the payload sent with the HTTP request. You also have header and data user options where you can insert a JSON object.
2. Select optional Booleans

You have two only new articles options, one for small runs and a saved per domain option for the use of the extractor on a large scale. With these options, the extractor will only scrape new articles each time you run it. For small runs, scraped URLs are saved in a dataset, while the per domain option saves scraped articles in a dataset and compares them with new ones.
If you go with the default only inside domain articles option, the extractor will only scrape articles on the domain from where they are linked. If the domain presents links to articles on different domains, e.g., https://www.bbc.com/ vs. https://www.bbc.co.uk, the extractor will not scrape them.
The enqueue articles from articles option allows the scraper to extract articles linked within articles. Otherwise, it will only scrape articles from category pages.
The extractor will scan different sitemaps from the initial article URL with the find articles in sitemaps option. Because this can lead to loading a vast amount of data, including old articles, the time and cost of the scraper will increase. Instead, we recommend using the optional array, sitemap URLs, below.
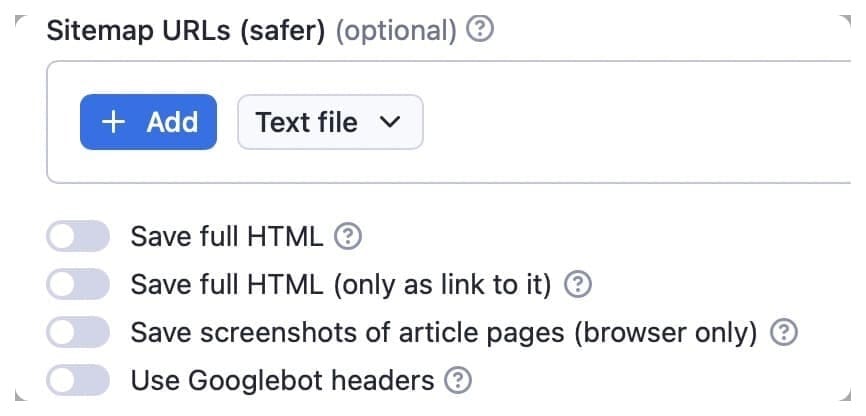
If you’re not sure what a sitemap URL is, it's an XML file that lists the URLs for a site. To get a sitemap URL, all you need to do is append /sitemap.xml to the domain URL.
With the sitemap URLs option, you can provide selected sitemap URLs that include the articles you need to scrape. Let’s say you want the sitemap URL for apify.com. Just insert https://apify.com/sitemap.xml.
You can choose to save the full HTML of the article page, but keep in mind that this will make the data less readable. The use Googlebot headers option allows you to bypass protection and paywalls on some websites, but this increases your chances of getting blocked, so use it with caution.
3. Choose what articles you want to extract
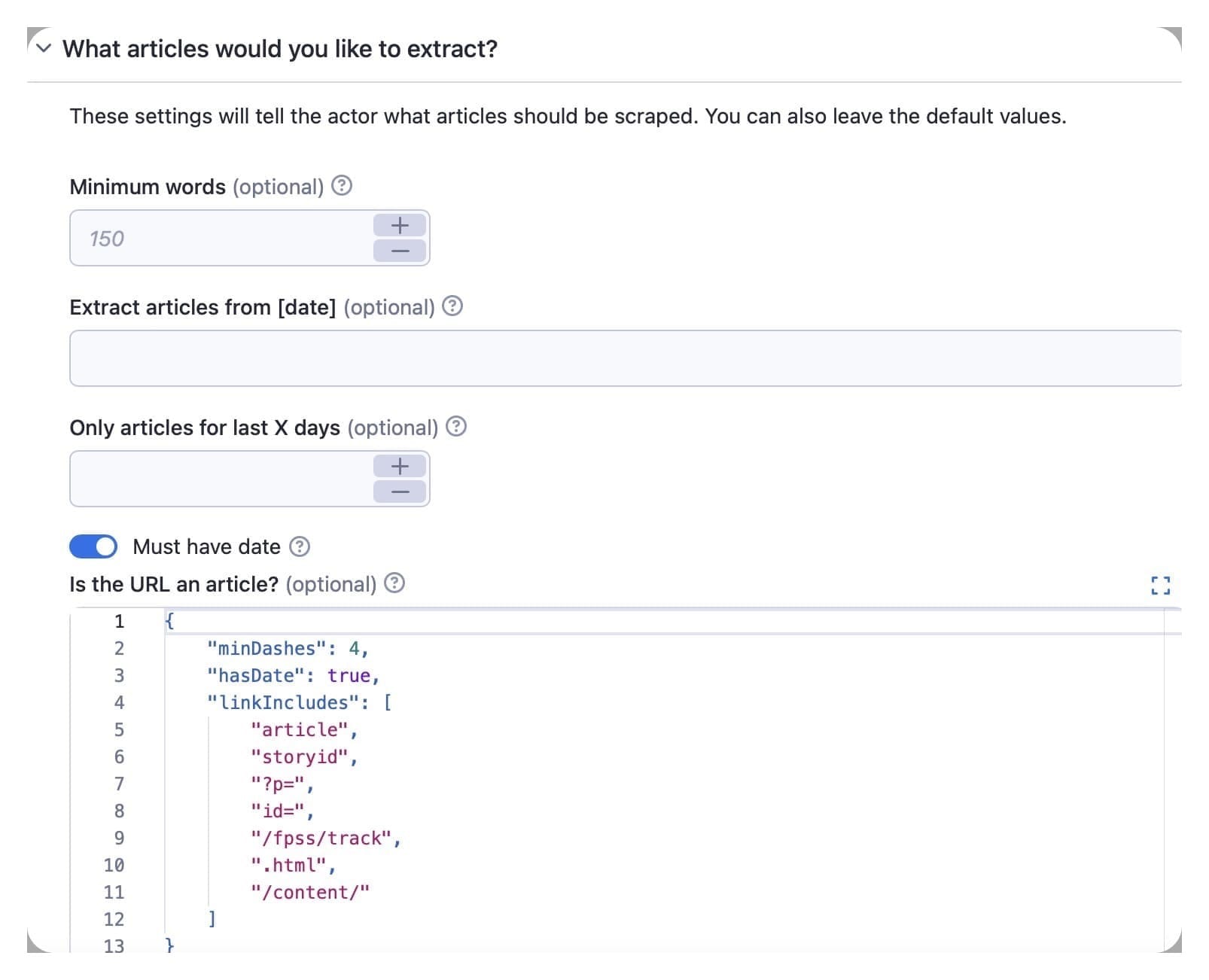
The default minimum word value is 150. This is typically sufficient for article recognition.
You can also use the date option to command the scraper to extract articles from a specific day. Otherwise, it will scrape all articles. You can use two formats for this option: YYYY-MM-DD, e.g., 2019-12-31, or a number type, e.g., 1 week, or 20 days.
The default must have date value lets the extractor know that it should only scrape articles with publication dates.
In the is the URL an article? option, you can input JSON settings to define what URLs should be considered articles by the scraper. If any are ‘true,’ it will open the link and extract the article.
4. Custom enqueuing and pseudo URLs
You can use the pseudo URLs function in the custom enqueuing box to include more links like pagination or categories. Read more about pseudo URLs here.
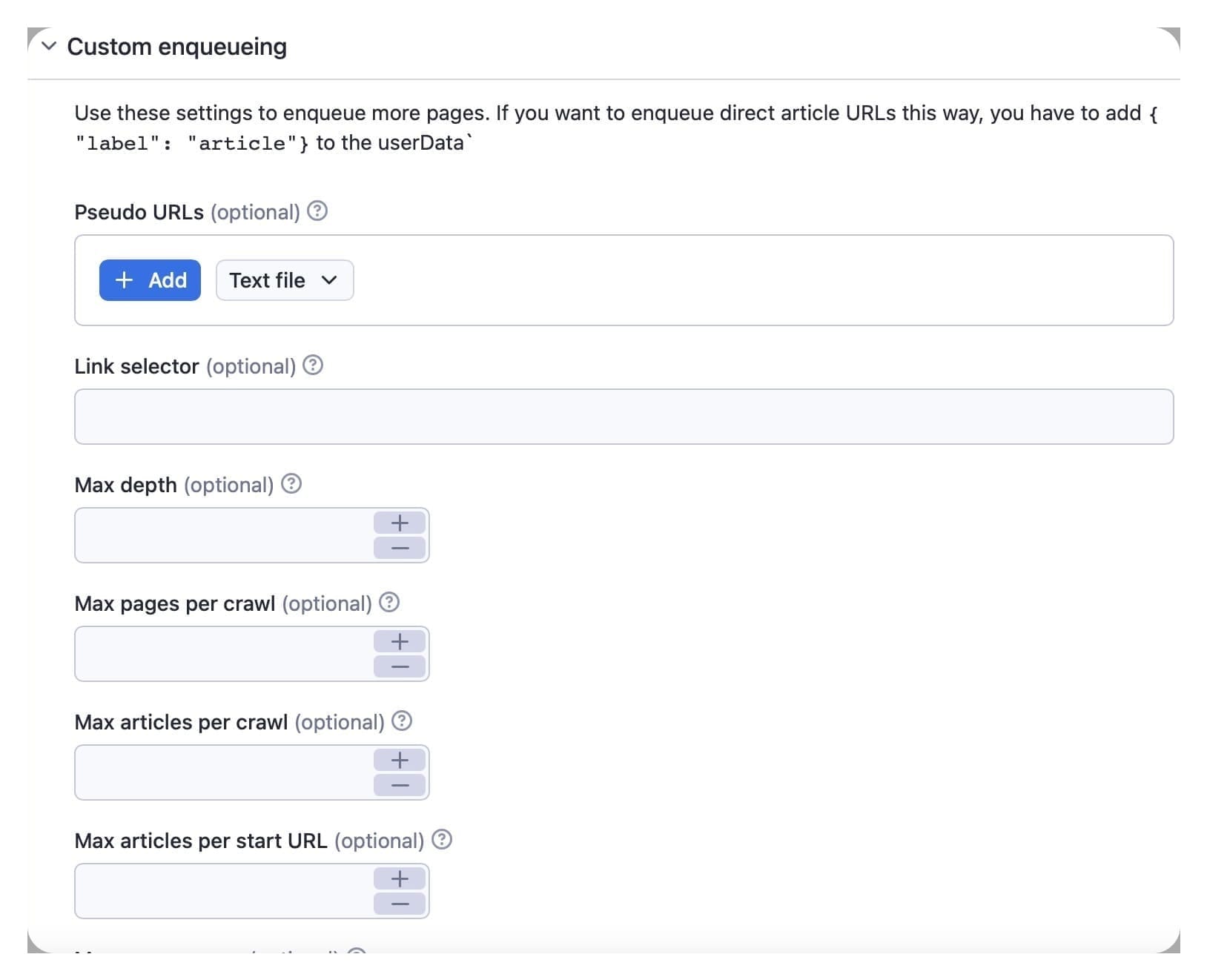
Use the link selector option to limit the tags which will be enqueued. To activate this option, you need to add a.some-class.
The max depth input is for the depth of crawling, i.e., how many times the scraper picks up a link to other web pages. If you input a number of total pages to be crawled in the max pages per crawl box, the extractor will stop automatically after reaching that number. The maximum number of total pages crawled includes the home page, pagination pages, and invalid articles.
The max articles per crawl option is the maximum number of valid articles the extractor will scrape and will stop automatically after reaching that number.
Use the max concurrency option to limit the speed of the scraper to avoid getting blocked.
5. Proxy configuration
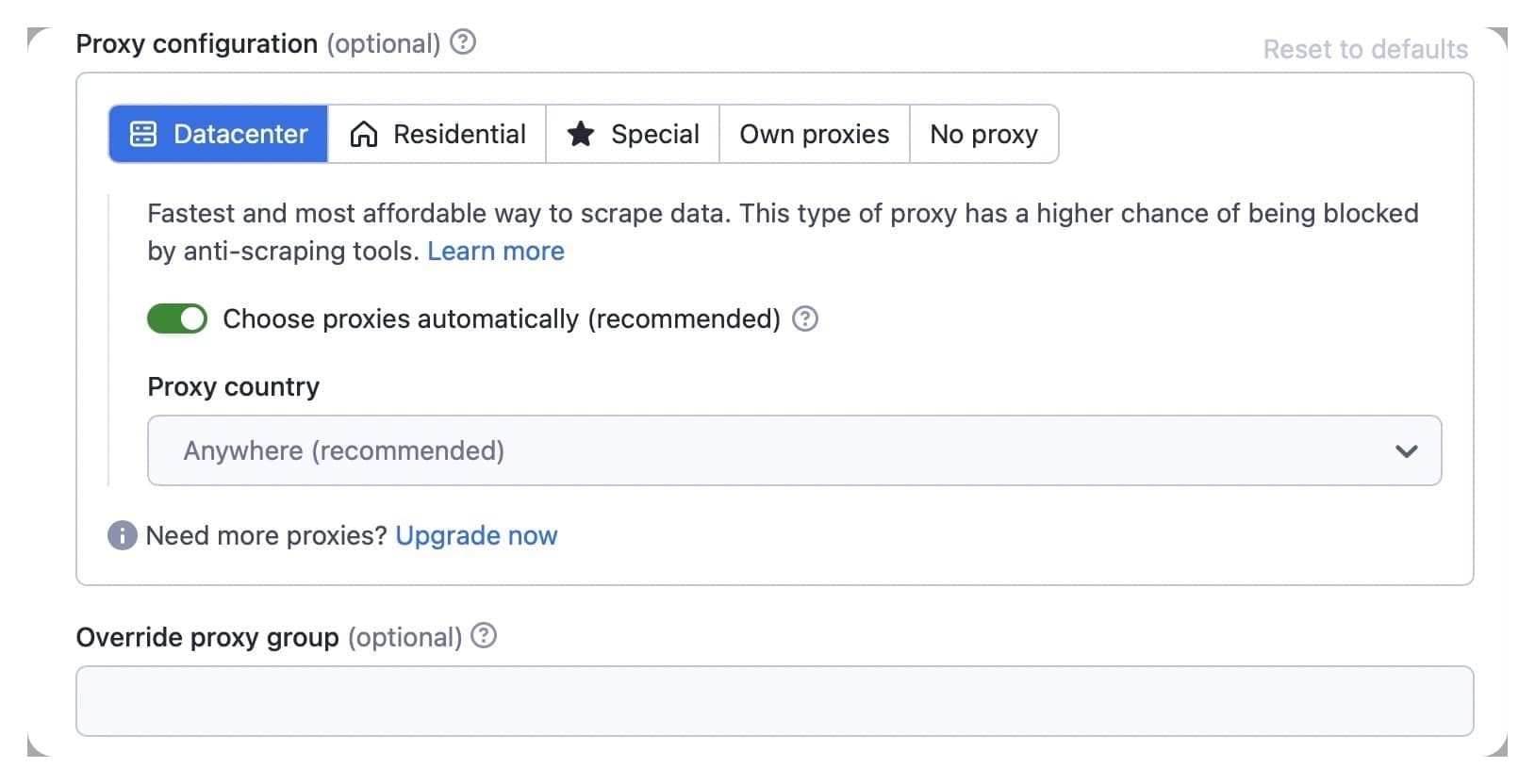
The default input is automatic proxy. If you want to use your own proxies, use the ProxyConfigurationOptions.proxyUrls option, and the configuration will rotate your list of proxy URLs.
6. Browser options
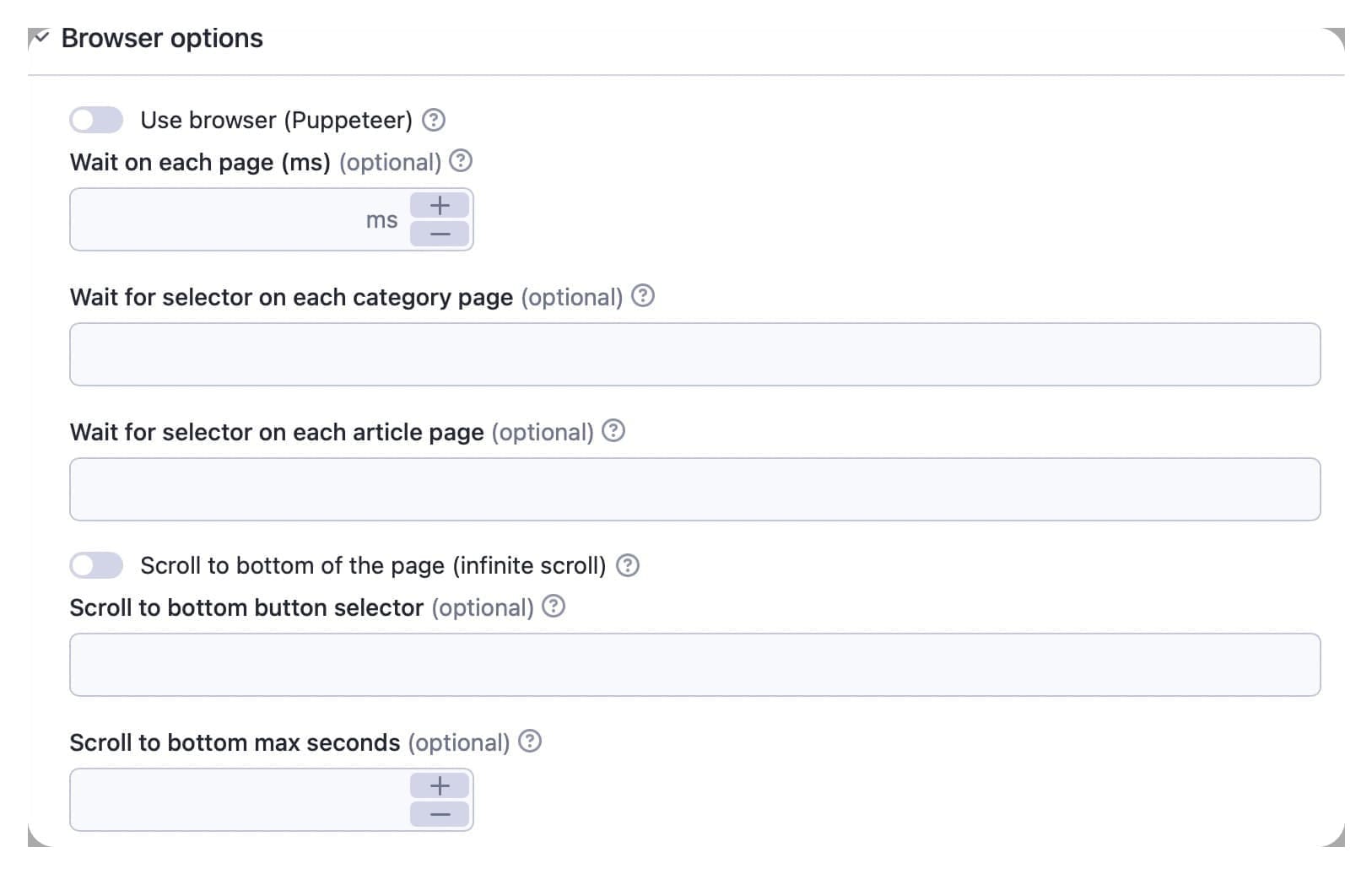
The use browser (Puppeteer) option is more expensive, but it allows you to evaluate JavaScript and wait for dynamically loaded data.
The wait on each page (ms) value is the number of milliseconds the extractor will wait on each page before scraping data. Wait for selector on each page is an optional string to tell the extractor for what selector to wait on each page before scraping the data.
7. Extend output function
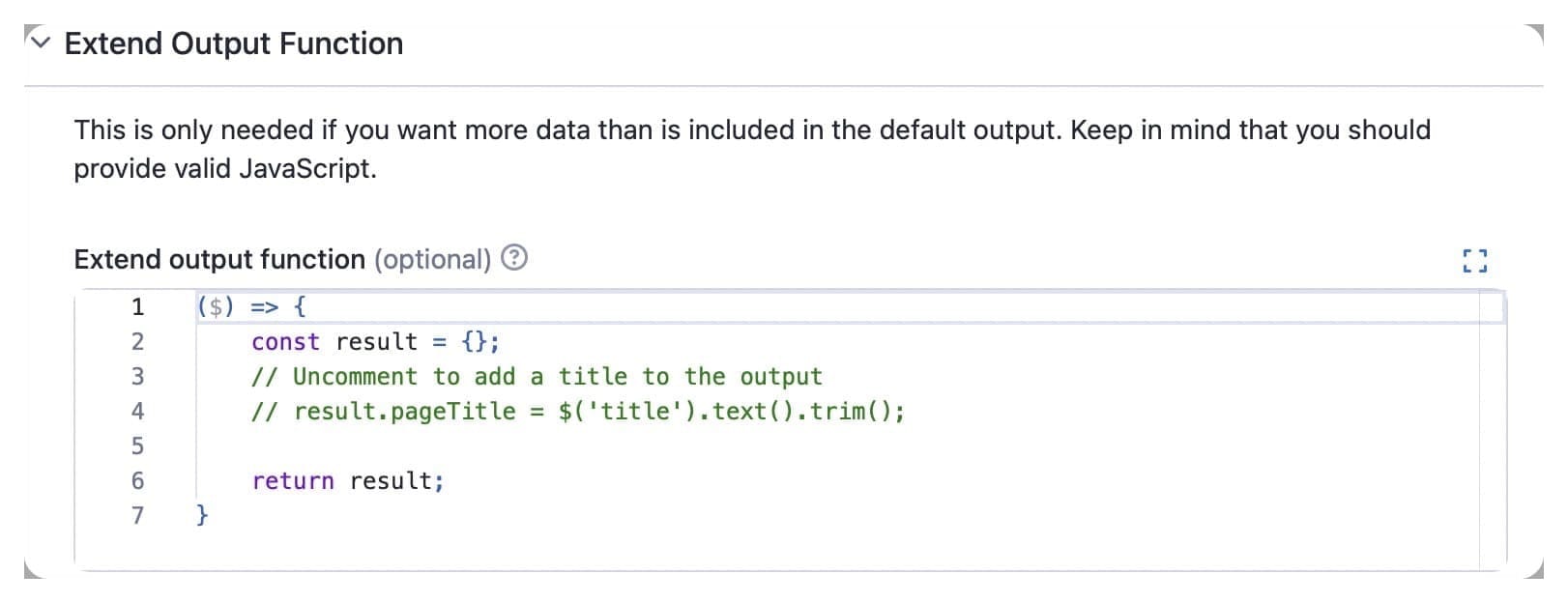
This function allows you to merge your custom extraction with the default one. You can only return an object from this function. This object will be merged/overwritten with the default output for each article.
8. Compute units and notifications
With the above options, you can command the scraper to stop running after reaching a certain number of compute units and to send notifications to specified email addresses when the number of CUs is reached.
9. Options
Finally, you can use the final box of options for the tag or number of the build you want to run (this can be something like latest, beta, or 1.2.34.), the number of seconds at which the scraper should time out (zero value means it will run until completion or forever), and the RAM allocated for the extractor in megabytes.
How to download news articles (example)
Now you've seen how Smart Article Extractor works, let's do a quick and simple step-by-step demonstration of the tool in action.
Step 1. Go to Smart Article Extractor on the Apify platform
If you still haven't signed up, don't forget to set up a free Apify account first. Then go to Smart Article Extractor on Apify Console.
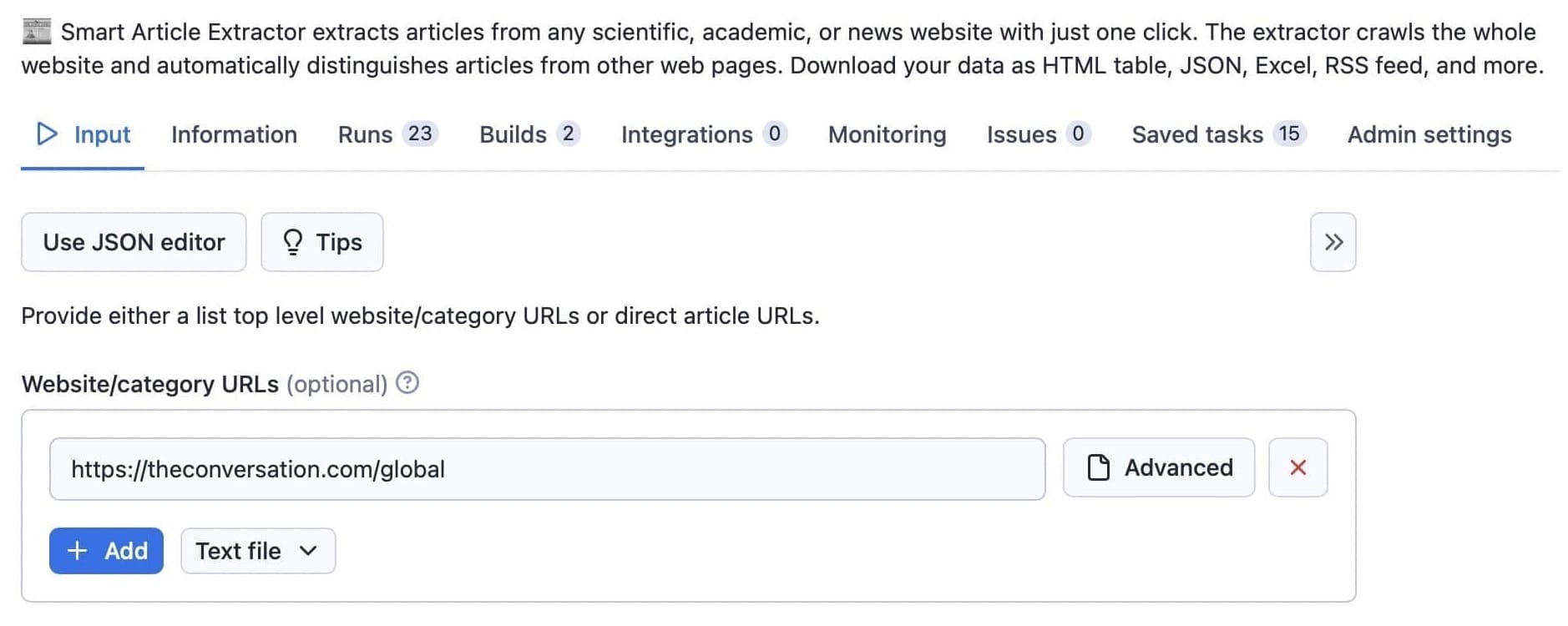
Step 2. Add URLs for the articles you want to download
We’ll scrape the start URL https://theconversation.com/global. If you keep the remaining default values, all you need to do is click Save & Start (step 4).
Step 3. Choose your settings (optional)
You can configure the tool for your specific case by following the step-by-step guide we covered earlier. Here are three of the most important options to keep in mind:
- You can select the publication dates from which you want articles to be extracted
- You can extend the search to pseudo URLs. Read more about pseudo URLs here.
- You can choose the minimum word count per article (the default 150 is the recommended minimum for article recognition)
Step 4. Start downloading articles
Once you’re happy with your configuration, or if you’re using the default settings, just click the Save & Start button. The extractor will now begin collecting articles. You will see the data in the log while the tool is running, but wait until the status has changed to succeeded before you try to download the information.
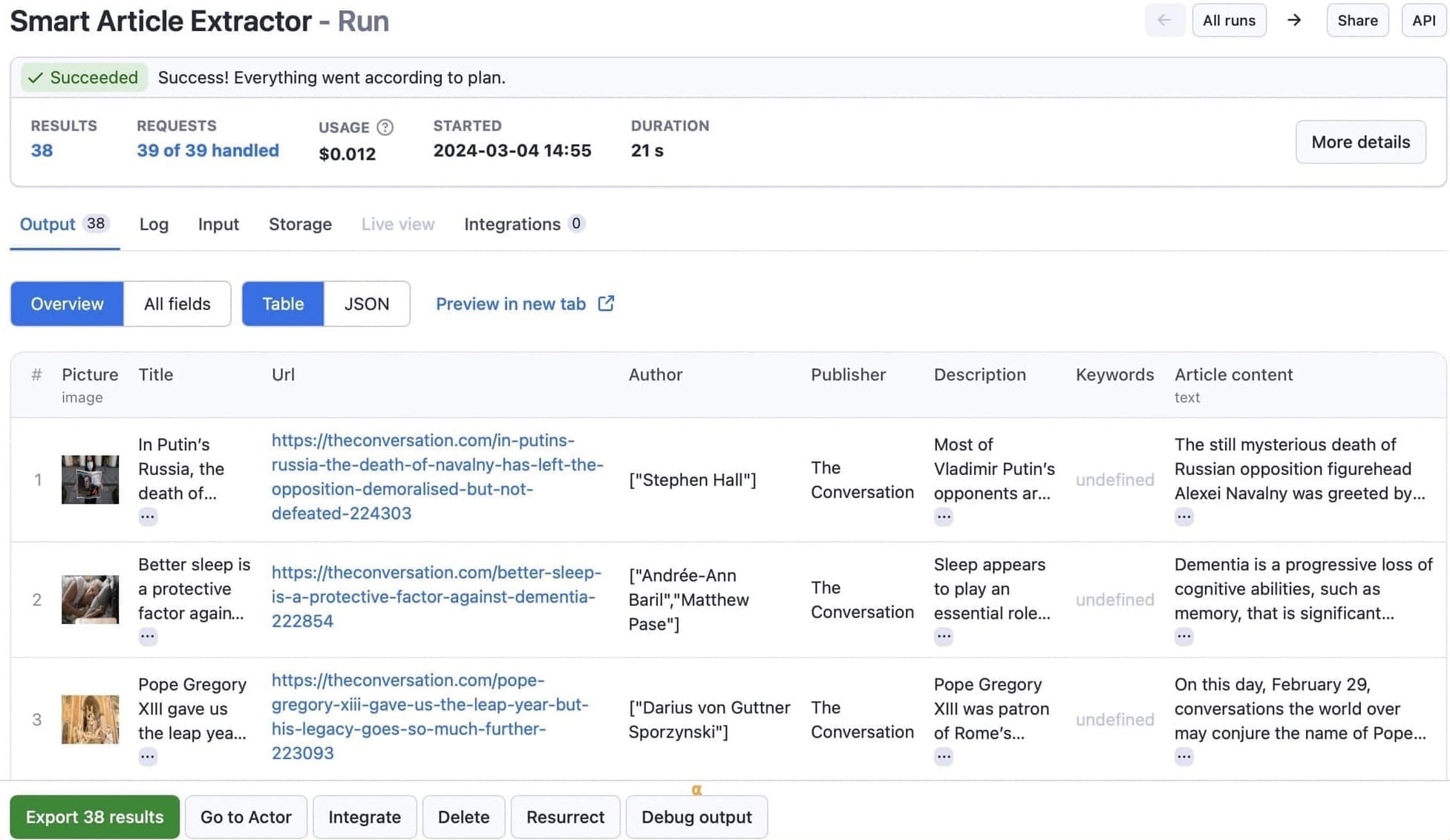
Step 5. Export and download the text data
Once the article extractor has finished, click on the Storage tab to download the information in any of the available formats.
Let’s go with CSV. Here's the dataset for this run:
Step 6 (Bonus step). Be secured
After successfully downloading the article data, take an additional step to ensure the security of your system and online activities by incorporating a trustworthy antivirus with VPN. This dual-layered defense not only safeguards the downloaded information but also protects your entire online experience, shielding against potential threats and maintaining a secure digital environment.
Start downloading articles
We barely scratched the surface with that example, so we suggest you get started with your own text-scraping tasks and enjoy discovering what else Smart Article Extractor can do. If you have any troubles, you can reach out to us, and we’ll be happy to help.
You'll also find a broad range of web scrapers already configured for extracting news articles from specific websites in Apify Store, such as New York Times Scraper, Washington Post Scraper, Google News Scraper, and more. If your research draws on more than news sites, you can also scrape Reddit data or work with scraping Facebook Pages to widen your corpus beyond published articles.




