In this case study, a data scientist used Apify's Google Maps API tool to scrape data on all bakeries in Paris. The reason? She wanted to see which ones opened up earliest so that she could plan her bicycle route accordingly. Have you heard a more charming data-related thing recently? Let’s see what you can do with data extracted from Google Maps paired with a data visualization tool. Here’s why and how she made that happen.
Why scrape bakeries on Google Maps?
One very early morning, while going on a regular cycling trip along the city that was still waking up, Bénédicte Colnet 🔗 noticed that it seemed way easier to stop for breakfast at the start of her route than when arriving at her destination in the center. The hour was early, and the route usually laid from the northeast of Paris (where it was easy to get a croissant even at 5 AM) towards the city center, where finding an open bakery was impossible. Of course, she could have just rushed by a few open bakeries on the way… 🚲 Or is there some deeper pattern going on? And what time do bakeries in Paris open their doors anyway?
Her hunch told her that the Paris bakeries at the beginning of the route must have started earlier, but how correct was her intuition? Being a data-oriented person, Bénédicte decided to answer her questions quantitatively and back up her hunch with data. The end goal was to examine bakeries in Paris to see which ones opened up earlier so she can plan her morning bicycle route better and enjoy some fresh pastry on the way. The task seemed daunting at first, but it was really quite easy to start.
How did she scrape Google Maps?
- The first step was to obtain a list of bakeries in Paris with their opening hours and geolocations. She could inspect every street in Paris with a notebook and write down the bakeries’ opening hours, but Bénédicte wanted to work smarter. So she went for Apify's unofficial Google Maps API.
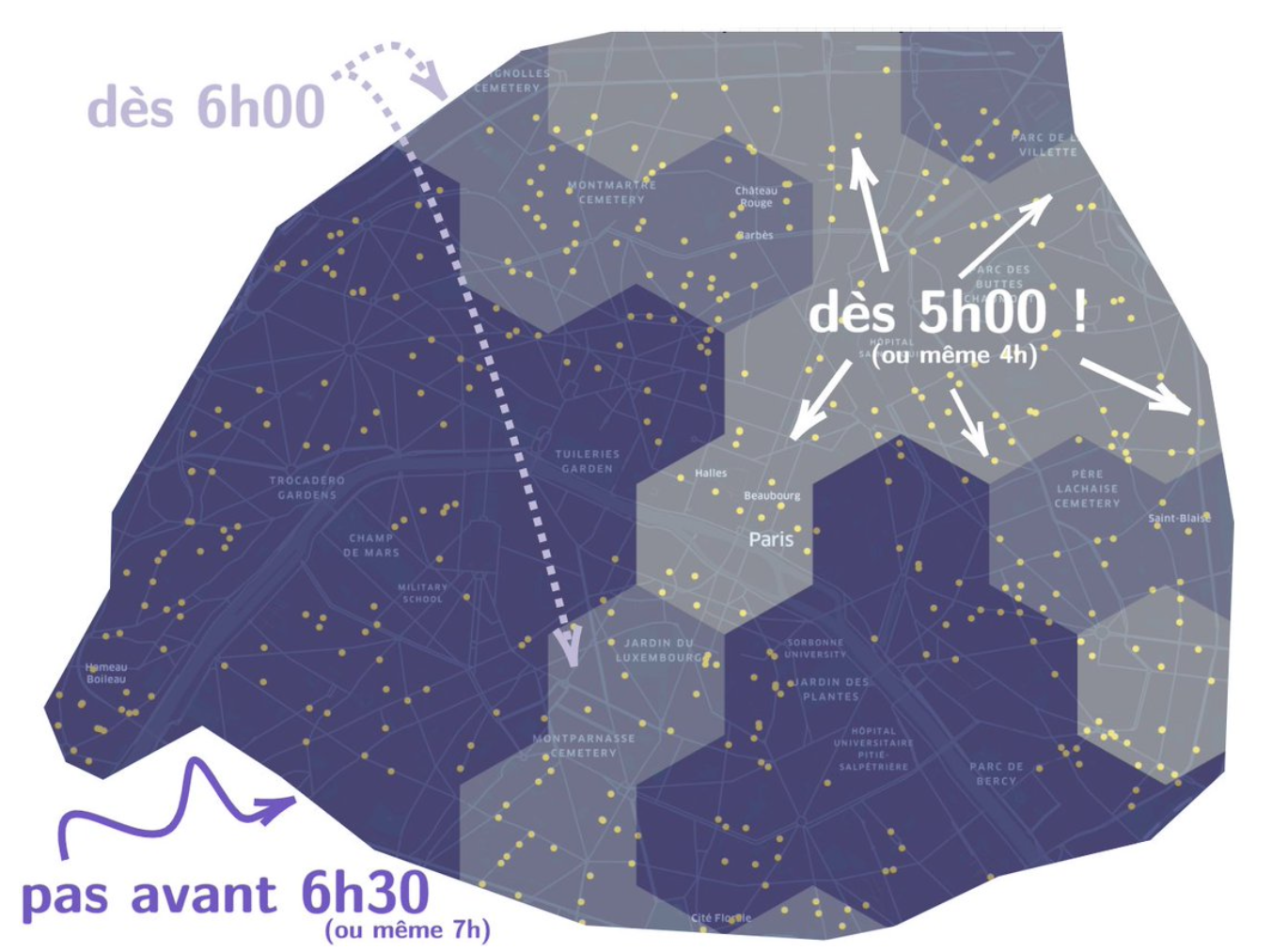
- After doing a little web scraping to extract the opening time, Bénédicte processed the data and created a new map of Paris. Using the geospatial analysis tool kepler.pl, she applied that data by marking each district according to the opening time of the earliest bakery in the area.
- Each yellow dot on the map represents a bakery. The hexagons (each of a 1km diameter) represent neighborhoods. Each was marked on average according to the opening time of the earliest bakery in the neighborhood (the darker, the later).
- Hunch confirmed! North-east = early hours bakeries, as early as 5 AM; center = closed till 6:30 or even 7 AM.
But the story didn’t end there. Visualizing web data can be incredibly versatile. With the right tools, skills, and approach, you can turn any data into art. She wouldn’t be a data person if she didn’t try to compare all that data with another telling graph.
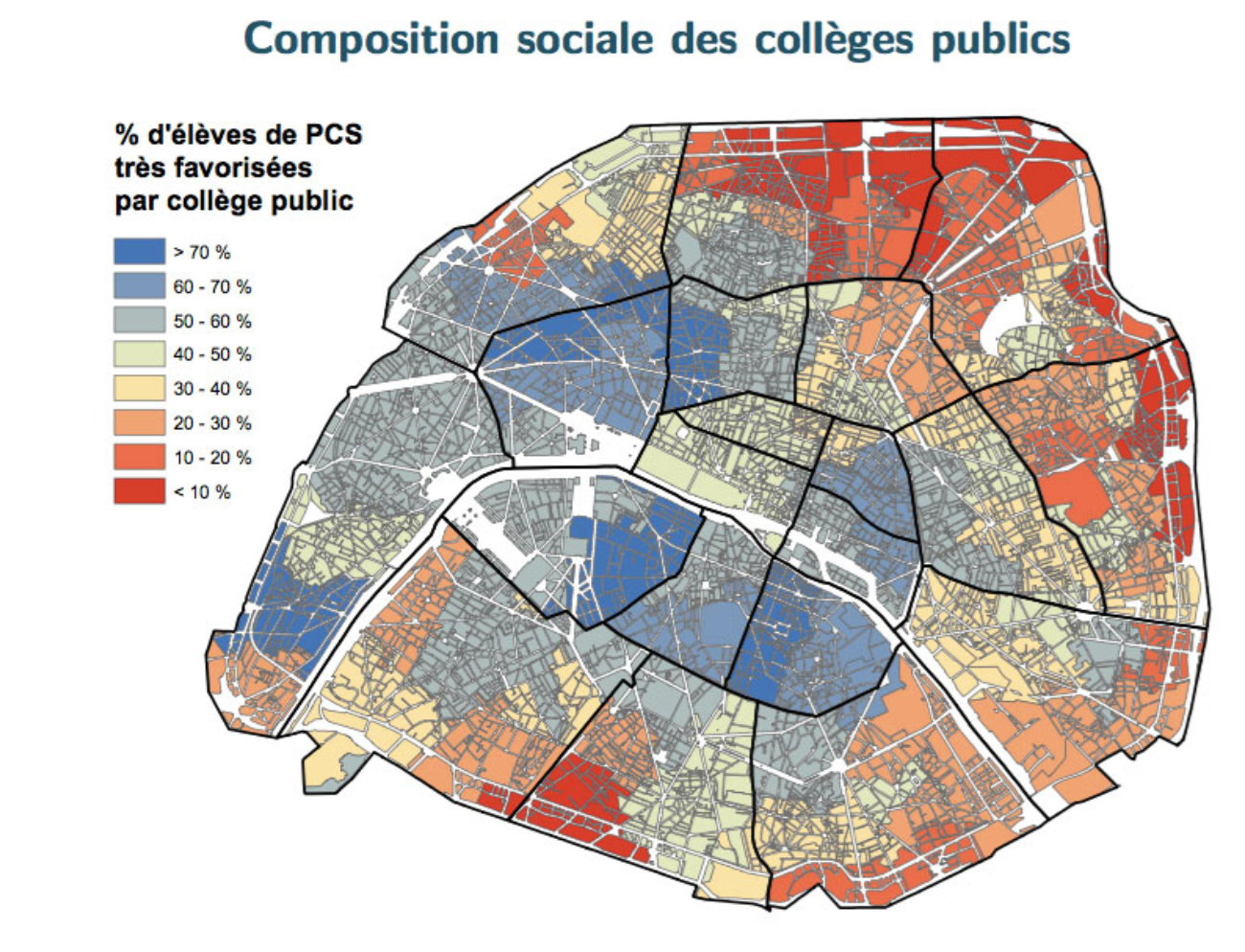
The map Bénédicte created reminded her of a few other already existing map visualizations. For instance, a map showing the social composition of public schools (source: fcpe). The segments on this map strangely correlated with the bakeries' map.
As well as this more recent infographic from le Parisien on Paris voting during the first tour of the Presidential election. Doesn't it also look a little bit like the bakeries map?

But let’s remind ourselves of the first rule of research: correlation does not equal causation. And with that, let’s finish this story with a teachable conclusion:
(i) A morning hunch can be quantified
(ii) Parisians can be divided into two categories: those who have their croissant early and those who prefer their mornings slow (our researcher prefers biking 🚲)
A data story from Bénédicte Colnet 🔗, a data scientist who studies statistics and is currently working on her Ph.D. Besides being a data researcher, Bénédicte loves all things data, so at times she finds herself exploring the world through Google Maps and backing up her hypotheses with objective results.
Here's her original tweet about the project:
La première étape est d’obtenir une liste des boulangeries de Paris avec leurs heures d’ouverture et géolocalisations. Pour cela, on ne va pas parcourir les rues de Paris avec un carnet (enfin, on pourrait), mais on va plutôt utiliser l’API de Google Map (par ex. via @apify)
— Bénédicte Colnet (@BenedicteColnet) July 26, 2022