


Firecrawl is known for the idea of one URL → LLM-ready data through a single REST call, while Tavily positions itself as a real-time search-plus-extraction layer purpose-built for retrieval-augmented generation (RAG) and agent workflows. Both tools hide the messy parts of browsers, proxies, and token budgeting, but they approach the problem from different angles.
Below, we'll go through them in detail, exploring the differences in philosophy and architecture, developer experience and customisation, infrastructure and autoscaling, ecosystem and community, and pricing and licensing.
At the end, we'll explain why you should consider Apify as an alternative to Tavily and Firecrawl.
Let's begin with a quick rundown of their key capabilities.
Firecrawl vs. Tavily: A quick comparison
| Capability | Firecrawl | Tavily |
|---|---|---|
| Core model | API-first SaaS (credit buckets) + AGPL-3.0; self-host fork | API-first search/extract SaaS (credit buckets) + MIT, tavily-mcp server |
| Extraction style | Zero-selector natural-language prompts (/extract with JSON Schema) | Two-step search → extract or direct /extract; optional crawler instructions |
| Dynamic-content handling | Pre-warmed headless Chromium; decision layer chooses fetch vs. browser | Graph crawler fetches HTTP first, falls back to headless browser when needed |
| Built-in intelligence | FIRE-1 agent can paginate, click, solve simple captchas; Markdown token reduction | auto_parameters tunes search depth; ranked results include score field; parallel graph traversal |
| Scaling model | Global browser fleet, 2 / 5 / 50 / 100 concurrent browsers per plan | 100 RPM dev → 1,000 RPM prod keys; backend auto-scales workers |
| Vector/RAG loaders | Official LangChain and LlamaIndex adapters | Official LangChain and LlamaIndex adapters + MCP server |
| Pricing headline | 1 page = 1 credit → 100k pages → $83/month (Standard) | 1 search = 1 credit → 100k credits → $500/month (Growth) |
| Licence | Hosted API commercial • Core engine AGPL-3.0 | Hosted API commercial • MCP and SDK MIT |
| Latest release | v 1.15.0 (18 Jul 2025) | tavily-python 0.7.10 (17 Jul 2025) |
Philosophy and architecture
Firecrawl
Firecrawl offers a single, consistent API that handles scraping, crawling, and AI-driven site navigation. The crawler explores internal links without sitemaps, skips duplicates, and infers which pages matter most from the site structure. A decision layer fetches static HTML when possible and runs a pre-warmed Chromium container when JavaScript is required.
For sites that hide information behind clicks, forms, or paginated views, you can enable the FIRE‑1 agent. It mimics human behavior by clicking “Load More,” filling search fields, and even solving simple CAPTCHA, eliminating special‑case code.
Performance optimizations run throughout the platform. Recently scraped pages come from cache in milliseconds, hundreds of URLs can be batched in a single call for parallel processing, and converting HTML to lightweight Markdown cuts the token count for downstream LLMs by roughly two‑thirds. The net effect is faster, lower‑maintenance data collection that remains reliable as websites evolve.
Tavily
Tavily is designed for real-time data aggregation. It frames web access as search first: the Search API fans out to multiple verticals, ranks and filters results, and can return raw content. A separate /extract or /crawl endpoint then pulls individual pages or entire sites. The open-source Tavily MCP Server mirrors the hosted API for on-premise or air-gapped deployments.
A single call can fan out to topics, apply a country bias, tune itself with auto_parameters, and multi-hop queries. Results arrive with a relevance score, permalink, and optional raw_content that you can inject straight into an embedder.
After you have URLs, the /extract endpoint lets you choose format=markdown|text, include or omit favicons, and cap output with max_tokens. You decide exactly how much HTML or plain text your LLM sees.
Developer experience and customisation
Firecrawl is language‑agnostic, accessible via REST with Node, Go, and Python SDKs. Its selector‑less approach lets you skip CSS or XPath entirely; the model inspects the DOM and fills your schema. Paging, infinite scroll, and form submits are delegated to FIRE‑1.
Tavily leans on search‑time AI. You can pull raw_content inline, but a two‑step search → extract approach is better for higher precision. Advanced extract depth handles JS‑heavy pages and tables, and graph‑based crawl explores hundreds of paths in parallel.
| Feature | Firecrawl | Tavily |
|---|---|---|
| On-ramp | REST; Node, Go, Python SDKs; playground | REST; Python async SDK; Postman API |
| Selector-less extraction | Yes (JSON Schema prompts) | Yes, after search or direct URL |
| Partial content controls | include_images, markdown, max_tokens | format, include_favicon, max_tokens |
| Language examples | cURL, Node, Go, Python | cURL, Python (sync/async) |
| Playground features | Live credit usage, agent options, code export | Live result scoring, batch testing, code export |
Infrastructure and autoscaling
Both Firecrawl and Tavily abstract proxy pools and region targeting. Firecrawl exposes more agent-level flags; Tavily focuses on higher-level search tunables.
| Feature | Firecrawl | Tavily |
|---|---|---|
| Who runs the browsers? | Firecrawl cloud fleet | Tavily backend |
| Concurrency | Plan-based browser limits | 100 → 1,000 RPM per key |
| Retries & captchas | Automatic retries + FIRE-1 solver | Automatic retries, no captcha solver |
| Monitoring | Dashboard: p95 latency, credit burn | Usage endpoint + status page |
Ecosystem and community
Firecrawl and Tavily run active Discord servers; Tavily also maintains a public forum and claims 600k+ registered developers.
| Metric | Firecrawl | Tavily |
|---|---|---|
| GitHub stars | 44,700 ★ | 630 ★ (tavily-mcp) |
| Release cadence | Bi-weekly SaaS deploys; monthly OSS sync | Weekly docs & SDK updates; monthly MCP tags |
| Integrations | LangChain, LlamaIndex, RelevanceAI | LangChain, LlamaIndex, Zapier, Make, n8n |
| Self-hosting | firecrawl-simple (AGPL-3.0) |
tavily-mcp (MIT) |
Pricing tiers
Firecrawl
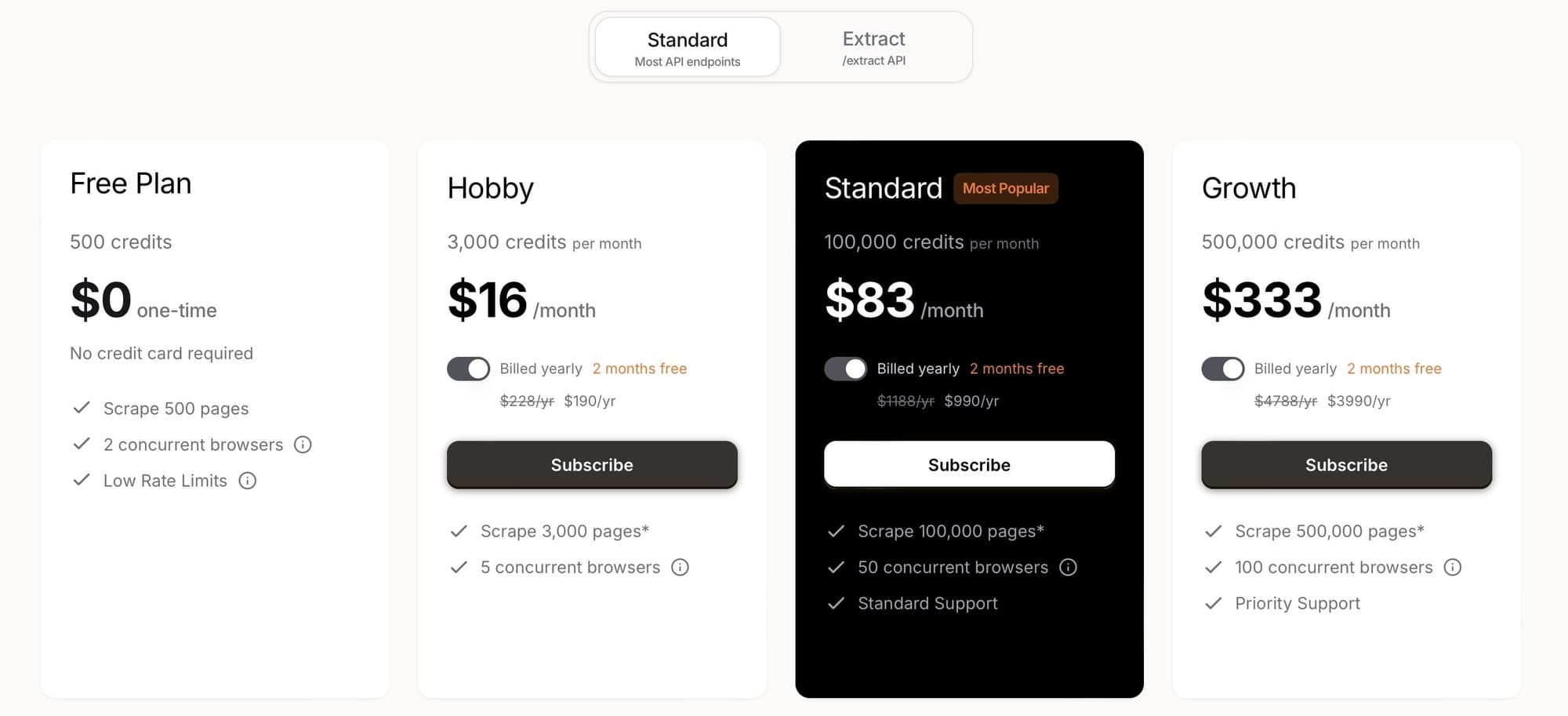
Firecrawl charges one credit per page for /scrape and /crawl. Standard pricing plans start at $16/month. Extraction tasks that go beyond simple scraping consume additional credits or tokens, and Firecrawl offers dedicated “Extract” plans ranging from $89 to $719/month, depending on token volume.
Tavily
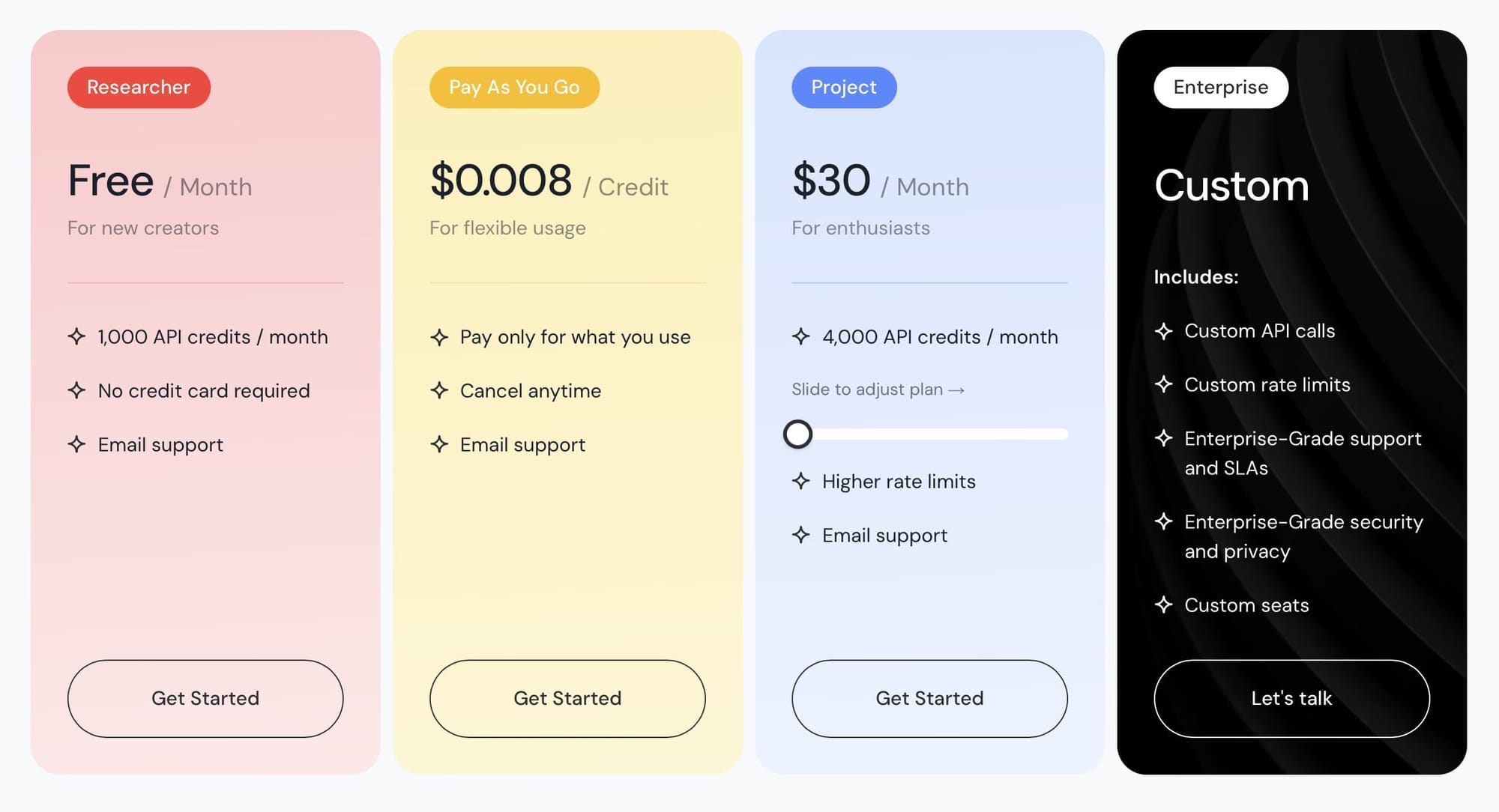
Tavily offers a mix of free credits, slider plans, and $0.008 PAYG suits bursty or search-heavy workloads where monthly usage is harder to pin down.
| Tier | Firecrawl pricing | Tavily pricing |
|---|---|---|
| Free | 500 credits (≈ 500 pages) — $0 one-time | 1,000 credits — $0/month |
| Entry plan | Hobby — 3,000 credits — $16/month 5 concurrent browsers |
Project — 4,000 credits — $30/month Higher rate limits |
| Pay-as-you-go | — | $0.008/credit — no monthly commit |
| Mid-range | Standard — 100,000 credits — $83/month 50 concurrent browsers |
≈ $800 via PAYG for 100,000 credits No fixed-price plan |
| High volume | Growth — 500,000 credits — $333/month 100 concurrent browsers |
Enterprise — custom quote Custom rate limits |
At 100k pages per month, Firecrawl’s Standard plan is roughly 10× cheaper than buying the same 100k credits from Tavily’s PAYG bucket. Tavily pays off when you need fewer pages but many discrete searches, or when you prefer to start without any monthly commitment.
Licensing considerations
Both hosted APIs are closed-source. Firecrawl’s self-host engine is AGPL-3.0 — if you modify and redistribute it, you must release your changes. Tavily’s MIT-licensed MCP lets you extend or repackage without open-sourcing.
A flexible alternative: Apify
If a single search or crawler API feels limiting, Apify offers a full-stack platform built around its Actor system — serverless scripts that share common input/output, storage, and scheduling. This ecosystem gives you thousands of ready-made scrapers plus the freedom to deploy your own. Because every Actor behaves the same way, you can link them into multistep workflows just by passing data from one to the next.
Here's why you should consider Apify as an alternative to Firecrawl and Tavily:
- Over 10,000 plug-and-play web scraping tools
The platform hosts the largest marketplace of scrapers, so you can collect data from every kind of website and feed AI agents and LLMs with up-to-the-second web data. All can be used with a REST API or an intuitive UI.
- Native agent tools
Apify exposes an MCP endpoint and starter kits for LangGraph, CrewAI, LlamaIndex, Mastra, and more. Your agent can discover the right scraper at runtime, trigger it, and stream structured data back.
- Elastic runtime and transparent pricing
You pay for compute units (1 GB RAM-hour) and a monthly subscription — starting at $29/month for the Starter plan or $0.3 per CU pay-as-you-go. Scale RAM, concurrent runs, or residential proxies only when the workload demands it.
- Open-source DNA
Prefer on-prem? Crawlee (MIT) gives you the same crawler core in Node.js or Python. Write locally, then lift-and-shift to Actors when you need managed scaling.
Conclusion
Firecrawl and Tavily eliminate browser headaches by making browsers crawler- and search-first. Apify adds a third path — a modular platform that already speaks the language of modern agent frameworks and lets you mix curated Actors with your own code.
Want to know exactly how Apify compares with Firecrawl? Check out our detailed comparison below.
Explore other alternatives to Tavily and Firecrawl here:
Note: This evaluation is based on our understanding of information available to us as of January 2026. Readers should conduct their own research for detailed comparisons. Product names, logos, and brands are used for identification only and remain the property of their respective owners. Their use does not imply affiliation or endorsement.





