


In God we trust. All others must bring data
— W. Edwards Deming
There's a pretty slim chance that you'll bother to check where this quote came from. Was it from a book, an article, or a speech? Are these really the words of the American engineer and statistician? Or did I just slavishly borrow the quote from a meme or article online without checking the source?
In this particular case, where this quote came from and whether it's been correctly attributed probably isn't very significant. What matters is what it tells us about the importance of data measurement and analysis when doing business.
However, in many cases, for anyone who deals with data, authenticity and reliability can be pretty significant factors - factors that are especially vital when it comes to data scraped from the web since such information can be particularly susceptible to quality and trustworthiness issues.
That brings us to the definition of data provenance.
What is data provenance?
Data provenance, often referred to as data lineage, refers to the documented history of a piece of data. It's like a detailed travel log that tracks the origin of the data, the steps it's taken, and any modifications it's undergone throughout its lifecycle.
Data provenance isn't just about what happens to data after collection; it encompasses the entire journey of the data, starting from how and where it was generated or collected.
Data provenance vs. data lineage: are they the same thing?
Although they're closely related and usually used interchangeably, data provenance and data lineage differ in scope and purpose.
Data lineage is used to understand data workflows, facilitate debugging and optimization, and assess the impact of changes in data processing.
Data provenance
Data provenance provides a detailed audit trail for a piece of data, including:
- Where did the data come from? Was it collected from sensors, entered manually, extracted from a database, or scraped from the web?
- Who has interacted with the data? This covers the individuals or systems that have accessed or modified the data throughout its lifecycle.
- What changes were made to the data? This details any transformations, calculations, or analyses the data has undergone since its original collection.
Data lineage
Data lineage focuses more specifically on the flow of data through various processes and transformations. It answers questions like:
- How has the data moved through different systems and processes? This includes the path the data has taken through various storage systems, databases, and analytical processes.
- What transformations has the data undergone? This aspect of lineage maps out the sequence of changes to the data, such as aggregation, filtering, and joining with other data sources.
- Why does the data appear in its current form? By tracing the data's journey, lineage provides insights into the decisions and processes that have shaped its final state.
A breakdown of the data provenance process
1. Before and during collection
Data provenance applies from the very moment data is created or collected. It includes documenting the methodology of data collection, the instruments used, the time and location of collection, and any conditions that might affect the data's integrity.
2. After collection (transformations and usage)
After data is collected, provenance tracks every modification, transformation, or analysis performed on the data. This could include cleaning the data, merging it with other data sets, analyzing it, or any form of processing. Each step is documented to ensure a clear understanding of how the data arrived at its current state. In financial data management, provenance plays a critical role in tracking the flow and transformations of financial transactions, ensuring transparency and accountability in reporting. When integrating data from QuickBooks to SQL Server, every data point, such as sales, expenses, and balance information, is carefully mapped and transferred to maintain accuracy and consistency across both systems (e.g., in a HVAC scheduling software-Quickbooks integration).
3. Storage and access
Data provenance also involves documenting where the data is stored and who has access to it throughout its lifecycle. This includes any changes in ownership or responsibility for the data, where it has been transferred, and how it has been secured.
Every data enterprise must be a responsible steward of data, algorithms, and AI.
– Data & Trust Alliance
Why is data provenance important?
Why does all this information about data matter? There are four primary reasons:
1. Trust and transparency
Data provenance builds trust by providing a clear picture of where the data came from, who has accessed it, and what modifications have been made. This transparency is particularly important in areas like financial reporting, scientific research, and legal proceedings.
2. Data quality
By tracking transformations, data provenance helps identify and rectify errors introduced during processing. This sees to it that users are basing their decisions on accurate and reliable information.
3. Regulatory compliance
Data provenance plays a key role in demonstrating compliance with regulations such as GDPR and HIPAA, which require organizations to be able to track and audit the flow of personal data.
4. Reproducibility
In research and scientific fields, data provenance fosters a culture of openness and collaboration by allowing others to replicate the analysis and verify the results.
Transparency and accuracy around the origin of food, water, raw materials and capital are fundamental prerequisites for society, essential to establishing trust and defining quality. We've always felt the same standard must apply to data.
— Neil Blumenthal, Co-Founder and Co-Chief Executive, Warby Parker
Data provenance use cases
Data provenance spans across various sectors to establish trust, integrity, and accountability in data management. What are the most common cases?
- Healthcare: As detailed in a comprehensive study by MDPI, data provenance ensures the authenticity and reliability of data for patient safety and treatment accuracy. It also plays an important role in healthcare data security, helping organizations protect sensitive patient records while maintaining compliance with strict regulatory requirements.
- Finance: In the financial sector, data provenance is crucial for maintaining compliance and making informed decisions. Scraping data for industry analyses and reports valuable for dealmakers in every sector helps track the origin and modifications of financial data, ensuring its integrity and reliability.
- Artificial intelligence: By documenting the origins and transformations of data used in AI models, data provenance lets stakeholders validate the fairness of algorithms, audit decision-making processes, and comply with data governance regulations. This documentation is a fundamental component of an AI Bill of Materials (BOM), which provides a comprehensive inventory of the datasets, models, and third-party components used to build an AI system. By maintaining a clear AI BOM, organizations can ensure transparency, detect potential vulnerabilities, and verify that their models comply with ethical and legal standards.
- Supply chain management: Data provenance is also used to track the origin, movement, and authenticity of goods throughout supply chains to prevent fraud and ensure compliance with regulations. It also plays a critical role in supplier risk management by offering transparency into vendor practices and potential disruptions.
- Scientific research: In the area of scientific research, data provenance documents the sources and methodology behind data collection and analysis to enable reproducibility and validate findings.
- Government and public services: In this field, data provenance is utilized to ensure transparency and accountability in data handling and decision-making processes, which is further supported by Atlantic.Net HIPAA hosting services that provide secure and compliant infrastructure for managing sensitive data.
- Manufacturing: Data provenance is used in manufacturing to monitor the lifecycle of products, from raw materials to finished goods, so as to optimize production processes and verify quality standards.
- Education: Data provenance is also utilized in education for managing academic records and research data to uphold integrity and support accreditation efforts.
61% of CEOs in the 2023 annual IBM Institute for Business Value CEO study cite the lack of clarity on data lineage and provenance as a top barrier to adoption of generative AI.
– Data & Trust Alliance
Applying data provenance to web scraping
Web scraping can get you a lot of data, but is the data trustworthy? Not always (I know that for a fact because I read it somewhere on the internet), and that's why data provenance sometimes needs to be applied to data scraping.
A solid solution to applying the principles of data provenance to data extracted from the web is with a web scraping platform. Here's why:
Data provenance is like a detailed travel log for your data, revealing its origin (the website URL), transformations (cleaning, filtering), and the date and time it was scraped. This information helps build trust in the data's accuracy and reliability.
Web scraping platforms offer tools that can significantly aid in capturing metadata and details about the scraping process. These features are designed to automate the documentation of where data comes from, when it was collected, and how it was processed, which are key aspects of data provenance.
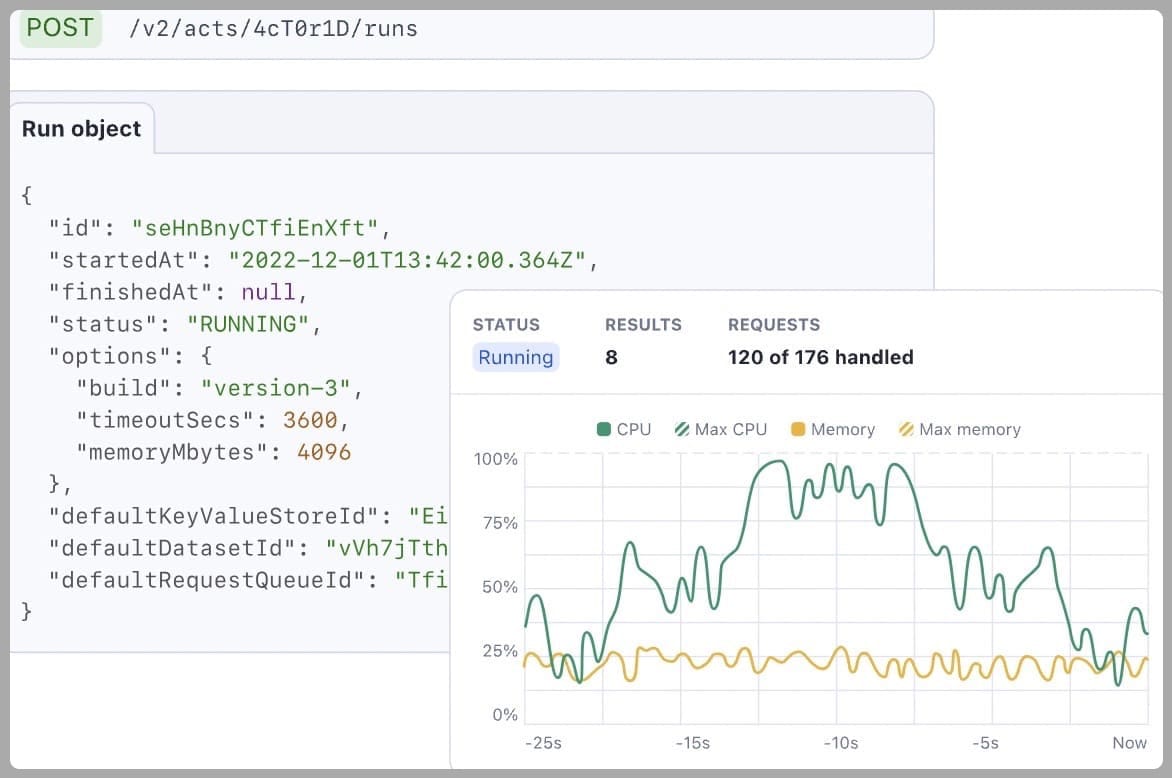
Automated data collection and data provenance
Web scraping platforms offer built-in features that automate capturing key data provenance points. These can include:
- URL capture: The platform automatically logs the specific URL scraped so you know the exact source of the data.
- Timestamp recording: The date and time of the scraping session are automatically recorded, providing a time capsule for the data's acquisition.
- Scripting details: You can store information about the scraping script used, including libraries and filtering criteria. This provides transparency into how the data was extracted.
Limitations and challenges of automation
All that being said, automation is not a panacea. The effectiveness of these automated features in ensuring data provenance depends heavily on the setup and management of the scraping process. You need to configure your scraping tasks thoughtfully and specify which data to collect, how to navigate through web pages, and when to capture data. Misconfiguration can lead to incomplete data capture, incorrect data association, or other errors that compromise data provenance.
How to use web scraping for data provenance
To maximize the benefits of web scraping platforms for data provenance, a balanced approach is needed. This involves:
1. Carefully configuring your scraper
You should thoroughly plan and test your scraping setups to make sure that they accurately capture the desired data along with its provenance information.
2. Conducting regular audits and error handling
Carry out periodic reviews of both the scraping process and the data collected to identify and correct any errors or missing information that could affect data provenance.
3. Providing documentation
While automated tools can capture much of the needed provenance information, you should supplement this with manual documentation about the context of the data collection and any non-standard decisions made during the scraping process.
Benefits of scraping platforms for data provenance
Using a web scraping platform can offer several advantages when it comes to data provenance:
- Reduced manual work: The platform handles the heavy lifting and saves you time and effort in capturing provenance details.
- Data storage: Your scraped data is stored alongside its provenance information in a secure and accessible location.
- Scheduling: A web scraping platform lets you automate data collection by letting you run scrapers on a schedule. That means you can continuously get fresh up-to-date information.
Make data provenance easier with Apify
Apify is a web scraping platform that simplifies data provenance, as it automates the capturing of crucial information about where data comes from and how it was acquired. This makes it easy to apply the principles of data provenance to scraped web data and ensures business decisions are not made on the basis of stale or unreliable information. All of this contributes to maintaining a clear traceable history to foster trust and reliability in your data analysis. Check us out.





