


If you're considering Bright Data for e-commerce scraping, here are a couple of things you should know:
- Their site-specific APIs (e.g., Amazon, Walmart) offer fast, structured outputs for supported domains. However, if you need to target a site not included in their API library or customize logic, you'll need to switch to the Web Scraper IDE, which is browser-based only.
- The IDE allows for JavaScript-based scraping workflows within Bright Data's platform, but there’s no official support for local development, CLI deployment, GitHub workflows, or version control.
Apify takes a different approach.
Rather than separate API products, Apify provides a full-stack scraping platform centered around "Actors" (Apify’s special word for scrapers). These Actors are self‑contained programs that run in the cloud with uniform input/output, shared storage, and common scheduling and monitoring. With Apify, you can:
- Use 10,000+ maintained scrapers (Actors) for platforms like Amazon, Shopify, and Google Shopping
- Fork or edit these scrapers directly
- Build your own locally using Crawlee or SDKs (JS or Python)
- Deploy via CLI or GitHub
This difference becomes especially clear when you need to build custom, multi-step, or team-managed scraping pipelines.
Want one tool to scrape many e-commerce websites? Try E-commerce Scraping Tool. With one run, you can extract product data from Amazon, Walmart, eBay, and any Shopify storefront. Input category and product URLs, and build a product and pricing database in minutes.
Apify vs. Bright Data (a quick comparison)
| Area/Feature | Bright Data | Apify |
|---|---|---|
| Primary model | Site-specific APIs + Web IDE | Actor-based platform + Crawlee SDK + CLI |
| Dataset access | Dataset Marketplace (~$2.50/1K) | No marketplace; fresh data only |
| Custom workflows | Web IDE (browser-only) | Local dev, CLI, GitHub, logging |
| E-commerce coverage | 120+ APIs | 10,000+ APIs + SDK for any site |
| Analytics layer | Bright Insights (~$1,000/mo) | Custom integrations |
| Proxy stack | Web Unlocker, CAPTCHA bypass | Apify Proxy or BYO proxies |
| Developer tooling | No CLI/GitHub; IDE-only | CLI, GitHub Actions, logs, retries |
| Free tier | 3-day trial, limited features | $5/month CU usage; no time limit |
What you get with Bright Data
Bright Data’s strength lies in speed-to-results for known targets like Amazon or Google Shopping, not in flexibility or developer control.
1. Web Scraper API Library
Bright Data’s library of 120+ site-specific APIs is designed to give you immediate access to structured data. You don’t have to worry about selecting HTML elements, parsing nested variants, or solving CAPTCHA walls — Bright Data handles all of it.

This is valuable if:
- You need results fast, and
- The site you’re targeting is already supported (e.g., Amazon, Walmart).
That said, these APIs are rigid. If the output structure doesn’t match your internal schema, or if you need to combine multiple pages/flows (e.g., search + detail + reviews), you’re out of luck unless you move to a different tool entirely.
So while it’s a great entry point, the Web Scraper API library doesn’t scale well to bespoke workflows or long-tail sites.
2. Web Scraper IDE
If Bright Data doesn’t already support your target, or if you need to customize logic (e.g., pagination, filtering, deep linking), you can use their Web Scraper IDE — a GUI tool for building scrapers in JavaScript.
This works well for one-off jobs or solo workflows, but lacks core development ergonomics:
- No way to run scrapers locally
- No GitHub integration or version control
- No CLI support for deployments or automation
- Limited support for environment variables or secrets
For solo use cases or quick prototyping, it’s usable. But if you’re part of a team, or if your logic needs to evolve over time, it becomes a maintenance liability.
3. Dataset Marketplace
The Dataset Marketplace lets you buy data that Bright Data has already collected — like Amazon product catalogs or Google Shopping results — without running a single scraper.
This is useful for:
- Baseline catalog pulls (e.g., 100K+ SKUs)
- One-off reports (e.g., pricing for Black Friday)
- Teams that don’t want to manage infrastructure
However, it’s a black box. You can’t inspect how the data was collected, control when it updates, or add fields you care about. If your needs change — like adding seller-level metadata or integrating the data into a dynamic alerting system — you’ll hit a wall quickly.
It’s a buy-vs-build decision: convenient if you need raw data today, limiting if you need ongoing, tailored pipelines.
4. Bright Insights
Bright Insights is Bright Data’s packaged analytics layer. Think dashboards for:
- Price monitoring
- MAP enforcement
- Search rank tracking
- OOS alerts
This is genuinely valuable if you want data plus analysis without building it yourself. But pricing starts around $1,000/month, and the dashboards aren’t customizable beyond the defaults.
So if you need something off-the-shelf for executive reporting or procurement tracking, it’s a turnkey solution. But if your business logic is complex, or if you need to integrate directly into ops workflows, you may find it inflexible.
5. MCP server
If you want to pull data from Bright Data’s e-commerce and retail scrapers right from your Claude Desktop without needing to deal with APIs, SDKs, and such, you can use their MCP server.
MCP acts as the bridge between scrapers and AI workflows. It doesn’t do the scraping itself, but it makes those scrapers and automation tools callable as functions that an agent can run on demand.
This gives AI agents browsing and unblocking capabilities, good for live, arbitrary site access. It can run in the cloud or locally. This partly addresses Bright Data’s limitation of not making scrapers available outside their platform, but you’re essentially still consuming Bright Data's credits and cannot build your own solution that you own 100%, unlike a custom Apify Actor. In short, Bright Data’s MCP server is another entry point to their existing services, while Apify goes for a broader, more flexible approach, as we'll explain further below.
What you get with Apify
Rather than offering pre-built APIs per site, Apify gives you a general-purpose scraping platform built around "Actors" — containers that can be scheduled, composed, and monitored. For developers or data teams that need to build and evolve scraping logic over time, it’s the better long-term investment.
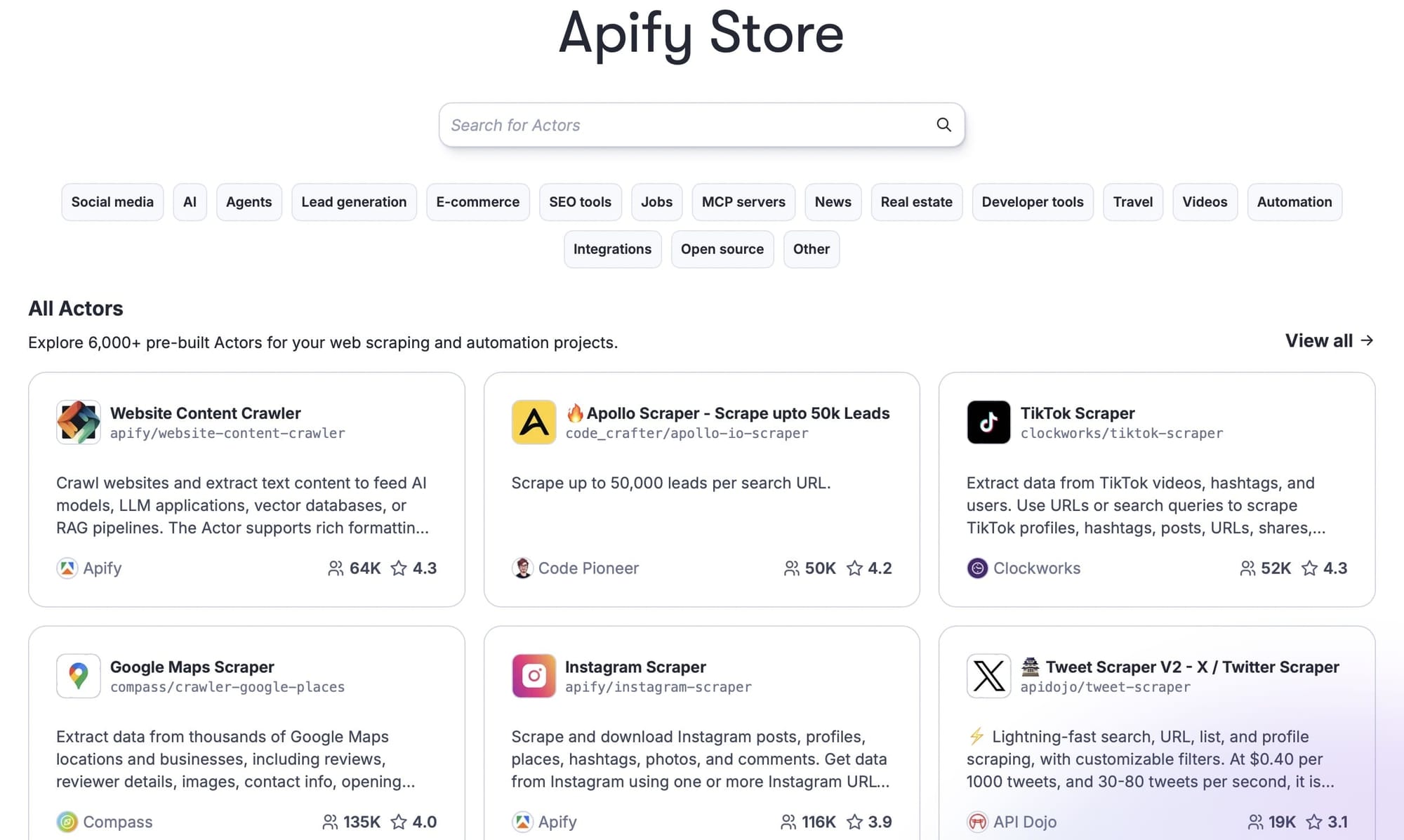
1. The world's largest marketplace of web scrapers
Apify Store is a marketplace of ready-made scrapers ideal for teams that want to get reliable data from popular e-commerce platforms without building custom scrapers from scratch. Non‑developers can launch and schedule those scrapers through a web UI, while engineering teams still have full SDK control when needed.
If you need Amazon, Walmart, Target, Best Buy, or eBay product data, for example, chances are a suitable scraper already exists and is kept up to date as site layouts change, so you don't have to start from a blank page. This means you gain speed and capacity on day one.
2. Local development
If an off-the-shelf scraper doesn't meet your needs, you can build your own. With Apify, you’re not tied to a browser-based IDE. You can build and test your scrapers:
- Locally using Crawlee (Apify’s open-source library) or SDKs
- In your own editor (VS Code, JetBrains, etc.)
- With git-based version control
You get full control over logic, testing, rollback, and code reuse. If your team works with CI pipelines or expects repeatable deployments, this gives you a familiar workflow.
It also means you can treat scrapers like any other software component — reviewed, tracked, and continuously improved.
3. CLI and GitHub workflows
You can deploy scrapers from shell scripts with the Apify CLI or from GitHub Actions using Apify’s official GitHub Action (apify/push-actor-action). This unlocks:
- Automated deployments
- Rollback on error
- Visibility into changes
- Infrastructure-as-code for scraping
This allows your scrapers to scale safely and reliably with your team.
4. Scheduling and orchestration
Actors in Apify aren’t just jobs but composable units. You can:
- Trigger them on a cron schedule
- Set up webhooks for downstream processes
- Pipe results to Slack, S3, BigQuery, or anywhere via integrations
- Handle failures with retry/backoff logic
- Chain steps: scrape → enrich → upload → notify
That means scraping isn’t just about “getting the data” but how that data moves into your systems, with control and transparency at every step.
5. MCP server
You can use Apify's MCP Server to turn any of Apify Store's 10,000 + Actors (or your own) into a callable tool. It works effectively with local dev, Git, CLI, and CI/CD.
While Apify uses MCP to make existing Actors easily callable by LLMs outside the platform, it also goes beyond that by giving you full freedom to build your own servers as Actors and own them 100%. You can run those locally, on Apify, or anywhere else, so you’re not restricted to only the tooling the platform provides.
And note: you can also publish and monetize your own MCP servers on Apify.
The advantage over a traditional API or SDK is that you don’t need to wire up custom endpoints or maintain client libraries; the tools register themselves automatically in the agent’s environment. For example, if you want an LLM to track competitor prices, MCP lets it trigger an Amazon Actor on Apify and pull the results straight into the conversation or app where you need them.
Pricing
Bright Data: Predictable pricing for structured data
If you're running known use cases (e.g., Amazon prices), Bright Data gives you clear per-record costs. It's especially useful for quick, high-volume extractions without worrying about scraper logic or edge cases.
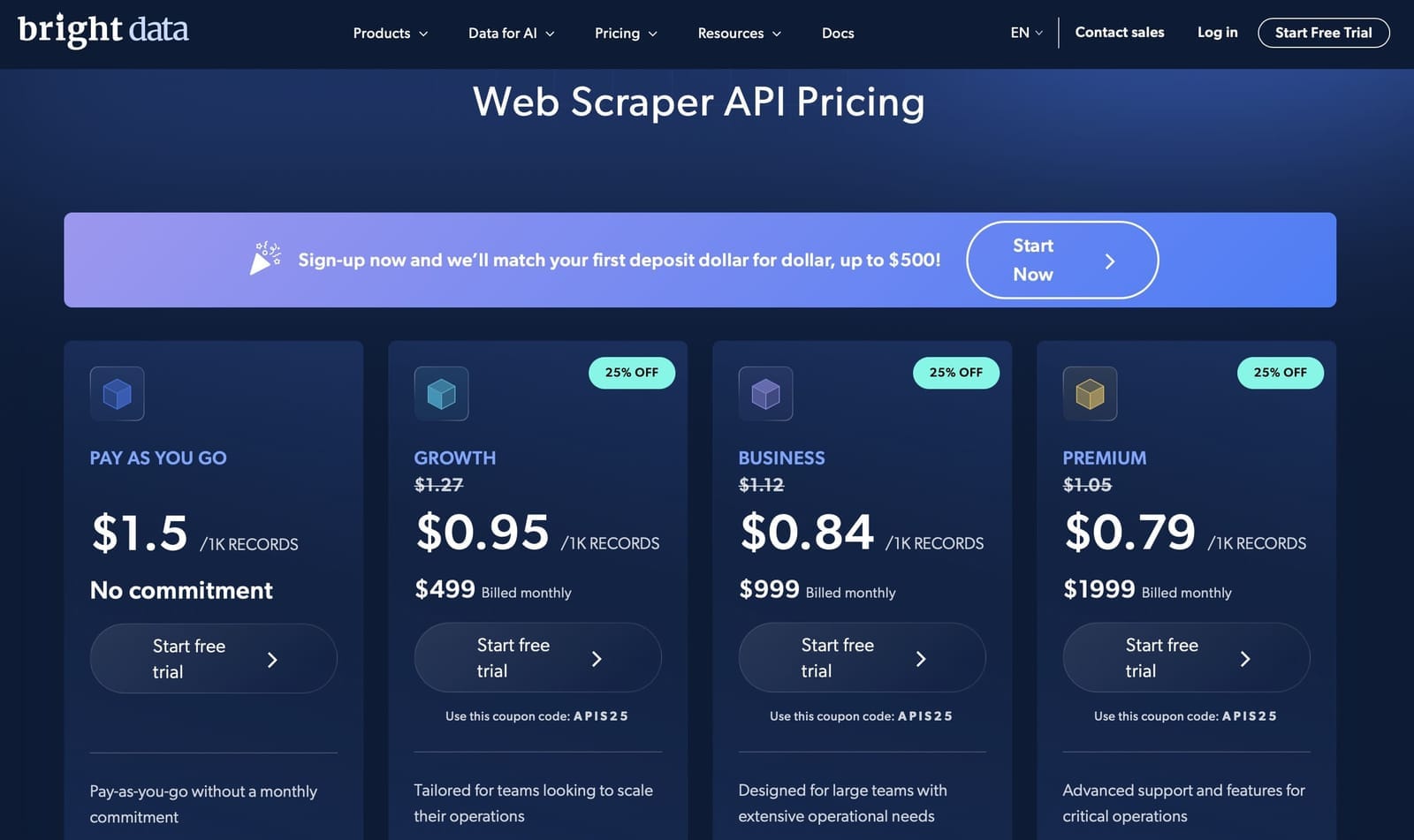
On the lower end, costs are $1.50/1K records on the pay‑as‑you‑go plan and $0.95/1K on volume plans starting at $499/mo. It also offers per-record pricing for its datasets ($2.50/1,000 records) and subscription options.
Enterprise plans involve sales interaction, meaning they’re not an option for users who want to manage everything themselves and start using the product right away without needing specific quotes.
Apify: Flexible pricing for custom flows
Apify charges for runtime and memory (compute units), not records. This is ideal for:
- Long-tail or multi-site scrapers
- Multi-step jobs (crawl > enrich > export)
- Reusable flows with error handling
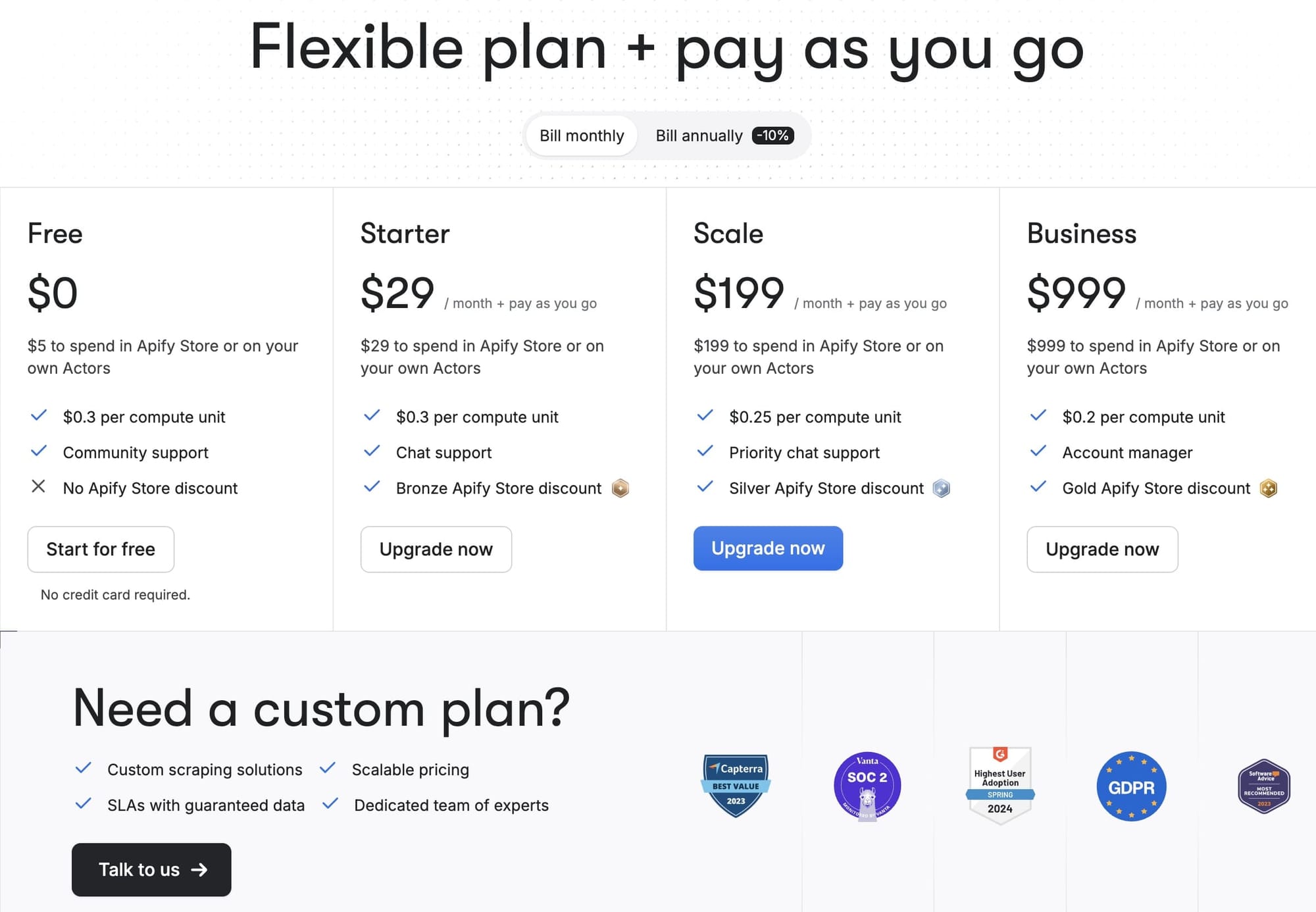
Apify's model tends to be cheaper over time for complex automation or pipelines. Paid subscriptions begin at $29/month.
Its fully managed solutions start at $1,749/month. If you’re not ready for a fully managed setup, it also offers custom enterprise plans with high-touch support, ideal for teams that want flexibility while still benefiting from enterprise-grade infrastructure.

Final verdict: Bright Data or Apify?
Bright Data is an excellent fit if your needs are straightforward and your targets are well-supported by their existing API catalog or dataset marketplace. It excels when:
- Your targets are among the 120+ supported sites (e.g., Amazon, Google Shopping, Walmart)
- You prefer to buy data via the Dataset Marketplace instead of collecting it yourself
- You're an enterprise buyer looking for MAP dashboards and managed analytics (Bright Insights)
- You need access to a reliable proxy infrastructure with unblocking capabilities and SLA-backed delivery
However, Bright Data’s developer experience is limited, making it harder to maintain scrapers in team environments or adjust over time.
Apify, by contrast, is built for developers and teams that want end-to-end control over their scraping and automation pipelines. It’s a better fit when:
- You need custom workflows, logic branching, or long-tail site coverage
- You want to build locally, version in GitHub, and deploy via CLI or CI
- You're building reusable Actors that can be scheduled, observed, and chained
- Your team needs structured logging, retry/backoff logic, and modular deployment
- You're scraping many sites or running multi-step ETL-style pipelines
- You want structured data fast with thousands of ready-made scrapers
While Apify doesn’t offer a dataset marketplace or pre-built dashboards, it provides the foundation to build those yourself with full visibility, maintainability, and flexibility.
Note: This evaluation is based on our understanding of information available to us as of January 2026. Readers should conduct their own research for detailed comparisons. Product names, logos, and brands are used for identification only and remain the property of their respective owners. Their use does not imply affiliation or endorsement.



