


Accessing Twitter data has become increasingly challenging for teams seeking large volumes of information:
- The official Twitter API requires applying for a developer account, waiting for approval, and building an app before you can even begin collecting data
- When you apply for API access, you have to provide the core use case and intent, but X doesn’t offer a clean list of “allowed” vs “disallowed” API use cases. Enforcement and interpretation of the intents are vague.
As a result, data analytics teams are turning to scraping tools as an alternative, looking for solutions that can deliver real-time and historical data, easily integrate with analytics dashboards such as Power BI or Tableau, and provide structured formats that can be fed into LLM pipelines.
To make data collection efficient, a Twitter/X scraper should ideally:
- search by keyword or hashtag to monitor tweets about certain topics, trends, or events.
- collect user and profile information to track competitors and (mis)information sources.
- extract large volumes of data to build targeted datasets for sentiment analysis, language modeling, or forecasting.
Let’s compare the top five Twitter/X scrapers offered by Apify, PhantomBuster, Octoparse, TexAu, and Bright Data.
The best Twitter scrapers: Quick comparison
| Tool | Pricing | Data source & method |
|---|---|---|
| Tweet Scraper V2 – X / Twitter Scraper on Apify Store | From $0.40 / 1,000 tweets (with Starter plan) | Scrapes public tweets and other info by keyword, profile/handle, or list URLs; runs in the cloud, delivers JSON/CSV/Excel |
| PhantomBuster: Twitter Phantoms | From €69/month (Starter plan) | Scrapes specific datasets per Phantom (tweets, followers, likers, etc.); uses session-cookie authenticated scraping; runs in the cloud, exports to Sheets/CSV |
| Octoparse: Twitter Advanced Search Scraper | From $83/month (Standard plan) | Scrapes tweets and user data via UI, by entering keywords, hashtags, date ranges like X’s Advanced Search; runs locally or in the cloud, exports to CSV/Excel/JSON |
| TexAu Twitter Automations | From $79/month (Starter plan) | Scrapes data using connected Twitter accounts via cookie login; runs locally or in the cloud; exports to Sheets/CSV |
| Bright Data Twitter Post No-Code Scraper | Pay-per-use, $0.0015/record | Scrapes tweets and user information using URLs in large volumes; runs in the cloud, exports to JSON/CSV |
1. Tweet Scraper V2 - X / Twitter Scraper on Apify Store
This scraper is an all-in-one solution, supporting multiple data collection modes: by keyword, profile, list URL, or direct tweet links, so users can easily handle research, monitoring, and enrichment tasks without switching tools. It was designed by an independent creator on the Apify platform for scaling and speed, delivering over 1,000 tweets per minute. Thanks to the advanced search and filtering options, the output can be narrowed down to hashtags, time range, or locations, and results are delivered in clean JSON, CSV, or Excel formats.
Getting started
Create a free Apify account to open the scraper in Apify Console. Enter the search information of your choosing - the tool handles URLs, search terms, Twitter handles, or conversation IDs. You can also add filters and advanced options before running the scraper.
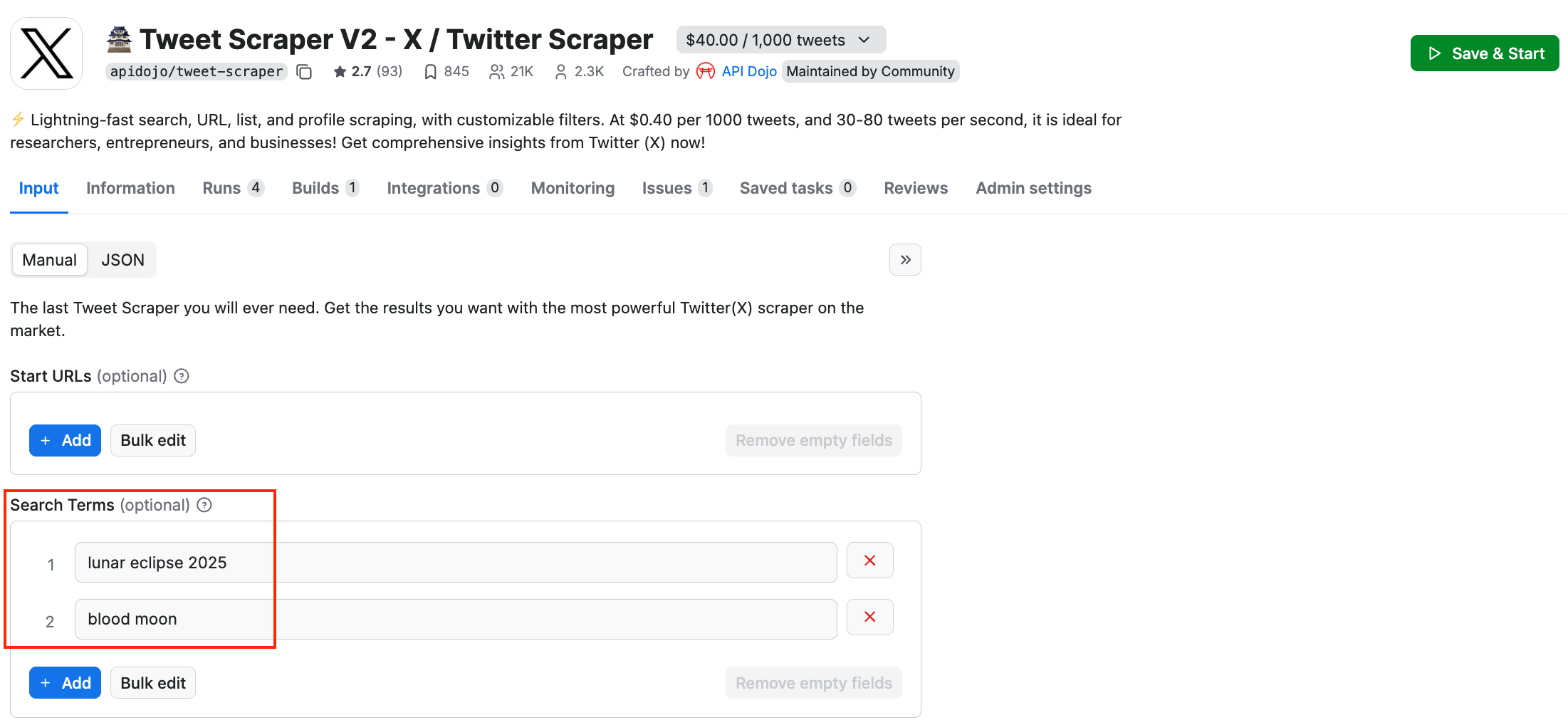
The advanced setup includes filtering your results by verified users, Twitter Blue, images, videos, and quotes. There’s also a Query Wizard feature to further narrow your output, if you want to collect tweets from a specific geo radius or posts mentioning another Twitter user:
Pricing: Starter Plan with $0.40/1,000 tweets
Pros
- Multiple scrape modes available: you can search using terms, profile/handle, URL, or by direct tweet URLs. Each of those matches a unique use case, such as trend tracking, competitor monitoring, research, or data enrichment
- Ideal for large-scale scraping - this tool was built for speed and delivers 30-80 tweets per second
- Rich filtering options supporting search operators with OR/AND logic, time ranges, language, and more
- Delivers structured output formats including JSON, CSV, and Excel
- Automations available: you can schedule runs and monitor tasks without manual input
- Proxy is already integrated without additional configuration needed
- Full API access is provided
Cons
- Learning curve for power users: setting up complex filters and combining search modes requires some technical understanding
- Reliant on the creator’s updates: If Twitter updates its frontend or anti-bot protections, you depend on the scraper’s author to do the fixes
2. PhantomBuster’s Twitter Phantoms
PhantomBuster’s platform offers a suite of specialized Phantoms (bots) for scraping Twitter/X. Phantoms are task-focused, designed to automate targeted data extraction. Since the platform doesn’t offer an all-in-one solution, you need to use multiple Phantoms to create comprehensive datasets. For example, if you want to scrape both tweets and profile information, you’ll need to use both Tweet Extractor and Twitter Profile Scraper. Scraping multiple profiles is possible with a manually created spreadsheet.
Getting started
Sign up to access the PhantomBuster platform and navigate to the Solutions to find Twitter Phantoms. The initial setup depends on each individual scraper. We’re using the Twitter Profile Scraper as an example, so we’re adding a URL to start scraping. To scrape from multiple URLs we’d have to create a spreadsheet first and use it as our starting point.

Pricing: Starter plan 69€/month
Pros
- Multiple Phantoms available on one platform - since they’re highly specialized, they work well for targeted datasets
- Exports in CSV or JSON formats; there’s also an option to pull results via the API (on paid plans)
- Automated schedules are available
- Phantoms can be chained together using Flows - a unique, visual drag-and-drop builder that allows users to create complete scraping pipelines
- Free tier offers 2 hours of execution time
- Internal proxy is included
Cons
- You can only run so many Phantoms simultaneously. If you're running multiple extractions or flows across platforms, you'll hit concurrency limits, and finishing tasks may require waiting or upgrading plans
- Some Phantoms require a Twitter session cookie to run, which can raise privacy and security concerns: Your account can get blocked for heavy scraping, and if the cookie leaks, anyone can access your account without your password or 2FA
- Chaining Phantoms can be tricky - users have to match the input and output data between Phantoms, while making sure the session cookie is not expired (otherwise the data flow will break)
3. Octoparse - Twitter Advanced Search Scraper
Octoparse offers a no-code Twitter scraper built specifically around Twitter’s Advanced Search interface, making it ideal for collecting tweets based on keywords and date ranges without writing code. It collects detailed information such as tweets, retweets, images, replies, likes, views, followers/following, conversation threads, and more. It can run either on desktop or in the cloud.
Getting started
Create an Octoparse account and find the Twitter Advanced Search Scraper template. To start, enter keywords, hashtags, and a date range, just like you would on the X’s Advanced Search page. Next, select Scraping mode (to scrape tweets from the last day, week, or month) and run the scraper.
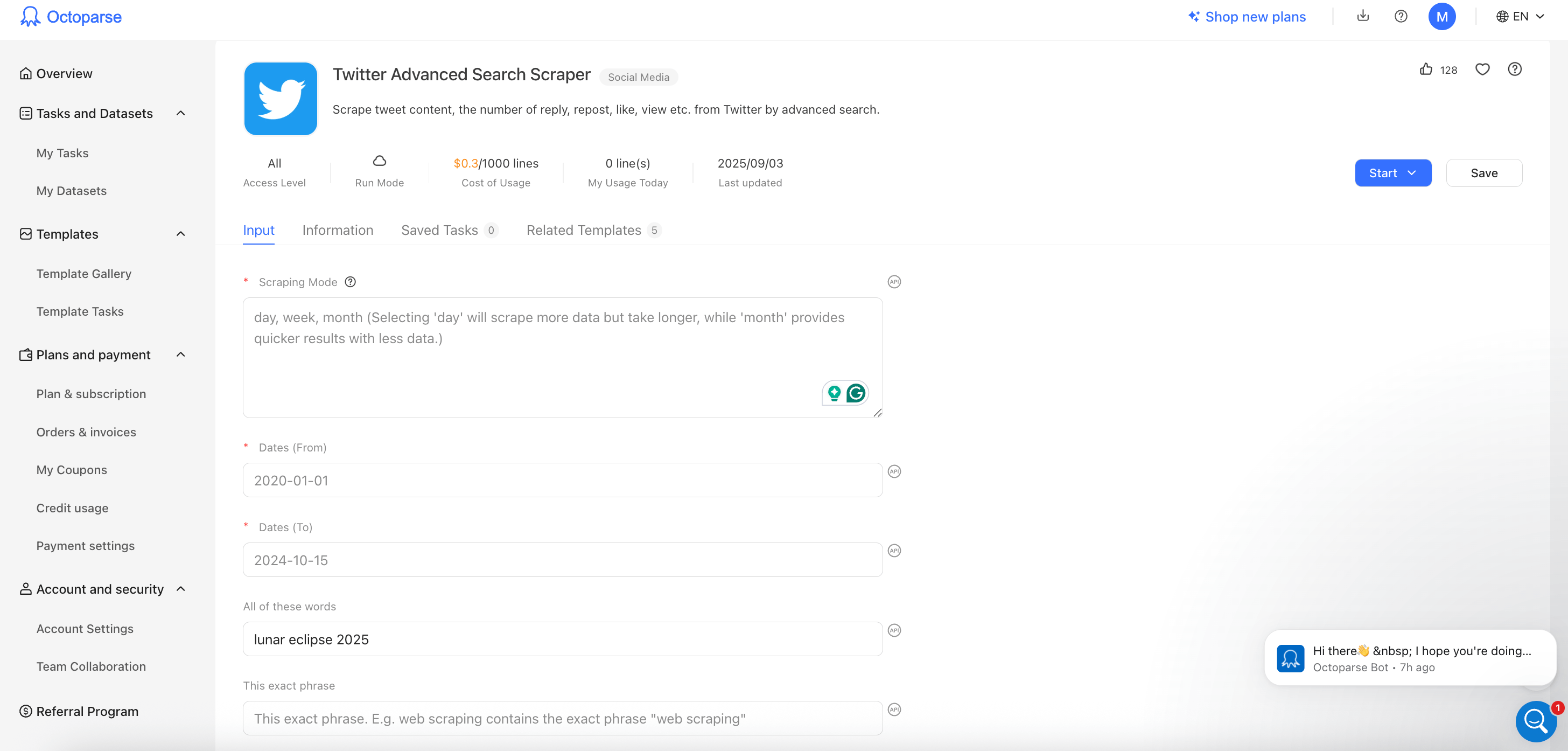
Pricing: Standard plan from $83/month
Pros
- No-code UI - the default input is similar to the advanced search feature on Twitter/X
- Automated schedules are available
- You can export to CSV, Excel, and JSON formats
- Scraping modes (day, week, month) help users control data volume and the scraper’s performance, which reduces the risk of getting blocked for extensive scraping
- Allows for more control for the tech-savvy users - the configuration is not pre-built, and you can edit every step of the scraping workflow, including wait times, scroll behaviour, and more
Cons
- Key features are unavailable on the Free plan (such as proxies, cloud backup, file downloads, and CAPTCHA solving)
- API access is available only on the Professional plan and above
- Historical results are limited - this scraper extracts data from up to 30 days in the past for your chosen keywords/hashtags
- Due to manual setup, it has to be maintained and updated frequently (e.g. selectors can break when X/Twitter changes HTML, and you might end up spending time fixing workflows instead of analyzing your data)
- Proxy use requires an additional configuration step and is paid separately from the subscription plan
4. TexAu Twitter Automations
TexAu provides a collection of ready-made Twitter automation tools designed for data extraction and account management. The automations extract profile data, website links, follower counts, subscribed lists, and more - each one focusing on a specific task. Runs can be executed in the cloud or locally via TexAu’s desktop app, and results are exported directly to formats like CSV or Google Sheets, making it a flexible option for analysts who need clean profile-level data.
Getting started
Register to get started and find the Twitter Automation of your choice - the setup will differ slightly with each tool. The next step for the Twitter Profile Scraper is importing your Twitter/X account(s) via secure link or cookie authentication and configuring the input. Here, you need to add a Twitter profile URL to scrape, or create a spreadsheet with URLs to scrape multiple profiles. You can also turn on Loop Mode to reprocess the Google Sheet from the start once all rows are completed, or define the number of rows of data to process.
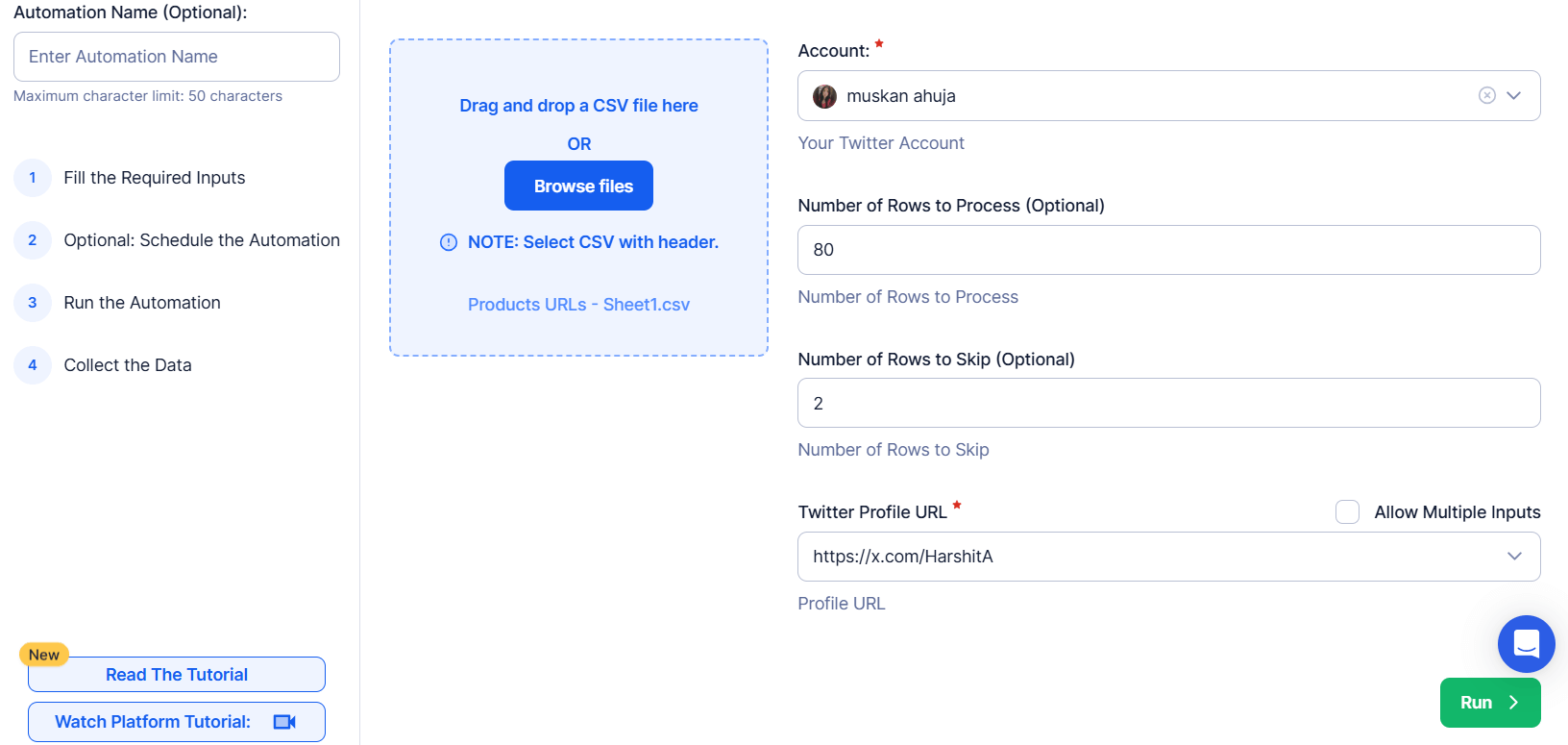
Pricing: Starter plan $79/month
Pros
- Many specialized automations available on one platform - a modular approach that works well for targeted datasets and data enrichment
- Support for Google Sheets, CSV/Excel exports
- You can run automations either in the cloud or locally via a desktop app (without burning the cloud monthly hours)
- Scheduling options are available for the cloud-based runs
- Proxy use is built in
Cons
- Pricing plans are based on scraping time instead of results (30h with the Starter plan), so it’s hard to realistically predict monthly volumes given possible delays, retries, and anti-bot throttling that reduce scraping speed
- API access available only in higher-priced plans - Teams and up (driving monthly subscription cost to $199)
- Automations require connecting your Twitter/X account to the TexAu platform, which can raise privacy and security concerns: your account can get blocked for heavy scraping, and if the cookie leaks, anyone can access your account without your password or 2FA
- Lack of detailed documentation for complex workflows
5. Bright Data Twitter Post No-Code Scraper
Bright Data offers a pre-built, cloud-based data collector for Twitter that runs in Bright Data’s infrastructure. To fetch your data, you can use profile URLs or Twitter search URLs containing keywords/hashtags. The scraper delivers structured tweet data (text, timestamps, engagement metrics) as JSON or CSV files, without code. It’s built for processing large volumes with batch processing support and an extensive proxy network.
Getting started
Create a Bright Data account and find a Twitter scraper in the library. Then you can add URLs and choose a scraper mode: the synchronous run for real-time data or asynchronous (recommended for high-volume requests without the need to serve an immediate or live response). You can also add other settings, such as record limit or defined output fields.
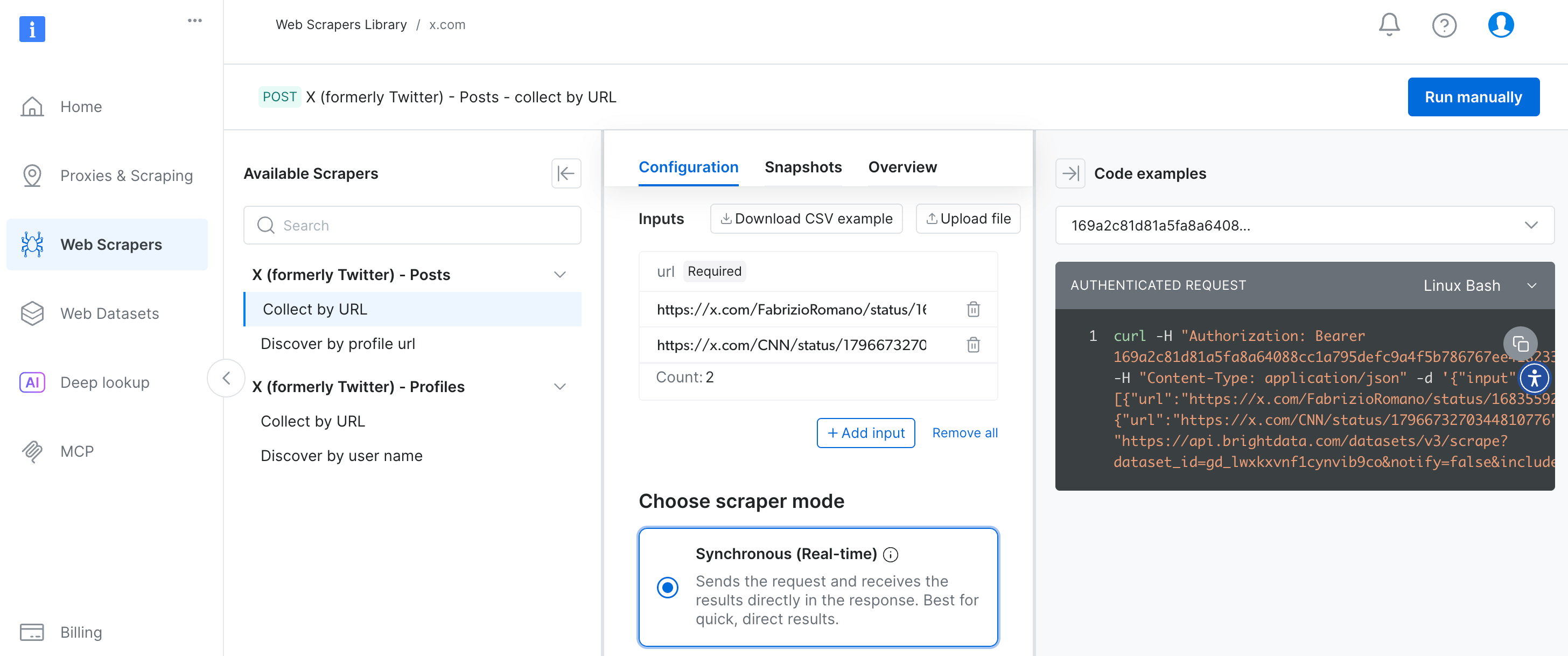
Pricing: $0.0015 per record
Pros
- Free trial with test credits for 7 days without a credit card
- Built for high volumes. The platform handles high concurrency with hundreds of scrapers running in parallel, as well as batch processing - you can upload a CSV file with a large amount of URLs to process in one go
- All-in-one solution that delivers not only tweet data (text, timestamp, likes, replies, and more), but also user information (such as profile bio, profile image URL, and number of followers)
- Every run creates a Snapshot with a packaged dataset containing results and metadata, which makes large jobs auditable, versioned, and easy to reproduce or share between team members
- Proxies are built in
- API usage is included by default
Cons
- Manual work is needed to scrape hashtags or keywords: you have to build the URLs first, as there is no keyword/hashtag input field in the UI
- Advanced filtering options aren’t offered, so the collected data needs a heavy post-processing
- Default export without API access is available in JSON and CSV only
- Lack of tutorials and documentation for non-tech users
Start scraping
Each of these tools takes a different approach, and the best choice depends on your budget, the scale of your data collection project, and how tech-savvy your team is:
- Tweet Scraper V2 – X / Twitter Scraper is the most powerful for bulk tweet collection and advanced filtering at scale - it handles tens of tweets per second, processes multiple URLs at the same time, and can collect deep historical data, which most scrapers can’t
- PhantomBuster and TexAu excel at profile-based data collection and custom workflow automation
- Octoparse stands out for its visual no-code UI that mimics Twitter’s Advanced Search, ideal for non-technical researchers
- Bright Data is ideal for enterprise-level scraping, with high concurrency and a proxy network

Note: This evaluation is based on our understanding of information available to us as of February 2026. Readers should conduct their own research for detailed comparisons. Product names, logos, and brands are used for identification only and remain the property of their respective owners. Their use does not imply affiliation or endorsement.
FAQ
What kind of data can I get from tweets?
Scrapers can return tweet text, timestamps, follower counts, author info, like/retweet counts, media URLs, and referenced/quoted tweets. Please note that scraped data may be incomplete or inconsistent if tweets are hidden, deleted, or restricted.
Do I need a developer account to scrape Twitter?
No, you don’t need a developer account to scrape. You need a developer account if you want to use the official API, which requires an application and an approval process.
What’s the difference between scraping and using the official API?
Scraping pulls raw data from the public web interface (HTML pages, internal requests), while the official API gives structured data (JSON) through documented endpoints. Scraping is quicker to start and can bypass application requirements. The API is stable and supported, but it requires approval and paid plans for any meaningful volume.



