We publish primarily about product improvements but rarely talk about the underlying platform changes that drive them.
With the new year, it's a great time to summarize some technical achievements under the hood, what tools we’ve implemented, and what lies ahead. A lot has happened over the past year! And while these changes may not be immediately apparent, they have a significant impact on you, our users.
🚀 We’ve reached 24,000 monthly active users, accounting for about 100% growth.
⚙️ Our product teams created, reviewed, merged, and deployed over 5,000 pull requests.
Migrating and rewriting 160k lines of code
In April, we finished the largest project in Apify’s history: migrating Apify Console from Meteor.js to the NestJS framework.
Meteor was built during the early Node.js era, using fibers to simplify async development. While convenient before promises and even async/await were released, it was stuck on Node.js 14, which reached end-of-life in 2023. To modernize, we gradually migrated 120,000+ lines of backend code to NestJS, converting everything from fibers to async/await and JavaScript to TypeScript.
Here’s how we managed the migration over six months:
- Both old and new server codes lived in the same monorepo.
- Backend endpoints were migrated one at a time to the NestJS server.
- Shared code was moved into NPM packages within the monorepo.
- Cron jobs transitioned to AWS Lambda functions.
- Once the backend migration was complete, the frontend bundler switched to Vite.
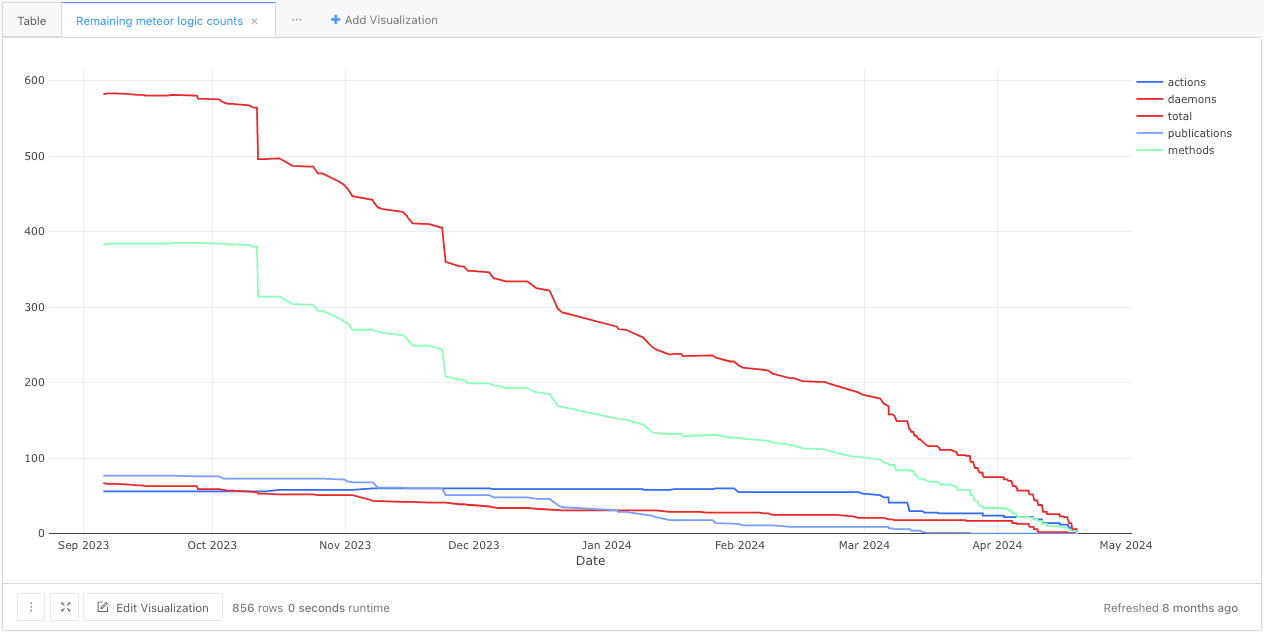
Results of this migration:
- UI bundle size shrank by 47%, speeding up load times.
- Production builds now take 3.5 seconds instead of 17.5 minutes.
- Local development builds dropped from 3 minutes to 500ms.
- TypeScript’s strict mode catches errors earlier.
Transitioning payments to Stripe
We moved from Braintree to Stripe to improve payment success rates and access advanced anti-fraud tools. Migrating over 10,000 user payment details went smoothly, thanks to careful planning - critical since Braintree allows only two export attempts during transitions.
Enabling other teams
We upgraded Strapi CMS implementation to help our marketing team launch over 40 landing pages without developer involvement:
We also implemented GrowthBook to give our product managers better control of A/B testing and feature flagging and started integrating Segment to enable our data team to control the flow of our metrics and user events.
Discovering new limits on the infrastructure side
Every system has its limits. For example, we use internal DNS to route traffic within our VPC. Earlier this year, we hit a DNS record size limit that caused system crashes. Switching to DNS over TCP solved this temporarily, but we also ran into AWS Route53's 400 IP address limit per DNS record. To address this, we now route traffic to nodes instead of pods, giving us some more space to grow, and we plan to adopt internal load balancers for long-term scalability.
Python as our new competency
JavaScript has always been our go-to language for the simplicity of having one language for everything from front end to infrastructure, but Python is the dominant language in web scraping and automation. To support the Python community, we added Python engineers to our open-source team, resulting in the release of Crawlee for Python.
In a few months, Crawlee for Python gained:
- 5k GitHub stars
- 300+ forks
- 40k monthly downloads
Porting Crawlee from TypeScript to Python was challenging, but we ensured the asynchronous API remained familiar while aligning with Python standards. Check out the code here to see how we have managed: Crawlee Python GitHub.
Unifying the look with the design system
Over time, our user-facing applications - apify.com, console.apify.com, docs.apify.com, and blog.apify.com - diverged in design. This year, we introduced a unified design system using shared components and design tokens. So far, we’ve partially standardized 21,000 URLs across our platforms.
Scaling our databases
Our main 1.5 TB / 32 vCPU MongoDB cluster hit performance bottlenecks, prompting us to optimize and monitor queries continuously. We now automatically track slow queries, deduplicate them, and assign them to the relevant teams via Sentry. This system ensures prompt fixes and clear assignments among teams.
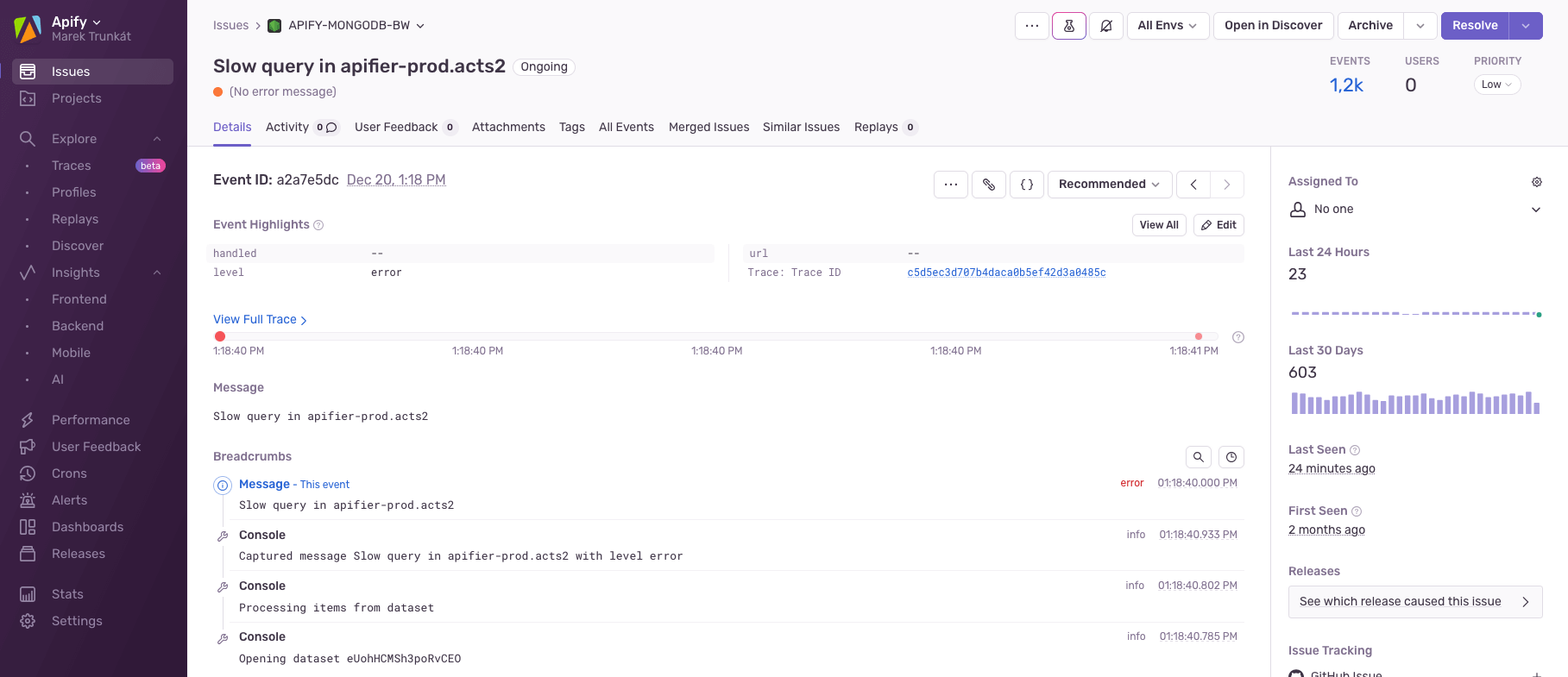
To sustain growth, we plan to make more database structure changes in the upcoming year, including sharding our main MongoDB cluster.
Improving our monitoring capabilities
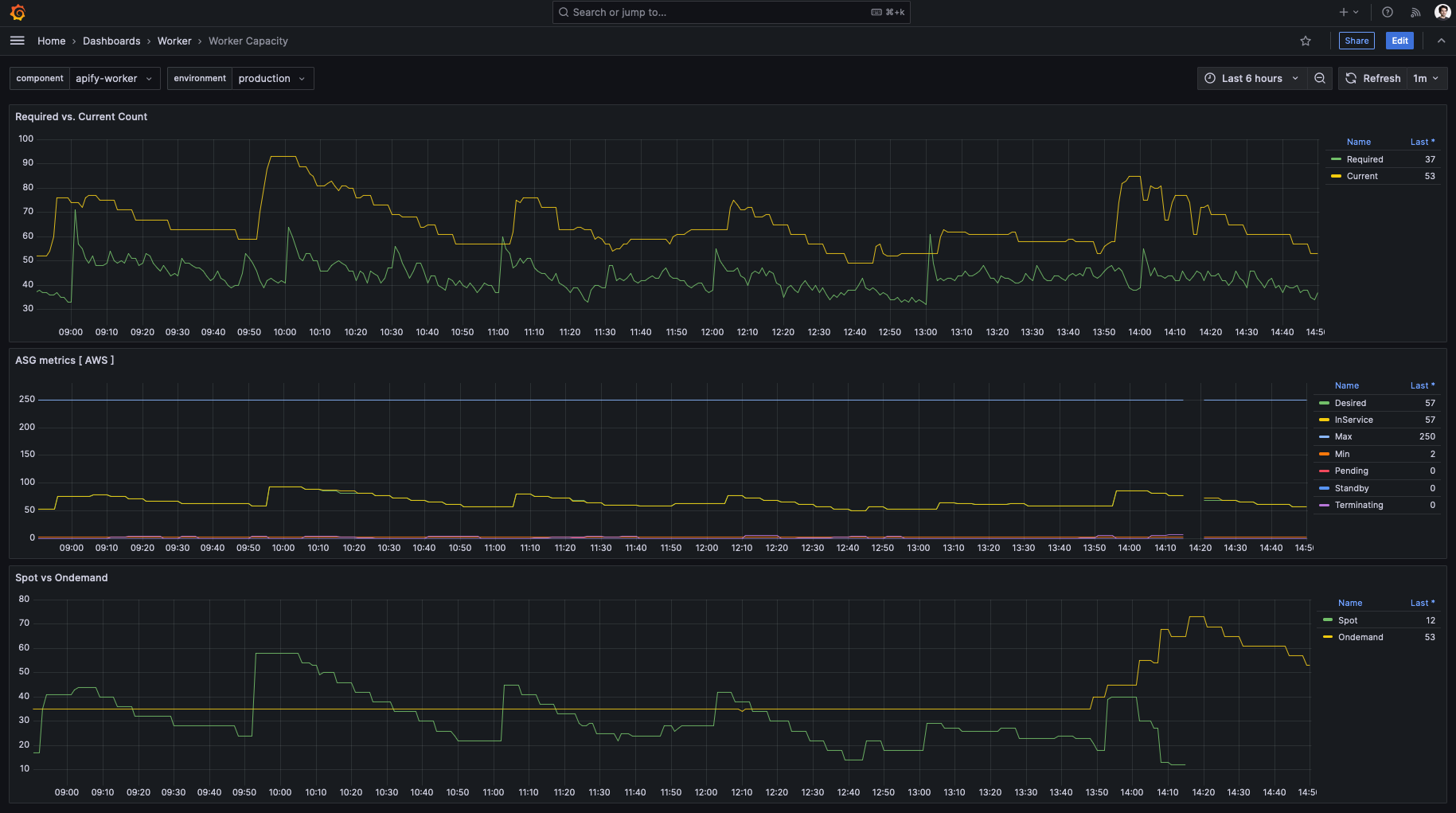
With hundreds of servers running and PBs of data flowing between our services and the internet, we rely heavily on good observability tools. We have used New Relic for many years, but with current volumes and team size, we have become blocked by some New Relic limitations and the overall cost.
In 2024, we migrated to a self-hosted Grafana stack powered by Mimir, Prometheus, and Tempo. This allowed us to ingest more metrics for optimizing workloads at less than half the original cost, so that Apify can continue to perform well.
Organizational changes
In June, we proceeded with a small reorganization of our teams to better align them with user personas and product areas. This allowed us to assign individual teams ownership of the main product metrics.
We also created two new product teams: one focused on AI and the other on integrating Apify with external platforms like Make, Zapier, and Keboola. This aligns with our 2025 strategy to target the AI market, including AI agents and tech partnerships through programmatic integrations.
To accommodate growth, we onboarded our first two engineering managers, Jakub and Vlada. Each is responsible for one independent group of teams on our shared mission.
- Related: When engineering meets improv: Off-script engineering with Kuba Wolf
Making sure we don’t need a rollback
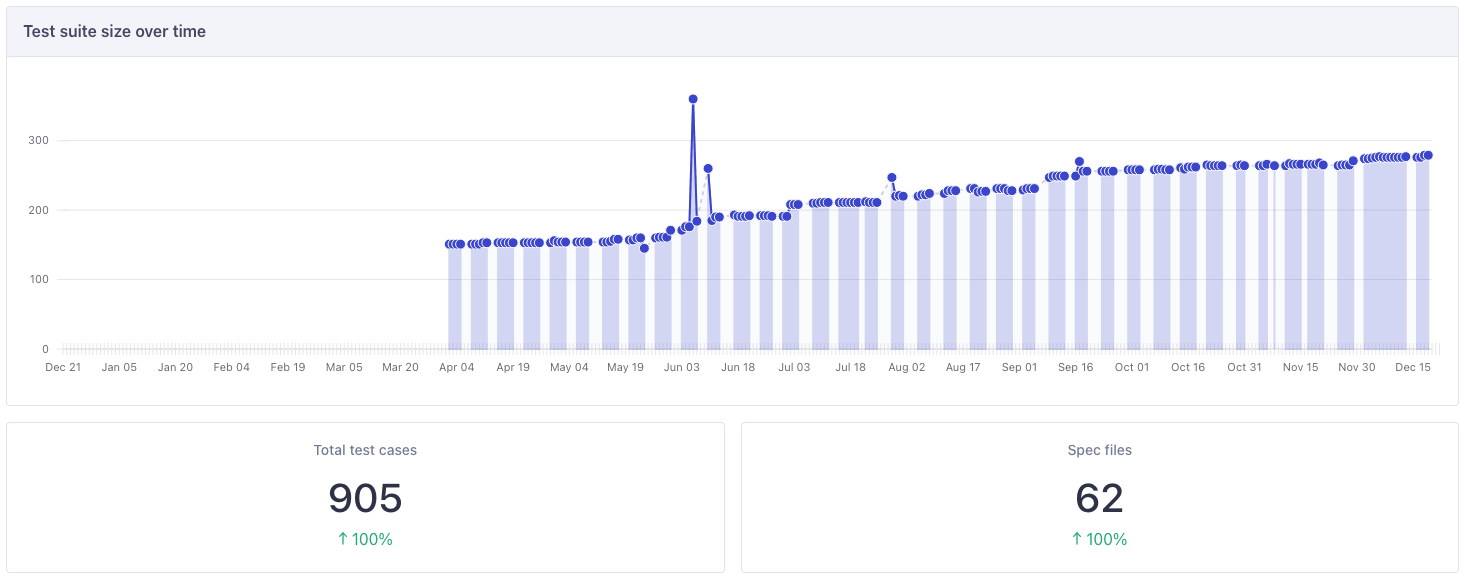
We also established a QA engineering role within our organization, with Terka leading this area. To better control test suite size and identify flaky tests, we started using Cypress Cloud, which says we grew our test suite by about 100% in 2024.
For Actors in Apify Store that we manage, we unified the CI/CD, bringing standardized testing for input options to ensure that we won’t break anything.
Networking and tech community
2024 was very fruitful regarding public speaking:
- Our developer community manager, Saurav Jain, spoke at Euro Python Prague.
- I went to Arrtist Berlin.
- Jiri Moravcik went to the Big Data Conference in Vilnius and PyData Prague.
- Josef Valek and Jan Kirchner later spoke at the PragueJS meetup.
- Matej Wolf spoke at Python Pizza Prague.
- Katerina Hronikova and Honza Kuzelik mentored a team in Czechitas.
We also hosted many meetups in our Prague Office—PyData, PythonPizza, DevOps, Engineering Leaders, Webexpo opening party, DataMesh, and various other meetups. See the video to experience the vibe we have here 👇
By the way, our own Discord community will soon reach 10,000 members!
What’s ahead of us?
This year, we'll tackle both scaling our organization and managing production workloads. We plan to build two new product teams and anticipate similar growth in load. Our focus includes making the Actor startup times more predictable by optimizing our internal runtime and allocator, and investing significantly in our database structure to overcome current limits.
With all this, we're looking for talented engineers across all frontend, AI, backend, and infrastructure. Are you up for the challenge?