
Content
Introduction to XPath and contains()
XPath stands for XML Path Language. It's a language used for navigating through elements and attributes in an XML document. Given its flexibility and precision, XPath is widely used in web scraping and automation testing to search through the HTML structure of web pages.
XPath's utility can handle dynamic content, which is where the contains() method comes in handy. The contains() function is great at matching elements that include a specified string within their text or attributes, making it a useful tool for dealing with web pages where content or attributes might change dynamically.
XPath syntax: how it works
XPath expressions can be categorized into absolute and relative paths.
Absolute XPath paths start from the root node and traverse down to the desired element, specifying each ancestor element in the hierarchy (e.g., html/body/div[0]/input). However, this approach is not the best, as any change in the document structure can invalidate the path.
Relative XPath (e.g., //input[@type='text']), on the other hand, allows for more flexibility and robustness, particularly when combined with functions like contains(). This method doesn't require a detailed path from the root, making it more resilient to changes in the document.
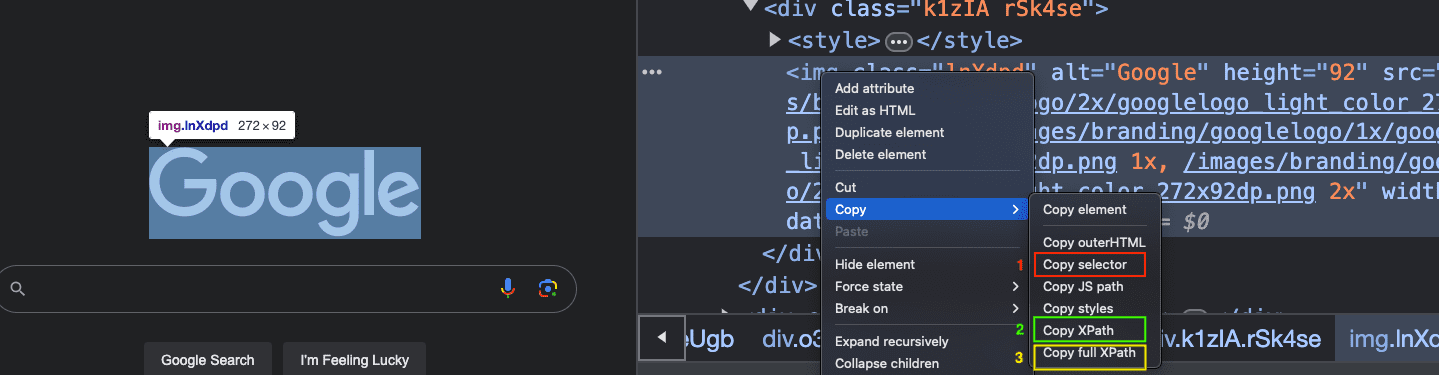
To further explain the process of creating selectors, consider using the browser's developer tools. Visit the Google Search page, right-click on any element, and then click on inspect. This will open the developer tools and highlight the selected element. Right-click on the element code and select Copy → Copy XPath or Copy full XPath,allowing you to obtain an element's XPath. Comparing this with the Copy selector option, which provides a CSS selector, can help you understand the differences between using XPath and CSS selectors. This approach in the browser is not only a convenient way to generate selectors but also aids in building the logic for more complex use cases.
//tagname[contains(@attribute, 'value')]//represents a relative path to the current page.node tagnamerepresents a reference to an element, e.g., input, div.@is used to select the attribute of an element. e.g., id, class, name.valueis used to reference the value contained in the attribute selected.
Using contains() to select elements by text
The contains() function can significantly simplify the task of selecting elements that include specific text. The syntax for using contains() is as follows:
//div[contains(text(), 'apify')]. This expression will select any div element containing apify.
The strength of contains() lies in its ability to handle elements with dynamic text or attributes. This enables users to target content that may not be exactly predictable.
Using XPath contains and advanced XPath techniques
To showcase the practical applications of contains(), consider the following examples.
- Example 1
Imagine you have an HTML document representing a blog post, which includes various sections, comments, and nested replies. Your goal is to find a specific comment by a user named "John Doe" and retrieve all replies to that comment.
<div class="post">
<h2>Simple Blog Post</h2>
<div class="comment" id="comment1">
<p class="author">Jane Smith</p>
<div class="body">This is a comment.</div>
</div>
<div class="comment" id="comment2">
<p class="author">John Doe</p>
<div class="body">I have a question.</div>
<div class="reply">
<p class="author">Alice</p>
<div class="body">Here's an answer.</div>
</div>
<div class="reply">
<p class="author">Bob</p>
<div class="body">Another perspective.</div>
</div>
</div>
</div>
//div[contains(@class, 'comment') and descendant::p[contains(@class, 'author') and contains(text(), 'John Doe')]]/div[contains(@class, 'reply')]
//div[contains(@class, 'comment')]:
Selects all divs that have a class containing "comment".descendant::p[contains(@class, 'author')andcontains(text(), 'John Doe')]:
From those comment divs, it further narrows down to those having a descendant paragraph(<p>)with a class of "author" and containing the text "John Doe"./div[contains(@class, 'reply')]:
Finally, it selects all direct child divs of the filtered comments that have a class containing "reply", which are the replies to John Doe's comment.
- Example 2
Suppose you're working with a dynamic web page that includes a list of notifications. These notifications have varying content, and you want to select all notifications that contain the word "urgent".
<ul class="notifications">
<li class="notification" data-type="update">System update available.</li>
<li class="notification" data-type="alert">Urgent: Security alert!</li>
<li class="notification" data-type="message">You have new messages.</li>
<li class="notification" data-type="alert urgent">Urgent: Meeting at 3 PM.</li>
</ul>
//li[contains(@class, 'notification') and contains(@data-type, 'urgent')]
//li[contains(@class, 'notification')]:
Selects all<li>elements that have a class containing "notification".contains(@data-type, 'urgent'):
Further filters those<li>elements to only those with a data-type attribute containing the word "urgent".
- Example 3
Imagine you are working with an online bookstore webpage that lists books in a structured format. Each book is contained within a div with the class, book, and each div includes details like the book title, author, and a list of genres it belongs to. There's also an Add to Cart button for each book.
<div class="book">
<h2>Book Title A</h2>
<p>Author: Leom Ayodele</p>
<ul class="genres">
<li>Fiction</li>
<li>Adventure</li>
</ul>
<button>Add to Cart</button>
</div>
<div class="book">
<h2>Book Title B</h2>
<p>Author: Leom Ayodele</p>
<ul class="genres">
<li>Non-Fiction</li>
<li>Science</li>
</ul>
<button>Add to Cart</button>
</div>
:bulb:
//div[contains(@class, 'book') and descendant::p[contains(text(), 'Leom Ayodele')] and descendant::li[contains(text(), 'Fiction')]]/button
//div[contains(@class, 'book')]:
Selects all div elements with a class that contains "book".descendant::p[contains(text(), 'Leom Ayodele')]:
Further filters those div elements to only include those that have a descendant<p>element containing the text "Leom Ayodele".descendant::li[contains(text(), 'Fiction')]:
Narrows down the selection to those div elements that also have a descendant<li>containing the text "Fiction"./button:
Selects the child<button>element of the filtered divs, which is the "Add to Cart" button for the book that matches both the author and genre criteria.
These examples showcase how to precisely target elements by navigating the DOM structure using XPath axes and logical operators. The descendant is used to look down the DOM tree from the selected div elements to find matching criteria deep within its structure, demonstrating a powerful way to locate elements that might not be directly accessible due to complex HTML structures.
When XPath cannot be used to find an element, either due to the page complexity or structure or dynamic content that changes the DOM after page load or any other reasons that may occur, below are useful approaches to handle such situations:
- CSS selectors are often simpler and can sometimes access elements more easily than XPath, especially for web pages with well-defined class and ID attributes. Modern web automation tools and libraries, like Selenium or Puppeteer, support CSS selectors alongside XPath, providing a good alternative for element selection.
- In cases where elements are not immediately available due to asynchronous operations (e.g., AJAX calls that fetch data after the initial page load), using explicit waits or polling mechanisms can help. Libraries like Selenium provide explicit wait functions to wait for an element to become present or visible before attempting to interact with it.
- Some automation tools offer functions to search for elements based on their visible text, not just their attributes. This can be an alternative when the structure around the text is too complex for a straightforward XPath, but the text content itself is predictable.
- Sometimes, the limitations are not with XPath itself but with how a particular tool implements or supports XPath. Exploring different automation tools or libraries might reveal one that works better with the web page in question or offers more powerful features for dealing with dynamic content.
Choosing the right approach depends on the specific challenges you're facing, such as the complexity of the web page, the nature of the dynamic content, the tools and libraries you're using, and the stability of the elements you're trying to interact with. In many cases, a combination of these strategies will provide the best results.
XPath tools and frameworks
Several tools and frameworks enhance the experience of using XPath, e.g., Selenium and Scrapy. These environments provide robust support for XPath, including the contains() function, facilitating complex web scraping and automation tasks.
You can also test XPath expressions, including those with contains() by using the $x() function in your browser's console. For instance, on a Google search page, open the developer tools, click on the console tab, and input $x('/html/body/div[1]/div[2]/div/img') to select the Google image on the page. This method allows for immediate experimentation with XPath queries in your web browser, reducing the development process for your automation tasks.
Implementing the contains() function in both Selenium and Scrapy allows for flexible text matching within element attributes or text content, making it easier to locate elements that match specific criteria. Here are brief examples for each:
Selenium with Javascript
In Selenium, the contains() function is part of the XPath query. You can use it to find elements that contain specific text or attribute values. Here's how you might use it in a Selenium script written in JavaScript:
import { Builder, By } from 'selenium-webdriver';
// Initialize the WebDriver for Chrome
let driver = await new Builder().forBrowser('chrome').build();
try {
// Open a webpage
await driver.get('<https://blog.apify.com/author/ayodele/>');
// Use contains() to find an element with a specific text
let element = await driver.findElement(By.xpath("//a[contains(text(), 'upload files in Puppeteer')]"));
// Use contains() to find an element with a specific attribute value
let elementWithAttribute = await driver.findElement(By.xpath("//div[contains(@class, 'post-info-')]"));
// Add your interaction with element here
// For example, click the element: await element.click();
} finally {
// Don't forget to close the driver
await driver.quit();
}
This example demonstrates how to locate elements by partial text match and partial attribute value match using contains() in your XPath expressions within a Selenium script.
Scrapy with Python
Scrapy is a powerful web scraping framework that uses selectors to extract data from web pages. You can use the contains() function in Scrapy selectors to select elements that contain certain text or have attributes that contain a specified value.
Here's a basic example of using contains() in a Scrapy script:
import scrapy
class ExampleSpider(scrapy.Spider):
name = 'example'
start_urls = ['<https://blog.apify.com/author/ayodele/>']
def parse(self, response):
# Use contains() to select links that include the word 'Puppeteer'
tag_links = response.xpath("//a[contains(text(), 'puppeteer')]/@href").extract()
# Log or further process the extracted data
self.log(f"Puppeteer Tag Links: {tag_links}")
This Scrapy example shows how to use contains() in XPath queries to extract links containing the text "Puppeteer".
Both examples illustrate the basic usage of contains() in XPath expressions within the context of Selenium and Scrapy. These snippets provide a basic usage for locating elements based on partial matches, which is especially useful in dynamic web environments where exact matches are not always possible.
Using XPath in web scraping and testing
XPath's precision makes it a preferred choice for web scraping and automation testing. However, it's important to consider other methods like CSS selectors, which might offer simpler solutions for certain tasks. The choice between XPath and other techniques depends on the specific requirements of the project, including the complexity of the web structures involved and the need for dynamic content handling.
Why XPath is useful for web scraping and automation testing
- Precision in selection: XPath allows for the precise selection of elements, even in complex and deeply nested HTML structures. This precision is invaluable when you need to extract specific data points from a webpage or interact with particular elements during automation testing.
- Dynamic content handling: XPath expressions can be designed to handle dynamic content. Functions like
contains(),starts-with(), andtext()enable the selection of elements based on partial matches, which is useful for dealing with elements that have dynamically generated attributes, such as the class names in React applications. These are not readable and are regenerated with each component or app update. This approach allows you to select elements in a way that is resilient to changes in the DOM structure or attribute values.
- Traversal flexibility: XPath supports navigating the HTML DOM with various axes such as ancestor, descendant, following-sibling, and preceding-sibling. This flexibility allows users to select elements based on their relationships to other elements, which is particularly useful in complex web pages where direct selection is not straightforward.
- Logical operators: XPath expressions can use logical operators (and, or) to combine multiple conditions. This capability enables fine-tuned element selection based on multiple criteria, enhancing the effectiveness of both web scraping and automation testing tasks.
- Support across tools: Most web scraping and automation testing tools and libraries (like Scrapy, Selenium, and others) offer built-in support for XPath, making it a universally applicable skill set across different technologies.
Alternatives to XPath for specific purposes
While XPath is powerful, there are scenarios where other methods might be more efficient or better suited:
- CSS selectors: When the goal is to select elements based on their class, id, or style attributes, CSS selectors can be more straightforward and readable than XPath.
- JavaScript and browser APIs: In dynamic web applications where elements are loaded asynchronously or manipulated by JavaScript, using JavaScript in conjunction with browser APIs (like
document.querySelector()anddocument.querySelectorAll())can directly interact with the DOM post-render.
- Selenium WebDriver API: For web automation testing that requires simulating real user actions (like clicking, scrolling, and keyboard input), the Selenium WebDriver API provides a high-level interface to control the browser programmatically.
Each of these alternatives has its niche where it might outperform XPath, depending on the specific requirements of the task at hand. The choice between XPath and other methods depends on factors like the complexity of the web page, the nature of the dynamic content, the specific data or interactions required, and personal or project-based preferences for tooling and readability.
Conclusion
With its contains() function, XPath is a great tool for web scraping and automation testing, as it enables extraction and interaction with dynamic web content. Understanding and applying XPath effectively can significantly enhance the efficiency and reliability of web scraping and automation tasks.




