
Content
Hey, we're Apify. You can build, deploy, share, and monitor any data extraction tools on the Apify platform. Check us out.
Scraping text for mining and analysis
According to the latest estimates, 328.77 million terabytes of data are created each day. The sheer scale of this represents an opportunity and a challenge for anyone interested in mining and analyzing textual data.
Whether your reason for collecting and analyzing texts is training large language models, academic research, financial trading, lead generation, or any of the myriad uses for text extraction, it's not something you can contemplate doing on any medium to large scale without a tool that automates the process to some extent.
In this definitive guide to text scraping, I'll show you:
I'll demonstrate these by showing you how to use two simple but effective tools for extracting text from digital platforms: Website Content Crawler and PDF Text Extractor.
With the first tool, I'll show you how to scrape texts from a URL as well as store linked documents from that website. With the second, I'll show you how to extract the text from PDF documents.
To use either tool, you'll need to set up a free Apify account (no credit card required) so you can use the free credits you receive when you sign up to give them a test run.
What is text scraping?
Text scraping is a use case of web scraping, an automated method of extracting data from websites. If you’re retrieving and converting content from a website to text or extracting article URLs from the web, then text scraping is what you’re doing. The process often begins with web crawling, an automated method of searching web pages by starting with a list of URLs and processing them for extraction.
Web scraping has become a popular method of text data extraction among developers, students, scholars, and researchers. Data extraction software recognizes types of content on a website and can be configured to crawl and scrape data specified by the user. For example, if you wish to extract article URLs, titles, or authors from a news website, text scraping radically reduces the time you’d spend searching for sources.
What is text mining?
Text mining, also known as text data mining, is the next step after text scraping. It is similar to text analytics, as it involves deriving quality information from extant text data. You can discover hitherto unknown information by extracting such data from online resources. While text analysis grew from the field of humanities in the form of manual analysis, text mining and text analysis are now synonymous. Both are computational methods involving automated web crawling and scraping to search, retrieve, and analyze text data.
Is text scraping legal?
Scraping data available online for everyone to see is legal since it merely automates a task that a human would have to do manually. Just ensure not to accumulate sensitive information such as personal data or copyrighted content, which are protected by various international regulations. You can learn more about the legality of web scraping in a comprehensive treatment of the subject called Is web scraping legal?
How can you scrape text from a URL?
To extract texts from a URL, I'll use Website Content Crawler. This is a tool that automatically crawls and extracts text content from websites, knowledge bases, help centers, or blogs and then converts the output into the desired format.
While it was designed to feed and fine-tune large language models, WCC is the ideal tool for any text-scraping project because it's already configured to remove unnecessary content, such as banners, ads, footers, menus, and so forth. Chances are, that's not the kind of text content you want in your dataset.
So, let's see how it works.
1. Go to Website Content Crawler and try for free
Website Content Crawler is available on Apify Store. If you have an Apify account already, you'll be directed to your dashboard (Apify Console) when you click the Try for free button. If not, you'll be directed to sign up first.
The free monthly credits you get with a free Apify account are more than enough to give the tool a test drive and certainly enough for this tutorial to cost you nothing.
Step 2. Insert the Start URL(s)
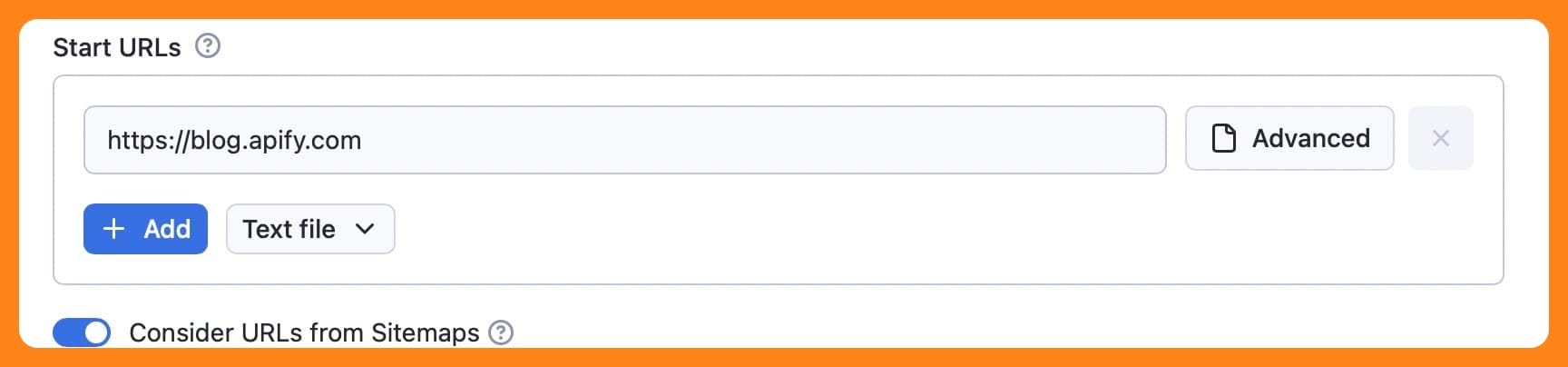
I'll start by adding the URL I want to scrape in the input field. If I want, I can add other URLs to the list, as well. These will be added to the crawler queue, and they'll be processed one by one.
2. Consider URLs from sitemaps
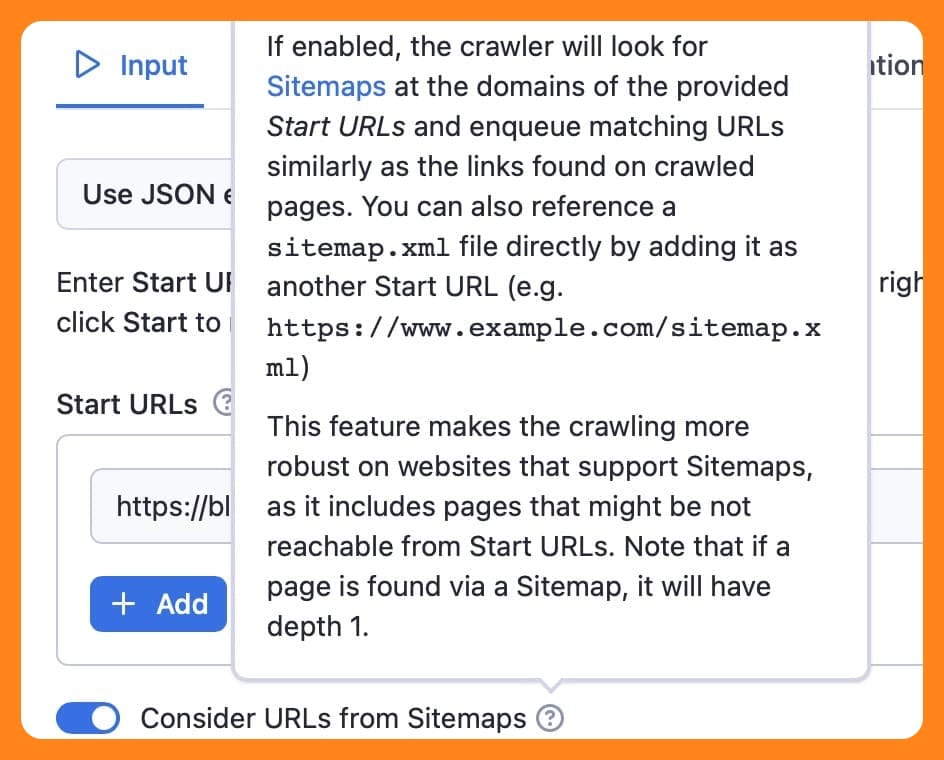
A new feature since I last wrote a tutorial on using this tool is the option to enable crawling sitemaps. And I'm really happy about it!
Enabling this option means the crawler will look for sitemaps at the domains of the provided Start URLs. This makes for much more accurate and reliable crawling, and in this particular case, it will come in very handy.
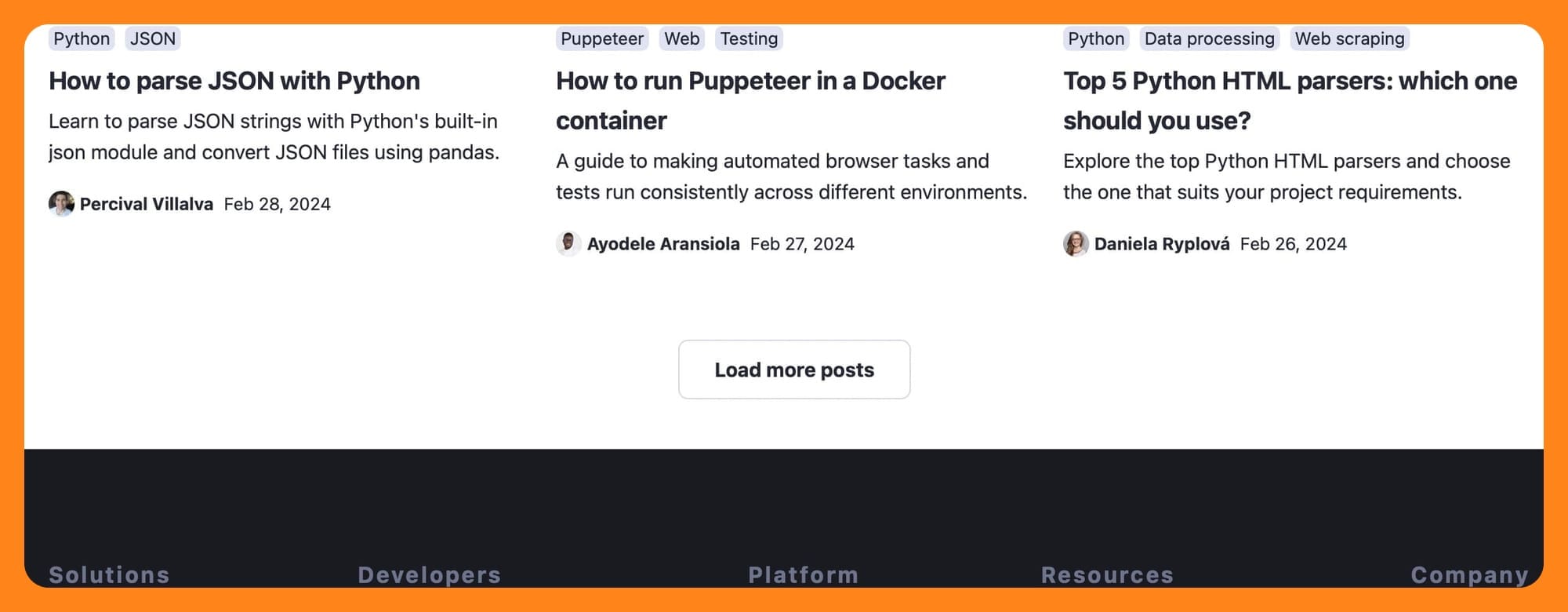
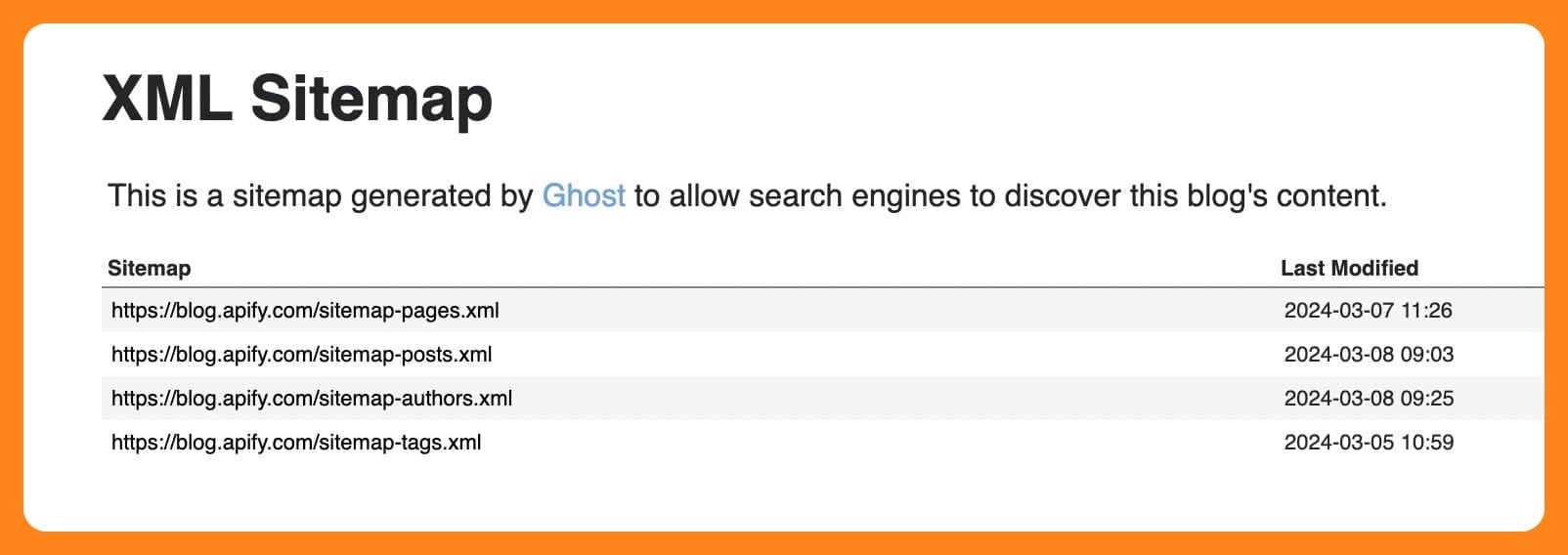
You see, the Apify Blog as a load more button. Crawling by sitemap means I'm sure to get all the articles from the blog, not just the articles on the first page and all the content linked to from the articles on that first page.
You can also use a sitemap URL in the Start URL field, if you want: https://blog.apify.com/sitemap.xml
3. Choose the Crawler type

The crawler type you choose depends on the structure of the website and what you need to extract. If you're dealing with a static website - something simple like documentation, for example - I recommend you choose the Cheerio option. It's way faster (I mean 20 times faster) than the default setting. This won't be able to deal with dynamically loaded content, though.
If you need a browser or wish to render client-side JavaScript, you have two options: the default Firefox+Playwright option and the Chrome+Playwright option. The Firefox mode is the slowest (it could take hours and will require more compute units, which means higher cost) but it's the most reliable and is better for anti-bot blocking. The Chrome browser is more detectable by anti-bot protections, but it's quicker and requires less memory.
Now, if you're having trouble deciding which crawler type to use, here's another cool new feature of Website Content Crawler: the adaptive switching mode.
While this is still experimental, please do try it! Instead of wasting your time trying to work out if and when to use Playwright, Puppeteer, and Cheerio, this mode handles it for you. Website Content Crawler automatically detects pages that can be processed with plain HTTP crawling and only switches for necessary content.
The result? It's faster than regular Playwright mode while also being able to process dynamic content.
4. HTML processing and output settings

Believe it or not, these are the only options that concern us in this case, as the default settings mean WCC will not be crawling and extracting menus, footers, ads, and so on, thanks to the built-in HTML processing features. But before I run the crawler, a word about saving files in the output settings, as this will be relevant for later.
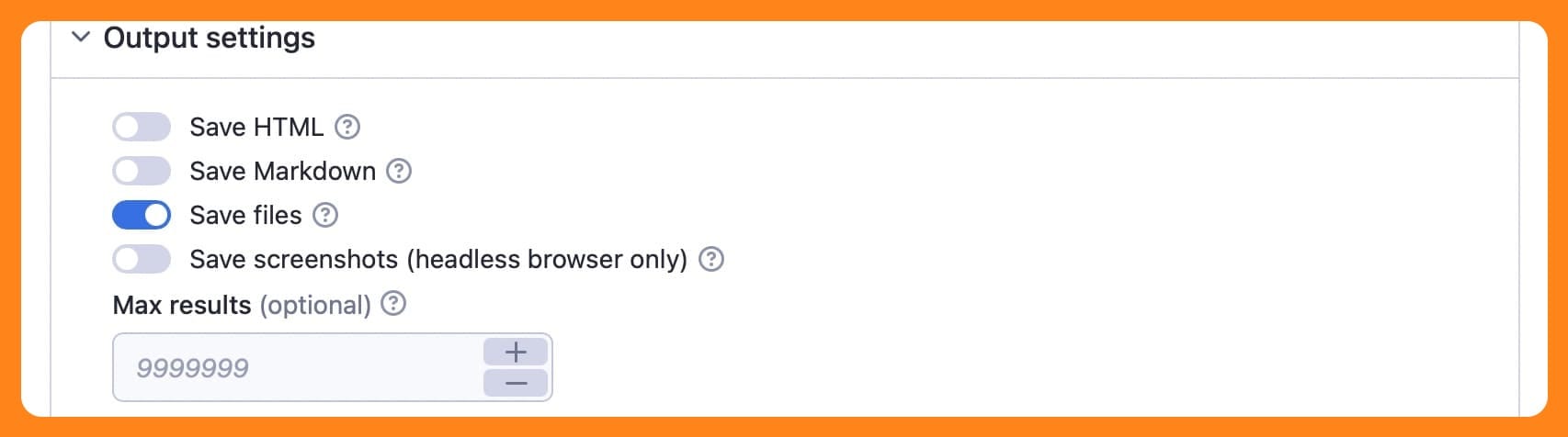
If you choose save files in the output settings, the crawler inspects the web page, and whenever it sees a link that goes to a PDF, Word document, or Excel sheet, it will download it to the Apify key-value store. However, it will not be able to extract text from within those documents. For that, we'll need a different tool, but more about that later.
5. Run the crawler to scrape and store text data
Clicking the save & start button will save your configuration and execute the code to run the crawler as specified. While it's running you can check the log to see if it's experiencing any problems, and you can abort the run at any point.
6. Export the extracted data
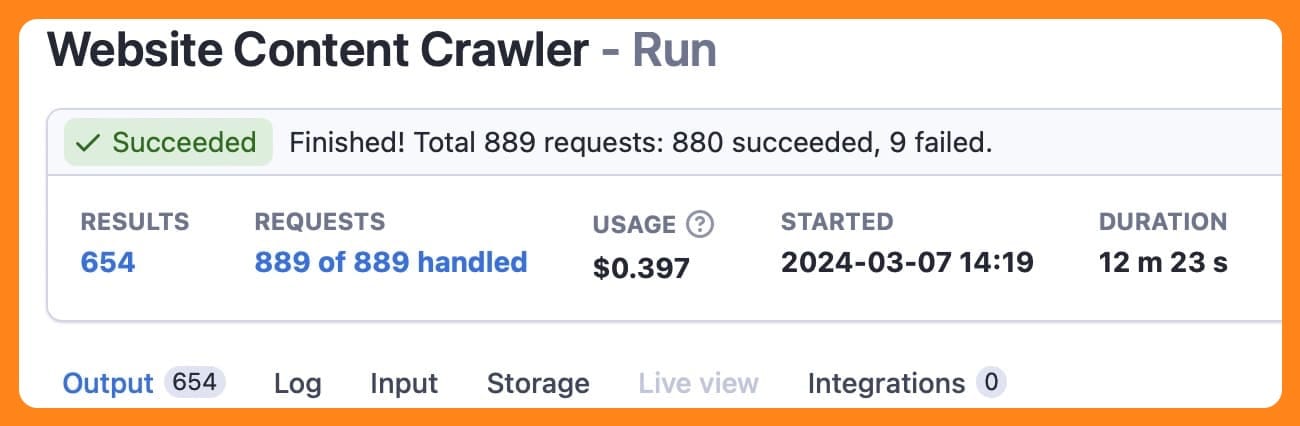
When a run has been successfully completed, the status will change from running to succeeded. The above run was using the adaptive switching mode. As you can see, it finished in just over 12 minutes. Below is the same run using the Cheerio mode, which completed the same task in just over three minutes but will not have retrieved any dynamically loaded content.
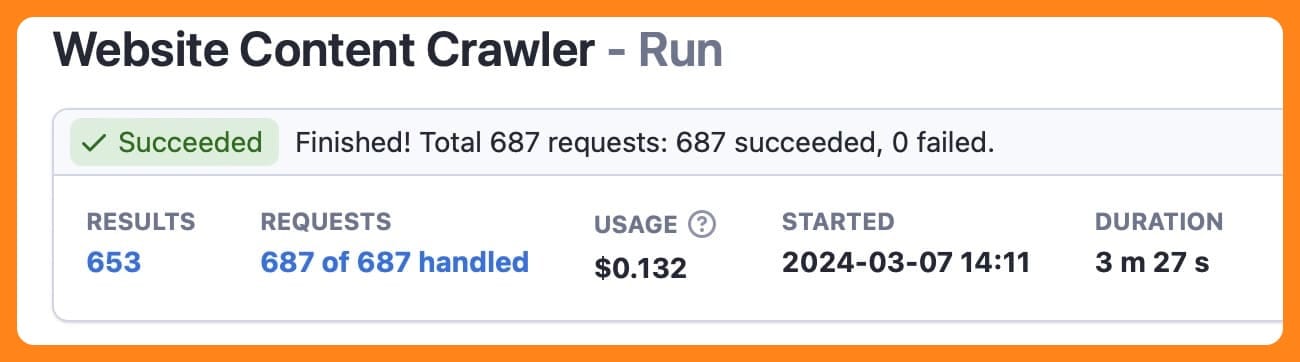
You can now view and download the extracted data by clicking on the export results button. Before you do that, you can see what data the crawler has extracted in the Overview or All fields tab. All fields will show you things like metadata and screenshot URLs. If you only want URLs and text, choose Overview.
You can view and download the articles you've extracted in multiple formats. I'll go with CSV.
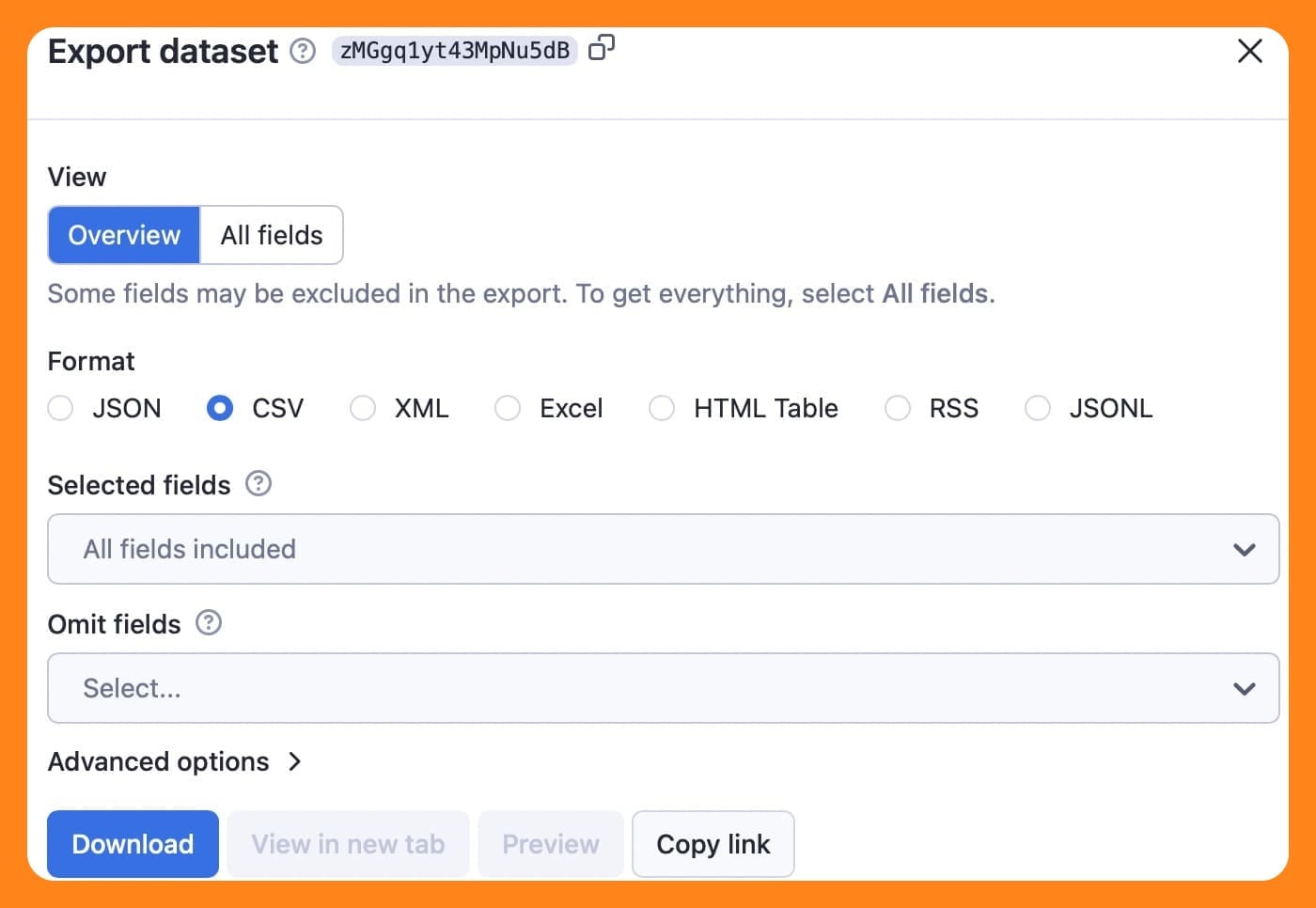
Here's the dataset from the run using the adaptive switching mode.
How to extract text from PDFs
I mentioned earlier that you can save PDFs and other files when crawling URLs with Website Content Crawler, but it won't extract text from the files. So, what if you need to scrape texts from PDFs?
The answer to that challenge is another tool designed for AI: PDF Text Extractor. Let's look at how that one works.
1. PDF URLs
Let's keep this simple. I'll extract the URL provided in the default setting:
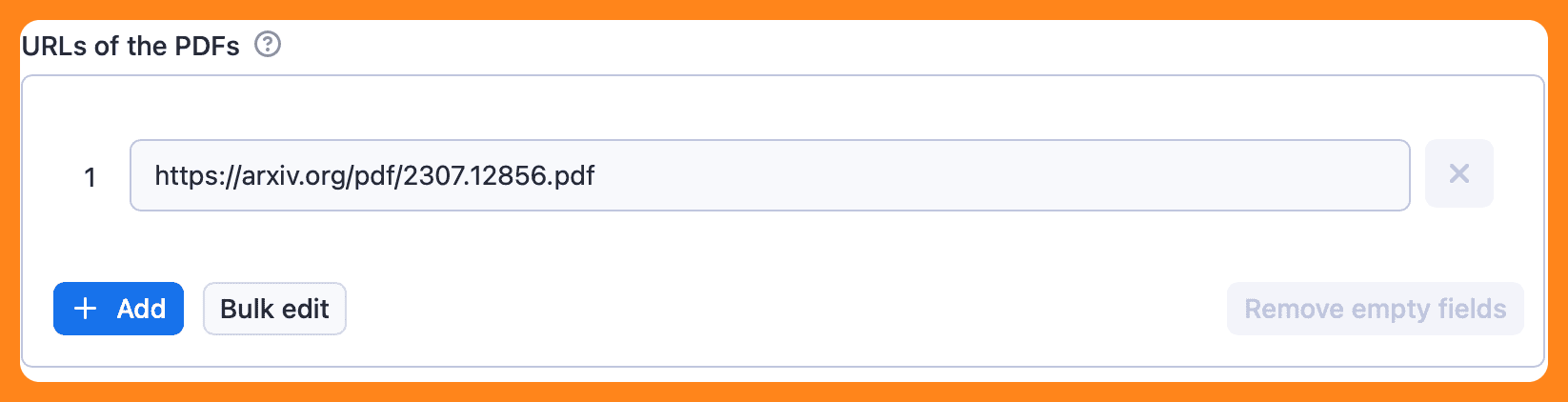
As with Website Content Crawler, you can use the + Add button to add other URLs to the crawler queue for the extractor to process them one by one.
If your text scraping use case is to provide textual data from PDF documents to large language models for, say, question answering, then you should enable the perform chunking function.
2. Perform chunking (optional)
Chunking means splitting long text into smaller parts so they can be fed to an LLM one at a time. Large language models have limited memory and a fixed content window, which means that they can only process a certain amount of text at a time.

The chunk size is the number of characters (not tokens). It's set to 1,000 by default, which should be sufficient in most cases.
The chunk overlap option refers to the character overlap between text chunks so you can determine the precise point to do the split.
3. Run the extractor to scrape text data from the PDF
As with Website Content Crawler, clicking the save & start button will save your configuration and execute the code to run the extractor as specified.
4. Export the extracted text

When it has completed a successful run, you can view the exported data in a table or JSON. You can then export the data in multiple formats. This time, I'll go with the HTML table. Here's the dataset.
Can't get enough of text scraping?
I've shown you how to use two amazing tools for scraping text from URLs and PDFs. But these aren't the only ones. You can also try Smart Article Extractor.
If, for some reason, these two tools haven't impressed you, check out my tutorial on how to extract and download news articles online with Smart Article Extractor.




