

Content
Hi, we're Apify. We've created 1,500+ data extraction tools and unofficial APIs for popular websites. Check us out.
What are HTML parsers, and why use them for web scraping?
Even if you’re a beginner dev, you're likely to encounter HTML parsers. These are essential tools that allow you to navigate and manipulate the structure of HTML documents efficiently.
HTML parsers are not just for sorting data from files of varying sizes; they play a vital role in web scraping.
Imagine you've scraped a vast amount of data from major websites like Facebook or Google. HTML parsers enable you to systematically extract the data you need from the mass of HTML code you've collected. They convert the HTML into a structured format that your code can understand and manipulate. This makes it easier to extract specific pieces of information without manually sifting through the HTML tags.

Why use Python for data parsing?
Python's popularity for web scraping and data parsing isn't unfounded. Its simplicity and readability make it a common choice among developers of all skill levels.
Python boasts a rich ecosystem of libraries specifically designed for web scraping and data parsing, such as Beautiful Soup and lxml. These libraries simplify the process of extracting information from HTML and XML documents, making Python a go-to language for these tasks.
Using Python for web scraping and subsequent data parsing streamlines the development process. This allows you to work within a single programming environment and make the most of Python's extensive resources and community support for efficient data handling.
Choosing the right HTML parser
Let's get to the point. Which Python HTML parser should you choose? That‘s not an easy question and has no right answer. The decision will be affected by the purpose of the project.
But most likely, you‘ll end up using one of the top five data-parsing Python libraries below.
- lxml
- PyQuery
- Beautiful Soup
- jusText
- Scrapy
Give the following table a quick glance just to become familiar with their main functions.
| lxml | PyQuery | jusText | Scrapy | Beautiful Soup | |
|---|---|---|---|---|---|
| XTML and HTML parsing | ✔️ | ✔️ | ✔️ | ✔️ | ✔️ |
| CSS and XPath selectors | ✔️ | ✔️ | ✔️ | ✔️ | ✔️ |
| HTML tree navigation | ✔️ | ✔️ | ❌ | ✔️ | ✔️ |
| ElementTreeAPI | ✔️ | ❌ | ❌ | ❌ | ❌ |
| Built-in HTTP client | ❌ | ❌ | ❌ | ✔️ | ❌ |
| HTML prettifier and smoother | ❌ | ❌ | ❌ | ❌ | ✔️ |
| XSLT support | ✔️ | ❌ | ❌ | ❌ | ❌ |
| HTML boilerplate removal | ❌ | ❌ | ✔️ | ❌ | ❌ |
Top 5 Python HTML parsers you should consider
Let‘s break it down, shall we? You need to consider all the pros and cons of these five most popular Python HTML libraries in a wider frame so you can make the tough decision of which one will be your parser hero for the next project.
To give you a better understanding of how each parser works, we'll provide a sample code snippet for each.
It's worth noting that, with the exception of Scrapy, these parsers need additional libraries like Requests or HTTPX to fetch HTML content from live websites. Therefore, our examples will use the predefined HTML snippet provided below:
html_content = """
<html>
<head>
<title>The Hitchhiker's Guide to the Galaxy</title>
</head>
<body>
<header>
<h1>The Hitchhiker's Guide to the Galaxy</h1>
<nav>
<ul>
<li><a href="#introduction">Introduction</a></li>
<li><a href="#chapter1">Chapter 1</a></li>
</ul>
</nav>
</header>
<section id="introduction">
<h2>Introduction</h2>
<p>Far out in the uncharted backwaters of the unfashionable end of the western spiral arm of the Galaxy lies a small unregarded yellow sun.</p>
<p>Orbiting this at a distance of roughly ninety-two million miles is an utterly insignificant little blue green planet whose ape-descended life forms are so amazingly primitive that they still think digital watches are a pretty neat idea.</p>
</section>
<section id="chapter1">
<h2>Chapter 1</h2>
<p>This planet has - or rather had - a problem, which was this: most of the people on it were unhappy for pretty much of the time.</p>
<p>Many solutions were suggested for this problem, but most of these were largely concerned with the movements of small green pieces of paper, which is odd because on the whole it wasn't the small green pieces of paper that were unhappy.</p>
</section>
</body>
</html>
"""
1. lxml
- XML and HTML parsing
- HTML5 support
- XPath
- ElementTree API
- XSLT support
- Namespace support
- Element creation
- Projects that require a vast amount of XHTML and HTML data parsed in a shorter time limit
lxml is widely seen as a fast library for data parsing. The main reason for that is its close connection with two good-quality C libraries — libxml2 and libxslt.
Thanks to the high compatibility of lxml, you usually don‘t have to worry about XML and HTML standards. Based on that, it's clear that lxml comes in handy when you need to parse complex and large documents, and it shouldn't take forever. It's ideal for data scraping from moderately complex web pages.
- Fast and efficient
- Great documentation and helpful community
- Used to solve complex problems with a number of parsing strategies
- Fully compatible with a wide range of XML and HTML standards
- Might be overly complicated for beginners
from lxml import etree
tree = etree.HTML(html_content)
first_paragraph = tree.xpath('//section[@id="chapter1"]/p[1]')
for p in first_paragraph:
print(p.text)
# Output:
# This planet has - or rather had - a problem, which was this: most of the people on it were unhappy for pretty much of the time.
In this code snippet, lxml.etree is utilized for parsing HTML content and applying XPath to navigate through the HTML document structure.
The etree.HTML function converts the html_content string into an lxml element tree, enabling the use of XPath expressions to locate specific elements. The tree.xpath method is used to select the first paragraph (<p>) within the section that has an id of "chapter1".
This precise targeting is achieved through the XPath expression '//section[@id="chapter1"]/p[1]', which looks for a <section> element with id="chapter1" and then selects its first <p> child. The loop then prints the text content of this paragraph.
2. PyQuery
- JQuery querying
- XML and HTML parsing
- XPath and CSS selectors
- Web element manipulation
- Element filtering
- Operation chaining
- Starting out with Python parsers when you already have experience with JavaScript parsers
PyQuery is built on top of lxml and is very similar to JQuery. It's ideal if you're comfortable using JavaScript parsers and want to start parsing in Python as well.
The pros include the combination of lxml power, intuitive syntax similar to JQuery, and an easy-to-use API.
Choose PyQuery if you're not that familiar with Python and you're looking for a high-performance parser.
However, when parsing larger HTML documents, you might sometimes experience slower interaction.
- Easy to use syntax and API
- Useful documentation and community support
- Slows down when parsing large documents
from pyquery import PyQuery as pq
d = pq(html_content)
links = d('a')
for link in links.items():
print(f'URL: {link.attr("href")}, Text: {link.text()}')
'''
Output:
URL: #introduction, Text: Introduction
URL: #chapter1, Text: Chapter 1
'''
In this code snippet, PyQuery is used to parse and interact with HTML content.
The PyQuery object d is created by passing in html_content, which allows for jQuery-like querying of HTML elements. The focus here is on extracting all anchor (<a>) elements within the HTML. By using d('a'), the code selects all links and iterates over them, printing out each link's href attribute (the URL) and its text content.
This demonstrates how PyQuery simplifies the process of navigating and extracting specific elements from HTML, similar to how one might do with jQuery in a web browser environment, making it an interesting tool for developers already familiar with jQuery syntax.
3. Beautiful Soup
- CSS and XPath selectors
- Unicode and UTF-8 character decoding and encoding
- Document modification
- HTML tree navigation
- HTML and XML parsing
- Search and filter
- HTML prettifier and smoother
- Parsing large amounts of data from static web pages with ease
Beautiful Soup is a beginner-friendly and simple Python parser that is widely used for data parsing. It's fast to set up and easy to use for finding and solving bugs.
Thanks to the HTML tree navigation and search and filter features, Beautiful Soup makes it easy to navigate through pages and files with pretty much every parsing strategy.
- Simply and easy to use
- Helpful community
- Supports a wide range of HTML parsing strategies
- Restricted support for proxies
from bs4 import BeautifulSoup
soup = BeautifulSoup(html_content, 'html.parser')
headers = soup.find_all(['h1', 'h2'])
for header in headers:
print(header.name, header.text.strip())
'''
Output:
h1 The Hitchhiker's Guide to the Galaxy
h2 Introduction
h2 Chapter 1
'''
The role of BeautifulSoup in this context is to enable easy extraction of specific elements from the HTML structure. The method find_all is used to locate all header tags (h1 and h2), and the loop iterates over these tags to print out their type (h1 or h2) along with their text content, effectively extracting and displaying the main titles and subtitles from the provided HTML.
This reiterates BeautifulSoup's ability to simplify the process of sifting through and extracting relevant parts of HTML content, making it a valuable tool for web scraping and data extraction tasks.
4. jusText
- CSS selector
- Page paragraphing
- HTML boilerplate removal
- When you need only specific data out of the millions you scraped.
As an addition to Beautiful Soup, you'll also find jusText. It‘s not as complex as the other Python HTML parsers mentioned, but it might serve as a good assistant and addition to other parsers when you need to solve specific problems in part of the parsed content.
Imagine you've scraped a web, and now you're overwhelmed with a huge amount of data, but you only need specific terms to be parsed. JustText will help you clean up web pages to isolate the main textual content you care about.
- Helps you in a fast and efficient way to sort only the important content you need.
- It's not a powerful parser on its own; you'll need Beautiful Soup as well.
import justext
paragraphs = justext.justext(html_content, justext.get_stoplist("English"))
for paragraph in paragraphs:
if not paragraph.is_boilerplate:
print(paragraph.text)
'''
Output:
The Hitchhiker's Guide to the Galaxy
Introduction
Far out in the uncharted backwaters of the unfashionable end of the western spiral arm of the Galaxy lies a small unregarded yellow sun.
Orbiting this at a distance of roughly ninety-two million miles is an utterly insignificant little blue green planet whose ape-descended life forms are so amazingly primitive that they still think digital watches are a pretty neat idea.
Chapter 1
This planet has - or rather had - a problem, which was this: most of the people on it were unhappy for pretty much of the time.
Many solutions were suggested for this problem, but most of these were largely concerned with the movements of small green pieces of paper, which is odd because on the whole it wasn't the small green pieces of paper that were unhappy.
'''
In this code snippet, justext is utilized to process a given HTML content, aiming to extract meaningful text while discarding the "boilerplate" - the common, less informative sections such as navigation links, ads, and footers.
The output verifies justext's effectiveness in isolating the main textual content from the HTML, presenting clean, readable text that includes titles and paragraphs from The Hitchhiker's Guide to the Galaxy, free from any surrounding clutter.
5. Scrapy
- Web scraping and crawling
- XML and HTML parsing
- Built-in HTTP client
- Concurrent and asynchronous operations
- Pagination
- Dedicated spiders
- Data organization
- Item pipeline
- Complex web scraping projects that require a powerful tool to help with more than data parsing
Finally, there's Scrapy - the most powerful tool in the field of web scraping and data parsing with Python. It's not only a parser but a full-fledged web scraping library.
Scrapy is a whole web crawling framework that has more than 50,000 stars on GitHub. Parsing data is not the only reason to use Scrapy. As the name suggests, you can also scrape and save content from the web.
That being said, you‘ve probably figured out already that using Scrapy is not a wise decision if you began your Python web scraping journey only yesterday. Even though we don‘t want to underestimate your skills, Scrapy might be more useful for an advanced developer who already has experience with web scraping.
- Smooth and high-speed scraping
- Works with large-scale data
- Greatly adaptable
- Beginners might get overwhelmed
- It lacks browser interaction and automation capabilities
Setting up a Scrapy project is a bit more involved compared to the other libraries we've discussed. The first step is to install the Scrapy framework:
pip install scrapy
Next, initiate a new Scrapy project and navigate into the folder that's created for it:
scrapy startproject quotes_project
cd quotes_project
Next, create a new Scrapy spider:
scrapy genspider quotes quotes.toscrape.com
Lastly, open the quotes.py file in your spider directory and replace its contents with the following code:
import scrapy
class QuotesSpider(scrapy.Spider):
name = "quotes"
start_urls = [
'http://quotes.toscrape.com/',
]
def parse(self, response):
for quote in response.css('div.quote'):
yield {
'text': quote.css('span.text::text').get(),
'author': quote.css('span small::text').get(),
}
To run a Scrapy project, run the following command:
scrapy crawl quotes -o output.json
Shortly, an output.json file with the extracted information will be generated in your directory:
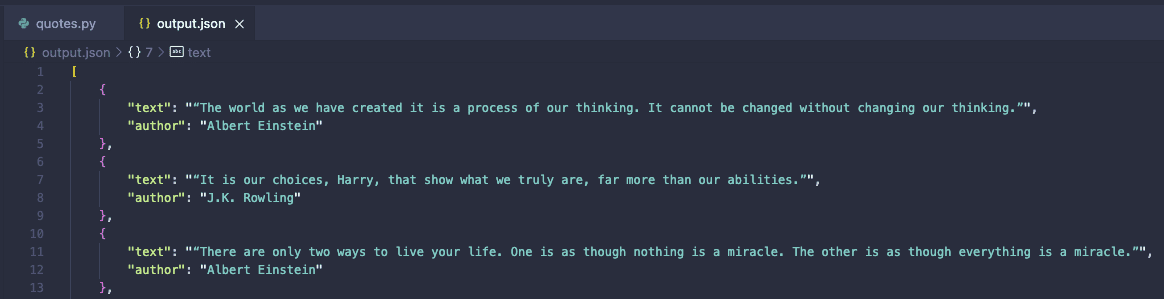
Scrapy is a comprehensive web scraping framework equipped with a wide range of tools that extend beyond basic HTML parsing. In this example, we showcased Scrapy's capability to retrieve content from a live website (quotes.toscrape.com), process the HTML, and present the results in a structured JSON format.
Which parser should you use?
You went through all the parsers and their features, and you still don‘t have an idea which one to choose?
We'll let you in on a secret: there's no best option.
To make the most out of a Python HTML parser, you should consider the nature of your project and decide based on its needs. It might also happen that you need some features from one parser and some from another. Well, what's easier than combining both of them?
Always remember that even though there are widely used and proven strategies for data parsing, innovation never killed nobody.
To avoid information overload, here's a simple table that summarizes the pros, cons, and best practices of the Python HTML parsers so you have the most important information in one place.
| Python HTML parser | Pros | Cons | Best practice |
|---|---|---|---|
| lxml | Fast with complex problems | Not beginner-friendly | Urgent projects |
| PyQuery | Easy for someone with experience with parsing in JavaScript | Slow with larger documents | Smaller data parsing project |
| Beautiful Soup | Simple to use with helpful community | Restricted support for proxies | Parsing large amounts of data |
| jusText | Efficient in separating crucial data | Only an extension of Beautiful Soup | Need to filter out specific data |
| Scrapy | Web scraping and data parsing framework in one | Not beginner-friendly | Complex web scraping project |
Decided? Congratulations!
If you‘ve chosen Beautiful Soup or PyQuery, here‘s some good news! Here, you can learn step-by-step how to parse HTML in Python with these tools.
Prefer Scrapy? Check out Web scraping with Scrapy 101.
May you enjoy many exciting web scraping and data parsing projects!




