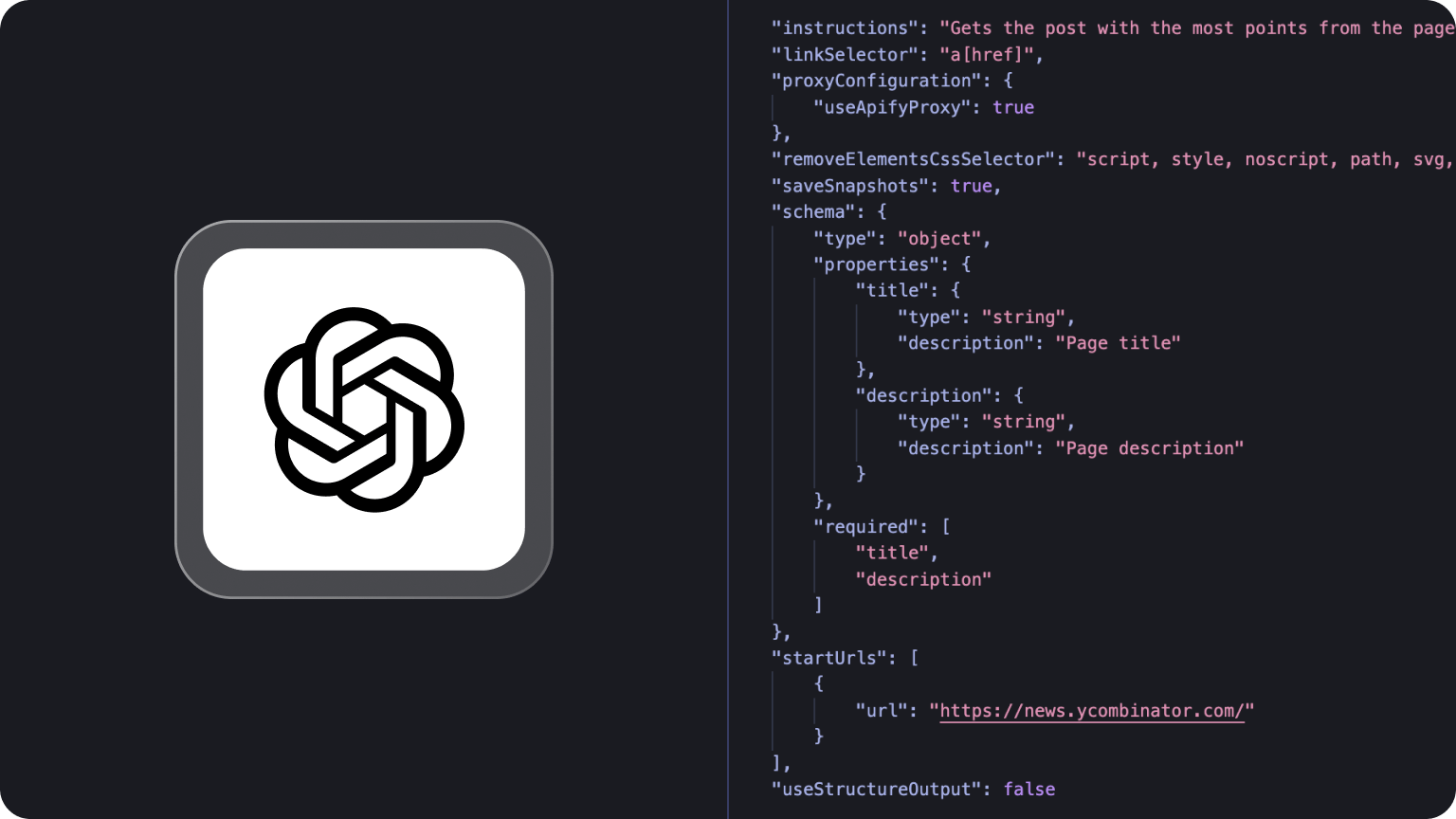
Content
We’re Apify, a full-stack web scraping and browser automation platform. A big part of what we do is getting better data for AI.
What is a custom GPT?
A custom GPT is a custom version of ChatGPT created for a specific purpose. It can combine extra knowledge, instructions, and a combination of skills. What's more, anyone with an OpenAI Plus account can build one. But what's the point of creating a custom GPT?
Why create custom GPTs?
You can streamline processes by providing specific instructions for your GPT. If you use GPT-4 for something specific on a regular basis, you'll have to keep repeating your specifications every single time. If you create your own, you don't have to explain what you want it to do because those prompts are in the GPT instructions, and it will remember them. So you could think of a custom GPT as a prompt shortcut.
How to create a custom GPT
Starting from scratch?
If you want to know how to build a custom GPT from scratch or how to add web scraping capabilities to your GPTs, check out our article on creating a GPT with custom actions, or watch the video below. Both take you through the whole process, including adding API specifications. But one thing not covered there is uploading a knowledge base. And that is what we'll focus on in this tutorial.
How to add custom actions to GPTs with Apify Actors
Adding knowledge to GPTs
Uploading files gives the GPT reliable information to refer to when generating answers. For example, here's a GPT we made: Crawlee Helper. This is designed to provide reliable answers to questions about using Apify's open-source web scraping and browser automation library, Crawlee. How does it do this reliably? By referring to the Crawlee documentation that has been uploaded to its knowledge.

And why is it helpful to upload the documentation? Because when GPT-4 uses its default 'web browsing' capability to retrieve information, it doesn't always provide reliable answers. Searching the knowledge we uploaded can provide much better responses to questions.
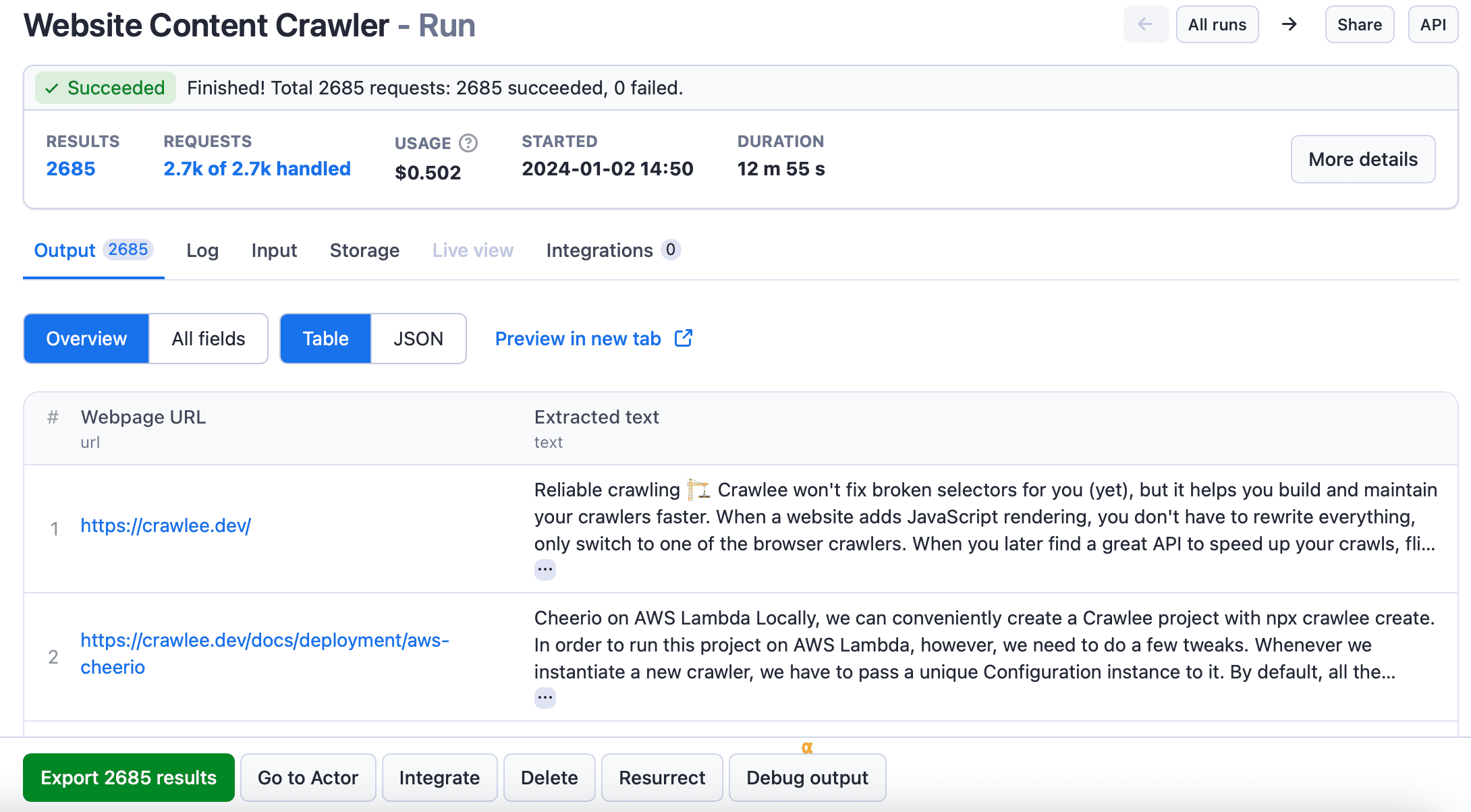
How did we do it? We used Website Content Crawler to scrape and download the Crawlee documentation and then simply uploaded it to our GPT's knowledge. So, I will show you how to use Website Content Crawler to perform similar actions for your own GPTs.
Website Content Crawler for GPTs
If you're not already familiar with it, Website Content Crawler is an Actor on Apify Store that was designed specifically for collecting and processing web data for feeding vector databases and training and fine-tuning large language models. It's ideal for this because it has built-in HTML processing and data-cleaning functions. That means you can easily remove fluff, duplicates, and other things on a web page that aren't relevant, and provide only the necessary data to the language model.
We have a handy tutorial on how to use it in this blog post on how to collect data for LLMs, so do check it out. But our use for it right now is much more straightforward than that. We're going to demonstrate here that you can use this tool to extract web data quickly - in this example, the documentation on the Crawlee website - and download it to your device so you can easily upload it to your very own GPT. So, let's get to it.
To emulate the example in this tutorial, you'll need:
a paid OpenAI account
a free or paid Apify account
Prefer video? Watch this tutorial on how to add a knowledge base to your GPTs
How to add knowledge to GPTs: step-by-step guide
Step 1: Go to Website Content Crawler
Go to Website Content Crawler on Apify Console. You'll be taken to the signup page when you click Try for free if you don't have an Apify account. So quickly sign up for free, and you can get started right away.
Step 2: Choose the URLs and crawler type
Once we're on the Website Content Crawler page, we need to replace the default input with the URL we want to scrape.
We're going to choose the Cheerio crawler type because it's insanely fast, and we won't have any JavaScript client-side rendering to contend with.

Step 3: Execute the code
Those are the only settings that concern us, so we can just click the Save & Start button to execute the code.

Step 4: Download the data
Once the crawler has successfully completed its run, you can go to the Output tab or Export results button and download the data in your desired format.
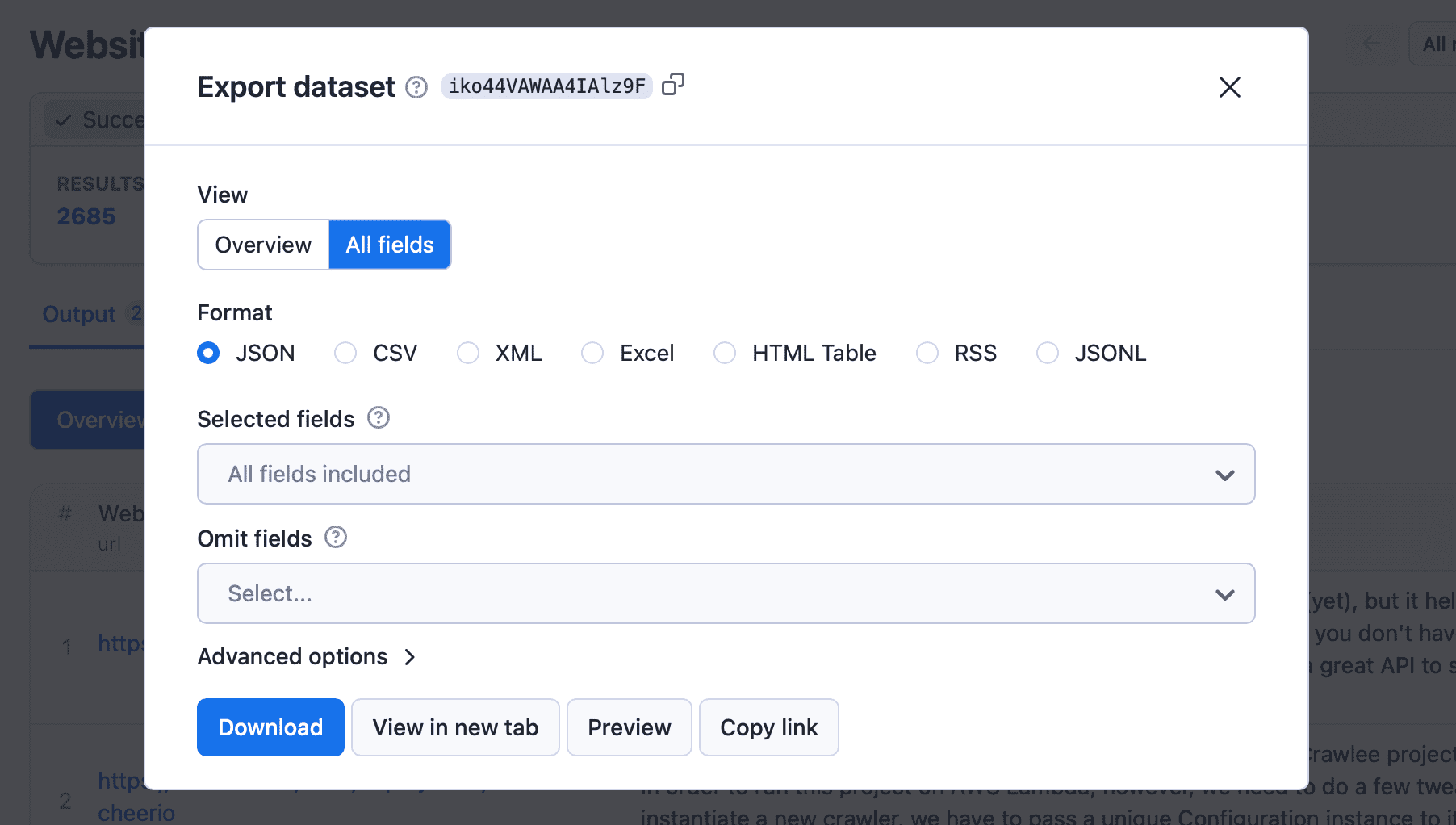
Keep in mind that ChatGPT might not accept large files and may get confused if you give it too much unnecessary data. So rather than choose All fields, let’s just stick with Overview, which includes the URL and body of text. Alternatively, you can choose the data you want to download via the Selected fields input.
Step 5: Upload the data to your GPT
Now you can upload the file to your GPT's knowledge.
And there you have it. That's how we uploaded knowledge to our Crawlee Helper GPT, so whenever you ask a question about the Crawlee documentation, it will go through the docs to provide the most accurate answers.
Try it for yourself
That's just one of many examples of how you can use Website Content Crawler and other Actors available on Apify Store to customize your GPTs!
Now you know how it works, how will you use Apify to customize your GPTs? Need some inspiration? Here are some Apify-powered GPTs you can try out.
Apify-powered GPTs
- InstaMagic: Data Delight: This Instagram Scraper lets you effortlessly gather posts, profiles, hashtags, and more.
- GUNSHIGPT: Specialized in TikTok data analysis and interpretation.
- CarbonMarketsHQ: An AI Assistant specialized in carbon markets [beta]. Has access to 10,000+ carbon project data, documentation, and market reports.
- SatoshiGPT: The ultimate Bitcoin expert. Ask about data, price, how-to, and anything Bitcoin-related.
- SERP scraper: Extract results from Google Search to find websites and answer your queries.
- Web Snapshot Guru: Efficient and casual screenshot assistant.
- Apify Adviser: Find the right Actor to scrape data from the web. Get help with the Apify platform.
- Chat with website: Takes a user question related to a website, conducts web scraping on its pages, analyzes the obtained information, and generates results.
- Crawlee Helper: An expert on the Crawlee web scraping library, it provides detailed answers from documentation.