


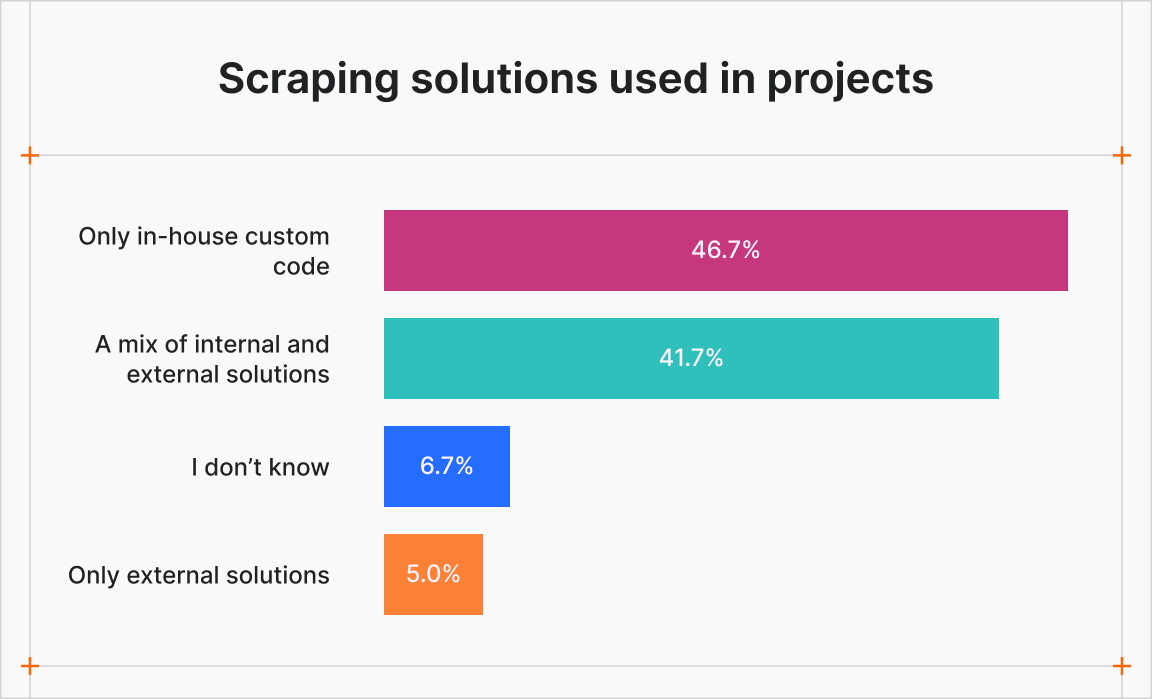
Infrastructure remains one of the most defining characteristics of modern web scraping. The state of web scraping report by Apify and The Web Scraping Club shows that custom, in-house solutions dominate: 46.7% of professionals rely exclusively on internal code, while 41.7% combine internal and external tools. Only 5% depend solely on external solutions.
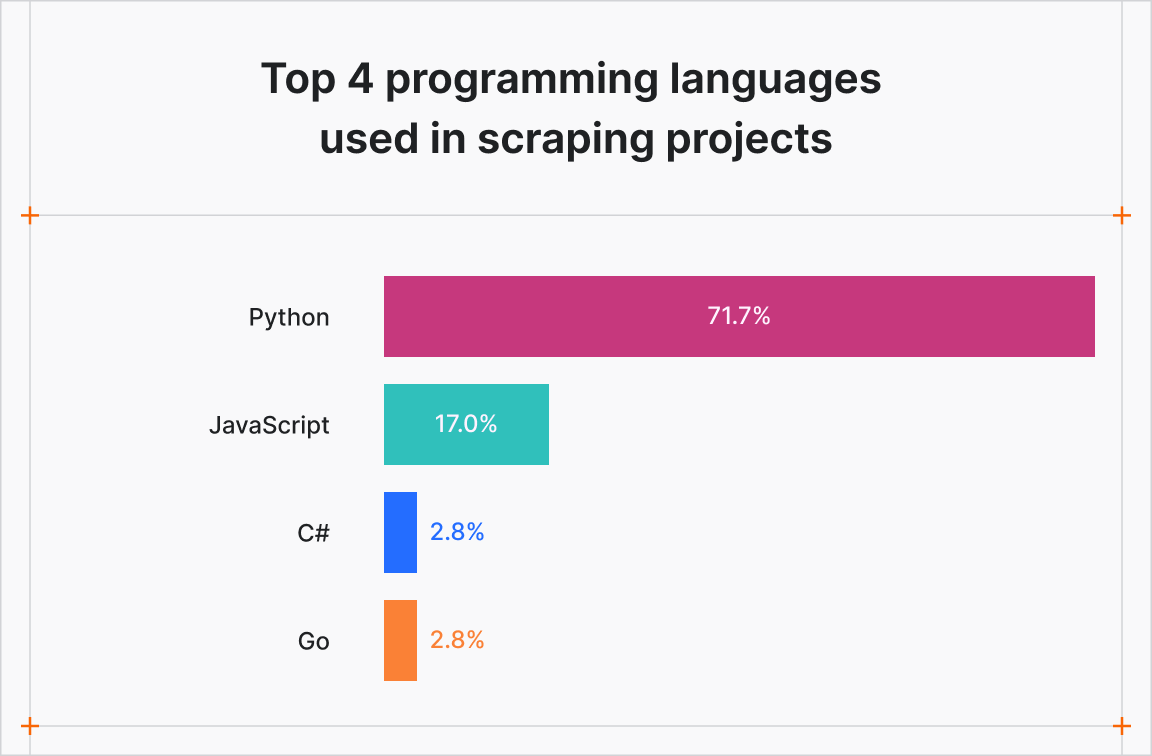
Programming language choices remain stable. 71.7% of respondents use Python, followed by 17% using JavaScript. Other languages such as C# and Go trail far behind. Commonly cited frameworks include Selenium, Puppeteer, Playwright, and Scrapy, reflecting continued reliance on tried-and-tested tooling.
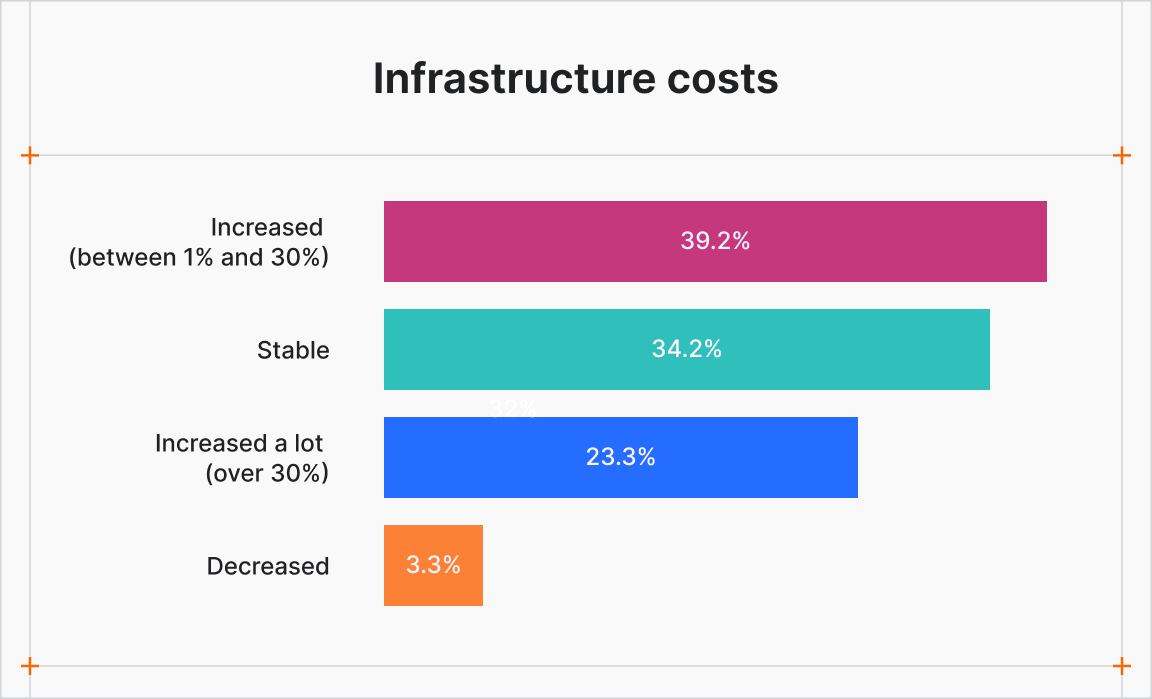
Costs, however, are rising. 62.5% of respondents reported increased infrastructure expenses over the past year, with 23.3% seeing increases of more than 30%. These costs include compute, hosting, and execution — excluding proxies — and are closely tied to the growing difficulty of scraping protected sites.
As anti-bot systems evolve, infrastructure must scale not just in size, but in sophistication. More retries, heavier browser automation, and complex workflows all contribute to higher operational overhead.
In 2026, scraping infrastructure is less about experimentation and more about long-term investment — optimized for reliability, adaptability, and sustained throughput.




