


Web scraping comes with its fair share of challenges. Websites are becoming increasingly difficult to scrape due to the rise of anti-scraping measures like CAPTCHAs and browser fingerprinting. At the same time, the demand for data, especially to fuel AI, is higher than ever.
As you probably know, web scraping isn’t always a stress-free process, but learning how to navigate these obstacles can be incredibly rewarding.
In this guide, we’ll cover 10 common problems you’re likely to encounter when scraping the web and, just as importantly, how to solve them:
- Dynamic content
- User agents and browser fingerprinting
- Rate limiting
- IP bans
- Honeypot traps
- CAPTCHAs
- Data storage and organization
- Automation and monitoring
- Scalability and reliability
- Real-time data scraping
For the solutions, we’ll use Crawlee, an open-source library for Python and Node.js, and the Apify platform. These tools make life easier, but the techniques we’ll talk about can be used with other tools as well. By the end, you’ll have a solid understanding of how to overcome some of the toughest hurdles web scraping can throw at you.
1. Dynamic content
Modern websites often use JavaScript frameworks like React, Angular, or Vue.js to create dynamic and interactive experiences. These single-page applications (SPAs) load content on the fly without refreshing the page, which is great for users but can complicate web scraping.
Traditional scrapers that pull raw HTML often miss data generated by JavaScript after the page loads. To capture dynamically loaded content, scrapers need to execute JavaScript and interact with the page, just like a browser.
That’s where headless browsers like Playwright, Puppeteer, or Selenium come in. They mimic real browsers, loading JavaScript and revealing the data you need.
In the example below, we’re using Crawlee, an open-source web scraping library, with Playwright to scrape a dynamic page (MintMobile). While Playwright alone could handle this, Crawlee adds powerful web scraping features you’ll learn about in the next sections.
import { PlaywrightCrawler } from 'crawlee';
import { firefox } from 'playwright';
const crawler = new PlaywrightCrawler({
launchContext: {
// Here you can set options that are passed to the playwright .launch() function.
launchOptions: {
headless: true,
},
launcher: firefox,
},
async requestHandler({ pushData, page, request, log }) {
await page.goto(request.url);
// Extract data
const productInfo = await page.$eval('#WebPage', (info) => {
return {
name: info.querySelector('h1[data-qa="device-name"]').innerText,
storage: info.querySelector(
'a[data-qa="storage-selection"] p:nth-child(1)'
).innerText,
devicePrice: info.querySelector(
'a[data-qa="storage-selection"] p:nth-child(2)'
).innerText,
};
});
if (!productInfo) {
log.warning(`No product info found on ${request.url}`);
} else {
log.info(`Extracted product info from ${request.url}`);
// Save the extracted data, e.g., push to Apify dataset
await pushData(productInfo);
}
},
});
// Start the crawler with a list of product review pages
await crawler.run([
'https://www.mintmobile.com/devices/samsung-galaxy-z-flip6/6473480/',
]);2. User agents and browser fingerprinting
If a website blocks your scraper, you can’t access the data, which makes all your efforts pointless. To avoid this, you want to make your scrapers mimic real users as much as possible. Two basic elements of anti-bot defenses to keep in mind are user agents and browser fingerprinting.
A user agent is a piece of metadata sent with every HTTP request, telling the website what browser and device are making the request. It looks something like this:
Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/114.0.0.0 Safari/537.36
If your scraper uses something obvious like the Axios default User Agent, axios/1.7.2 , the site will likely flag you as a bot and block your access.
Fingerprinting takes it a step further. Websites analyze details like your screen resolution, installed fonts, timezone, language, and even whether the browser is running in headless mode. All this data creates a unique “fingerprint” for your scraper. If your fingerprint looks too uniform or lacks variety, like using the same resolution or timezone across all requests, you’re more likely to get caught. Some sites can even track you across sessions, bypassing tactics like IP rotation.
As you can imagine, manually managing user agents and fingerprints can be a headache, it’s time-consuming, error-prone, and hard to keep up with as websites constantly improve their defenses.
Thankfully, modern open-source tools like Crawlee take care of these challenges for us. Crawlee automatically applies the correct user agent and fingerprints to our request to ensure our bots appear “human-like.” Its PlaywrightCrawler and PuppeteerCrawler also make headless browsers behave like real ones, lowering your chances of detection, which is why I opted for using Playwright with Crawlee in the first section 😉
3. Rate limiting
Rate limiting is how websites keep things under control by capping the number of requests a user or IP can make within a set time frame. This helps prevent server overload, defend against DoS attacks, and discourage automated scrapers. If your scraper goes over the limit, the server might respond with a 429 Too Many Requests error or even block your IP temporarily. This can be a major roadblock, interrupting your data collection and leaving you with incomplete results.
To solve this issue, you need to manage your request rates and stay within the website’s limits. Crawlee makes this easy by offering options to fine-tune how many requests your scraper sends at once, how many it sends per minute, and how it scales based on your system’s resources. This gives you the flexibility to adjust your scraper to avoid hitting rate limits while maintaining strong performance.
Here’s an example of how to handle rate limiting using Crawlee’s CheerioCrawler with adaptive concurrency to scrape Hacker News:
import { CheerioCrawler } from 'crawlee';
const crawler = new CheerioCrawler({
// Ensure there will always be at least 2 concurrent requests
minConcurrency: 2,
// Prevent the crawler from exceeding 20 concurrent requests
maxConcurrency: 20,
// ...but also ensure the crawler never exceeds 250 requests per minute
maxRequestsPerMinute: 250,
async requestHandler({ pushData, request, $, enqueueLinks, log }) {
log.info(`Processing ${request.url}...`);
// Extract data using Cheerio
const data = $('.athing')
.map((index, element) => {
const $element = $(element);
return {
title: $element.find('.title a').text(),
rank: $element.find('.rank').text(),
href: $element.find('.title a').attr('href'),
};
})
.get();
// Store the results to the default dataset.
await pushData(data);
// Find a link to the next page and enqueue it if it exists.
const infos = await enqueueLinks({
selector: '.morelink',
});
if (infos.processedRequests.length === 0)
log.info(`${request.url} is the last page!`);
},
});
await crawler.addRequests(['https://news.ycombinator.com/']);
// Run the crawler and wait for it to finish.
await crawler.run();
console.log('Crawler finished.');4. IP bans
Building on the discussion about rate limiting, IP bans are another common issue you might have come across when scraping the web. Simply put, when a scraper sends too many requests too quickly or behaves in ways that don’t seem natural, the server might block the IP address, either temporarily or permanently. When that happens, your data collection comes to a complete halt, and naturally, we want to prevent this from happening.
While managing your scraper’s concurrency can help avoid this, sometimes it’s not enough. If you’re still running into blocks, using proxy rotation is a great next step. By rotating IP addresses, you can spread out your requests and make it harder for websites to flag and block your crawler’s activity.
With Crawlee, adding proxies is straightforward. Whether you’re using your own servers or working with a third-party provider, Crawlee handles the rotation automatically, ensuring your requests come from different IPs.
If you already have a list of proxies ready, integrating them into your Crawlee scraper takes just a few lines of code. Here’s how you can do it:
import { ProxyConfiguration, CheerioCrawler } from 'crawlee';
const proxyConfiguration = new ProxyConfiguration({
proxyUrls: [
"http://proxy-1.com",
"http://proxy-2.com",
]
});
const proxyUrl = await proxyConfiguration.newUrl();
const crawler = new CheerioCrawler({
proxyConfiguration,
// ...rest of the code
});
Alternatively, you can use a third-party tool like Apify Proxy to access a large pool of residential and datacenter proxies, making proxy management even easier. It also gives you added flexibility by letting you control proxy groups and country codes.
import { Actor } from 'apify';
const proxyConfiguration = await Actor.createProxyConfiguration({
groups: ['RESIDENTIAL'],
countryCode: 'US',
});
const proxyUrl = await proxyConfiguration.newUrl();
5. Honeypot traps
Honeypot traps are hidden elements in a website’s HTML designed to detect and block automated bots and scrapers. These traps, like hidden links, forms, or buttons, are invisible to regular users but can be accidentally triggered by scrapers that process every element indiscriminately. When this happens, it signals bot activity to the website, often resulting in blocks, IP bans, and other issues. In short, you want to keep your scraper far away from these traps.
One way to avoid these traps is by filtering out hidden elements. You can check for CSS properties such as display: none and visibility: hidden to exclude them from your scraping process.
Another approach is to simulate real user behavior. Instead of scraping the entire HTML, focus on specific sections of the page where the data is located. Mimicking real interactions, like clicking on visible elements or navigating the page, helps your scraper appear more human-like and prevents it from interacting with invisible elements that a user wouldn’t be aware of.
Here’s an example of how you could modify the Hacker News scraper from the earlier section to filter out Honeypot traps:
import { CheerioCrawler } from 'crawlee';
const crawler = new CheerioCrawler({
async requestHandler({ pushData, request, $, enqueueLinks, log }) {
log.info(`Processing ${request.url}...`);
// Function to check if an element is visible (filter out Honeypots)
const isElementVisible = (element) => {
const style = element.css([
'display',
'visibility',
'opacity',
'height',
'width',
]);
return (
style.display !== 'none' &&
style.visibility !== 'hidden' &&
style.opacity !== '0'
);
};
// Extract data using Cheerio while avoiding Honeypot traps
const data = $('.athing')
.filter((index, element) => isElementVisible($(element)))
.map((index, element) => {
const $element = $(element);
return {
title: $element.find('.title a').text(),
rank: $element.find('.rank').text(),
href: $element.find('.title a').attr('href'),
};
})
.get();
// Store the results to the default dataset.
await pushData(data);
// Find a link to the next page and enqueue it if it exists.
const infos = await enqueueLinks({
selector: '.morelink',
});
if (infos.processedRequests.length === 0)
log.info(`${request.url} is the last page!`);
},
});
await crawler.addRequests(['https://news.ycombinator.com/']);
// Run the crawler and wait for it to finish.
await crawler.run();
console.log('Crawler finished.');6. CAPTCHAs
CAPTCHAs, or Completely Automated Public Turing tests to tell Computers and Humans Apart, are those familiar challenges we’ve all seen, clicking on traffic lights or selecting crosswalks in image grids. While frustrating for humans, they are designed to block bots, making them one of the toughest obstacles for scrapers. Encountering one during scraping can bring your process to a halt, as bots can’t solve these puzzles on their own.
The good news is that much of what we’ve already covered, like avoiding honeypot traps, rotating IPs, and making your scraper mimic human behavior, also helps reduce the chances of triggering CAPTCHAs. Websites generally try to show CAPTCHAs only when the activity looks suspicious. By blending in with regular traffic through techniques like rotating IPs, randomizing interactions, and managing request patterns thoughtfully, your scraper can often bypass CAPTCHAs entirely.
However, CAPTCHAs can still appear, even when precautions are in place. In such cases, your best bet is to integrate a CAPTCHA-solving service. Tools like Apify’s Anti Captcha Recaptcha Actor, which works with Anti-Captcha, can help you equip your crawlers with CAPTCHA-solving capabilities to handle these challenges automatically and avoid disrupting your scraping.
Here is an example of how you could use the Apify API to integrate the Anti Captcha Recaptcha Actor into your code:
import { ApifyClient } from 'apify-client';
// Initialize the ApifyClient with API token
const client = new ApifyClient({
token: '',
});
// Prepare Actor input
const input = {
{
"cookies": "name=value; name2=value2",
"key": "anticaptcha-key",
"proxyAddress": "8.8.8.8",
"proxyLogin": "theLogin",
"proxyPassword": "thePassword",
"proxyPort": 8080,
"proxyType": "http",
"siteKey": "6LfD3PIbAAAAAJs_eEHvoOl75_83eXSqpPSRFJ_u",
"userAgent": "Opera 6.0",
"webUrl": "https://2captcha.com/demo/recaptcha-v2"
}
};
(async () => {
// Run the Actor and wait for it to finish
const run = await client.actor("petr_cermak/anti-captcha-recaptcha").call(input);
})();
7. Data storage and organization
Storing and organizing data effectively is often overlooked in smaller projects but is actually a core component of any successful web scraping operation.
While collecting data is the first step, how you store, access, and present it has a huge impact on its usability and scalability. Web scraping generates a mix of data types, from structured information like prices and reviews to unstructured content like PDFs and images. This variety demands flexible storage solutions. For small projects, simple CSV or JSON files stored locally might work, but as your needs grow, these methods can quickly fall short.
For larger datasets or ongoing scraping, cloud-based solutions like MongoDB, Amazon S3 or Apify Storage become necessary. They’re designed to handle large volumes of data and offer quick querying capabilities.
One standout advantage of Apify Storage is that it’s specifically designed to meet the needs of web scraping. It offers Datasets for structured data, Key-Value Stores for storing metadata or configurations, and Request Queues to help manage and track your scraping workflows. It integrates seamlessly with tools like Crawlee, provides API access for straightforward data retrieval and management, and supports exporting data in multiple formats.
Best of all, Apify Storage is just one piece of the comprehensive Apify platform, which delivers a full-stack solution for all your web scraping needs.
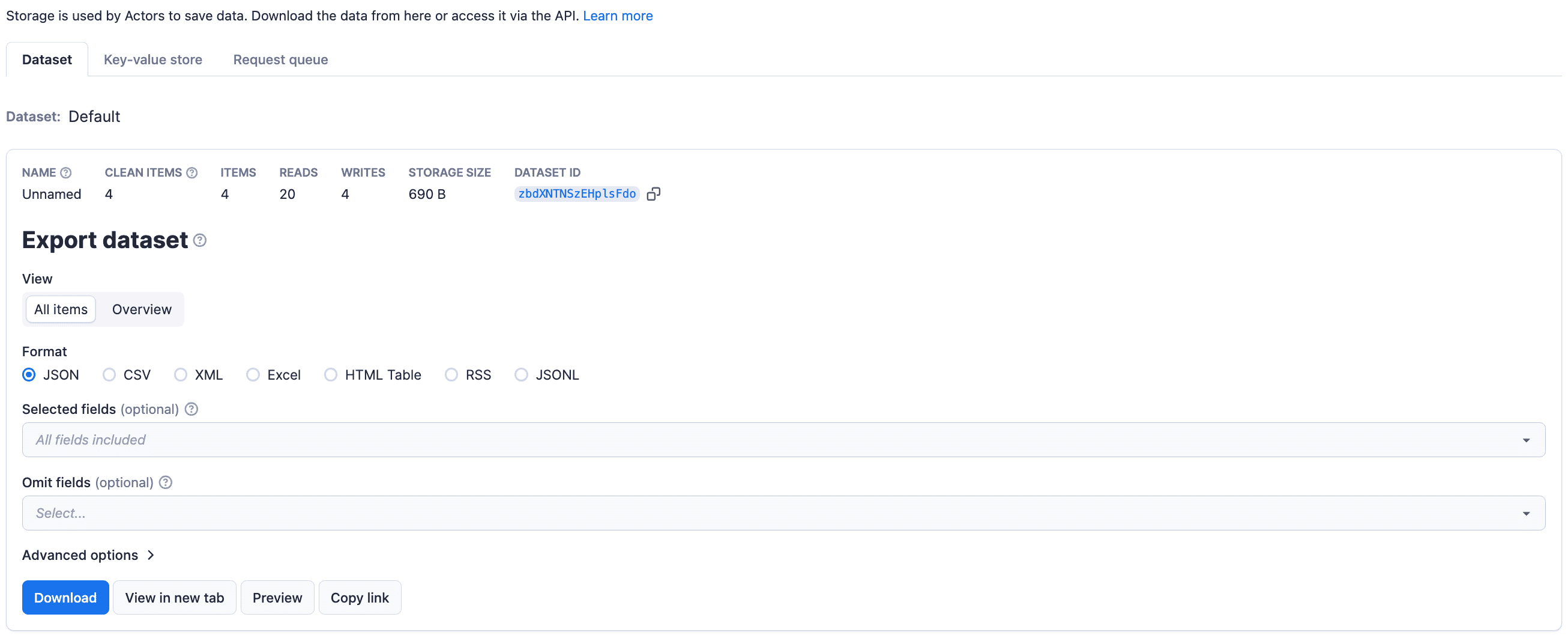
8. Automation and monitoring
Manually running scrapers every time you need fresh data is not practical, especially for projects requiring regular updates like price tracking, market research, or monitoring real-time changes.
Automation ensures your workflows run on schedule, minimizing errors and keeping your data current, while monitoring helps detect and address issues like failed requests, CAPTCHAs, or website structure changes before they cause disruptions.
Apify Platform Monitoring simplifies this process by providing tools specifically designed for automating and monitoring web scraping workflows. With task scheduling, you can set your scrapers to run at specific intervals, ensuring consistent data updates.
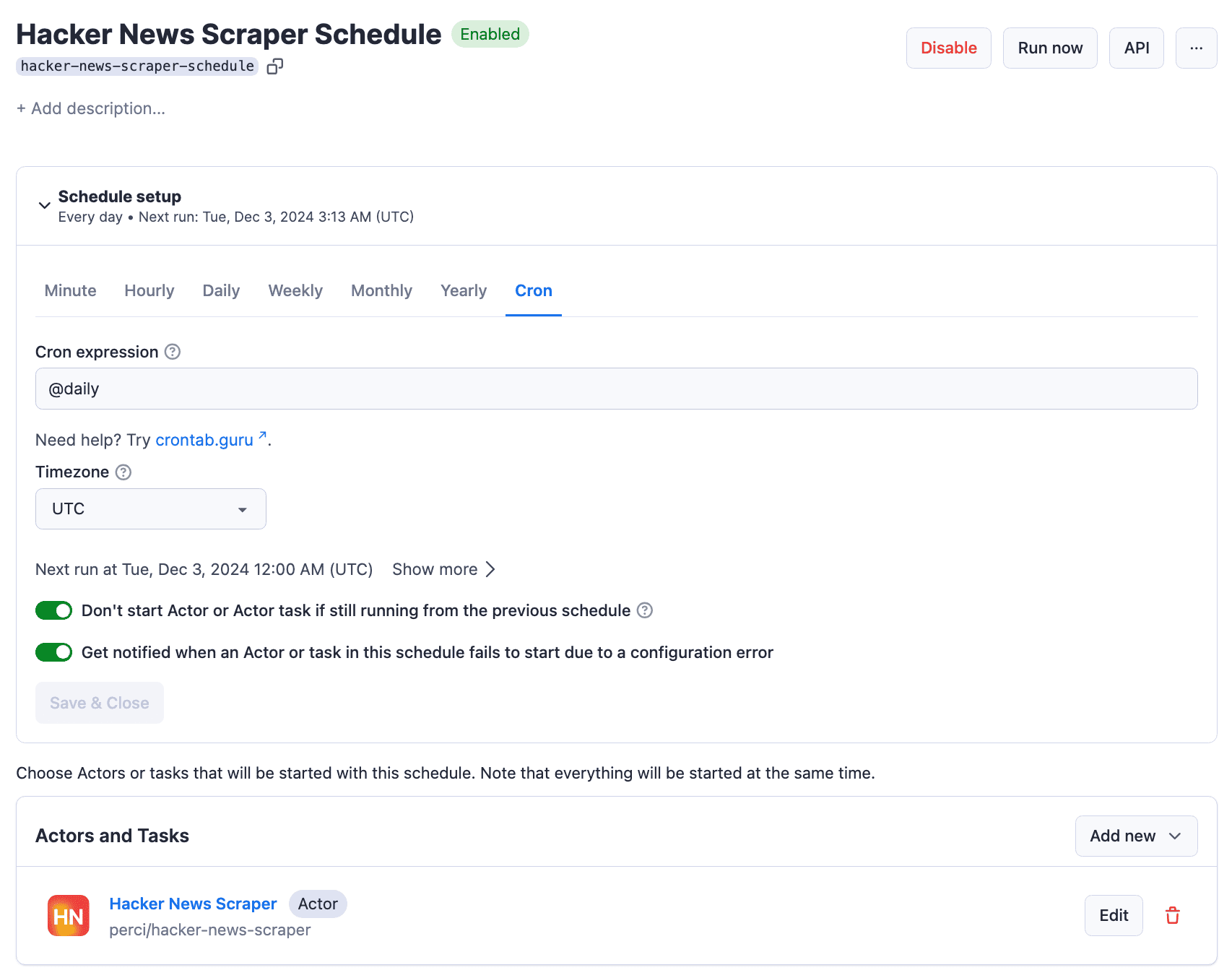
As well as helping you automate scraping, Apify offers monitoring features to view task statuses, detailed logs, and error messages. These features keep you informed about your scraper’s performance, including notifications and alerts, which can be configured to inform you of task completions or errors via email, Slack, or other integrations.
9. Scalability and reliability
Building a scalable and reliable scraping operation relies on the key principles we’ve covered: avoiding blocks, maintaining data consistency, storing collected data efficiently, and automating tasks with proper monitoring. Together, these elements create a solid foundation for a system that can grow with your needs while ensuring quality and performance remain intact.
One crucial yet often overlooked aspect of scalability is infrastructure management. Handling your own servers can quickly turn into a costly and time-consuming challenge, especially as your project expands. That’s why choosing a robust cloud-based solution like Apify from the very start of your project is a smart choice. Designed for scalability, it automatically adjusts to your project’s needs, so you never have to worry about provisioning servers or hitting capacity limits. You only pay for what you use, keeping costs manageable while ensuring your scrapers keep running without interruption.

10. Real-time data scraping
The idea behind real-time data scraping is to continuously collect data as soon as it becomes available. This is often a critical requirement for projects involving time-sensitive data, such as stock market analysis, price monitoring, news aggregation, and tracking live trends.
To achieve this, you need to deploy your code to a cloud platform and automate your scraping process with a proper schedule. For example, you can deploy your scraping script as an Apify Actor and schedule it to run at intervals that match how “fresh” you need the data to be. Apify’s scheduling and monitoring tools make it easy for you to implement this automation, ensuring a constant flow of real-time data while helping you promptly handle any errors to maintain accuracy and reliability.
Conclusion
And here we are at the end of the article. I hope you’ve found it helpful and can use it as a reference when dealing with the challenges we’ve discussed. Of course, every scraping project is unique, and it’s impossible to cover every scenario in one post. That’s where the value of a strong developer community comes in.
Connecting with other developers who have faced and solved similar challenges can make a big difference. It’s a chance to exchange ideas, get advice, and share your own experiences.
If you haven’t already, I encourage you to join the Apify & Crawlee Developer Community on Discord. It’s a great space to learn, collaborate, and grow alongside others who share your interest in web scraping.
Hope to see you there!





