Scraping Instagram isn’t easy, as the platform protects its data with strict anti-bot protections that can block the great majority of automated scripts. Plus, many interactions are only accessible to logged-in users.
While it's possible to retrieve data by intercepting the hidden API calls made by the web interface, these methods are unreliable and difficult to maintain. The most effective and sustainable solution is to connect to a working cloud-based Instagram scraper.
In this article, we’ll guide you through the process of calling a dedicated Instagram scraper via API. We’ll go from setting up your Python project to running your Instagram scraping integration script.
Why scraping Instagram is so tricky
Try accessing a public Instagram page using a VPN or a datacenter IP, and this is what you will likely view:
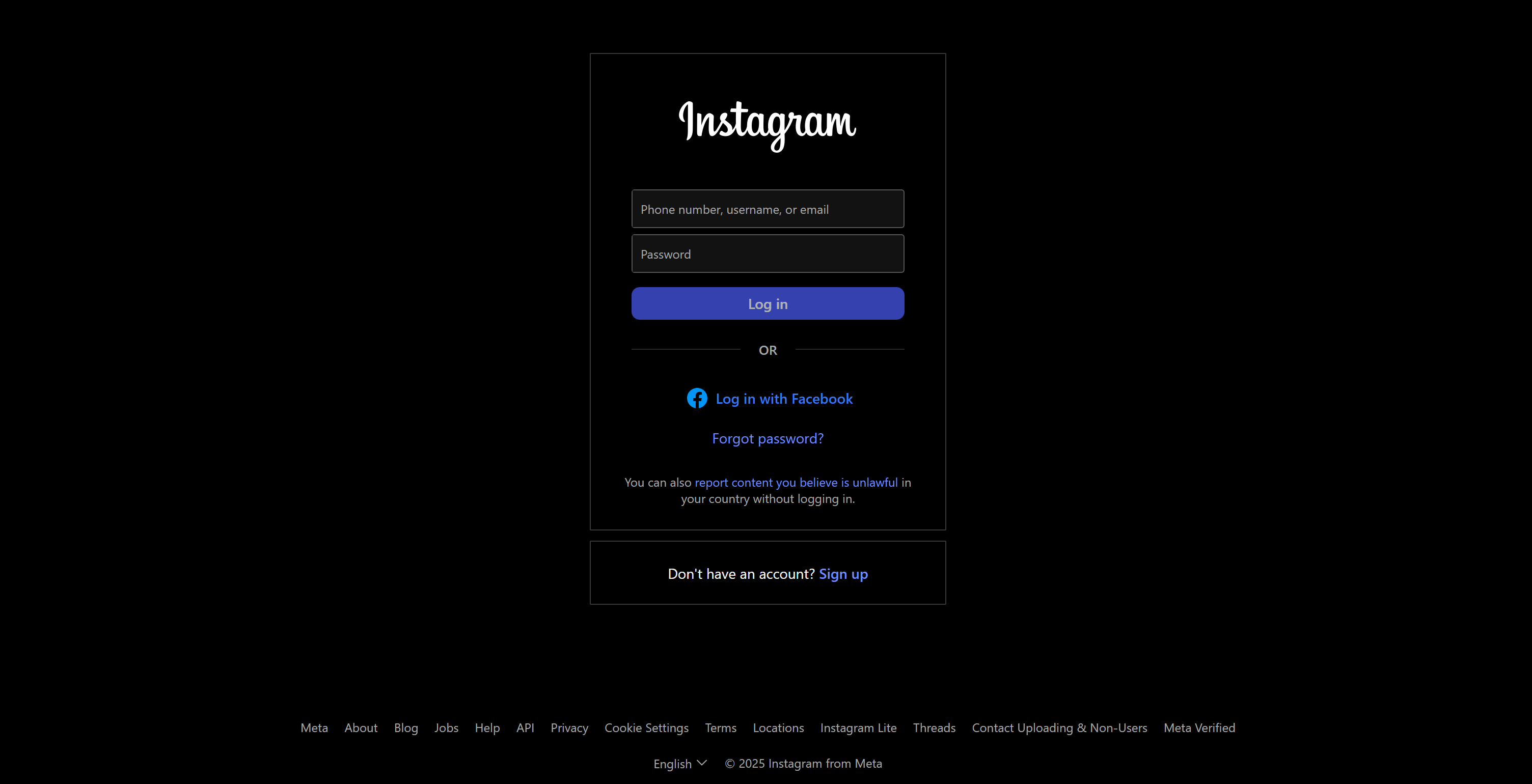
If you're wondering what happened, the Instagram anti-bot system has flagged your visit as suspicious and displays a login page instead. This happens even though the page is public and should be viewable without logging in. Now, try visiting the same page using a reliable residential IP address:
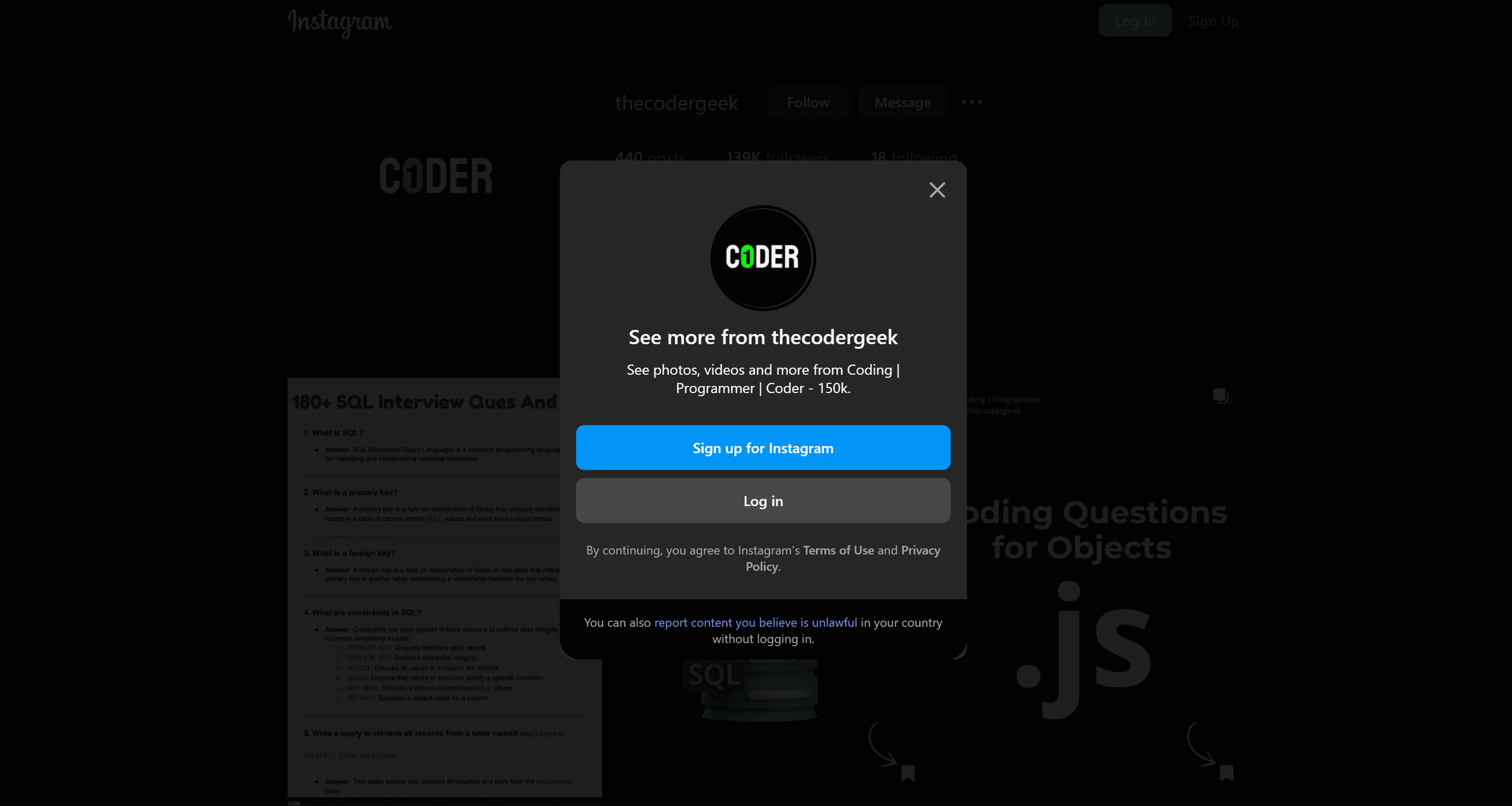
Behind the login modal, if you close it by clicking the “X” in the top-right corner, you’ll be able to see the Instagram posts and profile data:
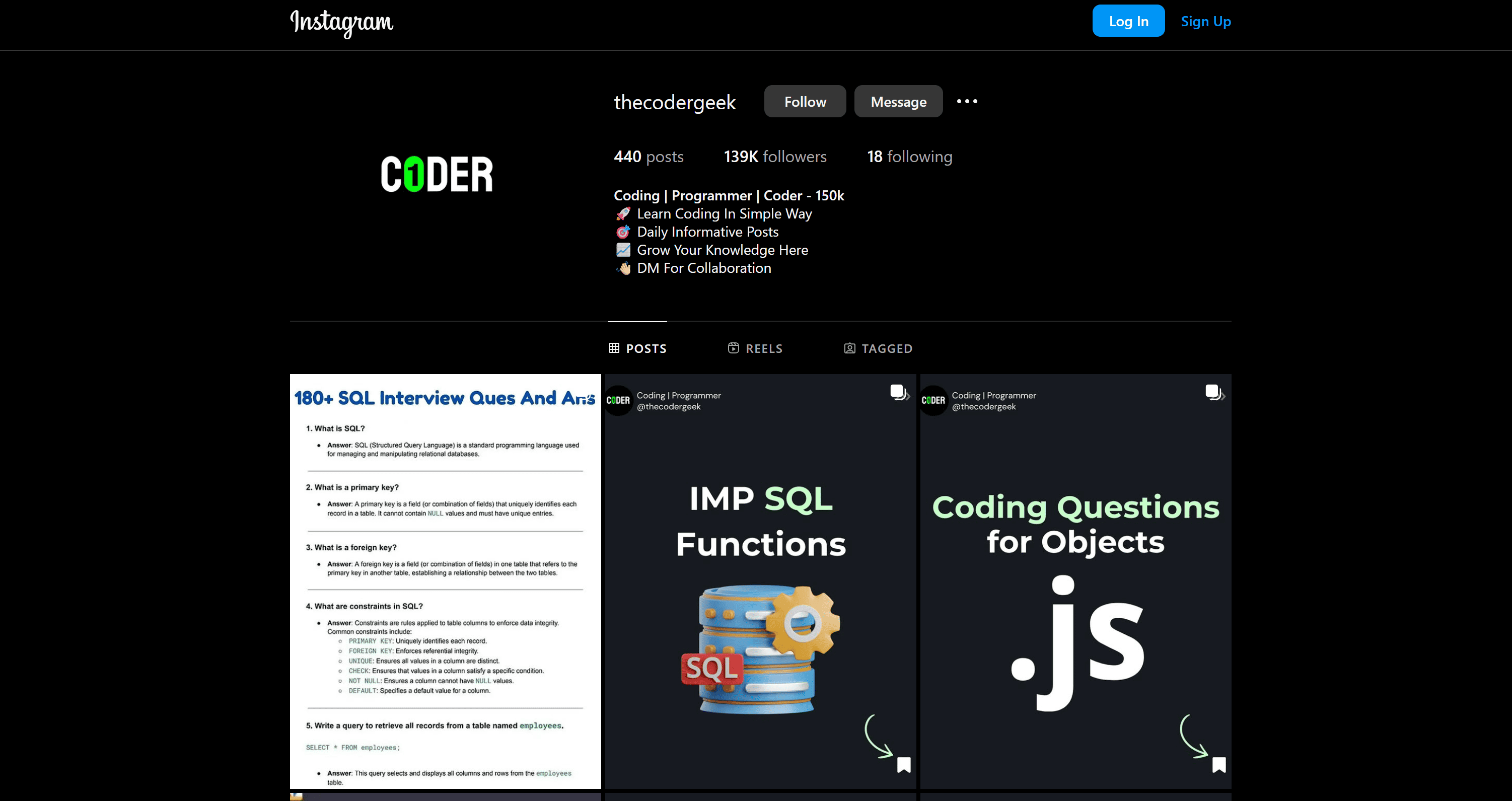
Now, try clicking on any post, and you’ll be blocked again by another login modal:
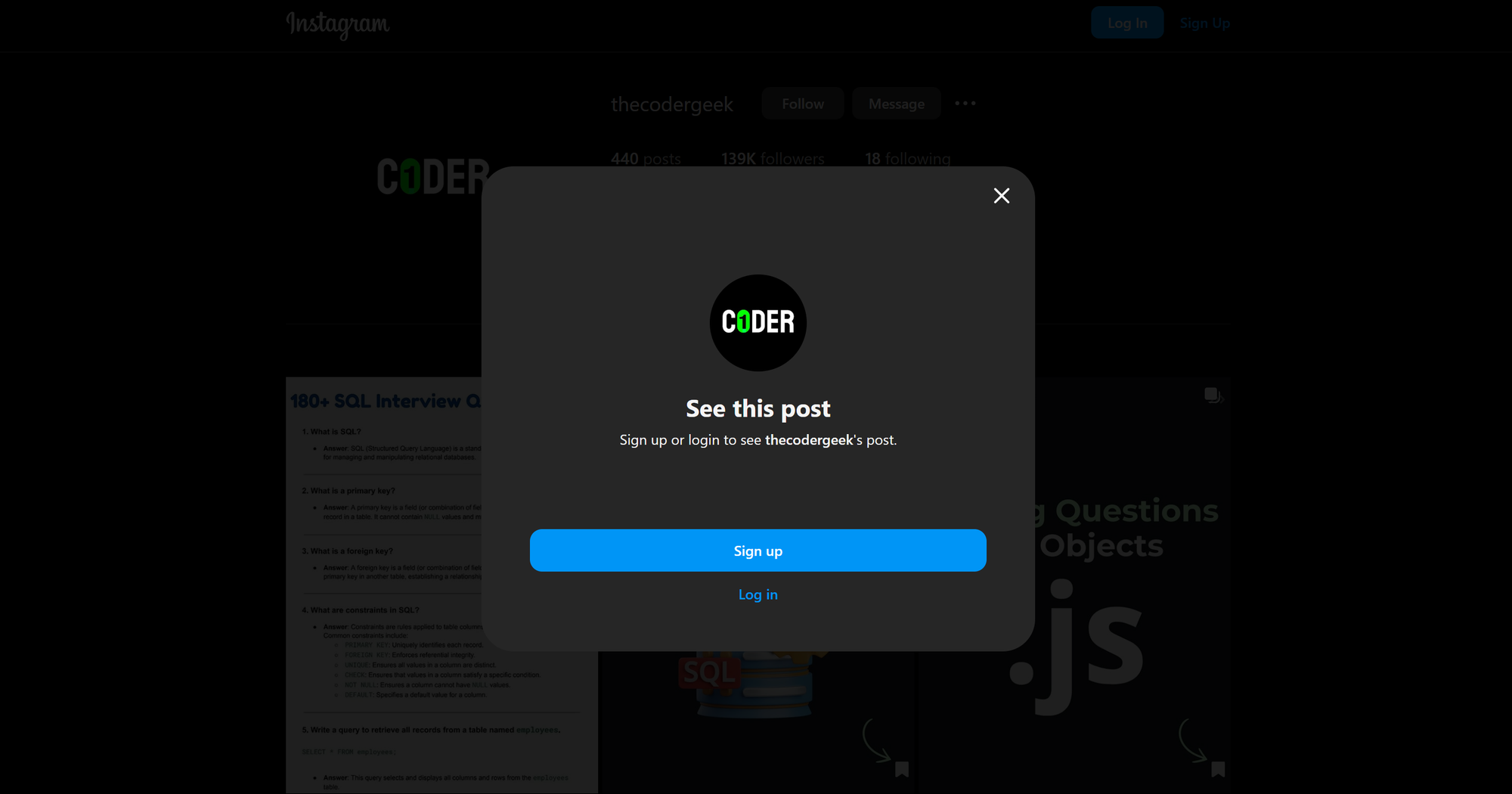
Keep in mind that everything above was done manually through a standard browser. Now, imagine replicating this behavior using an automated tool. That would make the interaction more complex, with the added risk of never being able to access the content at all (due to the login modals).
At this point, you might think scraping Instagram is impossible, but that’s not necessarily the case. If you inspect the network traffic and analyze the API calls made by the browser, you’ll find potential entry points to get the data you’re interested in. That approach is called API scraping.
Still, making those API calls without getting blocked is tricky, too. Instagram frequently changes its internal APIs and is notoriously aggressive when it comes to detecting and blocking automated requests to its APIs.
The key to success is to stay up to date with the headers Instagram expects for its API calls and execute those requests through machines configured with residential proxies. This is one of those cases where the technical challenge of building and maintaining a custom Instagram scraper is often too high to justify the effort.
So, a smarter move is to scrape Instagram in Python using a ready-made tool accessible via API.
How to use an Instagram scraper in Python
In this guided section, you’ll learn how to use an Apify Actor to scrape Instagram via API. If you’re not familiar with the term, an Apify Actor is a cloud-based scraper that runs on the Apify platform. Apify offers over 230 Instagram scraping Actors.
Here, you'll see how to connect to one of these Actors via API to programmatically scrape Instagram posts in your Python application.
Specifically, we’ll walk through the following steps:
- Python project setup
- Select the Instagram Post Scraper Apify Actor
- Configure the API integration
- Prepare your Python app for the Instagram scraping integration
- Retrieve and set your Apify API token
- Complete code
Let's begin!
Prerequisites
To get the most out of this guide, make sure you have the following:
- An Apify account
- A basic understanding of how Apify Actors work when called via API
- General knowledge of how API-based web scraping works
Since this tutorial uses Python for scraping data from Instagram, you’ll also need:
- Python 3.9+ or later installed on your machine
- A Python IDE (e.g., Visual Studio Code with the Python extension or PyCharm)
- Basic familiarity with Python programming
1. Python project setup
If you don't already have a Python application set up, follow the steps below to create a new project.
First, begin by creating a new folder:
mkdir instagram-scraper
Navigate into the folder and set up a virtual environment inside it:
cd instagram-scraper
python -m venv venv
Open the project in your IDE and create a new file named scraper.py. This will contain your scraping logic.
To activate the virtual environment on Windows, open the IDE's terminal and run the following:
venv\\Scripts\\activate
Equivalently, on Linux/macOS, execute:
source venv/bin/activate
2. Select Instagram Post Scraper
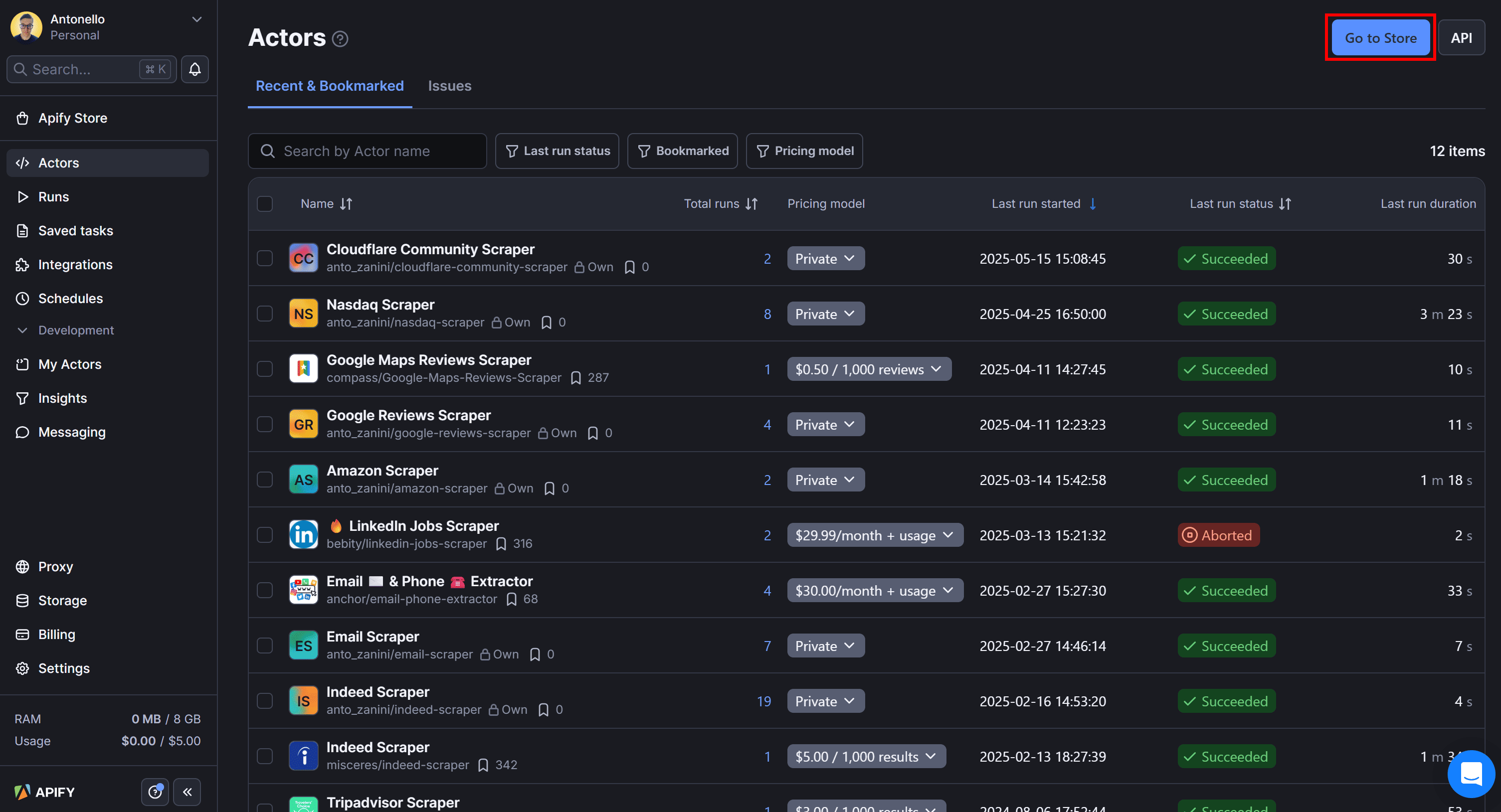
To initialize the Instagram scraper Actor for data retrieval via API, log in to your Apify account, go to Apify Console, and click the “Go to Store” button:
In Apify Store, search for “Instagram” and press Enter:
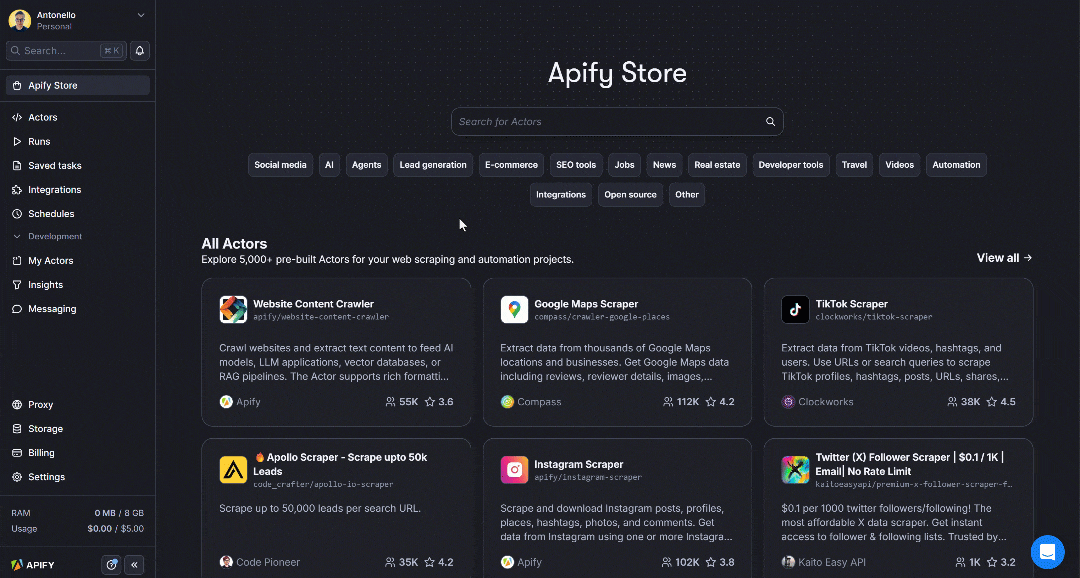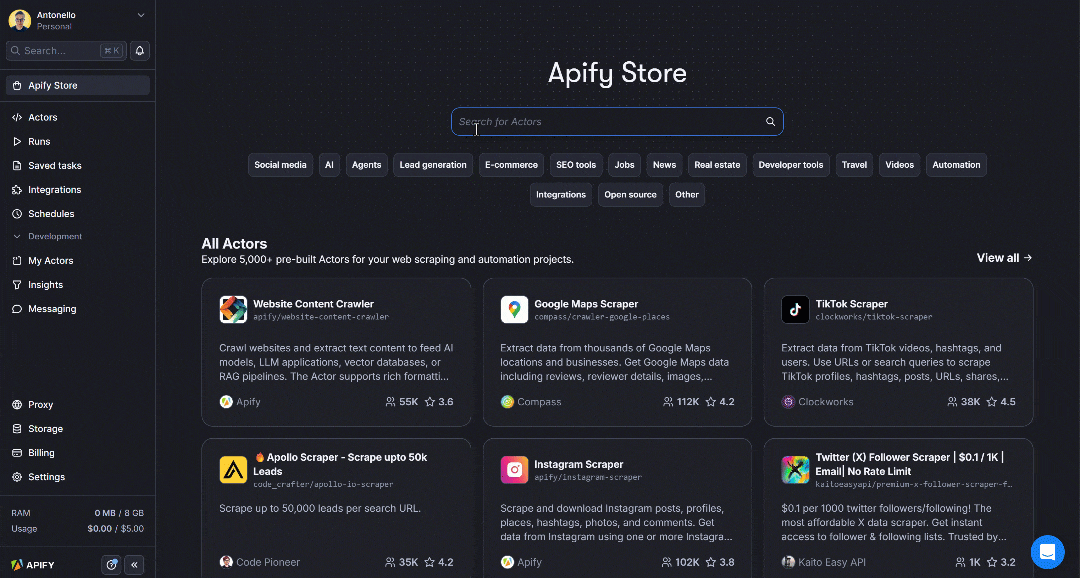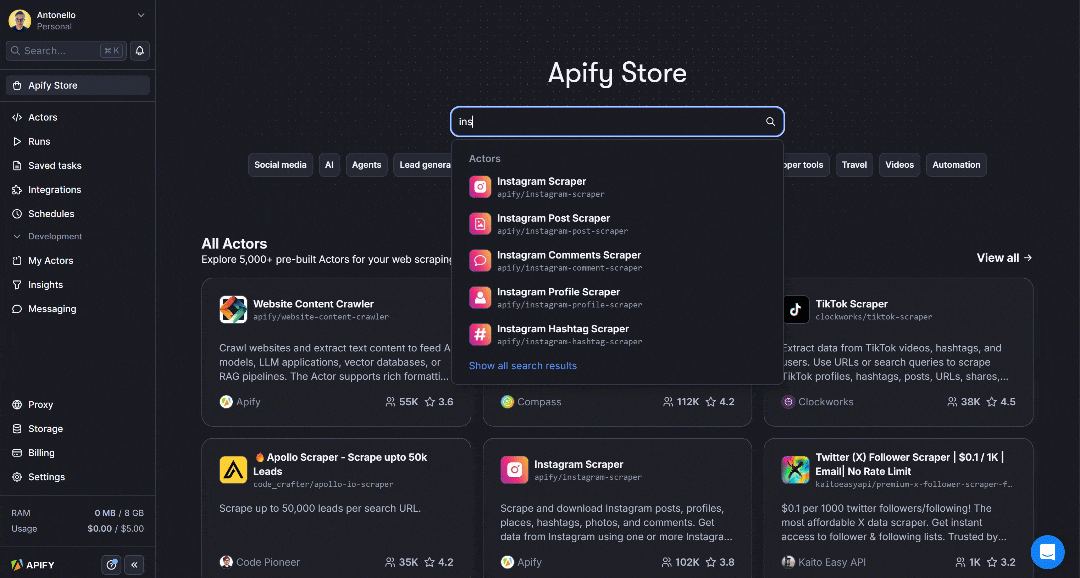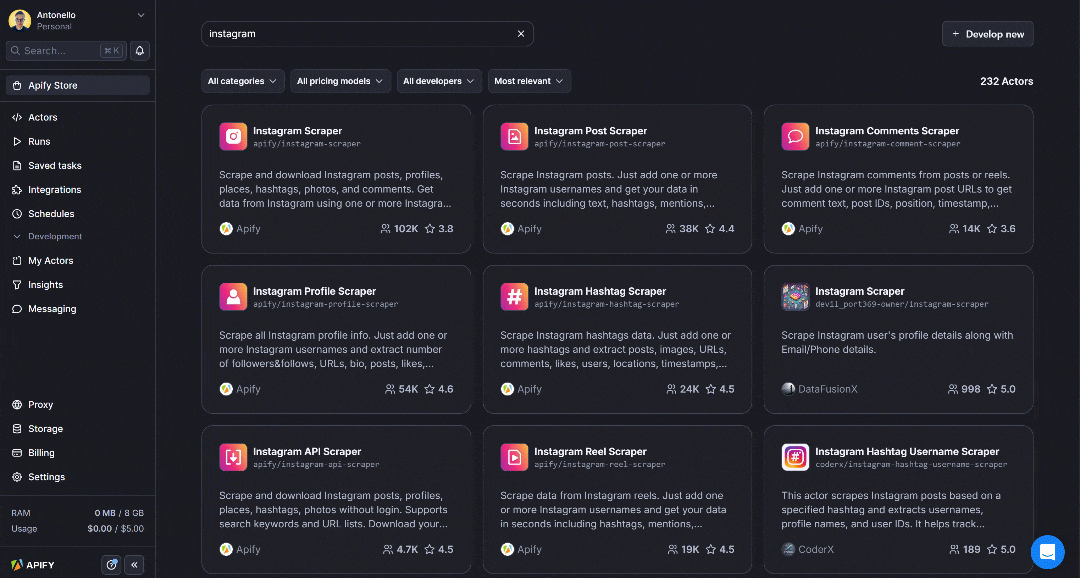
As you can see, you’ll find over 230 Instagram scraping Actors available. In this case, select the “Instagram Post Scraper” Actor:
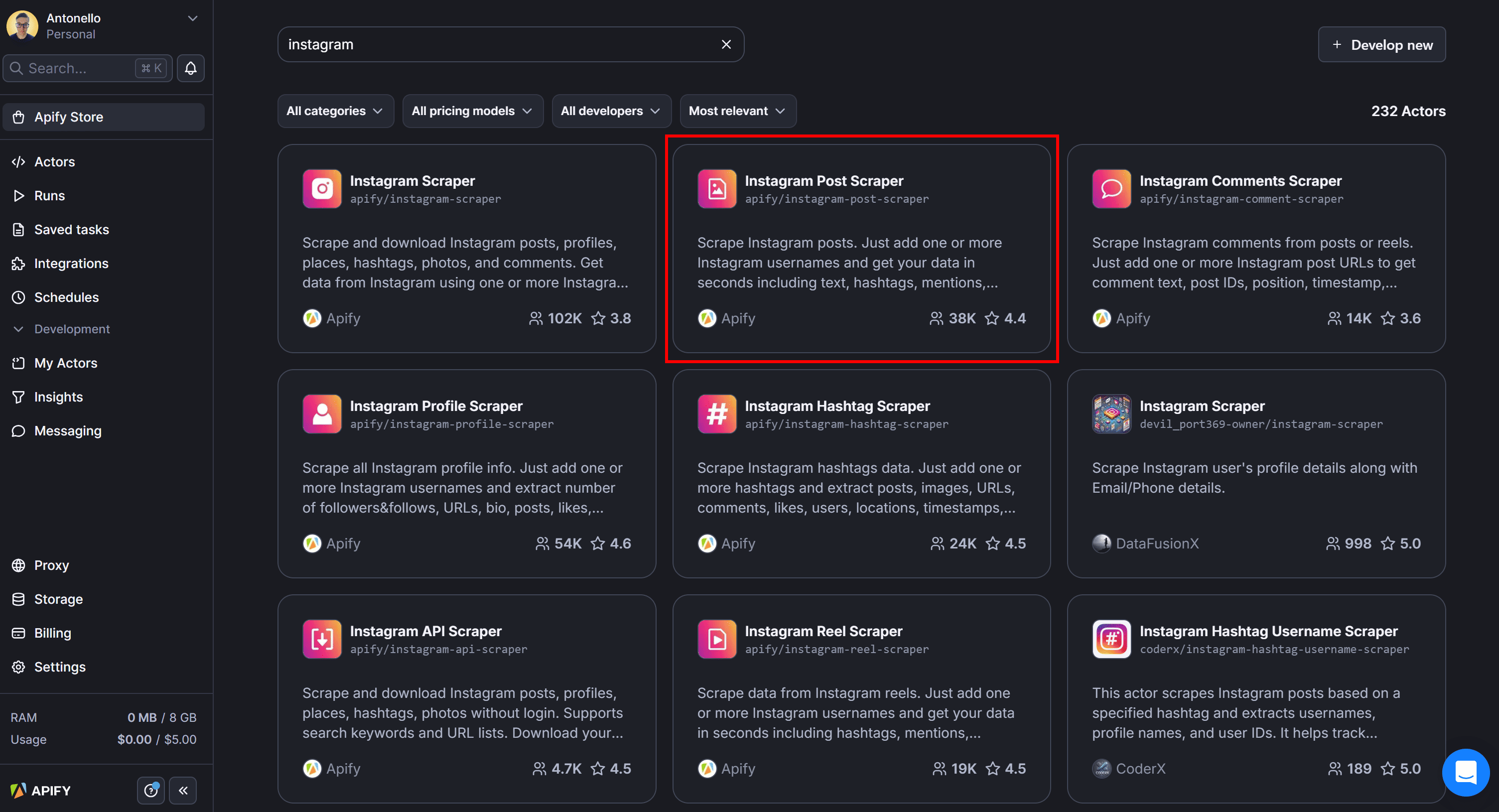
You’ll be redirected to the Instagram Post Scraper Actor page:
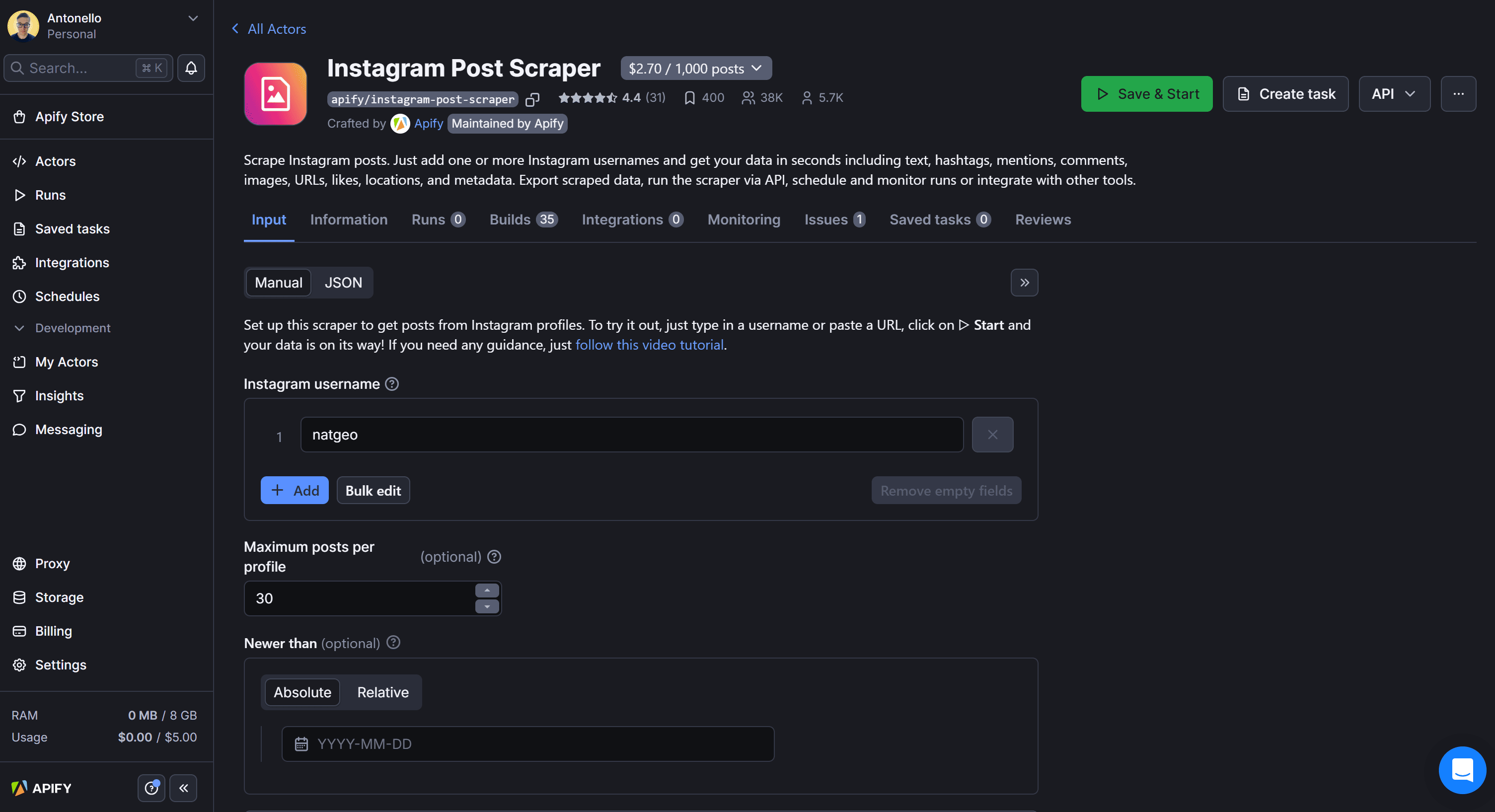
From here, you can test the Actor directly in the console by clicking the “Save & Start” button. Still, since our goal is to call it programmatically via API, we’ll follow a different workflow.
3. Configure the API integration
Expand the “API” dropdown in the top-right corner and select the “API client” option:
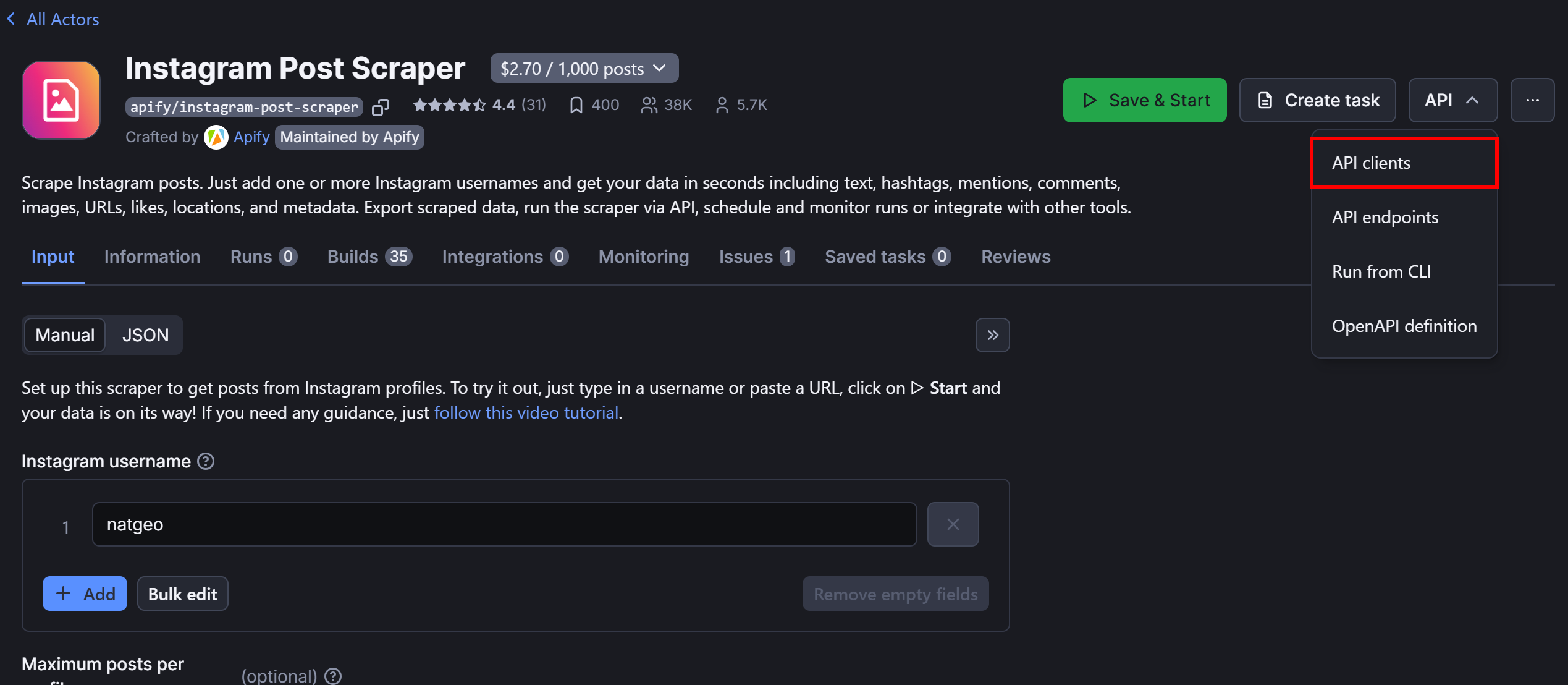
This will open the following modal:
As you can tell, the above modal contains a code snippet for calling the selected Actor via API using the Apify Client library. By default, it shows the Node.js version, but since we’re working in Python, click the “Python” tab:
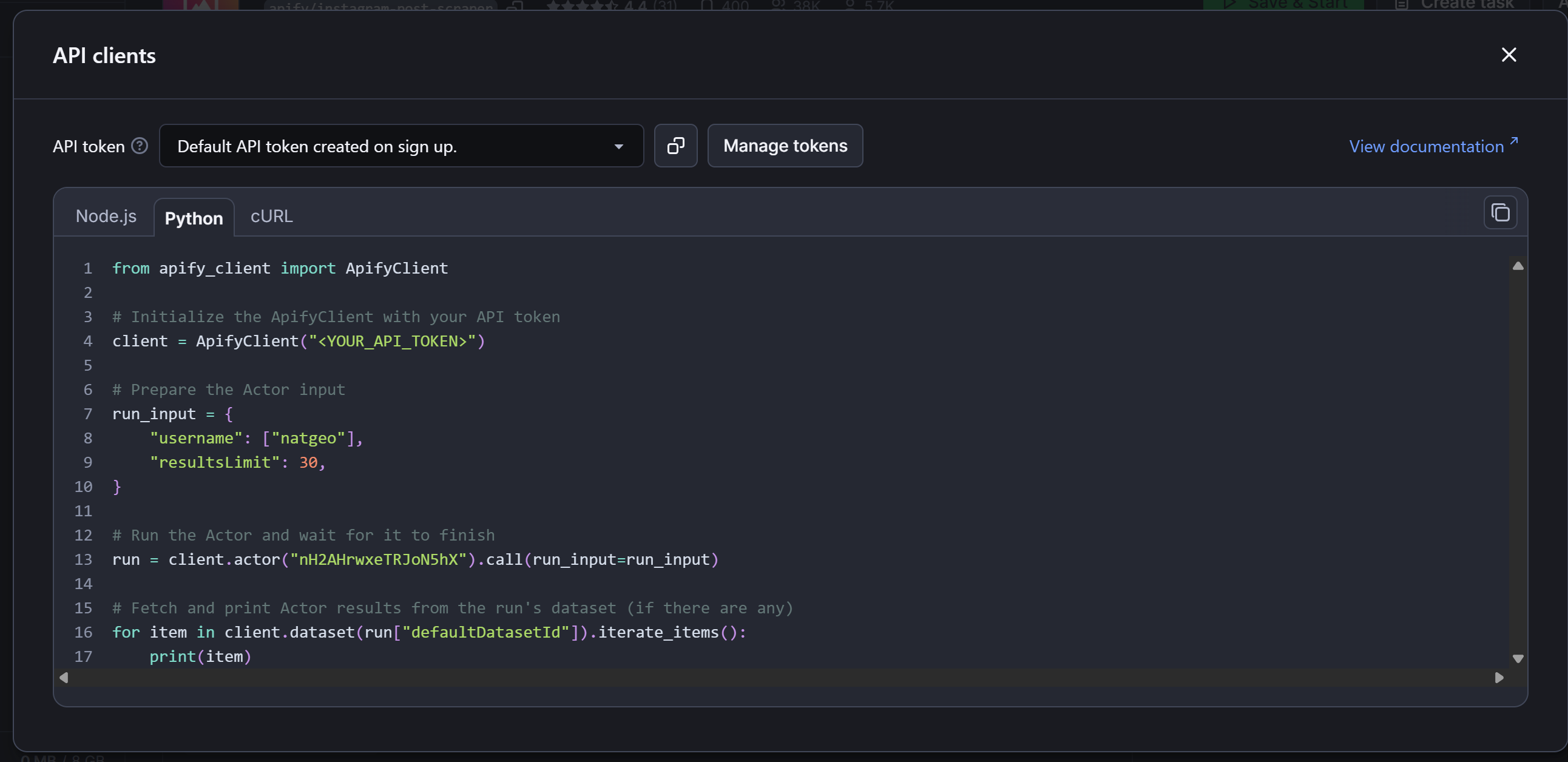
Copy the Python snippet and paste it into your scraper.py file. Keep this modal open, as we’ll return to it shortly.
4. Prepare your Python app for the Instagram scraping integration
If you inspect the code snippet you copied from the Apify Console, you’ll notice it uses the apify_client Python library. To install it, make sure your virtual environment is activated, then run:
pip install apify_client
You’ll also see that the snippet includes secrets (like your Apify API token) and other hardcoded strings and parameters.
To make your Instagram data retrieval integration more maintainable and secure, it’s best to store those values in environment variables. For this, we’ll use the python-dotenv library, which allows you to load environment variables from a .env file.
In your activated environment, install it with:
pip install python-dotenv
Then, add a .env file to your project's root folder, which should now contain:
instagram-scraper/
├── venv/
├── .env # <---
└── scraper.py
Initialize the .env file with the following variables:
APIFY_API_TOKEN=""
INSTAGRAM_USERNAME="natgeo"
INSTAGRAM_POST_SCRAPER_ACTOR_ID="nH2AHrwxeTRJoN5hX"
Next, add the logic to read those values in scraper.py:
from dotenv import load_dotenv
import os
# Load environment variables from .env file
load_dotenv()
# Read values from environment
APIFY_API_TOKEN = os.getenv("APIFY_API_TOKEN")
INSTAGRAM_USERNAME = os.getenv("INSTAGRAM_USERNAME")
INSTAGRAM_POST_SCRAPER_ACTOR_ID = os.getenv("INSTAGRAM_POST_SCRAPER_ACTOR_ID")
Note that os.getenv() allows you to retrieve the values of environment variables, which have been loaded from the .envfile due to the load_dotenv() function call.
Now, update your scraper.py file to use the values read from the envs:
# Initialize the ApifyClient with your API token
client = ApifyClient(APIFY_API_TOKEN)
# Prepare the Actor input
run_input = {
"username": [INSTAGRAM_USERNAME],
"resultsLimit": 30,
}
# Run the Actor and wait for it to finish
run = client.actor(INSTAGRAM_POST_SCRAPER_ACTOR_ID).call(run_input=run_input)
# Fetch and print Actor results from the run's dataset (if there are any)
for item in client.dataset(run["defaultDatasetId"]).iterate_items():
print(item)
Wonderful! You can now programmatically control your Instagram scraping integration simply by updating values in the .env file.
5. Retrieve and set your Apify API token
It’s now time to retrieve your Apify API token and add it to your .env file. This is the final piece needed to complete the Instagram scraping integration.
Back in the Instagram Posts Scraper Actor's “API clients” modal, click the “Manage tokens” button:
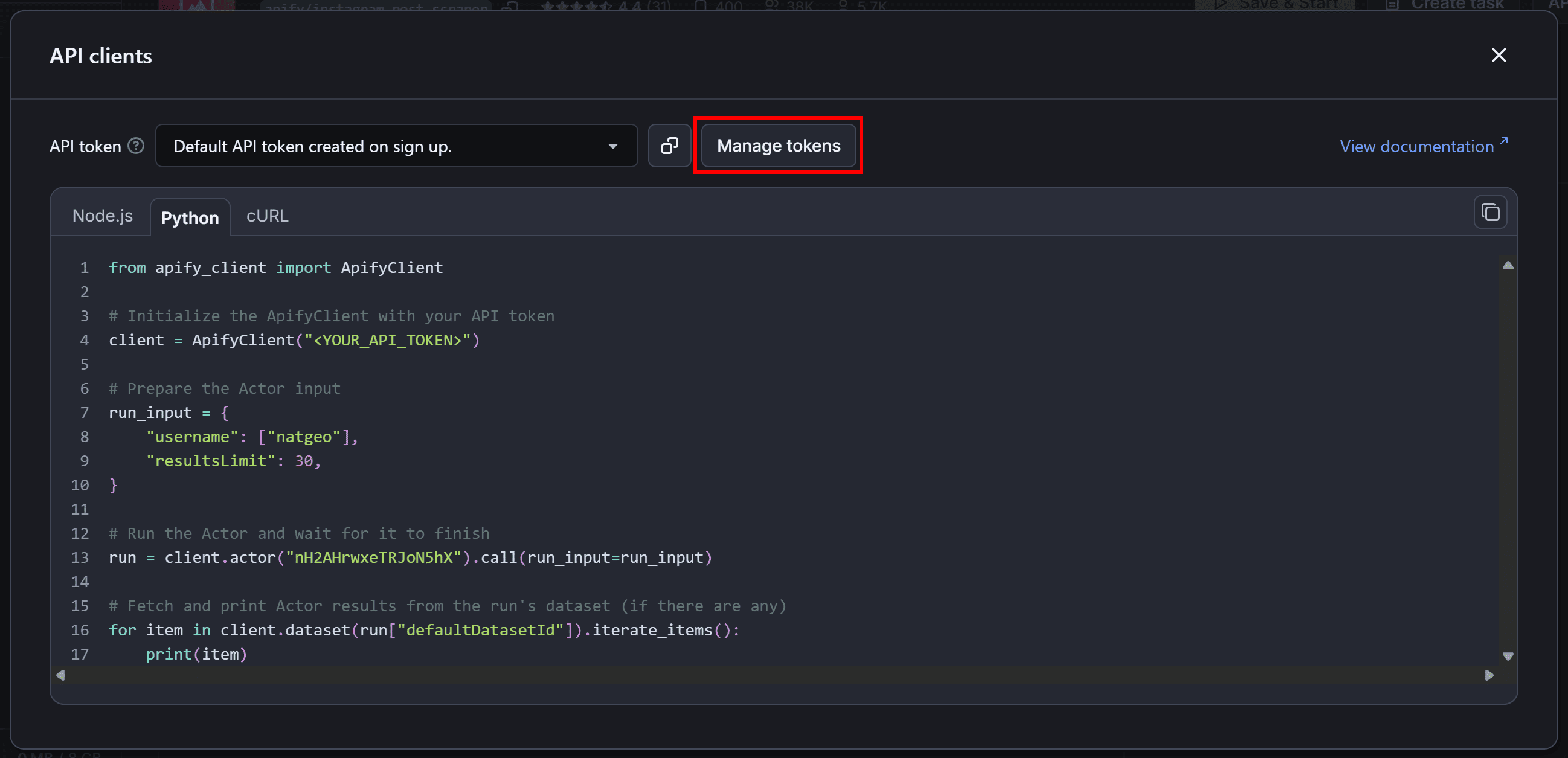
You’ll be redirected to the “API & Integrations” tab in your account settings. There, click the “Copy to clipboard” button to copy your personal Apify API token:
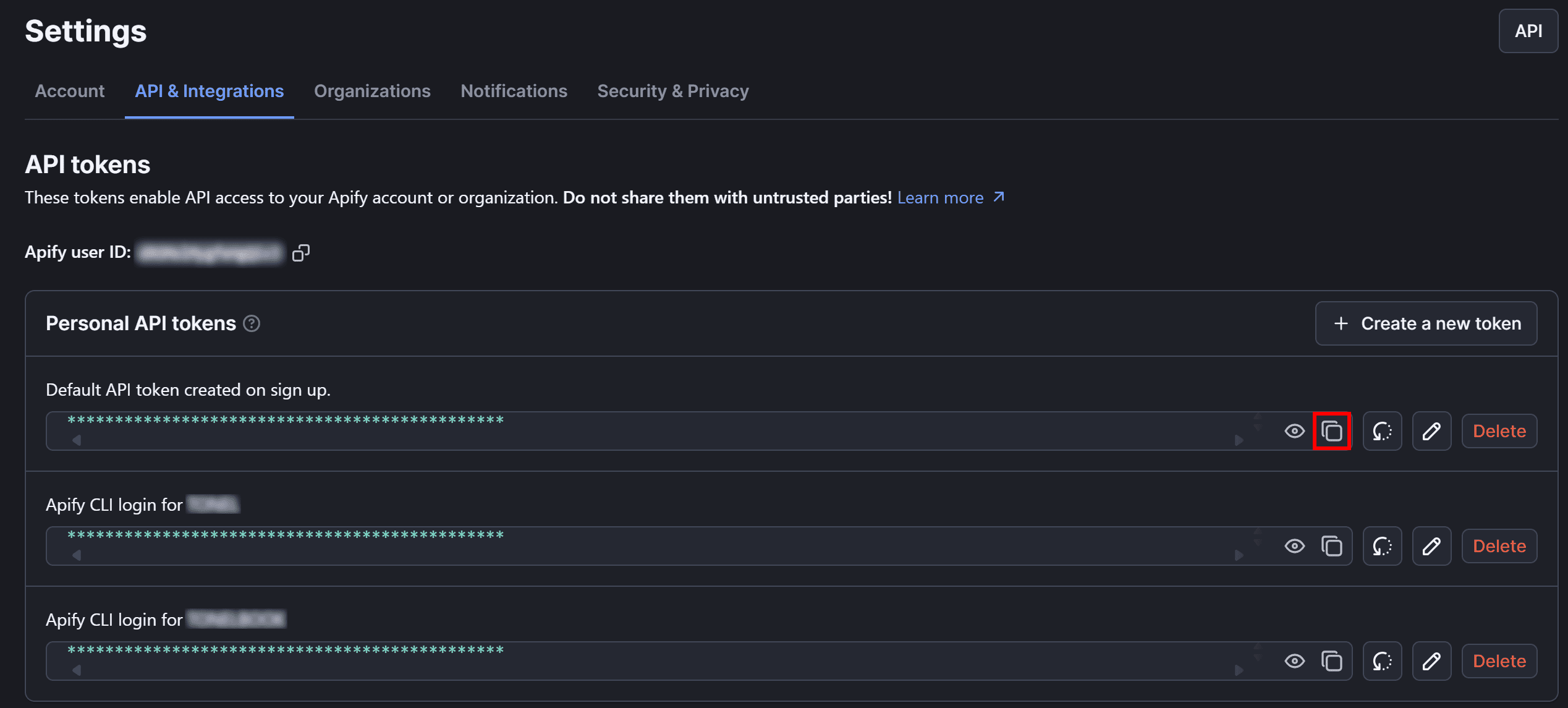
Now, paste the token into your .env file like this:
APIFY_API_TOKEN=
Make sure to replace the <YOUR_APIFY_API_TOKEN> placeholder with the actual token you just copied.
6. Complete code
Below is the final code of the Python scraper.py script that integrates with the Apify API to scrape Instagram post data:
# pip install apify_client python-dotenv
from apify_client import ApifyClient
from dotenv import load_dotenv
import os
# Load environment variables from .env file
load_dotenv()
# Read values from environment
APIFY_API_TOKEN = os.getenv("APIFY_API_TOKEN")
INSTAGRAM_USERNAME = os.getenv("INSTAGRAM_USERNAME")
INSTAGRAM_POST_SCRAPER_ACTOR_ID = os.getenv("INSTAGRAM_POST_SCRAPER_ACTOR_ID")
# Initialize the ApifyClient with your API token
client = ApifyClient(APIFY_API_TOKEN)
# Prepare the Actor input
run_input = {
"username": [INSTAGRAM_USERNAME],
"resultsLimit": 30,
}
# Run the Actor and wait for it to finish
run = client.actor(INSTAGRAM_POST_SCRAPER_ACTOR_ID).call(run_input=run_input)
# Fetch and print Actor results from the run's dataset (if there are any)
for item in client.dataset(run["defaultDatasetId"]).iterate_items():
print(item)
Instead, your .env file should look like this:
APIFY_API_TOKEN="apify_api_XXXXXXXXXXXXXXXXXXXXX"
INSTAGRAM_USERNAME="natgeo"
INSTAGRAM_POST_SCRAPER_ACTOR_ID="nH2AHrwxeTRJoN5hX"
Replace INSTAGRAM_USERNAME with the username of the public Instagram account you want to scrape post information from. In this case, we’ll keep the default natgeo username, which corresponds to the Instagram National Geographic page.
Run the above Instagram scraping integration script with:
python scraper.py
The execution may take a while, so be patient.
The output should be something like:
{
"caption": "According to a recent report, cancer is becoming more common in young people—especially women, who account for two-thirds of all cancers diagnosed in people under 50.\\n\\nWhile this trend isn't completely new, doctors cannot definitively explain what’s fueling the increases. But they do have some guesses, stemming from environment, policy, and culture.\\n\\nFind out what experts say about lowering your risk at the link in bio.\\n\\nImage by Centre Jean-Perrin/Science Photo Library",
"ownerFullName": "National Geographic",
"ownerUsername": "natgeo",
"url": "https://www.instagram.com/p/DKscBMITzuZ/",
"commentsCount": 1582,
"firstComment": "le schifezze nel cibo che coltiviamo e compriamo",
"likesCount": 51088,
"timestamp": "2025-06-09T21:00:10.000Z"
},
// Omitted for brevity...
{
"caption": "Photo by Muhammed Muheisen @mmuheisen | On a sunny spring day in the Netherlands, people enjoy a boat ride on a canal in Amsterdam. The city’s famous canals date back to the Middle Ages, when they were built primarily for defense and water management. During the late 16th century and the 17th century, they played a major part in Amsterdam’s commercial growth and expansion. Reflecting a mercantile spirit, many of the buildings along the canals were designed for mixed use: at once a residence, storage unit, and place of business. For more photos and videos from different parts of the world, follow me @mmuheisen.",
"ownerFullName": "National Geographic",
"ownerUsername": "natgeo",
"url": "https://www.instagram.com/p/DKa17J4MmGk/",
"commentsCount": 127,
"firstComment": "So beautiful 👌",
"likesCount": 57517,
"timestamp": "2025-06-03T01:00:12.000Z"
}
In detail, the script will return the last 30 Instagram posts made by the configured account, as specified by the resultsLimit argument.
Great! The above output contains the same Instagram post details you can see on the target page—but in a structured format.
Once the run completes, the dataset is available in your Apify account for 6 days by default. You can find it under the “Storage > Datasets” section of your account:
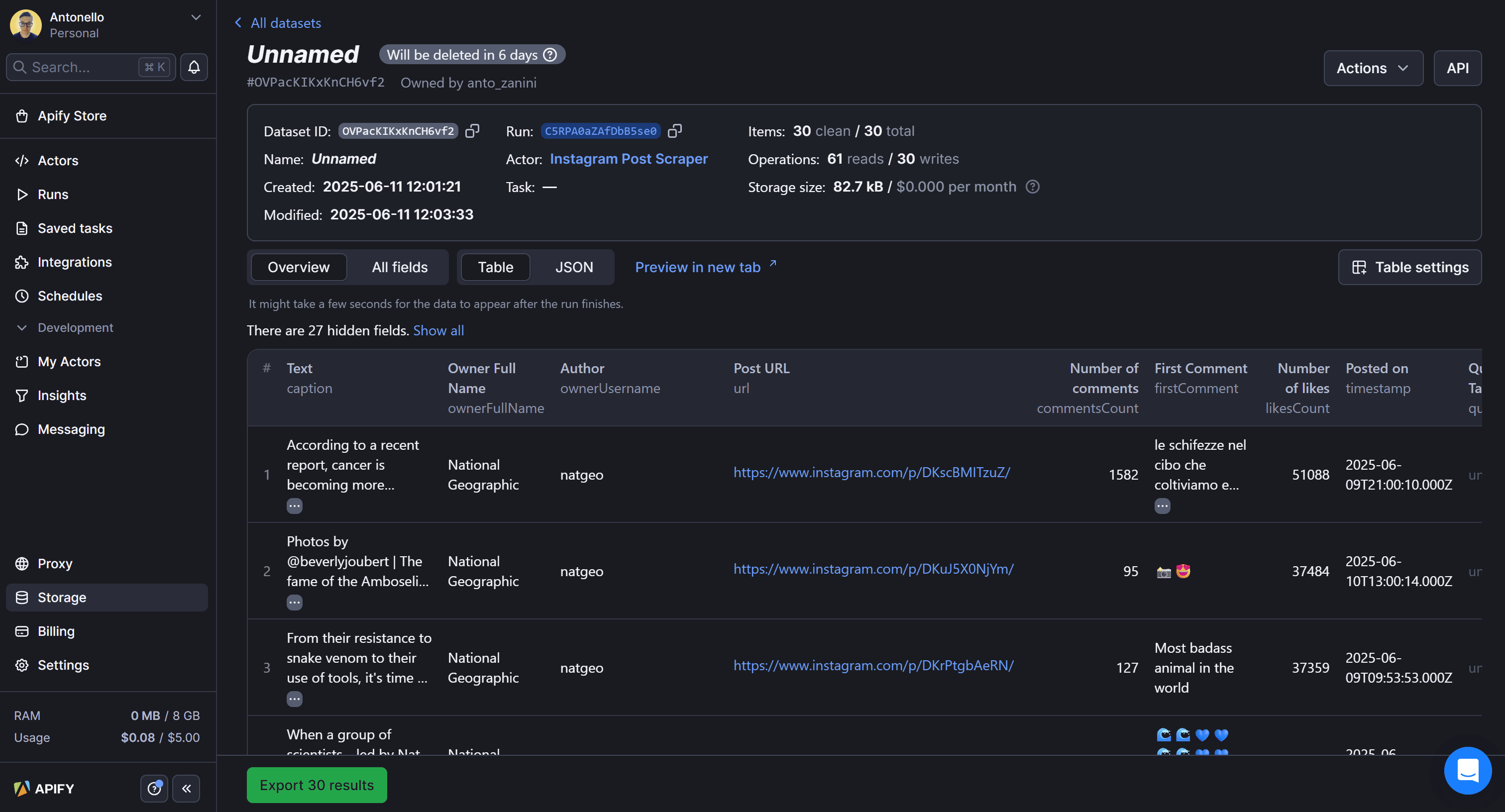
Here, you can view results in tabular format or raw JSON. Also, you can export the dataset to various formats like JSON, CSV, XML, Excel, HTML Table, RSS, and JSONL.
Et voilà! Instagram scraper integrated successfully.
Next steps
This tutorial has guided you through the basics of scraping Instagram post information via the API. To take your scraper to the next level, consider implementing these advanced techniques:
- Integrate pagination: Use Apify API’s pagination features to scrape more than just the first 30 posts.
- Data export: Export the scraped data to a JSON file or store it in a database for future analysis.
- Data analysis: Use the data retrieved from Instagram via the Apify scraping API to create charts or process it for your specific needs, leveraging the many Python data visualization and processing libraries available.
- Automated running: Configure your scripts to run automatically at scheduled intervals to keep scraping fresh data, since the target account will continue publishing new posts. That is possible thanks to the
ScheduleClientclass.
Conclusion
This tutorial showcased how Apify makes it possible to collect data from platforms that are otherwise difficult to scrape due to advanced anti-bot protections. This saves you the effort of building and maintaining your own scripts.

Frequently asked questions
Why scrape Instagram?
Scraping Instagram helps gather valuable public data like posts, comments, and follower insights. Businesses and researchers can use that data to analyze trends, monitor brand reputation, or gain market intelligence without manual browsing.
Can you scrape Instagram?
Yes, you can scrape Instagram, but it requires careful handling due to anti-bot protections and platform restrictions. Using Instagram’s APIs or specialized tools like Apify’s Instagram Post Scraper helps simplify the process and reduce the risk of being blocked.
Is it legal to scrape Instagram?
Yes, it's legal to scrape Instagram as long as you extract data only from public profiles. However, some kinds of data are protected by terms of service or national and even international regulations, so take great care when scraping data behind a login, personal data, intellectual property, or confidential data.
How to scrape Instagram?
To scrape Instagram, it’s recommended to connect to its hidden APIs or use dedicated scraping solutions that handle anti-bot protections. You can also write custom scripts using setups like Requests + Beautiful Soup or Playwright, but bypassing all blocks can be challenging.