In this article
We’ll break down how to reverse engineer a website’s internal API, focusing on practical techniques and common challenges. We’ll start with technology-independent steps that can be applied to any project so you can find and analyze relevant API requests.
After covering the fundamentals, we’ll dive into a hands-on demonstration of how to build a scraper that utilizes the discovered API endpoints. By the end, you’ll have a clear understanding of how to extract data efficiently from dynamic websites without resorting to full browser automation.
Prerequisites
- Basics of HTTP (requests, responses, headers, payloads, query parameters, and methods)
- Common data formats (HTML, JSON, XML)
- Basics of APIs (REST, GraphQL)
Extracting data from a web page: what are the options?
When scraping data from websites, the ideal approach is to use direct HTTP requests instead of emulating a web browser with tools like Playwright, Puppeteer, or Selenium. This is because browser automation is resource-intensive, slower, and more complex. It requires fully rendering pages, handling dynamic content, managing timeouts, and waiting for asynchronous data to load.
- For static websites, extracting data is relatively straightforward. Typically, we only need to fetch the page content using an HTTP request and extract the required information with CSS selectors. Tools like Cheerio or Beautiful Soup simplify this process by offering easy-to-learn syntax for selecting elements and parsing their content.
- Dynamic websites present a greater challenge. Since their content is partially or entirely generated by JavaScript, fetching the page’s HTML with a simple HTTP request often yields incomplete or empty data. At first, it may seem that browser automation is the only solution. But there might be a better alternative: finding and using the website’s internal APIs.
Using APIs instead of HTML parsing comes with several benefits:
- More stable: Unlike HTML structure, APIs tend to change less frequently. They're not affected by changes to the website's design, A/B testing, etc..
- More efficient: Instead of extracting data field by field using multiple selectors, an API might provide all data in a structured format (typically JSON).
- More comprehensive: Websites often fetch more data than they actually display. By analyzing API responses, you might gain access to hidden or additional data beyond what’s visible on the page. Moreover, extracting certain data with selectors is often tricky, especially when it's surrounded by other text.
However, identifying the right API requests can be challenging. A single page load can trigger numerous network requests. It can be tedious to go through them all manually to identify the relevant ones. Knowing how to locate and reverse engineer these API requests comes in very handy for advanced web scraping.
How to reverse engineer APIs
Extracting data from websites and automating the process requires a structured approach. We’ll break it down into four key parts:
- Part 1 – Finding data sources
- Part 2 – Testing API requests
- Part 3 – Understanding and modifying request structure
- Part 4 – Building a web scraper and automating data extraction
Part 1 – Finding data sources
We'll use Chrome Developer Tools to capture and analyze API requests. Other browsers have similar tools — though the layout and naming may vary. You can open developer tools by pressing F12 or right-clicking on a webpage and selecting Inspect.
The Network tab – your best friend for finding API requests
To see all requests sent from a web page, navigate to the Network tab and refresh the page. You’ll notice a large number of requests appearing in the list. But how do you filter out the noise and find the ones containing the data you need?
Filtering requests
In most cases, you can ignore scripts, stylesheets, and images. Focus on fetch requests, which typically retrieve API responses. Simply switch the filter from All to Fetch/XHR to narrow down the results.
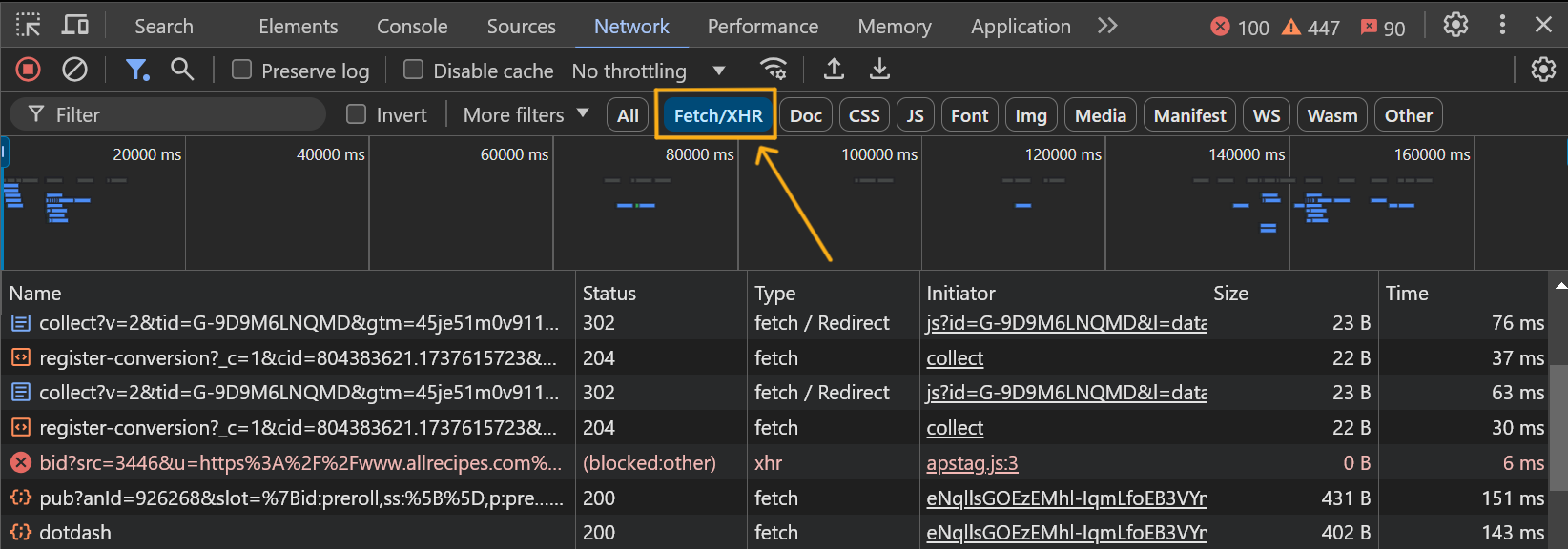
After that, you can inspect the outgoing requests and identify those that might contain useful data. Try interacting with the page while monitoring the Network tab to see which requests are triggered. For example, you can expand sections with additional data, scroll down a search page to load more results, navigate to the next search pages, or submit forms.
If the list of requests is too long, you can narrow it down further using a keyword filter. API request URLs often contain terms like api, /api, graphql, get, update, json, /v1 (or other version numbers). Filtering by these keywords can be helpful, especially if you've already identified a relevant API request and need to find similar ones. However, keep in mind that this step is optional and may not always work, as API endpoint URLs can follow any format without strict naming conventions.
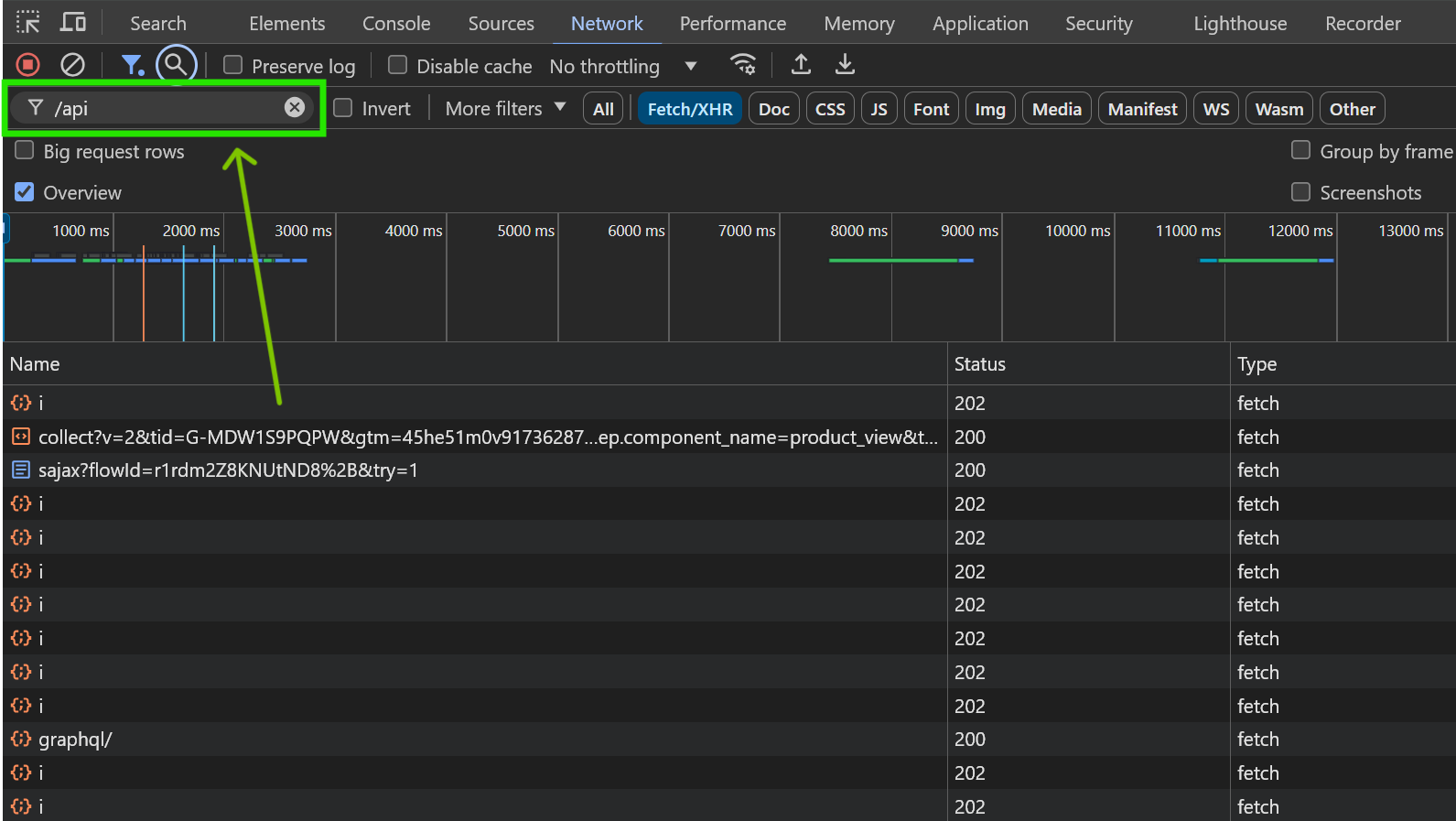
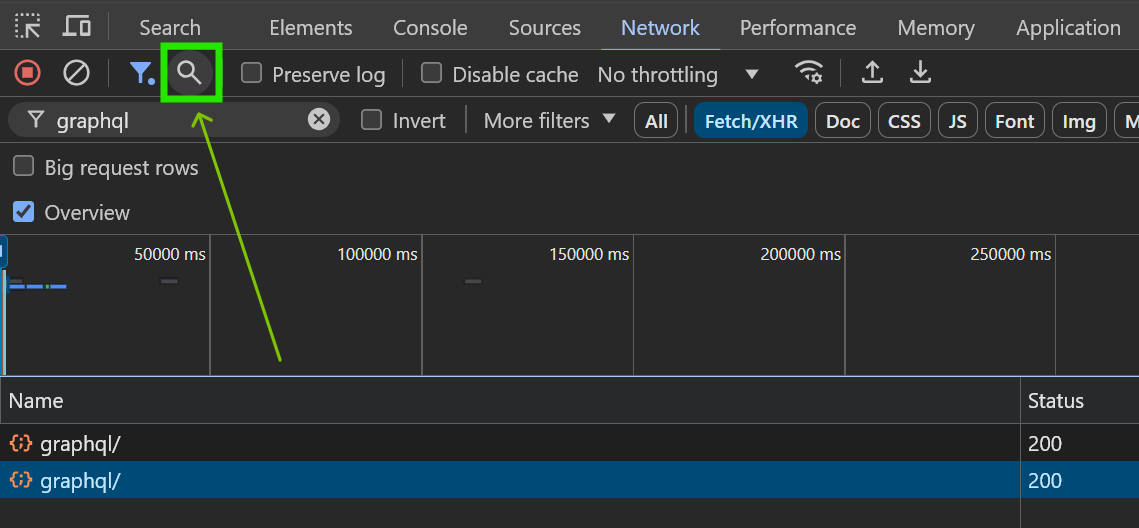
Searching within request responses
Filtering requests in the Network tab can help you locate the data you need, but it can still be time-consuming. A faster way to find relevant requests is by using the Search feature. You can access it through the dedicated Search tab located to the left of the Elements tab. A more efficient option is to stay within the Network tab, click the magnifying glass icon 🔍, and open the search panel on the side. This allows you to both filter and analyze requests without switching tabs.
Real-world example: scraping e-commerce data
Imagine we need to scrape product data from an e-commerce website like Zalando. We open a page containing information about a product's material and want to determine where this data originates. For example, the page displays: "Outer material: Leather." We can use "Leather" as a search keyword to see where it appears across all requests (including the request for the main HTML document).
The search feature supports both case-sensitive and case-insensitive queries, as well as regular expressions, allowing for more advanced searches if needed.
In the screenshot below, the keyword "Leather" appears in 10 files, with most occurrences found in the main HTML document available at Dr. Martens BACKPACK UNISEX - Rucksack - black.
When analyzing data sources, pay special attention to data stored in JSON structures. If one piece of structured data is present, there's a good chance that other useful information will be available within the same JSON object or array.
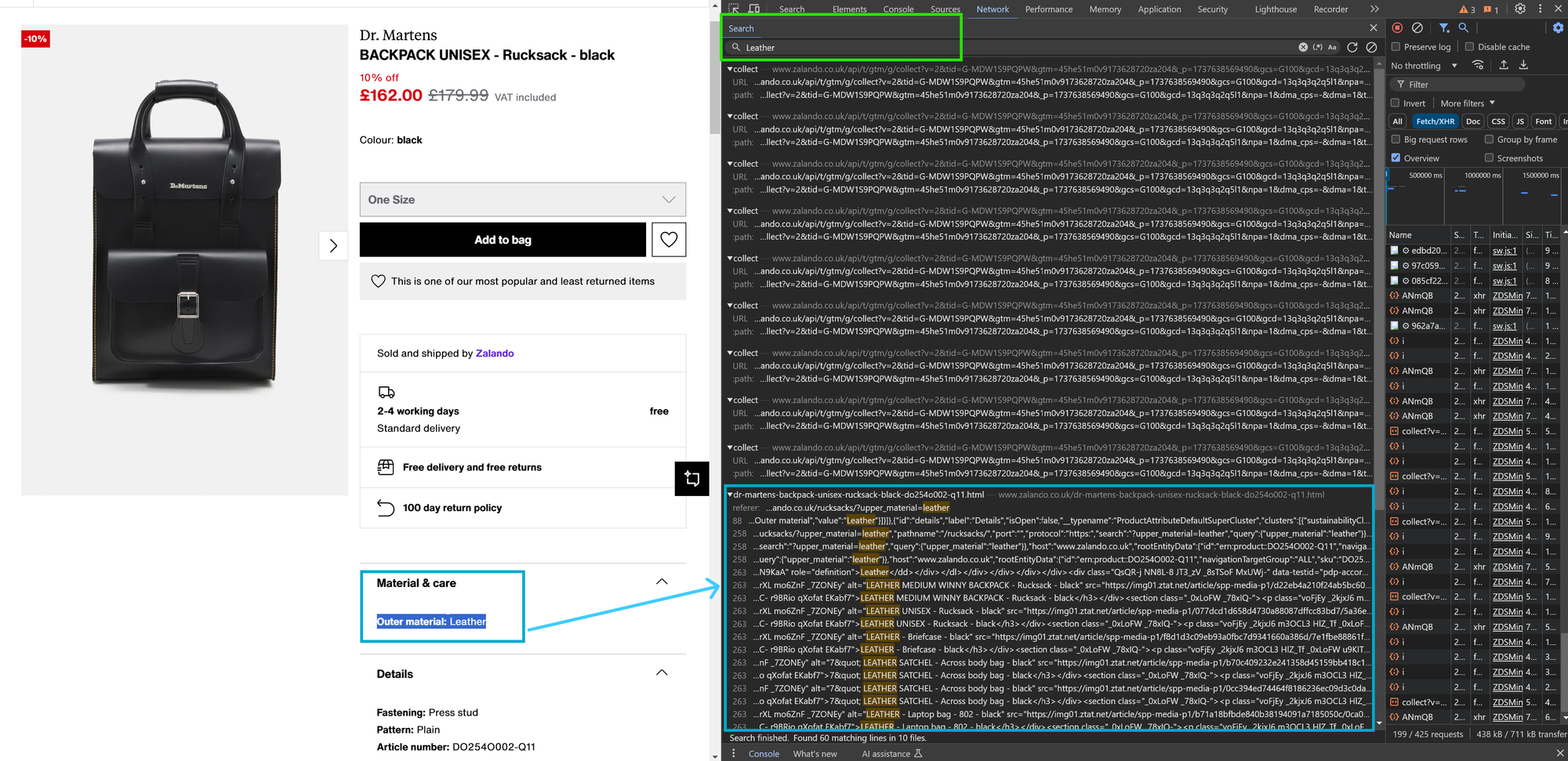
To view a specific occurrence of the searched keyword, simply click on the corresponding line, and the response for that request will open. For example, clicking on the line prefixed with 88 (as shown in the above image) reveals JSON data containing product attributes, including the following object:
{
"__typename": "ProductAttributeKeyValue",
"key": "Outer material",
"value": "Leather"
}
If you take a closer look at the response, you'll notice additional product attributes stored nearby, such as Fastening and Pattern:
[
{
"__typename": "ProductAttributeKeyValue",
"key": "Fastening",
"value": "Press stud"
}
{
"__typename": "ProductAttributeKeyValue",
"key": "Pattern",
"value": "Plain"
}
]
This example demonstrates that multiple structured attributes are available in the same data source.
The image below illustrates the connection between the data displayed on the webpage and the corresponding API response.
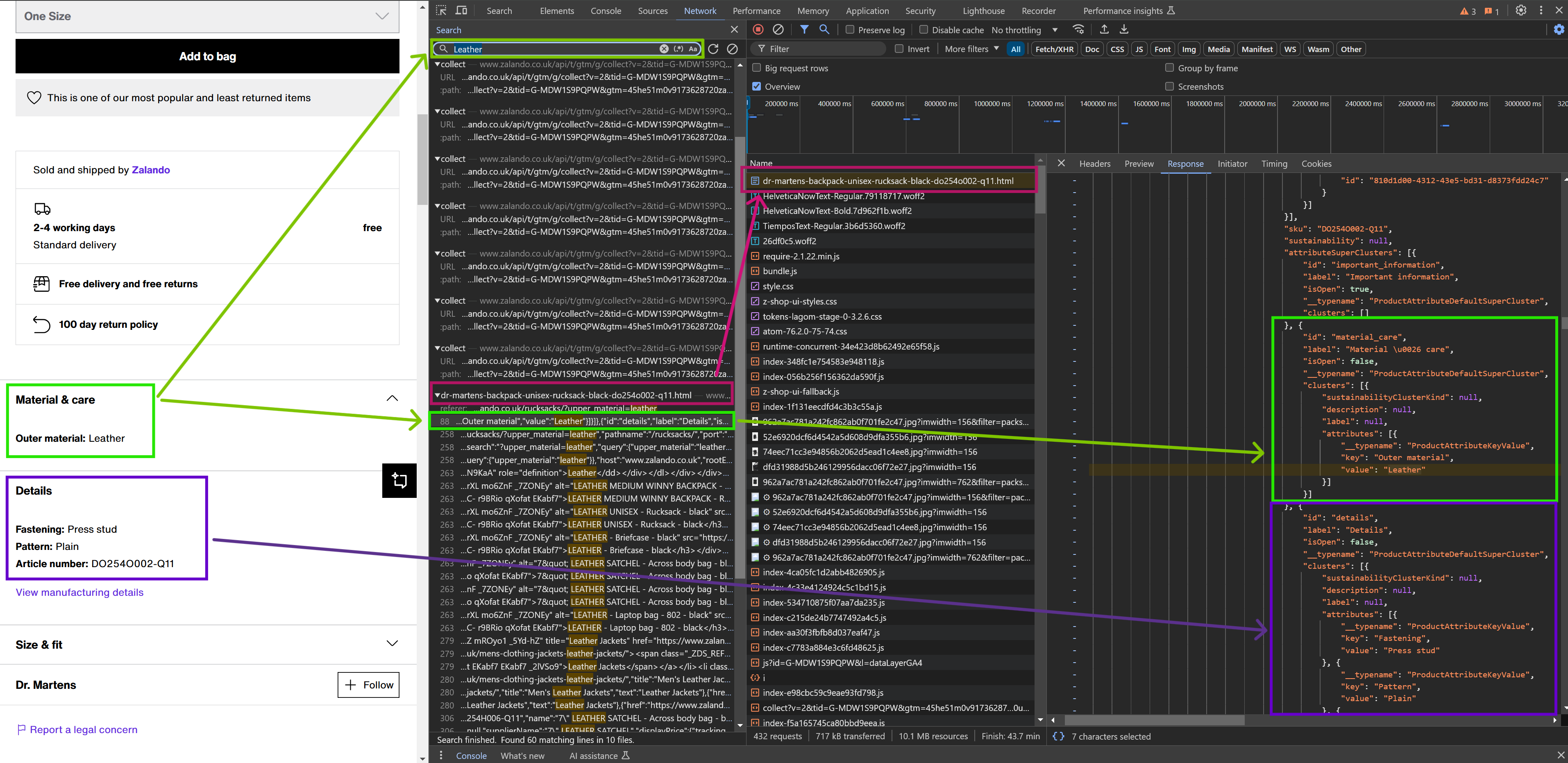
Searching by keyword/substring can sometimes be tricky, so it's worth experimenting with different terms. In our example with leather material, searching for the full phrase "Outer material: Leather" instead of just "leather" might seem like a good approach. However, this wouldn't return any results because "Outer material" and "Leather" are stored separately in the data source as an attribute key and value.
Extracting data from JSON-LD
Before moving forward, let's not overlook a valuable data source found on many websites: JSON-LD. This structured data format has several advantages:
- It can usually be located using the same CSS selector:
script[type="application/ld+json"]. - It follows a standardized format, so similar entities will likely share a consistent structure (e.g., recipes across different recipe websites).
However, JSON-LD also has some limitations:
- It may not include all the data displayed on the page, as the schema restricts what can be included.
- Some values might not be properly typed. Strings are often used instead of numbers, which can require additional processing.
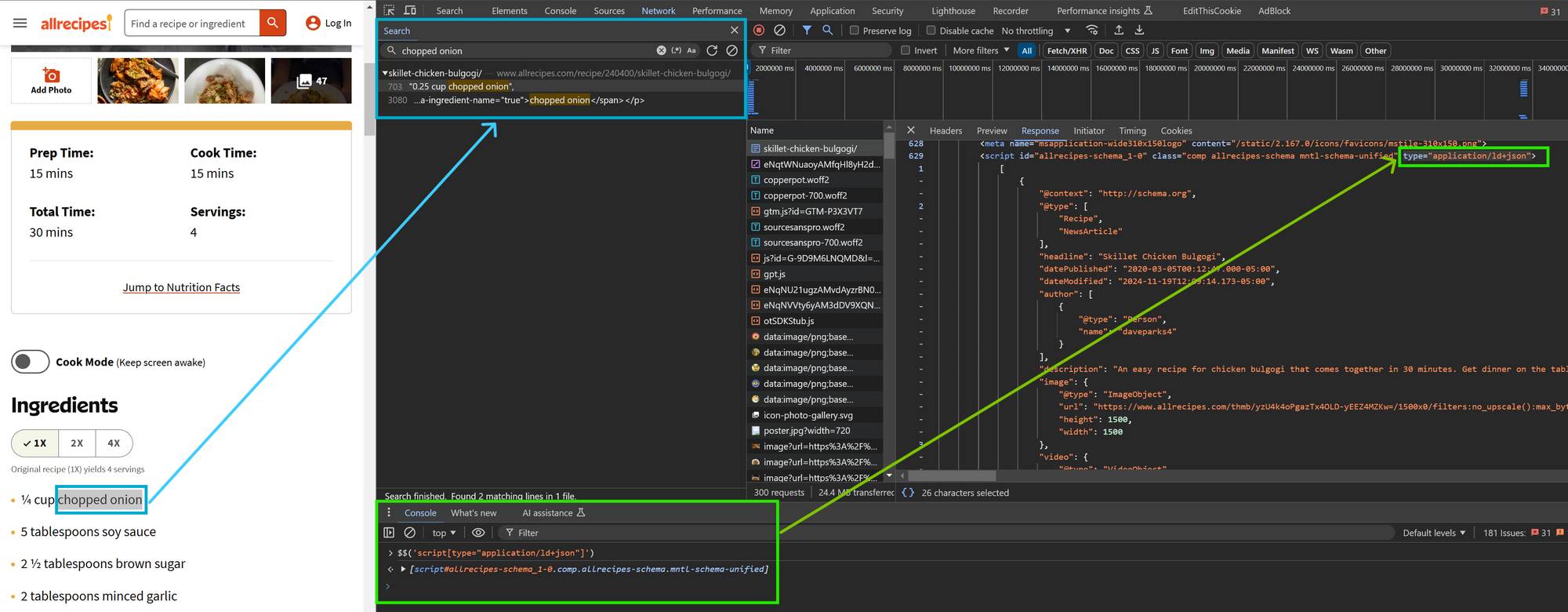
For example, consider the recipe page Skillet Chicken Bulgogi from Allrecipes. The screenshot below shows how JSON-LD data can be found using the script[type="application/ld+json"] selector in the DevTools Console. Notice the special syntax with double $: $$('script[type="application/ld+json"]'), which serves as an alternative to document.querySelectorAll('script[type="application/ld+json"]'). Likewise, the single $ syntax can be used instead of document.querySelector('script[type="application/ld+json"]').
Part 2 – Testing API requests
In our previous example with the Zalando website, we found structured data within a script element inside the main HTML document. That’s just one possible source of structured data. This time, we'll take a look at dedicated API requests that return JSON data.
Our test scenario will be scraping Airbnb listing reviews. When we visit a listing page and expand all reviews, we're redirected to a URL like: https://www.airbnb.com/rooms/1210760850228869300/reviews.
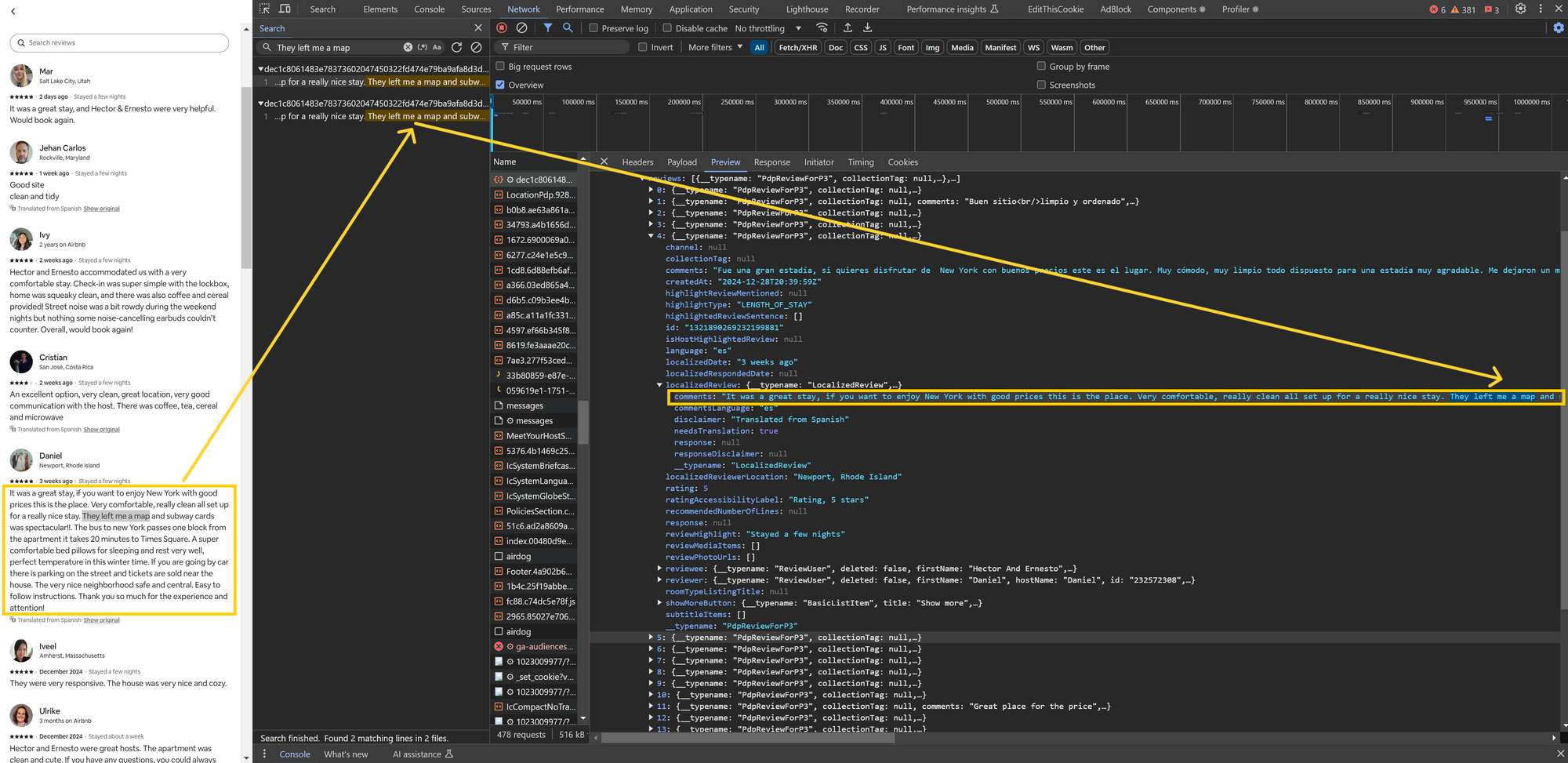
To locate the API request containing review data, we’ll apply the text-search method we learned in the previous example. Copying a snippet of review text, like 🔍 "They left me a map and subway cards", and searching for it helps us quickly identify the relevant API request.
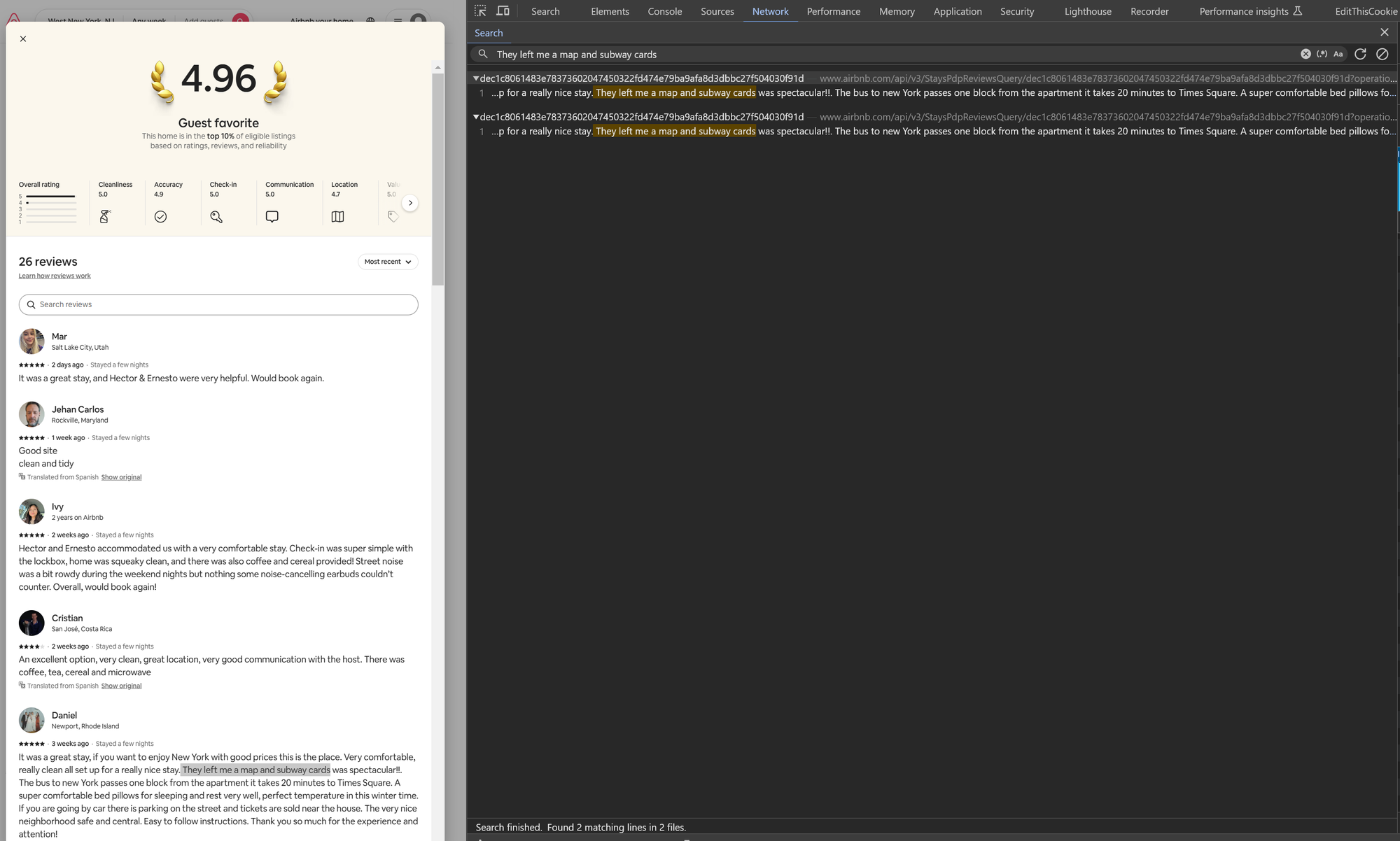
We discovered a request starting with https://www.airbnb.com/api/v3/StaysPdpReviewsQuery. The JSON response contains well-structured data for over 20 reviews. To quickly review the response content, the Preview tab is useful, while the Response tab is better for copying the full JSON data.
Reproducing the request outside the browser
How can we replicate the request outside the web browser? If it’s a simple GET request without special headers, we can just copy the request URL and use it in our web scraper. However, things get more complicated when dealing with non-GET methods (POST, PUT, DELETE, UPDATE), request headers, and payload.
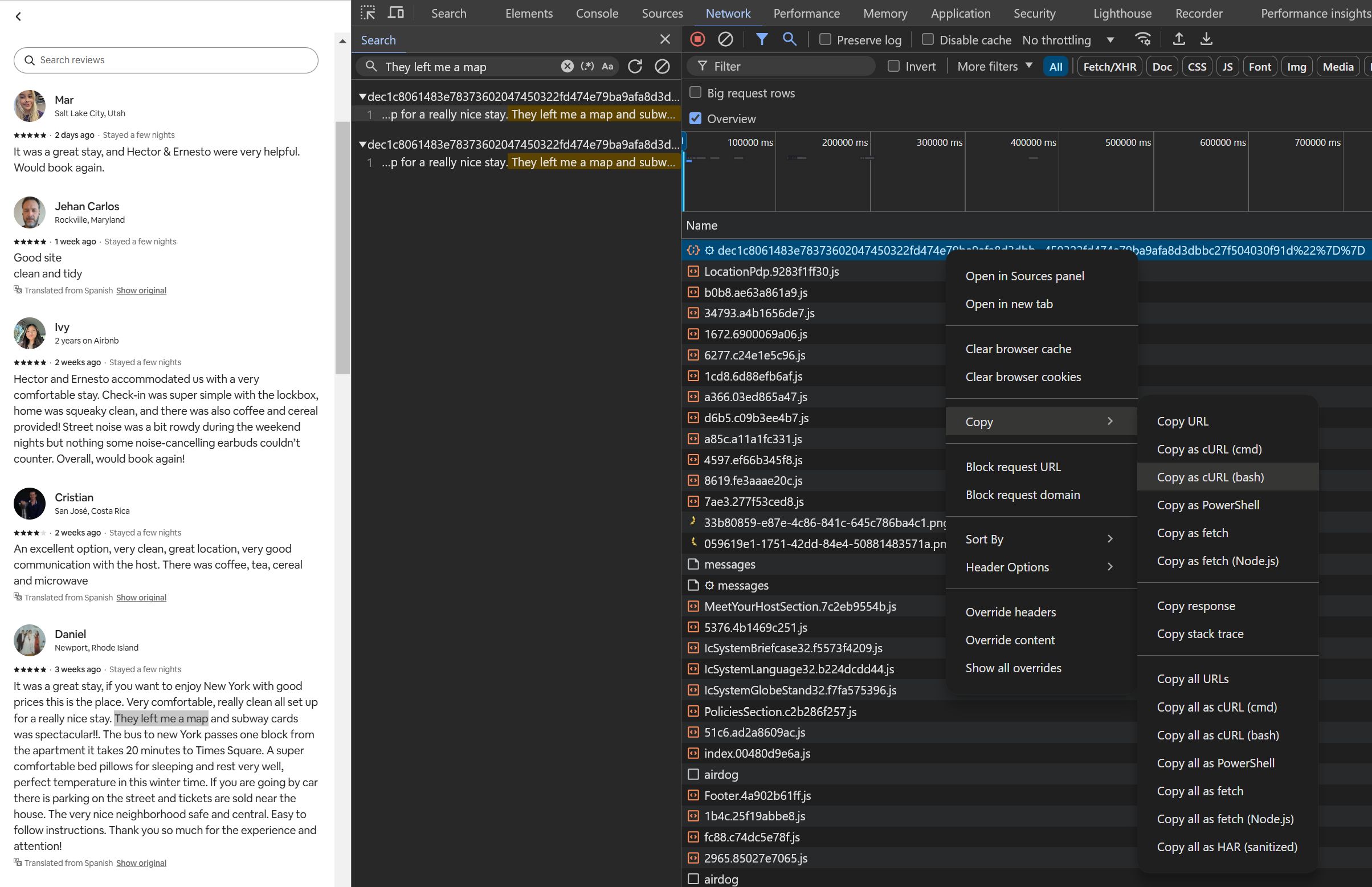
Most requests include numerous headers, but only a few are actually necessary. Luckily, there’s a quick way to copy requests from the Network tab in the browser’s developer tools and test them in the terminal or tools like Postman or Insomnia. By right-clicking on a request, selecting Copy, and choosing a format, we can copy the request along with its method, query parameters, headers, and payload.
For this tutorial, we’ll use Copy as cURL (bash), which allows us to paste the request into a terminal and execute it with the curl command.
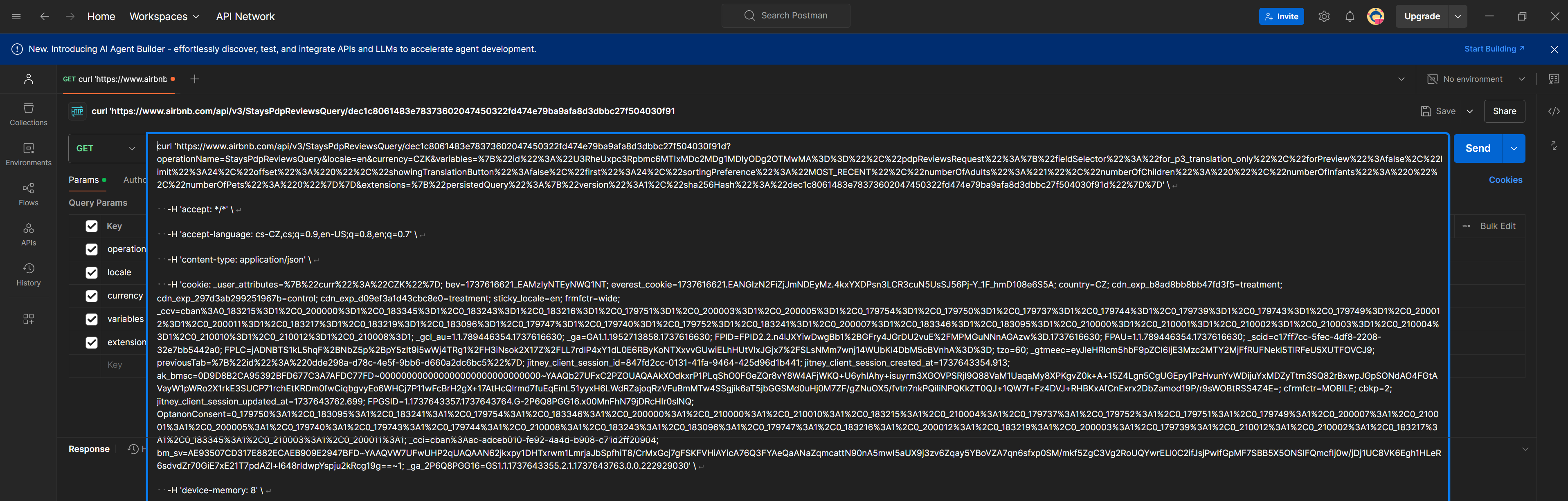
In Postman, you can import the request by creating a new request and pasting the full output of Copy as cURL (bash)into the Enter URL or paste text field. Postman will automatically extract the URL, method, payload, and headers, filling them into the appropriate boxes.
Optimizing request headers
Before you start playing with request headers, test sending the request using the Send button. If everything works correctly, you should receive the same response as seen in the browser. In most cases, the response body is all you need, but sometimes response headers (especially cookies) can be useful. For example, if the request initializes a session, the Set-Cookie header might include a session identifier.
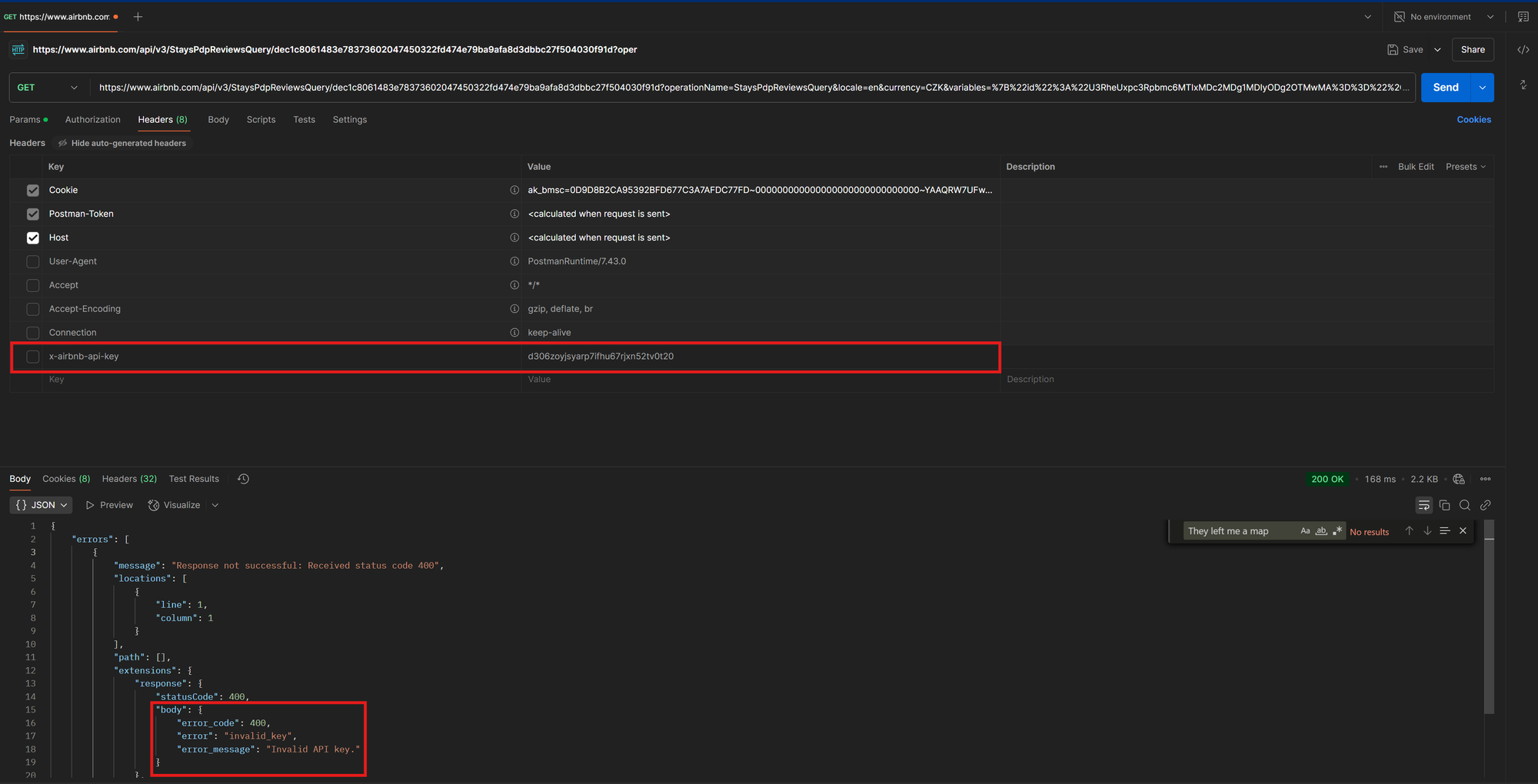
Once the request works as expected, begin disabling headers one by one or in batches, resending the request each time. This process helps determine the minimal set of headers required for a successful response. Be sure to check the response carefully. Sometimes a request might return a 200 OK status but still be missing key data. To verify, you can search for the same text as before, such as They left me a map.
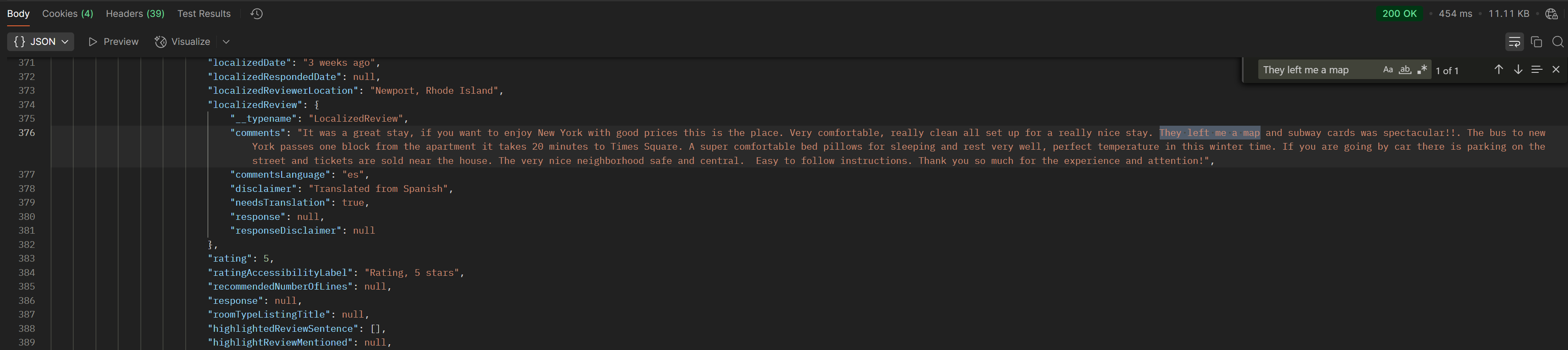
In our Airbnb reviews example, we can disable or remove all request headers except for Host and x-airbnb-api-key. Removing the Host header results in a 400 Bad Request error, while omitting the API key leads to a response containing only an error object with no data. It's worth noting that in this case, the API key is static, meaning it can be used as a constant.
Organizing your requests
You can save your test request into a collection, allowing you to group it with other related API requests for easy access and future reference, as shown in the screenshot below.
Part 3 - Understanding and modifying request structure
In the previous sections, we learned how to find relevant API requests and test them outside the browser. But we've only worked with requests for a single resource so far, such as one product, review, or recipe. While this is a great starting point, the real goal is to generalize these requests so we can extract more data, like all reviews for a specific listing.
To achieve this, we need to understand the request structure. This means identifying which parameters define the resource, which ones control aspects like language, and which remain constant. For search-related requests, we also need to figure out how to navigate between pages or simulate infinite scrolling.
Real-world example: scraping music tracks
Carefully analyzing the request URL, query parameters, payload (if applicable), and headers is crucial. Let’s look at an example API request that retrieves data for a user's music tracks from SoundCloud. We'd like to extract all tracks by Linkin Park available at https://soundcloud.com/linkinpark/tracks.
Using the browser's developer tools, we identified the following GET request on the first page of a user's tracks:
https://api-v2.soundcloud.com/users/1818488/tracks?representation=&client_id=1HxML01xkzWgtHfBreaeZfpANMe3ADjb&limit=20&offset=0&linked_partitioning=1&app_version=1739181955&app_locale=en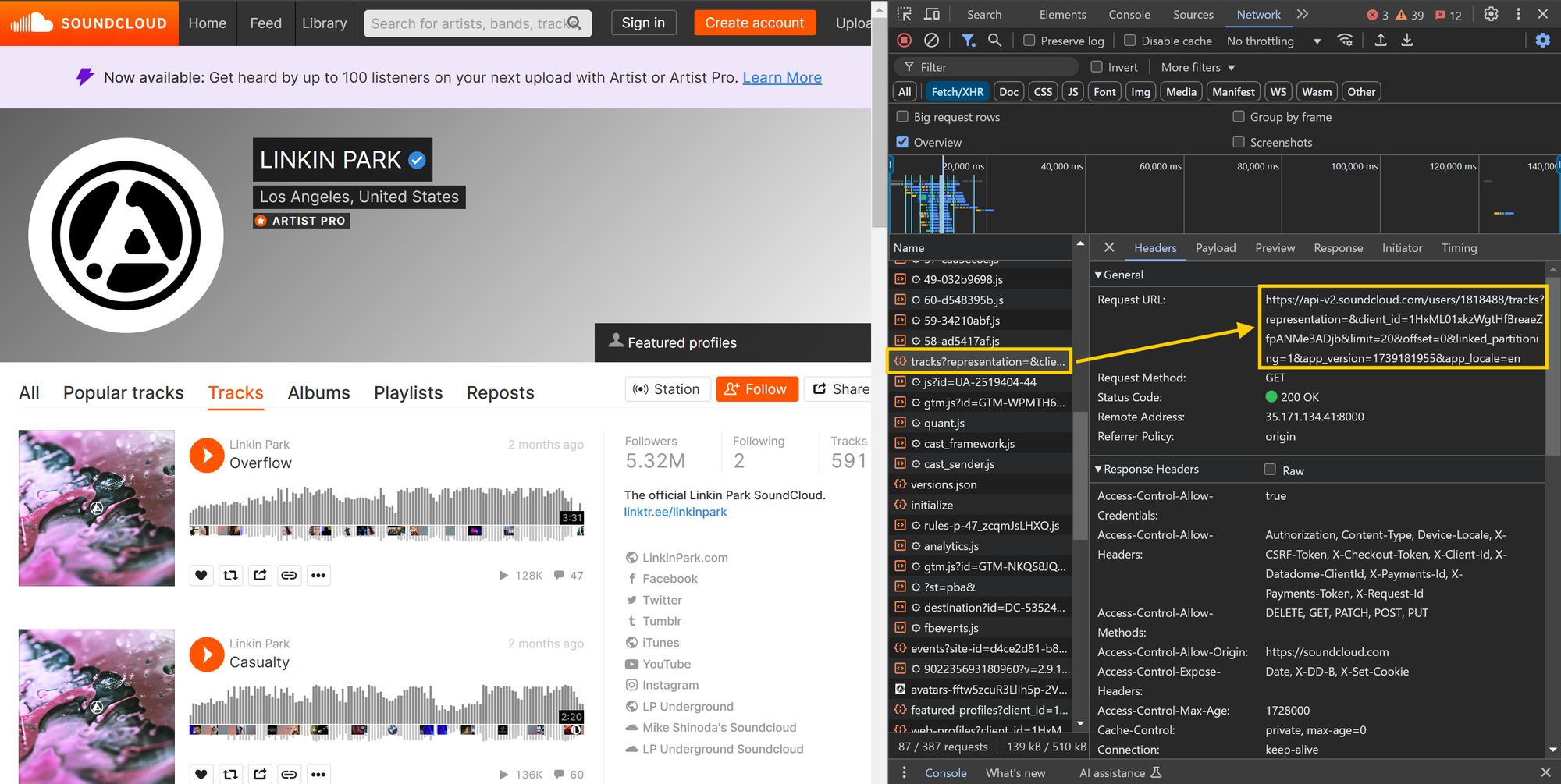
You can test this URL directly in your web browser or in Postman / Insomnia. There are no specific headers required, and you don't need to worry about the payload as well since it is a GET request. You should receive a detailed JSON response.
Now, let’s break down the URL into its components: the base API URL, path, and query parameters. This example below comes from the article Learning the API in our Web Scraping Academy. Be sure to check it out for more insights on API scraping and other topics.
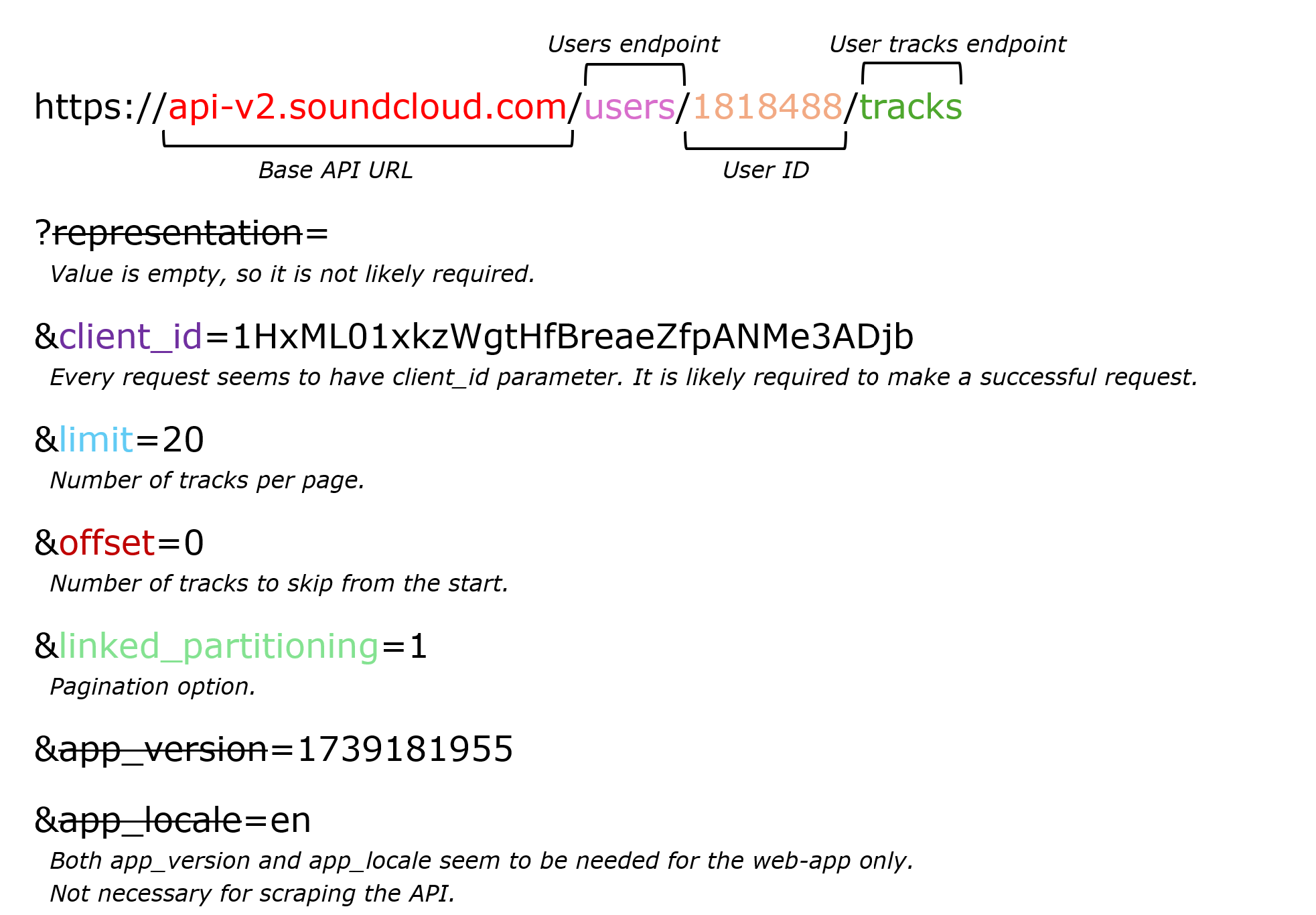
You can infer the following details from the request's URL:
- User Identification: Linkin Park is identified by the user ID
1818488in the URL's path. To scrape tracks from a different user, replace this ID accordingly. - Pagination: The API manages pagination using
limitandoffsetparameters. For example,offset=0&limit=20fetches the first 20 results whileoffset=20&limit=20retrieves results 21-40, and so on. You can experiment withlimitto find the highest allowed value, minimizing the number of requests needed to extract all results. - Optional parameters: Some parameters, such as
representation,app_version, andapp_locale, can be omitted without affecting the request. - Required API key: The
client_idparameter is essential for the request to work. Check if this value is static or dynamically generated by testing requests in multiple anonymous browser sessions. - Finding related requests: To explore other API requests from the same source, filter the requests in the dev tools'
Networktab usingapi-v2.soundcloud.com. This will show all requests made to SoundCloud’s API, helping you discover additional endpoints.
For requests using methods other than GET, you'll need to analyze the request payload/body in a similar manner. While we won’t provide a separate demonstration, the process remains largely the same. The key difference is that these requests must be tested outside the web browser using tools like Postman or Insomnia.
Navigating pagination
When scraping APIs, you'll often encounter limits on the number of results per request. To retrieve all data, you need to handle pagination properly. Common pagination methods include:
- Page-number pagination – Uses a
pageparameter to request specific result pages. - Offset pagination – Uses
offsetandlimitparameters to define how many results to skip and retrieve. - Cursor pagination – Uses a marker (
cursor) to indicate the starting point for the next set of results. The cursor can be a date, ID, or random string.
Keep in mind that parameter names don't follow strict naming conventions. Instead of page, limit, offset or cursor, some APIs may use variations like p, pg, count, maxItems, o, skip, c or other names and shortcuts.
For a deeper dive, check out the Handling pagination chapter in our Academy.
Part 4 – Building a web scraper and automating data extraction
In the previous sections, we covered how to find relevant data sources, test API requests outside the browser, and modify request parameters to extract more data. Now, it's time to take the final step: building a web scraper to automate data extraction at scale.
Handling API requests manually for each page is inefficient, especially for large datasets. A web scraper automates data collection by programmatically fetching and processing data from websites. Postman offers handy code snippets to get started, supporting various programming languages and frameworks like Node.js - Axios, Python - Requests, and more. Simply click the </> icon to open the code snippet panel and start automating your requests.
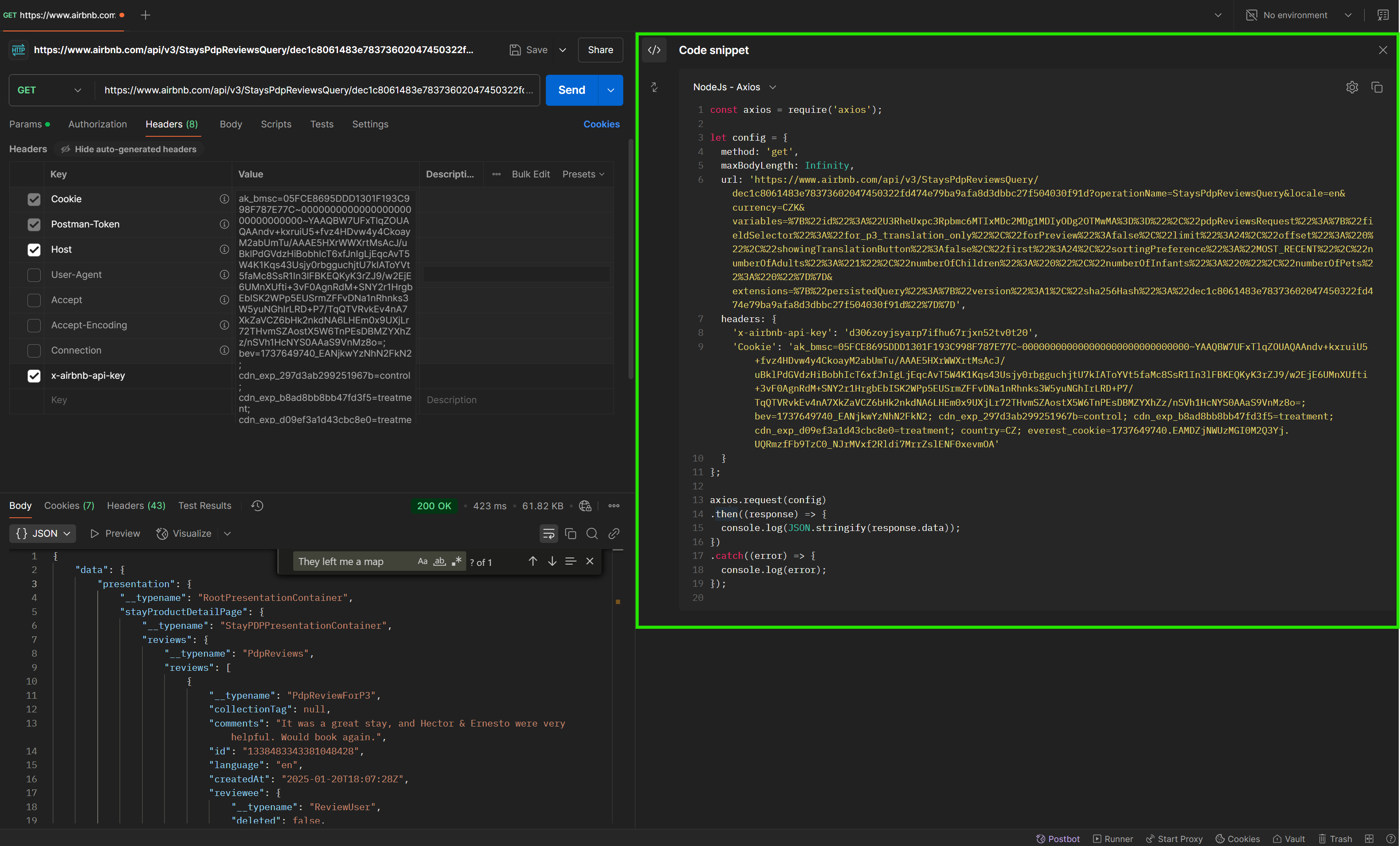
Building a scraper with Crawlee
Even with a working code snippet, there’s still plenty of work to do:
- Define handlers for different types of requests (search, detail, reviews, ...)
- Manage and synchronize concurrent requests
- Store extracted data in a structured dataset
- Use proxies to avoid blocking
- Implement logging and error handling
To help you out, here's our open-source web scraping library:
- Crawlee (JavaScript/TypeScript, Node.js)
- Crawlee for Python
You can quickly set up a project using one of the following commands (depending on your technology stack and preferences):
npx crawlee create my-crawler(JavaScript/TypeScript)pipx run crawlee create my-crawler(Python)
When working with API requests, HTML documents, or both, you can use CheerioCrawler template. Its pre-defined request handler offers a json object for API responses and a $ Cheerio object for parsing HTML using CSS selectors and jQuery-like syntax.
Deploying your scraper to Apify
For a more powerful and scalable solution, deploy your web scraper as an Apify Actor on the Apify cloud platform. Running your scraper in the cloud allows for automation, scheduling, and seamless scaling without worrying about infrastructure. Get started by creating a project directly from Apify CLI templates using this command:
apify createWith another single command, you can deploy the scraper to your Apify account:
apify pushAlternatively, you can integrate it with your Git repository.
Tips for API scraping
1. Optimize items per page limit
When fetching data via API requests, check the limit for the number of items per page by inspecting query parameters in the URL or request payload. Many APIs allow increasing this limit, reducing the total number of requests needed. Experiment with different values to find the highest limit allowed.
2. Use anonymous windows
When analyzing network requests in the dev tools' Network tab, use an anonymous (incognito) window, especially when copying request data. Make sure you're logged out of the website to prevent issues with accessing content that requires authentication.
3. Pay attention to cookies
When testing requests outside your browser, check the cookies being sent, as they can impact functionality. In Postman, you can inspect them by clicking Cookies under the Send button. Some requests may require a session ID from the target website to work correctly. If you overlook this, you might get inconsistent results between Postman, Insomnia, and your web scraper. However, if the request works fine without cookies, you can ignore them.
4. Decode Base64 encoded data
If you encounter seemingly random strings in request URLs, headers, payloads, or responses, try decoding them using Base64. Some APIs encode parameters, listing IDs, or other data in this format. You can use online tools for testing, such as Base64 Decode and Base64 Encode.
5. Handling request chains
Some APIs rely on a sequence of connected requests, where one request sets up necessary data or authentication before the next can retrieve the desired information. For example, you may need to send an initial POST request to initialize a session before making the main data request.
If a request fails due to missing parameters or tokens, inspect earlier requests to identify dependencies. Use the browser’s dev tools to search network traffic and analyze headers (especially Set-Cookie) and responses. You can also search for missing values using the Search from the Network tab, as we explained above.