


When RapidAPI first appeared, it looked like the perfect place to publish your API. Setup was simple, and billing was supposedly handled for you — so you could focus on building instead of chasing invoices. It grew into the largest API marketplace, with tens of thousands of APIs listed.
But if you’ve tried it, you know the reality can be different. For developers building scrapers, automation tools, and data APIs, RapidAPI’s strengths — a big catalog and straightforward listing process — don’t translate into the features you actually need for web data extraction tools: reliability under heavy load, resistance to blocking, and predictable monetization.

RapidAPI itself is now part of Nokia, acquired in late 2024 and folded into its “Network as Code” platform. The public API hub still exists, but so far, there are no publicly documented changes to core marketplace mechanics (infrastructure, monetization, support) since Nokia’s acquisition. Developers are generally responsible for scraper infrastructure (hosting, scaling, proxies, etc.), while hoping they gain traction in a very general-purpose directory.
Apify, by contrast, was built specifically for scraping and automation. It doesn’t try to be a universal API hub; it provides infrastructure, tools, and a marketplace tailored to extracting and automating data at scale.
The differences between RapidAPI and Apify
RapidAPI: A marketplace, not a platform
RapidAPI is fundamentally a marketplace. If you want to publish a scraper for Amazon, LinkedIn, or an e-commerce site, you first need to build it yourself, host it on your own servers, and then list it on RapidAPI. The platform doesn’t provide scraping infrastructure — it simply exposes what you’ve already built.
Apify: Turning websites into APIs
Apify doesn’t just host APIs — it turns websites into APIs. You write scraper logic once, and the platform provides a ready-to-call API endpoint with structured JSON, CSV, or Excel output. Hosting, scaling, and delivery are included.
| Capability | RapidAPI (Nokia) | Apify |
|---|---|---|
| Core role | API marketplace | Scraping and automation platform |
| What you bring | Fully built + hosted API | Scraper logic (infra provided) |
| Output formats | Varies per API | JSON, CSV, Excel, feeds built-in |
| Hosting | Developer-managed | Auto-scaled containers |
Standardization with Apify Actors
A big challenge on RapidAPI is inconsistency: every listing has different inputs, authentication methods, and output formats. Customers must learn how each one works from scratch.
Apify addresses this with its Actor model.
| Feature | RapidAPI | Apify |
|---|---|---|
| Inputs and outputs | ❌ Inconsistent | ✅ Standardized JSON in/out |
| Execution model | ❓ Varies | ✅ Containerized Actor runs |
| Data export | ❓ Depends on developer | ✅ JSON, CSV, Excel, feeds built-in |
| Scheduling | ❌ Manual setup | ✅ Built into Console |
An Apify Actor is a cloud program packaged as a container with standardized inputs and outputs. Each run spins up in its own container with dedicated CPU and memory. You pass in a JSON input, the Actor executes (scraping, transforming, automating), and results are stored automatically in built-in storages:
- Datasets for structured results
- Key-value stores for inputs/outputs/files
- Request queues for crawl scheduling
Actors can be triggered directly from Apify Console or via API. Each run behaves like a reliable API endpoint: consistent inputs, predictable outputs, and logs you can inspect in real time. You can schedule Actors to run on recurring jobs, trigger them with webhooks, and export results in JSON, CSV, Excel, or other formats.
This consistency fuels Apify Store. Customers know every Actor follows the same lifecycle — set inputs, run in the cloud, export results. For developers, that means your tools drop into a marketplace where buyers already understand how to use them, without custom docs or onboarding.
Infrastructure and scraping capabilities
Scraping isn’t just about writing logic, but keeping it alive at scale. Sites block requests, sessions expire, proxies burn out, and data spikes without warning. On RapidAPI, all of that is your responsibility. You must host and monitor servers, build retries, rotate sessions, add proxy layers, scale resources, and handle compliance yourself. RapidAPI mainly provides billing and exposure.
Apify removes that burden by baking both scraping helpers and infrastructure management into the platform. The SDK and Apify's open-source Crawlee library give you the core primitives for reliable scraping: request queues, session rotation and fingerprinting, retries, and proxy integration. Every Actor runs in a managed container that auto-scales, with logs, monitoring, and scheduling built into the Console. For larger customers, enterprise needs like SOC 2 compliance, GDPR readiness, and audit support are covered too.
| Need | RapidAPI | Apify |
|---|---|---|
| Request queues | ❌ DIY | ✅ Built-in |
| Session rotation & anti-blocking | ❌ DIY | ✅ SDK helpers |
| Error handling & retries | ❌ DIY | ✅ Built-in |
| Proxy support | ❌ Bring your own | ✅ Integrated Apify Proxy |
| Auto-scaling | ❌ Developer-managed | ✅ Fully managed |
| Logging & monitoring | ❌ Manual setup | ✅ Built-in Console |
| Compliance | ❌ Minimal | ✅ SOC 2, GDPR, audits |
Marketplace and monetization
I was making something like $500 a month on other side projects, but now Apify is bringing in more than $2,000 from Apify Store
– Guillaume Lancrenon, CTO and CPO of getcockpit.io

RapidAPI casts a wide net, listing everything from SMS APIs to payment gateways to weather feeds. Scrapers and automation tools are just one category among many, which makes discovery difficult and revenue inconsistent. Even if you set up plans and quotas, traction often depends on standing out in a very broad catalog.
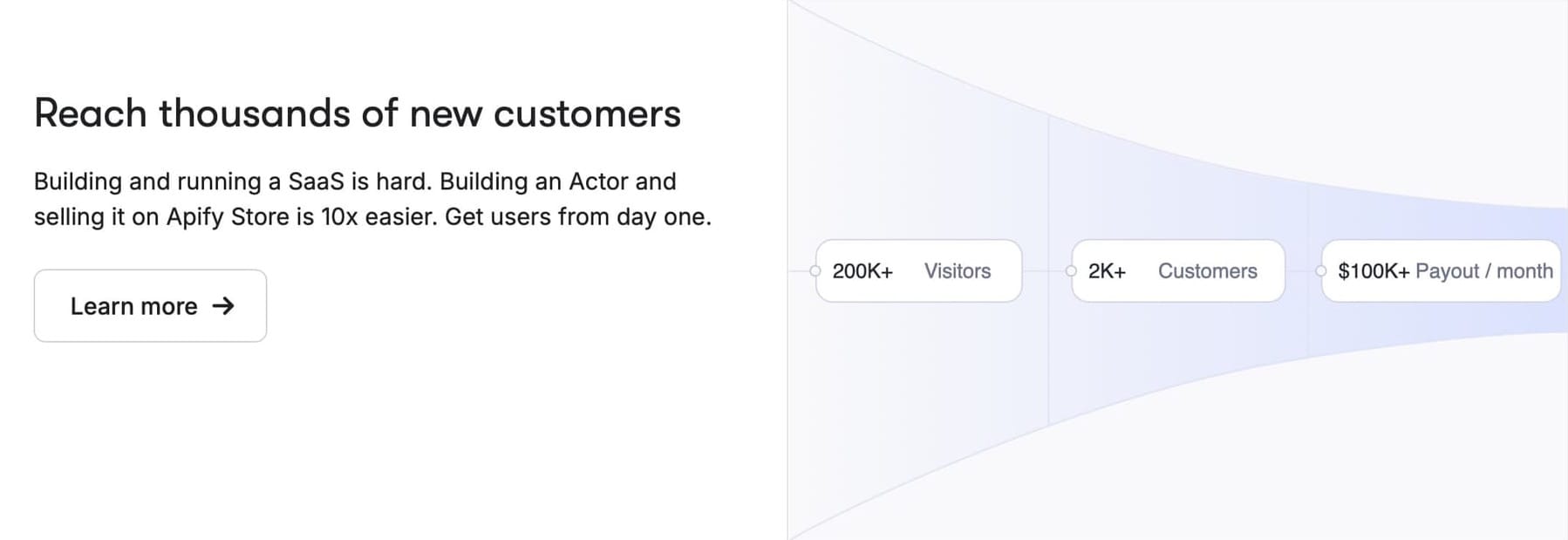
Apify takes a different approach. Apify Store is dedicated to scraping and automation, with over 10,000 maintained Actors. Customers browsing there aren’t looking for “any API” — they’re already searching for scrapers, automations, and data pipelines. That alignment drives adoption.

Monetization is built in: customers can subscribe to Actors, pay per run/event, or commission private/custom tools. Because the marketplace is focused, your scrapers are placed directly in front of the buyers who want them.
| Factor | RapidAPI | Apify |
|---|---|---|
| Marketplace scope | Broad, general-purpose | Focused on scraping and automation |
| Discovery | Mixed quality, varied intent | Curated Store with scraper-focused buyers |
| Monetization model | Subscription tiers and quotas | Pay per event, subscriptions, custom Actors |
| Developer results | Mixed traction | Documented recurring income |
Why switch from RapidAPI to Apify?
RapidAPI, now part of Nokia, still has value as a broad API catalog. If you’ve already built and hosted an API and just need exposure, it remains a large marketplace.
But if your focus is scraping, automation, or data APIs, Apify gives you what RapidAPI never did:
- A platform that turns websites into APIs
- Standardized Actors with predictable inputs/outputs
- SDKs and libraries that handle scraping challenges out of the box
- Managed infrastructure with compliance built in
- A marketplace aligned with your product type
- Clearer monetization pathways
If you’d rather spend time building tools instead of managing infrastructure, and earn passive income from what you've published, start building on Apify.

Note: This evaluation is based on our understanding of information available to us as of January 2026. Readers should conduct their own research for detailed comparisons. Product names, logos, and brands are used for identification only and remain the property of their respective owners. Their use does not imply affiliation or endorsement.



