Before we dive into what’s been happening in the new year, let’s recap the last one.
2019 in numbers
- 60,000+ users
- 600+ customers
- 1,000,000,000+ pages scraped monthly
- 3,315 TB of data extracted
- Doubled our internal team & Marketplace developers
And 2020 is shaping up to be even better! Read on to find out what’s new at Apify.
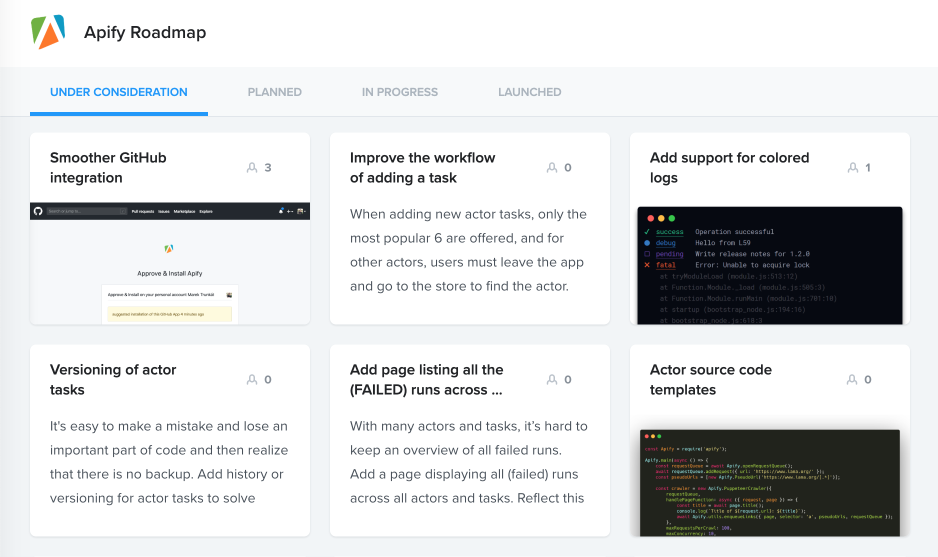
Public Apify roadmap
Your favorite web scraping platform needs you! We’re continuously updating the Apify roadmap to keep you up to date with what we have planned. Many new feature proposals are waiting for your feedback. Note that the Apify roadmap is no longer online. Join our Discord to give us your ideas!
Scraping tools
We’ve just added a new Scraping tools page to the Apify website.
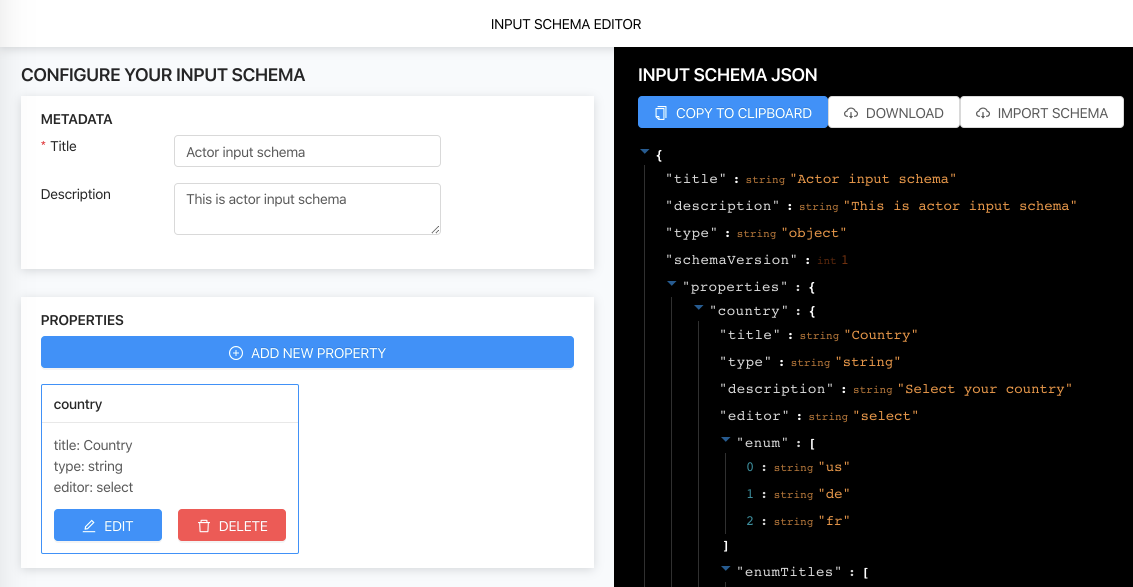
You can check out the brand new Input Schema Editor that simplifies the creation of Input Schema using an intuitive user interface for your next public Actor.
Also, if you haven’t tried it yet, give Page Analyzer a shot. It loads pages using headless Chrome and analyzes the HTML and JavaScript objects on the page, looks for schema.org microdata and JSON-LD metadata, analyzes AJAX requests, etc. to find the best way to extract the data you want.
Small things that make life easier
We’re continuously updating our user interface to improve user and developer experience. Here are some small improvements from the past weeks:
- Search has been added to Apify documentation.
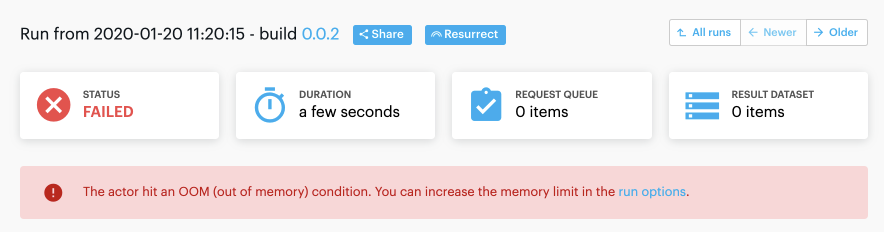
- If an Actor fails for common reasons, you’ll now see a hint explaining what happened:
- We’ve added a new top bar providing access to help and user accounts. This will be utilized more with the upcoming team accounts and later as a notification center:
- You can also now find our support chat under the help icon:
Apify SDK now supports intelligent session rotation
We’ve added a new class, SessionPool, to intelligently manage the rotation of IP addresses, cookies, and the HTTP headers of your crawlers in order to avoid blocking by target websites. This feature is integrated with PuppeteerCrawler and CheerioCrawler so that you can use it out of the box.
That’s all for now. Stay tuned for more updates! Want the latest news? Follow us on Twitter.